9.(Python数模)(分类模型一)K-means聚类
Python实现K-means聚类
K-means原理
K-means均值聚类算法作为最经典也是最基础的无标签分类学习算法。其实质就是根据两个数据点的距离去判断他们是否属于一类,对于一群点,就是类似用几个圆去框定这些点(簇),然后圆心的心就是聚类中心。
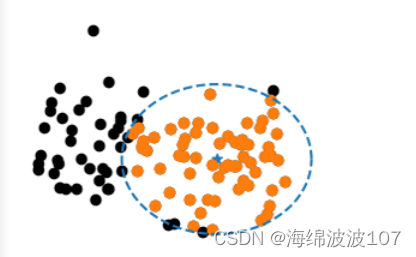
示例一
源代码
from sklearn.cluster import KMeans
import numpy as np# 构造数据样本点集X,并计算K-means聚类
X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]])
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)# 输出及聚类后的每个样本点的标签(即类别),预测新的样本点所属类别
print(kmeans.labels_)
print(kmeans.predict([[0, 0], [4, 4], [2, 1]]))
在这个例子中,KMeans函数的参数意义如下:
n_clusters:表示要创建的聚类数目,这里设置为2,意味着将数据划分为两个簇。
n_init:表示执行算法的次数,每次执行都会随机初始化质心,选择具有最小总误差的结果作为最终模型。这里设置为10,意味着将执行10次算法并选择最好的结果。
random_state:是一个随机数生成器的种子,用于控制随机初始化质心的过程。通过设置相同的种子,可以使得每次运行都得到相同的结果。
.fit(X)表示对数据X执行K均值聚类算法,并训练模型。
运行结果

示例二
源代码
import time
import numpy as np
import matplotlib.pyplot as pltfrom sklearn.cluster import KMeans
from sklearn.metrics.pairwise import pairwise_distances_argmin
from sklearn.datasets._samples_generator import make_blobs# ######################################
# Generate sample data
np.random.seed(0)batch_size = 45
centers = [[1, 1], [-1, -1], [1, -1]]
n_clusters = len(centers)
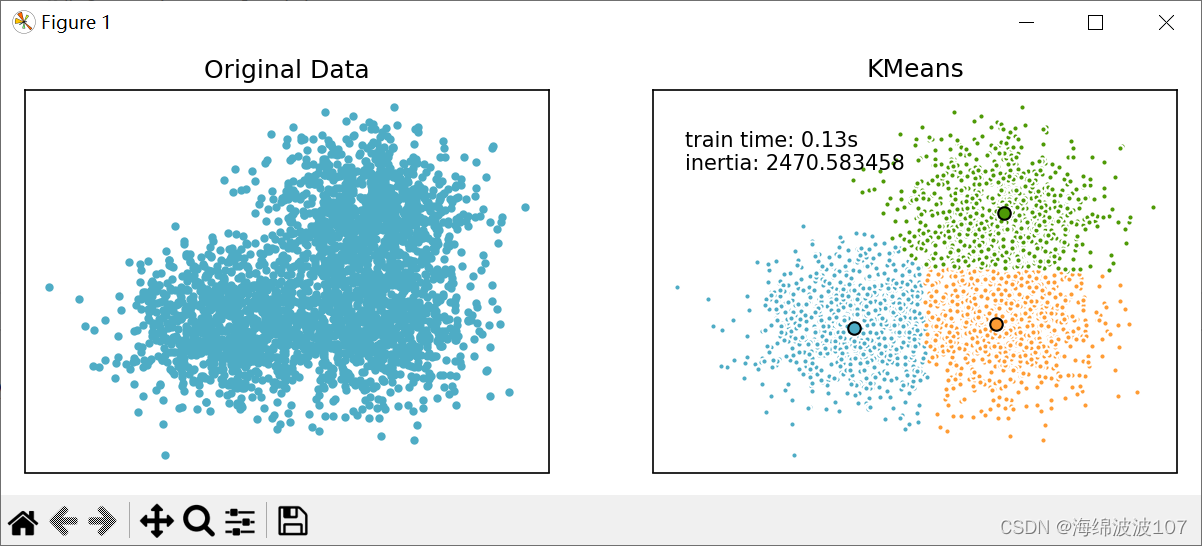
X, labels_true = make_blobs(n_samples=3000, centers=centers, cluster_std=0.7)# plot result
fig = plt.figure(figsize=(8,3))
fig.subplots_adjust(left=0.02, right=0.98, bottom=0.05, top=0.9)
colors = ['#4EACC5', '#FF9C34', '#4E9A06']# original data
ax = fig.add_subplot(1,2,1)
row, _ = np.shape(X)
for i in range(row):ax.plot(X[i, 0], X[i, 1], '#4EACC5', marker='.')ax.set_title('Original Data')
ax.set_xticks(())
ax.set_yticks(())# compute clustering with K-Means
k_means = KMeans(init='k-means++', n_clusters=3, n_init=10)
t0 = time.time()
k_means.fit(X)
t_batch = time.time() - t0k_means_cluster_centers = np.sort(k_means.cluster_centers_, axis=0)
k_means_labels = pairwise_distances_argmin(X, k_means_cluster_centers)# K-means
ax = fig.add_subplot(1, 2, 2)
for k, col in zip(range(n_clusters), colors):my_members = k_means_labels == k # my_members是布尔型的数组(用于筛选同类的点,用不同颜色表示)cluster_center = k_means_cluster_centers[k]ax.plot(X[my_members, 0], X[my_members, 1], 'w',markerfacecolor=col, marker='.') # 将同一类的点表示出来ax.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col,markeredgecolor='k', marker='o') # 将聚类中心单独表示出来
ax.set_title('KMeans')
ax.set_xticks(())
ax.set_yticks(())
plt.text(-3.5, 1.8, 'train time: %.2fs\ninertia: %f' % (t_batch, k_means.inertia_))plt.show()
运行结果
代码注释
1、使用Scikit-learn库中的make_blobs函数来生成随机的高斯分布数据集。通过指定n_samples参数为3000,centers参数为所需的中心点数量,cluster_std参数为0.7来生成数据集。返回数据点和对应的标签列表。
数据点列表

标签列表
2、fig.subplots_adjust(left=0.02, right=0.98, bottom=0.05, top=0.9)这段代码用于调整子图的位置。它通过设置左边界、右边界、底边界和顶边界的值来控制子图的位置。在这个例子中,左边界被设置为0.02,右边界被设置为0.98,底边界被设置为0.05,顶边界被设置为0.9。这意味着子图将占据整个画布的宽度的96%(从左边界到右边界),并且在垂直方向上从底边界的5%位置开始,到顶边界的90%位置结束。通过调整这些值,你可以改变子图在画布上的位置和大小。
3、ax = fig.add_subplot(1,2,1)这是在 Python 中创建一个简单的单图形对象,使用 matplotlib 库中的 fig.add_subplot() 方法。它创建了一个包含一个子图的图形。子图是位置在 (1,1) 的唯一子图。该变量 b’ax’ 将该子图对象存储起来,以便可以使用它来设置图形属性和添加绘图元素。
4、k_means = KMeans(init=‘k-means++’, n_clusters=3, n_init=10)。K-Means是一种常用的无监督学习算法,用于将数据划分为预先指定数量的簇(clusters)。在代码中,参数init='k-means’指定了用K-Means算法初始化聚类中心,初始化的方法有三种:k-means++,random,或者是一个数组。
k-means++能智能的选择初始聚类中心进行k均值聚类,加快收敛速度。该示例中初始化了聚类中心[[1, 1], [-1, -1], [1, -1]],选择K-means++加快收敛。random则是从数据中随机的选择k个观测值作为初始的聚类中心。
n_clusters=3指定了要生成的簇的数量为3,n_init=10指定了进行不同初始值运行的次数,以选择最佳的聚类结果。
对比
使用k-means++方法

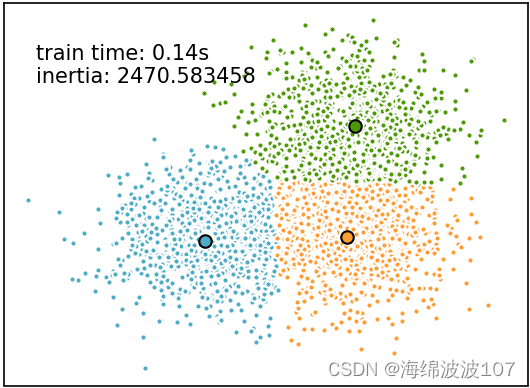
使用random方法的3个聚类中心

运算时间为0.14s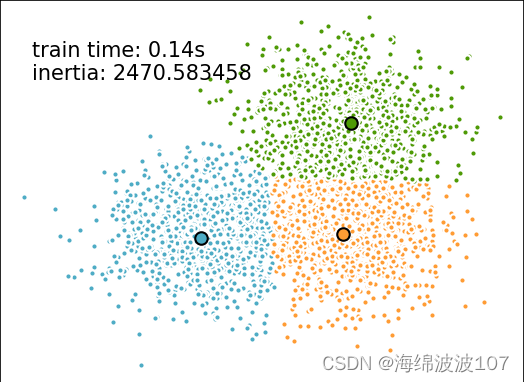
两种方法总内部方差一样,运算时间也一样,当更换为更大的数据时30000样本时,在相同运算时间下,k-means++计算的总内部方差更小,收敛效果更好。
5、k_means.fit(X)。使用了k-means算法的fit()方法来拟合数据集X。
6、k_means_cluster_centers = np.sort(k_means.cluster_centers_, axis=0)。在这段代码中,k_means是聚类模型,k_means.cluster_centers_是获取聚类中心的属性,np.sort是对聚类中心进行排序的函数,axis=0表示按照列的顺序进行排序。最后,k_means_cluster_centers存储了排序后的聚类中心。
聚类中心的属性如下:

排序后结果如下:

7、k_means_labels = pairwise_distances_argmin(X, k_means_cluster_centers)pairwise_distances_argmin()是一个函数,它根据输入的数据点X和K-means聚类算法的中心点k_means_cluster_centers,计算每个数据点最近的中心点,并返回对应的标签。换句话说,它会将数据点分配到最近的簇中,并返回每个数据点所属的簇标签。
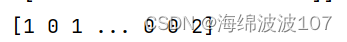
8、my_members = k_means_labels == k
得到一个布尔值列表,用于下面索引选出不同的类
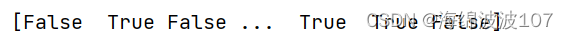
参考博文
Python学习——K-means聚类
一文速学数模-聚类模型(一)K-means聚类算法详解+Python代码实例
相关文章:
9.(Python数模)(分类模型一)K-means聚类
Python实现K-means聚类 K-means原理 K-means均值聚类算法作为最经典也是最基础的无标签分类学习算法。其实质就是根据两个数据点的距离去判断他们是否属于一类,对于一群点,就是类似用几个圆去框定这些点(簇),然后圆心…...
MinIO集群模式信息泄露漏洞(CVE-2023-28432)
前言:MinIO是一个用Golang开发的基于Apache License v2.0开源协议的对象存储服务。虽然轻量,却拥有着不错的性能。它兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据。该漏洞会在前台泄露用户的账户和密码。 0x00 环境配置 …...

【从零单排Golang】第十五话:用sync.Once实现懒加载的用法和坑点
在使用Golang做后端开发的工程中,我们通常需要声明一些一些配置类或服务单例等在业务逻辑层面较为底层的实例。为了节省内存或是冷启动开销,我们通常采用lazy-load懒加载的方式去初始化这些实例。初始化单例这个行为是一个非常经典的并发处理的案例&…...
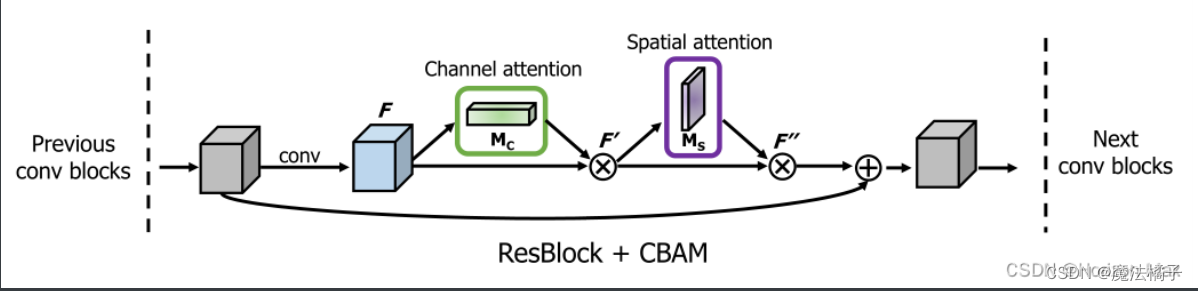
常见注意力机制
注意力机制 (具有自适应性) 18年提出的一种新的 卷积注意力模块 ;对前馈卷积神经网络 是一个 简单而有效的 注意力模块 ; 因为它的 轻量级和通用性 ,可以 无缝集成到任何CNN网络 当中, 对我们来讲&…...
解决报错之org.aspectj.lang不存在
一、IDEA在使用时,可能会遇到maven依赖包明明存在,但是build或者启动时,报找不存在。 解决办法:第一时间检查Setting->Maven-Runner红圈中的√有没有选上。 二、有时候,明明依赖包存在,但是Maven页签中…...

java之SpringBoot基础篇、前后端项目、MyBatisPlus、MySQL、vue、elementUi
文章目录 前言JC-1.快速上手SpringBootJC-1-1.SpringBoot入门程序制作(一)JC-1-2.SpringBoot入门程序制作(二)JC-1-3.SpringBoot入门程序制作(三)JC-1-4.SpringBoot入门程序制作(四)…...

golang中如何判断字符串是否包含另一字符串
golang中如何判断字符串是否包含另一字符串 在Go语言中,可以使用strings.Contains()函数来判断一个字符串是否包含另一个字符串。该函数接受两个参数:要搜索的字符串和要查找的子字符串,如果子字符串存在于要搜索的字符串中,则返…...

ONNX OpenVino TensorRT MediaPipe NCNN Diffusers ComfyUI
框架 和Java生成的中间文件可以在JVM上运行一样,AI技术在具体落地应用方面,和其他软件技术一样,也需要具体的部署和实施的。既然要做部署,那就会有不同平台设备上的各种不同的部署方法和相关的部署架构工具 onnx 在训练模型时可以…...
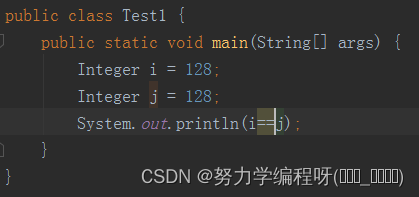
java中使用 Integer 和 int 的 含义、使用方法 及之间的区别
学习目标: 学习目标如下: 明确 Integer 和 int 的 含义、使用方法 及之间的区别 学习内容: 一、区别: 1.Integer是int的包装类,int则是java的一种基本的数据类型; 2.Integer变量必须实例化之后才能使用&a…...

点云从入门到精通技术详解100篇-点云的特征检测
目录 前言 点云配准的研究背景 多元时间序列的相似性分析研究背景及意义 国内外研究现状...

DOM破坏绕过XSSfilter例题
目录 一、什么是DOM破坏 二、例题1 编辑 三、多层关系 1.Collection集合方式 2.标签关系 四、例题2 一、什么是DOM破坏 DOM破坏(DOM Clobbering)指的是对网页上的DOM结构进行不当的修改,导致页面行为异常、性能问题、安全风险或其他不…...

代码随想录Day_56打卡
①、两个字符串的删除操作 给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字符串中的一个字符。 事例: 输入: word1 "sea", word2 "eat" 输出: 2 解释: 第一步将 "sea&…...

高忆管理:六连板捷荣技术或难扛“华为概念股”大旗
在本钱商场上名不见经传的捷荣技术(002855.SZ)正扛起“华为概念股”大旗。 9月6日,捷荣技术已拿下第六个连续涨停板,短短七个生意日,股价累积涨幅逾越90%。公司已连发两份股票生意异动公告。 是炒作,还是…...
「解析」YOLOv5 classify分类模板
学习深度学习有些时间了,相信很多小伙伴都已经接触 图像分类、目标检测甚至图像分割(语义分割)等算法了,相信大部分小伙伴都是从分类入门,接触各式各样的 Backbone算法开启自己的炼丹之路。 但是炼丹并非全是 Backbone,更多的是各…...
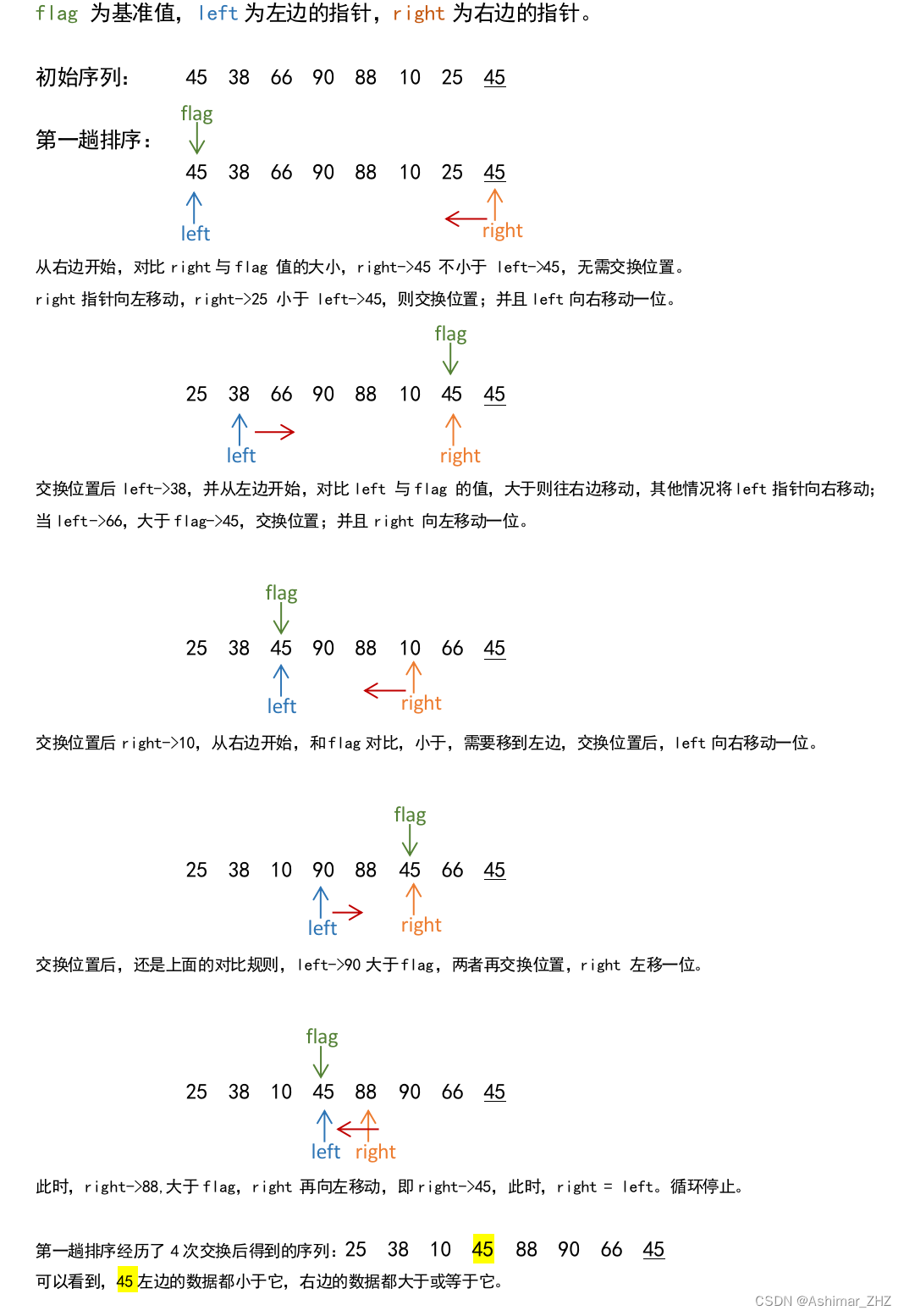
交换排序——冒泡排序、快速排序
交换排序就是通过比较交换实现排序。分冒泡排序和快速排序两种。 一、冒泡排序: 1、简述 顾名思义就是大的就冒头,换位置。 通过多次重复比较、交换相邻记录而实现排序;每一趟的效果都是将当前键值最大的记录换到最后。 冒泡排序算法的原…...

Android 10.0 禁用adb shell input输入功能
1.前言 在10.0的产品开发中,在进行一些定制开发中,对于一些adb shell功能需要通过属性来控制禁止使用input 等输入功能,比如adb shell input keyevent 响应输入事件等,所以就需要 熟悉adb shell input的输入事件流程,然后来禁用adb shell input的输入事件功能,接下来分…...
cuda显存访问耗时
背景: 项目中有个数据量大小为5195 * 512 * 128float 1.268G的显存,发现有个函数调用很耗时,函数里面就是对这个显存进行128个元素求和,得到一个5195 * 512的图像 分析 1. 为什么耗时 直观上感觉这个流程应该不怎么耗时才对&a…...
【HTML5高级第三篇】drag拖拽、音频视频、defer/async属性、dialog应用
文章目录 一、拖拽事件1.1 拖拽事件1.2 案例:拖拽丢弃图片 二、音频和视频三、defer 与 async 属性3.1 概述3.2 示例一:3.3 示例二: 四、dialog 元素 一、拖拽事件 原生JavaScipt案例合集 JavaScript DOM基础 JavaScript 基础到高级 Canvas…...

独享IP vs. 共享IP:哪种更适合你?
无论是个人用户还是企业组织,在互联网上都需要一个唯一标识来与其他设备进行通信。这就涉及到使用独立分配给自己或多个用户分享的公共 IP 地址(也称为共享 IP)。那么,究竟应该选择独占一个专用地址还是与他人分享相同地址呢&…...

【Arduino27】DHT11温湿度传感器模拟值实验
硬件准备 DHT11温湿度:1个 面包板:1个 杜邦线:3根 硬件连线 VDD引脚接 5V 电源 DATE引脚接 4号 接口 GND引脚接 GND 接口 软件程序 #include<DHT.h>#define DHT11_pin 4 //温湿度传感器引脚DHT dht(DHT11_pin,DHT11);float tem…...

技术人的英语能力如何影响薪资?数据说话
打开任何一个招聘平台,搜索“软件测试工程师”,你会发现一个越来越普遍的现象。对于那些薪资范围宽、技术描述详尽、公司名号响亮的岗位,末尾往往会附上一句:“英语可作为工作语言”、“英文读写能力优异”、“CET-6以上优先”。这…...
)
ChatGPT生成的SQL注入漏洞代码竟通过了87%静态扫描器?安全团队紧急避坑指南(含检测脚本)
更多请点击: https://codechina.net 第一章:ChatGPT生成的SQL注入漏洞代码竟通过了87%静态扫描器?安全团队紧急避坑指南(含检测脚本) 近期,某金融企业安全团队在代码审计中发现,一段由ChatGPT生…...

Linux grep 文本过滤与正则实战——日志筛选、文本匹配神器
前言grep 是 Linux 最核心的文本搜索、日志过滤命令,排查报错、筛选日志、过滤配置、批量匹配全部靠它。本文从基础用法到正则实战,全覆盖工作高频场景,看完彻底掌握 grep。一、grep 核心作用从文件/管道流中匹配包含指定关键词的行ÿ…...

2026年腾讯云OpenClaw/Hermes Agent配置Token Plan集成流程详解
2026年腾讯云OpenClaw/Hermes Agent配置Token Plan集成流程详解。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

有哪些一键生成论文工具是真的贴合学术规范,而不是模板套话?
在 AI 写作技术迅猛发展的当下,各类论文工具层出不穷,看似能快速完成写作任务,实则多数只是表面功夫、内容空洞的 "文字搬运工",生成的论文存在逻辑断层、术语错误、格式混乱等明显缺陷,读起来毫无专业感&am…...

SABIC原GE塑料原料全面解析与市场应用
SABIC原GE塑料原料凭借其卓越的性能稳定性与广泛的应用适配性,成为众多制造企业的优选材料。作为国际一线工程塑料品牌,其产品涵盖PETG、PCTGG、PC、PA66等全品类,通过源头直采模式可为下游企业降低15%-18%采购成本,并提供全流程技…...

Polar Sparsity技术:提升LLM推理效率的动态稀疏优化
1. 项目概述:Polar Sparsity技术背景与核心价值 在大型语言模型(LLM)推理任务中,计算效率始终是制约实际部署的关键瓶颈。传统稀疏化方法(如权重剪枝或神经元激活稀疏化)虽然在小批量场景下有效,…...

兜兜转转又回到大浪浪的S05,遥看当年黑丝在,今朝尽染满头霜。
偶然翻看CSDN头像,恍然惊觉已是十五载光阴。2011年拍照于此设头像。初来S05,一路辗转S01,兜兜转转,历经浮沉,如今终究重回最初的S05。这十几年来,方寸代码天地,见证了我的所有成长与蜕变。一路行…...
)
Lovable主题定制深度教程:不改一行PHP代码,实现品牌专属UI/UX升级(仅限当前版本v4.8.3私有补丁包)
更多请点击: https://codechina.net 第一章:Lovable主题定制深度教程:不改一行PHP代码,实现品牌专属UI/UX升级(仅限当前版本v4.8.3私有补丁包) Lovable v4.8.3 通过其增强型 CSS 变量体系与声明式主题注入…...

《QGIS空间数据处理与高级制图》022:融合后拓扑错误预检查
作者:翰墨之道,毕业于国际知名大学空间信息与计算机专业,获硕士学位,现任国内时空智能领域资深专家、CSDN知名技术博主。多年来深耕地理信息与时空智能核心技术研发,精通 QGIS、GrassGIS、OSG、OsgEarth、UE、Cesium、OpenLayers、Leaflet、MapBox 等主流工具与框架,兼具…...