「解析」YOLOv5 classify分类模板
学习深度学习有些时间了,相信很多小伙伴都已经接触 图像分类、目标检测甚至图像分割(语义分割)等算法了,相信大部分小伙伴都是从分类入门,接触各式各样的 Backbone算法开启自己的炼丹之路。
但是炼丹并非全是 Backbone,更多的是各种辅助代码,而这部分公开的并不多,特别是对于刚接触/入门的人来说就更难了,博主当时就苦于没有完善的辅助代码,走了很多弯路,好在YOLOv5提供了分类、目标检测的完整代码,不同于目标检测,因数据集不同,对应的数据辅助代码也不兼容,图像分类就不会有这方面的影响,只需要更换下模型,设置下输出类即可。可谓相当的成熟,学者必备!!!
官方代码:https://github.com/ultralytics/yolov5
分类任务有四部分组成:tutorial说明,train、val、predict 脚本
对于有一定基础的小伙伴可以直接查看 tutorial 自行运行,如果遇到一些暂无解决的问题时再往下阅读!
小插曲
对于调用官方库的模型时,不同数据集对应不同类别数,如果不想修改官方库的话,可以在创建好模型后,再修改最后的类别数
import torchvison.models as modelsmodel = models.__dict__["resnet50"]() # 加载官方模型库,默认是 imagesnet1000类
dataset_class = len(dataset.classes) # 计算训练数据集的类别数num_feature = model.fc.in_features
model.fc = nn.Sequential(nn.Linear(num_feature, dataset_class),nn.LogSofmax(dim=1))model.load_state_dict(torch.load"model_parmas.pt")
train任务
整个 图像分类任务还是较为复杂的,内容略微庞大,一篇讲解不完,讲解不清的可以下方留言,较难问题博主再出新博文解释。
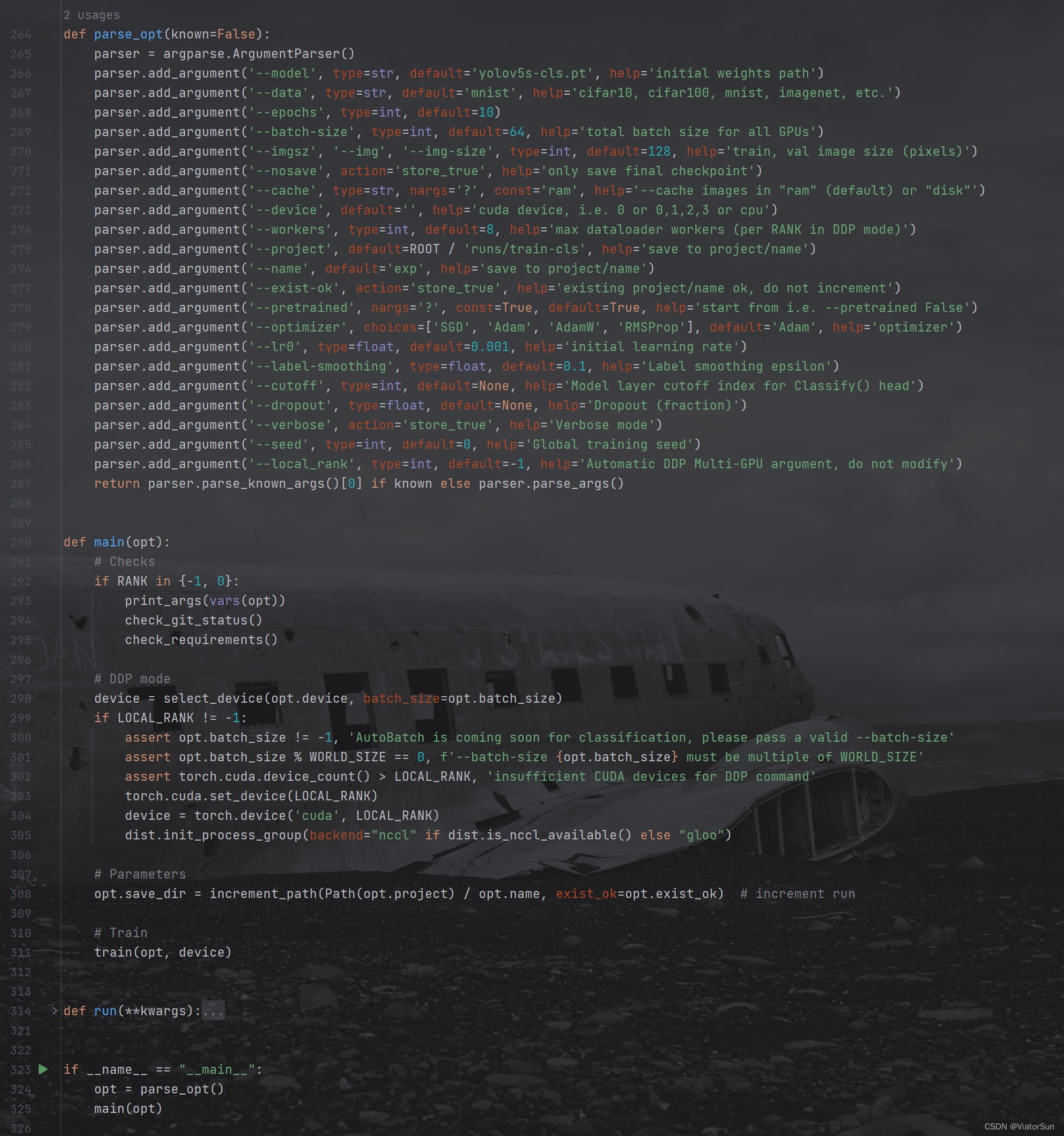
parse_opt() 函数
首先大家在学习代码时,一定要学会 debug 模型,这样才知道代码是如何运行的,一般从 if __name__ == "__main__": 开始进行。
首先是 def parse_opt(known=False): 解析配置参数
-
parser.add_argument('--model', type=str, default='yolov5s-cls.pt', help='initial weights path')
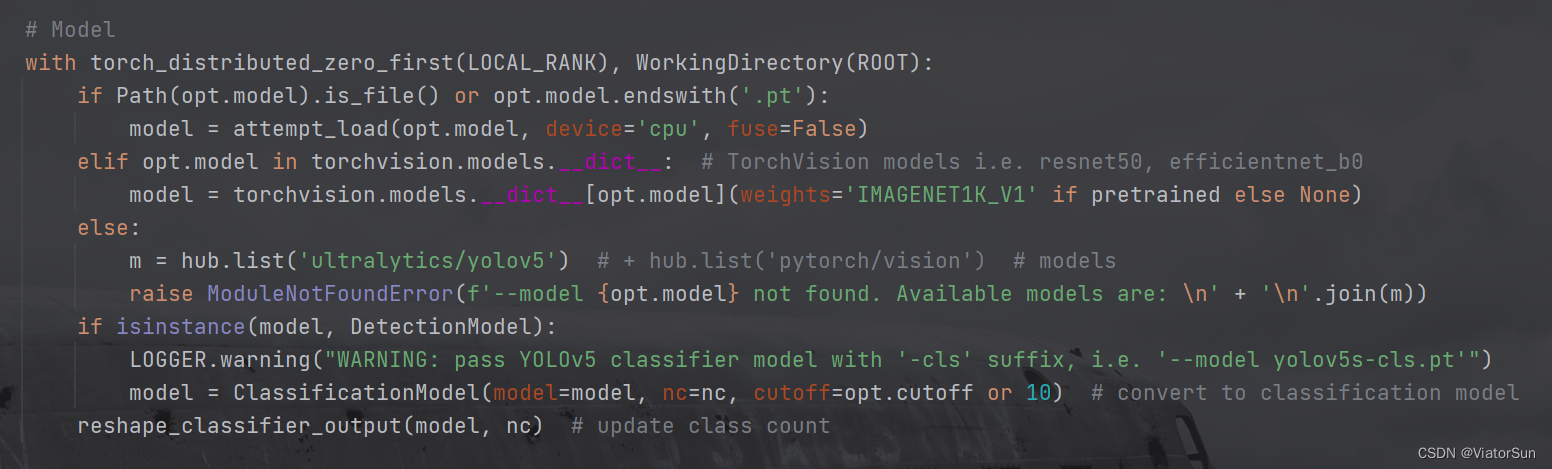
–model 参数是配置模型类型,从下面的解析 --model参数可以看出,如果 --model的值是模型权重名称/路径的话,直接加载到模型model,如果–model是torchvision模型库的,将从torchvision库中读取, 如果都没有的话,将以错误输出。
所以 --model 一定要是 模型权重名称/路径,并且需要能够读取得到才可以。亦可以是torchvision模型库中的模型名称也可以(可以通过torchvision.models.__dict_查看安装的torchvision封装了哪些模型库)
此外torchvision.models.__dict__[opt.model](weights='IMAGENET1K_V1' if pretrained else None)代码并不适用于所有版本的 torchvision模型,还是需要进入 torchvision.model下的具体模型代码中查看 调用方法,否则会出现错误。
-
parser.add_argument('--data', type=str, default='mnist', help='cifar10, cifar100, mnist, imagenet, etc.')
–data 可以是数据集的路径,也可以是数据集而名称, 只是数据集名称必须是 ultralytics 公开的数据集才可以,比如:Classification:Caltech 101、Caltech 256、CIFAR-10、CIFAR-100、Fashion-MNIST、ImageNet、ImageNet-10、Imagenette、Imagewoof、MNIST
如果是自定义的数据集,需要注意的是每一类的所有数据需要放到同一个文件夹下面,如同 cifar10 数据集一样,在 train/val/test 文件夹下分别建立每一类的子文件夹,其中可以存放全部图片,也可以有多层嵌套路径,注意:train/val/test下的文件夹名称和数量 要保持一致,否则训练出来的指标会很差

-
parser.add_argument('--epochs', type=int, default=10)
就是训练的迭代轮数 -
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=128, help='train, val image size (pixels)')
训练时 图片的尺寸大小 -
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
不保存中间每个epoch的权重,如果需要保存的话,将其设置为 False -
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
选择数据的读取方式,ram方式为一次性将所有的数据读取到内存里,以为内存与显存的传输速度高,因此训练市场可以极大降低,前提是内存够大,如果没有足够大的内存的话,可以算法disk硬盘读取,效率略低 -
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
选择训练设备,可以选择:“cup, mps, cuda”(MPS:Apple Metal Performance Shaders) -
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
数据集加载时的线程数 -
parser.add_argument('--project', default=ROOT / 'runs/train-cls', help='save to project/name')
项目保存路径及名称 -
parser.add_argument('--name', default='exp', help='save to project/name')
每次训练的子文件名 -
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
如果已经存在保存文件名/路径,可以覆盖保存 -
parser.add_argument('--pretrained', nargs='?', const=True, default=True, help='start from i.e. --pretrained False')
是否使用预训练权重(前提是必须是torchvision中的模型,官方提供预训练接口的模型才有用) -
parser.add_argument('--optimizer', choices=['SGD', 'Adam', 'AdamW', 'RMSProp'], default='Adam', help='optimizer')
优化器选择,此处官方配置好了 [‘SGD’, ‘Adam’, ‘AdamW’, ‘RMSProp’] 优化器,如果需要其他优化器,需用小伙伴自行配置 -
parser.add_argument('--lr0', type=float, default=0.001, help='initial learning rate')
优化器的初始学习率 -
parser.add_argument('--label-smoothing', type=float, default=0.1, help='Label smoothing epsilon')
label-smoothing 方法,对 label进行 smoothing 处理 -
parser.add_argument('--cutoff', type=int, default=None, help='Model layer cutoff index for Classify() head')
裁切模型的 classify分支 的层数,model.model = model.model[:cutoff] -
parser.add_argument('--dropout', type=float, default=None, help='Dropout (fraction)')
随机失效部分神经元,dropout处理 -
parser.add_argument('--verbose', action='store_true', help='Verbose mode')
冗余模式,记录中间的模型日志 -
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
全局随机种子 -
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
如果小伙伴有多卡,可以采用,此方法可以自动调用多个显卡的资源,即DDP 模式,-1 为不采用
train() 函数
train() 函数前面都是一些模型配置
- 模型训练保存路径,以及配置训练日志,默认情况下,模型训练保存 一个 last.pt 和 best.pt

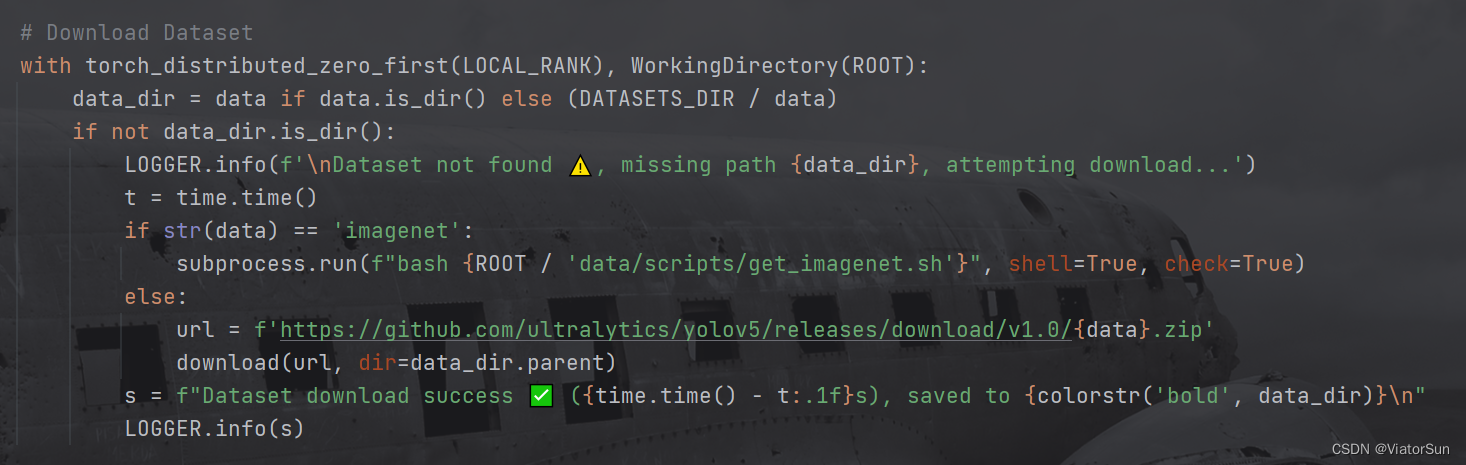
- 数据集下载,如果是官方的数据集,直接 对
--data设置数据集名称即可(完成路径也是可以的),如果是自己的数据集,需要设置数据集路径,只需要给到 train 的上一级目录即可
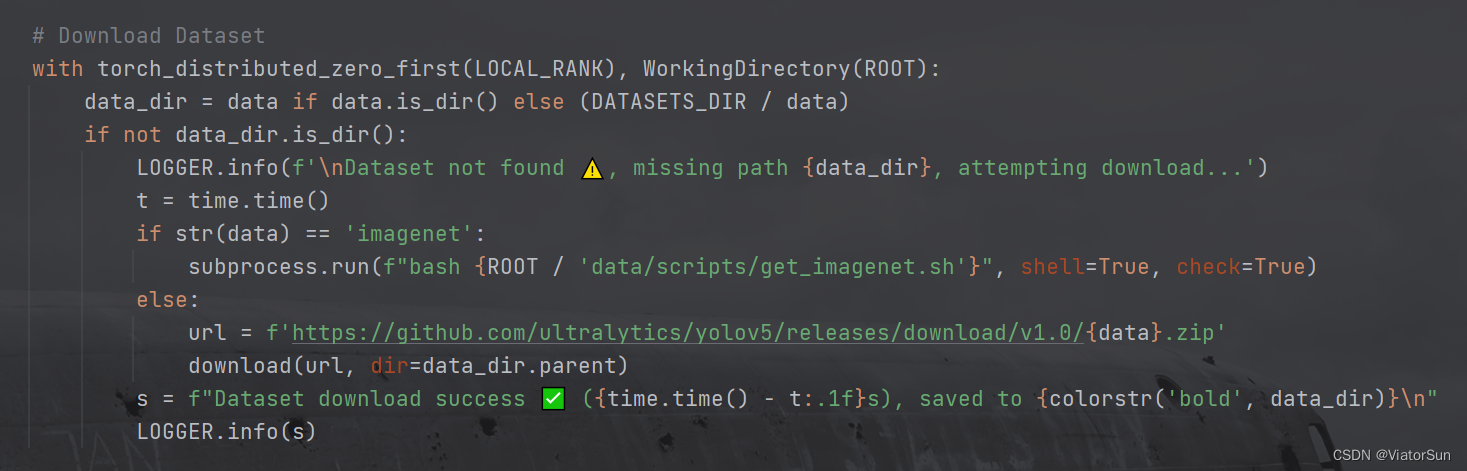
- 数据集构建,此处将读取数据集的类别数以及加载数据集,此处默认是以 test 为验证集的,如果没有test 备份选择 val。如果需要用 val 当验证集,手动改为 val即可。再次提示:train 下的文件夹名称和数量需要和 验证集下的保持一致,否则模型性能很低,且无法提升(惨痛的教训!)
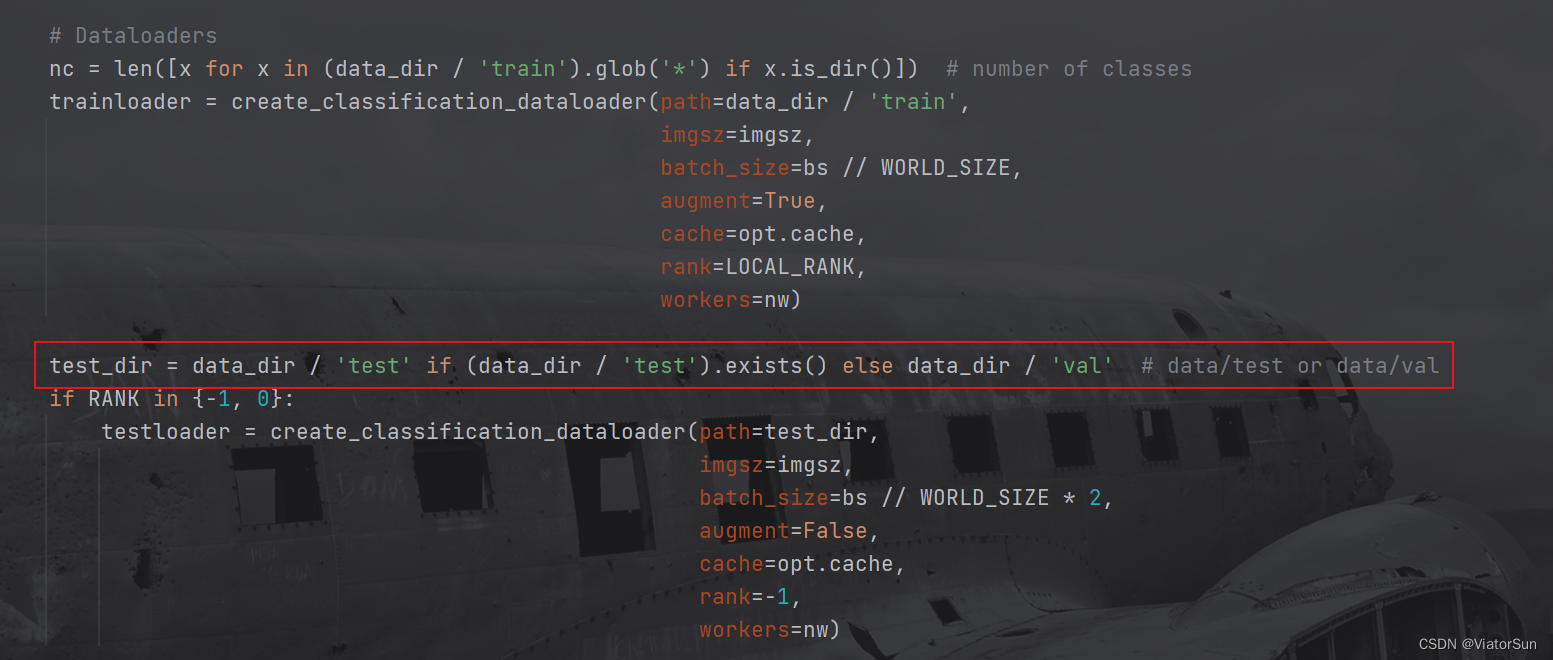
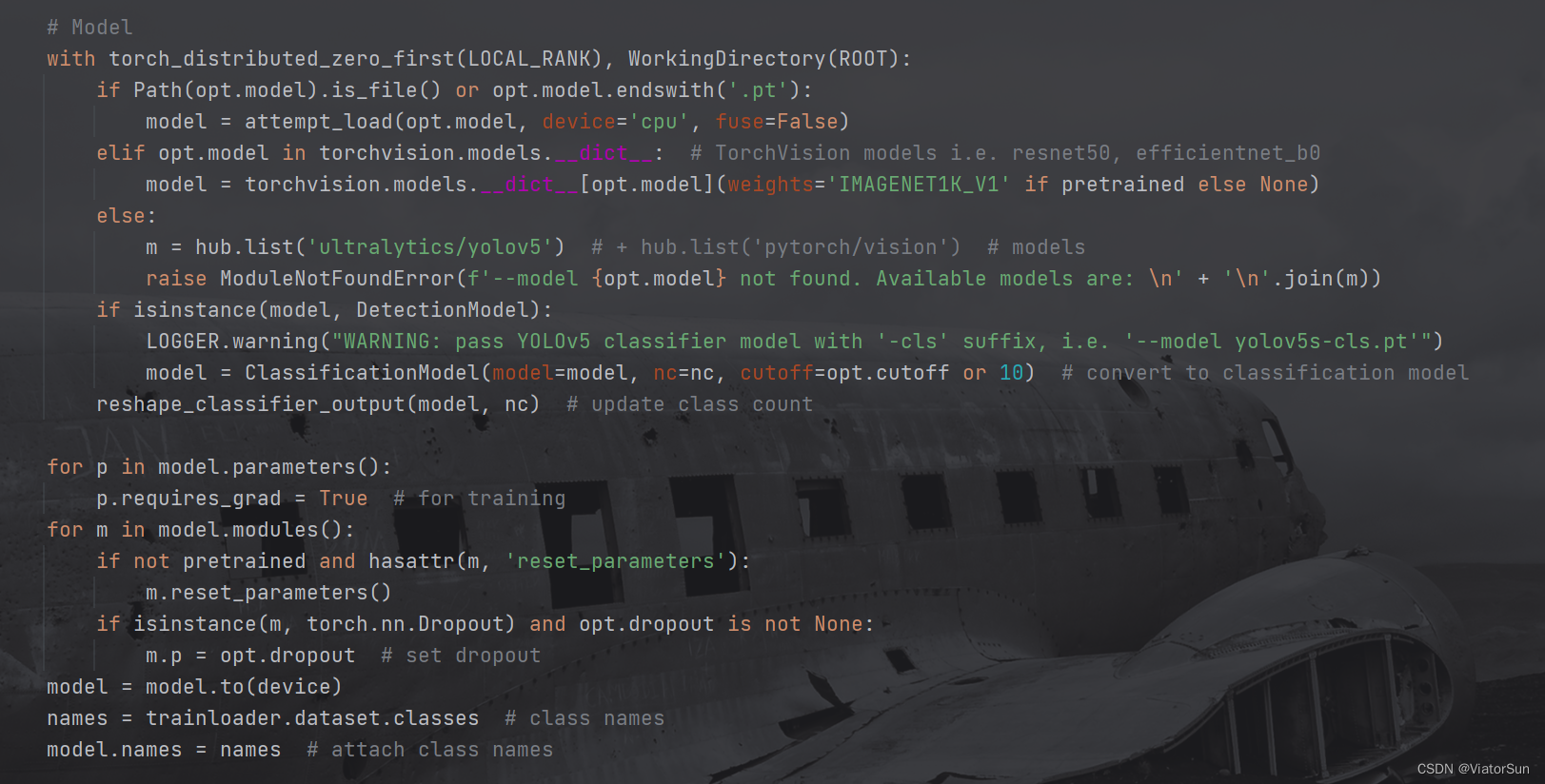
- 构建模型,此处需要注意一点,作为分类模型,模型的输出层必须和数据集的类别数量保持一致,必须!!!
如果不使用 torchvision中的模型,只需要将 model 赋值为自己的模型即可
- 日志保存模型等信息,以及加载 数据和标签,此处的数据加载器采用的是迭代器方式,因此采用 nest(iter());然后是优化器设置,学习率、调度器(scheduler)设置 和 EMA配置;最后是损失函数criterion。
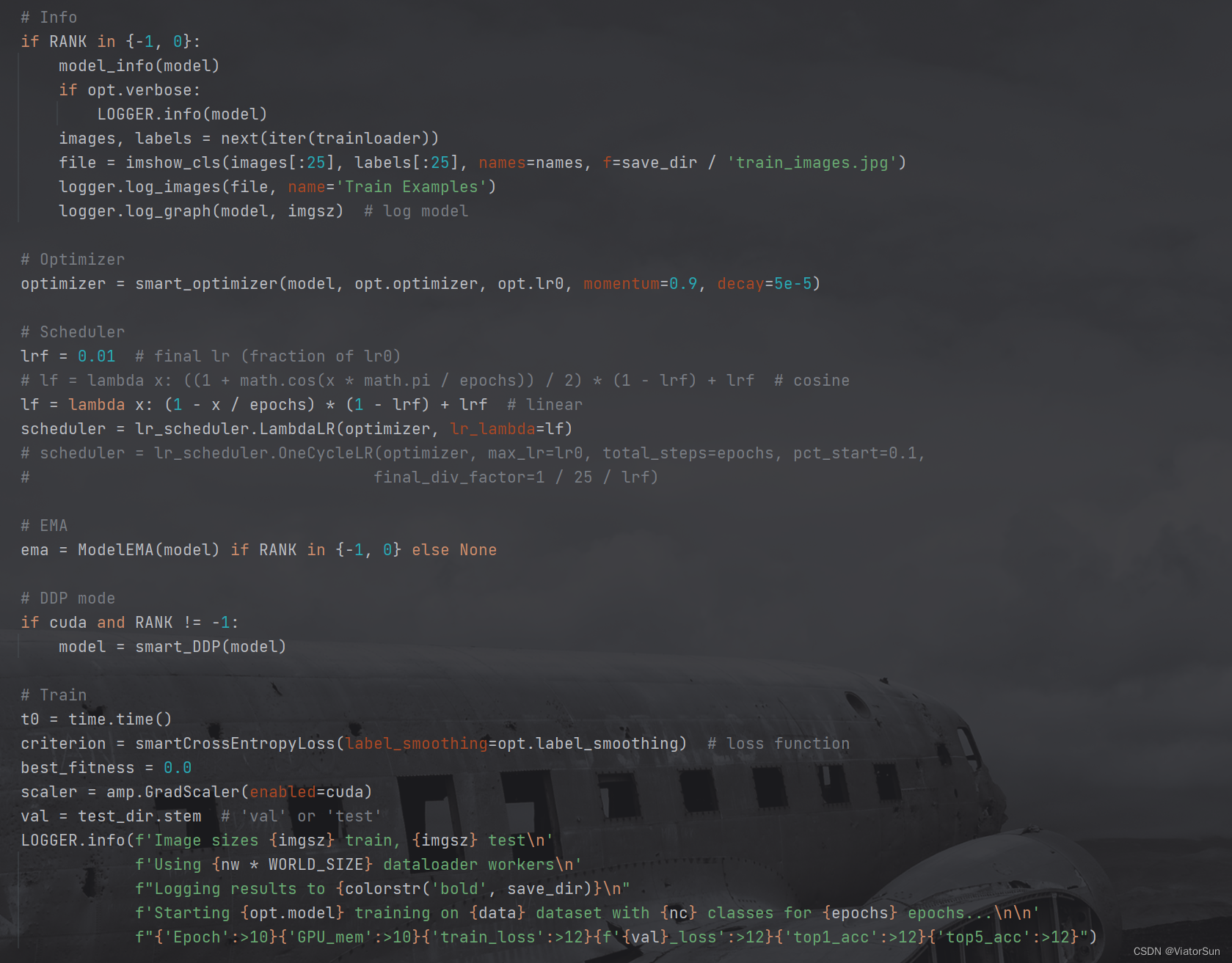
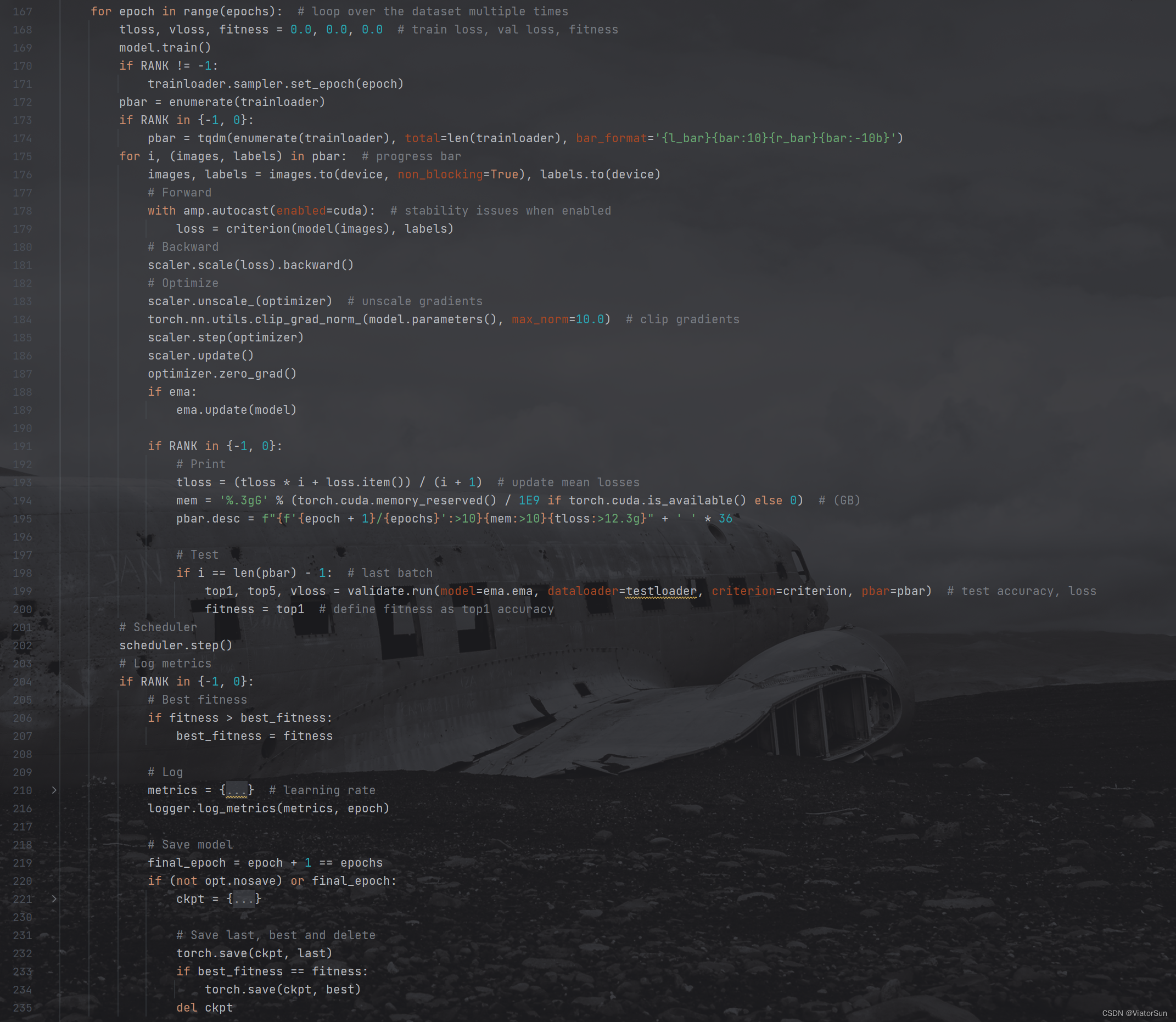
- 进行完上面所有的参数配置,真正的模型训练还在下面这个循环里
相关文章:
「解析」YOLOv5 classify分类模板
学习深度学习有些时间了,相信很多小伙伴都已经接触 图像分类、目标检测甚至图像分割(语义分割)等算法了,相信大部分小伙伴都是从分类入门,接触各式各样的 Backbone算法开启自己的炼丹之路。 但是炼丹并非全是 Backbone,更多的是各…...
交换排序——冒泡排序、快速排序
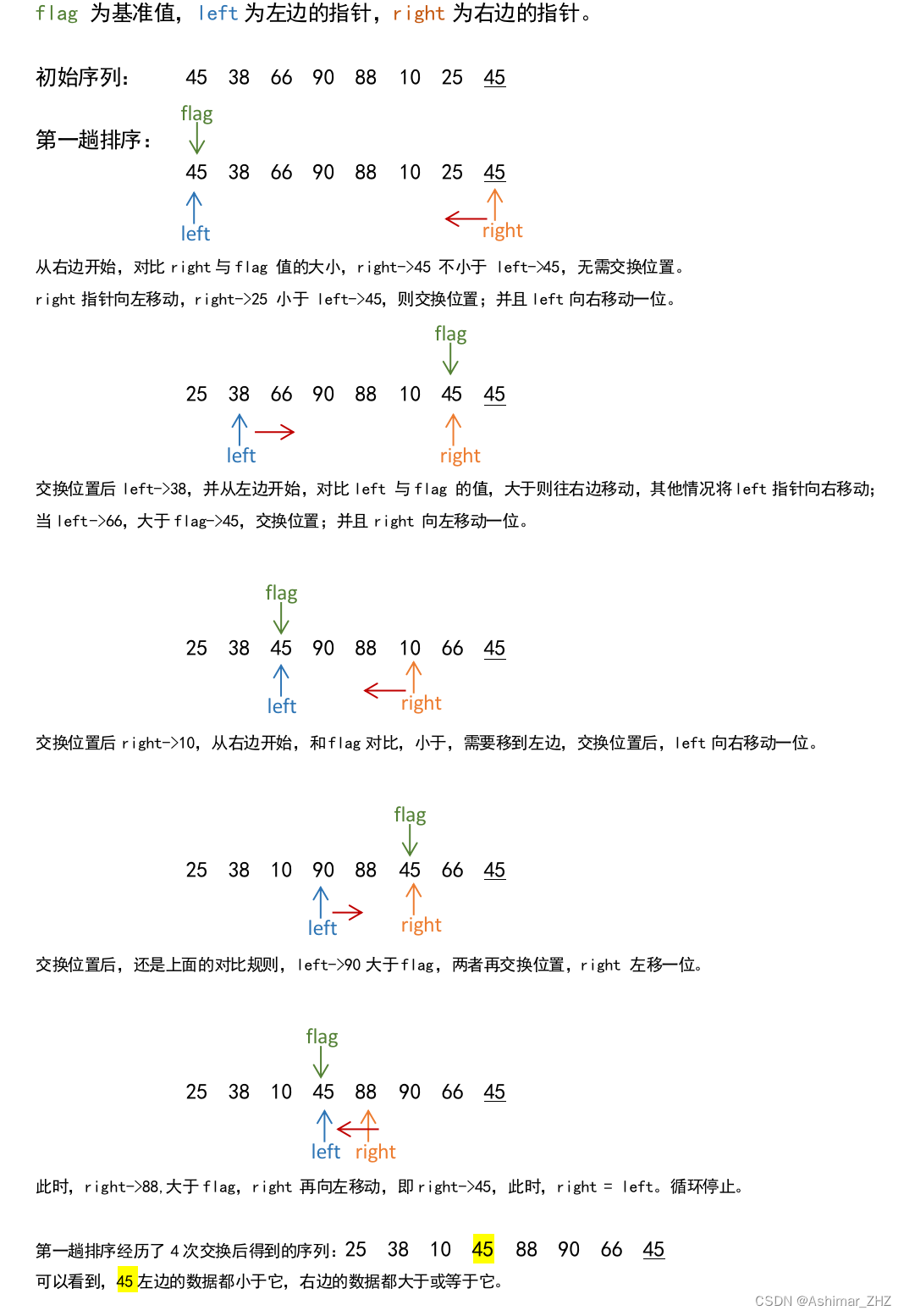
交换排序就是通过比较交换实现排序。分冒泡排序和快速排序两种。 一、冒泡排序: 1、简述 顾名思义就是大的就冒头,换位置。 通过多次重复比较、交换相邻记录而实现排序;每一趟的效果都是将当前键值最大的记录换到最后。 冒泡排序算法的原…...

Android 10.0 禁用adb shell input输入功能
1.前言 在10.0的产品开发中,在进行一些定制开发中,对于一些adb shell功能需要通过属性来控制禁止使用input 等输入功能,比如adb shell input keyevent 响应输入事件等,所以就需要 熟悉adb shell input的输入事件流程,然后来禁用adb shell input的输入事件功能,接下来分…...
cuda显存访问耗时
背景: 项目中有个数据量大小为5195 * 512 * 128float 1.268G的显存,发现有个函数调用很耗时,函数里面就是对这个显存进行128个元素求和,得到一个5195 * 512的图像 分析 1. 为什么耗时 直观上感觉这个流程应该不怎么耗时才对&a…...
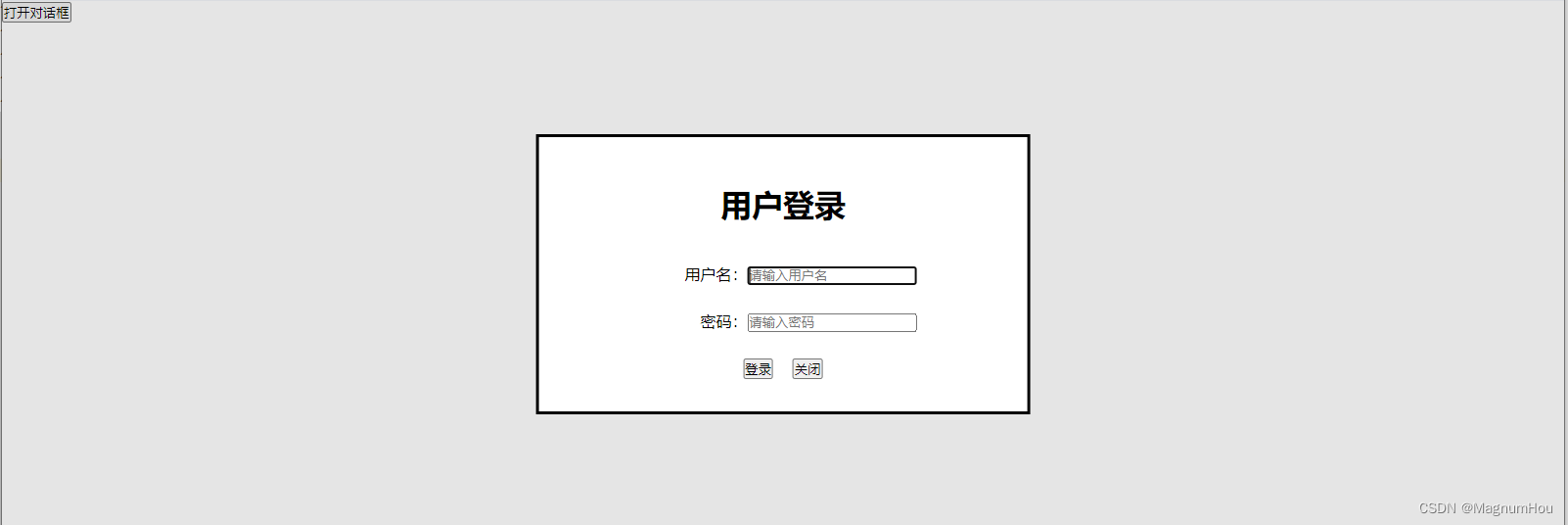
【HTML5高级第三篇】drag拖拽、音频视频、defer/async属性、dialog应用
文章目录 一、拖拽事件1.1 拖拽事件1.2 案例:拖拽丢弃图片 二、音频和视频三、defer 与 async 属性3.1 概述3.2 示例一:3.3 示例二: 四、dialog 元素 一、拖拽事件 原生JavaScipt案例合集 JavaScript DOM基础 JavaScript 基础到高级 Canvas…...

独享IP vs. 共享IP:哪种更适合你?
无论是个人用户还是企业组织,在互联网上都需要一个唯一标识来与其他设备进行通信。这就涉及到使用独立分配给自己或多个用户分享的公共 IP 地址(也称为共享 IP)。那么,究竟应该选择独占一个专用地址还是与他人分享相同地址呢&…...

【Arduino27】DHT11温湿度传感器模拟值实验
硬件准备 DHT11温湿度:1个 面包板:1个 杜邦线:3根 硬件连线 VDD引脚接 5V 电源 DATE引脚接 4号 接口 GND引脚接 GND 接口 软件程序 #include<DHT.h>#define DHT11_pin 4 //温湿度传感器引脚DHT dht(DHT11_pin,DHT11);float tem…...

dockerfile基于apline将JDK20打包成镜像
dockerfile基于apline将JDK20打包成镜像 今天就来和大家聊聊如何把最新出版的JDK20打包成docker镜像,很多uu都会采用centos作为基础镜像,这么做会有一个问题,centos系统会含有很多库文件,这些库文件JDK程序并不是完全需要的&a…...

MATLAB基础-MAT文件的读写操作
简介 MAT文件是MATLAB格式的双精度二进制数据文件,由MATLAB软件创建,可以使用MATLAB软件再其他计算机上以其他浮点格式读取,同时也可以使用其他软件通过MATLAB的应用程序接口来进行读写操作。如果只是再MATLAB环境中处理数据,使用…...

PostgreSQL PG15 新功能 PG_WALINSPECT
开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis ,Oracle ,Oceanbase 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请加微信号 liuaustin3 (…...

时序预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络时间序列预测
时序预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络时间序列预测 目录 时序预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神…...

数据结构和算法(2):向量
抽象数据类型 数组到向量 C/C 中,数组A[]中的元素与[0,n)内的编号一一对应,A[0],A[1],...,A[n-1];反之,每个元素均由(非负)编号唯一指代,并可直接访问A[i] 的物理地址 Ai s,s 为单…...

mysql 大表如何ddl
大家好,我是蓝胖子,mysql对大表(千万级数据)的ddl语句,在生产上执行时一定要千万小心,一不小心就有可能造成业务阻塞,数据库io和cpu飙高的情况。今天我们就来看看如何针对大表执行ddl语句。 通过这篇文章,…...
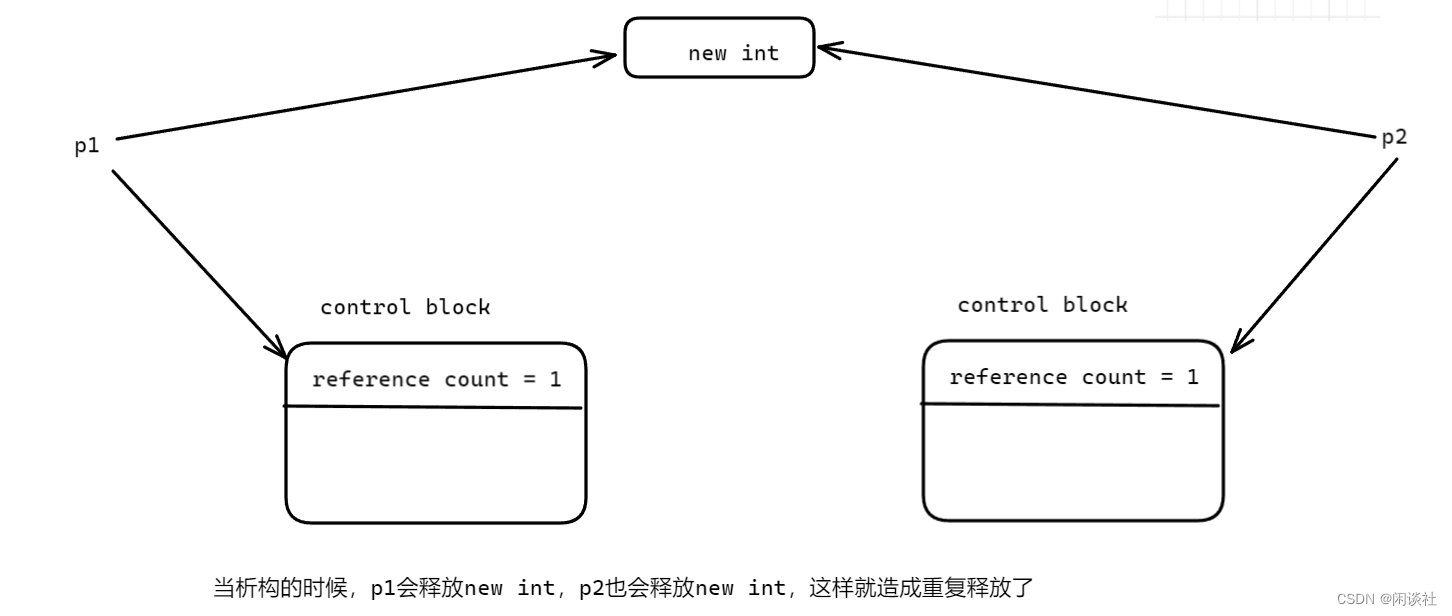
C++新特性:智能指针
一 、为什么需要智能指针 智能指针主要解决以下问题: 1)内存泄漏:内存手动释放,使用智能指针可以自动释放 2)共享所有权指针的传播和释放,比如多线程使用同一个对象时析构问题,例如同样的数据…...
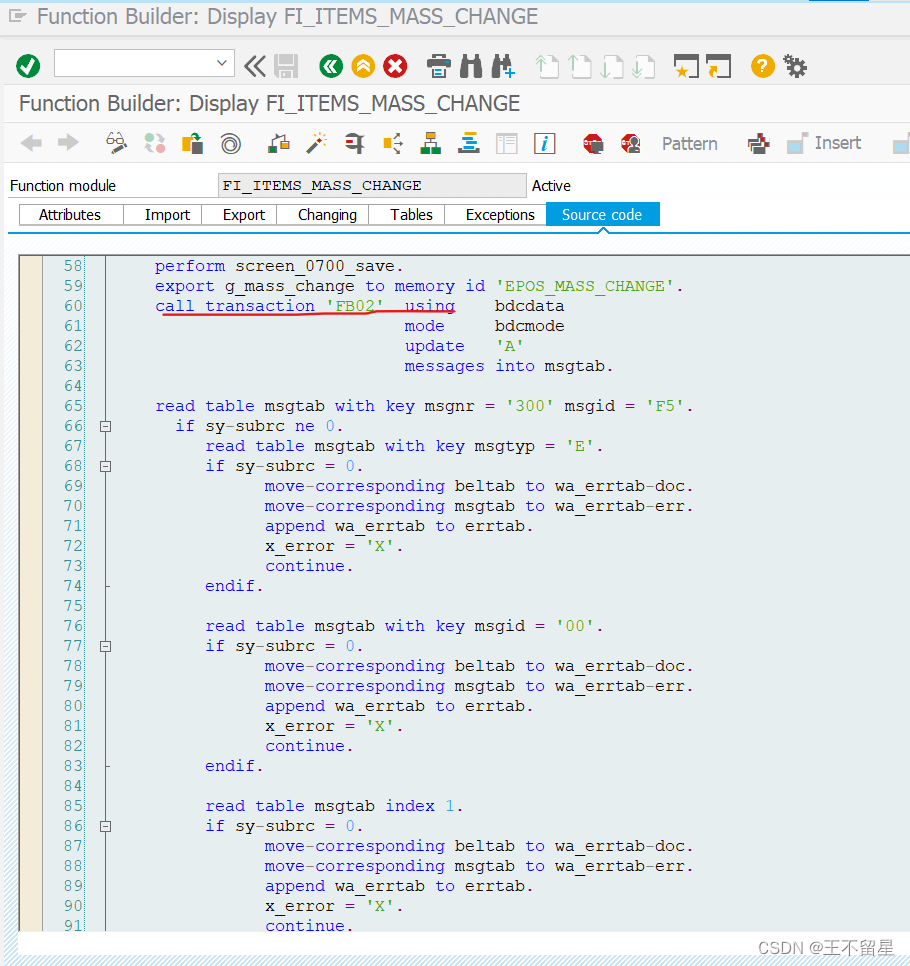
SAP FI之批量修改财务凭证的BAPI
文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结 前言 一般涉及修改财务凭证,或者其它凭证,不应直接更新数据库,而是使用系统提供的function module,或者BAPI,或者使用BDC。 一、 示例…...

Spring Boot + Vue的网上商城之商品分类
Spring Boot Vue的网上商城之商品分类 在网上商城中,商品分类是非常重要的一个功能,它可以帮助用户更方便地浏览和筛选商品。本文将介绍如何使用Spring Boot和Vue来实现商品分类的功能,包括一级分类和二级分类的管理以及前台按分类浏览商品…...

Docker 容器逃逸漏洞 (CVE-2020-15257)复现
漏洞概述 containerd是行业标准的容器运行时,可作为Linux和Windows的守护程序使用。在版本1.3.9和1.4.3之前的容器中,容器填充的API不正确地暴露给主机网络容器。填充程序的API套接字的访问控制验证了连接过程的有效UID为0,但没有以其他方式…...
Python 如何使用 csv、openpyxl 库进行读写 Excel 文件详细教程(更新中)
csv 基本概述 首先介绍下 csv (comma separated values),即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符。 程序在处理数据时…...

$nextTick属性使用与介绍
属性介绍 $nextTick 是 Vue.js 中的一个重要方法,之前我们也说过$ref 等一些重要的属性,这次我们说$nextTick,$nextTick用于在 DOM 更新后执行回调函数。它通常用于处理 DOM 更新后的操作,因为 Vue 在更新 DOM 后不会立即触发回调…...

【群智能算法改进】一种改进的鹈鹕优化算法 IPOA算法[2]【Matlab代码#58】
文章目录 【获取资源请见文章第5节:资源获取】1. 原始POA算法2. 改进后的IPOA算法2.1 随机对立学习种群初始化2.2 动态权重系数2.3 透镜成像折射方向学习 3. 部分代码展示4. 仿真结果展示5. 资源获取 【获取资源请见文章第5节:资源获取】 1. 原始POA算法…...

从B73到5000个RILs:手把手拆解玉米NAM群体构建的完整流程与关键决策
玉米NAM群体构建全流程解析:从亲本筛选到RILs优化的科学决策 站在玉米遗传研究的十字路口,我们常常面临一个核心挑战:如何在有限资源下构建既能捕获广泛遗传多样性,又能实现精准定位的群体?2009年,Buckler团…...

原神祈愿数据分析终极方案:genshin-wish-export架构革命与效能倍增
原神祈愿数据分析终极方案:genshin-wish-export架构革命与效能倍增 【免费下载链接】genshin-wish-export Easily export the Genshin Impact wish record. 项目地址: https://gitcode.com/GitHub_Trending/ge/genshin-wish-export 你是否曾在多设备间苦苦同…...

电子书转有声书完整指南:一键实现1158种语言的AI语音合成
电子书转有声书完整指南:一键实现1158种语言的AI语音合成 【免费下载链接】ebook2audiobook Generate audiobooks from e-books, voice cloning & 1158 languages! 项目地址: https://gitcode.com/GitHub_Trending/eb/ebook2audiobook 你是否曾希望将心爱…...

GitHub资源精准下载:3分钟掌握DownGit的完整使用指南
GitHub资源精准下载:3分钟掌握DownGit的完整使用指南 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 还在为下载GitHub上单个文件而烦恼吗?DownGit是你的终极解决方案!这个…...

ARM SVE向量化技术解析与性能优化实践
1. ARM SVE向量化技术解析 1.1 SVE架构设计理念 ARM可扩展向量扩展(Scalable Vector Extension, SVE)是ARMv8-A和ARMv9-A架构引入的长向量指令集,其核心创新在于向量长度无关(Vector Length Agnostic, VLA)的设计哲学。与传统固定长度的SIMD指令(如x86的…...

7 年评测经验博主发布扫地机器人挑选指南,邀你探讨机器人革命!
评测多款扫地机器人,Matic 脱颖而出博主发布了关于挑选最佳扫地机器人的指南,近期评测了戴森的 Spot & Scrub、鲨客的 Power Detect 以及 Matic。在其 7 年的扫地机器人评测生涯中,Matic 是最有意思的新型扫地机器人。拨开营销迷雾&#…...

AI工程师必备:可验证、可执行、可落地的AI资讯简报
1. 这是一份真正“能用”的AI资讯简报,不是信息噪音收集器 “ This AI newsletter is all you need #40 ”——看到这个标题,你大概率会下意识划走:又一个AI资讯邮件?每天几十封,点开三秒就关掉,标题党、…...
)
用随机森林实现手写英文字母识别(Python实战)
1. 项目概述:用随机森林搞定手写信件识别,这事儿比你想象中更接地气 “How To Perform Letter Recognition in Python Using Random Forest Classifier”——这个标题乍看像教科书里的章节名,但实际拆开来看,它直指一个非常具体、…...
)
今日算法(二叉搜索树)
题目描述给定一棵二叉搜索树(BST)的根节点 root,树中节点值各不相同。要求将其转换为累加树(Greater Sum Tree),规则如下:每个节点的新值 原节点值 所有比它大的节点值的总和二叉搜索树的性质…...

深度实战:如何利用7zip引擎实现加密压缩包密码暴力破解
深度实战:如何利用7zip引擎实现加密压缩包密码暴力破解 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 在数字资产管理中&#…...