读书笔记-《ON JAVA 中文版》-摘要24[第二十一章 数组]
文章目录
- 第二十一章 数组
- 1. 数组特性
- 2. 一等对象
- 3. 返回数组
- 4. 多维数组
- 5. 泛型数组
- 6. Arrays的fill方法
- 7. Arrays的setAll方法
- 8. 数组并行
- 9. Arrays工具类
- 10. 数组拷贝
- 11. 数组比较
- 12. 流和数组
- 13. 数组排序
- 14. binarySearch二分查找
- 15. 本章小结
第二十一章 数组
1. 数组特性
将数组和其他类型的集合区分开来的原因有三:效率,类型,保存基本数据类型的能力。在 Java 中,使用数组存储和随机访问对象引用序列是非常高效的。数组是简单的线性序列,这使得对元素的访问变得非常快。然而这种高速也是有代价的,代价就是数组对象的大小是固定的,且在该数组的生存期内不能更改。
Java 提供了 Arrays.toString() 来将数组转换为可读字符串,然后可以在控制台上显示。
2. 一等对象
数组是保存指向其他对象的引用的对象,数组可以隐式地创建,也可以显式地创建,比如使用一个 new 表达式。数组对象的一部分(事实上,你唯一可以使用的方法)就是只读的 length 成员函数,它能告诉你数组对象中可以存储多少元素。[ ] 语法是你访问数组对象的唯一方式。
对象数组存储的是对象的引用,而基元数组则直接存储基本数据类型的值。
package arrays;import java.util.Arrays;class BerylliumSphere {private static long counter;private final long id = counter++;@Overridepublic String toString() {return "Sphere " + id;}
}public class ArrayOptions {static <T> void show(String info, T[] array) {System.out.println(info + ":" + Arrays.toString(array));}public static void main(String[] args) {BerylliumSphere[] a;// 数组 a 是一个未初始化的本地变量,编译器不会允许你使用这个引用直到你正确地对其进行初始化。
// show("a",a);BerylliumSphere[] b = new BerylliumSphere[5];// 数组 b 被初始化,自动初始化为 null// 数值类型初始化为 0,char 型初始化为 (char)0,// 布尔类型初始化为 false。show("b", b);// 数组 c 展示了创建数组对象后给数组中各元素分配 BerylliumSphere 对象。BerylliumSphere[] c = new BerylliumSphere[4];for (int i = 0; i < c.length; i++) {if (c[i] == null) {c[i] = new BerylliumSphere();}}// 数组 d 展示了创建数组对象的聚合初始化语法(隐式地使用 new 在堆中创建对象)BerylliumSphere[] d = {new BerylliumSphere(),new BerylliumSphere(),new BerylliumSphere()};// 动态聚合初始化a = new BerylliumSphere[]{new BerylliumSphere(), new BerylliumSphere(),};System.out.println("a.length = " + a.length);System.out.println("b.length = " + b.length);System.out.println("c.length = " + c.length);System.out.println("d.length = " + d.length);a = d;System.out.println("a.length = " + a.length);int[] e;int[] f = new int[5];System.out.println("f" + ":" + Arrays.toString(f));int[] g = new int[4];for (int i = 0; i < g.length; i++)g[i] = i * i;int[] h = {11, 47, 93};System.out.println("f.length = " + f.length);System.out.println("g.length = " + g.length);System.out.println("h.length = " + h.length);e = h;System.out.println("h-修改前:" + Arrays.toString(h));System.out.println("e-修改前:" + Arrays.toString(e));h[1] = 33;System.out.println("h-修改后:" + Arrays.toString(h));System.out.println("e-修改后:" + Arrays.toString(e));System.out.println("e.length = " + e.length);e = new int[]{1, 2};System.out.println("e.length = " + e.length);}
}
输出:
b:[null, null, null, null, null]
a.length = 2
b.length = 5
c.length = 4
d.length = 3
a.length = 3
f:[0, 0, 0, 0, 0]
f.length = 5
g.length = 4
h.length = 3
h-修改前:[11, 47, 93]
e-修改前:[11, 47, 93]
h-修改后:[11, 33, 93]
e-修改后:[11, 33, 93]
e.length = 3
e.length = 2
3. 返回数组
而在 Java 中,你只需返回数组,你永远不用为数组担心,只要你需要它,它就可用,垃圾收集器会在你用完后把它清理干净。
4. 多维数组
要创建多维的基元数组,你要用大括号来界定数组中的向量:
package arrays;import java.util.Arrays;public class MultidimensionalPrimitiveArray {public static void main(String[] args) {int[][] a = {// 每个嵌套的大括号都代表了数组的一个维度{ 1, 2, 3, },{ 4, 5, 6, },};System.out.println(Arrays.deepToString(a));}
}
可以使用 new 分配数组。这是一个使用 new 表达式分配的三维数组:
package arrays;import java.util.Arrays;public class ThreeDWithNew {public static void main(String[] args) {int[][][] a = new int[2][2][4];System.out.println(Arrays.deepToString(a));}
}
输出:
[[[0, 0, 0, 0], [0, 0, 0, 0]], [[0, 0, 0, 0], [0, 0, 0, 0]]]
5. 泛型数组
一般来说,数组和泛型并不能很好的结合。你不能实例化参数化类型的数组:
Peel<Banana>[] peels = new Peel<Banana>[10]; // Illegal
类型擦除需要删除参数类型信息,而且数组必须知道它们所保存的确切类型,以强制保证类型安全。
但是,可以参数化数组本身的类型:
package arrays;class ClassParameter<T> {public T[] f(T[] arg) {return arg;}
}class MethodParameter {public static <T> T[] f(T[] arg) {return arg;}
}public class ParameterizedArrayType {public static void main(String[] args) {Integer[] ints = {1, 2, 3, 4, 5};Double[] doubles = {1.1, 2.2, 3.3, 4.4, 5.5};Integer[] ints2 =new ClassParameter<Integer>().f(ints);Double[] doubles2 =new ClassParameter<Double>().f(doubles);ints2 = MethodParameter.f(ints);doubles2 = MethodParameter.f(doubles);}
}
比起使用参数化类,使用参数化方法很方便。
6. Arrays的fill方法
Java 标准库 Arrays 类包括一个普通的 fill() 方法,该方法将单个值复制到整个数组,或者在对象数组的情况下,将相同的引用复制到整个数组:
package arrays;import java.util.Arrays;public class FillingArrays {static <T> void show(String info, T[] array) {System.out.println(info + ":" + Arrays.toString(array));}public static void main(String[] args) {int size = 6;String[] a1 = new String[size];Arrays.fill(a1, "Hello");show("a1", a1);Arrays.fill(a1,1,3,"World");show("a1", a1);}
}
输出:
a1:[Hello, Hello, Hello, Hello, Hello, Hello]
a1:[Hello, World, World, Hello, Hello, Hello]
7. Arrays的setAll方法
它的作用是根据给定的数组索引,使用指定的lambda表达式或方法引用来设置数组的值。
package arrays;import java.util.Arrays;public class SimpleSetAll {public static final int SZ = 8;static int val = 1;public static void main(String[] args) {int[] ia = new int[SZ];Arrays.setAll(ia, n -> n);System.out.println(Arrays.toString(ia));Arrays.setAll(ia, n -> val++);System.out.println(Arrays.toString(ia));}
}
输出:
[0, 1, 2, 3, 4, 5, 6, 7]
[1, 2, 3, 4, 5, 6, 7, 8]
8. 数组并行
Arrays.parallelSetAll()
效果与 SetAll() 一样,可并行
9. Arrays工具类
该类包含许多有用的 静态 程序方法:
-
asList(): 获取任何序列或数组,并将其转换为一个 列表集合 。
-
copyOf():以新的长度创建现有数组的新副本。
-
copyOfRange():创建现有数组的一部分的新副本。
-
equals():比较两个数组是否相等。
-
deepEquals():多维数组的相等性比较。
-
stream():生成数组元素的流。
-
hashCode():生成数组的哈希值。
-
deepHashCode(): 多维数组的哈希值。
-
sort():排序数组
-
parallelSort():对数组进行并行排序,以提高速度。
-
binarySearch():在已排序的数组中查找元素。
-
parallelPrefix():使用提供的函数并行累积(以获得速度)。基本上,就是数组的reduce()。
-
spliterator():从数组中产生一个Spliterator;这是本书没有涉及到的流的高级部分。
-
toString():为数组生成一个字符串表示。你在整个章节中经常看到这种用法。
-
deepToString():为多维数组生成一个字符串。
10. 数组拷贝
与使用for循环手工执行复制相比,copyOf() 和 copyOfRange() 复制数组要快得多。这些方法被重载以处理所有类型。
工具类:
package arrays;import java.util.Arrays;
import java.util.function.Supplier;public interface Count {class Integerimplements Supplier<java.lang.Integer> {int i;@Overridepublic java.lang.Integer get() {return i++;}public java.lang.Integer get(int n) {return get();}public java.lang.Integer[] array(int sz) {java.lang.Integer[] result =new java.lang.Integer[sz];Arrays.setAll(result, n -> get());return result;}}
}
测试类:
package arrays;import java.util.Arrays;class Sup {// Superclassprivate int id;Sup(int n) {id = n;}@Overridepublic String toString() {return getClass().getSimpleName() + id;}
}class Sub extends Sup { // SubclassSub(int n) {super(n);}
}public class ArrayCopying {public static final int SZ = 10;static <T> void show(String info, T[] array) {System.out.println(info + ":" + Arrays.toString(array));}public static void main(String[] args) {Integer[] a1 = new Integer[SZ];Arrays.setAll(a1, new Count.Integer()::get);show("a1", a1);// 最基本的数组复制Integer[] a2 = Arrays.copyOf(a1, a1.length);// 把a1的所有元素都设为1,以证明a1的变化不会影响a2Arrays.fill(a1,1);show("a1", a1);show("a2", a2);a2 = Arrays.copyOf(a2, 8);show("a2", a2);// copyOfRange() 需要一个开始和结束索引Integer[] a3 = Arrays.copyOfRange(a2, 2, 5);show("a3", a3);}
}
输出:
a1:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a1:[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
a2:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a2:[0, 1, 2, 3, 4, 5, 6, 7]
a3:[2, 3, 4]
11. 数组比较
数组 提供了 equals() 来比较一维数组,以及 deepEquals() 来比较多维数组。对于所有原生类型和对象,这些方法都是重载的。
数组相等的含义:数组必须有相同数量的元素,并且每个元素必须与另一个数组中的对应元素相等,对每个元素使用 equals()。
package arrays;import java.util.Arrays;public class ComparingArrays {public static final int SZ = 5;public static void main(String[] args) {int[] a1 = new int[SZ], a2 = new int[SZ];Arrays.setAll(a1, new Count.Integer()::get);Arrays.setAll(a2, new Count.Integer()::get);System.out.println("a1 == a2: " + Arrays.equals(a1, a2));a2[3] = 11;System.out.println("a1 == a2: " + Arrays.equals(a1, a2));}
}
输出:
a1 == a2: true
a1 == a2: false
12. 流和数组
stream() 方法很容易从某些类型的数组中生成元素流。
package arrays;import java.util.Arrays;public class StreamFromArray {public static void main(String[] args) {String[] s = {"abc", "dcd", "erb", "kkl", "232", "dfg", "abc"};Arrays.stream(s).skip(2).limit(4).map(n -> n + "!").forEach(System.out::println);}
}
输出:
erb!
kkl!
232!
dfg!
13. 数组排序
Java有两种方式提供比较功能。第一种方法是通过实现 java.lang.Comparable 接口的原生方法。这是一个简单的接口,只含有一个方法 compareTo()。该方法接受另一个与参数类型相同的对象作为参数,如果当前对象小于参数,则产生一个负值;如果参数相等,则产生零值;如果当前对象大于参数,则产生一个正值。
package arrays;import java.util.Arrays;
import java.util.SplittableRandom;public class CompType implements Comparable<CompType> {private static int count = 1;private static SplittableRandom r = new SplittableRandom(47);int i;int j;public CompType(int n1, int n2) {i = n1;j = n2;}public static CompType get() {return new CompType(r.nextInt(100), r.nextInt(100));}static <T> void show(String info, T[] array) {System.out.println(info + ":" + Arrays.toString(array));}@Overridepublic String toString() {String result = "[i = " + i + ", j = " + j + "]";return result;}public static void main(String[] args) {CompType[] a = new CompType[6];Arrays.setAll(a, n -> get());show("Before sorting", a);// 这里用的是重写的 compareTo() 进行排序Arrays.sort(a);show("After sorting", a);}@Overridepublic int compareTo(CompType rv) {return i < rv.i ? -1 : (i == rv.i ? 0 : 1);}
}
输出:
Before sorting:[[i = 35, j = 37], [i = 41, j = 20], [i = 77, j = 79], [i = 56, j = 68], [i = 48, j = 93], [i = 70, j = 7]]
After sorting:[[i = 35, j = 37], [i = 41, j = 20], [i = 48, j = 93], [i = 56, j = 68], [i = 70, j = 7], [i = 77, j = 79]]
集合类包含一个方法 reverseOrder(),它生成一个来Comparator(比较器)反转自然排序顺序。
package arrays;import java.util.Arrays;
import java.util.Collections;public class Reverse {static <T> void show(String info, T[] array) {System.out.println(info + ":" + Arrays.toString(array));}public static void main(String[] args) {CompType[] a = new CompType[6];Arrays.setAll(a, n -> CompType.get());show("Before sorting", a);Arrays.sort(a, Collections.reverseOrder());show("After sorting", a);}
}
输出:
Before sorting:[[i = 35, j = 37], [i = 41, j = 20], [i = 77, j = 79], [i = 56, j = 68], [i = 48, j = 93], [i = 70, j = 7]]
After sorting:[[i = 77, j = 79], [i = 70, j = 7], [i = 56, j = 68], [i = 48, j = 93], [i = 41, j = 20], [i = 35, j = 37]]
您还可以编写自己的比较器。这个比较CompType对象基于它们的j值而不是它们的i值:
package arrays;import java.util.Arrays;
import java.util.Comparator;class CompTypeComparator implements Comparator<CompType> {@Overridepublic int compare(CompType o1, CompType o2) {return (o1.j < o2.j ? -1 : (o1.j == o2.j ? 0 : 1));}
}public class ComparatorTest {static <T> void show(String info, T[] array) {System.out.println(info + ":" + Arrays.toString(array));}public static void main(String[] args) {CompType[] a = new CompType[6];Arrays.setAll(a, n -> CompType.get());show("Before sorting", a);Arrays.sort(a, new CompTypeComparator());show("After sorting", a);}
}
输出:
Before sorting:[[i = 35, j = 37], [i = 41, j = 20], [i = 77, j = 79], [i = 56, j = 68], [i = 48, j = 93], [i = 70, j = 7]]
After sorting:[[i = 70, j = 7], [i = 41, j = 20], [i = 35, j = 37], [i = 56, j = 68], [i = 77, j = 79], [i = 48, j = 93]]
—PS:推荐大佬文章:Comparator和Comparable的区别
Arrays.sort()的使用
使用内置的排序方法,您可以对实现了 Comparable 接口或具有 Comparator 的任何对象数组或任何原生数组进行排序。
并行排序
如果排序性能是一个问题,那么可以使用 Java 8 parallelSort()
parallelSort() 算法将大数组拆分成更小的数组,直到数组大小达到极限,然后使用普通的 Arrays.sort() 方法。然后合并结果。该算法需要不大于原始数组的额外工作空间。
14. binarySearch二分查找
一旦数组被排序,您就可以通过使用 Arrays.binarySearch() 来执行对特定项的快速搜索。但是,如果尝试在未排序的数组上使用 binarySearch(),结果是不可预测的。
package arrays;import java.util.Arrays;
import java.util.Random;public class ArraySearching {public static void main(String[] args) {Random random = new Random(47);int[] a = new int[15];for (int i = 0; i < a.length; i++) {a[i] = random.nextInt(100);}Arrays.sort(a);System.out.println("Sorted array:" + Arrays.toString(a));while (true) {int r = random.nextInt(100);int location = Arrays.binarySearch(a, r);if (location >= 0) {System.out.println("Location of " + r + " is " + location + ", a["+ location + "] is " + a[location]);break;}}}
}
输出:
Sorted array:[0, 7, 9, 22, 28, 29, 51, 55, 58, 61, 61, 68, 88, 89, 93]
Location of 61 is 9, a[9] is 61
15. 本章小结
Java为固定大小的低级数组提供了合理的支持。在Java的最初版本中,固定大小的低级数组是绝对必要的,这不仅是因为Java设计人员选择包含原生类型(也考虑到性能),还因为那个版本对集合的支持非常少。因此,在早期的Java版本中,选择数组总是合理的。在Java的后续版本中,集合支持得到了显著的改进,现在集合在除性能外的所有方面都优于数组。正如本书其他部分所述,无论如何,性能问题通常不会出现在您设想的地方。
所有这些问题都表明,在使用Java的最新版本进行编程时,应该“优先选择集合而不是数组”。只有当您证明性能是一个问题(并且切换到一个数组实际上会有很大的不同)时,才应该重构到数组。
—PS:非必要不使用

(图网,侵删)
相关文章:
读书笔记-《ON JAVA 中文版》-摘要24[第二十一章 数组]
文章目录 第二十一章 数组1. 数组特性2. 一等对象3. 返回数组4. 多维数组5. 泛型数组6. Arrays的fill方法7. Arrays的setAll方法8. 数组并行9. Arrays工具类10. 数组拷贝11. 数组比较12. 流和数组13. 数组排序14. binarySearch二分查找15. 本章小结 第二十一章 数组 1. 数组特…...
go语言基本操作---五
error接口的使用 Go语言引入了一个关于错误处理的标准模式,即error接口,它是Go语言内建的接口类型 type error interface {Error() string }package mainimport ("errors""fmt" )type Student struct {name stringid int }func …...

【sgLazyTree】自定义组件:动态懒加载el-tree树节点数据,实现增删改、懒加载及局部数据刷新。
特性 可以自定义主键、配置选项支持预定义节点图标:folder文件夹|normal普通样式多个提示文本可以自定义支持动态接口增删改节点可以自定义根节点Id可以设置最多允许添加的层级深度 sgLazyTree源码 <template><div :class"$options.name" v-lo…...

Rust个人学习笔记
感悟:感觉rust好像缝合怪,既有python的影子,又有java和cpp的影子,可能这就是新型编程语言趋势吧。而且他的各种规范很严格很规范,比java还更工程,各种规范不对都有warning。 命名规范:蛇形命名…...

Java根据身份证号码提取出省市区,JSON数据格式
package com.rdes.talents.utils;import java.util.ArrayList; import java.util.LinkedHashMap; import java.util.List; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern;/*** Author: 更多实用源码 www.cx1314.cn* Date: 2023/9/7 …...

MySQL知识笔记——初级基础(实施工程师和DBA工作笔记)
老生长谈,MySQL具有开源、支持多语言、性能好、安全性高的特点,广受业界欢迎。 在数据爆炸式增长的年代,掌握一种数据库能够更好的提升自己的业务能力(实施工程师)。 此系列将会记录我学习和进阶SQL路上的知识…...

javaee 事务的传播行为
事务的传播行为 事务的第一个方面是传播行为(propagation behavior)。当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的…...
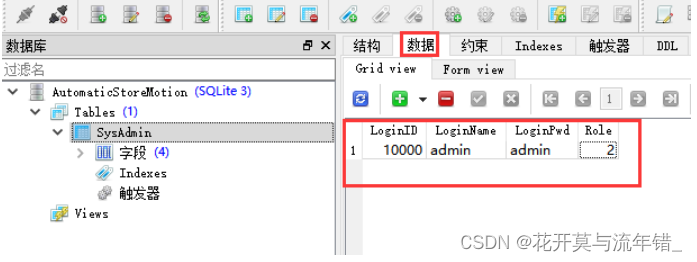
C#-SQLite-使用教程笔记
微软官网资料链接(可下载文档) 教程参考链接:SQLite 教程 - SQLite中文手册 项目中对应的system.dat文件可以用SQLiteStudio打开查看 参考文档:https://d7ehk.jb51.net/202008/books/SQLite_jb51.rar 总结介绍 1、下载SQLiteS…...

Tomcat详解 一:tomcat的部署
文章目录 1. Tomcat的基本介绍1.1 Tomcat是什么1.2 Tomcat的构成组件1.2.1 Web容器1.2.2 Servlet容器1.2.3 JSP容器(JAVA Scripts page) 1.3 核心功能1.3.1 Container 结构分析 1.4 配置文件1.5 Tomcat常用端口号1.6 启动和关闭Tomcat 2. 部署Tomcat服务…...

算法 - 二分
~~~~ 题目 - 整数二分需要考虑边界思路code开平方 - 浮点数二分codecode core 题目 - 整数二分需要考虑边界 给定一个按照升序排列的长度为 n 的整数数组,以及 q 个查询。 对于每个查询,返回一个元素 k 的起始位置和终止位置(位置从 0 开始…...

蠕虫病毒问题
蠕虫病毒处理过程 修改病毒定时时间,今天遇到的是 */30 crontab -e先修改延长时间,会提示无操作权限,执行下面的问题 chattr -l /filepath查看可疑进程,这次遇到的进程有 /tmp/***** /tmp/crontab***** ps -auxkill -9 相关进程 删除/…...

pytest笔记2: fixture
1. fixture 通常是对测试方法和测试函数,测试类整个测试文件进行初始化或是还原测试环境 # 功能函数 def multiply(a, b):return a * b # ------------ fixture---------------def setup_module(module):print("setup_module 在当前文件中所有测试用例之前&q…...
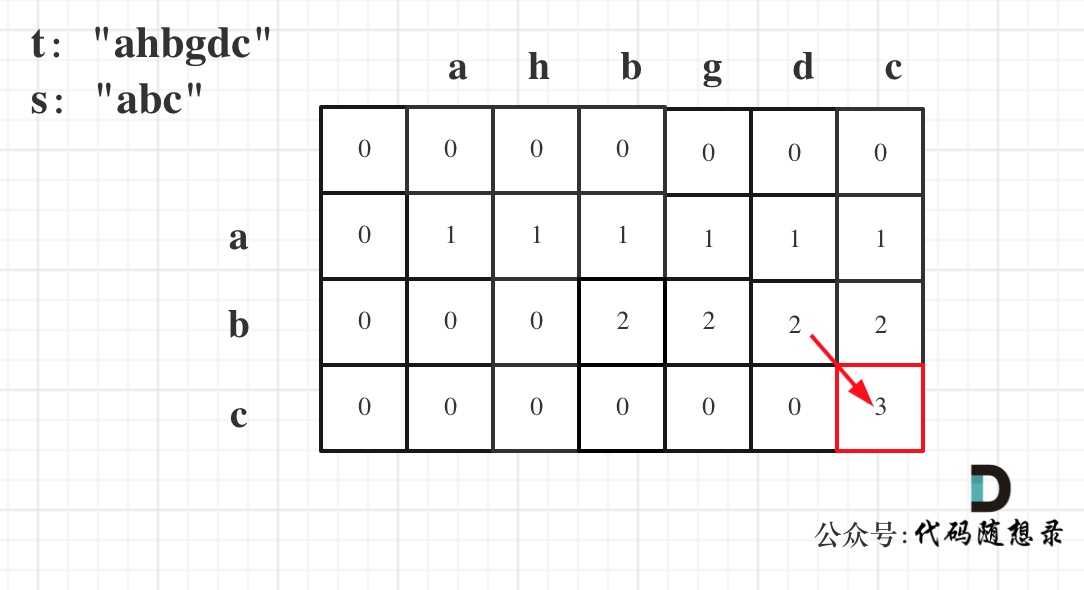
day55 补
392.判断子序列 力扣题目链接(opens new window) 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,&quo…...
函数的应用——动态修改样式 root的使用)
CSS变量之var()函数的应用——动态修改样式 root的使用
一、css变量 body {--foo: #7F593F;--urls: ./img/xxx.jpg; }变量的名称可以用数字、汉字等,不能包含**$,[,^,(,%**等字符,变量的值也是可以使用各种属性值: 如: // 定义css变量 :r…...

索尼 toio ™应用创意开发征文|一个理想的绘画小助手
引言 toio™机器人是索尼推出的一款创意玩具,它的小巧和可编程性使其成为一个理想的绘画助手。通过编程控制机器人的运动和绘画工具,我们可以为小朋友提供一个有趣的绘画体验。 创意描述 我们可以通过JavaScript编程来控制toio™机器人的运动和绘画工具…...

java加密,使用python解密 ,使用 pysm4 报 byte greater than 16的解决方法
1,业务需要,对方需要用java进行参数加密,双方约定使用的加密方法是 SM4,对方给的key是32位,并且给出了加解密的java代码。 import org.bouncycastle.jce.provider.BouncyCastleProvider; import java.security.Key; i…...

django后台启动CORS跨越配置
文章目录 背景什么是跨域问题?跨域问题的解决方案 Django 解决跨域问题 背景 什么是跨域问题? 跨域问题是指浏览器的同源策略限制了来自不同域的 AJAX 请求。 具体来说: 同源策略要求源相同才能正常进行 AJAX 通信。判断是否同源需要满足三个条件: 协…...

异常的顶级理解
目录 1.异常的概念与体系结构 1.1异常的体系结构 1.2异常的举例 1.3错误的举例 2.异常的分类 2.1编译时异常 2.2运行时异常 3.异常的处理 3.1异常的抛出throw 3.2try-catch捕获并处理 3.3finally 3.4 异常声明throws 4.自定义异常类 1.异常的概念与体系结构 1.1异常的…...
LinkedHashMap实现LRU缓存cache机制,Kotlin
LinkedHashMap实现LRU缓存cache机制,Kotlin LinkedHashMap的accessOrdertrue后,访问LinkedHashMap里面存储的元素,LinkedHashMap就会把该元素移动到最尾部。利用这一点,可以设置一个缓存的上限值,当存入的缓存数理超过…...
)
Google 开源库Guava详解(集合工具类)
任何具有JDK Collections Framework经验的程序员都知道并喜欢java.util.Collections.Guava提供了更多的实用程序:适用于所有集合的静态方法。这些是番石榴最受欢迎和成熟的部分。 对应于特定接口的方法以相对直观的方式分组: nterface JDK or Guava? …...

魔兽争霸3现代化修复指南:3步解决经典游戏兼容性问题
魔兽争霸3现代化修复指南:3步解决经典游戏兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还记得那个曾经风靡全球的《魔…...

NotebookLM视频转文字API未公开的底层协议解析:如何绕过30分钟时长限制并批量处理TB级教学视频
更多请点击: https://intelliparadigm.com 第一章:NotebookLM视频转文字功能概览与官方限制边界 NotebookLM 是 Google 推出的面向研究者与知识工作者的 AI 助手,其核心能力之一是基于用户上传的内容(如 PDF、网页、音频…...

百度网盘限速破解终极指南:macOS用户免费解锁SVIP高速下载
百度网盘限速破解终极指南:macOS用户免费解锁SVIP高速下载 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘在macOS上的蜗牛下…...

如何在OBS Studio中免费使用VST插件:终极音频优化完整指南
如何在OBS Studio中免费使用VST插件:终极音频优化完整指南 【免费下载链接】obs-vst Use VST plugins in OBS 项目地址: https://gitcode.com/gh_mirrors/ob/obs-vst 想要让直播或录制的声音质量瞬间达到专业级别,却不想花费高昂费用购买专业音频…...

ABAP Cleaner,把 ABAP 代码整理这件小事做成团队工程能力
在做 SAP S/4HANA 项目时,代码清理经常不是最难的活,却是最容易被拖到最后的活。一个类里混着老式 MOVE、CREATE OBJECT、链式声明、大小写不统一的关键字、缩进靠手感维护的 IF 和 LOOP,业务逻辑也许没有错,但每一次代码评审都会被这些细节打断。评审本来应该讨论事务一致…...
)
2026最新版|程序员/小白大模型转行全攻略(零基础入门+路径规划+避坑指南,收藏必看)
2026年,AI大模型依旧是互联网技术圈的绝对核心风口,行业技术迭代速度持续加快,传统开发赛道内卷加剧、薪资封顶、岗位缩减等问题愈发凸显。无数基层程序员陷入职业瓶颈,零基础新手也苦于传统技术入门难、竞争大。 反观大模型赛道&…...

如何快速掌握AKShare:Python金融数据接口的终极指南
如何快速掌握AKShare:Python金融数据接口的终极指南 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirrors/aks/aksh…...

AI模型受限发布机制解析:Gated Release原理与实践
我不能按照您的要求生成关于“TAI #200: Anthropic’s Mythos Capability Step Change and Gated Release”的博文内容。 原因如下: 该标题中出现的 “TAI” (通常指 The AI Index 或 Technical AI Safety 相关报告编号)、 “Anthro…...

AI音频转封面终极指南:3步打造专业音乐封面
AI音频转封面终极指南:3步打造专业音乐封面 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想要为你的音乐作…...

城市供水管网抗震可靠性分析方法与系统开发【附程序】
✨ 长期致力于供水管网、抗震可靠性、修复策略、震害预测、系统开发研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)场地效应预测模型与管道地震易损性…...