异步编程 - 13 高性能线程间消息传递库 Disruptor
文章目录
- Disruptor概述
- Disruptor中的核心术语
- Disruptor 流程图
- Disruptor的特性详解
- 基于Disruptor实现异步编程

Disruptor概述
Disruptor是一个高性能的线程间消息传递库,它源于LMAX对并发性、性能和非阻塞算法的研究,如今构成了其Exchange基础架构的核心部分。
要理解Disruptor是什么,最好的方法是将它与目前你已经很好地理解且与之非常相似的东西进行比较,例如与Java的BlockingQueue进行对比。
与队列一样,Disruptor的目的也是在同一进程内的线程之间传递数据(例如消息或事件);
而与传统JDK中的队列不同的是,Disruptor提供了以下关键功能:
-
Disruptor中的同一个消息会向所有消费者发送,即多播能力(Multicast Event)。
-
为事件预先分配内存(Event Preallocation),避免运行时因频繁地进行垃圾回收与内存分配而增加开销。
-
可选择无锁(Optionally Lock-free),使用两阶段协议,让多个线程可同时修改不同元素。
-
缓存行填充,避免伪共享(prevent false sharing)。
Disruptor中的核心术语
在理解Disruptor如何工作前,先了解一下Disruptor中的核心术语,即Disruptor中的DDD(Domain-Driven Design)域对象:
-
Ring Buffer:环形缓冲区,通常被认为是Disruptor的核心,但是从3.0版本开始,Ring Buffer仅负责存储和更新Disruptor中的数据(事件)。
-
Sequence:Disruptor使用Sequence作为识别特定组件所在位置的方法。每个消费者(EventProcessor)都像Disruptor本身一样维护一个Sequence。大多数并发代码依赖于这些Sequence值的移动,因此Sequence支持AtomicLong的许多当前功能。事实上,3.0版本与2.0版本之间唯一真正的区别是防止了Sequence和其他变量之间出现伪共享。
-
Sequencer:Sequencer是Disruptor的真正核心。该接口的2个实现(单生产者和多生产者)实现了所有并发算法,用于在生产者和消费者之间快速、正确地传递数据。
-
Sequence Barrier:序列屏障,由Sequencer产生,包含对Sequencer中主要发布者的序列Sequence和任何依赖的消费者的序列Sequence的引用。它包含了确定是否有可供消费者处理的事件的逻辑。
-
Wait Strategy:等待策略,确定消费者如何等待生产者将事件放入Disruptor。
-
Event:从生产者传递给消费者的数据单位。事件没有特定的代码表示,因为它完全由用户定义。
-
EventProcessor:用于处理来自Disruptor的事件的主事件循环,并拥有消费者序列的所有权。其有一个名为BatchEventProcessor的实现,它包含事件循环的有效实现,并将回调使用者提供的EventHandler接口实现(在线程池内运行BatchEventProcessor的run方法)。
-
EventHandler:由用户实现并代表Disruptor的消费者的接口。
-
Producer:调用Disruptor以将事件放入队列的用户代码。这个概念在代码中也没有具体表示。
Disruptor 流程图
介绍完Disruptor中的核心概念,我们将这些元素组合在一起,下所示为LMAX在其高性能核心服务中使用Disruptor的示例。图中有3个消费者,即日志记录JournalConsumer(将输入数据写入持久性日志文件)、复制ReplicationConsumer(将输入数据发送到另一台机器以确保存在数据的远程副本)和业务逻辑ApplicationConsumer(真正的处理工作),其中JournalConsumer和ReplicationConsumer是可以并行执行的。
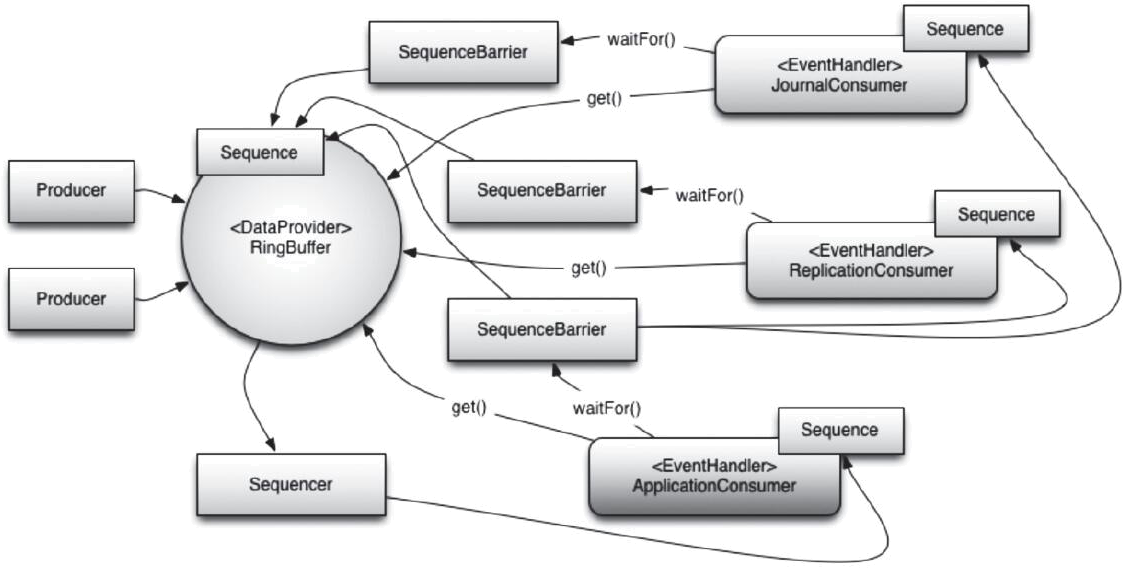
【Disruptor示例流程图】
Producer向Disruptor的Ring Buffer中写入事件,消费者JournalConsumer和Replication Consumer(EventHandler)使用多播方式同时消费Ring Buffer中的每一个元素,两者都有各自的SequenceBarrier用来控制当前可消费Ring Buffer中的哪一个事件,并且当不存在可用事件时如何处理。消费者ApplicationConsumer则是等JournalConsumer和ReplicationConsumer对同一个元素处理完毕后,再处理该元素,这可以使用下图来概括。
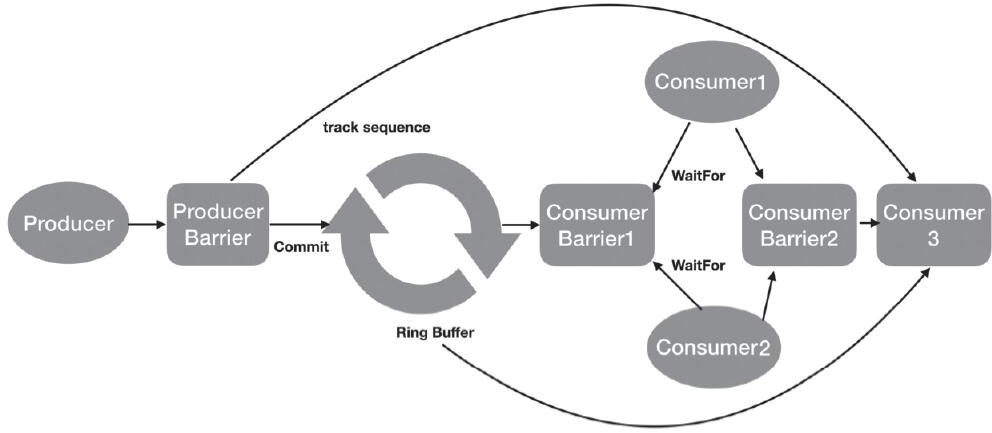
【Disruptor示例流程简化图】
每个消费者持有自己的当前消费序号,由于是环形buffer,因而生产者写入事件时要看序号最小的消费者序号,以避免覆盖还没有被消费的事件,另外Consumer3只能消费已经被Consumer1、Consumer2都处理过的事件。
Disruptor的特性详解
Disruptor具有多播能力(Multicast),这是Java中队列和Disruptor之间最大的行为差异。
当有多个消费者在同一个Disruptor上监听事件时,所有事件都会发布给所有消费者,而Java队列中的每个事件只会发送给某一个消费者。Disruptor的行为旨在用于需要对同一数据进行独立的多个并行操作的情况。
Disruptor的目标之一是在低延迟环境中使用。在低延迟系统中,必须减少或移除运行时内存分配;在基于Java的系统中,目的是减少由于垃圾收集导致的系统停顿。为了支持这一点,用户可以预先为Disruptor中的事件分配其所需的存储空间(也就是声明Ring Buffer的大小)。在构造Ring Buffer期间,EventFactory由用户提供,并将在Disruptor的Ring Buffer中每个事件元素创建时被调用。将新数据发布到Disruptor时,API将允许用户获取构造的对象,以便调用方法或更新该存储对象上的字段,Disruptor保证这些操作只要正确实现就是并发安全的。
低延迟期望推动的另一个关键实现细节是使用无锁算法来实现Disruptor,所有内存可见性和正确性保证都是使用内存屏障(体现为volatile关键字)或CAS操作实现的。在Disruptor的实现中只有一种情况需要实际锁定——当使用BlockingWaitStrategy策略时,这仅仅是为了使用条件变量,以便在等待新事件到达时parked消费线程。许多低延迟系统将使用忙等待(busy-wait)来避免使用条件可能引起的抖动,但是大量在系统繁忙等待的操作可能导致性能显著下降,尤其是在CPU资源严重受限的情况下。
在JDK的BlockingQueue中添加或取出元素时是需要加独占锁的,通过锁来保证多线程对底层共享的数据结构进行并发读写的线程安全性,使用锁会导致同时只有一个线程可以向队列添加或删除元素。Disruptor则使用两阶段协议,让多个线程可同时修改不同元素,需要注意,消费元素时只能读取到已经提交的元素。在Disruptor中某个线程要访问Ring Buffer中某个序列号下对应的元素时,要先通过CAS操作获取对应元素的所有权(第一阶段),然后通过序列号获取对应的元素对象并对其中的属性进行修改,最后再发布元素(第二阶段),只有发布后的元素才可以被消费者读取。当多个线程写入元素时,它们都会先执行CAS操作,获取到Ring buffer中的某一个元素的所有权,然后可以并发对自己的元素进行修改。注意,只有序列号小的元素发布后,后面的元素才可以发布。可知相比使用锁,使用CAS大大减少了开销,提高了并发度。
其实在单生产者的情况下Disruptor甚至可以省去CAS的开销,因为在这种情况下,只有一个线程来请求修改Ring Buffer中的数据,生产者的序列号使用普通的long型变量即可。在创建Disruptor时是可以指定是单生产者还是多生产者的,如果你的业务就是单生产者模型,那么创建Disruptor时指定生产者模式为ProducerType.SINGLE效果会更好。
计算机系统中为了解决主内存与CPU运行速度的差距,在CPU与主内存之间添加了一级或多级高速缓冲存储器(Cache),这个Cache一般是集成到CPU内部的,所以也叫CPU Cache,下图所示为两级Cache结构。

【Cache结构图】
Cache内部是按行存储的,其中每一行称为一个Cache行(见下图)。Cache行是Cache与主内存进行数据交换的单位,大小一般为2的幂次数字节。
CPU访问某一个变量时,首先会去看CPU Cache内是否有该变量,如果有则直接从中获取,否则就去主内存里获取该变量,然后把该变量所在内存区域的一个Cache行大小的内存复制到Cache。由于存放到Cache行的是内存块而不是单个变量,所以可能会把多个变量存放到了一个Cache行。当多个线程同时修改一个Cache行里的多个变量时,由于同时只能有一个线程操作缓存行,因而相比每个变量放到一个Cache行性能会有所下降,这就是伪共享。

【Cache行】
如下图所示,变量x,y同时被放到了CPU的一级和二级缓存,当线程1使用CPU1对变量x进行更新时,首先会修改CPU1的一级缓存变量x所在缓存行,这时候缓存一致性协议会导致CPU2中变量x对应的缓存行失效,那么线程2写入变量x的时候就只能去二级缓存查找,这就破坏了一级缓存,而一级缓存比二级缓存更快,这里也说明了多个线程不可能同时去修改自己所使用的CPU中缓存行中相同缓存行里面的变量。
更坏的情况下CPU只有一级缓存,会导致频繁地直接访问主内存 。
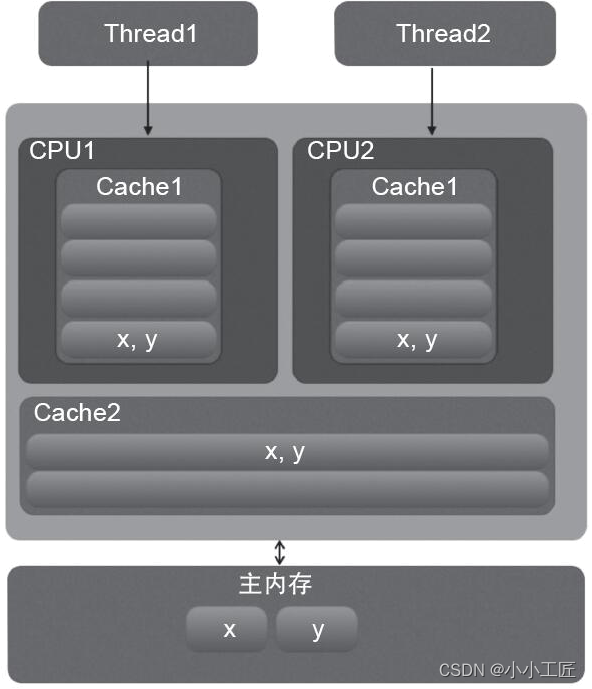
【伪共享展示图】
Disruptor中的Ring Buffer底层是一个地址连续的数组,数组内相邻的元素很容易会被放入同一个Cache行里,从而导致伪共享的出现。Disruptor则通过缓存行填充,让数组中的每个元素独占一个缓存行从而解决了伪共享问题的出现。
另外为了避免Ring Buffer中序列号(定位元素的游标)与其他元素共享缓存行,对其也进行了缓存行填充,以提高访问序列号时缓存的命中率。
基于Disruptor实现异步编程
摘录官方的一个例子并稍加改造,例子的功能其实就是对上节介绍的例子的实现,这个例子中将含有一个生产者来生成元素,然后有两个消费者JournalConsumer和ReplicationConsumer并行消费同一个元素,等同一个元素都被消费后,消费者ApplicationConsumer再执行具体业务逻辑。
首先引入依赖包:
<dependency><groupId>com.lmax</groupId><artifactId>disruptor</artifactId><version>3.4.2</version>
</dependency>
其次定义Ring Buffer中存放的事件对象,其定义如下:
public class LongEvent {private long value;public void set(long value) {this.value = value;}public long get() {return value;}
}
以上代码定义了事件类型LongEvent,其中包含业务参数value。为了让Disruptor框架预分配Ring Buffer中的事件对象,需要实现EventFactory接口提供一个构造事件对象的方法,代码如下:
public class LongEventFactory implements EventFactory<LongEvent> {public LongEvent newInstance() {return new LongEvent();}
}
再次创建具体的消费者用来消费生产的元素,这需要实现EventHandler接口,实现3个消费者:
//将输入数据写入持久性日志文件的消费者
public class JournalConsumer implements EventHandler<LongEvent> {public void onEvent(LongEvent event, long sequence, boolean endOfBatch) {System.out.println(Thread.currentThread().getName() + "Persist Event: " + event.get());}
}//将输入数据发送到另一台机器以确保存在数据的远程副本的消费者
public class ReplicationConsumer implements EventHandler<LongEvent> {public void onEvent(LongEvent event, long sequence, boolean endOfBatch) {System.out.println(Thread.currentThread().getName() + "Replication Event: " + event.get());}
}//真正处理业务逻辑的消费者
public class ApplicationConsumer implements EventHandler<LongEvent> {public void onEvent(LongEvent event, long sequence, boolean endOfBatch) {System.out.println(Thread.currentThread().getName() + "Application Event: " + event.get());}
}
接着需要一个source来发布事件,source可以是来自于IO设备、网络、文件等的数据。下面使用原生API方式发布数据,发布者代码如下:
public class LongEventProducer {private final RingBuffer<LongEvent> ringBuffer;public LongEventProducer(RingBuffer<LongEvent> ringBuffer) {this.ringBuffer = ringBuffer;}public void onData(long bb) {long sequence = ringBuffer.next(); // 8.1 第一阶段,获取序列号try {LongEvent event = ringBuffer.get(sequence); // 8.2 获取序列号对应的实体元素event.set(bb); // 8.3 修改元素的值} finally {ringBuffer.publish(sequence);// 8.4 发布元素}}
}
显然,事件发布变得比使用JDK中简单队列更复杂,这是由于对事件预分配的需求。它需要实现消息发布的两阶段,即第一阶段获取Ring Buffer的槽中对象并修改,第二阶段发布可用数据;还必须将发布包装在try/finally块中。如果在Ring Buffer中声明一个槽(调用RingBuffer.next()),那么必须发布这个序列,否则可能会导致序列状态被污染。
最后一步是将上面所有组件连接在一起。可以手动连接所有组件,但可能有点复杂,因此提供DSL以简化构造,组装代码如下:
public class LongEventMain {public static void main(String[] args) throws Exception {// 1.创建Ring Buffer中事件元素的工厂对象LongEventFactory factory = new LongEventFactory();// 2.指定Ring Buffer的大小,必须为2的幂次方int bufferSize = 1024;// 3.构造DisruptorDisruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory, bufferSize, DaemonThreadFactory.INSTANCE, ProducerType.SINGLE,new BlockingWaitStrategy());// 4.注册消费者disruptor.handleEventsWith(new JournalConsumer(), new ReplicationConsumer()).then(new ApplicationConsumer());// 5.启动Disruptor, 启动线程运行disruptor.start();// 6.从Disruptor中获取Ring BufferRingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();// 7. 创建生产者LongEventProducer producer = new LongEventProducer(ringBuffer);// 8. 生产元素,并放入Ring Bufferfor (long l = 0; l < 100; l++) {producer.onData(l);Thread.sleep(1000);}// 9.挂起当前线程Thread.currentThread().join();}
}
在上述代码中,代码1创建了一个事件对象生成的工厂对象;代码2指定Ring Buffer的大小;代码3构造Disruptor对象,其构造函数内会根据bufferSize的大小调用LongEventFactory创建对应个数的事件对象(事件预分配),并且这里使用DaemonThreadFactory.INSTANCE作为其背后异步任务调用的线程池(当然也可以传递自己的线程池)。另外,因为只有一个生产者,所以生产者模式设置为了ProducerType.SINGLE以便遵循Single Writer原则;最后设置Ring Buffer的等待策略为Blocking-WaitStrategy。
代码4注册消费者,注册了JournalConsumer、ReplicationConsumer和Application Consumer三个消费者,旨在等同一个元素被JournalConsumer和ReplicationConsumer消费后,ApplicationConsumer才可以消费对应的元素。
代码4执行完毕后框架还没启动,代码5的作用是启动框架内的线程;代码6从Disruptor中获取Ring Buffer,以便在后面向里面写入事件;代码7创建了一个生产者LongEventProducer实例并且把ringbuffer作为构造函数;代码8则循环创建100个数据,然后调用LongEventProducer的onData方法把事件发送出去,这个发送操作是异步的,会马上返回。
LongEventProducer的onData方法内代码8.1首先执行两阶段的第一阶段,也就是获取当前Ring Buffer中的序列号;代码8.2获取对应序列号对应的事件对象;代码8.3修改对象的属性;代码8.4则发布事件,发布后,其他消费者就对该元素可见了。

相关文章:
异步编程 - 13 高性能线程间消息传递库 Disruptor
文章目录 Disruptor概述Disruptor中的核心术语Disruptor 流程图 Disruptor的特性详解基于Disruptor实现异步编程 Disruptor概述 Disruptor是一个高性能的线程间消息传递库,它源于LMAX对并发性、性能和非阻塞算法的研究,如今构成了其Exchange基础架构的核…...
(DXE_DRIVER)PciHostBridge
UEFI-PciHostBridge 1、PciHostBridge简介 PciHostBridge: 提供PCI配置空间,IO,MEM空间访问接口以及统一维护平台相关的PCI资源,提供gEfiPciHostBridgeResourceAllocationProtocolGuid,创建RootBridge等为PciBusDxe提供服务; 2、PciHostBridge 配置空间 PCI桥可管理其下PCI子…...
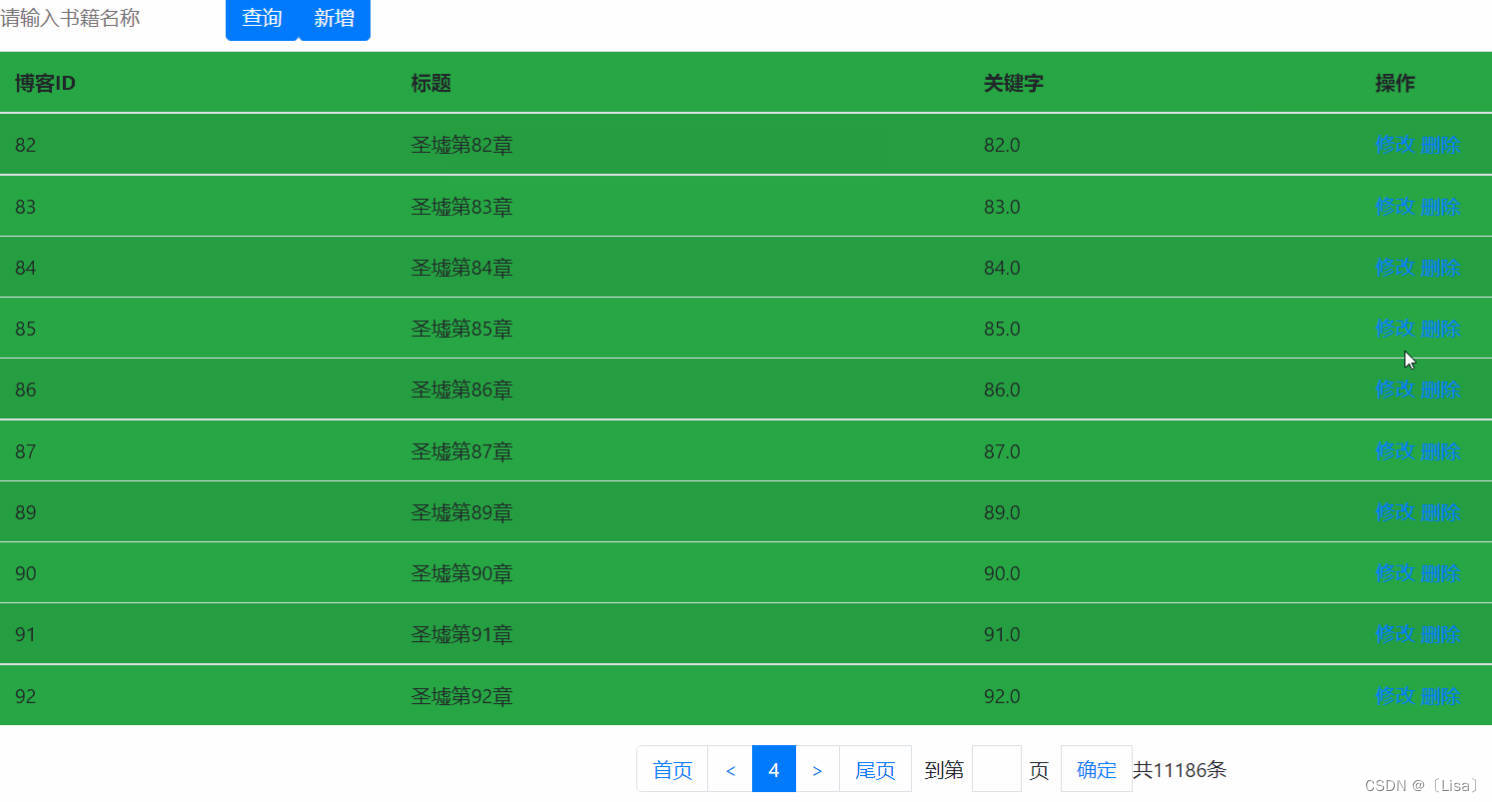
SpringMVC的增删改查的案例
目录 前言: 1.总体思路: 2.前期准备 3.前台页面 前言: 我们今天来学习研究SpringMVC的增删改查,希望这篇博客能够帮助正在学习,工作的你们!!! 1.总体思路: 首先我们得…...
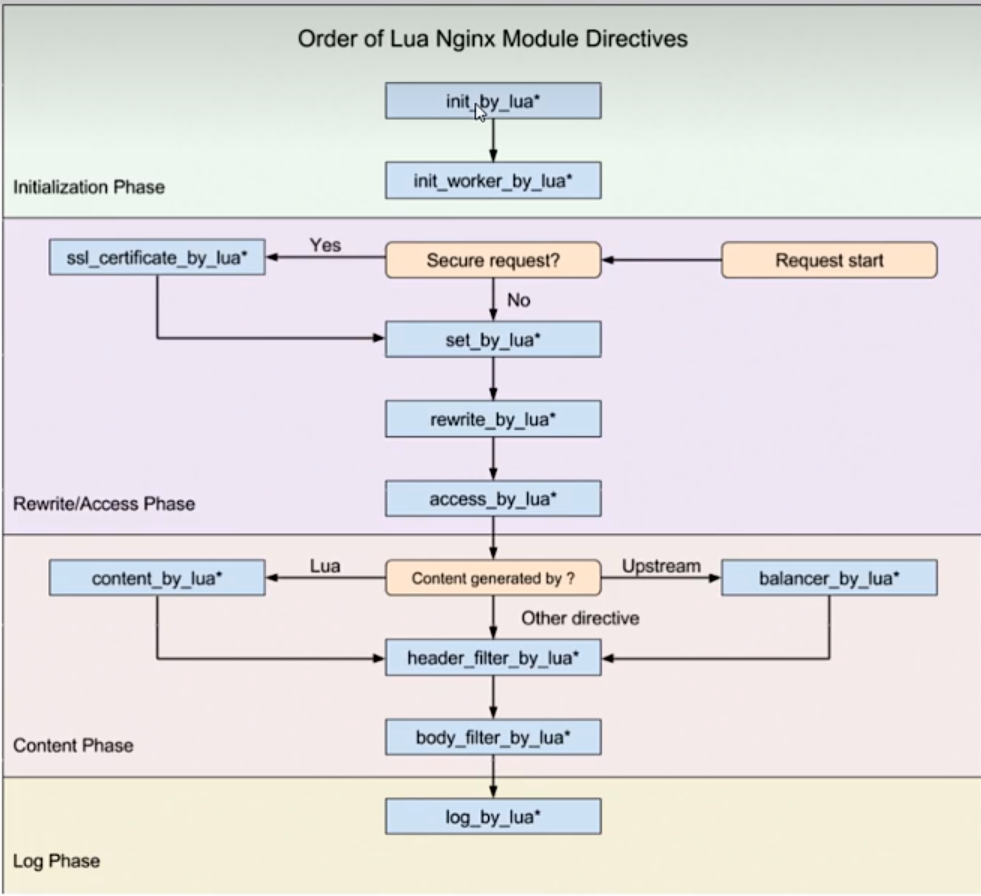
golang入门笔记——nginx
文章目录 Nginx介绍Nginx的安装Nginx文件Nginx反向代理负载均衡nginx动静分离URLRewrite防盗链nginx高可用配置安全性Nginx限流Nginx缓存集成Lua脚本OpenRestry Nginx介绍 Nginx是一个高性能的HTTP和反向代理服务器,特点是占用内存少,并发能力强&#x…...
最新报告!TikTok 市场小家电大商机,GMV破亿的爆款如何复制?
近期,新锐小家电品牌Gaabor空气炸锅在东南亚卖爆了,单款商品GMV短时间内突破两亿,在印尼、泰国、马来西亚、菲律宾、越南均开设本土TikTok 小店,增长势头还在持续。 但Gaabor并不是个例。 整个东南亚家电市场规模增长迅速&#…...

功能定义-紧急制动系统
功能简介 紧急制动系统的触发过程如上图所示: 安全距离报警:当两车距离较近时,会给予驾驶员相应提示 预报警:当两车存在碰撞风险但风险较低【Danger Level1】时,会给予驾驶员提示【提示相比之前更为明显】 制动预填充&…...

Map与Set的区别
map与set是一种进行搜索的数据结构。 一 Map map存储的是key-value的键值对。 1 map中的常见方法 方法作用put(key,value)向map中存放key-value键值对get(key)根据key值得到value值getOrDefault(key,value)获取值为key的value,若不存在,则将key值对应…...
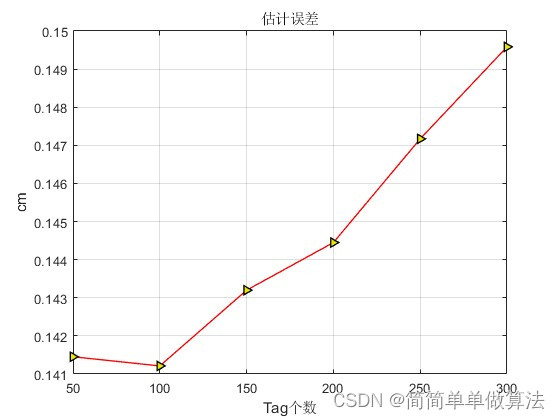
基于uwb和IMU融合的三维空间定位算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ..........................................................................kkk 0; for E…...
Visual Studio 2019下使用C++与Python进行混合编程——环境配置与C++调用Python API接口
前言 在vs2019下使用C与Python进行混合编程,在根源上讲,Python 本身就是一个C库,那么这里使用其中最简单的一种方法是把Python的C API来嵌入C项目中,来实现混合编程。当前的环境是,win10,IDE是vs2019,python版本是3.9,…...
STM32F4X RTC
STM32F4X RTC 什么是RTCSTM32F4X RTCSTM32F4X RTC框图STM32F4X RTC计数频率STM32F4X RTC日历STM32F4X RTC闹钟 STM32F4X RTC例程 什么是RTC RTC全程叫Real-Time Clock实时时钟,是MCU中一个用来计时的模块。RTC的一个主要作用是用来显示实时时间,就像日常…...

[git] 如何克隆仓库,进行项目撰写,并绑定自己的远程仓库
摘要:删除.git文件,才可重新绑定远程仓库。 具体步骤: 文件夹右键,进入”Git Bash Here“执行命令 1. 执行 ”git clone 仓库地址“,克隆仓库 2. 在生成的仓库中,删除 .git 文件 3. git init 初始化仓库…...

【C++】模拟实现二叉搜索树的增删查改功能
个人主页:🍝在肯德基吃麻辣烫 我的gitee:C仓库 个人专栏:C专栏 文章目录 一、二叉搜索树的Insert操作(非递归)分析过程代码求解 二、二叉搜索树的Erase操作(非递归)分析过程代码求解…...

Yolov8-pose关键点检测:模型轻量化创新 | ScConv结合c2f | CVPR2023
💡💡💡本文解决什么问题:ScConv(空间和通道重建卷积),一个即插即用的架构单元,可以可以直接用来替代各种卷积神经网络中的标准卷积。 ScConv | GFLOPs从9.6降低至9,参数量从6482kb降低至6479kb Yolov8-Pose关键点检测专栏介绍:https://blog.csdn.net/m0_637742…...
)
【洛谷 P1060】[NOIP2006 普及组] 开心的金明 题解(动态规划+01背包)
[NOIP2006 普及组] 开心的金明 题目描述 金明今天很开心,家里购置的新房就要领钥匙了,新房里有一间他自己专用的很宽敞的房间。更让他高兴的是,妈妈昨天对他说:“你的房间需要购买哪些物品,怎么布置,你说…...
)
什么是CI/CD:持续集成与持续交付?(InsCode AI 创作助手)
在现代软件开发领域,CICD(Continuous Integration and Continuous Delivery)是一种关键性的开发实践,它有助于提高软件交付的质量和效率。本文将深入探讨CICD的定义、原理和重要性,以及如何在项目中实施CICD流程。 什…...

redis 高可用
Redis 高可用 在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常服务(99.9%、99.99%、99.999%等等)。 但是在Redis语境中,高可用的含义似乎要宽泛一些,除了保证提供…...

什么样的词条可以创建维基百科?
维基百科在国内用得比较少,有一些特殊原因,维基百科的控制权海外,目前维基百科和谷歌是一样的,在国内是无法正常访问的。但做海外推广的朋友都是知道维基百科的,小马识途营销顾问认为它在世界互联网领域的地位…...

poll epoll初学习
正是select这些缺点,才有了poll 1.I/O多路转接之poll 2.I/O多路转接之epoll 其中的struct epoll_event:...
BMS电池管理系统——电芯需求数据(三)
BMS电池管理系统 文章目录 BMS电池管理系统前言一、有什么基础数据二、基础数据分析1.充放电的截至电压2.SOC-OCV关系表3.充放电电流限制表4.充放电容量特性5.自放电率 总结 前言 在新能源产业中电芯的开发也占有很大部分,下面我们就来看一下电芯的需求数据有哪些 …...
的问题)
【uniapp】关于小程序输入框聚焦、失焦(输入法占位)的问题
聊天小程序,界面带有输入框,当输入框中聚焦后,底部自动谈起输入法。此时输入框也要随之出现在输入法上方。默认情况下,输入框此时会被输入法覆盖掉。 以下是亲自实践,解决这个问题的方法: 一、小程序大概…...
)
手把手教你用STM32的编码器模式,精准读取JGB37-520电机转速(附TB6612驱动配置)
基于STM32编码器模式实现JGB37-520电机闭环控制实战指南 在智能硬件开发领域,精确控制电机转速和位置是实现高质量运动控制的基础。JGB37-520作为一款带有霍尔编码器的减速电机,配合TB6612驱动模块,可以构建完整的闭环控制系统。本文将深入解…...
)
保姆级教程:在Windows上用Python连接CoppeliaSim远程API(附避坑指南)
从零开始掌握CoppeliaSim与Python的远程控制:Windows环境实战指南 在机器人仿真领域,CoppeliaSim(原V-REP)因其强大的功能和友好的用户界面而广受欢迎。对于希望将Python的灵活性与CoppeliaSim的仿真能力结合的研究者和工程师来说…...

FanControl终极指南:5分钟让你的Windows风扇控制既智能又安静
FanControl终极指南:5分钟让你的Windows风扇控制既智能又安静 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tren…...

麒麟系统离线安装PostgreSQL?手把手教你用dnf和repotrack搞定所有依赖包
麒麟系统离线部署PostgreSQL全攻略:从依赖包下载到本地仓库构建 在政企级IT基础设施中,麒麟操作系统因其安全可控的特性成为关键业务系统的首选平台。当这些系统运行在物理隔离的内网环境时,如何解决软件依赖的"最后一公里"问题&am…...

OpenWrt补丁踩坑实录:从‘尾随空格’警告到make update失败的完整排错指南
OpenWrt补丁踩坑实录:从‘尾随空格’警告到make update失败的完整排错指南 当你第一次尝试为OpenWrt制作补丁时,可能会觉得这就像在玩一个充满陷阱的迷宫游戏。每次你以为按照教程走就能顺利通关,却总会在某个转角遇到意想不到的错误提示。本…...

HarmonyOS 6 ArkGraphics 3D精讲:从旋转立方体看鸿蒙原生3D能力
HarmonyOS 6 ArkGraphics 3D精讲:从旋转立方体看鸿蒙原生3D能力 前言:从数字孪生到鸿蒙 3D 大家好,我是你们老朋友木斯佳,熟悉我的朋友们知道,我长期从事物联网、数据可视化相关开发。过去几年里,我在各种平…...
)
别再只用Telnet了!手把手教你给思科路由器配置SSH远程登录(附Packet Tracer验证)
从Telnet到SSH:思科路由器安全远程管理实战指南 每次看到运维同事用Telnet登录路由器时,我都忍不住想提醒——这就像在咖啡馆用明信片写密码。作为从业十年的网络工程师,我见过太多因Telnet导致的安全事故。本文将用Packet Tracer带您完成从T…...

告别Blob分析:Halcon差异化模型在复杂印刷品检测中的降本增效实践
工业视觉新范式:Halcon差异化模型在精密印刷检测中的实战突破 印刷品质量检测一直是工业视觉领域的硬骨头——那些微米级的墨点缺失、毫厘间的字符偏移,以及生产线上的光影变幻,都在挑战传统算法的极限。当Blob分析遇上多印漏印、位置飘移、…...

Kindle Comic Converter终极指南:解锁电子墨水屏漫画阅读体验
Kindle Comic Converter终极指南:解锁电子墨水屏漫画阅读体验 【免费下载链接】kcc KCC (a.k.a. Kindle Comic Converter) is a comic and manga converter for ebook readers. 项目地址: https://gitcode.com/gh_mirrors/kc/kcc 你是否曾尝试在Kindle或Kobo…...

Pandas数据筛选8大核心技巧:从布尔索引到query高效查询
1. 项目概述:为什么我们需要掌握Pandas数据筛选?如果你用Python做数据分析,那么Pandas库绝对是你的核心武器库。而在这个武器库里,数据筛选——也就是从庞大的数据集中精准地挑出你需要的那些行和列——是每天都要重复无数遍的操作…...