一文带你快速入门『YOLOv8』
前言
本文是 YOLOv8 入门指南(大佬请绕过),将会详细讲解安装,配置,训练,验证,预测等过程
YOLOv8 官网:ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite (github.com)

注意:如果遇到权重文件,模型文件下载缓慢的问题,可以在自己本机上下载,再上传到服务器。也可以选择代理或是 IDM 这样的下载软件
安装配置
虚拟环境
本文使用 conda 创建虚拟环境,没有配置 conda 也可以使用 python venv 虚拟环境
# 创建环境
conda create -n pytorch python=3.8 -y
# 查看环境
conda env list
# 激活环境
conda activate pytorch
安装依赖
请自行到 Pytorch 官网寻找安装命令(需要保证 PyTorch>=1.8)

# 请自行替换命令
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cpu
拉取仓库
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
# 安装依赖
pip install -e .
如果只是想要快速尝试训练自定义数据集并预测结果,可以跳过后面章节教学,直接跳到最后章节的实战演练
两种使用方式
YOLO 命令行
YOLO命令行界面(command line interface, CLI), 方便在各种任务和版本上训练、验证或推断模型。CLI不需要定制或代码,可以使用 yolo 命令从终端运行所有任务。
【YOLO CLI 官方文档】:CLI - Ultralytics YOLOv8 Docs
语法(Usage)
yolo TASK MODE ARGSWhere TASK (optional) is one of [detect, segment, classify]MODE (required) is one of [train, val, predict, export, track]ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
查看所有参数:yolo cfg
训练(Train)
在COCO128上以图像大小 640 训练 YOLOv8n 100 个 epoch
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
恢复中断的训练
yolo detect train resume model=last.pt
验证(Val)
在COCO128数据集上验证经过训练的 YOLOv8n 模型准确性。无需传递参数,因为它 model 保留了它的训练 data 和参数作为模型属性。
yolo detect val model=path/to/best.pt
预测(Predict)
使用经过训练的 YOLOv8n 模型对图像运行预测。
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg'
导出(Export)
将 YOLOv8n 模型导出为不同的格式,如 ONNX、CoreML 等。
yolo export model=path/to/best.pt format=onnx
可用导出形式如下
| Format 格式 | format Argument | format 论点 | Model 型 | Metadata 元数据 | Arguments 参数 |
|---|---|---|---|---|---|
| PyTorch | - | yolov8n.pt | ✅ | - | - |
| TorchScript | torchscript | yolov8n.torchscript | ✅ | imgsz, optimize | - |
| ONNX | onnx | yolov8n.onnx | ✅ | imgsz, half, dynamic, simplify, opset | - |
| OpenVINO | openvino | yolov8n_openvino_model/ | ✅ | imgsz, half | - |
| TensorRT | engine | yolov8n.engine | ✅ | imgsz, half, dynamic, simplify, workspace | - |
| CoreML | coreml | yolov8n.mlpackage | ✅ | imgsz, half, int8, nms | - |
| TF SavedModel | saved_model | yolov8n_saved_model/ | ✅ | imgsz, keras | - |
| TF GraphDef | pb | yolov8n.pb | ❌ | imgsz | - |
| TF Lite | tflite | yolov8n.tflite | ✅ | imgsz, half, int8 | - |
| TF Edge TPU | edgetpu | yolov8n_edgetpu.tflite | ✅ | imgsz | - |
| TF.js | tfjs | yolov8n_web_model/ | ✅ | imgsz | - |
| PaddlePaddle | paddle | yolov8n_paddle_model/ | ✅ | imgsz | - |
| ncnn | ncnn | yolov8n_ncnn_model/ | ✅ | imgsz, half | - |
覆盖默认配置文件
首先使用命令 yolo copy-cfg 在当前工作目录中创建一个 default.yaml 的副本 default_copy.yaml,之后即可指定配置文件来覆盖默认配置文件
yolo cfg=default_copy.yaml imgsz=320
Python 脚本
YOLOv8 可以无缝集成到 Python 项目中,以进行对象检测、分割和分类。同时易于使用的 Python 界面是一个宝贵的资源,能够快速实现高级对象检测功能
【YOLO Python 官方文档】:CLI - Ultralytics YOLOv8 Docs — CLI - Ultralytics YOLOv8 文档
示例
from ultralytics import YOLO# 从头开始创建一个新的YOLO模型
model = YOLO('yolov8n.yaml')# 加载预训练的YOLO模型(推荐用于训练)
model = YOLO('yolov8n.pt')# 使用'coco128.yaml'数据集对模型进行训练,训练3个epoch
results = model.train(data='coco128.yaml', epochs=3)# 在验证集上评估模型的性能
results = model.val()# 使用模型对图像进行目标检测
results = model('https://ultralytics.com/images/bus.jpg')# 将模型导出为ONNX格式
success = model.export(format='onnx')

训练
训练模式用于在自定义数据集上训练 YOLOv8 模型。在此模式下,使用指定的数据集和超参数训练模型。训练过程涉及优化模型的参数,以便它可以准确地预测图像中对象的类别和位置。
预训练(From pretrained 推荐使用)
from ultralytics import YOLOmodel = YOLO('yolov8n.pt') # pass any model type
results = model.train(epochs=5)
初始训练(From scratch)
from ultralytics import YOLOmodel = YOLO('yolov8n.yaml')
results = model.train(data='coco128.yaml', epochs=5)
恢复训练(Resume)
model = YOLO("last.pt")
results = model.train(resume=True)
验证
Val 模式用于在训练 YOLOv8 模型后对其进行验证。在此模式下,在验证集上评估模型,以衡量其准确性和泛化性能。此模式可用于调整模型的超参数以提高其性能。
训练后验证
from ultralytics import YOLO# 导入YOLO模型
model = YOLO('yolov8n.yaml')# 使用'coco128.yaml'数据集对模型进行训练,训练5个epoch
model.train(data='coco128.yaml', epochs=5)# 对训练数据进行自动评估
model.val() # 它会自动评估您训练的数据。
单独验证
from ultralytics import YOLO# 导入YOLO模型
model = YOLO("model.pt")
# 如果您没有设置data参数,它将使用model.pt中的数据YAML文件。
model.val()
# 或者您可以设置要验证的数据
model.val(data='coco128.yaml')
预测
预测模式用于使用经过训练的 YOLOv8 模型对新图像或视频进行预测。在此模式下,模型从检查点文件加载,用户可以提供图像或视频来执行推理。该模型预测输入图像或视频中对象的类别和位置。
from ultralytics import YOLO
from PIL import Image
import cv2model = YOLO("model.pt")
# 接受各种格式 - 图像/目录/路径/URL/视频/PIL/ndarray。0表示网络摄像头
results = model.predict(source="0")
results = model.predict(source="folder", show=True) # 显示预测结果。接受所有YOLO预测参数# 使用PIL库
im1 = Image.open("bus.jpg")
results = model.predict(source=im1, save=True) # 保存绘制的图像# 使用ndarray
im2 = cv2.imread("bus.jpg")
results = model.predict(source=im2, save=True, save_txt=True) # 将预测结果保存为标签# 使用PIL/ndarray列表
results = model.predict(source=[im1, im2])
导出
导出模式用于将 YOLOv8 模型导出为可用于部署的格式。在此模式下,模型将转换为可供其他软件应用程序或硬件设备使用的格式。将模型部署到生产环境时,此模式非常有用。
from ultralytics import YOLOmodel = YOLO('yolov8n.pt')
model.export(format='onnx', dynamic=True)
跟踪
跟踪模式用于使用 YOLOv8 模型实时跟踪对象。在此模式下,模型从检查点文件加载,用户可以提供实时视频流来执行实时对象跟踪。此模式对于监控系统或自动驾驶汽车等应用非常有用。
from ultralytics import YOLO# 加载模型
model = YOLO('yolov8n.pt') # 加载官方的检测模型
model = YOLO('yolov8n-seg.pt') # 加载官方的分割模型
model = YOLO('path/to/best.pt') # 加载自定义模型# 使用模型进行目标跟踪
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
训练器
YOLO模型类是Trainer类的高级包装器。每个YOLO任务都有自己的从BaseTrainer继承来的训练器。
from ultralytics.yolo import v8 import DetectionTrainer, DetectionValidator, DetectionPredictor# trainer
trainer = DetectionTrainer(overrides={})
trainer.train()
trained_model = trainer.best# Validator
val = DetectionValidator(args=...)
val(model=trained_model)# predictor
pred = DetectionPredictor(overrides={})
pred(source=SOURCE, model=trained_model)# resume from last weight
overrides["resume"] = trainer.last
trainer = detect.DetectionTrainer(overrides=overrides)
多任务支持
下面示例主要使用 Python 脚本的形式,CLI 形式可以自行到官网找到对应示例代码
官方文档:Train - Ultralytics YOLOv8 Docs
目标检测
物体检测是一项涉及识别图像或视频流中物体的位置和类别的任务。
对象检测器的输出是一组包围图像中的对象的包围框,以及每个框的类标签和置信度分数。当你需要识别场景中感兴趣的物体,但不需要知道物体的确切位置或它的确切形状时,物体检测是一个很好的选择。
训练
在图像大小为 640 的 COCO128 数据集上训练 YOLOv8n 100 个 epoch。
设备是自动确定的。如果 GPU 可用,则将使用它,否则将在 CPU 上开始训练。
from ultralytics import YOLO# 加载一个模型
model = YOLO('yolov8n.yaml') # 从YAML文件构建一个新模型
model = YOLO('yolov8n.pt') # 加载一个预训练模型(推荐用于训练)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML文件构建模型并加载权重# 训练模型
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)
可以使用 device 参数指定训练设备。如果未传递任何参数,则将使用 GPU device=0 (如果可用),否则 device=cpu 将使用。
from ultralytics import YOLO# 加载一个模型
model = YOLO('yolov8n.pt') # 加载一个预训练模型(推荐用于训练)# 使用2个GPU训练模型
results = model.train(data='coco128.yaml', epochs=100, imgsz=640, device=[0, 1])
验证
Val 模式用于在训练 YOLOv8 模型后对其进行验证。在此模式下,在验证集上评估模型,以衡量其准确性和泛化性能。此模式可用于调整模型的超参数以提高其性能。
YOLOv8 模型会自动记住其训练设置,因此您只需 yolo val model=yolov8n.pt 使用 or model('yolov8n.pt').val() 即可在原始数据集上轻松验证相同图像大小和原始数据集上的模型
在COCO128数据集上验证经过训练的 YOLOv8n 模型准确性。无需传递参数,因为它 model 保留了它的训练 data 和参数作为模型属性
from ultralytics import YOLO# 导入模型
model = YOLO('yolov8n.pt') # 加载一个官方模型
model = YOLO('path/to/best.pt') # 加载一个自定义模型# 验证模型
metrics = model.val() # 不需要参数,数据集和设置会被记住
metrics.box.map # mAP50-95
metrics.box.map50 # mAP50
metrics.box.map75 # mAP75
metrics.box.maps # 包含每个类别的mAP50-95的列表
预测
YOLOv8 预测模式可以为各种任务生成预测,在使用流式处理模式时返回对象列表或内存高效的 Results Results 对象生成器。通过传入 stream=True 预测器的调用方法来启用流式处理模式。
YOLOv8 可以处理不同类型的输入源进行推理,如下表所示。源包括静态图像、视频流和各种数据格式。该表还指示每个源是否可以在流模式下与参数 stream=True ✅一起使用。流式传输模式有利于处理视频或实时流,因为它会创建结果生成器,而不是将所有帧加载到内存中
from ultralytics import YOLO# 导入模型
model = YOLO('yolov8n.pt') # 加载一个预训练的YOLOv8n模型# 对图像列表进行批量推理
results = model(['im1.jpg', 'im2.jpg']) # 返回一个Results对象列表# 处理结果列表
for result in results:boxes = result.boxes # 用于边界框输出的Boxes对象masks = result.masks # 用于分割掩模输出的Masks对象keypoints = result.keypoints # 用于姿势输出的Keypoints对象probs = result.probs # 用于分类输出的Probs对象
导出
导出模式用于将 YOLOv8 模型导出为可用于部署的格式。在此模式下,模型将转换为可供其他软件应用程序或硬件设备使用的格式。将模型部署到生产环境时,此模式非常有用。
from ultralytics import YOLO# 导入模型
model = YOLO('yolov8n.pt') # 加载一个官方模型
model = YOLO('path/to/best.pt') # 加载一个自定义训练的模型# 导出模型
model.export(format='onnx')
实例分割和目标分类此处不再赘述,可以自行查找官方文档
实战演练
下面将会自定义训练目标检测数据集
注意:没有特殊说明,路径均是以项目根目录为准
官方数据集
首先下载权重文件并将放到 ultralytics 项目根目录

之后测试预训练模型的效果,在根目录执行如下命令
yolo predict model=yolov8n.pt source=ultralytics/assets/bus.jpg

之后我们查看保存的检测好的图片 /root/Development/ultralytics/runs/detect/predict2

训练 COCO128 数据集(这里可以配置 tensorboard 可视化面板,这里不赘述)
yolo train data=coco128.yaml model=yolov8n.pt epochs=3 lr0=0.01 batch=4
与此同时根目录下面生成了一个datasets文件夹,里面有 coco128 的数据集
注意:这里的 datasets 下载目录是在
~/.config/Ultralytics/settings.yaml文件中定义的,可以后续修改

之后查看存储的训练结果的文件夹,weights 文件夹里面装的是效果最好的一次权重文件以及最后一轮训练的权重文件
自定义数据集
下载数据集
【下载地址】:Mask Wearing Dataset - raw (roboflow.com)

然后下载 zip 压缩包即可
配置数据集
上传到项目根目录的 datasets,并重命名数据集为 MaskDataSet(本次演示直接使用下载的数据集,后面的部分步骤是针对自己制作数据集的要求)
data.yaml修改如下
path: ../datasets/MaskDataSet
train: ./train/images
val: ./valid/images
test: ./test/imagesnc: 2
names: ['mask', 'no-mask']roboflow:workspace: joseph-nelsonproject: mask-wearingversion: 4license: Public Domainurl: https://universe.roboflow.com/joseph-nelson/mask-wearing/dataset/4
划分数据集
我们需要将数据集按照指定比例划分(训练集:验证集:测试集=7:2:1)
【数据集划分脚本】:division-of-data/DivisionOfData.py at main · kuisec/division-of-data (github.com)
标注数据集
安装 lableme,执行 pip install labelme,然后命令行输入 labelme即可进入图形化界面
但是注意:labelme 生成的标签是 json 文件的格式,后续需要转化成 txt 文件才能被 yolov 使用
这里说下两种标注工具 labelImg 和 labelme 的区别
labelimg 是一种矩形标注工具,常用于目标识别和目标检测,其标记数据输出为.xml和.txt
labelme 是一种多边形标注工具,可以准确的将轮廓标注出来,常用于分割,其标记输出格式为json
【数据集标注文件格式转换脚本】:DeepLearning/others/label_convert at master · KKKSQJ/DeepLearning (github.com)
训练数据集
yolo train data=datasets/MaskDataSet/data.yaml model=yolov8n.pt epochs=10 lr0=0.01 batch=4

使用效果最好的权重文件进行预测测试(需要提前上传 ultralytics/assets/mask.jpg口罩图片)
yolo predict model=runs/detect/train26/weights/best.pt source=ultralytics/assets/mask.jpg
查看最终效果

参考文章
YOLOv8详解 【网络结构+代码+实操】_zyw2002的博客-CSDN博客
YOLOv8教程系列:一、使用自定义数据集训练YOLOv8模型(详细版教程,你只看一篇->调参攻略),包含环境搭建/数据准备/模型训练/预测/验证/导出等_Zhijun.li@Studio的博客-CSDN博客
零基础教程:使用yolov8训练自己的目标检测数据集_Dragon_0010的博客-CSDN博客
YOLOv5实操——检测是否戴口罩-CSDN博客
本文由博客一文多发平台 OpenWrite 发布!
相关文章:
一文带你快速入门『YOLOv8』
前言 本文是 YOLOv8 入门指南(大佬请绕过),将会详细讲解安装,配置,训练,验证,预测等过程 YOLOv8 官网:ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONN…...

# 将PCL点云转换为Eigen向量进行运算
将PCL点云转换为Eigen向量进行运算 在处理点云数据时,我们常需要将PCL中的点云转换为Eigen向量,进行一些矩阵运算。这里介绍PCL点云到Eigen向量的两种转换方法。 点云转换为Eigen数组 对于一个PCL的点云,可以通过getArray4fMap()函数获取Eigen数组表示: // PCL点云 pcl::Po…...
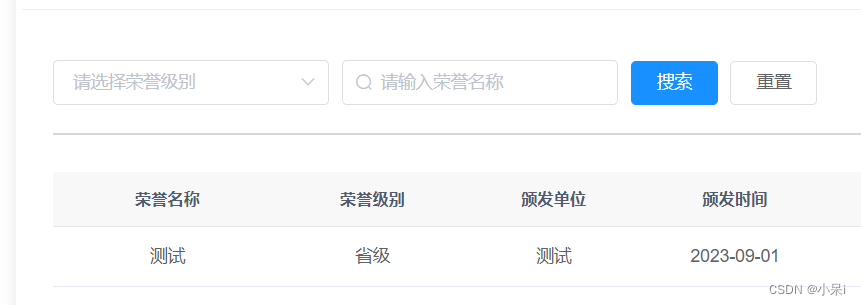
elmentui表单重置及出现的问题
一、表单: 二、代码——拿官方的代码举例(做了一些小改动): 改动:model绑定的字段,由form改为queryParams ref绑定的字段form改为queryFrom 注:model绑定的这个字段用来做数据双向绑定的 注:ref绑定的这…...

游戏平台加盟该怎么做?需要准备什么?
游戏平台加盟是一种合作模式,允许个人或企业以加盟商的身份参与游戏平台,并从中获得一定的权益和收益。以下是一些步骤和需要准备的事项,来考虑如何进行游戏平台加盟: 步骤: 研究市场和平台:了解游戏市场和…...

selenium中定位shadow-root,以及获取shadow-root内部的数据
通过shadow-root的父级定位到shadow-root,再通过语句进行操作 两种方法: 第一种,Python种JS实现 第二种,selenium实现 1.0 案例网站 参考某橘色网站 2.0 js语句定位 可在控制台进行测试 测试语句 document.querySelector("ali-ba…...

OpenCV(三十二):轮廓检测
1.轮廓概念介绍 在计算机视觉和图像处理领域中,轮廓是指在图像中表示对象边界的连续曲线。它是由一系列相邻的点构成的,这些点在边界上连接起来形成一个封闭的路径。 轮廓层级: 轮廓层级(Contour Hierarchy)是指在包含…...

接口自动化测试做线上巡检,如何避免数据污染
在接口自动化测试中,避免数据污染是非常重要的,特别是在线上环境中进行巡检。 1. 使用独立的测试环境:建议使用专门的测试环境来进行接口自动化测试,而不是直接在生产环境中进行。测试环境应该是一个独立的、与生产环境隔离的环境…...

C++ 指针
C 指针 学习 C 的指针既简单又有趣。通过指针,可以简化一些 C 编程任务的执行,还有一些任务,如动态内存分配,没有指针是无法执行的。所以,想要成为一名优秀的 C 程序员,学习指针是很有必要的。 正如您所知…...

SpringBoot集成kubernetes-client升级k8s后初始化失败问题
SpringBoot集成kubernetes-client升级k8s后初始化失败问题 1.问题描述 程序以前使用的k8s版本是1.16,fabric8.kubernetes-client的版本是4.10.2,springboot版本是2.3.5。由于环境切换,这次需要升级k8s的版本,现在将k8s版本升级到…...
MySQL 学习笔记
😀😀😀创作不易,各位看官点赞收藏. 文章目录 MySQL 学习笔记1、DQL 查询语句1.1、基本查询1.2、函数查询1.2.1、单行函数1.2.2、聚合函数 1.3、复杂查询1.3.1、连接查询1.3.2、子查询 1.4、SQL 语句 执行顺序 2、DDL 定义语句2.1、…...

Docker 的常用命令
0 基本命令 概述 [root192 home]# docker --helpUsage: docker [OPTIONS] COMMANDA self-sufficient runtime for containersOptions:--config string Location of client configfiles (default "/root/.docker")-c, --context string Name of the context…...

嵌入式-电子电路四个基本定律
目录 1、欧姆定律 2、焦耳定律 3、基尔霍夫电流定律 4、基尔霍夫电压定律 1、欧姆定律 欧姆定律是关于导体两端电压与导体中电流关系的定律。具体表述为:在同一电路中,通过某段导体的电流跟这段导体两端的电压成正比,跟这段导体的电阻成反…...

【linux命令讲解大全】083.Linux 常用命令ispell , spell , atrm, chattr
文章目录 ispell补充说明语法参数 spell补充说明语法参数 atrm补充说明语法选项参数 实例 chattr补充说明语法选项 实例 从零学 python ispell 检查文件中出现的拼写错误。 补充说明 ispell命令用于检查文件中出现的拼写错误。 语法 ispell [参数] 参数 文件:…...

JAVA实现SAP接口
JAVA实现SAP接口 环境spring-bootmaven 1.maven依赖 <dependency><groupId>com.github.virtualcry</groupId><artifactId>sapjco-spring-boot-starter</artifactId><version>3.1.4</version></dependency>2.配置文件 applic…...

华南理工大学811信号与系统考研分数线,招生人数,报考统计,考情分析,就业,真题,大纲,参考书,华工811
华南理工大学811信号与系统考研分数线,招生人数,报考统计,考情分析,就业,真题,大纲,参考书,华工811 华南理工大学811信号与系统考研分数线,招生人数,报考统…...

Android 字符串 占位符
在 Android 中,字符串中的 % 后面跟着的字符称为格式化占位符,用于指示在运行时将值插入到字符串中的位置,并指定插入的值的类型。常见的格式化占位符类型如下: %s:字符串占位符。它用于插入字符串值。 String name …...

vue页面添加水印(可用于H5,APP)
vue页面添加水印 背景实现新建vue组件使用效果 尾巴 背景 最近实现了一个小功能,就是给页面添加背景水印。实现思路就是定义一个宽高充满屏幕的组件,然后使用绝对定位并通过层级控制让水印显示在页面的最前端。 实现 代码相对简单,相信有点…...
下载git
1.官网下载可能会有访问失败 2.用其他的镜像源下载 快 准 狠 CNPM Binaries Mirror...

MSYS2 如何切换镜像源(附带脚本自动修改)
这篇文章将总结【如何切换MSYS2镜像】,其实比较简单,但还是记录一下吧。 下面示例中附带一个脚本,这样你就不用一个个手动修改了。 1. 镜像服务配置文件 MSYS2 的所有镜像服务配置,都在其安装路径下的etc/pacman.d目录下 可以看到…...

使用ICMP协议来判断UDP端口的存活状态
我们使用了原始套接字(socket.SOCK_RAW)来发送和接收ICMP消息,也就是通过模拟ICMP协议来进行UDP端口的探测。我们构造了一个简单的ICMP数据包,并将其发送到目标主机的特定端口。然后,我们等待接收目标主机返回的ICMP消…...

基于python的民宿预定管理系统设计与实现j470j
目录同行可拿货,招校园代理 ,本人源头供货商功能需求分析用户端功能房东端功能管理员端功能技术实现要点扩展功能建议项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能需求分析 民宿…...

3步轻松下载B站视频:BilibiliDown图形化下载器完整指南
3步轻松下载B站视频:BilibiliDown图形化下载器完整指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/…...
)
2269 上市公司智慧供应链对数字创新的平均处理效应指标【ATT】(2000-2024)
数据来源上市公司年报时间跨度2000-2024区域跨度全国所有上市公司数据格式数据格式为Excel形式数据简介本数据集旨在全面测度中国上市公司智慧供应链建设的政策冲击效应,涵盖了2000年至2024年A股上市公司的长周期面板数据。作为研究数字经济与实体经济深度融合的关键…...

Z-Image-Turbo模型在智能车领域的应用:仿真场景图像生成
Z-Image-Turbo模型在智能车领域的应用:仿真场景图像生成 最近和几个做自动驾驶算法的朋友聊天,他们都在为一个问题头疼:测试数据不够用。特别是那些罕见的极端场景,比如暴雨天、浓雾夜,或者刺眼的逆光路况,…...

从入门到精通解析Python Selenium如何模拟浏览器操作
Selenium是一款开源的自动化测试工具,核心优势在于能模拟真实用户操作浏览器(如点击、输入、滚动),并渲染动态加载的网页内容(解决Requests库无法爬取JS动态数据的问题)。 一、Selenium入门准备:…...

YOLO-v5实战:用预训练模型快速检测图片中的物体
YOLO-v5实战:用预训练模型快速检测图片中的物体 1. 引言:为什么选择YOLO-v5 在计算机视觉领域,物体检测是一项基础而重要的任务。YOLO(You Only Look Once)系列模型因其速度快、精度高的特点,成为工业界和…...

trae中安装mcp报Cannot find package/ERR_MODULE_NOT_FOUND问题
简介 我在trae中安装高德地图的mcp和其他的mcp报出了以下错误,以此记录并分享给大家。 新的改变 node:internal/modules/esm/resolve:204 const resolvedOption FSLegacyMainResolve(pkgPath, packageConfig.main, baseStringified); ^ Error: Cannot find pack…...

Graphormer部署指南:3.7GB纯Transformer图神经网络GPU快速启动
Graphormer部署指南:3.7GB纯Transformer图神经网络GPU快速启动 1. 项目概述 Graphormer是一种基于纯Transformer架构的图神经网络,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。这个3.7GB大小的模型在OGB、PCQM4M…...

Phi-3-mini-4k-instruct-gguf多场景落地:跨境电商多语言商品描述批量生成
Phi-3-mini-4k-instruct-gguf多场景落地:跨境电商多语言商品描述批量生成 1. 跨境电商的痛点与解决方案 跨境电商卖家每天面临的最大挑战之一,就是为同一款商品准备不同语言版本的描述。传统做法要么需要雇佣多语种文案人员,要么使用机械的…...

最后的GIL堡垒正在崩塌:现在不掌握这6种无锁Python并发安全范式,你的微服务将在Q3大规模core dump
第一章:GIL消亡史与无锁Python并发的必然性Python 的全局解释器锁(GIL)自1991年诞生起,便成为 CPython 解释器中一道不可逾越的并发屏障。它确保同一时刻仅有一个线程执行 Python 字节码,虽简化了内存管理与引用计数实…...