SQLAlchemy 封装的工具类,数据库pgsql(数据库连接池)
1.SQLAlchemy是什么?
SQLAlchemy 是 Python 著名的 ORM 工具包。通过 ORM,开发者可以用面向对象的方式来操作数据库,不再需要编写 SQL 语句。
SQLAlchemy 支持多种数据库,除 sqlite 外,其它数据库需要安装第三方驱动。
1.1组成部分:
Engine, 框架引擎
Connect Pooling 数据库连接池
Dialect ,选择连接数据库DB API种类
Schema/Types , 架构和类型
SQL Expression Language: SQL表达式
1.2 SQLAlchemy 不能创建数据库,可以建表,创建字段
创建engine对象:dialect+driver://username:password@host:port/database
# 使用pymysql驱动连接到mysql
engine = create_engine('mysql+pymysql://user:pwd@localhost/testdb')
# 使用pymssql驱动连接到sql server
engine = create_engine('mssql+pymssql://user:pwd@localhost:1433/testdb')
1.3 filter 和 filter_by 区别:
1.filter用类名.属性名,比较用==,filter_by()直接用属性名,比较用=, filter_by() 只接受键值对参 数,所以 filter_by() 不支持><(大于和小于)和 and_、or_查询。
2.filter不支持组合查询,只能连续调用filter来变相实现。
3. filter传的是表达式,filter_by传的是参数
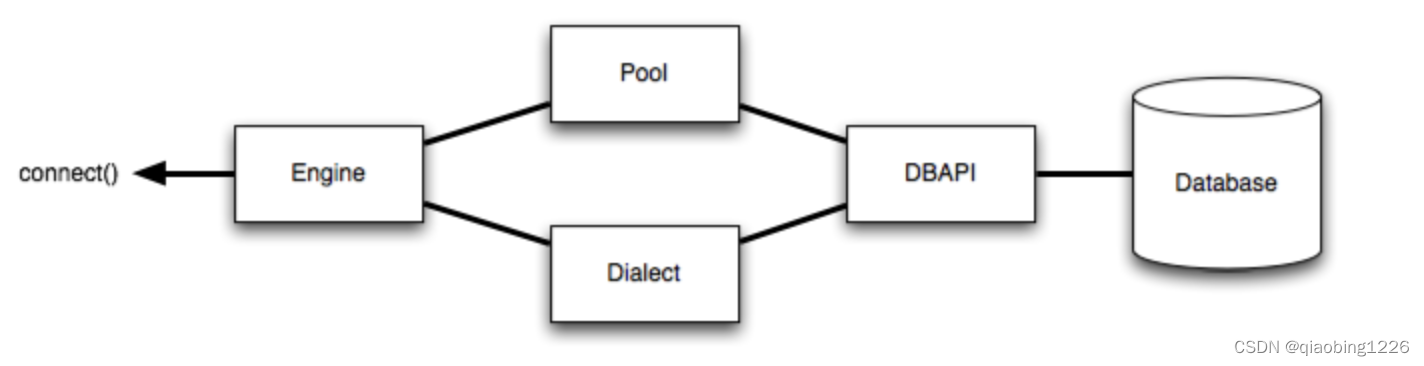
2. 使用数据库连接池说明
Engine 对象是使用 sqlalchemy 的起点,Engine 包括数据库连接池 (Pool) 和 方言 (Dialect,指不同数据库 sql 语句等的语法差异),两者一起把对数据库的操作,以符合 DBAPI 规范的方式与数据库交互。
3.工具类展示
3.1 数据库配置类:db_config.py
# dev环境配置
host = "dev-pg.test.xxxx.cloud"
port = 1921
user = "check"
database = "checkn"
password = "Ku2221AP123aXsNW"
# 连接池大小,默认为5,设置为0时表示连接无限制
pool_size = 10
# 连接池中最大连接数,如果访问数据库的请求数超过了pool_size,连接池将会自动创建新的连接,
# 直到创建达到max_overflow个连接为止。默认情况下,max_overflow值为10
max_overflow = 20
# 连接池中获取连接的等待时间,超过该等待时间后,获取连接方法将会超时,引发连接失败异常。默认情况下,timeout为30秒。
pool_timeout = 60
3.2 数据库类封装:database.py
# !/usr/bin/python
# -*- coding: UTF-8 -*-from sqlalchemy import *
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import Session
from sqlalchemy.ext.declarative import declarative_baseimport db_configclass dbTools(object):session = None;isClosed = True;def open(self, host=db_config.host, port=db_config.port, db=db_config.database, user=db_config.user,pwd=db_config.password, pool_size=db_config.pool_size, max_overflow=db_config.max_overflow,pool_timeout=db_config.pool_timeout):url = 'postgresql://%s:%s@%s:%d/%s' % (user, pwd, host, port, db)# echo: 设置为ture时,会将orm语句转化成sql语句并打印出来,一般debug时候使用engine = create_engine(url, poolclass=QueuePool, pool_size=pool_size, max_overflow=max_overflow,pool_timeout=pool_timeout, echo=True)DbSession = sessionmaker(bind=engine)self.session = DbSession()self.isClosed = Falsereturn self.sessiondef query(self, type):query = self.session.query(type)return querydef execute(self, sql):return self.session.execute(sql)def add(self, item):self.session.add(item)def add_all(self, items):self.session.add_all(items)def delete(self, item):self.session.delete(item)def commit(self):self.session.commit()def close(self):if self.isClosed:passself.session.close()self.isClosed = True
3.3 模型类 modeBatchInfo.py
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import String, Column, Integer, DateTime, Enum, Table, ForeignKey, Text
from sqlalchemy.orm import relationship# 创建Base类
Base = declarative_base()# 创建ORM模型类
class icsBatchInfo(Base):__tablename__ = 'ics_batch_info'batch_id = Column(Integer, primary_key=True)process_id = Column(String)task_id = Column(String)data_path = Column(Text)project_id = Column(String)user_name = Column(String)user_type = Column(String)status = Column(String)start_time = Column(DateTime)end_time = Column(DateTime)confidence_code = Column(String)repair_code = Column(String)report_count = Column(Integer)task_scope = Column(Text)adcity_code = Column(String)progress = Column(String)task_type = Column(String)job_id = Column(String)
3.4 开始使用工具类:main.py
# coding=utf-8
from database import dbTools
from modelBatchInfo import icsBatchInfo
from sqlalchemy import textif __name__ == "__main__":dbtools = dbTools()dbtools.open()# 打开一个文件with open('task.txt') as fr:# 读取文件所有行lines = fr.readlines()lines = [i.rstrip() for i in lines]list = []list.append("taskId,batchId\n")for taskId in lines:# 1. 使用对象查询# result = dbtools.query(icsBatchInfo).filter_by(task_id=taskId).all()# result = dbtools.query(icsBatchInfo).filter(icsBatchInfo.task_id == taskId).all()# nodes = dbtools.filter(icsBatchInfo.py.master == False).all()# 2. 使用sql查询sql = text("select * from ics_batch_info where batch_id=(select MAX(batch_id) from ics_batch_info WHERE task_id = '{taskId}')".format(taskId=taskId))result = dbtools.execute(sql)for batchInfo in result:list.append(batchInfo.task_id + "," + str(batchInfo.batch_id) + "\n")dbtools.close()list[len(list) - 1] = list[len(list) - 1].rstrip();with open("最大批次查询结果.csv", 'w') as fw:fw.writelines(list)print("☺☺☺执行完毕☺☺☺")
说明:
读取本目录下task.txt 中的任务号,去查数据库记录,并将需求查出来的内容写到本地csv文件"最大批次查询结果.csv" 文件。
上阶尽管费力,却一步比一步高。不经过琢磨,宝石也不会发光
相关文章:
SQLAlchemy 封装的工具类,数据库pgsql(数据库连接池)
1.SQLAlchemy是什么? SQLAlchemy 是 Python 著名的 ORM 工具包。通过 ORM,开发者可以用面向对象的方式来操作数据库,不再需要编写 SQL 语句。 SQLAlchemy 支持多种数据库,除 sqlite 外,其它数据库需要安装第三方驱动。…...

【Git】Git 基础
Git 基础 参考 Git 中文文档 — https://git-scm.com/book/zh/v2 1.介绍 Git 是目前世界上最先进的分布式版本控制系统,有这么几个特点: 分布式:是用来保存工程源代码历史状态的命令行工具保存点:保存点可以追溯源码中的文件…...

腾讯云AI绘画:探究AI创意与技术的新边界
目录 一、2023的“网红词汇”——AI绘画二、智能文生图1、智能文生图的应用场景2、风格和配置的多样性3、输入一段话,腾讯云AI绘画给你生成一张图4、文本描述生成图像,惊艳全场 三、智能图生图:重新定义图像美学1、智能图生图的多元应用场景2…...

离线数仓同步数据1
用户行为表数据同步 2.1.4 日志消费Flume测试 [gpbhadoop104 ~]$ cd /opt/module/flume/ [gpbhadoop104 flume]$ cd job/ [gpbhadoop104 job]$ rm file_to_kafka.confcom.atguigu.gmall.flume.interceptor.TimestampInterceptor$Builder #定义组件 a1.sourcesr1 a1.channelsc1…...

c语言开篇---跟着视频学C语言
标识符 标识符必须声明定义,可以是变量、函数或其他实体。 Int是标识符吗? 不是,int是c语言关键词,不是随意命名的 C语言关键词如下: 常量 不需要被声明,不能赋值更改。 printf函数 printf是由print打印…...

本地yum源-如学
学不学? 如学~ 到底学不学? 如学~ 学? 如学~ 配置本地的镜像yum 使用到的 rpm 包 是根据centos8 里面自带的 在 /dev/cdrom 中包含着 一些系统自带的 rpm # 先将 /dev/cdrom 设备进行挂载 mkdir /up # 在…...
【实训】“宅急送”订餐管理系统(程序设计综合能力实训)
👀樊梓慕:个人主页 🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》 🌝每一个不曾起舞的日子,都是对生命的辜负 前言 大一小学期,我迎来了人生中的第一次实训…...

openeuler上安装polarismesh集群
1、安装MySQL数据库 数据库连接地址10.10.10.168 用户root 密码123456 MySQL安装参考搭建DSS环境(六)之安装基础环境MySQL_linux安装dss_青春不流名的博客-CSDN博客 2、安装Redis集群 IPResid PORTSentinel PORTPASSWORDCluster NAME10.10.10.110637…...

Java基础——stream
流 stream是什么?stream优点stream和集合的区别stream的创建steam的操作从steam中取值 stream是什么? stream可以简化对集合的操作,具体操作由流内部实现,而无需用户自行实现过程 stream优点 对于以下ArrayList List<Strin…...

Spring Quartz 持久化解决方案
Quartz是实现了序列化接口的,包括接口,所以可以使用标准方式序列化到数据库。 而Spring2.5.6在集成Quartz时却未能考虑持久化问题。 Spring对JobDetail进行了封装,却未实现序列化接口,所以持久化的时候会产生NotSerializable问题&…...
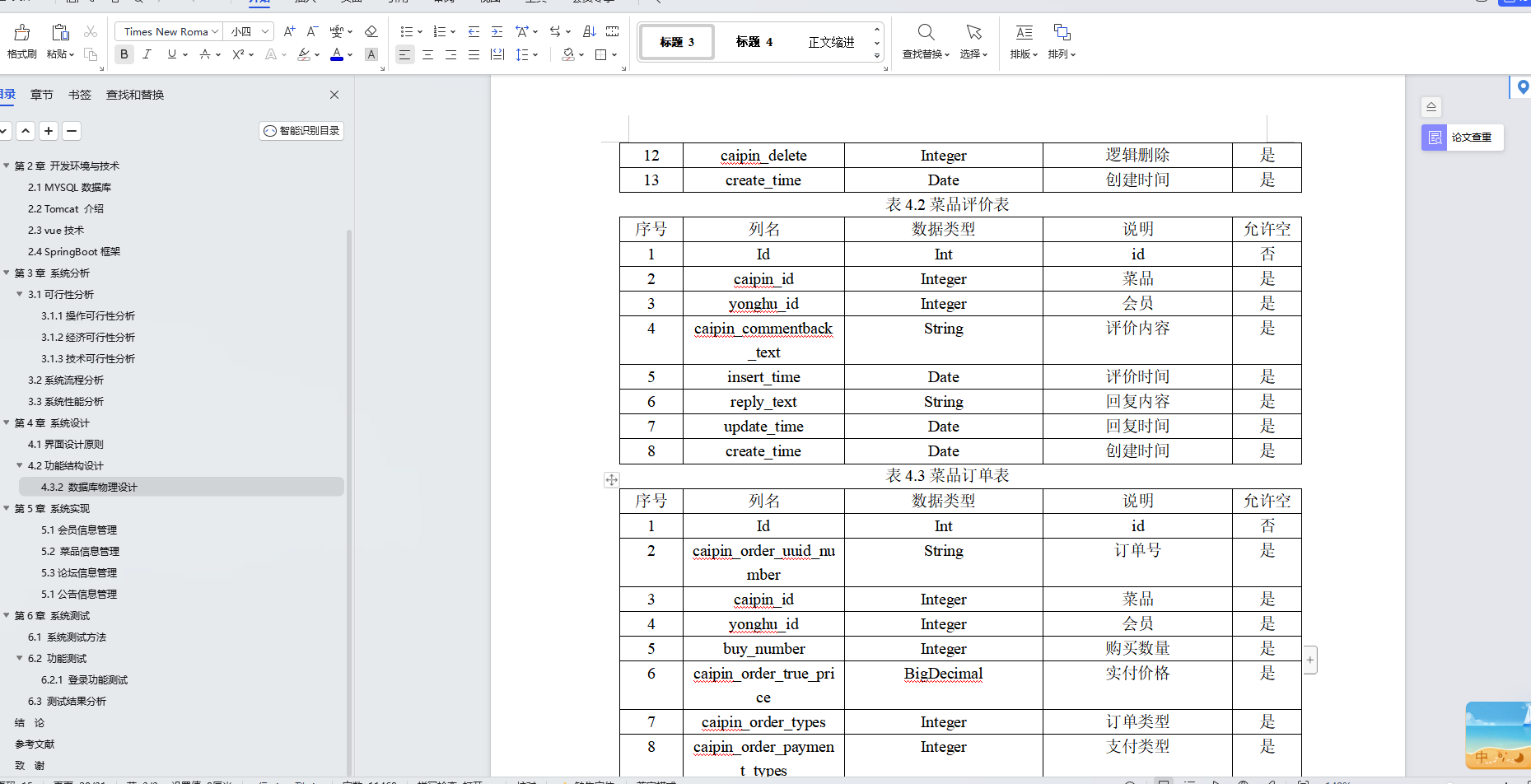
基于Java+SpringBoot+Vue前后端分离火锅店管理系统设计和实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...
Unity——导航系统补充说明
一、导航系统补充说明 1、导航与动画 我们可以通过设置动画状态机的变量,让动画匹配由玩家直接控制的角色的移动。那么自动导航的角色如何与动画系统结合呢? 有两个常用的属性可以获得导航代理当前的状态: 一是agent.velocity,…...

nginx实现负载均衡load balance
目录 nginx实现负载均衡load balance相关算法负载均衡https的访问后端的real server是否知道真正访问的用户的IP地址健康检查提升负载均衡的并发数量七层负载均衡和四层负载均衡七层负载均衡四层负载均衡四层和七层的区别502错误 nginx实现负载均衡load balance 准备ÿ…...

淘宝订单接口:连接消费者与商家的桥梁
当我们谈论淘宝订单接口时,我们谈论的是淘宝网为卖家和买家提供的一个用于处理订单的核心系统。通过这个接口,卖家可以接收订单、处理订单状态,并更新买家和平台的状态信息;买家则可以实时追踪自己的订单状态,更好地掌…...

数据结构-第一期——数组(Python)
目录 00、前言: 01、一维数组 一维数组的定义和初始化 一维变长数组 一维正向遍历 一维反向遍历 一维数组的区间操作 竞赛小技巧:不用从a[0]开始,从a[1]开始 蓝桥杯真题练习1 读入一维数组 例题一 例题二 例题三 实战训…...
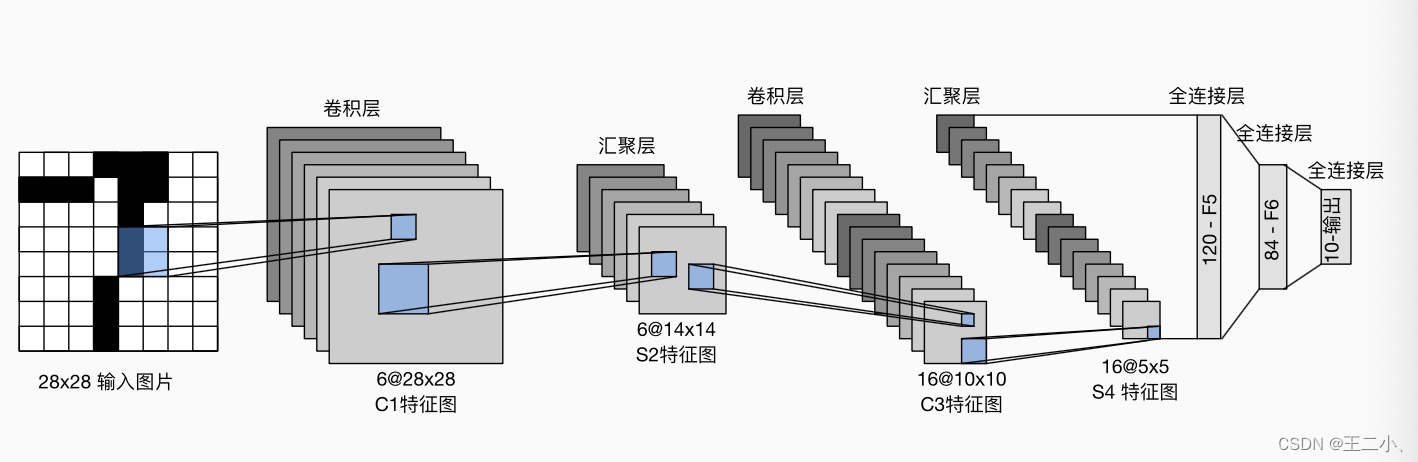
八 动手学深度学习v2 ——卷积神经网络之卷积+填充步幅+池化+LeNet
目录 1. 图像卷积总结2. 填充和步幅 padding和stride3. 多输入多输出通道4. 池化层5. LeNet 1. 图像卷积总结 二维卷积层的核心计算是二维互相关运算。最简单的形式是,对二维输入数据和卷积核执行互相关操作,然后添加一个偏置。核矩阵和偏移是可学习的参…...

SparkCore
第1章 RDD概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。 RDD类比工厂生产。 …...

配置 Windows 系统环境变量
直接按键盘上面的 WINS 打开 Windows 搜索 搜索“编辑系统环境变量” 也可以右键此电脑->属性->高级系统设置打开相同的界面 点击环境变量 一般添加就是添加在框出的 Path 里面,双击可以看到现有的环境变量并进行编辑 例如我在博客中写把 Java 的 jdk 解压好…...

【计算机视觉】图片文件格式的讲解
文章目录 一、图片的压缩二、计算机表示颜色三、JPG和PNG3.1 JPG3.2 PNG 一、图片的压缩 图片文件格式有可能会对图片的文件大小进行不同程度的压缩,图片的压缩分为有损压缩和无损压缩两种。 有损压缩。指在压缩文件大小的过程中,损失了一部分图片的信…...

2023最全的性能测试种类介绍,这6个种类特别重要!
系统的性能是一个很大的概念,覆盖面非常广泛,包括执行效率、资源占用、系统稳定性、安全性、兼容性、可靠性、可扩展性等,性能测试就是描述测试对象与性能相关的特征并对其进行评价而实施的一类测试。 性能测试是一个统称,它其实包…...

OTA电路仿真实战:用Virtuoso617分析频率响应与相位特性
OTA电路仿真实战:用Virtuoso617分析频率响应与相位特性 在模拟电路设计领域,运算跨导放大器(OTA)作为核心构建模块,其性能直接决定了整个系统的表现。本文将带您深入Virtuoso617的仿真世界,通过实战案例解…...

终极指南:掌握Starlight文档导航自定义排序的7个高级技巧
终极指南:掌握Starlight文档导航自定义排序的7个高级技巧 【免费下载链接】starlight 🌟 Build beautiful, accessible, high-performance documentation websites with Astro 项目地址: https://gitcode.com/gh_mirrors/st/starlight Starlight是…...

STM32C8T6最小系统板“隐形”电路详解:VBAT、BOOT、SWD那些容易忽略但关键的设计点
STM32C8T6最小系统板“隐形”电路详解:VBAT、BOOT、SWD那些容易忽略但关键的设计点 当你在深夜调试STM32最小系统板时,是否遇到过这些"玄学"问题:RTC时间莫名其妙丢失、SWD接口时好时坏、芯片突然"锁死"无法烧录…...
)
UniApp项目实战:用UTS插件实现安卓后台保活(附完整Service配置与权限处理)
UniApp安卓后台保活实战:UTS插件与Service优化全解析 在移动应用开发中,后台任务保活一直是开发者面临的棘手问题。想象一下:你的UniApp应用需要持续获取用户位置、实时推送消息或播放音乐,却频繁被系统清理,用户体验直…...
)
IntelliJ插件开发实战:5分钟搞定Action类库配置(附完整代码示例)
IntelliJ插件开发实战:5分钟搞定Action类库配置(附完整代码示例) 如果你刚接触IntelliJ插件开发,可能会被各种概念和配置搞得晕头转向。Action作为插件开发中最基础也最核心的组件之一,掌握它的使用方法是开发交互式功…...

颠覆传统数学输入:MathLive交互式公式编辑器三步实现跨平台数学表达
颠覆传统数学输入:MathLive交互式公式编辑器三步实现跨平台数学表达 【免费下载链接】mathlive A web component for easy math input 项目地址: https://gitcode.com/gh_mirrors/ma/mathlive 在数字化教育与科研领域,数学公式的编辑始终是制约效…...

从零到一:UniApp前端网页托管与自定义域名配置实战指南
1. 从零开始:UniApp前端网页托管全流程解析 第一次接触UniApp前端网页托管时,我也被各种专业术语搞得晕头转向。经过几个项目的实战,我发现这套流程其实就像租房子:你得先有个门牌号(域名),再找…...
)
Minikube国内环境配置全攻略:从安装到Dashboard镜像加速(含阿里云镜像源)
Minikube国内环境高效配置指南:从零搭建到Dashboard可视化 对于国内开发者而言,在本地环境中快速搭建Kubernetes学习平台往往面临镜像拉取缓慢甚至失败的困扰。本文将系统性地介绍如何利用Minikube在国内网络环境下构建稳定的单机Kubernetes环境…...
结合:多模态理解新思路)
vLLM-v0.17.1与卷积神经网络(CNN)结合:多模态理解新思路
vLLM-v0.17.1与卷积神经网络(CNN)结合:多模态理解新思路 1. 多模态AI的行业痛点与解决方案 计算机视觉和自然语言处理长期作为AI两大独立分支发展,但在实际业务场景中,图像与文本的协同理解需求日益凸显。传统方案通…...
非常详细收藏我这一篇就够了!大模型教程)
大模型入门学习教程(非常详细)非常详细收藏我这一篇就够了!大模型教程
本文系统介绍了LLM(大型语言模型)的基础知识,包括机器学习的数学基础、Python编程及其在数据科学中的应用、神经网络原理等。文章深入剖析了LLM科学家和工程师的角色,涵盖了大型语言模型架构、指令数据集构建、预训练模型、监督微…...