Transformer(一)—— Attention Batch Normalization
Transformer详解
- 一、RNN循环神经网络
- 二、seq2seq模型
- 三、Attention(注意力机制)
- 四、Transformer
- 4.1 self attention
- 4.2 self-attention的变形——Multi-head Self-attention
- 4.3 Masked Attention
- 4.4 Positional Encoding
- 4.5 Batch Normalization
- 4.6 Layer Normalization
- 4.7 Transformer LN改进方法:Pre-LN
- 五、参考
一、RNN循环神经网络
为了区分不同语境,我们需要神经网络拥有记忆功能。
对于一个文本的每一个词可以看做是一个时序。RNN的每一个时序是一个前馈神经网络,但是为了在每一个时刻都包含前边时序的信息,所以RNN的每个时序共享了隐藏层,即当前时刻的输入不仅包含了当前时刻的词,还包含了前一时刻的隐藏层的输出。
二、seq2seq模型
刚才的例子其实是N对N的循环神经网络,即我的输入序列长度是N,输出也是对应的N长度的序列。其实循环神经网络还有其他的比如:1对N、N对1。
但很多时候我们会遇到输入序列和输出序列不等长的例子但又不是1对N和N对1,如机器翻译,智能问答,源语言和目标语言的句子往往并没有相同的长度。为此我们引出RNN最重要的一个变种:N vs M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。
Encoder-Decoder框架在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子的语义编码C都是一样的,没有任何区别。而语义编码C是由原句子中的每个单词经过Encoder编码产生的,这意味着原句子中任意单词对生成某个目标单词来说影响力都是相同的,这就是模型没有体现出注意力的缘由。
三、Attention(注意力机制)
图片展示的Encoder-Decoder框架是没有体现“注意力模型”的,所以可以把它看做是注意力不集中分心模型。因为在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子的语义编码C都是一样的,没有任何区别。而语义编码C是由原句子中的每个单词经过Encoder编码产生的,这意味着原句子中任意单词对生成某个目标单词来说影响力都是相同的,这就是模型没有体现出注意力的缘由。
对不同的模块翻译,给予不同的权重
四、Transformer
目前,在NLP领域当中,主要存在三种特征处理器——CNN、RNN以及Transformer,当前Transformer的流行程度已经大过CNN和RNN,它抛弃了传统CNN和RNN神经网络,整个网络结构完全由Attention机制以及前馈神经网络组成。
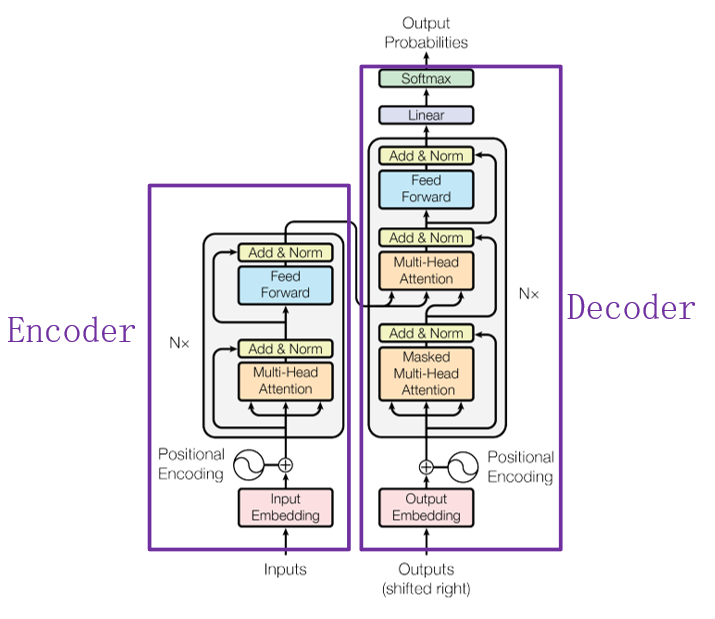
上图中的Transformer可以说是一个使用“self attention”的Seq2seq模型。
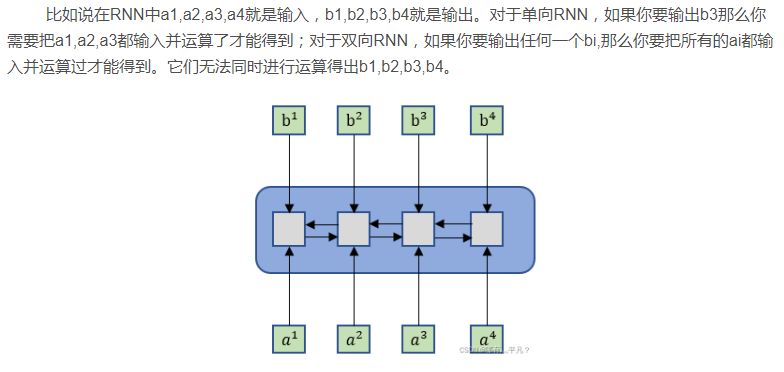
如果给出一个Sequence要处理,最常想到的可能就是RNN了,如下图1所示。RNN被经常使用在输入是有序列信息的模型中,但它也存在一个问题——它不容易被“平行化”。那么“平行化”是什么呢?
4.1 self attention
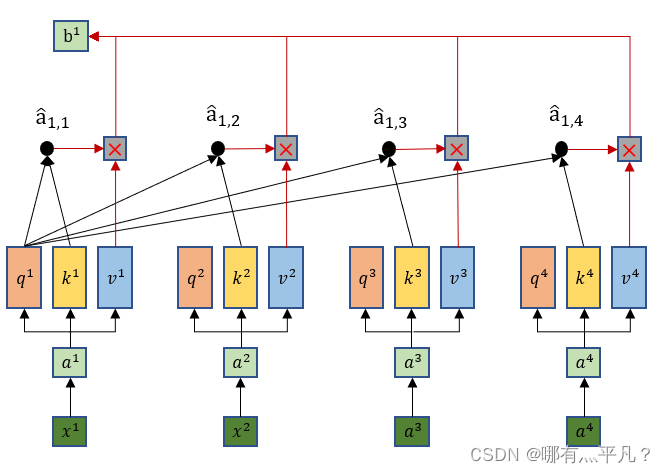
这里就可以看出输出b1是综合了所有的输入xi信息,同时这样做的优势在于——当b1只需要考虑局部信息的时候(比如重点关注x1,x2就行了),那么它可以让 输出的值为0就行了。
输出的值为0就行了。
4.2 self-attention的变形——Multi-head Self-attention
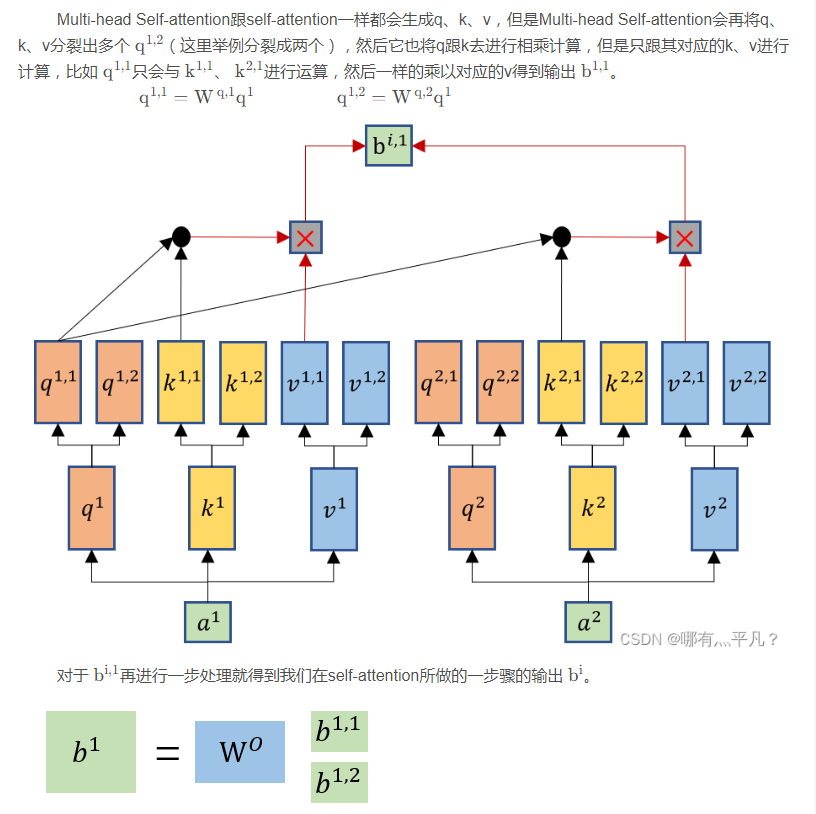
那么这个Multi-head Self-attention设置多个q,k,v有什么好处呢?
举例来说,有可能不同的head关注的点不一样,有一些head可能只关注局部的信息,有一些head可能想要关注全局的信息,有了多头注意里机制后,每个head可以各司其职去做自己想做的事情。
将每个head上的attention score分数打出,可以具象化地感受每个head的关注点,以入句子"The animal didn’t cross the streest because it was too tired"为例,可视化代码可点此

上图,颜色越深表示attention score越大,我们构造并连接五层的attention模块,可以发现it和animal,street关系密切。
现在我们把8个头全部加上去,见下图,一种颜色表示一个头下attention score的分数,可以看出,不同的头所关注的点各不相同。

4.3 Masked Attention
有时候,我们并不想在做attention的时候,让一个token看到整个序列,我们只想让它看见它左边的序列,而要把右边的序列遮蔽(Mask)起来。例如在transformer的decoder层中,我们就用到了masked attention,这样的操作可以理解为模型为了防止decoder在解码encoder层输出时“作弊”,提前看到了剩下的答案,因此需要强迫模型根据输入序列左边的结果进行attention。
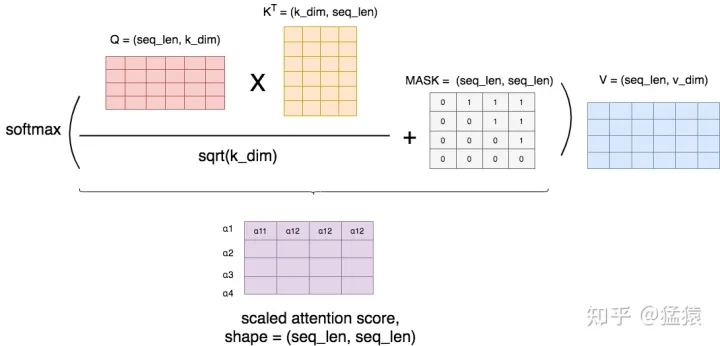
首先,我们按照前文所说,正常算attention score,然后我们用一个MASK矩阵去处理它(这里的+号并不是表示相加,只是表示提供了位置覆盖的信息)。在MASK矩阵标1的地方,也就是需要遮蔽的地方,我们把原来的值替换为一个很小的值(比如-1e09),而在MASK矩阵标0的地方,我们保留原始的值。这样,在进softmax的时候,那些被替换的值由于太小,就可以自动忽略不计,从而起到遮蔽的效果。
举例来说明MASK矩阵的含义,每一行表示对应位置的token。例如在第一行第一个位置是0,其余位置是1,这表示第一个token在attention时,只看到它自己,它右边的tokens是看不到的。以此类推。
4.4 Positional Encoding
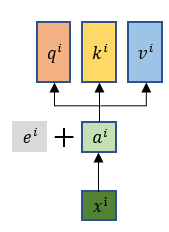
根据前面self-attention介绍中,我们可以知道其中的运算是没有去考虑位置信息,而我们希望是把输入序列每个元素的位置信息考虑进去,那么就要在 ai 这一步还有加上一个位置信息向量 e^i , 每个 e i都是其对应位置的独特向量。—— e i 是通过人工手设(不是学习出来的)。
Transformer 是以字作为输入,将字进行字嵌入之后,再与位置嵌入进行相加(不是拼接,就是单纯的对应位置上的数值进行加和)
为了使得位置嵌入和字嵌入能够相加,因此位置嵌入维度和字嵌入的维度必须相同,所以 i∈[0,d),因此就有 k∈[0,d−12]
需要使用位置嵌入的原因也很简单,因为 Transformer 摈弃了 RNN 的结构,因此需要一个东西来标记各个字之间的时序 or 位置关系,而这个东西,就是位置嵌入
4.5 Batch Normalization
- Internal Covariate Shift
在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化的这一过程被称作Internal Covariate Shift。

对于激活函数梯度饱和问题,有两种解决思路。第一种就是更为非饱和性激活函数,例如线性整流函数ReLU可以在一定程度上解决训练进入梯度饱和区的问题。另一种思路是,我们可以让激活函数的输入分布保持在一个稳定状态来尽可能避免它们陷入梯度饱和区,这也就是Normalization的思路。
- 我们如何减缓Internal Covariate Shift?
ICS产生的原因是由于参数更新带来的网络中每一层输入值分布的改变,并且随着网络层数的加深而变得更加严重,因此我们可以通过固定每一层网络输入值的分布来对减缓ICS问题。
-
Batch Normalization思路
我们解决了第一个问题,即用更加简化的方式来对数据进行规范化,使得第 l 层的输入每个特征的分布均值为0,方差为1。【但却导致了数据表达能力的缺失】

-
Batch Normalization的优势:
-
BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度
-
BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定
-
BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
-
BN具有一定的正则化效果

总的来说,BN通过将每一层网络的输入进行normalization,保证输入分布的均值与方差固定在一定范围内,减少了网络中的Internal Covariate Shift问题,并在一定程度上缓解了梯度消失,加速了模型收敛;并且BN使得网络对参数、激活函数更加具有鲁棒性,降低了神经网络模型训练和调参的复杂度;最后BN训练过程中由于使用mini-batch的mean/variance作为总体样本统计量估计,引入了随机噪声,在一定程度上对模型起到了正则化的效果。
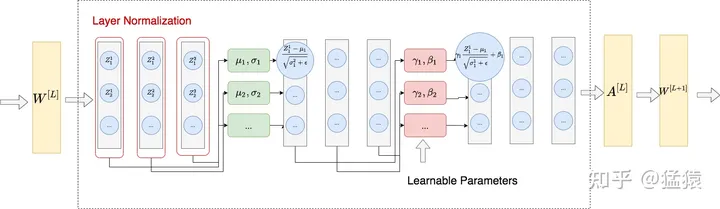
4.6 Layer Normalization
整体做法类似于BN,不同的是LN不是在特征间进行标准化操作(横向操作),而是在整条数据间进行标准化操作(纵向操作)
4.7 Transformer LN改进方法:Pre-LN
五、参考
- NLP中的RNN、Seq2Seq与attention注意力机制
- Transformer入门刨析详解
- Transformer学习笔记一:Positional Encoding(位置编码)
- Transformer 中的 Positional Encoding
- Transformer学习笔记二:Self-Attention(自注意力机制)
- Batch Normalization原理与实战
- Transformer学习笔记三:为什么Transformer要用LayerNorm/Batch Normalization & Layer Normalization (批量&层标准化)
相关文章:
Transformer(一)—— Attention Batch Normalization
Transformer详解 一、RNN循环神经网络二、seq2seq模型三、Attention(注意力机制)四、Transformer4.1 self attention4.2 self-attention的变形——Multi-head Self-attention4.3 Masked Attention4.4 Positional Encoding4.5 Batch Normalization4.6 Lay…...
2023高教社杯数学建模C题思路代码 - 蔬菜类商品的自动定价与补货决策
# 1 赛题 在生鲜商超中,一般蔬菜类商品的保鲜期都比较短,且品相随销售时间的增加而变差, 大部分品种如当日未售出,隔日就无法再售。因此, 商超通常会根据各商品的历史销售和需 求情况每天进行补货。 由于商超销售的蔬菜…...

【C++漂流记】一文搞懂类与对象的封装
本篇文章主要说明了类与对象中封装的有关知识,包括属性和行为作为整体、访问权限、class与struct的区别、成员属性的私有化,希望这篇文章可以帮助你更好的了解类与对象这方面的知识。 文章目录 一、属性和行为作为整体二、访问权限三、class与struct的区…...
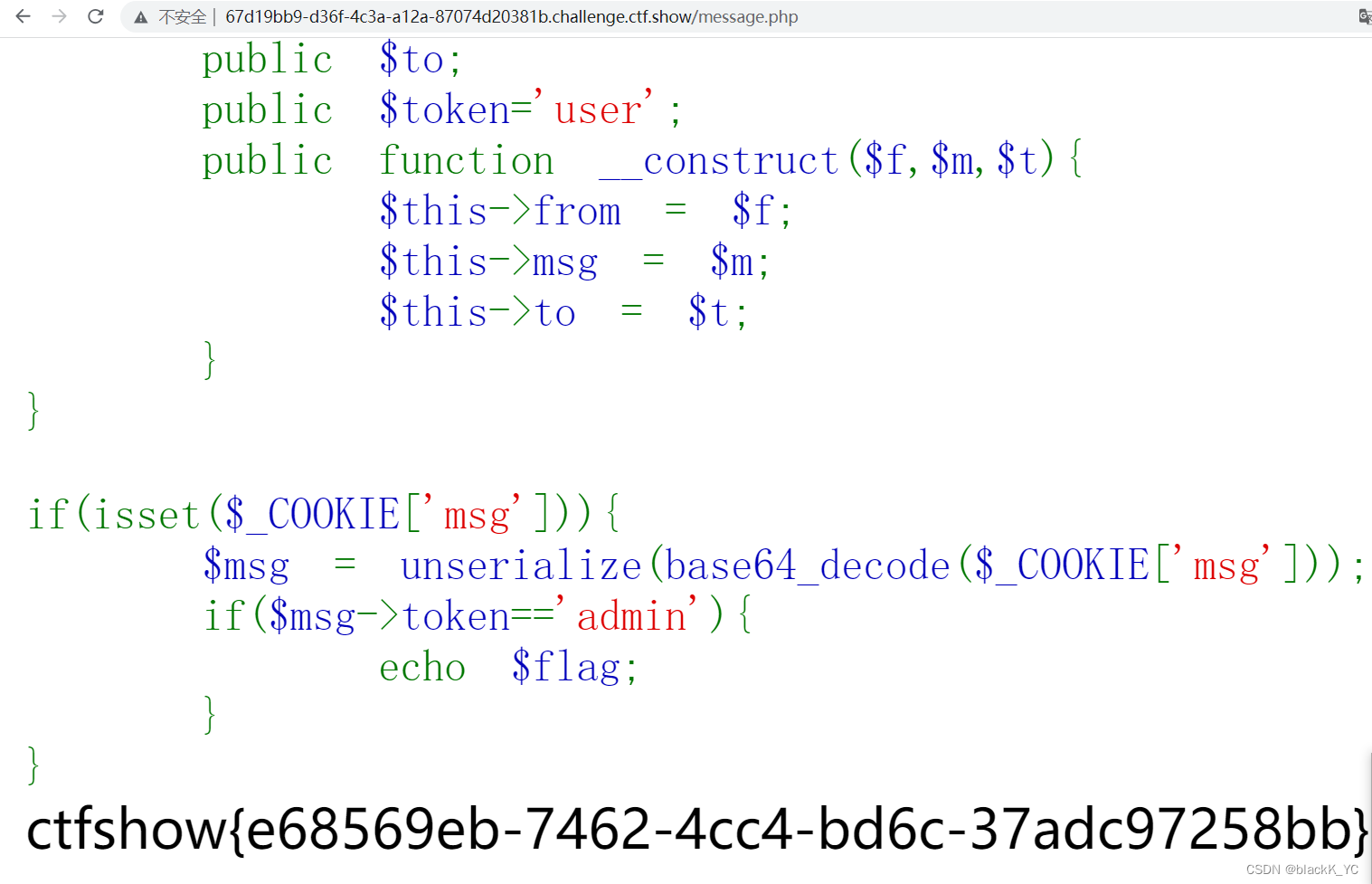
ctfshow 反序列化
PHP反序列化前置知识 序列化和反序列化 对象是不能在字节流中传输的,序列化就是把对象转化为字符串以便存储和传输,反序列化就是将字符串转化为对象 魔术方法 __construct() //构造,当对象new时调用 __wakeup() //执行unserialize()时&am…...

数据结构:线性表之-单向链表(无头)
目录 什么是单向链表 顺序表和链表的区别和联系 顺序表: 链表: 链表表示(单项)和实现 1.1 链表的概念及结构 1.2单链表(无头)的实现 所用文件 将有以下功能: 链表定义 创建新链表元素 尾插 头插 尾删 头删 查找-给一个节点的…...

为IT服务台构建自定义Zia操作
Zia是manageengine的商业人工智能助手,是ServiceDesk Plus Cloud的虚拟会话支持代理。使用Zia,您可以优化帮助台管理,还可以缩小最终用户与其帮助台之间的差距,Zia通过执行预配置的操作来帮助用户完成他们的服务台任务。 例如&…...
【C/C++】BMP格式32位转24位
问题 如题 解决方法 bmp文件格式参考:【C/C++】BITMAP格式分析_vc++ bitmap头文件_sunriver2000的博客-CSDN博客BITMAP文件大体上分成四个部分,如下表所示。文件部分长度(字节)位图文件头 Bitmap File Header14位图信息数据头 Bitmap Info Header40调色板 Palette4*n (n≥…...

合宙Air724UG LuatOS-Air LVGL API控件-滑动条 (Slider)
滑动条 (Slider) 滑动条看起来和进度条是有些是有些像,但不同的是滑动条可以进行数值选择。 示例代码 -- 回调函数 slider_event_cb function(obj, event)if event lvgl.EVENT_VALUE_CHANGED then local val (lvgl.slider_get_value(obj) or "0")..&…...
SQLAlchemy 封装的工具类,数据库pgsql(数据库连接池)
1.SQLAlchemy是什么? SQLAlchemy 是 Python 著名的 ORM 工具包。通过 ORM,开发者可以用面向对象的方式来操作数据库,不再需要编写 SQL 语句。 SQLAlchemy 支持多种数据库,除 sqlite 外,其它数据库需要安装第三方驱动。…...

【Git】Git 基础
Git 基础 参考 Git 中文文档 — https://git-scm.com/book/zh/v2 1.介绍 Git 是目前世界上最先进的分布式版本控制系统,有这么几个特点: 分布式:是用来保存工程源代码历史状态的命令行工具保存点:保存点可以追溯源码中的文件…...

腾讯云AI绘画:探究AI创意与技术的新边界
目录 一、2023的“网红词汇”——AI绘画二、智能文生图1、智能文生图的应用场景2、风格和配置的多样性3、输入一段话,腾讯云AI绘画给你生成一张图4、文本描述生成图像,惊艳全场 三、智能图生图:重新定义图像美学1、智能图生图的多元应用场景2…...

离线数仓同步数据1
用户行为表数据同步 2.1.4 日志消费Flume测试 [gpbhadoop104 ~]$ cd /opt/module/flume/ [gpbhadoop104 flume]$ cd job/ [gpbhadoop104 job]$ rm file_to_kafka.confcom.atguigu.gmall.flume.interceptor.TimestampInterceptor$Builder #定义组件 a1.sourcesr1 a1.channelsc1…...

c语言开篇---跟着视频学C语言
标识符 标识符必须声明定义,可以是变量、函数或其他实体。 Int是标识符吗? 不是,int是c语言关键词,不是随意命名的 C语言关键词如下: 常量 不需要被声明,不能赋值更改。 printf函数 printf是由print打印…...

本地yum源-如学
学不学? 如学~ 到底学不学? 如学~ 学? 如学~ 配置本地的镜像yum 使用到的 rpm 包 是根据centos8 里面自带的 在 /dev/cdrom 中包含着 一些系统自带的 rpm # 先将 /dev/cdrom 设备进行挂载 mkdir /up # 在…...
【实训】“宅急送”订餐管理系统(程序设计综合能力实训)
👀樊梓慕:个人主页 🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》 🌝每一个不曾起舞的日子,都是对生命的辜负 前言 大一小学期,我迎来了人生中的第一次实训…...

openeuler上安装polarismesh集群
1、安装MySQL数据库 数据库连接地址10.10.10.168 用户root 密码123456 MySQL安装参考搭建DSS环境(六)之安装基础环境MySQL_linux安装dss_青春不流名的博客-CSDN博客 2、安装Redis集群 IPResid PORTSentinel PORTPASSWORDCluster NAME10.10.10.110637…...

Java基础——stream
流 stream是什么?stream优点stream和集合的区别stream的创建steam的操作从steam中取值 stream是什么? stream可以简化对集合的操作,具体操作由流内部实现,而无需用户自行实现过程 stream优点 对于以下ArrayList List<Strin…...

Spring Quartz 持久化解决方案
Quartz是实现了序列化接口的,包括接口,所以可以使用标准方式序列化到数据库。 而Spring2.5.6在集成Quartz时却未能考虑持久化问题。 Spring对JobDetail进行了封装,却未实现序列化接口,所以持久化的时候会产生NotSerializable问题&…...
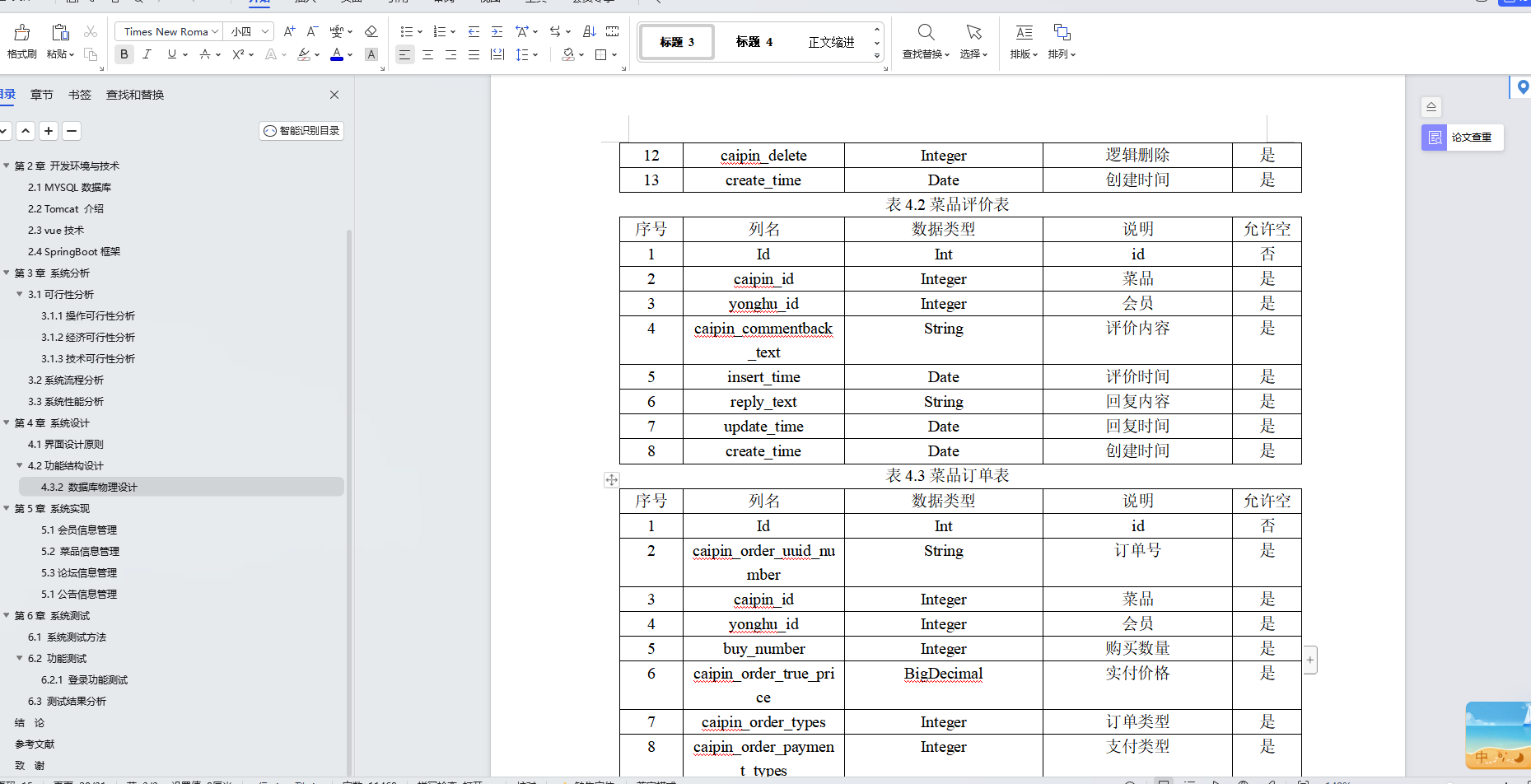
基于Java+SpringBoot+Vue前后端分离火锅店管理系统设计和实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...
Unity——导航系统补充说明
一、导航系统补充说明 1、导航与动画 我们可以通过设置动画状态机的变量,让动画匹配由玩家直接控制的角色的移动。那么自动导航的角色如何与动画系统结合呢? 有两个常用的属性可以获得导航代理当前的状态: 一是agent.velocity,…...

从‘下载失败弹个错’到‘优雅的用户体验’:前端文件下载错误处理与PDF预览的进阶实践
从‘下载失败弹个错’到‘优雅的用户体验’:前端文件下载错误处理与PDF预览的进阶实践 在当今的Web应用中,文件下载功能几乎是每个系统的标配。然而,很多开发者往往只关注功能的实现,而忽略了异常处理和用户体验的细节。当用户点…...

Downr1n iOS降级与越狱实战指南:从问题诊断到解决方案
Downr1n iOS降级与越狱实战指南:从问题诊断到解决方案 【免费下载链接】downr1n downgrade tethered checkm8 idevices ios 14, 15. 项目地址: https://gitcode.com/gh_mirrors/do/downr1n 一、决策指南:为什么选择Downr1n? 1.1 核心…...
Ollama一键部署translategemma-27b-it:图文翻译模型在国产统信UOS验证通过
Ollama一键部署translategemma-27b-it:图文翻译模型在国产统信UOS验证通过 1. 开篇:当翻译遇上图文对话 想象一下,你拿到一份产品说明书,上面有中文文字和复杂的图表。你需要把它翻译成英文,但传统的翻译工具只能处理…...

WaveTools鸣潮工具箱终极指南:画质优化与抽卡分析的完整解决方案
WaveTools鸣潮工具箱终极指南:画质优化与抽卡分析的完整解决方案 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools WaveTools鸣潮工具箱是一款专为《鸣潮》玩家设计的强大辅助工具,它…...

大气层系统全链路实战指南:从需求分析到风险控制的完整实施路径
大气层系统全链路实战指南:从需求分析到风险控制的完整实施路径 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 大气层系统(Atmosphere)作为Switch定制化…...

基于迁移学习的口罩检测模型优化
基于迁移学习的口罩检测模型优化 1. 引言 口罩检测作为计算机视觉领域的一个重要应用场景,在实际部署中常常面临数据量不足、训练成本高、模型泛化能力弱等问题。传统从零开始训练检测模型需要大量标注数据和计算资源,而迁移学习技术能够有效解决这些痛…...

丹青识画与Unity引擎结合:打造沉浸式虚拟博物馆体验
丹青识画与Unity引擎结合:打造沉浸式虚拟博物馆体验 想象一下,你漫步在一个精心构建的虚拟博物馆里,墙上挂着梵高的《星月夜》、达芬奇的《蒙娜丽莎》。你被一幅画深深吸引,举起手机(在虚拟世界里)&#x…...

Z-Image-GGUF在软件测试中的应用:自动化生成测试用例示意图
Z-Image-GGUF在软件测试中的应用:自动化生成测试用例示意图 你是不是也遇到过这样的场景?写测试用例文档时,为了描述一个复杂的用户操作流程,绞尽脑汁写了半天文字,结果评审时,开发同事还是没完全看懂&…...
)
别只盯着心跳了!CANopen主站用SDO还能配置这些关键参数(附PDO映射实例)
别只盯着心跳了!CANopen主站用SDO还能配置这些关键参数(附PDO映射实例) 在工业自动化领域,CANopen协议因其高可靠性和灵活性成为设备互联的首选方案之一。许多工程师对通过SDO(服务数据对象)配置心跳时间已…...

拓扑排序不止于理论:用邻接矩阵实现时,我踩过的3个坑和性能优化
拓扑排序实战:邻接矩阵实现中的性能陷阱与优化策略 邻接矩阵作为图论中最直观的存储结构,常被初学者用来实现拓扑排序算法。但当我们真正将其投入实际项目时,往往会遭遇意想不到的性能瓶颈和逻辑陷阱。本文将分享三个真实项目中踩过的坑&…...