0401hive入门-hadoop-大数据学习.md
文章目录
- 1 Hive概述
- 2 Hive部署
- 2.1 规划
- 2.2 安装软件
- 3 Hive体验
- 4 Hive客户端
- 4.1 HiveServer2 服务
- 4.2 DataGrip
- 5 问题集
- 5.1 Could not open client transport with JDBC Uri
- 结语
1 Hive概述
Apache Hive是一个开源的数据仓库查询和分析工具,最初由Facebook开发,并后来捐赠给Apache软件基金会。Hive允许用户使用SQL语言来查询和分析存储在Hadoop分布式文件系统(HDFS)中的大规模数据集。它的设计目标是使非技术用户能够轻松地在Hadoop集群上执行数据查询和分析任务,而无需编写复杂的MapReduce代码。
以下是Hive的主要特点和概述:
- SQL-Like查询语言: Hive提供了一种类似于SQL的查询语言,称为HiveQL(Hive Query Language),它允许用户使用熟悉的SQL语法来查询和操作数据。这使得数据库管理员和分析师能够更容易地利用Hadoop集群进行数据分析。
- 元数据存储: Hive维护了一个元数据存储,其中包含有关数据表、分区、列、数据类型和表之间关系的信息。这使得用户可以在不了解底层数据存储结构的情况下查询数据。
- 扩展性: Hive是高度可扩展的,可以处理大规模数据集。它允许用户将数据表分成分区,并支持分区级别的操作,从而提高了查询性能。
- UDF(用户定义函数): Hive允许用户编写自定义函数,以满足特定的数据处理需求。这些自定义函数可以使用Java或Python编写,并与HiveQL一起使用。
- 集成: Hive可以与其他Hadoop生态系统工具集成,如Hadoop MapReduce、Apache HBase、Apache Spark等。这意味着用户可以在不同的工具之间共享数据并执行复杂的数据处理任务。
- 可视化工具: 虽然Hive本身是一个命令行工具,但也有许多可视化工具和商业智能平台(如Tableau、QlikView)支持Hive,使用户能够使用图形界面进行数据分析和报告生成。
- 安全性: Hive提供了基于SQL标准的权限管理机制,以确保只有授权的用户可以访问和修改数据。
- 数据格式支持: Hive支持多种数据格式,包括文本、Parquet、ORC(Optimized Row Columnar)等,可以根据需求选择最适合的格式。
Hive通常用于数据仓库、数据分析、报告生成和数据ETL(抽取、转换、加载)等用例,特别是对于那些需要在Hadoop集群上处理大规模数据的组织。它提供了一种方便的方式来查询和分析分布式存储的数据,使更多的人能够从大数据中获得有价值的见解。
Apache Hive是一个开源的数据仓库查询和分析工具,最初由Facebook开发,并后来捐赠给Apache软件基金会。Hive允许用户使用SQL语言来查询和分析存储在Hadoop分布式文件系统(HDFS)中的大规模数据集。它的设计目标是使非技术用户能够轻松地在Hadoop集群上执行数据查询和分析任务,而无需编写复杂的MapReduce代码。
以下是Hive的主要特点和概述:
- SQL-Like查询语言: Hive提供了一种类似于SQL的查询语言,称为HiveQL(Hive Query Language),它允许用户使用熟悉的SQL语法来查询和操作数据。这使得数据库管理员和分析师能够更容易地利用Hadoop集群进行数据分析。
- 元数据存储: Hive维护了一个元数据存储,其中包含有关数据表、分区、列、数据类型和表之间关系的信息。这使得用户可以在不了解底层数据存储结构的情况下查询数据。
- 扩展性: Hive是高度可扩展的,可以处理大规模数据集。它允许用户将数据表分成分区,并支持分区级别的操作,从而提高了查询性能。
- UDF(用户定义函数): Hive允许用户编写自定义函数,以满足特定的数据处理需求。这些自定义函数可以使用Java或Python编写,并与HiveQL一起使用。
- 集成: Hive可以与其他Hadoop生态系统工具集成,如Hadoop MapReduce、Apache HBase、Apache Spark等。这意味着用户可以在不同的工具之间共享数据并执行复杂的数据处理任务。
- 可视化工具: 虽然Hive本身是一个命令行工具,但也有许多可视化工具和商业智能平台(如Tableau、QlikView)支持Hive,使用户能够使用图形界面进行数据分析和报告生成。
- 安全性: Hive提供了基于SQL标准的权限管理机制,以确保只有授权的用户可以访问和修改数据。
- 数据格式支持: Hive支持多种数据格式,包括文本、Parquet、ORC(Optimized Row Columnar)等,可以根据需求选择最适合的格式。
核心的功能:
- 元数据管理
- SQL解析
2 Hive部署
2.1 规划
Hive 是单机工具,只需要部署在一台服务器即可。
Hive 虽然是单机的,但是它可以提交分布式运行的
MapReduce 程序运行。
规划
我们知道 Hive 是单机工具后,就需要准备一台服务器供 Hive 使用即可。
同时 Hive 需要使用元数据服务,即需要提供一个关系型数据库,我们也选择一台服务器安装关系型数据库即可
| 机器 | 服务 |
|---|---|
| node1 | Hive |
| node1 | Mysql |
2.2 安装软件
步骤1:安装Mysql5.7
# 更新秘钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
# 安装mysql yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
# yum安装mysql
yum -y install mysql-community-server
# 启动mysql
systemctl start mysqld
# 设置msyql开机自启
systemctl enable mysqld
# 检查Mysql服务状态
systemctl status mysqld
# 第一次启动mysql会在日志文件中生成root用户的一个随机密码
cat /var/log/mysqld.log | grep "password"- 连接mysql 我们是做实验用,设置简单密码(生成中不要这样子搞)
set global validate_password_policy=LOW;
set global validate_password_length=4;
alter user 'root'@'localhost' identified by '123456';
grant all privileges on *.* to root@"%" identified by '123456' with grant option;
flush privileges;
步骤2:配置Hadoop
Hive的运行依赖Hadoop(HDFS、MapReduce、YARN都依赖),同时涉及到HDFS文件系统的访问,所有要配置Hadoop的代理用户,即设置Hadoop用户允许代理(模拟)其他用户。
配置如下内容在Hadoop的core-site.xml中,并分发到其他节点,且重启HDFS集群
<property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value>
</property>
步骤3:下载解压Hive
-
node1切换到hadoop用户
su - hadoop -
下载Hive安装包或者本地上传
http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz -
解压
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/ -
设置软连接
ln -s /export/server/apache-hive-3.1.3-bin.tar.gz /export/server/hive
步骤4:提供Mysql 驱动包
-
下载或者上传Mysql驱动包
https:// repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-5.1.34.jar -
将下载好的Mysql驱动包移入Hive安装目录下lib目录内
mv mysql-connector-java-5.1.34.jar /export/server/hive/lib/
步骤5:配置Hive
- 在 Hive 的 conf 目录内,新建 hive-env.sh 文件,填入以下环境变量内容:
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
-
在 Hive 的 conf 目录内,新建 hive-site.xml 文件,填入以下内容
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><property><name>hive.server2.thrift.bind.host</name><value>node1</value></property><property><name>hive.metastore.uris</name><value>thrift://node1:9083</value></property><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property> </configuration>- 现在使用的是5.1.34 Mysq驱动包,配置的连接驱动也是旧版废弃的
步骤6:初始化元数据库
-
在Mysql数据库中新建数据库:hive
create database hive charset utf8; -
执行元数据库初始化命令
cd /export/server/hive bin/schematool -initSchema -dbType mysql -verbos打印
Initialization script completed schemaTool completed初始化完成
步骤7:启动Hive
-
当前用户为hadoop
-
确保Hive文件夹所属为hadoop用户
-
创建hive日志文件夹
mkdir /export/server/hive/logs -
启动元数据管理服务
# 前台启动 bin/hive --service metastore # 后台启动 nohup bin/hive --service metastore >> logs/metastore.log 2>&1 & -
启动客户端,二选一(当前简单测试选择 Hive Shell)
-
Hive Shell方式:可以直接写SQL
/bin/hive -
Hive ThriftServer:不可以直接写SQL,需要外部客户端链接使用
bin/hive --service hiveserver2
-
3 Hive体验
首先确保启动了metastore服务,可以执行
bin/hive
进入hive shell环境中,可以执行SQL语句,如下图所示:

-
创建表
create table test(id int,name string,gender string); -
插入数据
insert into test values(1, '爱因斯坦', '男'),(2, '麦克斯韦', '男'),(3, '居里夫人', '女'); -
查询数据
select gender, count(*) cnt from test group by gender; -
验证Hive的数据存储:Hive的数据存储在HDFS的:
/user/hive/warehouse,如下图所示

- 验证SQL语句启动的MapReduce程序:打开YARN的WEB UI页面查看任务情况-
http://node1:8088,如下图所示

4 Hive客户端
4.1 HiveServer2 服务
在启动 Hive 的时候,除了必备的 Metastore 服务外,我们前面提过有 2 种方式使用 Hive :
• 方式 1 : bin/hive 即 Hive 的 Shell 客户端,可以直接写 SQL
• 方式 2 : bin/hive --service hiveserver2
后台执行脚本:
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
bin/hive --service metastore ,启动的是元数据管理服务
bin/hive --service hiveserver2 ,启动的是 HiveServer2 服务
HiveServer2 是 Hive 内置的一个 ThriftServer 服务,提供 Thrift 端口供其它客户端链接
可以连接 ThriftServer 的客户端有:
• Hive 内置的 beeline 客户端工具(命令行工具)
• 第三方的图形化 SQL 工具,如 DataGrip 、 DBeaver 、 Navicat 等
# 先启动 metastore 服务 然后启动 hiveserver2 服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
4.2 DataGrip
我们这里以DataGrip为例,其他客户端自行测试。
步骤1:创建工程文件夹
E:\gaogzhen\projects\bigdata\DataGripProjects\hive-demo
步骤2:DataGrip创建新工程并关联本地文件夹

步骤3:DataGrip连接Hive

1693897609904)
步骤4:配置Hive JDBC驱动

连接成功,如下图所示:

5 问题集
5.1 Could not open client transport with JDBC Uri
-
报错内容
Error: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=EXECUTE , inode="/tmp":hadoop:supergroup:drwx------ -
解决方案参考下面连接4,修改hdfs /tmp访问权限,前面我们配置了hadoop用户代理,不知道为啥没生效
结语
如果小伙伴什么问题或者指教,欢迎交流。
❓QQ:806797785
参考链接:
[1]大数据视频[CP/OL].2020-04-16.
[2]0102阿里云配置3台ECS服务器-大数据学习[CP/OL].
[3]0201hdfs集群部署-hadoop-大数据学习[CP/OL].
[4]beeline连接hive2报错Permission denied[CP/OL].
相关文章:
0401hive入门-hadoop-大数据学习.md
文章目录 1 Hive概述2 Hive部署2.1 规划2.2 安装软件 3 Hive体验4 Hive客户端4.1 HiveServer2 服务4.2 DataGrip 5 问题集5.1 Could not open client transport with JDBC Uri 结语 1 Hive概述 Apache Hive是一个开源的数据仓库查询和分析工具,最初由Facebook开发&…...

springboot项目打包优化,将所有第三方包单独打包至lib目录
在pom.xml中配置以下代码,随后使用mvnw clean package打包 <build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><!-- 主…...

使用 Ccrypt 在 Linux 中加密/解密文件
Ccrypt 是一个用于数据加密和解密的命令行工具。Ccrypt 基于 Rijndael 密码,与 AES 标准中使用的密码相同。另一方面,在 AES 标准中,使用 128 位块大小,而 ccrypt 使用 256 位块大小。Ccrypt 通常使用 .cpt 文件扩展名来表示加密文件。 它是一个轻量级的工具,该工具的安装…...

poi3.10 excel xls 设置列宽行高背景色加粗
poi excel xls格式 设置列宽行高背景色加粗HSSFWorkbook wb new HSSFWorkbook(); Sheet sheet wb.createSheet("sheet1");HSSFCellStyle style wb.createCellStyle(); style.setFillForegroundColor(IndexedColors.LIGHT_TURQUOISE.getIndex());//背景色 style.se…...

揭秘分布式文件系统大规模元数据管理机制——以Alluxio文件系统为例
作者简介: 辭七七,目前大,正在学习C/C,Java,Python等 作者主页: 七七的个人主页 文章收录专栏: 七七的闲谈 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖Ὁ…...

微信小程序onReachBottom事件使用
在微信小程序中,onReachBottom事件用于监听页面滚动到页面底部的时候触发的事件。当用户滑动页面到底部时,可以通过监听该事件来执行相应的操作。 要使用onReachBottom事件,需要在对应的页面或组件中定义一个函数,并在Page或Comp…...

数据孤岛的突破口在哪里?
国务院于2021年12月发布的《“十四五”数字经济发展规划》中提到,我国数字经济发展中数字鸿沟问题未得到有效解决,各行业应充分发挥数据要素作用,加强数据治理和监管工作。“数据孤岛”问题虽早已被提出,但至今仍然存在࿰…...

【送书活动】全网超50万粉丝的Linux大咖良许,出书了!
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...
深入浅出学Verilog--基础语法
1、简介 Verilog的语法和C语言非常类似,相对来说还是非常好学的。和C语言一样,Verilog语句也是由一连串的令牌(Token)组成。1个令牌必须由1个或1个以上的字符(character)组成,令牌可以是&#x…...

基于Spring、SpringMVC、Mybatis的超市管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于SSM的超市订单管理系统,java项目。 …...

spring中的@Configuration配置类和@Component
在Spring的开发工作中,基本都会使用配置注解,尤其以Component及Configuration为主,当然在Spring中还可以使用其他的注解来标注一个类为配置类,这是广义上的配置类概念,但是这里我们只讨论Component和Configuration&…...
企业架构LNMP学习笔记29
Nginx负载均衡配置: 架构分析: 1)用户访问请求Nginx负载均衡服务器; 2)Nginx负载均衡服务器再分发请求到Web服务器。 实际配置负载均衡,只需修改作为负载均衡服务器的Nginx即可,当前架构中的…...

Ubuntu14.04离线安装gcc-5.3.0
离线安装gcc 下载gcc安装包下载相关依赖下载gmp下载mpfr下载mpc 编译、安装gcc配置环境变量 拉取的一个虚拟机使用的系统是Ubuntu14.04,gcc版本是4.8.4,由于gcc版本较低,不太支持Libtorch,于是搜寻了许多办法来解决这个问题&#…...
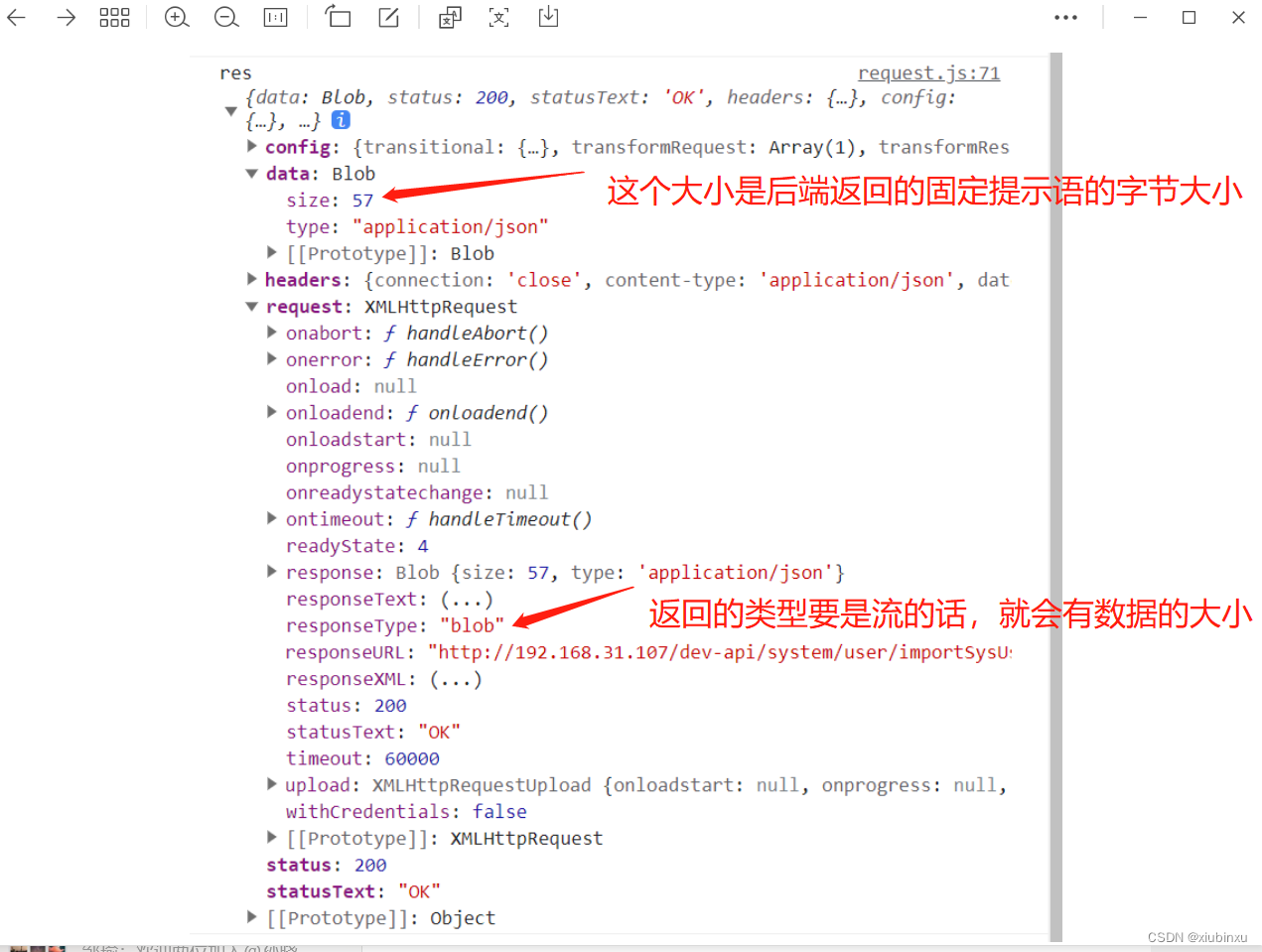
axios返回几种数据格式? 其中Blob返回时的size是什么意思?
axios返回几种数据格式? 其中Blob返回时的size是什么意思? 1、字符串(String):服务器可以返回纯文本或HTML内容,Axios会将其作为字符串返回。 2、JSON(JavaScript Object Notation)ÿ…...
【GO语言基础】基本数据类型
系列文章目录 【Go语言学习】ide安装与配置 【GO语言基础】前言 【GO语言基础】变量常量 【GO语言基础】数据类型 文章目录 系列文章目录数据类型数值型:整数类型:浮点数类型: 字符型-布尔型-字符串零值转义字符 常用类型转换运算符总结 数据…...

【Python】OpenCV立体相机配准与三角化代码实现
下面的介绍了使用python和OpenCV对两个相机进行标定、配准,同时实现人体关键点三角化的过程 import cv2 as cv import glob import numpy as np import matplotlib.pyplot as pltdef calibrate_camera(images_folder):images_names = glob.glob(images_folder...

通过Idea或命令将本地项目上传至git
通过Idea或命令将本地项目上传至git 一、Git创建仓库 1、登录Gitee账号,点击新建 2、填写如下相关信息,点击创建 3、在此处可以复制项目链接 二、Idea配置和解绑git,提交项目 1、idea打开项目,操作如下 2、在弹框里选择…...

python selenium 爬虫教程
Python和Selenium是很强大的爬虫工具,可以用于自动化地模拟浏览器行为,从网页中提取数据。下面是一个简单的使用Python和Selenium进行爬虫的案例。 入门: 1. 安装和配置: 首先,你需要安装Python和Selenium。可以使用…...

Linux基础知识及常见指令
Linux简介及相关概念 什么是Linux? Linux是一个免费开源的操作系统内核,最初由Linus Torvalds于1991年创建。它是各种Linux发行版(通常称为“发行版”)的核心组件,这些发行版是完整的操作系统,包括Linux内…...

分享一个基于Python和Django的产品销售收入数据分析系统源码
💕💕作者:计算机源码社 💕💕个人简介:本人七年开发经验,擅长Java、Python、PHP、.NET、微信小程序、爬虫、大数据等,大家有这一块的问题可以一起交流! 💕&…...

CircuitPython内存优化:冻结模块原理与嵌入式开发实践
1. 项目概述:当微控制器项目撞上内存墙在嵌入式开发的世界里,尤其是玩转像Adafruit Circuit Playground Express这类资源受限的微控制器时,我们常常会与一个无形的“天花板”迎头相撞——内存限制。你可能正兴致勃勃地为你的智能徽章或互动艺…...

揭秘AMD处理器底层控制:Ryzen SDT调试工具从入门到精通
揭秘AMD处理器底层控制:Ryzen SDT调试工具从入门到精通 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://g…...

Allegro铺铜避坑指南:从十字花焊盘到孤铜删除,新手必知的10个实用技巧
Allegro铺铜避坑指南:从十字花焊盘到孤铜删除,新手必知的10个实用技巧 第一次在Allegro中铺铜时,那种手足无措的感觉我至今记忆犹新。面对密密麻麻的参数选项和看似简单的操作背后隐藏的各种"坑",即使是完成了布局布线的…...

在 Taotoken 上观测多模型 API 调用用量与成本明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Taotoken 上观测多模型 API 调用用量与成本明细 对于使用多个大模型 API 的开发者而言,清晰、透明地掌握调用情况和…...

基于Argo Tunnel的轻量级容器PaaS部署实践
1. 项目概述与核心价值最近在折腾容器化部署和边缘计算场景时,我一直在寻找一个足够轻量、灵活且能快速拉起服务的方案。传统的Kubernetes集群对于小型项目或个人开发者来说,学习成本和运维负担都太重了,而单纯的Docker Compose又缺乏服务发现…...

品牌如何通过AI搜索优化构建长期影响力?GEO战略资产打造可持续竞争壁垒
摘要品牌通过AI搜索优化(GEO)构建长期影响力与权威认知,关键在于将其从短期获客技术升级为沉淀知识、构建AI信任机制的战略资产。核心路径是持续向AI模型提供高质量、结构化的品牌知识,使其成为AI的“可信信源”,并主动…...

紧急预警:2024Q3起PlayAI将下线v2.1旧版翻译协议!迁移倒计时47天,5类遗留系统升级避坑手册
更多请点击: https://intelliparadigm.com 第一章:PlayAI多语种同步翻译功能详解 PlayAI 的多语种同步翻译功能基于端到端神经机器翻译(NMT)架构与实时语音流处理引擎深度融合,支持中、英、日、韩、法、西、德、俄等…...

AWorksLP嵌入式平台FatFs文件系统与SD卡驱动移植实战指南
1. 项目概述:为什么要在AWorksLP上折腾FatFs和SD卡?在嵌入式开发里,存储扩展是个绕不开的话题。尤其是当你手头的MCU片上Flash只有几百KB,却要存点日志、配置文件,甚至是一些小体积的音频、图片资源时,外挂…...
)
ubuntu linux虚拟机安装部署hermes详细教程(安装、问题处理)
文章目录 前言 一、Hermes 介绍 1. 什么是 Hermes Agent? 2. 核心特性 3. 为什么选择 Hermes Agent? 4. 适用场景 二、安装Hermes 1.安装 2.配置 3.开始对话 4.接入多平台(可选) 5.保持更新 三、Hermes接入微信 四、常见错误解决 1.Failed to connect to github.com port 4…...

Grid++Report设计器避坑指南:搞不定自动换行和字体缩小?看这篇就够了
GridReport设计器避坑指南:搞不定自动换行和字体缩小?看这篇就够了 当你面对一份需要展示长商品描述、多行地址或其他复杂文本的报表时,是否曾被GridReport的自动换行和字体缩小功能折磨得焦头烂额?作为一款功能强大的报表设计工具…...