数据结构和算法(3):列表
列表是一种线性数据结构,它允许在其中存储多个元素,并且可以动态地添加或删除元素。
循秩访问
可通过重载下标操作符,实现寻秩访问
template <typename T> // assert: 0 <= r < size
T List<T>::operator[](Rank r) const { //O(r),效率低下,可偶尔为之,却不宜常用Posi(T) p = first(); //从首节点出发while (0 < r--) p = p->succ; //顺数第r个节点即是return p->data;//目标节点
}//任一节点的秩,亦即其前驱的总数
效率比较低,总和为 O ( n 2 ) \mathcal O(n^2) O(n2),平摊到每个元素上为 O ( n ) \mathcal O(n) O(n)
接口与实现
根据是否修改数据结构,所有操作大致分为两类方式:
1)静态︰仅读取,数据结构的内容及组成一般不变:get、search;
2)动态:需写入,数据结构的局部或整体将改变:insert、remove。
与操作方式相对应地,数据元素的存储与组织方式也分为两种:
1)静态∶数据空间整体创建或销毁;
数据元素的物理存储次序与其逻辑次序严格一致;
可支持高效的静态操作;
比如向量,元素的物理地址与其逻辑次序线性对应;
2)动态︰为各数据元素动态地分配和回收的物理空间;
逻辑上相邻的元素记录彼此的物理地址,在逻辑上形成一个整体;
可支持高效的动态操作。
列表(List) 是采用动态存储策略的典型结构。其中的元素称作节点(node),各节点通过指针或引用彼此联接,在逻辑上构成一个线性序列。
相邻节点彼此互称前驱或后继。前驱或后继若存在,则必然唯一。没有前驱/后继的唯一节点称作首/末节点。
//listnode.h
template <typename T> struct ListNode;
template <typename T> using ListNodePosi = ListNode<T>*; //列表节点位置
template <typename T> struct ListNode { //列表节点模板类(以双向链表形式实现)
// 成员T data; ListNodePosi<T> pred, succ; //数值、前驱、后继
// 构造函数ListNode() {} //针对header和trailer的构造ListNode ( T e, ListNodePosi<T> p = NULL, ListNodePosi<T> s = NULL ): data( e ), pred( p ), succ( s ) {} //默认构造器
// 操作接口ListNodePosi<T> insertAsPred( T const& e ); //紧靠当前节点之前插入新节点ListNodePosi<T> insertAsSucc( T const& e ); //紧随当前节点之后插入新节点
};
列表节点:ADT接口
作为列表的基本元素,列表节点首先需要独立地“封装”实现
为此,可设置并约定若干基本的操作接口
 `
`
#include "listNode.h" //引入列表节点类template <typename T> class List { //列表模板类private:Rank _size; ListNodePosi<T> header, trailer; //规模、头哨兵、尾哨兵
protected:void init(); //列表创建时的初始化Rank clear(); //清除所有节点void copyNodes( ListNodePosi<T>, Rank ); //复制列表中自位置p起的n项ListNodePosi<T> merge( ListNodePosi<T>, Rank, List<T>&, ListNodePosi<T>, Rank ); //归并void mergeSort( ListNodePosi<T>&, Rank ); //对从p开始连续的n个节点归并排序void selectionSort( ListNodePosi<T>, Rank ); //对从p开始连续的n个节点选择排序void insertionSort( ListNodePosi<T>, Rank ); //对从p开始连续的n个节点插入排序void radixSort( ListNodePosi<T>, Rank ); //对从p开始连续的n个节点基数排序public:
// 构造函数List() { init(); } //默认List( List<T> const& L ); //整体复制列表LList( List<T> const& L, Rank r, Rank n ); //复制列表L中自第r项起的n项List( ListNodePosi<T> p, Rank n ); //复制列表中自位置p起的n项// 析构函数~List(); //释放(包含头、尾哨兵在内的)所有节点
// 只读访问接口Rank size() const { return _size; } //规模bool empty() const { return _size <= 0; } //判空ListNodePosi<T> operator[]( Rank r ) const; //重载,支持循秩访问(效率低)ListNodePosi<T> first() const { return header->succ; } //首节点位置ListNodePosi<T> last() const { return trailer->pred; } //末节点位置bool valid( ListNodePosi<T> p ) //判断位置p是否对外合法{ return p && ( trailer != p ) && ( header != p ); } //将头、尾节点等同于NULLListNodePosi<T> find( T const& e ) const //无序列表查找{ return find( e, _size, trailer ); }ListNodePosi<T> find( T const& e, Rank n, ListNodePosi<T> p ) const; //无序区间查找ListNodePosi<T> search( T const& e ) const //有序列表查找{ return search( e, _size, trailer ); }ListNodePosi<T> search( T const& e, Rank n, ListNodePosi<T> p ) const; //有序区间查找ListNodePosi<T> selectMax( ListNodePosi<T> p, Rank n ); //在p及其n-1个后继中选出最大者ListNodePosi<T> selectMax() { return selectMax( header->succ, _size ); } //整体最大者
// 可写访问接口ListNodePosi<T> insertAsFirst( T const& e ); //将e当作首节点插入ListNodePosi<T> insertAsLast( T const& e ); //将e当作末节点插入ListNodePosi<T> insert( ListNodePosi<T> p, T const& e ); //将e当作p的后继插入ListNodePosi<T> insert( T const& e, ListNodePosi<T> p ); //将e当作p的前驱插入T remove( ListNodePosi<T> p ); //删除合法位置p处的节点,返回被删除节点void merge( List<T>& L ) { merge( header->succ, _size, L, L.header->succ, L._size ); } //全列表归并void sort( ListNodePosi<T>, Rank ); //列表区间排序void sort() { sort( first(), _size ); } //列表整体排序Rank dedup(); //无序去重Rank uniquify(); //有序去重void reverse(); //前后倒置(习题)
// 遍历void traverse( void ( * )( T& ) ); //依次实施visit操作(函数指针)template <typename VST> void traverse( VST& ); //依次实施visit操作(函数对象)
}; //List
创建列表

template <typename T> void List<T>::init() { //列表初始化,在创建列表对象时统一调用header = new ListNode<T>; trailer = new ListNode<T>; //创建头、尾哨兵节点header->succ = trailer; header->pred = NULL; //向前链接trailer->pred = header; trailer->succ = NULL; //向后链接_size = 0; //记录规模
}
无序列表
插入与构造
//插入
template <typename T> //将e紧靠当前节点之前插入于当前节点所属列表(设有哨兵头节点header)
ListNodePosi<T> ListNode<T>::insertAsPred( T const& e ) {ListNodePosi<T> x = new ListNode( e, pred, this ); //创建新节点pred->succ = x; pred = x; //设置正向链接return x; //返回新节点的位置
}
//基于复制的构造
template <typename T> //列表内部方法:复制列表中自位置p起的n项
void List<T>::copyNodes( ListNodePosi<T> p, Rank n ) { // p合法,且至少有n-1个真后继init(); //创建头、尾哨兵节点并做初始化while ( n-- ) { insertAsLast( p->data ); p = p->succ; } //将起自p的n项依次作为末节点插入
}//insertAsLast 就相当于 insertBefore(trailer)
在列表中插入一个新节点 node 作为 p 的直接前驱,顺序为:
①node->succ = p
②node->pred = p->pred
③p->pred->succ = node
④p->pred = node
p->pred->succ = node 和 node->pred = p->pred 的正确执行需要能够定位p原先的直接前驱p->pred,而 p->pred = node 会破坏 p 到其的链接,故 p->pred->succ = node 和 node->pred = p->pred 必须在 p->pred = node 之前执行
删除和析构
//删除
template <typename T> T List<T>::remove( ListNodePosi<T> p ) { //删除合法节点pT e = p->data; //备份待删除节点的数值(假定T类型可直接赋值)p->pred->succ = p->succ; p->succ->pred = p->pred; //短路联接delete p; _size--; //释放节点,更新规模return e; //返回备份的数值
} //O(1)
//析构
template <typename T> List<T>::~List() //列表析构器
{ clear(); delete header; delete trailer; } //清空列表,释放头、尾哨兵节点template <typename T> Rank List<T>::clear() { //清空列表Rank oldSize = _size;while ( 0 < _size ) remove ( header->succ ); //反复删除首节点,直至列表变空return oldSize;
}//O(n),线性正比于列表规模
查找
template <typename T> //在无序列表内节点p(可能是trailer)的n个(真)前驱中,找到等于e的最后者
ListNodePosi<T> List<T>::find( T const& e, Rank n, ListNodePosi<T> p ) const {while ( 0 < n-- ) //(0 <= n <= Rank(p) < _size)对于p的最近的n个前驱,从右向左if ( e == ( p = p->pred )->data ) return p; //逐个比对,直至命中或范围越界return NULL; //p越出左边界意味着区间内不含e,查找失败
} //失败时,返回NULL
当存在多个目标时,会停止最靠后的元素节点。
去重
template <typename T> int List<T>::deduplicate() { //剔除无序列表中的重复节点if (_size < 2) return //平凡列表自然无重复int oldsize = _size; //记录原规模Posi(T) p = first(); Rank r = 1; //p从首节点起while (trailer != (p = p->succ )) //依次直到末节点Posi(T) q = find(p->data,r, p); //在p的r个(真)前驱中,查找与之雷同者q ? remove(q):r++; //若的确存在,则删除之;否则秩递增——可否remove(p)?不可!因为后面要指向其后继} //assert:循环过程中的任意时刻,p的所有前驱互不相同
return oldSize - _size; //列表规模变化量,即被删除元素总数
}//正确性及效率分析的方法与结论,与Vector::deduplicate()相同
有序列表
唯一化(去重)
template <typename T> Rank List<T>::uniquify() { //成批剔除重复元素,效率更高if ( _size < 2 ) return 0; //平凡列表自然无重复Rank oldSize = _size; //记录原规模ListNodePosi<T> p = first(); ListNodePosi<T> q; //p为各区段起点,q为其后继while ( trailer != ( q = p->succ ) ) //反复考查紧邻的节点对(p, q)if ( p->data != q->data ) p = q; //若互异,则转向下一区段else remove( q ); //否则(雷同)直接删除后者,不必如向量那样间接地完成删除return oldSize - _size; //列表规模变化量,即被删除元素总数
}//只需遍历整个列表一趟,O(n)
查找
template <typename T>//在有序列表内节点p的n个(真)前驱中,找到不大于e的最后者
Posi(T) List<T>::search(T const & e, int n, Posi(T) p) const {while ( e <= n-- )//对于p的最近的n个前驱,从右向左if((( p = p->pred ) -> data <= e ) break;//逐个比较return p;//直至命中、数值越界或范围界后,返回查找终止的位置
}//最好o(1),最坏o(n);等概率时平均o(n),正比于区间宽度
列表的循位置访问和向量的循秩访问有着根本区别,前者靠的是位置,后置靠的是秩。
选择排序
基本思路是在未排序的部分中找到最小(或最大)的元素,然后将其与未排序部分的第一个元素交换位置,以此类推,直到整个序列排序完成。
基本思路和步骤:
- 初始状态:将整个序列分为两部分,已排序部分和未排序部分。一开始,已排序部分为空,未排序部分包含整个序列。
- 找到最小元素:在未排序部分中找到最小的元素,并记录其位置(索引)。
- 交换位置:将找到的最小元素与未排序部分的第一个元素交换位置。
- 更新已排序部分:将已排序部分的末尾扩展,包括刚刚交换的元素。
- 重复步骤2至4:重复执行步骤2至4,直到未排序部分为空。
- 排序完成:当未排序部分为空时,整个序列就被排序完成。
template <typename T> //对列表中起始于位置p、宽度为n的区间做选择排序
void List<T>::selectionSort( ListNodePosi<T> p, Rank n ) { // valid(p) && Rank(p) + n <= sizeListNodePosi<T> head = p->pred, tail = p;for ( Rank i = 0; i < n; i++ ) tail = tail->succ; //待排序区间为(head, tail)while ( 1 < n ) { //在至少还剩两个节点之前,在待排序区间内ListNodePosi<T> max = selectMax ( head->succ, n ); //找出最大者(歧义时后者优先)insert( remove( max ), tail ); //将其移至无序区间末尾(作为有序区间新的首元素)tail = tail->pred; n--;}
}template <typename T> //从起始于位置p的n个元素中选出最大者
ListNodePosi<T> List<T>::selectMax( ListNodePosi<T> p, Rank n ) {ListNodePosi<T> max = p; //最大者暂定为首节点pfor ( ListNodePosi<T> cur = p; 1 < n; n-- ) //从首节点p出发,将后续节点逐一与max比较if ( !lt( ( cur = cur->succ )->data, max->data ) ) //若当前元素不小于max,则max = cur; //更新最大元素位置记录return max; //返回最大节点位置
}
总共迭代 n 次,在第 k 次迭代中, selectmax() 为 O ( n − k ) \mathcal O(n-k) O(n−k),remove() 和 insertBefore() 均为 O ( 1 ) \mathcal O(1) O(1),故总体复杂度应为 O ( n 2 ) \mathcal O(n^2) O(n2)。
尽管如此,元素移动操作远远少于冒泡排序,也就是说 O ( n 2 ) \mathcal O(n^2) O(n2) 主要来自比较操作.
尽管它不如一些高级排序算法(如快速排序或归并排序)快,但它简单直观,对于小型数据集来说是一个有效的排序方法。然而,对于大型数据集,选择排序的性能可能不够理想。
插入排序
基本思路是将一个序列分成已排序部分和未排序部分。初始时,已排序部分只包含第一个元素,然后逐步将未排序部分的元素插入到已排序部分,保持已排序部分的有序性。这个过程类似于我们在打牌时对手中的牌进行排序,每次将一张新牌插入到已经有序的牌中。
基本思路和步骤:
- 初始状态:将整个序列分为两部分,已排序部分和未排序部分。一开始,已排序部分只包含第一个元素,未排序部分包含其余的元素。
- 从未排序部分选择一个元素:从未排序部分选择第一个元素,将其视为待插入的元素。
- 向已排序部分插入元素:将待插入元素与已排序部分的元素从右向左逐个比较,直到找到合适的位置。在比较过程中,较大的元素会向右移动,为待插入元素腾出空间。
- 插入元素:一旦找到了合适的位置,将待插入元素插入到已排序部分。
- 更新已排序部分:已排序部分扩展一个位置,包括刚刚插入的元素。
- 重复步骤2至5:重复执行步骤2至5,直到未排序部分为空。
- 排序完成:当未排序部分为空时,整个序列就被排序完成。
template <typename T> //对列表中起始于位置p、宽度为n的区间做插入排序
void List<T>::insertionSort( ListNodePosi<T> p, Rank n ) { // valid(p) && Rank(p) + n <= sizefor ( Rank r = 0; r < n; r++ ) { //逐一为各节点insert( search( p->data, r, p ), p->data ); //查找适当的位置并插入p = p->succ; remove( p->pred ); //转向下一节点} //n 次迭代,每次O(r+1)
} //仅使用 O(1) 辅助空间,属于就地算法
最好情况:完全(或)几乎有序,每次迭代,只需 1 次比较, 0 次交换,累计 O ( n ) \mathcal O(n) O(n)。
最坏要 O ( n 2 ) \mathcal O(n^2) O(n2)。
逆序对
逆序对(Inverse Pairs) 是一个在数组或序列中常见的概念。在一个序列中,如果两个元素的顺序与它们在原始序列中的顺序相反,就称这两个元素构成了一个逆序对。
通常情况下,逆序对用于衡量一个序列的有序程度,逆序对越多,序列越无序。
考虑一个简单的整数数组 [2, 4, 1, 3, 5],其中逆序对包括 (2, 1) 和 (4, 1),因为这些元素的顺序在原始数组中相反。
相关文章:
数据结构和算法(3):列表
列表是一种线性数据结构,它允许在其中存储多个元素,并且可以动态地添加或删除元素。 循秩访问 可通过重载下标操作符,实现寻秩访问 template <typename T> // assert: 0 < r < size T List<T>::operator[](Rank r) cons…...

使用playright自动下载vscode已安装插件
import os import re import subprocess import traceback from playwright.sync_api import Playwright, sync_playwright, expect# 执行CMD命令 cmd_command "code --list-extensions" # 获取已安装扩展列表 process subprocess.Popen(cmd_command, stdoutsubpr…...

单片机语言实例:2、点亮数码管的多种方法
一、共阳数码管静态显示 程序实例1: #include<reg52.h> //包含头文件,一般情况不需要改动, //头文件包含特殊功能寄存器的定义void main (void) {P10xc0; //二进制 为 1100 0000 参考数码管排列,//可以得出0对应的段点…...
C#学习 - 初识类与名称空间
类(class)& 名称空间(namespace) 类是最基础的 C# 类型,是一个数据结构,是构成程序的主体 名称空间以树型结构组织类 using System; //前面的using就是引用名称空间 //相当于C语言的 #include <..…...
Python爬取电影信息:Ajax介绍、爬取案例实战 + MongoDB存储
Ajax介绍 Ajax(Asynchronous JavaScript and XML)是一种用于在Web应用程序中实现异步通信的技术。它允许在不刷新整个网页的情况下,通过在后台与服务器进行数据交换,实时更新网页的一部分。Ajax的主要特点包括: 异步通…...

JavaScript的面向对象
一、认识对象 1.概述 对象(object)是 JavaScript 语言的核心概念,也是最重要的数据类型。 什么是对象?简单说,对象就是一组“键值对”(key-value)的集合,是一种无序的复合数据集合…...
MybatisPlus 核心功能 条件构造器 自定义SQL Service接口 静态工具
MybatisPlus 快速入门 常见注解 配置_软工菜鸡的博客-CSDN博客 2.核心功能 刚才的案例中都是以id为条件的简单CRUD,一些复杂条件的SQL语句就要用到一些更高级的功能了。 2.1.条件构造器 除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此…...
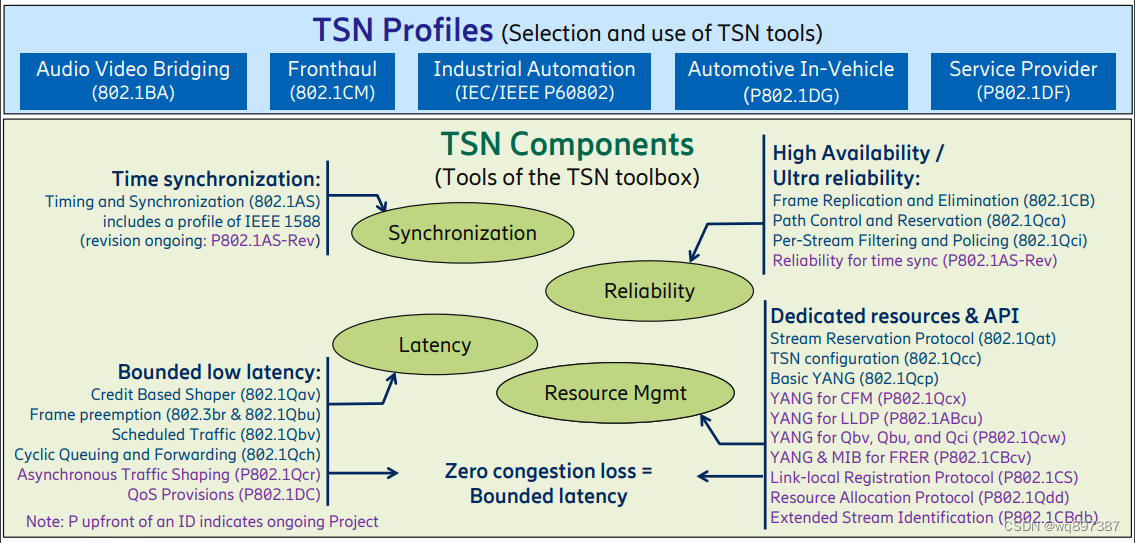
TSN时间敏感网络
目录 时间敏感网络介绍 子协议介绍 时间同步 IEEE802.1AS 调度和流量整形 IEEE802.1Q IEEE802.1Qbv IEEE802.1cr IEEE802.1Qbu IEEE802.1Qch IEEE802.1Qav IEEE802.1Qcc 纠错机制与安全 IEEE802.1Qci IEEE802.1CB IEEE802.1Qca 参考 时间敏感网络介绍 TSN(Tim…...

【2023年数学建模国赛】C题解题思路
第一问 要求分析分析蔬菜各品类及单品销售量的分布规律及相互关系。该问题可以拆分成三个角度进行剖析。 1)各种类蔬菜的销售量分布、蔬菜种类与销售量之间的关系;2)各种类蔬菜的销售量的月份分布、各种类蔬菜销售量与月份之间的相关关系&a…...

5分钟 将“.py”文件转为“.pyd”文件
代码: from distutils.core import setup from distutils.extension import Extension from Cython.Build import cythonize import osfile_list os.listdir("./") extensions [] for file in file_list:if file.endswith(".py") and file !…...
)
python 入门到精通(一)
文章目录 1.使用pycharm进行第一个程序的编写2.python基础语法篇2.1 常用的值类型2.2 注释2.3 变量2.4 数据类型2.5 数据类型转换2.6 什么是标识符2.7 运算符2.8 字符串扩展2.8.1 字符串拼接2.8.2 字符串格式化2.8.3 格式化的精度控制2.8.4 字符串格式化 - 快速写法2.8.5 字符串…...
异步的JavaScript 和 XML)
AJAX (Asynchronous JavaScript And XML)异步的JavaScript 和 XML
1、概念 Asynchronous JavaScript And XML 异步的JavaScript 和 XML异步和同步:客户端和服务器端相互通信的基础上 同步:客户端必须等待服务端的响应。在等待的期间客户端不能做其他操作。异步:客户端不需要等待服务器端的响应。在服务器…...
华为云云耀云服务器L实例评测|安装Java8环境 配置环境变量 spring项目部署 【!】存在问题未解决
目录 引出安装JDK8环境查看是否有默认jar上传Linux版本的jar包解压压缩包配置环境变量 上传jar包以及运行问题上传Jar包运行控制台开放端口访问失败—见问题记录关闭Jar的方式1.进程kill -92.ctrl c退出 问题记录:【!】未解决各种方式查看端口情况联系工程师最后排查…...
安卓多渠道打包(五)360加固walle多渠道打包
背景: 1、360加固宝,签名收費了,脚本上传加固也针对特定帐号才可实现。 内容 本文将会分享安卓项目中,使用360加固,再用walle签名,产出多渠道加固包的全流程。 环境 win10 jdk11 as2022 gradle7.5 最…...

Jmeter 实现 mqtt 协议压力测试
1. 下载jmeter,解压 https://jmeter.apache.org/download_jmeter.cgi 以 5.4.3 为例,下载地址: https://dlcdn.apache.org//jmeter/binaries/apache-jmeter-5.4.3.zip linux下解压: unzip apache-jmeter-5.4.3.zip 2. 下载m…...
蓝桥杯官网练习题(凑算式)
类似填空题: ①算式900: https://blog.csdn.net/s44Sc21/article/details/132746513?spm1001.2014.3001.5501https://blog.csdn.net/s44Sc21/article/details/132746513?spm1001.2014.3001.5501 ②九宫幻方③七星填数④幻方填空:https:/…...
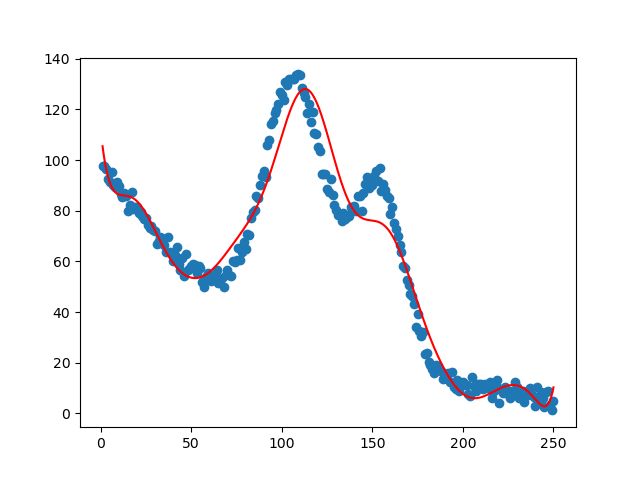
机器学习实战-系列教程5:手撕线性回归4之非线性回归(项目实战、原理解读、源码解读)
🌈🌈🌈机器学习 实战系列 总目录 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 手撕线性回归1之线性回归类的实现 手撕线性回归2之单特征线性回归 手撕线性回归3之多特征线性回归 手撕线性回归4之非线性回归 1…...

【C语言基础】那些你可能不知道的C语言“潜规则”
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
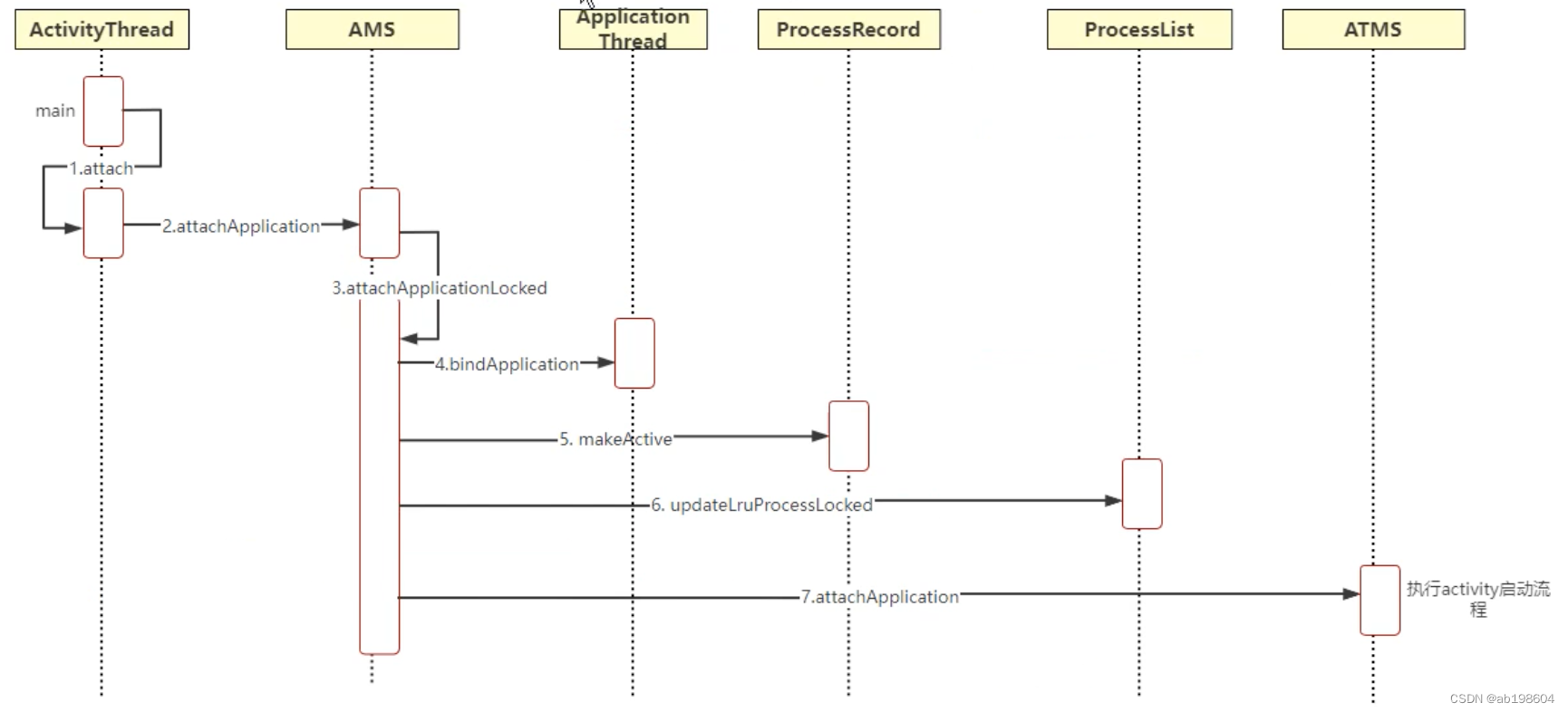
android framework之Applicataion启动流程分析(三)
现在再回顾一下Application的启动流程,总的来说,虽然进程的发起是由ATMS服务发起的,但是进程的启动还是由AMS负责,所以需要调用AMS的startProcess()接口完成进程启动流程,AMS要处理的事情很多,它将事务交给…...

使用Scrapy框架集成Selenium实现高效爬虫
引言: 在网络爬虫的开发中,有时候我们需要处理一些JavaScript动态生成的内容或进行一些复杂的操作,这时候传统的基于请求和响应的爬虫框架就显得力不从心了。为了解决这个问题,我们可以使用Scrapy框架集成Selenium来实现高效的爬…...
)
从Gemini Nano到Orion Core:Google 2026 AI芯片级升级路线图(附17个真实POC性能基准数据)
更多请点击: https://intelliparadigm.com 第一章:Gemini Nano到Orion Core:Google 2026 AI芯片级演进全景图 Google 正在以空前的系统性节奏重构其AI硬件栈——从终端侧轻量模型推理引擎 Gemini Nano,到2026年即将量产的全栈自研…...

AI赋能二进制安全:BinAIVulHunter项目实战与逆向工程集成
1. 项目概述与核心价值最近在安全圈里,一个名为BinAIVulHunter的开源项目引起了我的注意。这个项目名直译过来就是“二进制AI漏洞猎人”,光看名字就能猜到它的核心玩法:利用人工智能技术,来自动化分析二进制文件,挖掘其…...

三步高效配置:快速实现百度网盘直链下载的完整指南
三步高效配置:快速实现百度网盘直链下载的完整指南 【免费下载链接】baiduyun 油猴脚本 - 一个免费开源的网盘下载助手 项目地址: https://gitcode.com/gh_mirrors/ba/baiduyun 你是否还在为百度网盘下载速度缓慢而烦恼?是否厌倦了客户端限速的困…...
PixelAnnotationTool:破解语义分割标注效率瓶颈的智能解决方案
PixelAnnotationTool:破解语义分割标注效率瓶颈的智能解决方案 【免费下载链接】PixelAnnotationTool Annotate quickly images. 项目地址: https://gitcode.com/gh_mirrors/pi/PixelAnnotationTool 在计算机视觉领域,高质量的语义分割数据标注是…...

数字永生:将意识上传云端的技术与伦理极限
——一个软件测试从业者的技术解构与风险分析各位同行,当你看到“数字永生”这四个字时,脑海里浮现的是什么?是马斯克口中2045年即将实现的意识上传,还是《黑镜》里那些被困在虚拟牢笼中的数字灵魂?作为一个每天与需求…...

从入门到精通:IGV基因组浏览器实战操作全解析
1. IGV基因组浏览器初探 第一次接触IGV(Integrative Genomics Viewer)是在五年前分析RNA-seq数据时,当时被它轻量级的安装包和流畅的基因组导航体验惊艳到了。作为一款由Broad研究所开发的免费工具,IGV完美平衡了专业性和易用性—…...

乔布斯产品哲学对硬件工程师的启示:从参数到体验的转变
1. 项目概述:一次对乔布斯遗产的技术性致敬2011年10月6日,当史蒂夫乔布斯逝世的消息传来,整个科技界陷入了一种复杂的情绪。作为一名长期在电子工程与消费电子领域工作的人,我的感受尤为深刻。那天,我和我的同事们&…...

通过curl命令直接测试Taotoken聊天补全接口的配置与排错方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的配置与排错方法 对于开发者而言,在集成大模型API时,直接使用c…...

SLV:用AI对话驱动Solana节点部署与运维的革命性工具
1. 项目概述:SLV,一个为Solana节点管理注入AI灵魂的工具如果你在Solana生态里跑过验证器节点或者搭建过RPC服务,那你一定对下面这套流程不陌生:找一台靠谱的服务器,手动SSH连上去,一行行敲命令安装依赖、编…...
)
从Anaconda虚拟环境到Docker镜像:一份给数据科学家的迁移指南(避坑Dockerfile编写)
从Anaconda到Docker:数据科学家的环境迁移实战手册 当你的机器学习模型在本地运行良好,却在同事的电脑上频频报错时;当论文评审要求提供可复现的实验环境时;当需要将训练好的模型部署到云服务器时——conda虚拟环境的局限性便开始…...