大数据技术之Hadoop:HDFS存储原理篇(五)
目录
一、原理介绍
1.1 Block块
1.2 副本机制
二、fsck命令
2.1 设置默认副本数量
2.2 临时设置文件副本大小
2.3 fsck命令检查文件的副本数
2.4 block块大小的配置
三、NameNode元数据
3.1 NameNode作用
3.2 edits文件
3.3 FSImage文件
3.4 元素据合并控制参数
3.5 SecondaryNameNode的作用
四、HDFS的读写流程
4.1 写入流程
4.2 读取流程
一、原理介绍
1.1 Block块
HDFS分布式文件存储,通常是将1个文件拆分成多个部分,然后分别发送到不同服务器节点上。
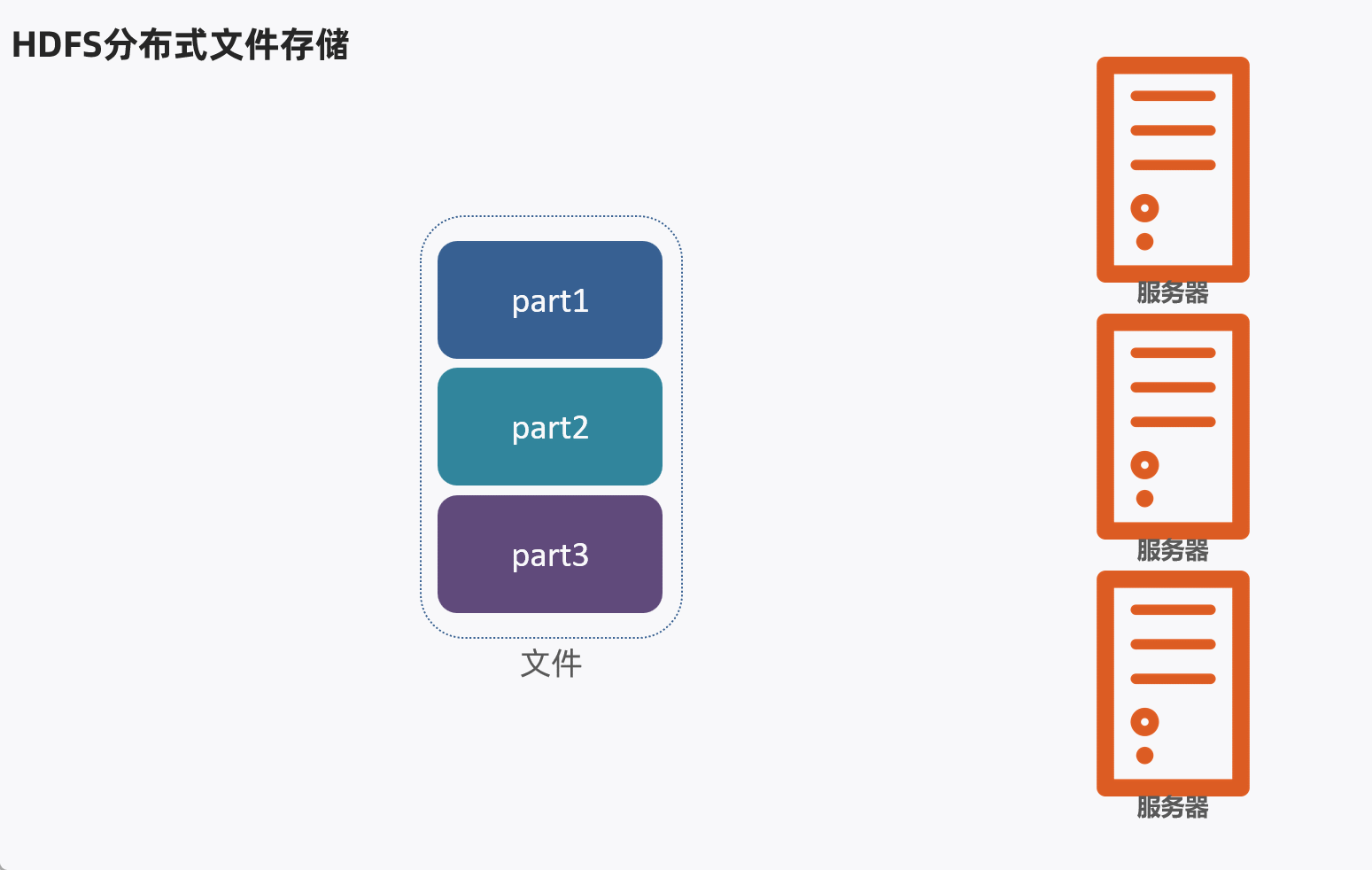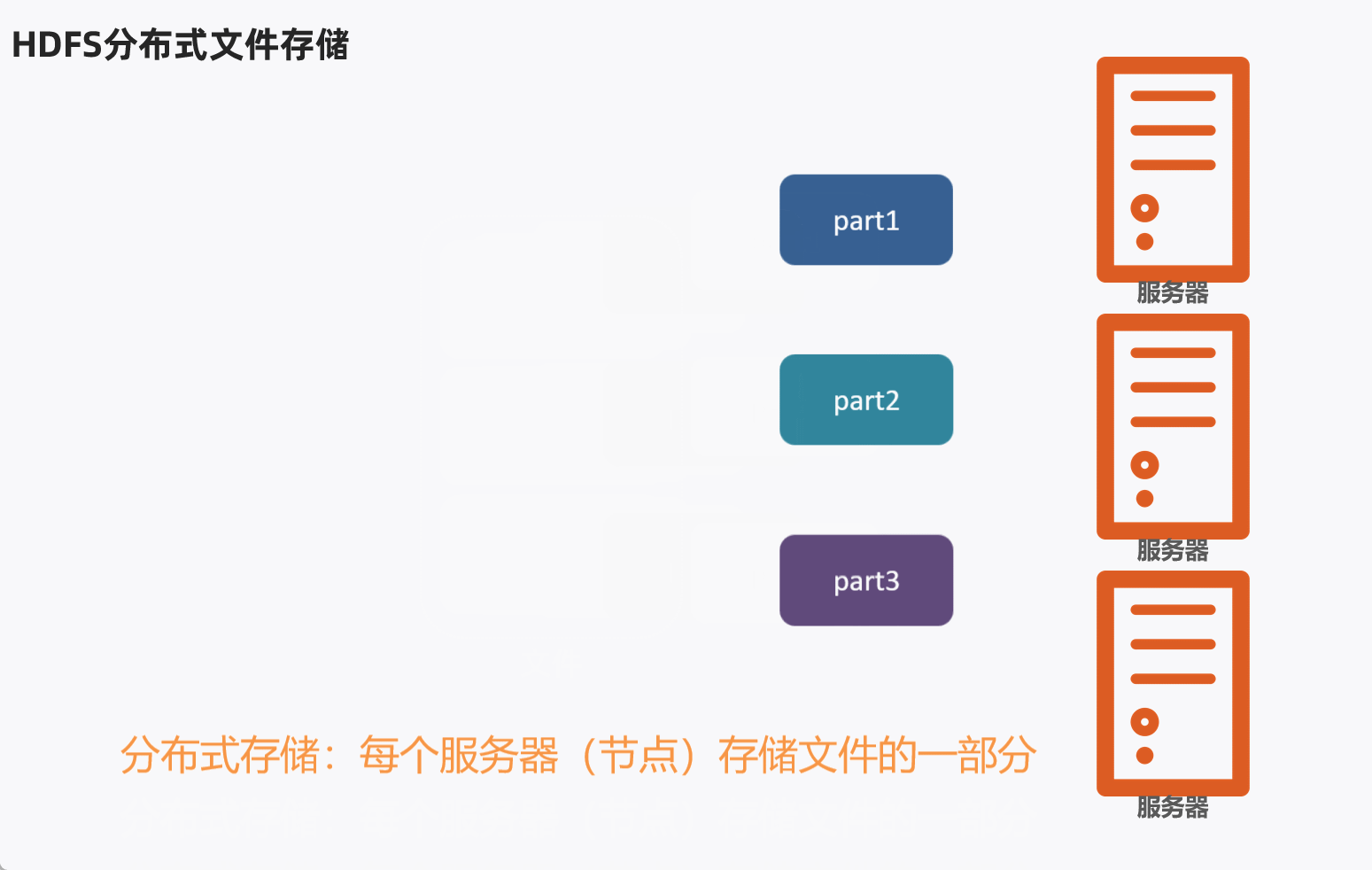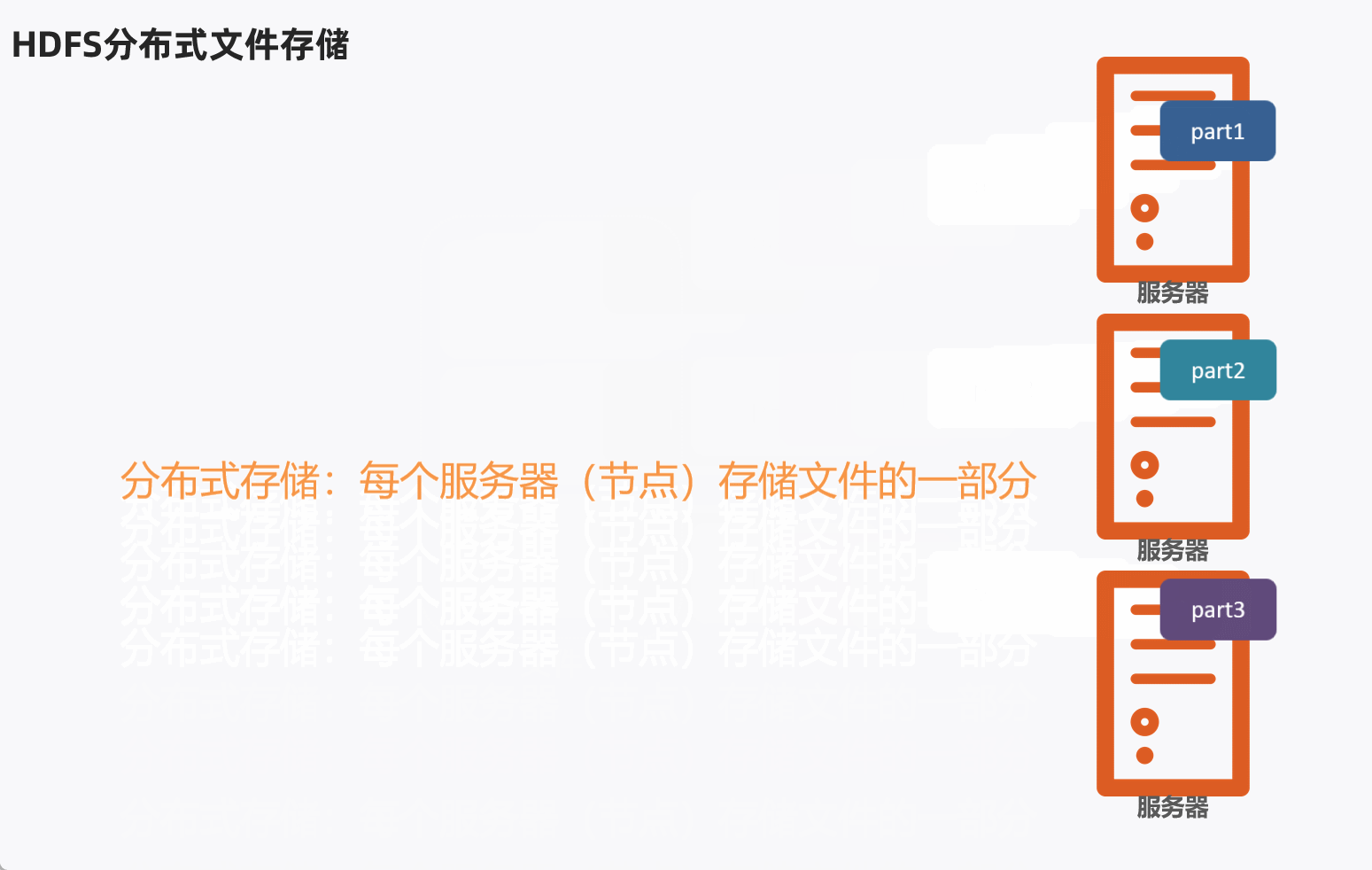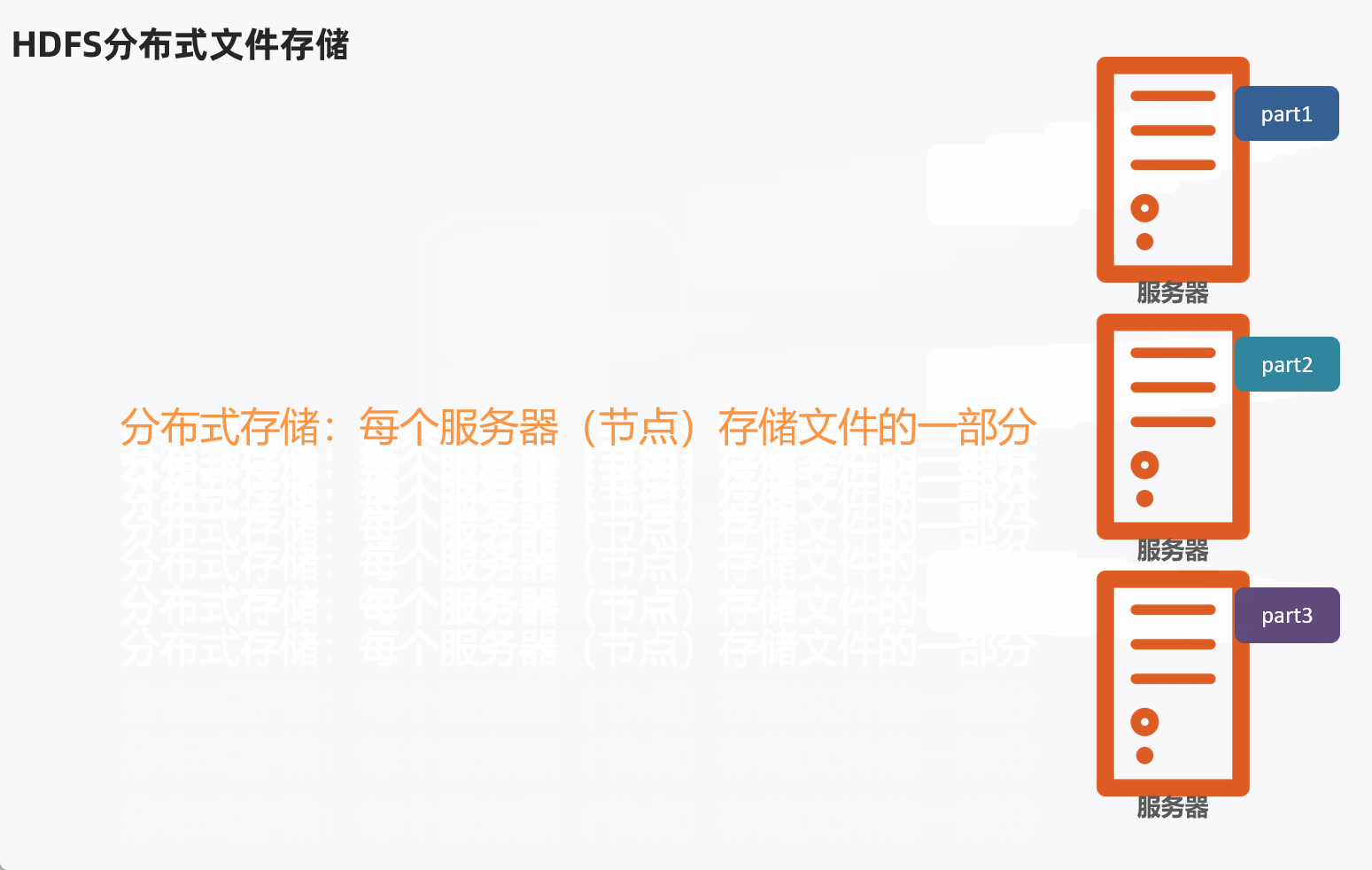
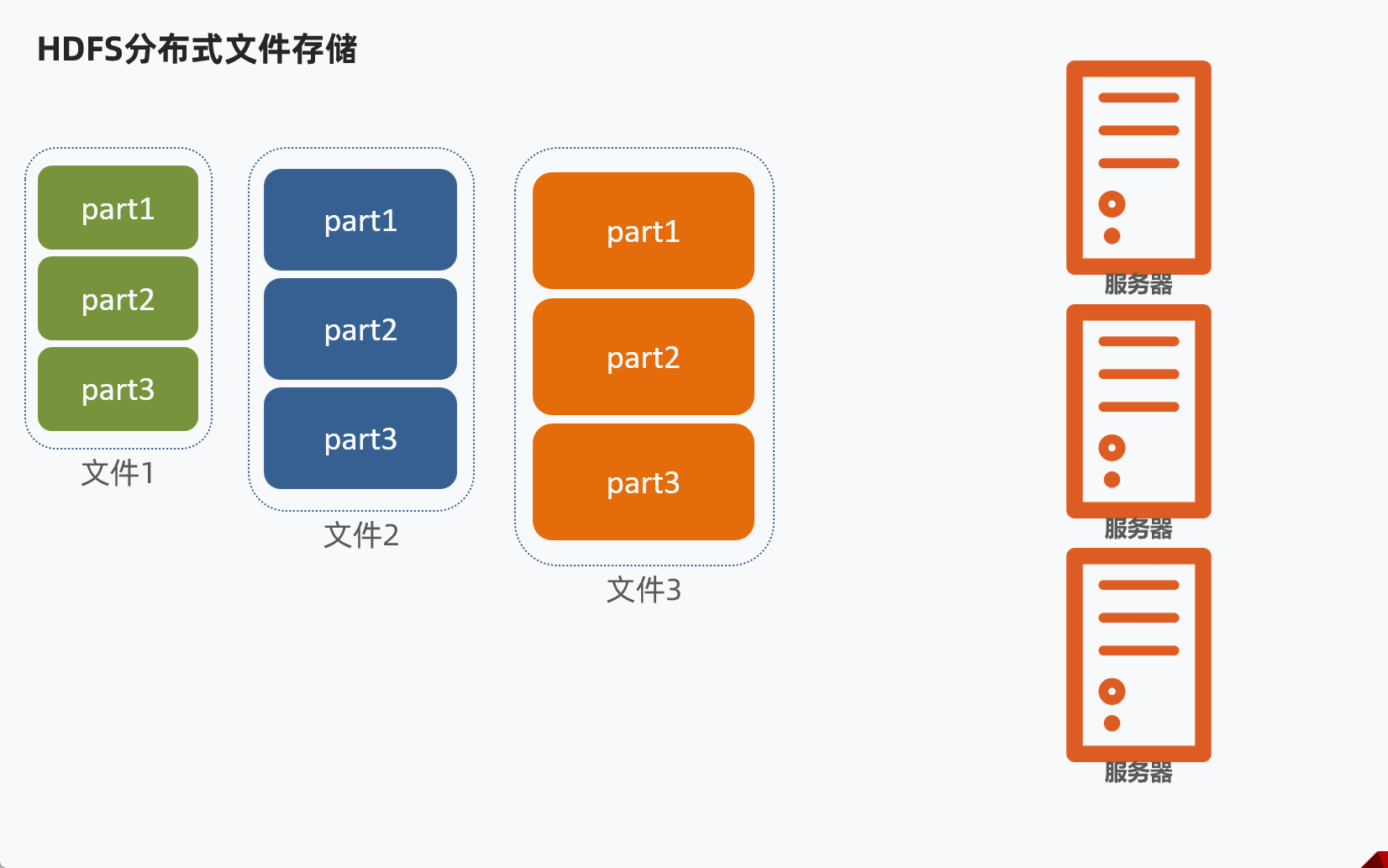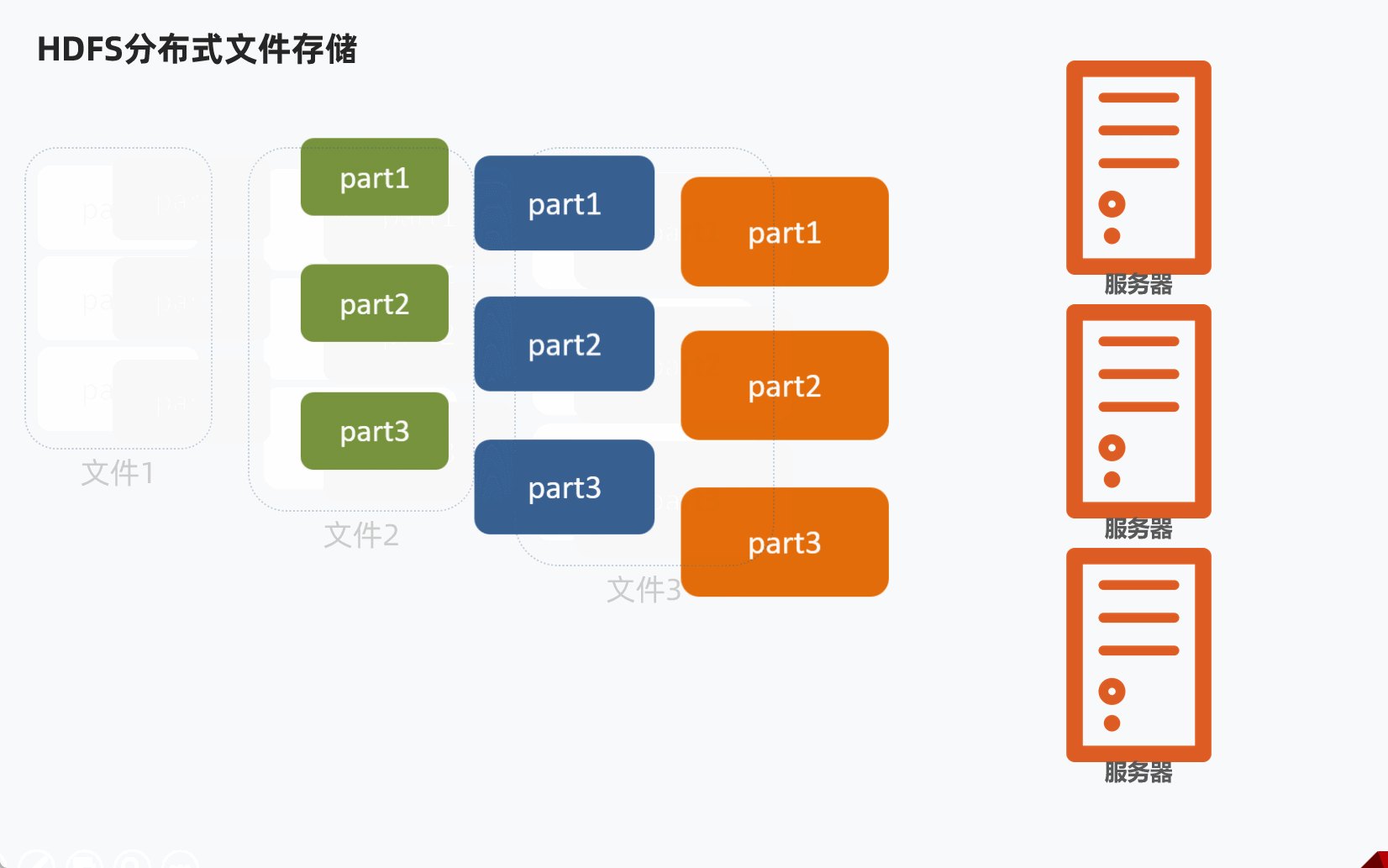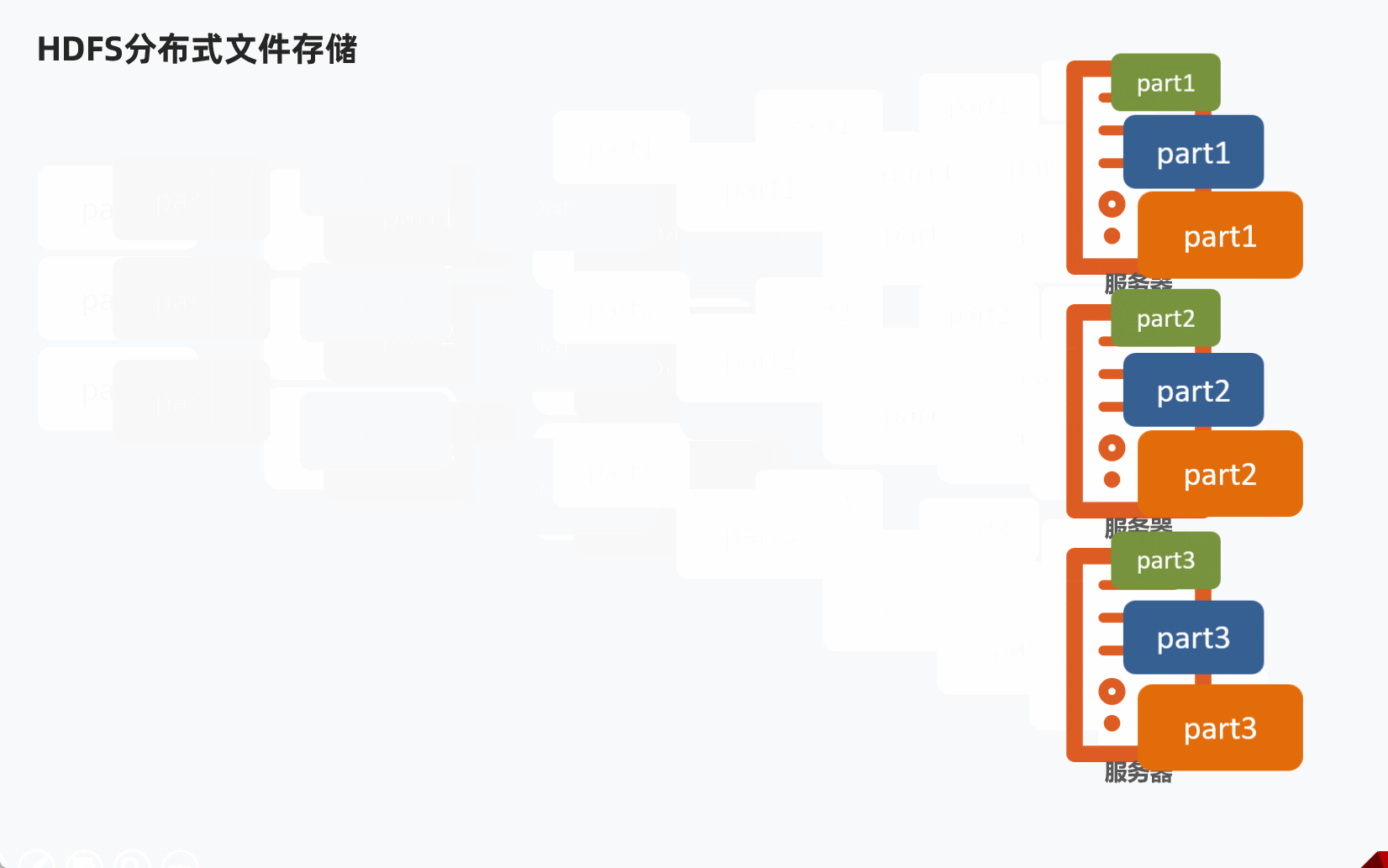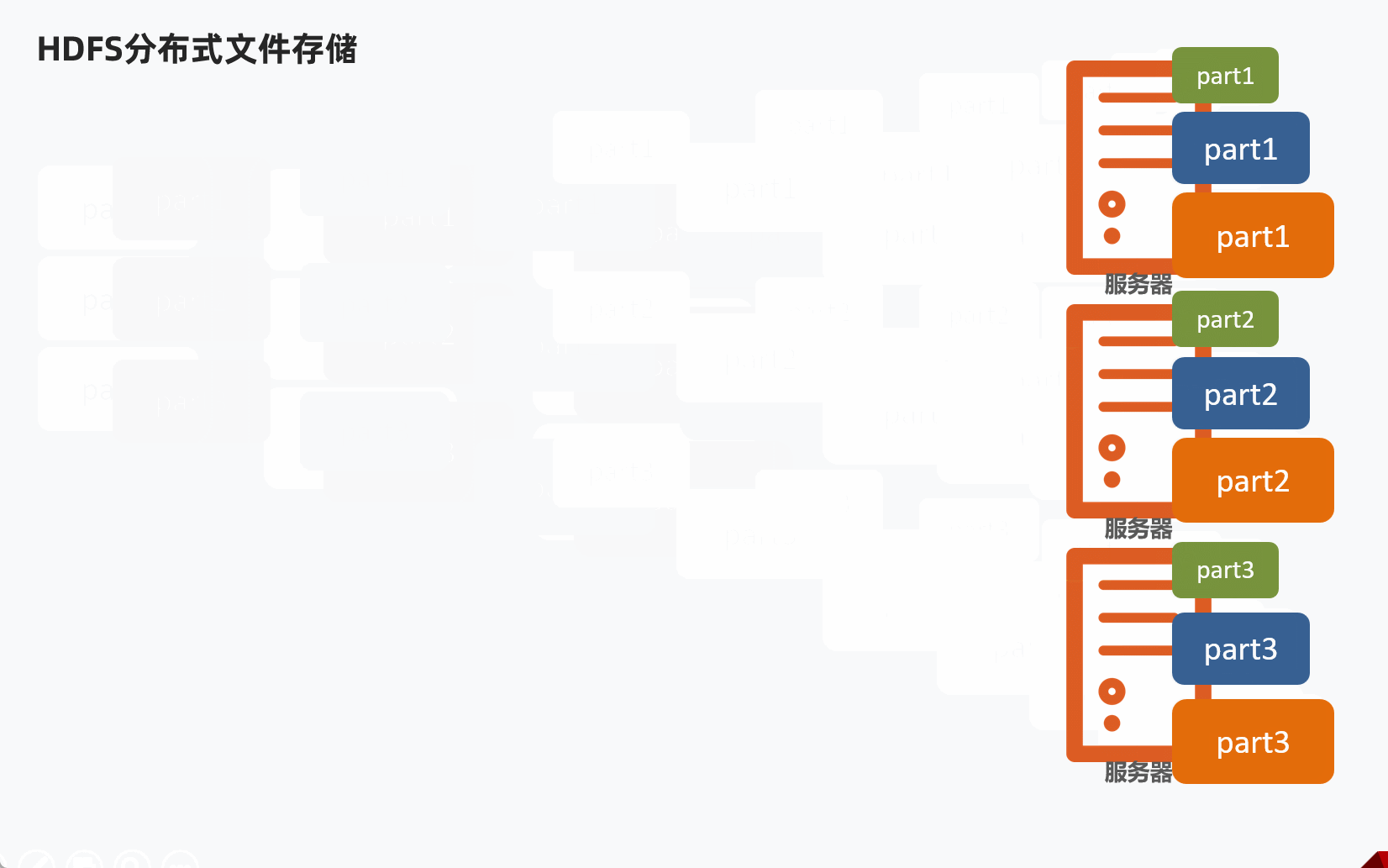
问题:不同的文件大小不一,粗暴的拆分然后放到服务器不同节点,会导致各个部分的大小也不一样,不利于统一管理。
解决办法:设定统一的管理单位,block块。
- Block块,HDFS最小存储单位
- 每个256MB(可以修改)
这样可以将文件分成多个Block块,不同的Block块存入对应服务器。
举例说明
某个文件大小1G,那么理论上可以分为4个Block块。
如果集群有三台服务器,那么某台服务器放2个Block块,然后其他两台服务器各1个Block块。
1.2 副本机制
如果不备份,假如某个块损坏了,那么就会导致整个文件不可用。
所以,副本机制是保障数据安全的非常重要的机制。

二、fsck命令
2.1 设置默认副本数量

默认的HDFS文件的副本数量就是3个。
当然这个值可以修改,具体可以在hdfs-site.xml中配置如下属性
<property><name>dfs.replication</name><value>3</value>
</property>
这个属性默认是3,一般情况下,我们无需主动配置(除非需要设置非3的数值)
如果需要自定义这个属性,请修改每一台服务器的hdfs-site.xml文件,并设置此属性。
2.2 临时设置文件副本大小
如果不加限制,我们创建的文件或者上传的文件,默认副本数就是上面设置的值。
但是单次文件上传,我们也可以指定某个文件拥有多少个副本。
hadoop fs -D dfs.replication=2 -put test.txt /tmp/
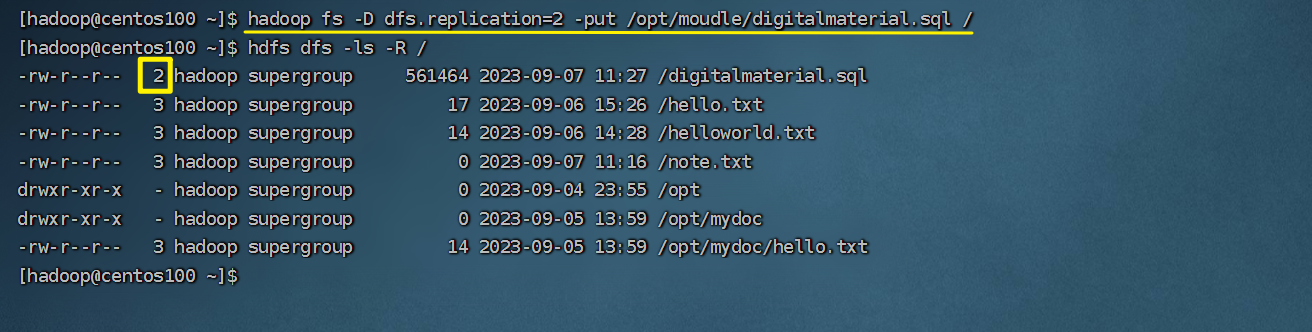 对于已经存在HDFS的文件,修改dfs.replication属性不会生效,如果要修改已存在文件可以通过命令
对于已经存在HDFS的文件,修改dfs.replication属性不会生效,如果要修改已存在文件可以通过命令
hadoop fs -setrep [-R] 2 path如上命令,指定path的内容将会被修改为2个副本存储。
-R选项可选,使用-R表示对子目录也生效。
2.3 fsck命令检查文件的副本数
我们要查看详细的文件副本数信息,可以通过如下命令:
hdfs fsck path [-files [-blocks [-locations]]]
fsck可以检查指定路径是否正常
-files可以列出路径内的文件状态
-files -blocks 输出文件块报告(有几个块,多少副本)
-files -blocks -locations 输出每一个block的详情

2.4 block块大小的配置
默认情况下,block块的大小是256MB,当然我们也可以修改。
<property><name>dfs.blocksize</name><value>268435456</value><description>设置HDFS块大小,单位是b</description></property>
三、NameNode元数据
3.1 NameNode作用
NameNode作用:管理Block块。
在hdfs中,文件是被划分了一堆堆的block块,那如果文件很大、以及文件很多,Hadoop是如何记录和整理文件和block块的关系呢?
答案就在于NameNode。
NameNode基于一批edits和一个fsimage文件的配合完成整个文件系统的管理和维护。
3.2 edits文件
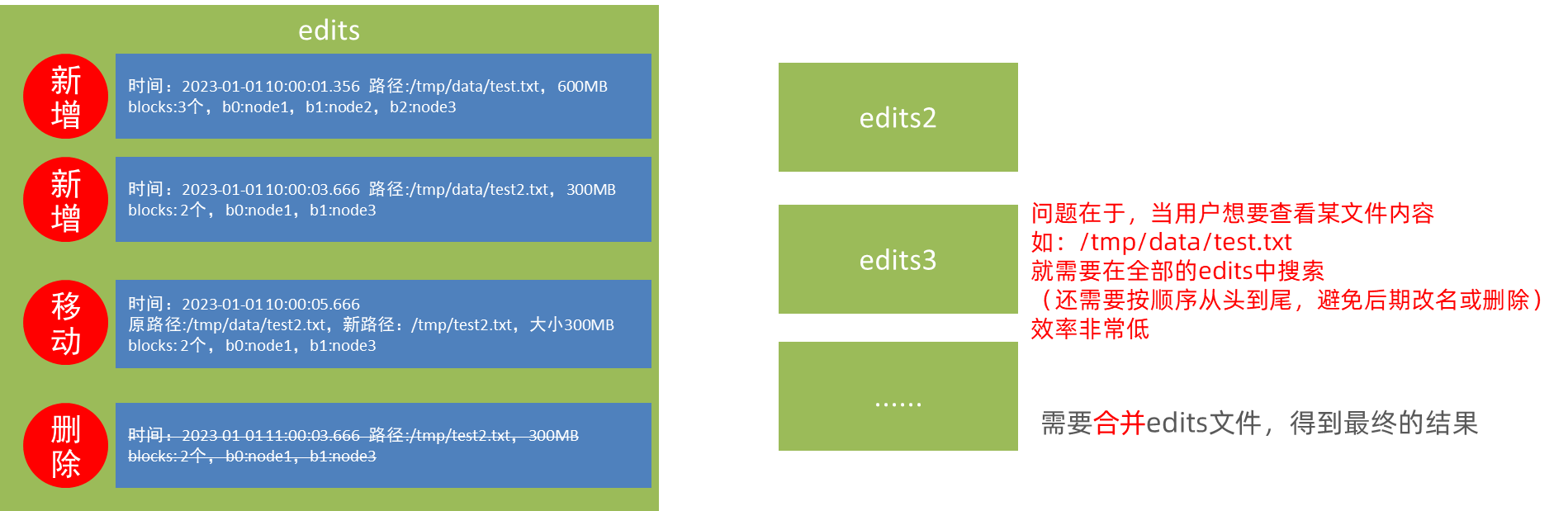
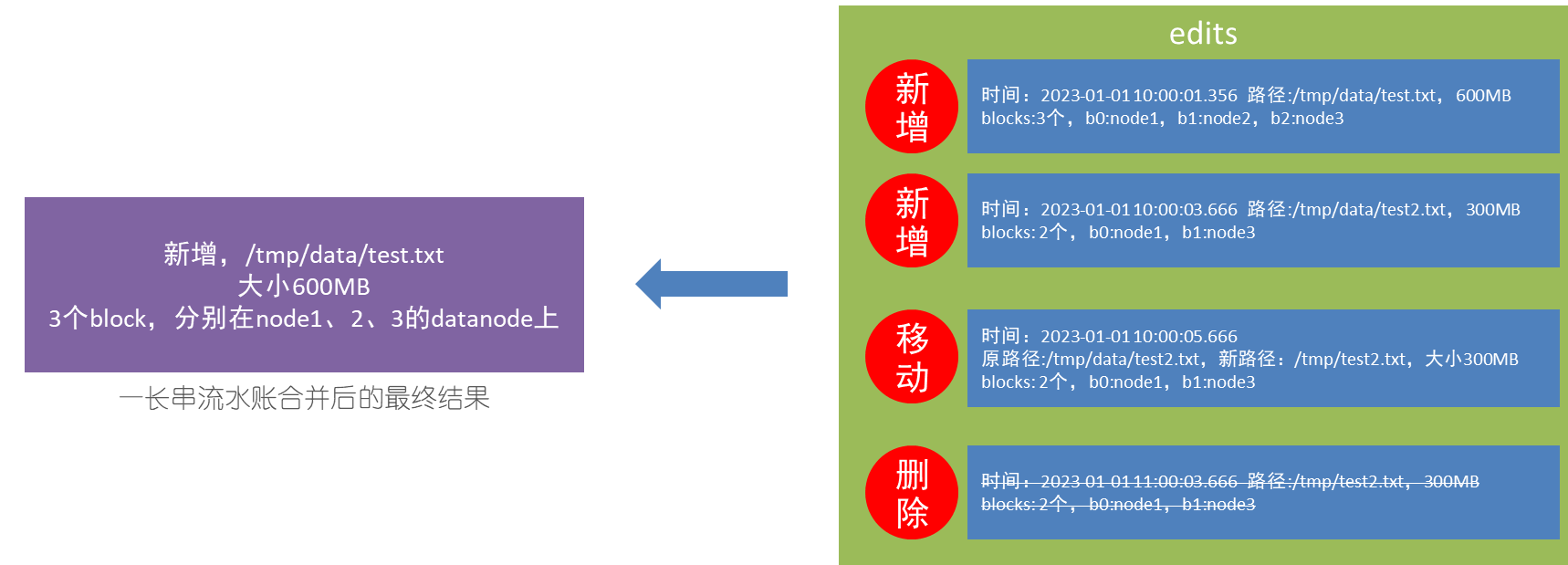
edits文件,是一个流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件其对应的block。



3.3 FSImage文件
将全部的edits文件,合并为最终结果,即可得到一个FSImage文件

小结
NameNode基于edits和FSImage的配合,完成整个文件系统文件的管理。
1. 每次对HDFS的操作,均被edits文件记录
2. edits达到大小上线后,开启新的edits记录
3. 定期进行edits的合并操作
- 如当前没有fsimage文件, 将全部edits合并为第一个fsimage
- 如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
4. 重复123流程
3.4 元素据合并控制参数
对于元数据的合并,是一个定时过程,基于:
dfs.namenode.checkpoint.period,默认3600(秒)即1小时
dfs.namenode.checkpoint.txns,默认1000000,即100W次事务
只要有一个达到条件就执行。
检查是否达到条件,默认60秒检查一次,基于:
dfs.namenode.checkpoint.check.period,默认60(秒),来决定。
3.5 SecondaryNameNode的作用
对于元数据的合并,还记得HDFS集群有一个辅助角色:SecondaryNameNode吗?
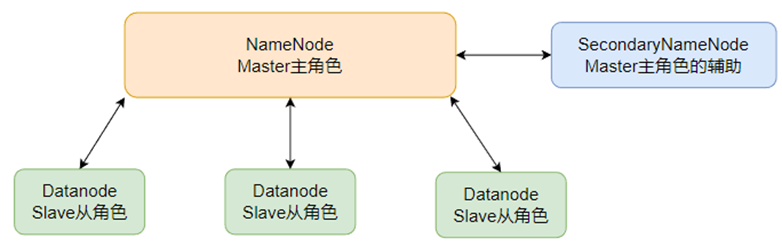
没错,合并元数据的事情就是它干的
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage)
然后合并完成后提供给NameNode使用。
四、HDFS的读写流程
4.1 写入流程

1. 客户端向NameNode发起请求
2. NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址
3. 客户端向指定的DataNode发送数据包
4. 被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其它DataNode
5. 如上图,DataNode1复制给DataNode2,然后基于DataNode2复制给Datanode3和DataNode4
6. 写入完成客户端通知NameNode,NameNode做元数据记录工作
关键信息点:
NameNode不负责数据写入,只负责元数据记录和权限审批
客户端直接向1台DataNode写数据,这个DataNode一般是离客户端最近(网络距离)的那一个
数据块副本的复制工作,由DataNode之间自行完成(构建一个PipLine,按顺序复制分发,如图1给2, 2给3和4)
4.2 读取流程
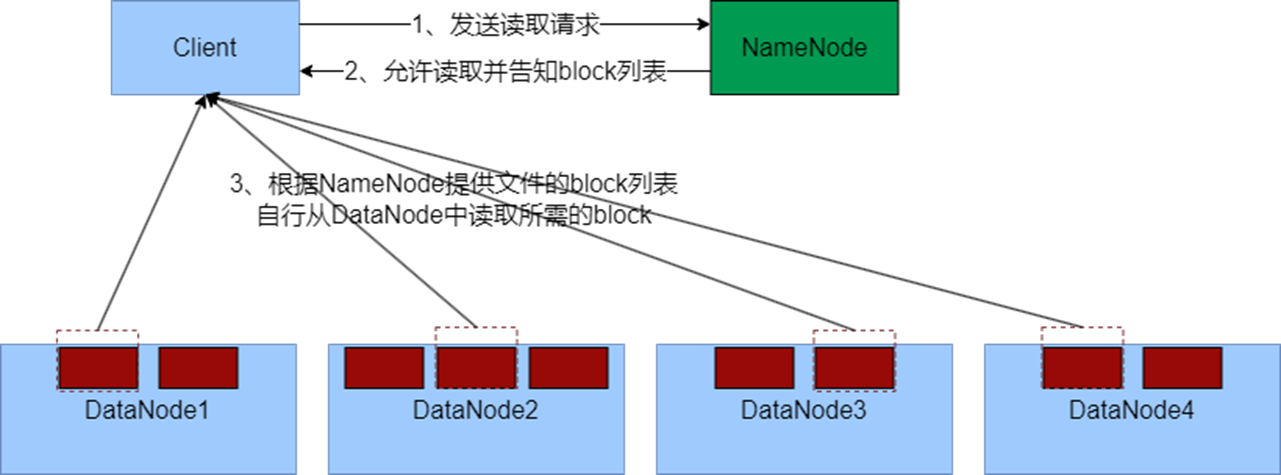
1、客户端向NameNode申请读取某文件
2、 NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表
3、客户端拿到block列表后自行寻找DataNode读取即可
关键点:
数据同样不通过NameNode提供
NameNode提供的block列表,会基于网络距离计算尽量提供离客户端最近的
这是因为1个block有3份,会尽量找离客户端最近的那一份让其读取。
最难不过坚持,继续下一关~✨
相关文章:
大数据技术之Hadoop:HDFS存储原理篇(五)
目录 一、原理介绍 1.1 Block块 1.2 副本机制 二、fsck命令 2.1 设置默认副本数量 2.2 临时设置文件副本大小 2.3 fsck命令检查文件的副本数 2.4 block块大小的配置 三、NameNode元数据 3.1 NameNode作用 3.2 edits文件 3.3 FSImage文件 3.4 元素据合并控制参数 …...

用C语言实现牛顿摆控制台动画
题目 用C语言实现牛顿摆动画,模拟小球的运动,如图所示 拆解 通过控制台API定位输出小球运动的只是2边小球,中间小球不运动,只需要固定位置输出左边小球上升下降时,X、Y轴增量一致。右边小球上升下降时,X、…...

如何自己开发一个前端监控SDK
最近在负责团队前端监控系统搭建的任务。因为我们公司有统一的日志存储平台、日志清洗平台和基于 Grafana 搭建的可视化看板,就剩日志的采集和上报需要自己实现了,所以决定封装一个前端监控 SDK 来完成日志的采集和上报。 架构设计 因为想着以后有机会…...
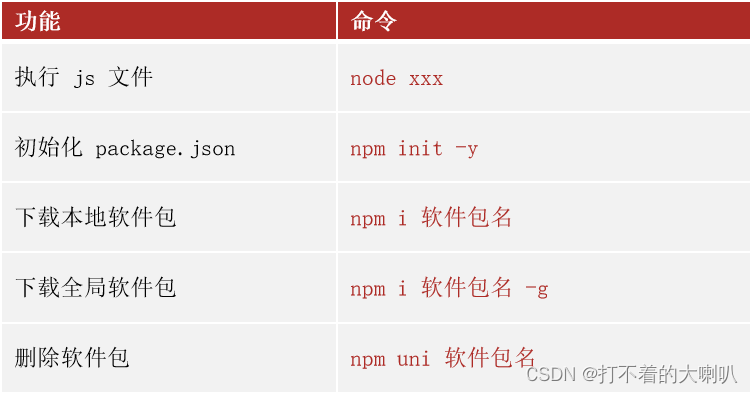
node.js笔记
首先:浏览器能执行 JS 代码,依靠的是内核中的 V8 引擎(C 程序) 其次:Node.js 是基于 Chrome V8 引擎进行封装(运行环境) 区别:都支持 ECMAScript 标准语法,Node.js 有独立…...
mysql 增量备份与恢复使用详解
目录 一、前言 二、数据备份策略 2.1 全备 2.2 增量备份 2.3 差异备份 三、mysql 增量备份概述 3.1 增量备份实现原理 3.1.1 基于日志的增量备份 3.1.2 基于时间戳的增量备份 3.2 增量备份常用实现方式 3.2.1 基于mysqldump增量备份 3.2.2 基于第三方备份工具进行增…...

9月5日上课内容 第一章 NoSQL之Redis配置与优化
本章结构 关系型数据库和非关系型数据库 概念介绍 ●关系型数据库: 关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。 SQL 语句(标准数据查询语言)就是…...

QT 第四天
一、设置一个闹钟 .pro QT core gui texttospeechgreaterThan(QT_MAJOR_VERSION, 4): QT widgetsCONFIG c11# The following define makes your compiler emit warnings if you use # any Qt feature that has been marked deprecated (the exact warnings # depend…...

nrf52832 GPIO输入输出设置
LED_GPIO #define LED_START 17 #define LED_0 17 #define LED_1 18 #define LED_2 19 #define LED_3 20 #define LED_STOP 20设置位输出模式: nrf_gpio_cfg_output(LED_0); 输出高电平:nrf_gpio_pin_set(LED_0); 输…...
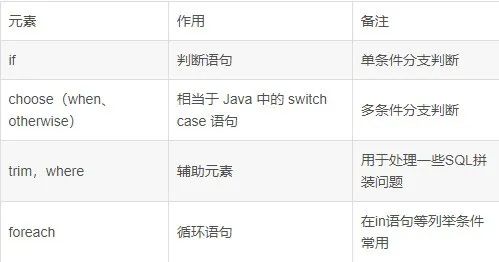
MyBatis 动态 SQL 实践教程
一、MyBatis动态 sql 是什么 动态 SQL 是 MyBatis 的强大特性之一。在 JDBC 或其它类似的框架中,开发人员通常需要手动拼接 SQL 语句。根据不同的条件拼接 SQL 语句是一件极其痛苦的工作。例如,拼接时要确保添加了必要的空格,还要注意去掉列…...

CSS 斜条纹进度条
效果: 代码: html: <div class"active-line flex"><!-- lineWidth:灰色背景 --><div class"bg-line"><div v-for"n in 30" class"gray"></div></div><div…...
每天10个小知识点)
JavaScript(1)每天10个小知识点
目录 1. JavaScript 有哪些数据类型,它们的区别?**2. 数据类型检测的方式有哪些**3. null 和 undefined 区别**4. intanceof 操作符的实现原理及实现**5. 如何获取安全的 undefined 值?**6. Object.is() 与比较操作符 “”、“” 的区别*…...

scanf和scanf_s函数详解
目录 引言: 1.scanf函数的用法: 2.scanf_s函数的用法: 3.scanf和scanf_s的区别: 结论: 引言: 在C语言中,输入函数scanf是非常常用的函数之一,它可以从标准输入流中读取数据并将其…...
基于SSM的在线购物系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用JSP技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...
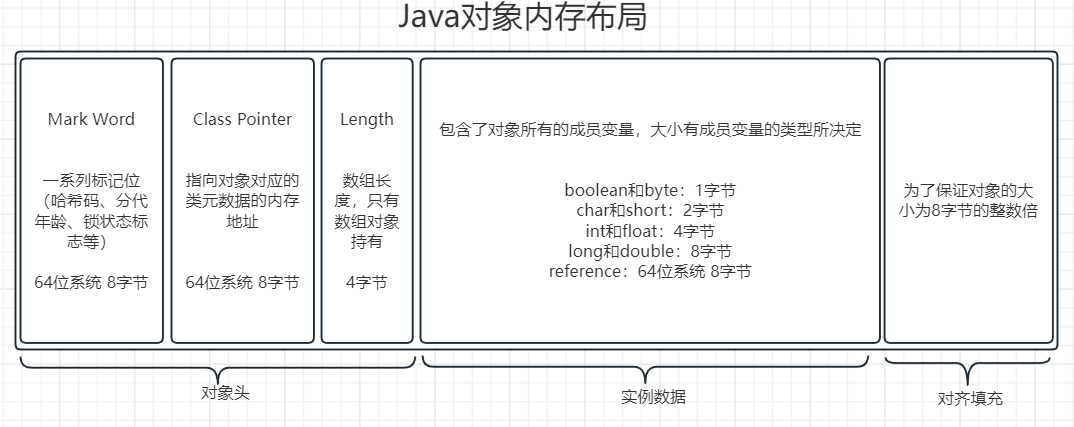
认识JVM的内存模型
从上一节了解到整个JVM大的内存区域,分为线程共享的heap(堆),MethodArea(方法区),和线程独享的 The pc Register(程序计数器)、Java Virtual Machine Stacks(…...
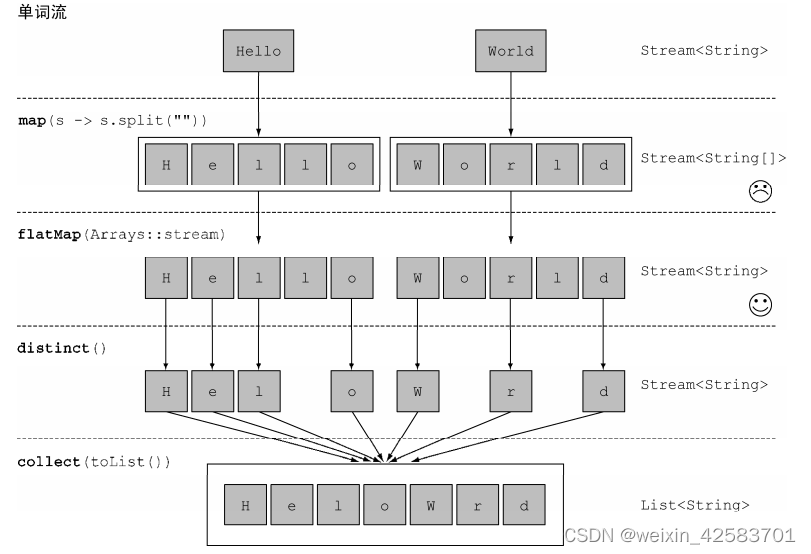
Java8实战-总结19
Java8实战-总结19 使用流映射对流中每一个元素应用函数流的扁平化 使用流 映射 一个非常常见的数据处理套路就是从某些对象中选择信息。比如在SQL里,你可以从表中选择一列。Stream API也通过map和flatMap方法提供了类似的工具。 对流中每一个元素应用函数 流支持…...

论文浅尝 | 训练语言模型遵循人类反馈的指令
笔记整理:吴亦珂,东南大学硕士,研究方向为大语言模型、知识图谱 链接:https://arxiv.org/abs/2203.02155 1. 动机 大型语言模型(large language model, LLM)可以根据提示完成各种自然语言处理任务。然而&am…...

【云计算网络安全】解析DDoS攻击:工作原理、识别和防御策略 | 文末送书
文章目录 一、前言二、什么是 DDoS 攻击?三、DDoS 攻击的工作原理四、如何识别 DDoS 攻击五、常见的 DDoS 攻击有哪几类?5.1 应用程序层攻击5.1.1 攻击目标5.1.2 应用程序层攻击示例5.1.3 HTTP 洪水 5.2 协议攻击5.2.1 攻击目标5.2.2 协议攻击示例5.2.3 …...

64位Linux系统上安装64位Oracle10gR2及Oracle11g所需的依赖包
在64位Linux系统上安装64位Oracle 10gR2,到底需要装哪些包? 这不是一个完整的安装教程,仅仅探讨在64位CentOS 5.8系统上安装64位Oracle 10gR2,到底需要装哪些RPM包. 实验环境VMWare Workstation 8.0 Linux发行版: CentOS 5.8 x86_64 Kernel版本: 2.6.18-308.el5 Oracle Dat…...

Unity InputSystem 基础使用之鼠标交互
资料 官方文档 导入InputSystem包 Package Manager 搜索Input System进行下载启用该包,会重启Unity Editor 注意 InputSystem可以和旧版输入系统一起使用 设置:Project Settings->Player->Other Settings->Configuration->Active Input…...

《算法竞赛·快冲300题》每日一题:“二进制数独”
《算法竞赛快冲300题》将于2024年出版,是《算法竞赛》的辅助练习册。 所有题目放在自建的OJ New Online Judge。 用C/C、Java、Python三种语言给出代码,以中低档题为主,适合入门、进阶。 文章目录 题目描述题解C代码Java代码Python代码 “ 二…...

Git Conflict Resolution
1. 这篇文章解决什么问题? Git 冲突不是异常情况,而是多人协作和分支开发里的正常现象。 常见问题包括: 1. 为什么会产生冲突? 2. 冲突文件里的 <<<<<<<、、>>>>>>> 是什么?…...

别再死磕外链了:用Python+搜索API实现Google SEO自动化内容生产
做Google SEO的人都有一个共同感受:越来越难了。 以前发发外链、堆堆锚文本就能上去,现在不行了。Google的算法从"匹配关键词"进化到了"匹配搜索意图"。外链权重从60%降到30%,内容质量成了核心排名因素。 但问题是&#…...

Photoshop AVIF插件实战:解锁下一代图像格式的完整解决方案
Photoshop AVIF插件实战:解锁下一代图像格式的完整解决方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 为Adobe Photoshop添加AVIF格式支持不再…...

大模型压缩实战:量化、剪枝与知识蒸馏技术解析与应用
1. 项目概述:当大模型遇见“瘦身”革命最近在跟几个做AI应用落地的朋友聊天,大家普遍都在吐槽一个事儿:现在的大语言模型(LLM)能力是强,但动辄几十亿、上百亿的参数规模,部署成本高得吓人&#…...

新手入门教程使用curl命令直连Taotoken测试大模型聊天补全接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门教程:使用curl命令直连Taotoken测试大模型聊天补全接口 本文面向刚接触API调用的开发者,旨在指导如…...

喜马拉雅音频本地化实战:绕过xm格式,直接获取mp3文件的两种方法对比
喜马拉雅音频本地化实战:两种高效获取MP3文件的技术方案深度评测 作为国内领先的音频分享平台,喜马拉雅拥有海量优质内容,但其特有的XM格式却给用户跨平台使用带来了困扰。许多技术爱好者尝试过各种转换工具,却发现市面上几乎没有…...

【Oracle数据库指南】第06篇:Oracle DML语句与事务控制——数据操作与ACID特性深度解析
上一篇【第05篇】Oracle子查询与集合操作——嵌套查询与结果合并全解析 下一篇【第07篇】SQL*Plus基础——登录、环境设置与缓冲区操作 摘要 本文全面讲解Oracle DML(数据操作语言)语句,包括INSERT、UPDATE、DELETE和MERGE的详细用法&#x…...

在Node.js后端服务中集成Taotoken调用多模型API实战
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken调用多模型API实战 构建需要AI能力的Web服务时,后端开发者常面临模型选型、API接入复…...

Capital许可排队严重?不想买新许可,闲置回收立即可用
我去年在做项目时,客户说他们Capital许可证池天天爆队,新增用户连基本的算力都抢不到。当时我就琢磨,许可证回收这事儿到底有多重要?去年底我带着团队做了一个实验,直接把闲置许可证利用率干到45%,127个许可…...

AI安全控制框架:应对能力超越控制的风险与韧性防御策略
1. 项目概述:当能力超越控制“Project Glasswing”这个名字本身就充满了隐喻。玻璃翼,轻盈、透明、脆弱,却又能在阳光下折射出复杂的光谱。这像极了我们今天要讨论的核心议题:人工智能的能力边界正以前所未有的速度扩张࿰…...