Python爬虫 教程:IP池的使用
前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取
一、简介
爬虫中为什么需要使用代理
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会禁止这个IP的访问。
所以我们需要设置一些代理IP,每隔一段时间换一个代理IP,就算IP被禁止,依然可以换个IP继续爬取。
代理的分类:
-
正向代理:代理客户端获取数据。正向代理是为了保护客户端防止被追究责任。
-
反向代理:代理服务器提供数据。反向代理是为了保护服务器或负责负载均衡。
免费代理ip提供网站
-
http://www.goubanjia.com/
-
西刺代理
-
快代理
匿名度:
-
透明:知道是代理ip,也会知道你的真实ip
-
匿名:知道是代理ip,不会知道你的真实ip
-
高匿:不知道是代理ip,不会知道你的真实ip
类型:
-
http:只能请求http开头的url
-
https:只能请求https开头的url
示例
import requests
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
url = 'https://www.baidu.com/s?wd=ip'# 不同的代理IP,代理ip的类型必须和请求url的协议头保持一致
proxy_list = [{"http": "112.115.57.20:3128"}, {'http': '121.41.171.223:3128'}
]# 随机获取代理IP
proxy = random.choice(proxy_list)page_text = requests.get(url=url,headers=headers,proxies=proxy).textwith open('ip.html','w',encoding='utf-8') as fp:fp.write(page_text)print('over!')
二、IP池
1、免费IP池
从西刺代理上面爬取IP,迭代测试能否使用,
建立一个自己的代理IP池,随时更新用来抓取网站数据

'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import requests
from lxml import etree
import time
import random
from fake_useragent import UserAgentclass GetProxyIP(object):def __init__(self):self.url = 'https://www.xicidaili.com/nn/'self.proxies = {'http': 'http://163.204.247.219:9999','https': 'http://163.204.247.219:9999'}# 随机生成User-Agentdef get_random_ua(self):ua = UserAgent() # 创建User-Agent对象useragent = ua.randomreturn useragent# 从西刺代理网站上获取随机的代理IPdef get_ip_file(self, url):headers = {'User-Agent': self.get_random_ua()}html = requests.get(url=url, proxies=self.proxies, headers=headers, timeout=5).content.decode('utf-8', 'ignore')parse_html = etree.HTML(html) tr_list = parse_html.xpath('//tr') # 基准xpath,匹配每个代理IP的节点对象列表for tr in tr_list[1:]:ip = tr.xpath('./td[2]/text()')[0]port = tr.xpath('./td[3]/text()')[0] self.test_proxy_ip(ip, port) # 测试ip:port是否可用# 测试抓取的代理IP是否可用def test_proxy_ip(self, ip, port):proxies = {'http': 'http://{}:{}'.format(ip, port),'https': 'https://{}:{}'.format(ip, port), }test_url = 'http://www.baidu.com/'try:res = requests.get(url=test_url, proxies=proxies, timeout=8)if res.status_code == 200:print(ip, ":", port, 'Success')with open('proxies.txt', 'a') as f:f.write(ip + ':' + port + '\n')except Exception as e:print(ip, port, 'Failed')def main(self):for i in range(1, 1001):url = self.url.format(i)self.get_ip_file(url)time.sleep(random.randint(5, 10))if __name__ == '__main__':spider = GetProxyIP()spider.main()
从IP池中取IP,也就是在爬虫程序中从文件随机获取代理IP
import random
import requestsclass BaiduSpider(object):def __init__(self):self.url = 'http://www.baidu.com/'self.headers = {'User-Agent': 'Mozilla/5.0'}self.flag = 1def get_proxies(self):with open('proxies.txt', 'r') as f:result = f.readlines() # 读取所有行并返回列表proxy_ip = random.choice(result)[:-1] # 获取了所有代理IPL = proxy_ip.split(':')proxy_ip = {'http': 'http://{}:{}'.format(L[0], L[1]),'https': 'https://{}:{}'.format(L[0], L[1])}return proxy_ipdef get_html(self):proxies = self.get_proxies()if self.flag <= 3:try:html = requests.get(url=self.url, proxies=proxies, headers=self.headers, timeout=5).textprint(html)except Exception as e:print('Retry')self.flag += 1self.get_html()if __name__ == '__main__':spider = BaiduSpider()spider.get_html()
2.收费代理API
写一个获取收费开放API代理的接口
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import requests
from fake_useragent import UserAgentua = UserAgent() # 创建User-Agent对象
useragent = ua.random
headers = {'User-Agent': useragent}def ip_test(ip):url = 'http://www.baidu.com/'ip_port = ip.split(':')proxies = {'http': 'http://{}:{}'.format(ip_port[0], ip_port[1]),'https': 'https://{}:{}'.format(ip_port[0], ip_port[1]),}res = requests.get(url=url, headers=headers, proxies=proxies, timeout=5)if res.status_code == 200:return Trueelse:return False# 提取代理IP
def get_ip_list():# 快代理:https://www.kuaidaili.com/doc/product/dps/api_url = 'http://dev.kdlapi.com/api/getproxy/?orderid=946562662041898&num=100&protocol=1&method=2&an_an=1&an_ha=1&sep=2'html = requests.get(api_url).content.decode('utf-8', 'ignore')ip_port_list = html.split('\n')for ip in ip_port_list:with open('proxy_ip.txt', 'a') as f:if ip_test(ip):f.write(ip + '\n')if __name__ == '__main__':get_ip_list()
3.私密代理
语法结构
用户名和密码会在给API_URL的时候给。不是自己的账号和账号密码。
proxies = {
'协议':'协议://用户名:密码@IP:端口号'
}
proxies = {'http':'http://用户名:密码@IP:端口号','https':'https://用户名:密码@IP:端口号'
}
proxies = {'http': 'http://309435365:szayclhp@106.75.71.140:16816','https':'https://309435365:szayclhp@106.75.71.140:16816',
}
获取开放代理的接口
import requests
from fake_useragent import UserAgentua = UserAgent() # 创建User-Agent对象
useragent = ua.random
headers = {'User-Agent': useragent}
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''def ip_test(ip):url = 'https://blog.csdn.net/qq_34218078/article/details/90901602/'ip_port = ip.split(':')proxies = {'http': 'http://1786088386:b95djiha@{}:{}'.format(ip_port[0], ip_port[1]),'https': 'http://1786088386:b95djiha@{}:{}'.format(ip_port[0], ip_port[1]),}res = requests.get(url=url, headers=headers, proxies=proxies, timeout=5)if res.status_code == 200:print("OK")return Trueelse:print(res.status_code)print("错误")return False# 提取代理IP
def get_ip_list():# 快代理:https://www.kuaidaili.com/doc/product/dps/api_url = 'http://dps.kdlapi.com/api/getdps/?orderid=986603271748760&num=1000&signature=z4a5b2rpt062iejd6h7wvox16si0f7ct&pt=1&sep=2'html = requests.get(api_url).content.decode('utf-8', 'ignore')ip_port_list = html.split('\n')for ip in ip_port_list:with open('proxy_ip.txt', 'a') as f:if ip_test(ip):f.write(ip + '\n')if __name__ == '__main__':get_ip_list()
思路:
-
写一个类;
-
get_ip() requests请求接口,得到ip和port;
-
test_ip()请求某一网站,根据状态码或in判断是否有某一内容来判断此ip是否可用,返回Ture和False即可;
-
save_ip()测试成功后保存;
尾语
最后感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。

相关文章:
Python爬虫 教程:IP池的使用
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 一、简介 爬虫中为什么需要使用代理 一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率…...

Ansible之playbook剧本
一、playbook概述1.1 playbook 介绍1.2 playbook 组成部分 二、playbook 示例2.1 playbook 启动及检测2.2 实例一2.3 vars 定义、引用变量2.4 指定远程主机sudo切换用户2.5 when条件判断2.6 迭代2.7 Templates 模块1.先准备一个以 .j2 为后缀的 template 模板文件,设…...
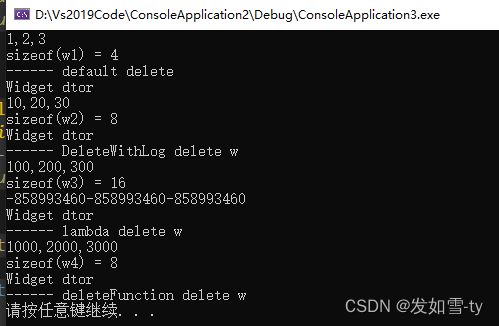
unique_ptr的大小探讨
unique_ptr大小和删除器有很大关系,具体区别看如下代码的分析。不要让unique_ptr占用的空间太大,否则不会达到裸指针同样的效果。 #include <iostream> #include <memory> using namespace std;class Widget {int m_x;int m_y;int m_z;publ…...

人工智能TensorFlow PyTorch物体分类和目标检测合集【持续更新】
1. 基于TensorFlow2.3.0的花卉识别 基于TensorFlow2.3.0的花卉识别Android APP设计_基于安卓的花卉识别_lilihewo的博客-CSDN博客 2. 基于TensorFlow2.3.0的垃圾分类 基于TensorFlow2.3.0的垃圾分类Android APP设计_def model_load(img_shape(224, 224, 3)_lilihewo的博客-CS…...

ElementPlus·面包屑导航实现
面包屑导航 使用vue3中的UI框架elementPlus的 <el-breadcrumb> 实现面包屑导航 <template><!-- 面包屑 --><div class"bread-container" ><el-breadcrumb separator">"><el-breadcrumb-item :to"{ path:/ }&quo…...

【项目管理】PM vs PMO 18点区别
导读:项目经理跟PMO主要有哪些区别?首先从定义上了解,然后根据其他维度进行对比分析,基本可以了解这二者的区别,文中罗列18点区别供各位参考。 目录 1、定义 1.1 PMO 1.2 PM 2、两者区别 2.1 ROI 2.2 项目成功率…...

13 Python使用Json
概述 在上一节,我们介绍了如何在Python中使用xml,包括:SAX、DOM、ElementTree等内容。在这一节,我们将介绍如何在Python中使用Json。Json的英文全称为JavaScript Object Notation,中文为JavaScript对象表示法ÿ…...

PDFBOX和ASPOSE.PDF
一、aspose.pdf 文档 https://docs.aspose.com/pdf/java/ 1、按段落分段 /*** docx文本按段分段*/ public static void main(String[] args) {int i 1;try {// 打开文件流FileInputStream file new FileInputStream("I:\\范文.docx");// 创建 Word 文档对象XWPFDo…...

第51节:cesium 范围查询(含源码+视频)
结果示例: 完整源码: <template><div class="viewer"><el-button-group class="top_item"><el-button type=...

YOLOv5改进算法之添加CA注意力机制模块
目录 1.CA注意力机制 2.YOLOv5添加注意力机制 送书活动 1.CA注意力机制 CA(Coordinate Attention)注意力机制是一种用于加强深度学习模型对输入数据的空间结构理解的注意力机制。CA 注意力机制的核心思想是引入坐标信息,以便模型可以更好地…...
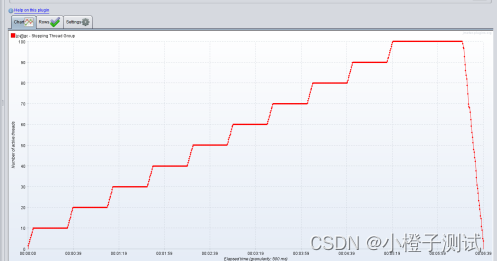
Jmeter系列-阶梯加压线程组Stepping Thread Group详解(6)
前言 tepping Thread Group是第一个自定义线程组但,随着版本的迭代,已经有更好的线程组代替Stepping Thread Group了【Concurrency Thread Group】,所以说Stepping Thread Group已经是过去式了,但还是介绍一下 Stepping Thread …...

图像的几何变换(缩放、平移、旋转)
图像的几何变换 学习目标 掌握图像的缩放、平移、旋转等了解数字图像的仿射变换和透射变换 1 图像的缩放 缩放是对图像的大小进行调整,即 使图像放大或缩小 cv2.resize(src,dsize,fx0,fy0,interpolationcv2.INTER_LINEAR) 参数: src :输入图像dsize…...

计算机网络第四章——网络层(上)
提示:朝碧海而暮苍梧,睹青天而攀白日 文章目录 网络层是路由器的最高层次,通过网络层就可以将各个设备连接到一起,从而实现这两个主机的数据通信和资源共享,之前学的数据链路层和物理层也是将两端连接起来,但是却没有网…...

【MyBatis】一、MyBatis概述与基本使用
Mybatis概述 Mybatis是一个半自动化的框架,需要自己写sql语句,对比JDBC其有耦合性更低的SQL语句与Java代码,各司其职不相互冗杂,对比Hibernate与JPA其又有更灵活的SQL编写能力。 环境搭建 引入相关依赖并打jar包 <dependenc…...

Java事件机制简介 内含面试题
面试题分享 云数据解决事务回滚问题 点我直达 2023最新面试合集链接 2023大厂面试题PDF 面试题PDF版本 java、python面试题 项目实战:AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮…...

springMVC基础技术使用
目录 1.常用注解 1.1RequestMapping 1.2.RequestParam 1.3.RequestBody 1.4.PathVariable 2.参数传递 2.1 slf4j-----日志 2.2基础类型 2.3复杂类型 2.4RequestParam 2.5PathVariable 2.6RequestBody 2.7请求方法(增删改查) 3.返回值 3.1void …...

UI设计师的发展前景是否超越了平面设计?
这是一个现代经济学的典型话题:应该跟随趋势追逐风口,还是坚守成熟的“夕阳产业” UI 设计行业发展短短不过 20 多年,但平面设计这个“夕阳产业”最早可以追溯到上世纪的二三十年代。显而易见的答案是,更新兴的 UI 设计师得到的好…...

MyBatis的基本操作
目录 一、MyBatis的增删改查1、添加2、删除3、修改4、查询一个实体类对象5、查询集合 二、MyBatis的各种查询功能1、查询一个实体类对象2、查询一个list集合3、查询单个数据4、查询一条数据为map集合5、查询多条数据为map集合 三、特殊SQL的执行1、模糊查询2、批量删除3、动态设…...

【Tomcat】在SpringBoot项目中,Tomcat是如何处理HTTP请求的
目录 首先了解一下标准的Tomcat处理HTTP请求的流程 SpringBoot项目中Tomcat处理流程 首先了解一下标准的Tomcat处理HTTP请求的流程 监听端口:Tomcat 在启动时监听指定的端口,等待客户端发送请求。 接收请求:当客户端发起一个 HTTP 请…...

python开发基础篇1——后端操作K8s API方式
文章目录 一、基本了解1.1 操作k8s API1.2 基本使用 二、数据表格展示K8s常见资源2.1 Namespace2.2 Node2.3 PV2.4 Deployment2.5 DaemonSet2.6 StatefulSet2.7 Pod2.8 Service2.9 Ingress2.10 PVC2.11 ConfigMap2.12 Secret2.13 优化 一、基本了解 操作K8s资源api方式…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

HoRain云--CLAUDE.md 使用指南
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...

3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南
3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南 【免费下载链接】Whisper-WebUI A Web UI for easy subtitle using whisper model. 项目地址: https://gitcode.com/gh_mirrors/wh/Whisper-WebUI 还在为视频制作繁琐的字幕而烦恼吗?Whis…...

UE5 Cesium项目里,如何把默认的飞行Pawn换成建筑漫游Pawn?保姆级迁移教程
UE5 Cesium项目建筑漫游Pawn迁移实战:从飞行模式到精细化浏览的完整指南当你在UE5中结合Cesium插件构建数字孪生场景时,DynamicPawn提供的全球飞行体验令人印象深刻。但当视角聚焦到单体建筑或室内空间时,那种仿佛操控无人机般的操作方式就显…...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...

从SIM800到BK A7670E:4G Cat.1模块硬件平替转接板设计全解析
1. 项目概述:从2G到4G的硬件平替升级 手头有个老项目,用的还是SIM800这种经典的2G模块,现在网络环境变了,2G退网是大势所趋,信号覆盖越来越差,项目得活下去,升级到4G成了刚需。但问题来了&#…...

如何永久保存微信聊天记录?WeChatMsg终极数据导出指南
如何永久保存微信聊天记录?WeChatMsg终极数据导出指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...