【Spark分布式内存计算框架——离线综合实战】5. 业务报表分析
第三章 业务报表分析
一般的系统需要使用报表来展示公司的运营情况、 数据情况等,本章节对数据进行一些常见报表的开发,广告数据业务报表数据流向图如下所示:

具体报表的需求如下:

相关报表开发说明如下:
- 第一、数据源:每天的日志数据,即ETL的结果数据,存储在Hive分区表,依据分区查询数据;
- 第二、报表分为两大类:基础报表统计(上图中①)和广告投放业务报表统计(上图中②);
- 第三、不同类型的报表的结果存储在MySQL不同表中,上述7个报表需求存储7个表中:
各地域分布统计:region_stat_analysis
广告区域统计:ads_region_analysis
广告APP统计:ads_app_analysis
广告设备统计:ads_device_analysis
广告网络类型统计:ads_network_analysis
广告运营商统计:ads_isp_analysis
广告渠道统计:ads_channel_analysis
- 第四、由于每天统计为定时统计,各个报表中加上统计日期字段:report_date;
3.1 报表运行主类
所有业务报表统计放在一个应用程序中,在实际运行时,要么都运行,要么都不运行,创建报表运行主类:PmtReportRunner.scala,将不同业务报表需求封装到不同类中进行单独处理,其中编程逻辑思路如下:
// 1. 创建SparkSession实例对象
// 2. 从Hive表中加载广告ETL数据,日期过滤
// 3. 依据不同业务需求开发报表
// 4. 应用结束,关闭资源
具体代码PmtReportRunner.scala如下:
package cn.itcast.spark.report
import cn.itcast.spark.utils.SparkUtils
import org.apache.spark.sql.functions.{current_date, date_sub}
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.storage.StorageLevel
/**
* 针对广告点击数据,依据需求进行报表开发,具体说明如下:
* - 各地域分布统计:region_stat_analysis
* - 广告区域统计:ads_region_analysis
* - 广告APP统计:ads_app_analysis
* - 广告设备统计:ads_device_analysis
* - 广告网络类型统计:ads_network_analysis
* - 广告运营商统计:ads_isp_analysis
* - 广告渠道统计:ads_channel_analysis
*/
object PmtReportRunner {
def main(args: Array[String]): Unit = {
// 设置Spark应用程序运行的用户:root, 默认情况下为当前系统用户
System.setProperty("user.name", "root")
System.setProperty("HADOOP_USER_NAME", "root")
// 1. 创建SparkSession实例对象
val spark: SparkSession = SparkUtils.createSparkSession(this.getClass)
import spark.implicits._
// 2. 从Hive表中加载广告ETL数据
val pmtDF: DataFrame = spark.read
.table("itcast_ads.pmt_ads_info")
.where($"date_str" === date_sub(current_date(), 1))
//pmtDF.printSchema()
//pmtDF.select("uuid", "ip", "province", "city").show(20, truncate = false)
// 如果没有加载到数据,结束程序
if(pmtDF.isEmpty){
System.exit(-1)
}
// TODO: 由于多张报表的开发,使用相同的数据,所以缓存
pmtDF.persist(StorageLevel.MEMORY_AND_DISK)
// 3. 依据不同业务需求开发报表
/*
不同业务报表统计分析时,两步骤:
i. 编写SQL或者DSL分析
ii. 将分析结果保存MySQL数据库表中
*/
// 3.1. 地域分布统计:region_stat_analysis
//RegionStateReport.doReport(pmtDF)
// 3.2. 广告区域统计:ads_region_analysis
//AdsRegionAnalysisReport.doReport(pmtDF)
// 3.3. 广告APP统计:ads_app_analysis
//AdsAppAnalysisReport.processData(pmtDF)
// 3.4. 广告设备统计:ads_device_analysis
//AdsDeviceAnalysisReport.processData(pmtDF)
// 3.5. 广告网络类型统计:ads_network_analysis
//AdsNetworkAnalysisReport.processData(pmtDF)
// 3.6. 广告运营商统计:ads_isp_analysis
//AdsIspAnalysisReport.processData(pmtDF)
// 3.7. 广告渠道统计:ads_channel_analysis
//AdsChannelAnalysisReport.processData(pmtDF)
// 数据不再使用,释放资源
pmtDF.unpersist()
// 4. 应用结束,关闭资源
//Thread.sleep(1000000)
spark.stop()
}
}
上述代码中,考虑到如果要处理昨日广告数据ETL没有完成,那么Hive分区表中没有数据,所以加载数据以后,调用DataFrame.isEmpty判断是否不为空。
3.2 各地域数量分布
按照地域(省份province和城市city)统计广告数据分布情况,看到不同地区有多少数据,从而能够地区优化公司运营策略,最终结果如下图所示:

数据库创建表
在MySQL数据库中创建数据库【itcast_ads_report】和表【region_stat_analysis】,DDL语句:
-- 创建数据库,不存在时创建
-- DROP DATABASE IF EXISTS itcast_ads_report;
CREATE DATABASE IF NOT EXISTS itcast_ads_report;
USE itcast_ads_report;
-- 创建表
-- DROP TABLE IF EXISTS itcast_ads_report.region_stat_analysis ;
CREATE TABLE `itcast_ads_report`.`region_stat_analysis` (
`report_date` varchar(255) NOT NULL,
`province` varchar(255) NOT NULL,
`city` varchar(255) NOT NULL
`count` bigint DEFAULT NULL,
PRIMARY KEY (`report_date`,`province`,`city`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
后面将报表结果数据保存MySQL表中时,采用的是自己编写代码,并不使用DataFrame自带format(“jdbc”)方式,不能满足需求:当某日报表统计程序运行多次时,插入数据到结果表中,采用Append最佳方式,主键冲突;采用OverWrite方式,将会将表删除,以前统计结果也都删除。因此,调用DataFrame中foreachPartition方法,将每个分区数据保存到表中,INSTER语句:
INSERT
INTO
itcast_ads_report.region_stat_analysis
(report_date, province, city, count)
VALUES
(?, ?, ?, ?)
ON DUPLICATE KEY UPDATE
count=VALUES(count) ;
说明:Navicate 连接MySQL8 时,可以会报错,进行如下相关设置:
SHOW VARIABLES LIKE 'validate_password%';
/*
+--------------------------------------+--------+
| Variable_name | Value |
+--------------------------------------+--------+
| validate_password.check_user_name | ON |
| validate_password.dictionary_file | |
| validate_password.length | 8 |
| validate_password.mixed_case_count | 1 |
| validate_password.number_count | 1 |
| validate_password.policy | MEDIUM |
| validate_password.special_char_count | 1 |
+--------------------------------------+--------+
*/
set global validate_password.policy=LOW;
set global validate_password.length = 6 ;
SHOW VARIABLES LIKE 'validate_password%';
/*
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| validate_password.check_user_name | ON |
| validate_password.dictionary_file | |
| validate_password.length | 6 |
| validate_password.mixed_case_count | 1 |
| validate_password.number_count | 1 |
| validate_password.policy | LOW |
| validate_password.special_char_count | 1 |
+--------------------------------------+-------+
*/
flush privileges;
SELECT user,host,plugin from mysql.user ;
/*
+------------------+-----------+-----------------------+
| user | host | plugin |
+------------------+-----------+-----------------------+
| root | % | caching_sha2_password |
| mysql.infoschema | localhost | caching_sha2_password |
| mysql.session | localhost | caching_sha2_password |
| mysql.sys | localhost | caching_sha2_password |
+------------------+-----------+-----------------------+
*/
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
编写SQL
在Beeline客户端,编写SQL语句,完成报表开发需求,语句如下:
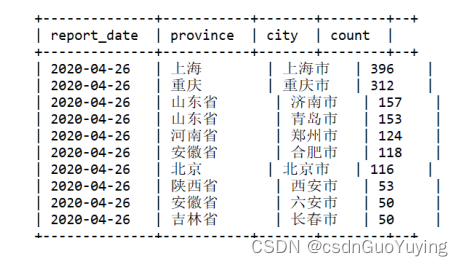
SELECT CAST(DATE_SUB(NOW(), 1) AS STRING) AS report_date,
province,
city,
COUNT(1) AS count
FROM itcast_ads.pmt_ads_info
WHERE date_str="2020-04-25"
GROUP BY province, city
ORDER BY count
DESC LIMIT 10 ;
执行语句返回结果截图:
报表开发
编写【RegionStateReport.scala】类,创建【doReport】方法,接收DataFrame为参数,进行报表统计,并最终保存至MySQL表中,封装保存结果数据代码至saveToMySQL方法中。
1)、业务实现代码
package cn.itcast.spark.report
import cn.itcast.spark.config.ApplicationConfig
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.{DataFrame, Row, SaveMode}
/**
* 报表开发:按照地域维度(省份和城市)分组统计广告被点击次数
* 地域分布统计:region_stat_analysis
*/
object RegionStateReport {
/**
* 不同业务报表统计分析时,两步骤:
* i. 编写SQL或者DSL分析
* ii. 将分析结果保存MySQL数据库表中
*/
def doReport(dataframe: DataFrame): Unit = {
// 导入隐式转换及函数库
import dataframe.sparkSession.implicits._
import org.apache.spark.sql.functions._
// i. 使用DSL(调用DataFrame API)报表开发
val resultDF: DataFrame = dataframe
// 按照地域维度分组(省份和城市)
.groupBy($"province", $"city")
// 直接count函数统计,列名称为count
.count()
// 按照次数进行降序排序
.orderBy($"count".desc)
// 添加报表字段(报表统计的日期)
.withColumn(
"report_date", // 报表日期字段
// TODO:首先获取当前日期,再减去1天获取昨天日期,转换为字符串类型
date_sub(current_date(), 1).cast(StringType)
)
//resultDF.printSchema()
resultDF.show(50, truncate = false)
// ii. 保存分析报表结果到MySQL表中
//saveResultToMySQL(resultDF)
// 将DataFrame转换为RDD操作,或者转换为Dataset操作
//resultDF.coalesce(1).rdd.foreachPartition(iter => saveToMySQL(iter))
}
}
运行PmtReportRunner报表主类程序,结果如下:

2)、可以直接使用DataFrame.format(“jdbc”)至MySQL表
/**
* 保存数据至MySQL表中,直接使用DataFrame Writer操作,但是不符合实际应用需求
*/
def saveResultToMySQL(dataframe: DataFrame): Unit = {
dataframe
.coalesce(1)
.write
// Overwrite表示,当表存在时,先删除表,再创建表和插入数据, 所以不用此种方式
//.mode(SaveMode.Overwrite)
// TODO: 当多次运行程序时,比如对某日广告数据报表分析运行两次,由于报表结果主键存在数据库表中,产生
冲突,导致报错失败
.mode(SaveMode.Append)
.format("jdbc")
// 设置MySQL数据库相关属性
.option("driver", ApplicationConfig.MYSQL_JDBC_DRIVER)
.option("url", ApplicationConfig.MYSQL_JDBC_URL)
.option("user", ApplicationConfig.MYSQL_JDBC_USERNAME)
.option("password", ApplicationConfig.MYSQL_JDBC_PASSWORD)
.option("dbtable", "itcast_ads_report.region_stat_analysis")
.save()
}
保存方式选择Append追加或覆写Overwrite,都会出现问题,所以在实际项目开发中,使用SparkSQL分析数据报表报错数据库时,往往不会使用dataframe.write.jdbc方式。
3)、自己编写JDBC代码,插入数据到数据库表中:当主键存在时更新值,不存在时插入值。
/**
* 方式一:
* REPLACE INTO test(title,uid) VALUES ('1234657','1003');
* 方式二:
* INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1;
*/
定义方法【saveToMySQL】传递参数【Iterator[Row]:每个分区数据】,代码如下:
import java.sql.{Connection, DriverManager, PreparedStatement}
/**
* 保存数据至MySQL数据库,使用函数foreachPartition对每个分区数据操作,主键存在时更新,不存在时插入
*/
def saveToMySQL(datas: Iterator[Row]): Unit = {
// a. 加载驱动类
Class.forName(ApplicationConfig.MYSQL_JDBC_DRIVER)
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// b. 获取连接
conn = DriverManager.getConnection(
ApplicationConfig.MYSQL_JDBC_URL, //
ApplicationConfig.MYSQL_JDBC_USERNAME, //
ApplicationConfig.MYSQL_JDBC_PASSWORD
)
// c. 获取PreparedStatement对象
val insertSql ="""
|INSERT
|INTO
| itcast_ads_report.region_stat_analysis
| (report_date, province, city, count)
|VALUES (?, ?, ?, ?)
| ON DUPLICATE KEY UPDATE
| count=VALUES (count)
|""".stripMargin
pstmt = conn.prepareStatement(insertSql)
conn.setAutoCommit(false)
// d. 将分区中数据插入到表中,批量插入
datas.foreach{ row =>
pstmt.setString(1, row.getAs[String]("report_date"))
pstmt.setString(2, row.getAs[String]("province"))
pstmt.setString(3, row.getAs[String]("city"))
pstmt.setLong(4, row.getAs[Long]("count"))
// 加入批次
pstmt.addBatch()
}
// TODO: 批量插入
pstmt.executeBatch()
conn.commit()
}catch {
case e: Exception => e.printStackTrace()
}finally {
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
采用批量插入的方式将RDD分区数据插入到MySQL表中,提升性能。
完整代码
报表开发程序【RegionStateReport.scala】完整代码如下:
package cn.itcast.spark.report
import java.sql.{Connection, DriverManager, PreparedStatement}
import cn.itcast.spark.config.ApplicationConfig
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.{DataFrame, Row, SaveMode}
/**
* 报表开发:按照地域维度(省份和城市)分组统计广告被点击次数
* 地域分布统计:region_stat_analysis
*/
object RegionStateReport {
/**
* 不同业务报表统计分析时,两步骤:
* i. 编写SQL或者DSL分析
* ii. 将分析结果保存MySQL数据库表中
*/
def doReport(dataframe: DataFrame): Unit = {
// 导入隐式转换及函数库
import dataframe.sparkSession.implicits._
import org.apache.spark.sql.functions._
// i. 使用DSL(调用DataFrame API)报表开发
val resultDF: DataFrame = dataframe
// 按照地域维度分组(省份和城市)
.groupBy($"province", $"city")
// 直接count函数统计,列列名称为count
.count()
// 按照次数进行降序排序
.orderBy($"count".desc)
// 添加报表字段(报表统计的日期)
.withColumn(
"report_date", // 报表日期字段
// TODO:首先获取当前日期,再减去1天获取昨天日期,转换为字符串类型
date_sub(current_date(), 1).cast(StringType)
)
//resultDF.printSchema()
resultDF.show(10, truncate = false)
// ii. 保存分析报表结果到MySQL表中
//saveResultToMySQL(resultDF)
// 将DataFrame转换为RDD操作,或者转换为Dataset操作
resultDF.coalesce(1).rdd.foreachPartition(iter => saveToMySQL(iter))
}
/**
* 保存数据至MySQL表中,直接使用DataFrame Writer操作,但是不符合实际应用需求
*/
def saveResultToMySQL(dataframe: DataFrame): Unit = {
dataframe
.coalesce(1)
.write
// Overwrite表示,当表存在时,先删除表,再创建表和插入数据, 所以不用此种方式
//.mode(SaveMode.Overwrite)
// TODO: 当多次运行程序时,比如对某日广告数据报表分析运行两次,由于报表结果主键存在数据库表中,产生
冲突,导致报错失败
.mode(SaveMode.Append)
.format("jdbc")
// 设置MySQL数据库相关属性
.option("driver", ApplicationConfig.MYSQL_JDBC_DRIVER)
.option("url", ApplicationConfig.MYSQL_JDBC_URL)
.option("user", ApplicationConfig.MYSQL_JDBC_USERNAME)
.option("password", ApplicationConfig.MYSQL_JDBC_PASSWORD)
.option("dbtable", "itcast_ads_report.region_stat_analysis")
.save()
}
/**
* 保存数据至MySQL数据库,使用函数foreachPartition对每个分区数据操作,主键存在时更新,不存在时插入
*/
def saveToMySQL(datas: Iterator[Row]): Unit = {
// a. 加载驱动类
Class.forName(ApplicationConfig.MYSQL_JDBC_DRIVER)
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// b. 获取连接
conn = DriverManager.getConnection(
ApplicationConfig.MYSQL_JDBC_URL, //
ApplicationConfig.MYSQL_JDBC_USERNAME, //
ApplicationConfig.MYSQL_JDBC_PASSWORD
)
// c. 获取PreparedStatement对象
val insertSql ="""
|INSERT
|INTO
| itcast_ads_report.region_stat_analysis
| (report_date, province, city, count)
|VALUES (?, ?, ?, ?)
| ON DUPLICATE KEY UPDATE count= VALUES(count)
|""".stripMargin
pstmt = conn.prepareStatement(insertSql)
conn.setAutoCommit(false)
// d. 将分区中数据插入到表中,批量插入
datas.foreach{ row =>
pstmt.setString(1, row.getAs[String]("report_date"))
pstmt.setString(2, row.getAs[String]("province"))
pstmt.setString(3, row.getAs[String]("city"))
pstmt.setLong(4, row.getAs[Long]("count"))
// 加入批次
pstmt.addBatch()
}
// TODO: 批量插入
pstmt.executeBatch()
conn.commit()
}catch {
case e: Exception => e.printStackTrace()
}finally {
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
}
相关文章:
【Spark分布式内存计算框架——离线综合实战】5. 业务报表分析
第三章 业务报表分析 一般的系统需要使用报表来展示公司的运营情况、 数据情况等,本章节对数据进行一些常见报表的开发,广告数据业务报表数据流向图如下所示: 具体报表的需求如下: 相关报表开发说明如下: 第一、数据…...

力扣-删除重复的电子邮箱
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:196. 删除重复的电子邮箱二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果5.其…...

git基础
git-note Github Manual | GitHub Cheat Sheet | Visual Git Cheat Sheet 安装配置工具分支创建仓库.gitignore文件同步更改进行更改重做提交术语表 安装 desktop.github.com | git-scm.com 配置工具 对所有本地仓库的用户信息进行配置 对你的commit操作设置关联的用户名…...
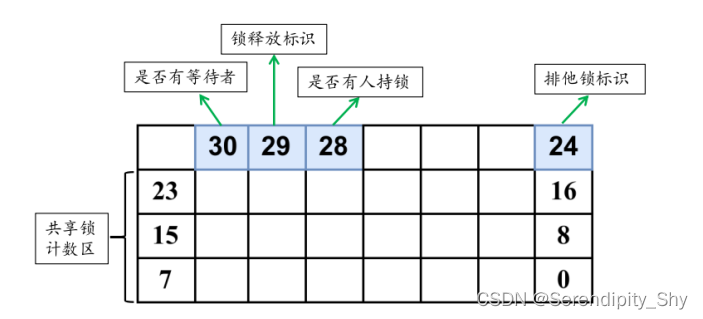
postgres 源码解析50 LWLock轻量锁--1
简介 postgres LWLock(轻量级锁)是由SpinLock实现,主要提供对共享存储器的数据结构的互斥访问。LWLock有两种锁模式,一种为排他模式,另一种是共享模式,如果想要读取共享内存中的内容,需要在读取…...

JVM优化常用命令
jps列出正在运行的虚拟机进程jpstop列出线程CPU或内存占用top top -Hp pid //列出pid全部线程jstat监视虚拟机运行状态信息jstat -gc pid 5000 //每隔5s打印gc情况jmapjmap -heap pid //输出jvm内存情况 jmap -histo:live pid | more //查看堆内存中的对象数量和大小 jma…...

按键中断实验
gpio.c#include"gpio.h"//给gpio使能和设置为输入模式void hal_gpio_init(){//使能GPIOF控制器RCC->MP_AHB4ENSETR|(0x1<<5);//通过GPIOF_将pf9/pf7/pf8设置为输入模式 GPIOF->MODER&(~(0x3<<18));GPIOF->MODER&(~(0x3<<14));GPI…...
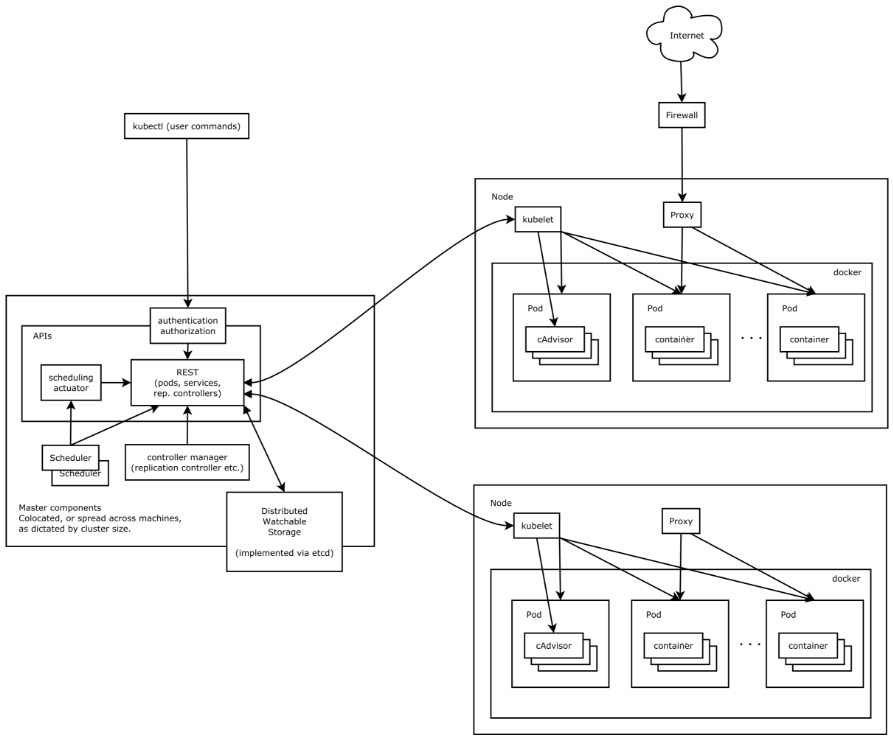
kubernetes入门介绍,从0到1搭建并使用
Kubernetes是一个容器编排系统,用于自动化应用程序部署、扩展和管理。本指南将介绍Kubernetes的基础知识,包括基本概念、安装部署和基础用法。 基础介绍 Kubernetes是Google开发的开源项目,是一个容器编排系统,可以自动化部署、…...

【C语言进阶】字符串函数与内存函数的学习与模拟实现
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:C语言进阶 🎯长路漫漫浩浩,万事皆有期待 文章目录1.字符串处理函数介…...

【JavaEE初阶】第一节.多线程(进阶篇 ) 常见的锁策略、CAS及它的ABA问题
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、常见的锁策略 1.1 乐观锁 vs 悲观锁 1.2 普通的互斥锁 vs 读写锁 1.3 重量级锁 vs 轻量级锁 1.4 自旋锁 vs 挂起等待锁 1.5 公平…...

Linux基础命令-pstree树状显示进程信息
Linux基础命令-uname显示系统内核信息 Linux基础命令-lsof查看进程打开的文件 Linux基础命令-uptime查看系统负载 文章目录 前言 一 命令介绍 二 语法及参数 2.1 使用man查看命令语法 2.2 常用参数 三 参考实例 3.1 以树状图的形式显示所有进程 3.2 以树状图显示进程号…...
keepalived+LVS配置详解
keepalivedLVS配置详解keepalived简介keepalived的应用场景keepalived工作原理VRRP协议核心组件分层工作工作状态LVS简介LVS三种模式NAT模式(网络地址映射)IPTUN模式(IP隧道)DR模式(直接路由)三种模式对比keepalivedLVS配置1.master配置2. keepalived配置文件3 修改keepalived配…...

Unity之C#端使用protobuf
什么是protobuf protobuf全称Protocol Buffers,由Google推出的一种平台、语言无关的数据交互格式,目前使用最广泛的一种数据格式,尤其在网络传输过程中,有很强的安全性,而且数据量比json和xml要小很多。 最主要的是pr…...
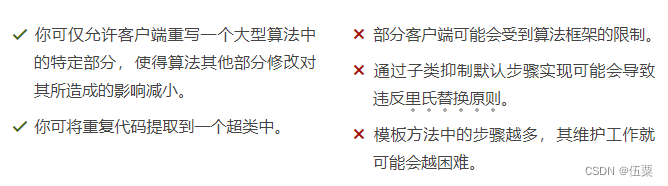
C++设计模式(18)——模板方法模式
亦称: Template Method 意图 模板方法模式是一种行为设计模式, 它在超类中定义了一个算法的框架, 允许子类在不修改结构的情况下重写算法的特定步骤。 问题 假如你正在开发一款分析公司文档的数据挖掘程序。 用户需要向程序输入各种格式…...

SQLserver 索引碎片
Oracle 不需要整理碎片,原因? 1. rowid 默认的索引是B-树索引。索引建立在表中的一个或多个列或者是表的表达式上,将列值和行编号一起存储。行编号是唯一标记表中行的伪列。 行编号是物理表中的行数据的内部地址&am…...
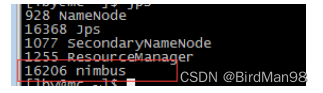
【Storm】【二】安装
1 准备 1.1 准备linux服务器 本文搭建的是3节点的集群,需要3台linux服务器,我这里使用的是centos7版本的linux虚拟机,虚拟机网络配置如下: 主节点: master 192.168.92.90 从节点: slave1 192.168.92.…...

Android ConditionVariable
Android ConditionVariable 线程操作经常用到wait和notify,用起来稍显繁琐,而Android给我们封装好了一个ConditionVariable类,用于线程同步。提供了三个方法block()、open()、close()。 void block() //阻塞当前线程,直到条件为…...
Action Segmentation数据集介绍——Breakfast
文章目录简介细节Cooking actibitiesillustration of the actions论文讲解Breakfast(The Breakfast Action Dataset)简介 早餐动作数据集包括与早餐准备相关的10个动作,由18个不同厨房的52个不同的人执行。该数据集是最大的完全带注释的数据…...

横道图时间标尺在P6软件中的设置
卷首语 由于其直观简洁且易于管理的特性,使其成为展示项目活动顺序及时间安排的最常用的进度管理工具。 甘特图 甘特图(Gantt Chart),又称为横道图或棒条图,是最早的项目进度管理工具之一。由于其直观简洁且易于管理…...
空间复杂度(超详解+例题)
全文目录引言空间复杂度例题test1test2(冒泡排序)test3(求阶乘)test4(斐波那契数列)总结引言 在上一篇文章中,我们提到判断一个算法的好坏的标准是时间复杂度与空间复杂度。 时间复杂度的作用…...

Document-Level event Extraction via human-like reading process 论文解读
Document-Level event Extraction via human-like reading process 论文:2202.03092v1.pdf (arxiv.org) 代码:无 期刊/会议:ICASSP 2022 摘要 文档级事件抽取(DEE)特别困难,因为它提出了两个挑战:论元分散和多事件。第一个挑战…...

WarcraftHelper:魔兽争霸3终极兼容性增强插件完全指南
WarcraftHelper:魔兽争霸3终极兼容性增强插件完全指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为《魔兽争霸…...

操作简便吗?8款AI论文写作工具综合榜,毕业答辩稳了!
写论文时是不是总卡在开头,毫无思路?文献资料太多,却找不到重点?格式调整一遍又一遍,查重还是不理想? 别担心!AI论文写作工具正在改变你的科研体验。本文将从学术严谨性、文献引用能力、查重合规…...

别再死记硬背了!用这5个Unity粒子特效案例,彻底搞懂ParticleSystem核心参数
别再死记硬背了!用这5个Unity粒子特效案例,彻底搞懂ParticleSystem核心参数粒子特效是游戏开发中不可或缺的视觉元素,从角色技能到环境氛围,都离不开ParticleSystem的灵活运用。但很多开发者在学习过程中陷入了一个误区——试图通…...
)
Windows 11账户密码管理避坑指南:从默认42天到永久有效,完整配置流程(含ChatGPT答案验证)
Windows 11密码策略深度解析:从42天默认值到永久有效的终极配置手册 每次系统提示"您的密码即将过期"时,那种被打断工作的烦躁感想必大家都不陌生。Windows 11默认的42天密码有效期策略,实际上源自微软早期安全框架的设计哲学——通…...

强化学习赋能匹配滤波器:可解释心电R波检测新范式
1. 项目概述:当经典匹配滤波器遇上强化学习在生物医学信号处理,尤其是心电分析这个行当里,R波的精准检测是几乎所有后续分析的基石。无论是计算心率、分析心率变异性,还是筛查心律失常,第一步都是把那些尖尖的R波从嘈杂…...

从华为EulerOS到openEuler:一个国产操作系统的开源之路与社区生态
从华为EulerOS到openEuler:一个国产操作系统的开源之路与社区生态在开源软件的世界里,每一个成功项目的背后都有一段独特的故事。当华为决定将其内部使用的EulerOS操作系统开源为openEuler时,这不仅是一个技术决策,更是一次关于开…...

Unity UI性能崩坏真相:UGUI重建机制与FGUI数据驱动协同
1. 这不是“UI怎么做”,而是“为什么UI总在上线前崩掉”我带过七支Unity项目团队,从百人MMO到独立游戏Demo,几乎每支队伍都经历过同一个深夜:美术交了新皮肤,策划改了按钮文案,程序顺手调了个CanvasScaler的…...

用机器学习与SHAP解析教育公平:巴西学生成绩预测模型实战
1. 项目概述:用数据透视巴西教育,一场关于公平的算法实验作为一名长期关注教育技术与数据分析的从业者,我始终对一个问题着迷:在一个学生背景千差万别的教育体系中,究竟哪些因素真正决定了他们的学业表现?是…...

你的GPU内存还好吗?MemTestCL深度诊断指南
你的GPU内存还好吗?MemTestCL深度诊断指南 【免费下载链接】memtestCL OpenCL memory tester for GPUs 项目地址: https://gitcode.com/gh_mirrors/me/memtestCL 你的显卡在运行大型游戏时会不会突然花屏?AI训练过程中是否经常遇到莫名其妙的崩溃…...

告别低效写作:盘点2026年顶尖配置的的降AI率网站
轻松降低论文AI率在2026年已不再是难题。最新实测数据显示,2026年降AI率网站正以惊人的效率改变写作方式,覆盖AI痕迹消除、文本优化、降重处理等关键场景,真正实现高效去AI化,让论文修改不再费时费力。 一、全流程王者:…...