每天一道大厂SQL题【Day12】微众银行真题实战(二)
每天一道大厂SQL题【Day12】微众银行真题实战(二)
大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题,以每日1题的形式,带你过一遍热门SQL题并给出恰如其分的解答。
一路走来,随着问题加深,发现不会的也愈来愈多。但底气着实足了不少,相信不少朋友和我一样,日积月累才是最有效的学习方式!
每日语录
人还是要有梦想的,即使是咸鱼, 也要做最咸的那一条。

第12题:贷款产品不良统计
需求列表
笔试题目
说明:SQL语法请使用HiveSQL/SparkSQL
基于附录2《借据表》统计下述指标,请提供计SOL
| 产品类型 | 在贷客户数 | 在贷余额 | 不良余额 | 余额不良率 | 不良客户数 | 客户不良率 |
|---|---|---|---|---|---|---|
| XX贷 | ||||||
| YY贷 | ||||||
| ZZ贷 | ||||||
| 汇总 |
数据准备
链接:https://pan.baidu.com/s/1Wiv-LVYziVxm8f0Lbt38Gw?pwd=s4qc
提取码:s4qc
debt.txt文件
set spark.sql.shuffle.partitions=4;
create database webank_db;
use webank_db;
create or replace temporary view check_view (ds comment '日期分区',
sno comment '流水号', uid comment '用户id',
is_risk_apply comment '是否核额申请',
is_pass_rule comment '是否通过规则',
is_obtain_qutoa comment '是否授信成功', quota comment '授信金额',
update_time comment '更新时间')
as
values ('20201101', 's000', 'u000', 1, 1, 1, 700, '2020-11-01 08:12:12'),
('20201102', 's088', 'u088', 1, 1, 1, 888, '2020-11-02 08:12:12'),
('20201230', 's091', 'u091', 1, 1, 1, 789, '2020-12-30 08:12:12'),
('20201230', 's092', 'u092', 1, 0, 0, 0, '2020-12-30 08:12:12'),
('20201230', 's093', 'u093', 1, 1, 1, 700, '2020-12-30 08:12:12'),
('20201231', 's094', 'u094', 1, 1, 1, 789, '2020-12-31 08:12:12'),
('20201231', 's095', 'u095', 1, 1, 1, 600, '2020-12-31 08:12:12'),
('20201231', 's096', 'u096', 1, 1, 0, 0, '2020-12-31 08:12:12')
;
--创建核额流水表
drop table if exists check_t;
create table check_t (
sno string comment '流水号', uid string,
is_risk_apply bigint, is_pass_rule bigint, is_obtain_qutoa bigint, quota decimal(30,6), update_time string
) partitioned by (ds string comment '日期分区');
--动态分区需要设置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table check_t partition (ds) select sno,
uid, is_risk_apply, is_pass_rule, is_obtain_qutoa, quota,
update_time,
ds
from check_view;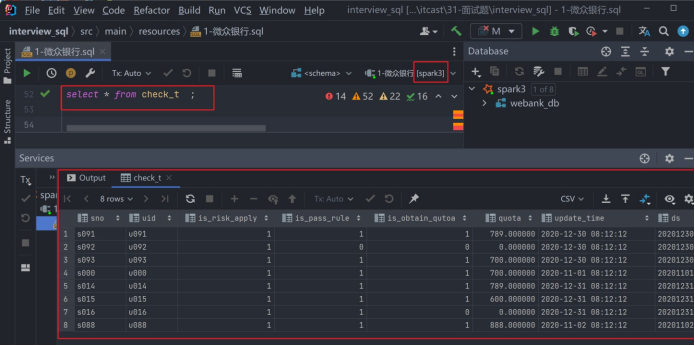
-- 创 建 借 据 表
create table debt(
duebill_id string comment '借据号',
uid string, prod_type string,
putout_date string,
putout_amt decimal(30, 6),
balance decimal(30, 6),
is_buliang int,
overduedays int
)partitioned by (ds string comment '日期分区');
--资料提供了一个34899条借据数据的文件
--下面补充如何将文件的数据导入到分区表中。需要一个中间普通表过度。
drop table if exists webank_db.debt_temp;
create table webank_db.debt_temp(
duebill_id string comment '借据号', uid string,
prod_type string,
putout_date string, putout_amt decimal(30, 6),
balance decimal(30,6),
is_buliang int, overduedays int,
ds string comment '日期分区'
) row format delimited fields terminated by '\t';load data local inpath '/root/debt.txt' overwrite into table webank_db.debt_temp;--动态分区需要设置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table webank_db.debt partition (ds)
select * from webank_db.debt_temp;--技巧:如果查询debt表,由于分区数太多,导致查询很慢。
-- 开发阶段,我们可以事先将表缓存起来,并且降低分区数比如为6,那么查缓存表大大提升了开发效率。
-- 上线阶段,再用实际表替换缓存表。
--首次缓存会耗时慢
cache table cache_debt as select /+ coalesce(6) / from
debt;
--第二次使用缓存会很快
select count(*) from cache_debt;
select ds,count(1) from cache_debt group by ds;
思路分析
--第二问 假设是今天(2021-10-29)的统计,并考虑对用户去重select * from debt where ds='2021-10-29' ;
drop table if exists prod_type_agg;
create table prod_type_agg(
prod_type string comment '产品',
cnt int,
sum_balance decimal(30, 6),
bad_balance decimal(30, 6),
bad_balance_rate decimal(7, 6),
bad_cnt int,
bad_cnt_rate decimal(7, 6)
) partitioned by (ds string comment '结果分区');
- 在贷客户数:指在某一时点,有未偿还贷款余额的客户数。
- 在贷余额:指在某一时点,所有未偿还贷款的总金额。
- 不良余额:指在某一时点,所有不良贷款(即次级、可疑和损失类贷款)的总金额。
- 余额不良率:指在某一时点,不良余额占在贷余额的比例。公式为:余额不良率 = 不良余额 / 在贷余额
- 不良客户数:指在某一时点,有不良贷款(即次级、可疑和损失类贷款)的客户数。
- 客户不良率:指在某一时点,不良客户数占在贷客户数的比例。公式为:客户不良率 = 不良客户数 / 在贷客户数
方案1 使用union all
方案2 使用grouping sets
答案获取
建议你先动脑思考,动手写一写再对照看下答案,如果实在不懂可以点击下方卡片,回复:大厂sql 即可。
参考答案适用HQL,SparkSQL,FlinkSQL,即大数据组件,其他SQL需自行修改。
加技术群讨论
点击下方卡片关注 联系我进群
或者直接私信我进群
微众银行源数据表附录:
- 核额流水表
| 字段名 | 字段意义 | 字段类型 |
|---|---|---|
| ds | 日期分区,样例格式为20200101,每个分区有全量流水 | string |
| sno | 每个ds内主键,流水号 | string |
| uid | 户id | string |
| is_risk_apply | 是否核额申请(核额漏斗第一步)取值0和1 | bigint |
| is_pass_rule | 是否通过规则(核额漏斗第二步)取值0和1 | bigint |
| is_obtain_qutoa | 是否授信成功(核额漏斗第三步)取值0和1 | bigint |
| quota | 授信金额 | decimal(30,6) |
| update_time | 更新时间样例格式为2020-11-14 08:12:12 | string |
- 借据表
| 字段名 | 字段意义 | 字段类型 |
|---|---|---|
| ds | 日期分区,样例格式为20200101每个分区有全量借据 | string |
| duebilid | 借据号(每个日期分区内的主键) | string |
| uid | 用户id | string |
| prod_type | 产品名称仅3个枚举值XX贷YY贷ZZ贷 | string |
| putout_date | 发放日期样例格式为2020-10-10 00:10:30 | bigint |
| putout_amt | 发放金额 | decimal(30,6) |
| balance | 借据余额 | decimal(30,6) |
| is_buliang | 状态-是否不良取值0和1 | bigint |
| overduedays | 逾期天数 | bigint |
- 模型输出表
| 字段名 | 字段意义 | 字段类型 |
|---|---|---|
| ds | 日期分区,样例格式为20200101增量表部分流水记录可能有更新 | string |
| sno | 流水号,主键 | string |
| create time | 创建日期样例格式为2020-10-10 00:10:30与sno唯一绑定,不会变更 | string |
| uid | 用户id | string |
| content | son格式key值名称为V01~V06,value值取值为0和1 | string |
| create_time | 更新日期样例格式为2020-10-1000:10:30 | string |
文末SQL小技巧
提高SQL功底的思路。
1、造数据。因为有数据支撑,会方便我们根据数据结果去不断调整SQL的写法。
造数据语法既可以create table再insert into,也可以用下面的create temporary view xx as values语句,更简单。
其中create temporary view xx as values语句,SparkSQL语法支持,hive不支持。
2、先将结果表画出来,包括结果字段名有哪些,数据量也画几条。这是分析他要什么。
从源表到结果表,一路可能要走多个步骤,其实就是可能需要多个子查询,过程多就用with as来重构提高可读性。
3、要由简单过度到复杂,不要一下子就写一个很复杂的。
先写简单的select from table…,每个中间步骤都执行打印结果,看是否符合预期, 根据中间结果,进一步调整修饰SQL语句,再执行,直到接近结果表。
4、数据量要小,工具要快,如果用hive,就设置set hive.exec.mode.local.auto=true;如果是SparkSQL,就设置合适的shuffle并行度,set spark.sql.shuffle.partitions=4;
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢不能老盯着手机屏幕,要不时地抬起头,看看老板的位置⭐
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12182595.html
相关文章:
每天一道大厂SQL题【Day12】微众银行真题实战(二)
每天一道大厂SQL题【Day12】微众银行真题实战(二) 大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题&…...
带您了解TiDB MySQL数据库中关于日期、时间的坑
带您了解TiDB & MySQL数据库中关于日期、时间的坑时间的基础知识什么是时间计算时间的几种方法世界时(UT)协调世界时(UTC)国际原子时(TAI)时区的概念中国所在的时区操作系统的时区datetimedatectl数据库…...

【华为OD机试模拟题】用 C++ 实现 - 求字符串中所有整数的最小和
最近更新的博客 华为OD机试 - 入栈出栈(C++) | 附带编码思路 【2023】 华为OD机试 - 箱子之形摆放(C++) | 附带编码思路 【2023】 华为OD机试 - 简易内存池 2(C++) | 附带编码思路 【2023】 华为OD机试 - 第 N 个排列(C++) | 附带编码思路 【2023】 华为OD机试 - 考古…...
harbor 仓库迁移升级
harbor 仓库迁移升级 harbor仓库安装数据传输仓库切换版本 v1.8.0 v2.3.5 harbor仓库安装 环境准备:安装docker详见:docker 的介绍和部署,并下载docker-compose详见:docker 三剑客compose。 现有支持的安装harbor仓库的方式有两…...

评论功能设计思路~
文章目录 评论功能设计框架1、定义2、目标3、动机4、评论类别**5、评论互动****6、评论区展示结构****6.1 主题式****6.2 平铺式****6.3 盖楼式****7、评论排序机制****8、评论加载形式****9、其他**结语评论功能设计框架 1、定义 评论是指针对于事物进行主观或客观的自我印象…...

算法训练营 day52 动态规划 买卖股票的最佳时机系列1
算法训练营 day52 动态规划 买卖股票的最佳时机系列1 买卖股票的最佳时机 121. 买卖股票的最佳时机 - 力扣(LeetCode) 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票…...

3.基于分割的文本检测算法--DBNet++
文章目录1.概况2.DBNet中的主要方法2.1 网络结构2.2 适应特征图融合模块(Adaptive Scale Fusion Module, ASF)3.ASF模块的源码实现参考资料欢迎访问个人网络日志🌹🌹知行空间🌹🌹 1.概况 2022年02月份论文:Real-Time S…...

IOS打包、SDK接入记录等
IOS打包、SDK接入记录等 Mac上安装HCLR路径 /Applications/Unity/Hub/Editor/2019.4.40f1c1/Unity.app/Contents/il2cpp HCLR 指定4.40是要Unity启动打开的il2cpp,否则HCLR Installer他会报找不到MonoBleedingEdge Mac删除证书 只能点击钥匙串做上角的登录后&…...
【C++】类与对象(引入)
目录 前言 类的引入 类的定义 封装与访问限定符 封装 访问限定符 类的实例化 类的大小 this指针 特性 前言 🎶我们都知道,C语言是面向过程的编程,而C是面向对象的编程,更多体现在编程的关注点上。 🎶就拿洗…...
Redis 高级数据类型
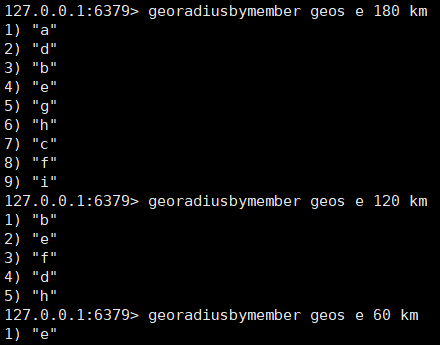
文章目录一、Bitmaps:属性状态统计二、HyperLogLog:基数统计三、GEO:地理位置信息计算提示:以下是本篇文章正文内容,Redis系列学习将会持续更新 一、Bitmaps:属性状态统计 Bitmaps类型: 统计一…...

Java8 新特性-函数式接口
什么是函数式接口 先来看看传统的创建线程是怎么写的 Thread t1 new Thread(new Runnable() {Overridepublic void run() {System.out.println("t1");} }); t1.start();再来看看使用了函数式接口是怎么写的 Thread t2 new Thread(() -> System.out.println(&…...
这套软件测试试卷能打90分,直接入职字节吧
目录 一.填空 二、 判断题(正确的√,错误的╳)共10分,每小题1分 三、数据库部分:(共15分) 四、设计题。本题共 1 小题,满分 20分 一.填空 1、 系…...
GUI可视化应用开发及Python实现
0 建议学时 4学时,在机房进行 1 开发环境安装及配置 1.1 编程环境 安装PyCharm-community-2019.3.3 安装PyQt5 pip install PyQt5-tools -i https://pypi.douban.com/simple pip3 install PyQt5designer -i https://pypi.douban.com/simple1.2 环境配置 选择“…...
【论文简述】GMFlow: Learning Optical Flow via Global Matching(CVPR 2022)
一、论文简述 1. 第一作者:Haofei Xu 2. 发表年份:2022 3. 发表期刊:CVPR oral 4. 关键词:光流、代价体、Transformers、全局匹配、注意力机制 5. 探索动机:过去几年中具有代表性的光流学习框架的核心估计方式没有…...

【Spark分布式内存计算框架——离线综合实战】5. 业务报表分析
第三章 业务报表分析 一般的系统需要使用报表来展示公司的运营情况、 数据情况等,本章节对数据进行一些常见报表的开发,广告数据业务报表数据流向图如下所示: 具体报表的需求如下: 相关报表开发说明如下: 第一、数据…...

力扣-删除重复的电子邮箱
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:196. 删除重复的电子邮箱二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果5.其…...

git基础
git-note Github Manual | GitHub Cheat Sheet | Visual Git Cheat Sheet 安装配置工具分支创建仓库.gitignore文件同步更改进行更改重做提交术语表 安装 desktop.github.com | git-scm.com 配置工具 对所有本地仓库的用户信息进行配置 对你的commit操作设置关联的用户名…...
postgres 源码解析50 LWLock轻量锁--1
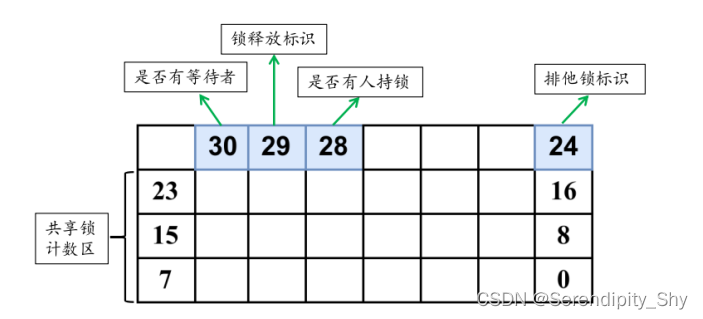
简介 postgres LWLock(轻量级锁)是由SpinLock实现,主要提供对共享存储器的数据结构的互斥访问。LWLock有两种锁模式,一种为排他模式,另一种是共享模式,如果想要读取共享内存中的内容,需要在读取…...

JVM优化常用命令
jps列出正在运行的虚拟机进程jpstop列出线程CPU或内存占用top top -Hp pid //列出pid全部线程jstat监视虚拟机运行状态信息jstat -gc pid 5000 //每隔5s打印gc情况jmapjmap -heap pid //输出jvm内存情况 jmap -histo:live pid | more //查看堆内存中的对象数量和大小 jma…...

按键中断实验
gpio.c#include"gpio.h"//给gpio使能和设置为输入模式void hal_gpio_init(){//使能GPIOF控制器RCC->MP_AHB4ENSETR|(0x1<<5);//通过GPIOF_将pf9/pf7/pf8设置为输入模式 GPIOF->MODER&(~(0x3<<18));GPIOF->MODER&(~(0x3<<14));GPI…...

大语言模型在嵌入式系统开发中的应用与挑战
1. 嵌入式系统开发与大语言模型的碰撞 在智能家居、工业自动化和物联网设备蓬勃发展的今天,嵌入式系统作为连接数字世界与物理世界的桥梁,其开发复杂度正呈指数级增长。传统嵌入式开发要求工程师同时具备三大核心能力:理解电子元件特性与电路…...

LED闪灯电路板学习 过程
原理图和pcb是开源的,照着抄就行了,难点主要在于焊接,,焊接我分为三步,第一步一定要点锡,呈现45度角,大约3秒到5秒,第二步就是要夹稳零件往一边靠,第三步就是要顺水的焊锡焊另外一边,最重要就是第二步,熬过去就简单了,打了5个板子花了三天时间从零成功,重…...

3分钟快速修复洛雪音乐播放问题:六音音源完整指南
3分钟快速修复洛雪音乐播放问题:六音音源完整指南 【免费下载链接】New_lxmusic_source 六音音源修复版 项目地址: https://gitcode.com/gh_mirrors/ne/New_lxmusic_source 你是否曾经在升级洛雪音乐后,发现心爱的歌单突然变成了灰色,…...

Neural Complete架构解析:LSTMBase类与TextEncoderDecoder工作流程
Neural Complete架构解析:LSTMBase类与TextEncoderDecoder工作流程 【免费下载链接】neural_complete A neural network trained to help writing neural network code using autocomplete 项目地址: https://gitcode.com/gh_mirrors/ne/neural_complete Neu…...

Apache Fesod:Java开发者处理海量Excel数据的终极解决方案
Apache Fesod:Java开发者处理海量Excel数据的终极解决方案 【免费下载链接】fesod Fast. Easy. Done. Processing spreadsheets without worrying about large files causing OOM. 项目地址: https://gitcode.com/gh_mirrors/fast/fesod 在处理海量Excel数据…...

HTTPS静态资源403/404根因排查:从Nginx配置到SELinux权限
1. 这不是SSL证书的问题,而是HTTP服务配置的“隐身故障”你刚在云服务商控制台花了几十块钱买了张正规CA签发的SSL证书,上传到Nginx或Apache,配好了443端口,https://yourdomain.com打开首页也绿锁高亮,一切看起来都对—…...

2026年5月儿童护眼灯品牌推荐:TOP5排名书桌防蓝光评测
摘要 当儿童近视率持续攀升,家长在选购护眼灯时面临从“照亮”到“护眼”的认知升级,如何在琳琅满目的品牌中锁定真正科学有效的方案成为核心焦虑。根据世界卫生组织最新数据,全球儿童近视患病率预计在2050年将达到50%,而照明环境…...

告别SSH连接玄学!用Finalshell管理多台Linux服务器时,如何一劳永逸搞定IP变动?
多服务器IP漂移难题的终极解决方案:Finalshell高效管理实践每次打开Finalshell准备工作时,发现熟悉的服务器连接突然变成一片红色"Connection timed out"——这种场景对于需要同时管理多台Linux服务器的运维人员和开发者来说,无异于…...

Akagi麻将AI助手:5分钟搭建你的实时对局分析系统,告别盲目打牌!
Akagi麻将AI助手:5分钟搭建你的实时对局分析系统,告别盲目打牌! 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majs…...

PDF补丁丁:5个高效PDF处理方案解决办公文档管理痛点
PDF补丁丁:5个高效PDF处理方案解决办公文档管理痛点 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https://gitc…...