【C++】string类的基本使用
层楼终究误少年,自由早晚乱余生。你我山前没相见,山后别相逢…

文章目录
- 一、编码(ascll、unicode字符集、常用的utf-8编码规则、GBK)
- 1.详谈各种编码规则
- 2.汉字在不同的编码规则中所占字节数
- 二、string类的基本使用
- 1.string类的本质(管理字符的动态顺序表)
- 2.string类对象的常见构造
- 3.三种遍历string类对象的操作
- 3.1 [ ] + 下标(operator[ ]的重载函数)
- 3.2 基于范围的for循环(C++11新增特性:auto自动类型推导)
- 3.3 迭代器(正向、反向、const正向、const反向)
- 3.4 类中哪些函数需要实现两个版本?哪些不需要呢?
- 4.string类对象的容量操作(reserve( ):对比vs和g++对于扩容采取策略的差异)
- 5.string类对象的元素访问
- 6.string类对象的修改操作(operator+= 才是yyds)
- 7.string类对象的字符串操作(String operations)
- 8.string类的非成员函数重载
一、编码(ascll、unicode字符集、常用的utf-8编码规则、GBK)
1.详谈各种编码规则
ASCII码表里的字符总共有多少个?(转载自百度知道博主教育达人小李的文章)


百度百科:统一码Unicode
百度百科:UTF-8编码
UTF-8兼容ascll编码,linux下默认使用的就是UTF-8的编码方式。
百度百科:GBK字库
vs编译器默认使用的编码方式是GB2312编码。

下面这篇文章写的非常不错,十分推荐大家看看。(我的建议是搞懂UTF-8的编码规则即可,UTF-16和32不常用,所以掌握UTF-8的编码原理就足够了,因为这些知识只要了解即可,知道有这么回事就行,不必过于细究。)
Unicode、UTF-8、UTF-16 终于懂了(转载自知乎博主程序员十三的文章)
2.汉字在不同的编码规则中所占字节数
utf-8中的汉字占用多少字节(转载自博客园博主醉人的文章)

我的vs编译器默认的编码规则就是GB2312编码,字母和数字都是一个字节,汉字占用2个字节。
各种编码的中文占用几个字节?Unicode、ISO 10646、UTF-8、GB-2312、GBK的区别是什么?(转载自csdn博主天上的云川的文章)

字符编码ASCII,GB2312,GBK,Unicode,UTF-8(转载自知乎博主sunny的文章)
二、string类的基本使用
1.string类的本质(管理字符的动态顺序表)
1.
最常用的类就是string,这些类都是基于类模板basic_string,由于类模板参char16_t、char32_t、wchar_t、的不同,实例化出对应不同需求的类,例如u16string,u32string,wstring。
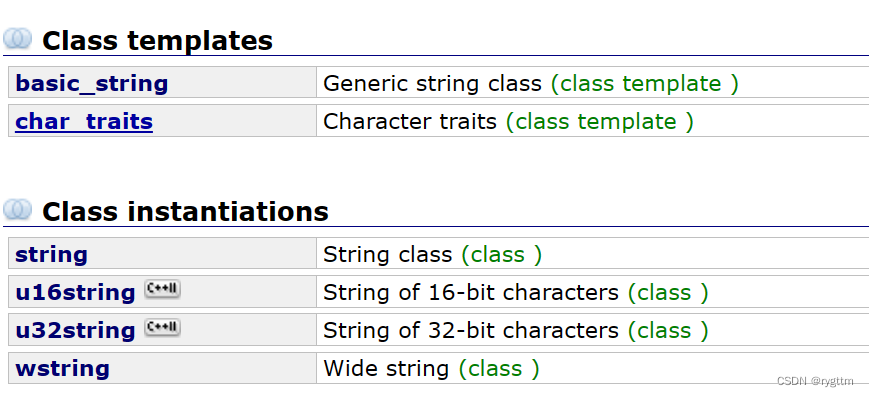
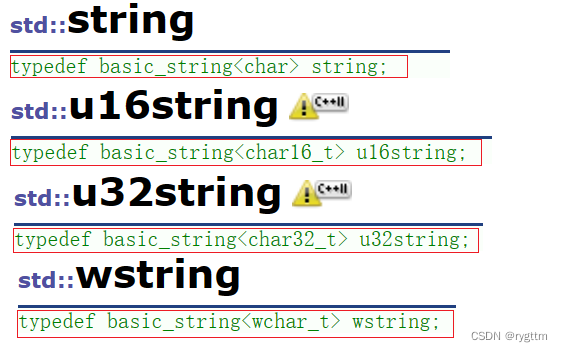

我应该用std::string、std::u16string还是std::u32string?(转载自知乎博主王万霖的文章)
2.
最常用的类就是string,实际上string就是我们数据结构初阶学习的动态顺序表,在理解上,只需要将其看成一个动态开辟的柔性数组即可。
动态增长的字符数组,string可以看成是一个管理字符的顺序表
template<class T>
class my_basic_string
{private:T* _str;size_t _size;size_t _capacity;
};
typedef my_basic_string<char> string;//存UTF-8的,所以模板参数传char。如果是UTF-16,那就传char16_t。
2.string类对象的常见构造
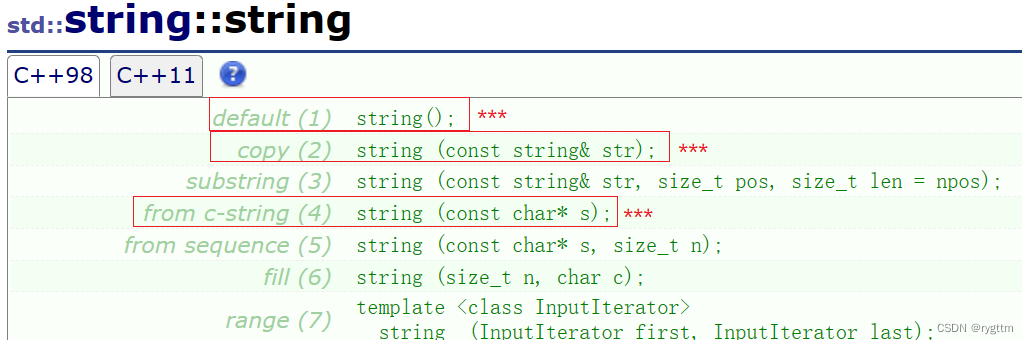
1.
string的constructor构造函数里面重载了许多的string类的构造函数,其中包括多个构造函数和拷贝构造函数,由于第一次学STL,所以我们将string这个类讲的细致全面一些,以便于了解STL是怎么学习的,后面的其他容器包括string实际上只需要掌握常见的重要接口即可,遇到其他不常见的接口,只需要查询C++文献即可。
2.
我们所使用的string类被包含在< string >头文件里面,而string头文件的内容又被封装在std命名空间里面,大型项目里面建议使用域作用限定符不展开命名空间std,但在我们自己平常的学习过程中,无需太过繁琐,展开std命名空间即可。

3.
最常用的构造函数就是string类默认的无参构造函数和以常量字符串为参数的构造函数。
s2和s3对象的构造结果是一样的,只是书写的形式不同,s3形式看起来更像赋值重载,但他其实是进行了隐式类型转换,编译器做了优化,本质实际上是构造+拷贝构造,先根据常量字符串构造出一个string类对象,然后再将这个对象拷贝构造给对象s3。
从拷贝构造和赋值重载的定义也可以知道,s3是拷贝构造,因为赋值重载是已经存在的两个对象之间的赋值,而拷贝构造是已经存在的对象去初始化创建另外一个对象,对象s3明显不是已经存在的,所以s3是拷贝构造,编译器在这里会优化为直接构造。

编译器对于拷贝构造的优化

4.
其他可以了解一下的接口还有字符和个数作为参数的构造函数,s4即为被10个字符*初始化构造的对象。
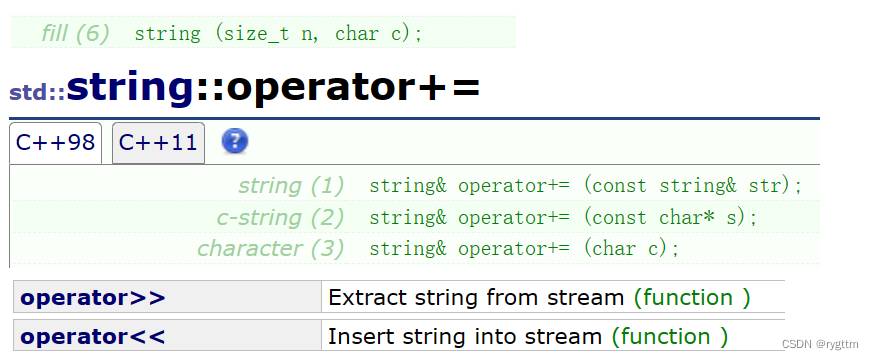
string类中重载了+=函数,+=函数也有三种重载函数形式,分别为以常量字符串、string类对象的引用、普通字符为参数的三个运算符重载函数,这就可以方便我们将自定义类型当作内置类型使用,极大的提高了代码可读性。
string类还重载了流提取和流插入运算符,这也可以帮助我们快速的看到string类对象的内容,也提升了代码的可读性。
由此可见,重载函数和运算符重载,真是C++的伟大之处。
5.
除构造函数外,string类肯定还有拷贝构造默认成员函数,常见用法就是用一个已经存在的string类对象拷贝构造出一个新对象例如s5和s6。拷贝构造的另一种写法就是看起来比较像赋值重载,但本质和拷贝构造无差别,仅仅是代码形式不同而已。
实际上这里还涉及到深拷贝的问题,底层实现中,在内存里一定是存在两份动态字符数组的,如果仅仅是浅拷贝,那么在析构的时候,会出现同一块内存释放两次的情况,这就会导致越界访问已经还给操作系统的内存,势必会导致程序崩溃。当然现在我们不需要关心这些问题,因为string类已经有人帮我们写好了,但如果我们自己实现时,就需要考虑这样的问题了。后面我们会自己模拟实现string类。
还有一种适当了解的构造函数形式就是常量字符串和字符串的前n个字符作为参数的构造的重载函数,例如s7,我用计算机网络的前6个字符来构造对象s7,因为vs默认的编码规则是GB2312,所以s7的内容就是计算机。

6.
还有一种拷贝构造的重载形式,就是从pos位置开始,横跨我们指定的字符长度,用str串的子串来进行构造新的string类对象,并且这个重载函数的参数是半缺省参数,按照从右向左连续缺省的原则,这个参数就是npos,默认值是-1,但是类型是size_t无符号整型,也就是unsigned int,所以这个值实际上就是四十二亿九千万多,那就意味着,如果我们不指定len的大小,则构造对象时,默认使用的是从pos位置开始直到str的结尾的字串。
如果len的指定大小过大,超出str的字符长度,则以str的末尾作为结束标志,如果指定过小,则舍去相应的字符即可。

7.上面说了这么多重载函数的用法,但只要重点掌握三个函数即可,即为无参,常量字符串等参数的构造函数和类对象引用作为参数的拷贝构造。
注意:拷贝构造的参数必须是类对象的引用,否则将引发无穷递归调用,疯狂建立拷贝构造的函数栈帧。
#include <iostream>
#include <string>
#include <vector>
#include <list>
using namespace std;//库文件string的内容也是被封装在std命名空间里面的。
void test_string1()
{string s1;string s2("今天是个");//传参构造string s3 = "操作系统";//这里支持隐式类型转换,因为string类的拷贝构造函数没有explicit修饰,构造 + 拷贝构造 = 直接优化为构造。//上面代码看起来像是赋值重载,但实际上是构造+拷贝构造,编译器在这个地方会做优化。(详情见文章类和对象核心总结,编译器的优化)string s4(10, '*');s2 += "好日子";//运算符重载,+=的本质实际上是在堆上有一个数组,这个数组是动态开辟的。cout << s1 << endl;//string类当中,支持了流插入运算符重载。所以我们可以将自定义类型当作内置类型使用。cout << s2 << endl;cout << s3 << endl;cout << s4 << endl;string s5(s3);//拷贝构造string s6 = s3;//这个也是拷贝构造,只不过写法不一样。//这里的拷贝构造涉及深拷贝的问题,因为两个指针指向同一数组,在释放时会出现越界访问已经还给操作系统的内存。cout << s5 << s6 << endl;string s7("计算机网络", 6);//GBK编码中汉字占2字节,utf8汉字占用3字节或4字节。cout << s7 << endl;string s8(s7, 0);//参数案例:4、3、30、最后一个参数不给,函数也有缺省值npos,这个npos是类里面声明的静态成员变量,定义在类外面。//static const size_t npos = -1;size_t修饰的无符号整型的-1是四十二亿九千万大小,所以可以直接看成取到字符串的末尾。//从第0个位置开始走4个字节的长度,那么s8就是"计算"。如果走3字节长度,则s8就是"计"。如果长度过大,到达末尾即结束。cout << s8 << endl;//****只需重点了解无参,常量字符串等参数的构造函数和类对象引用作为参数的拷贝构造,稍微知道字符和字符个数做参的构造函数即可****
}
3.三种遍历string类对象的操作
3.1 [ ] + 下标(operator[ ]的重载函数)
1.
如果我们现在遇到一个需求,让对象s1里面的每个字符的ascll码值都+1,那我们势必要对对象s1进行遍历操作,这个时候就可以用到operator[ ],string类中给我们实现了两个版本,一个用于普通对象,表示可以修改和访问string类对象的内容。另一个用于const修饰的对象,表示只能访问string类对象内容,不可以修改。
这两个版本的返回值是相同的,都是返回string类对象的字符的引用。利用普通版本,便可以遍历操作对象s1中的每一个字符并进行修改。

2.
size()函数返回有效字符的个数,不包括\0,\0是标识字符。
void test_string2()
{string s1("1234");//需求:让对象s1里面的每个字符都加1//如果要让字符串的每个字符都加1,肯定离不开遍历,下面学习三种遍历string的方式。//1.下标 + []for (size_t i = 0; i < s1.size(); i++){s1[i]++;//本质上}cout << s1 << endl;//GB2312兼容ascll编码,所以++后的结果为2345.
}
3.2 基于范围的for循环(C++11新增特性:auto自动类型推导)
1.
C++11新特性,auto自动类型推导,在基于范围的for循环情况下,可以使用auto引用来操作数组s1里面的每个元素。
void test_string2()
{//2.范围forfor (auto& ch : s1)//自动推导s1数组的每个元素后,用元素的引用作为迭代变量,通过引用达到修改s1数组元素的目的。{ch++;}cout << s1 << endl;//在上面这种需求下,范围for看起来似乎更为方便
}
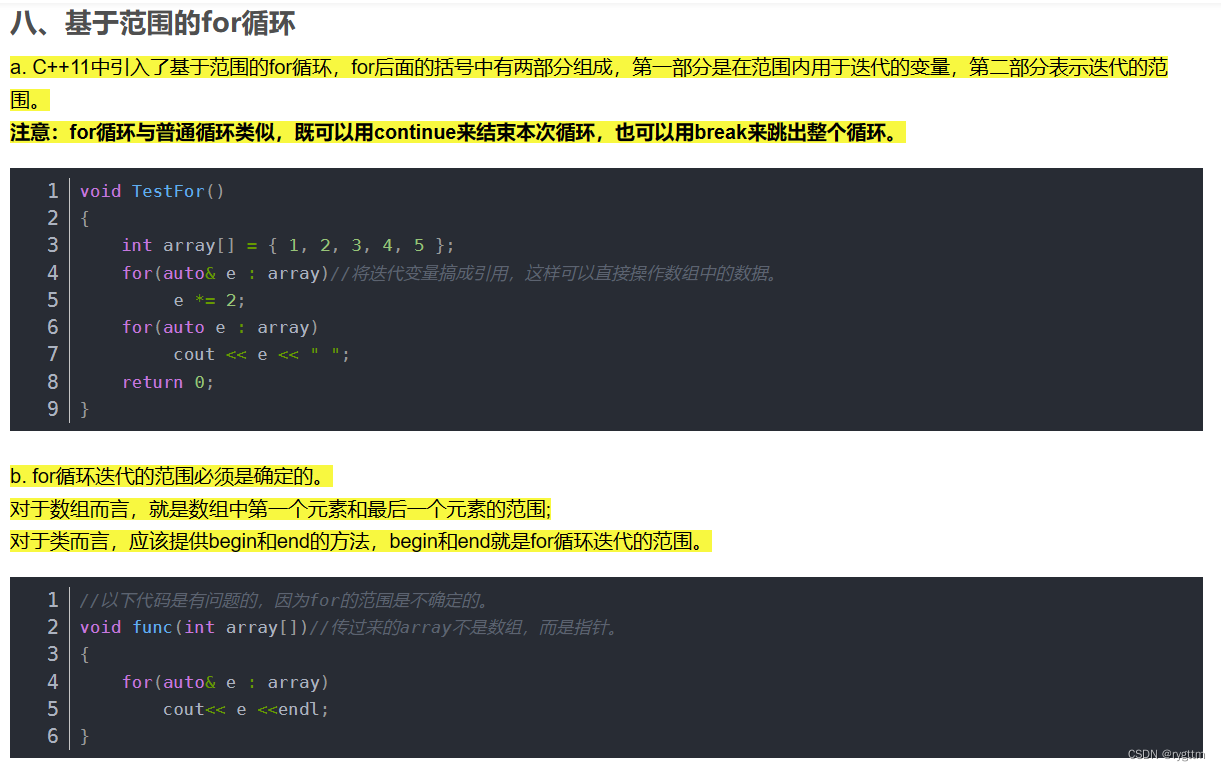
2.
但在将需求改为翻转字符串之后,基于范围的for循环就不适用了,而下标加方括号的方式还可以使用,并且交换函数也不用我们实现,std命名空间里面有函数模板swap,通过我们所传参数,函数模板便可以进行隐式的实例化。
函数模板的两种实例化方式(隐式和显示实例化)
3.
对于翻转,我们还可以使用reverse算法和迭代器来实现,这个放到以后的文章去讲,现在只是提一下,有个印象就好。

//新需求:反转一下字符串。size_t begin = 0, end = s1.size() - 1;//有效字符是不包含\0的,所以end下标要再往前挪动一个位置。//\0不是有效字符,而是标识字符。while (begin < end)//begin和end相等的时候,不用交换了{swap(s1[begin++], s1[end--]);//利用库函数swap}cout << s1 << endl;reverse(s1.begin(), s1.end());//reverse算法和迭代器,后面会讲到,这里只是提一下cout << s1 << endl;
3.3 迭代器(正向、反向、const正向、const反向)
1.
迭代器实际上具有普适性,对于大多数容器都可以适用,而[ ]+下标这样的使用方式只对于vector和string适用,后面学习到的list、树等就不适用了,而迭代器由于其强大的普适性依旧可以适用,这也正是迭代器学习的意义。
2.
迭代器在使用的方式和行为上比较像指针,但是它和指针还是有区别的,它既有可能是指针,又有可能不是指针。在定义时要指定类域,譬如it1的定义,就需要指定类域里面的iterator类型,begin()会返回获取第一个字符的迭代器,end()会返回最后一个字符下一个位置的迭代器,一般情况下就是标识字符\0,其实在使用上就是类似于指针,解引用迭代器就可以获得相应的字符,然后就可以对字符进行操作,从下面代码可以看出,it1不仅可以访问而且还可以修改对象s1的内容。并且除string外,vector和list也可以照常使用iterator,这也验证了iterator的普适性。
void test_string2()
{//3.迭代器:通用的访问形式 iterators --- 行为上像指针一样的东西,有可能是指针,也有可能不是指针string::iterator it1 = s1.begin();// string类域里面的迭代器iterator类型,定义出it1迭代器变量。while (it1!=s1.end())//end返回的是最后一个有效数据的下一个位置(一般情况下是\0){*it1 += 1;++it1;}it1 = s1.begin();while (it1 != s1.end())//end返回的是最后一个数据的下一个位置的迭代器{cout << *it1 << " ";++it1;}cout << endl;vector<int> v;vector<int>::iterator vit = v.begin();while (vit != v.end()){cout << *vit << " ";vit++;}cout << endl;list<int> lt;list<int>::iterator ltit = lt.begin();while (ltit != lt.end()){cout << *ltit << " ";ltit++;}cout << endl;//****只有string和vector这两个容器能用[],后面的list、树等容器就不支持[]了。****
}
3.
除begin()和end()外,还有rbegin()和rend(),前面两个返回的是正向迭代器,后面这两个返回的是相应字符的反向迭代器,也就是从末尾开始,到开头结束,和正常的方向反过来,在使用上和正向迭代器没有任何区别。
如果嫌string::reverse_iterator 写起来比较麻烦的话,可以用auto来进行类型的自动推导,但不建议这么干,因为这会降低代码的可读性。
4.
实现Print函数时,参数采用了引用和const,因为传值拷贝需要中间变量,一旦涉及资源的传递,则代价会非常大,堆上需要重新给中间变量开辟空间,所以我们采用了传引用拷贝。但如果你用普通的迭代器类型接收begin()返回的字符迭代器,实际上会报错,仔细观察报错信息就会发现是const和非const之间无法转换,这实际上就是因为对象s被用const修饰,所以begin()返回的是const迭代器类型,而你用普通的迭代器接收,就会出现无法正常转换的问题,所以需要用string::const_iterator来接收。
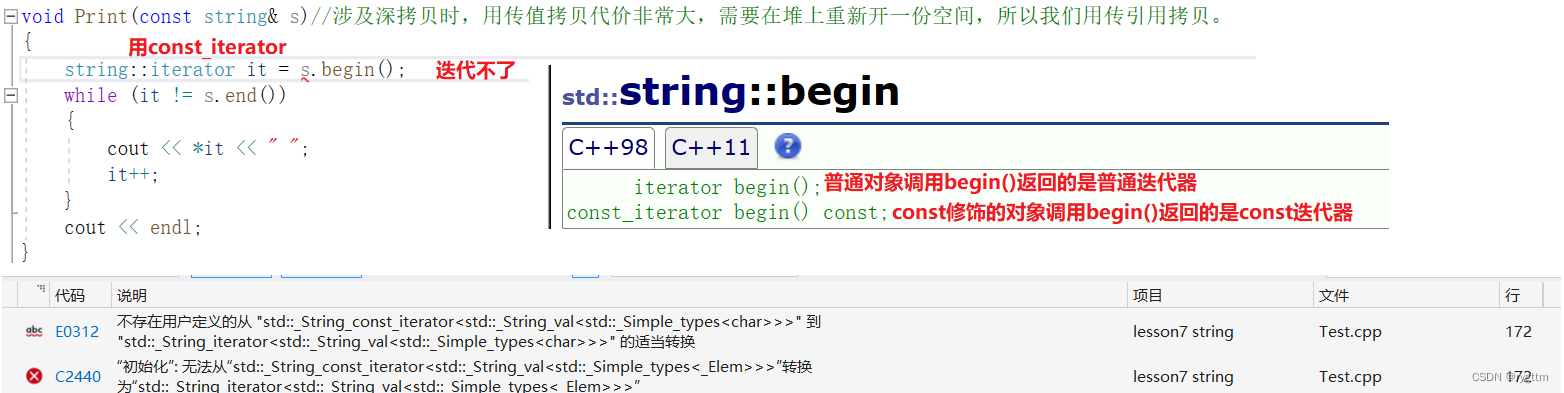
5.
const迭代器的内容只支持读,不支持修改,非const迭代器的内容既可以读也可以修改。对于begin(),end(),rbegin(),rend(),他们每个函数都实现了两个版本,一个用于普通string对象,一个用于const修饰的对象。

6.
const修饰的是迭代器的内容,而不是迭代器本身。相当于const修饰的是指针指向的内容,而不是指针本身。
//迭代器分类:
//正向 反向 --- 普通对象,可以遍历读写容器数据
//const正向 const反向 --- const修饰对象,只能遍历读,不能修改容器数据。void Print(const string& s)//涉及深拷贝时,用传值拷贝代价非常大,需要在堆上重新开一份空间,所以我们用传引用拷贝,并加const修饰。
{//普通迭代器的内容支持读和写,无论是正向还是反向迭代器。//const迭代器的内容仅仅支持遍历读,而不支持写。string::const_iterator cit = s.begin();//普通迭代器编译无法通过,因为const修饰的对象s里的begin返回时,需要用const迭代器来接收。//const修饰的是迭代器变量所指向的内容,相似于指针指向的内容,而不是修饰迭代器本身,也就是指针本身,因为迭代器需要向后遍历。while (cit != s.end()){//*it += 1;cout << *cit << " ";cit++;}cout << endl;//string::const_reverse_iterator rcit = s.rbegin();auto rcit = s.rbegin();//如果嫌长可以用auto推导一下。因为s是const修饰,rbegin又代表反向迭代器,auto能推导出来类型。while (rcit != s.rend()){cout << *rcit << " ";rcit++;}cout << endl;
}
void test_string3()
{string s1("1234");string::iterator it = s1.begin();//正向迭代器while (it != s1.end()){cout << *it << " ";it++;}cout << endl;//string::reverse_iterator rit = s1.rbegin();//反向迭代器auto rit = s1.rbegin();//auto用于类型的自动推导,rbegin()返回的是反向迭代器。while (rit != s1.rend()){cout << *rit << " ";rit++;}cout << endl;Print(s1);
}
7.
在C++11中,iterators新添了4个版本的函数,在原来的4个版本上加了前缀c,表示这四个版本的函数针对于const修饰的对象所使用,但实际上这是多此一举,没啥用,原来的四个版本完全够使用了,可能有的人类和对象,重载函数等知识没学好,搞不清什么时候调用const版本,什么时候调用非const版本。

3.4 类中哪些函数需要实现两个版本?哪些不需要呢?
1.
在迭代器部分可以看到C++98标准的4个函数都实现了两个版本,const和非const,所以只要修改数据的函数就应该实现两个版本,这是否正确呢?
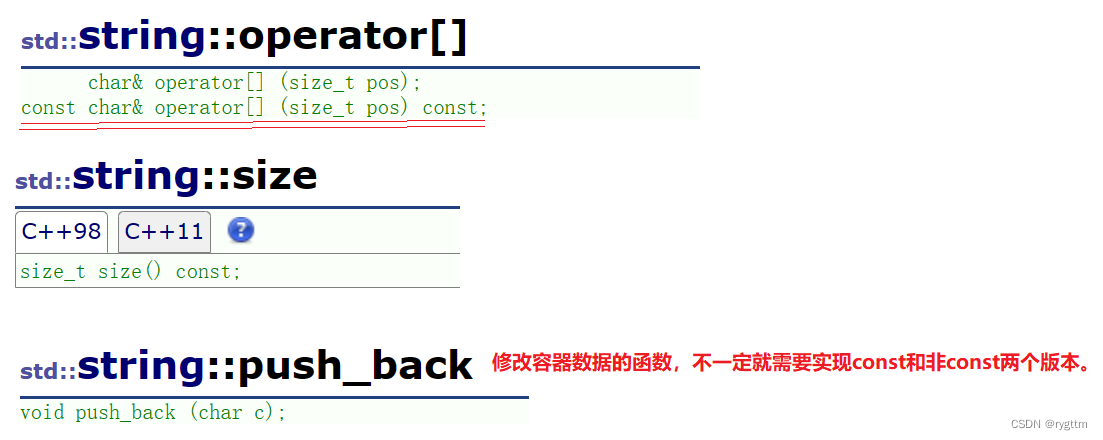
2.
从push_back只实现了一个版本就可以看出,上面的推论实际是不正确的,其实是否需要实现两个版本,要看函数的具体功能是什么。
push_back肯定不具有读的功能,所以只需要实现非const版本即可。而那些迭代器既有可能读又有可能写,所以那些函数具有读写功能,需要实现两个版本。

4.string类对象的容量操作(reserve( ):对比vs和g++对于扩容采取策略的差异)

1.
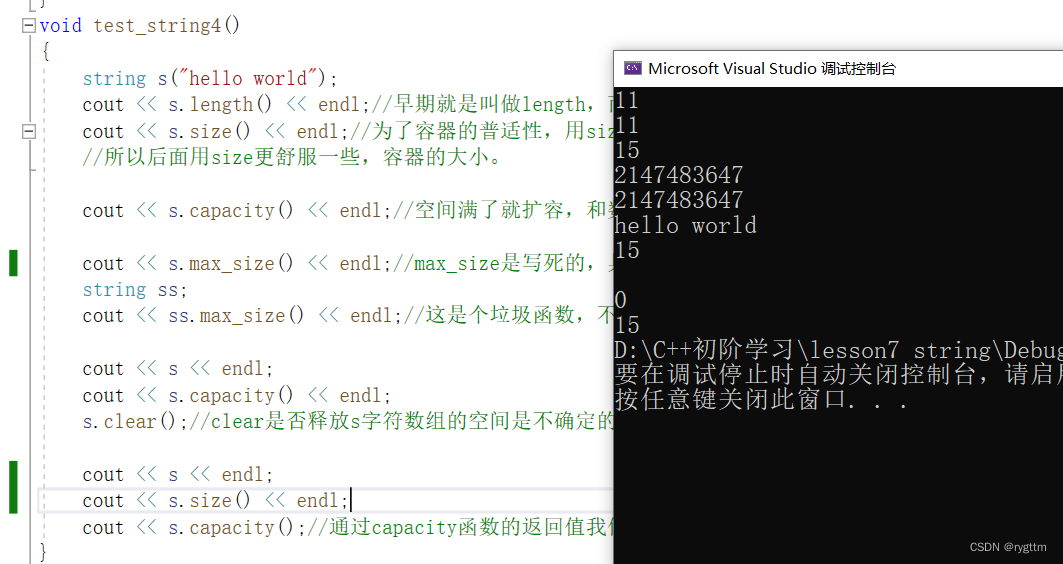
length()和size()返回的大小都是容器有效字符的个数,但为什么会出现两个功能相同的函数呢?这其实是因为某些历史原因,C++只能向前兼容,原本length()是比较适用于string类的,但是用在其他的类上就有些奇怪,比如树,树的长度?怪不怪,所以为了增强普适性,增加了size()来表示各个容器的大小,这样就舒服很多了。
2.
clear()用于抹去容器中的数据,但内存空间是不会释放的,从clear()之后调用的capacity的结果可以看到,内存上开辟的空间是没有释放的,但size会被置为0,所以在打印s时的结果为空。
void test_string4()
{string s("hello world");cout << s.length() << endl;//早期就是叫做length,而不是sizecout << s.size() << endl;//为了容器的普适性,用size更好一点,因为哈希表、树等容器叫做length不太好,叫size更好一些。//所以后面用size更舒服一些,容器的大小。cout << s.capacity() << endl;//空间满了就扩容,和数据结构里的动态顺序表很相似。cout << s.max_size() << endl;//max_size是写死的,具体大小看编译器的底层实现,我的编译器是四十二亿九千万的一半。string ss;cout << ss.max_size() << endl;//这是个垃圾函数,不需要我们关心。cout << s << endl;cout << s.capacity() << endl;s.clear();//clear是否释放s字符数组的空间是不确定的,因为不同的编译器采用的STL版本是不同的,底层实现上有区别。cout << s << endl;cout << s.size() << endl;cout << s.capacity();//通过capacity函数的返回值我们可以知道,vs编译器下的clear是不会释放字符串对象s的空间的。
}
3.
下面的代码可以帮助我们看到,在容器空间大小不够时,vs编译器对于扩容采取的具体策略,将这段代码放到linux的g++编译器下,我们也可以看到g++对于扩容采取的具体策略。
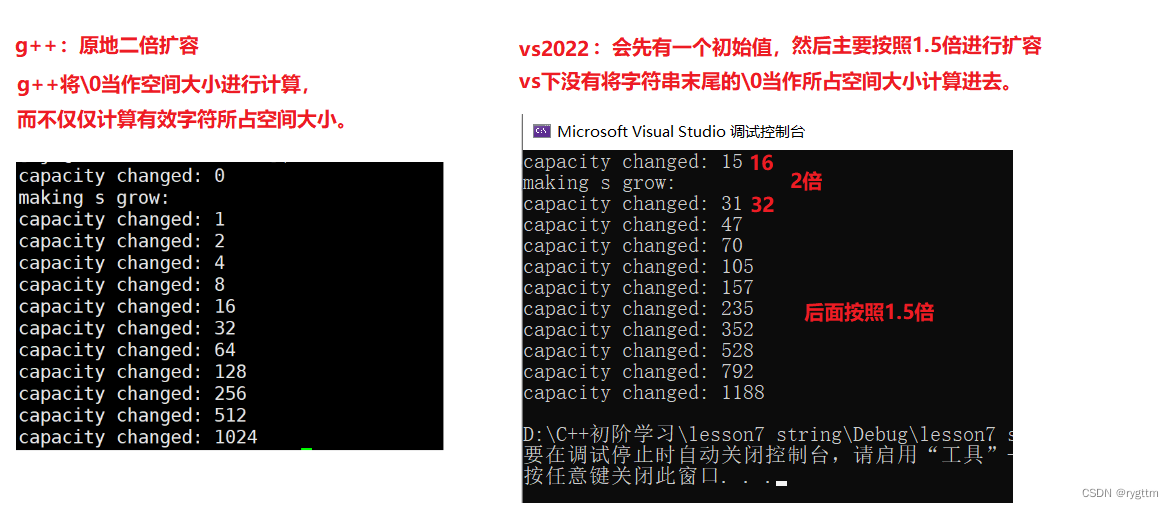
4.
从上面可以看到两个编译器进行扩容的过程,但我们知道扩容的代价实际上是非常大的,因为异地扩容还需要进行原来数据的拷贝,会降低程序的效率,所以能不能在已知空间大小的情况下,一次性提前开辟好呢?避免多次的扩容造成的效率降低。
这个时候可以使用reserve()接口来提前指定好capacity的大小,一次就开辟好对应大小的空间,为字符串预留好空间。
由于对齐因素,vs编译器底层实际开辟的空间要稍微大一些。
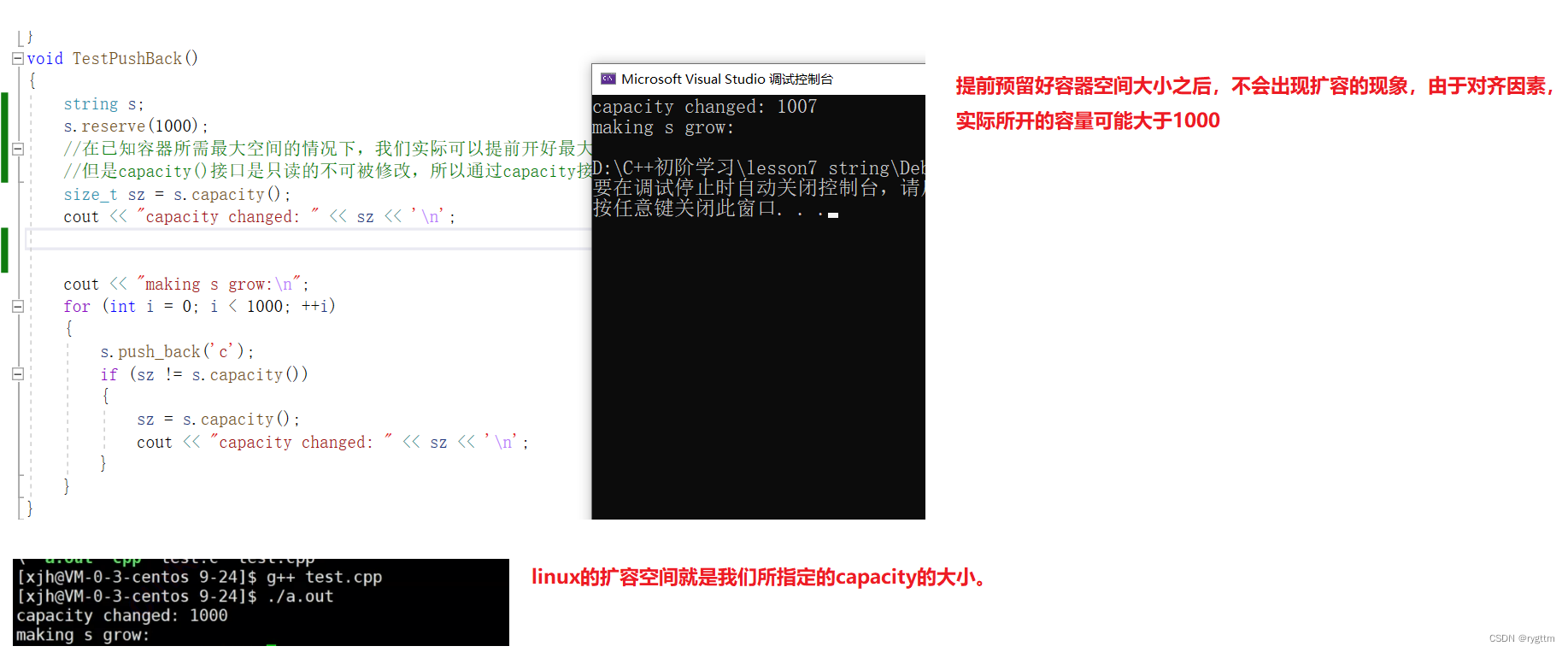
void TestPushBack()
{string s;s.reserve(1000);//reserve的价值就是在已知插入数据的个数前提下,提前开辟好一份空间,避免开始时多次的扩容导致的效率降低。//在已知容器所需最大空间的情况下,我们实际可以提前开好最大空间,这样就不需要扩容了,因为扩容的代价很大,尤其是异地扩容。//但是capacity()接口是只读的不可被修改,所以通过capacity接口来指定容器的最大空间是不行的,这个时候就可以使用接口reserve来指定。//vs由于对齐会将扩容的空间开辟的比我们显示的要大一些,这是因为内存对齐原则,后面学习到内存池的空间配置器时,就知道为什么对齐了//提前预留的空间不够时,push_back还是会自动扩容的,继续扩大capacity的值,我们不用担心。size_t sz = s.capacity();cout << "capacity changed: " << sz << '\n';cout << "making s grow:\n";for (int i = 0; i < 1000; ++i){s.push_back('c');if (sz != s.capacity()){sz = s.capacity();cout << "capacity changed: " << sz << '\n';}}
}
void test_string5()
{TestPushBack();
}
5.
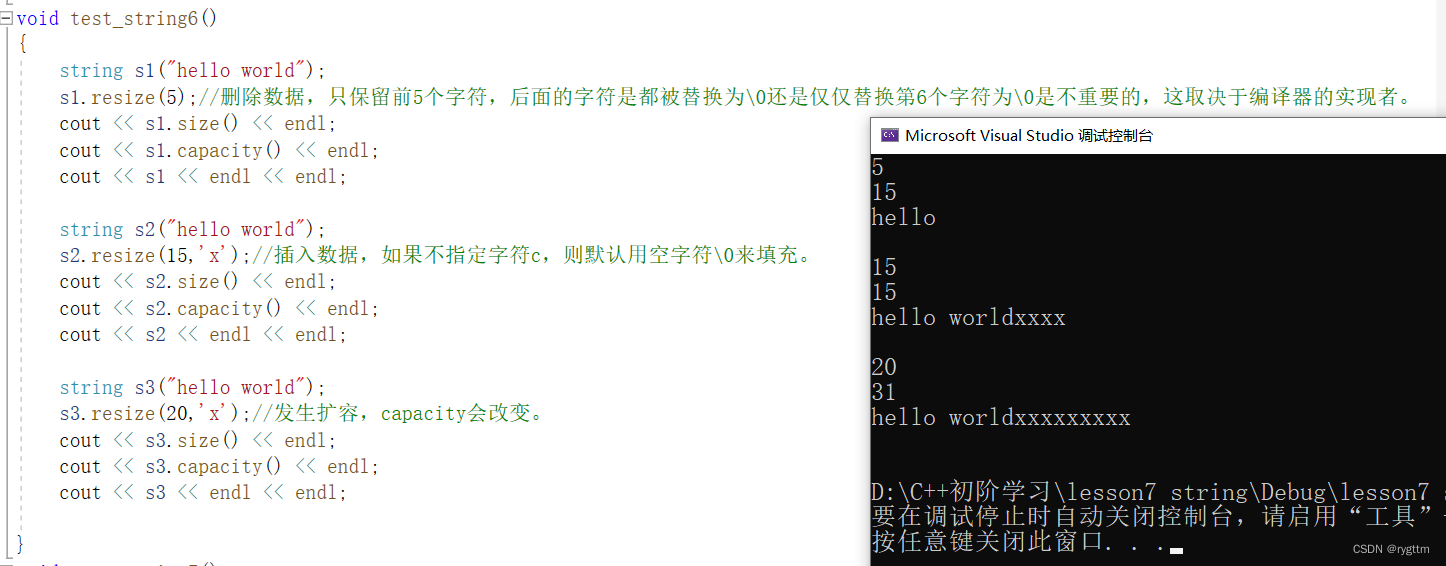
reserve()改变容器的capacity,resize()改变容器的size,对于字符串hello world来说,传参n的大小对应了resize有三种情况。

void test_string6()
{string s1("hello world");s1.resize(5);//删除数据,只保留前5个字符,后面的字符是都被替换为\0还是仅仅替换第6个字符为\0是不重要的,这取决于编译器的实现者。 cout << s1.size() << endl;cout << s1.capacity() << endl;cout << s1 << endl << endl;string s2("hello world");s2.resize(15,'x');//插入数据,如果不指定字符c,则默认用空字符\0来填充。cout << s2.size() << endl;cout << s2.capacity() << endl;cout << s2 << endl << endl;string s3("hello world");s3.resize(20,'x');//发生扩容,capacity会改变。cout << s3.size() << endl;cout << s3.capacity() << endl;cout << s3 << endl << endl;}
6.
C++11新引进的shrink_to_fit()函数用于将capacity减少到和size相等,

5.string类对象的元素访问

1.
operator[]和at的作用一致,都是返回动态顺序表某一位置的字符。
但发生越界访问时,operator[]采用assert断言报错的方式进行解决,而at会抛异常。

2.
C++11引入的back和front用于返回动态数组的首尾元素,但这两个函数实际上不怎么常用,因为operator[0]和operator[s.size()-1]便可以取到顺序表的首尾元素。

6.string类对象的修改操作(operator+= 才是yyds)

1.
push_back()用于单个字符的尾插,如果要向容器中增加字符串的话,利用push_back()的效率就非常低,因为我们需要一个一个字符的尾插。

2.
append函数重载实际和我们的构造函数非常的相似,就好比你在路上碰到一个姑娘,你觉得她非常的眼熟,你焦急的跑过去看她的脸庞,结果发现她竟和你的初恋长的一模一样,你满怀期待的细细询问,发现此女子并非当初的那个她,仅仅只是模样十分相似罢了,你心灰意冷的走开,逐渐开始回味你们美好的当初,但一切好似黄粱一梦,终散为烟……
黄昏里,你又踏上了孤独的旅途,终究还是要回到路上…
append就是那个姑娘,构造函数就是你的初恋。append最常用的接口依旧是参数为常量字符串,其他接口含义这里不做介绍,因为与前面所讲的构造函数十分相似。
3.
operator+=是非常好用的string类对象修改操作函数,运算符重载帮助我们使用自定义类型在形式上十分像使用内置类型,这极大的提升了代码的可读性,堪称string类对象修改函数的yyds,其重载函数有三种形式,分别是常量字符串,string类对象的引用,char型字符c。
void test_string7()
{/*string s1("hello world ");//函数重载的强大s1.push_back('x');s1.push_back('x');s1.append(" hello linux");cout << s1 << endl;string s2(" hello C++");s1.append(s2);cout << s1 << endl;*/string s1("hello world ");//运算符重载的强大s1 += '!';s1 += "hello windows";cout << s1 << endl;string s2(" hello C++");s1 += s2;cout << s1 << endl;
}4.
insert和erase用于在数组的某个具体位置插入或删除字符,但对于string类,不建议使用insert和erase,因为我们知道对于顺序表(string类对象)来说,发生插入和删除数组中某个数据时,要进行其他数据的挪动,代价非常大,所以不到万不得已,不要轻易的使用这两个函数。
erase有自己的缺省值,如果我们用缺省值,那就是npos,-1的补码也就是全1,全1被当作无符号整型处理将会非常大,所以如果不给erase指定删除字符的个数,则会从指定位置pos处后面的所有字符进行删除。
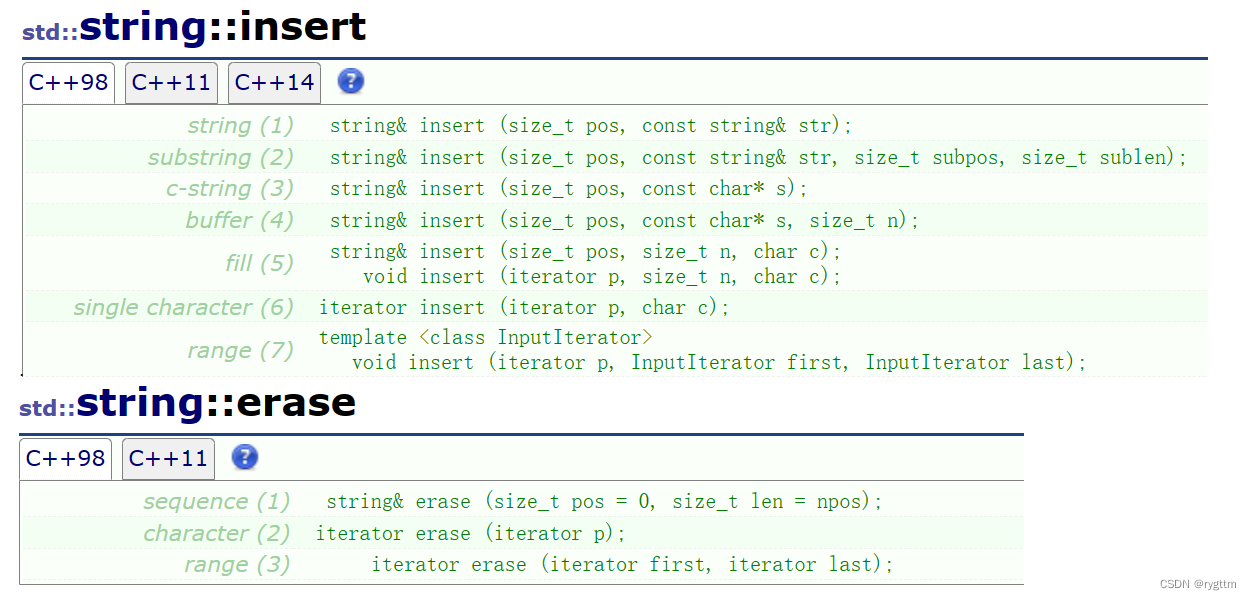
void test_string8()
{string s("hello world");s.insert(0, "wyn");//头部插入,要挪动数据,效率不好,频繁头插会降低效率。cout << s << endl;s.erase(0, 3);cout << s << endl;s.erase(5, 100);//给的数字过大,则有多少删多少。cout << s << endl;s.erase(0);//npos默认值是二十一亿多,所以直接删完。-1存的是补码,也就是全1,全1看作无符号整数就会非常大。cout << s;
}
5.
assign用于将原有字符串用新的字符串进行替代,参数格式与构造函数也非常的相似,assign实际上对比的是赋值重载,因为赋值重载只能将一个字符串完整的赋值给另一个字符串,而assign不仅可以操作完整的字符串,字符串的substr也可以进行操作,例如代码中,我用了"hello wyn lalala"的前9个字符取代了原来的字符串s1.
replace与assign不同的是,replace进行的不是整体字符串的替代,而是字符串中部分字符的替换。例如下面代码中的s2的前5个字符被替换为"hi"
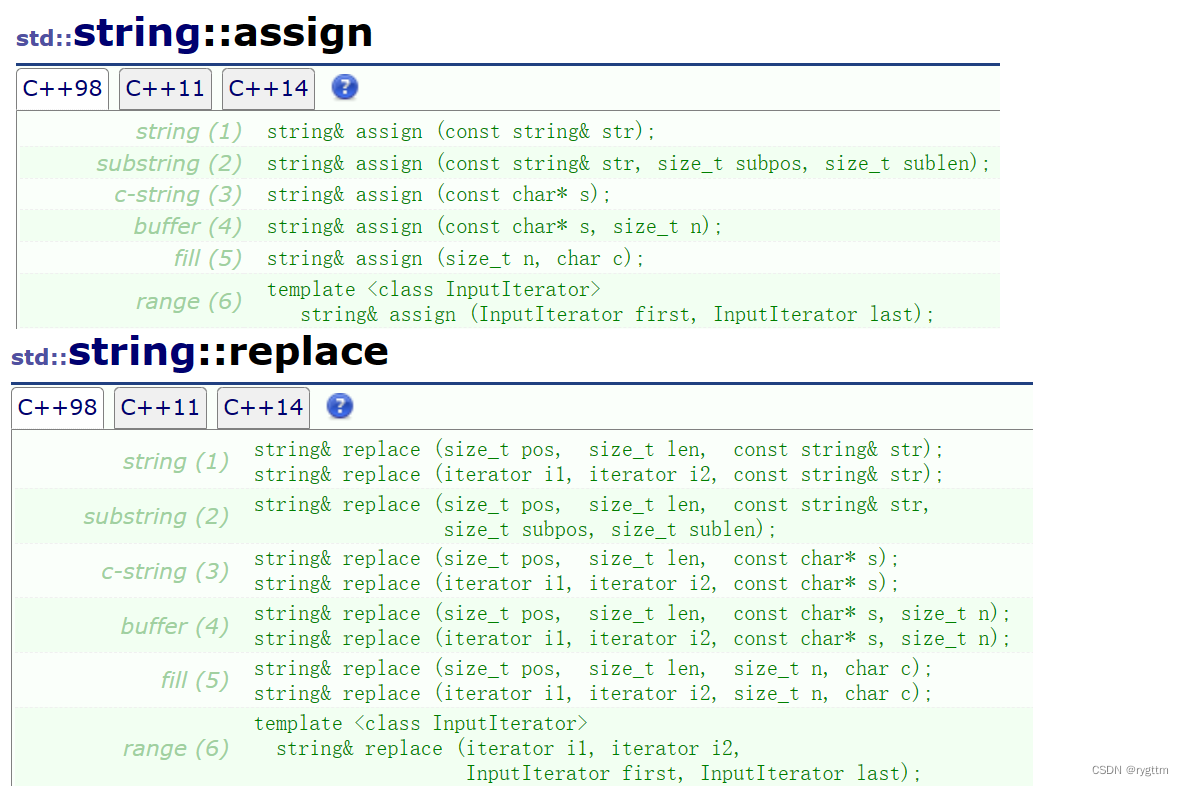
6.
以前在学习C语言时,比较常见的一道题是将字符串中的空格替换为类似于20%这样的字符串,在C语言阶段由于原地替换的代价较大,我们一般会采用重新开辟一块数组,然后从前向后遍历字符串,将每个字符尾插到新的数组里面,遇到空格时,就将"20%"分开尾插到新数组里面,直到字符串遍历结束。
在C++阶段中,这样的问题就显得比较简单了,因为我们有库提供的string,我们可以用find接口配合replace接口来进行字符串中空格的替换,题目解决起来就简单了许多。
除这样的方法,也是可以采用新开辟数组的方式,C++中只要新创建一个string类对象即可,我们用范围for进行遍历循环,利用尾插的思想进行空格的替换,有operator+=和范围for的帮助,解决起来同样很轻松。
void test_string9()
{//assign和replace的功能差别巨大string s1("hello linux and windows");string s2("hello linux and windows");string s3(s2);string s4(s2);//assign对比的是赋值重载,赋值重载只能将一个对象完整的赋值给另一个对象,assign可以将一个对象的某部分进行赋值。s1.assign("hello wyn lalala",9);cout << s1 << endl;s2.replace(0, 5, "hi");//还是不建议用replace,因为他还是要挪动数据,导致效率降低。cout << s2 << endl;//将s3中的所有空格替换为百分号size_t pos = s3.find(' ', 0);while (pos != string::npos){s3.replace(pos, 1, "20%");//replace的效率非常低pos = s3.find(' ', pos);}cout << s3 << endl;string ret;ret.reserve(s4.size() + 10);//提前开好空间大小,避免扩容带来的效率降低for (auto ch : s4){if (ch != ' ')ret += ch;elseret += "20%";}cout << ret << endl;}
7.string类对象的字符串操作(String operations)

1.
find和rfind用于进行字符串中某部分字符的查找,查找的对象可以是字符,string类对象,常量字符串等等,我们可以指定开始查找的位置等等,如果不指定pos,则默认从字符串的开头进行查找,rfind与find一样,只不过rfind会将最后一个字符认定为开始,倒着去进行查找,有点像reverse_iterator反向迭代器,

2.
substr可以用来截取字符串中的某一部分,并将这一部分重新构造出一个string类对象然后返回,需要我们指定开始截取的位置和需要截取的长度,如果不指定截取长度,则默认从截取位置向后将所有的字符串进行截取,因为缺省值是npos.

3.
如果要让我们截取某一字符串的后缀名,我们就可以用find和substr配合进行使用,截取到字符串的后缀名。
在linux中的文件名后缀有很多组合在一起的,所以这时候如果要查找字符’.'的位置,我们可以从后往前查,利用rfind即可做到。
void test_string11()
{// "Test.cpp"string file;cin >> file;//要求取file的后缀int pos = file.find('.');if (pos != string::npos){//string suffix = file.substr(pos, file.size() - pos);//计算.后面的字符有多少string suffix = file.substr(pos);//利用缺省值npos作为缺省参数cout << suffix << endl;}// "Test.cpp.zip.tar"//要求取file的后缀string file2;cin >> file2;pos = file.rfind('.');if (pos != string::npos){string suffix = file2.substr(pos);cout << suffix << endl;}}
4.
c_str用于返回C语言式的字符串,类型是常量字符串这个接口的设计主要是为了让C++能够和C语言的接口配合起来进行使用。
例如C语言中某些文件操作接口,参数要求传字符串,这个时候可以用c_str()来实现常量字符串的传参,让C++和C语言接口能够配合起来进行使用。
data的作用和c_str相同,他也是历史遗留下来的接口,我们只要用c_str就可以了,这个更加常用一些。

void test_string10()
{//c_str可以让C++更好的兼容C语言,data的功能和c_str类似,但平常都用c_str。string file("test.cpp");FILE* fp = fopen(file.c_str(), "r");//"r"代表常量字符串,'r'代表char型的字符,两者的权限是不一样的,一个可读可写,一个只读。assert(fp);char ch = fgetc(fp);while (ch != EOF){cout << ch;ch = fgetc(fp);}fclose(fp);
}
8.string类的非成员函数重载

1.
getline是命名空间std封装的一个函数,它的作用有点类似于C语言的fgets,都是用于获取一行字符串,默认的scanf和cin都是以空格和换行符作为字符串的分隔,所以当出现含有空格的字符串需要输入时,cin就不起作用了,getline就派上用场了。
下面这道题就是经典的getline的使用场景题目。
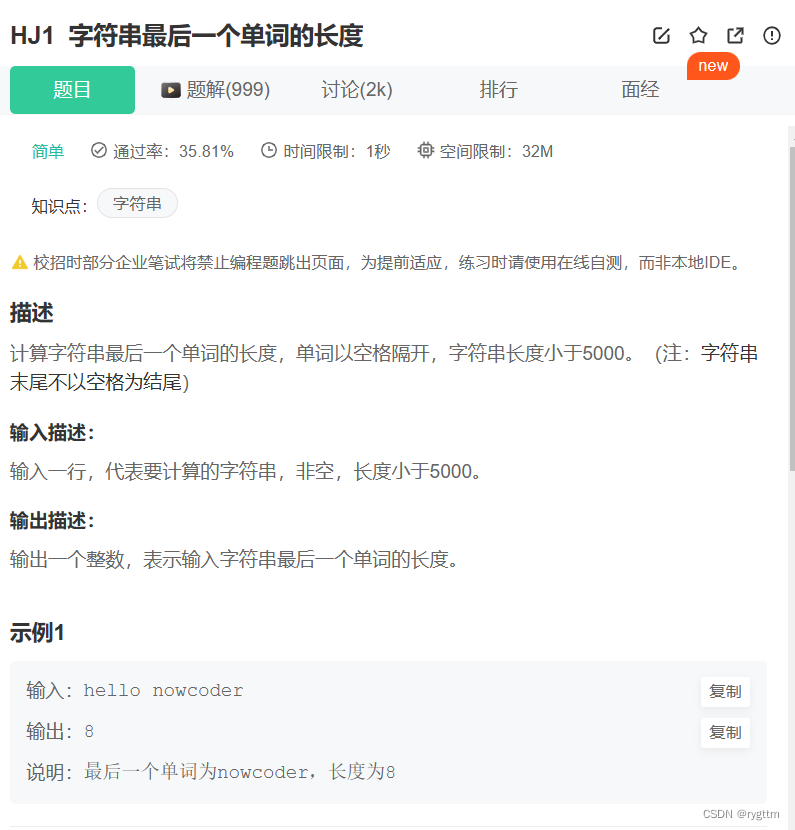
#include <iostream>
#include <string>
using namespace std;int main()
{string str;getline(cin,str);int pos = str.rfind(' ');cout << str.size() - pos - 1 << endl;
}
2.
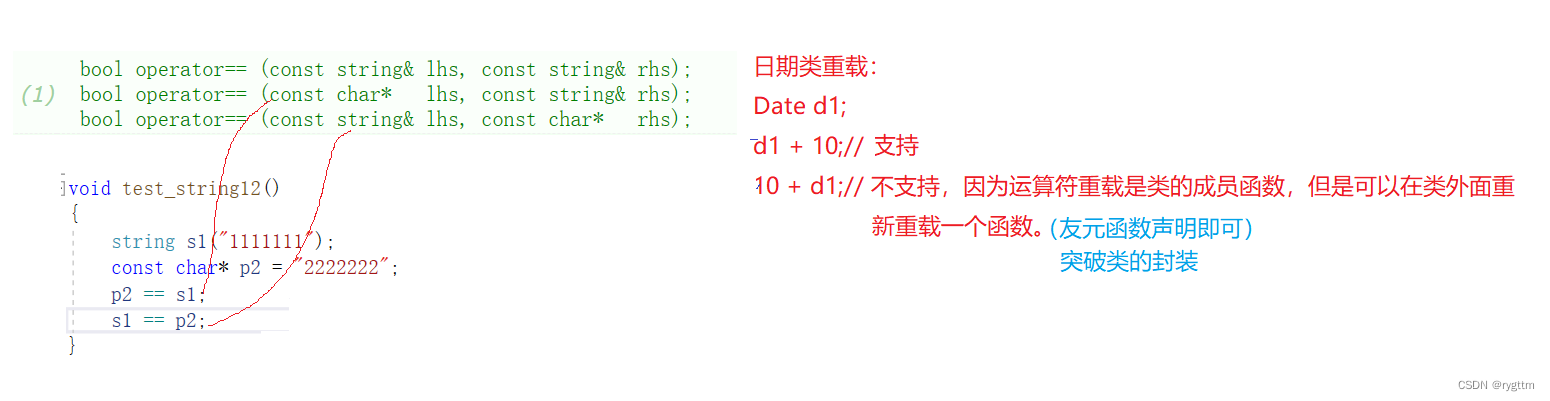
下面是string类对象的关系运算符重载函数,每一个运算符都重载了三个形式,实际上是为了满足多种使用场景。
例如在比较字符串和string类对象时,运算符左右两侧的类型由于写法不同导致类型不同,则对应的运算符重载为了满足不同的写法,就必须实现多个重载函数。
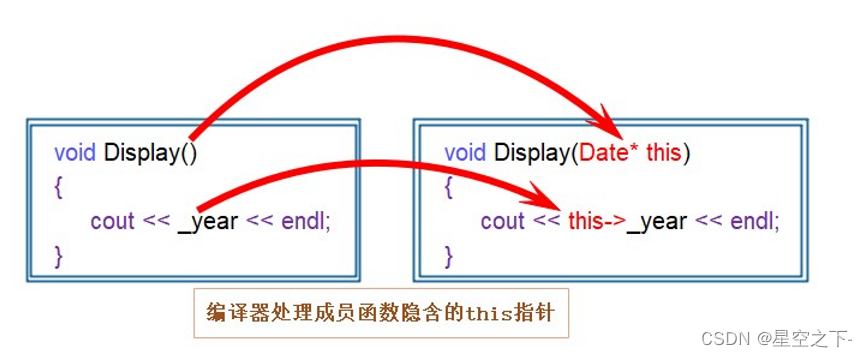
而d1+10可以支持,是因为日期类有自己的类成员函数,但如果改成10+d1就无法调用对应的函数了,因为10抢了类成员函数中this指针的位置。

void test_string12()
{string s1("1111111");const char* p2 = "2222222";p2 == s1;s1 == p2;
}
相关文章:
【C++】string类的基本使用
层楼终究误少年,自由早晚乱余生。你我山前没相见,山后别相逢… 文章目录一、编码(ascll、unicode字符集、常用的utf-8编码规则、GBK)1.详谈各种编码规则2.汉字在不同的编码规则中所占字节数二、string类的基本使用1.string类的本质…...
【第一章 - 绪论】- 数据结构(近八千字详解)
目录 一、 数据结构的研究内容 二、基本概念和术语 2.1 - 数据、数据元素、数据项和数据对象 2.2 - 数据结构 2.2.1 - 逻辑结构 2.2.2 - 存储结构 2.3 - 数据类型和抽象数据类型 三、抽象数据类型的表现与实现 四、算法和算法分析 4.1 - 算法的定义及特性 4.2 - 评价…...

QIfw制作软件安装程序
前言 Qt Installer Framework是Qt默认包的发布框架。它很方便,使用静态编译Qt制作而成。从Qt的下载地址中下载Qt Installer Framework,地址是:http://download.qt.io/official_releases/qt-installer-framework/ 。支持我们自定义一些我们需要的东西包括页面、交互等。 框…...
【C++】C++入门(上)
前言: C是在C语言的基础上不断添加东西形成的一门语言,在C语言的基础上引入了面向对象的思想。因此C既是面向对象的语言,也是面向过程的语言。因为C是以C语言为基础的,所以基本上C兼容所有的C语言。目前最常用的版本是C98和C11这两…...
)
5. Kimball维度建模常用术语及概念(一)
文章目录维度建模过程相关概念1. 收集业务需求与数据实现2. 协作维度建模研讨3. 四步骤维度设计过程4. 业务过程5. 粒度6. 描述环境的维度7. 用于度量的事实8. 维度模型事实表技术术语1. 事实表结构2. 可加、半可加、不可加事实3. 事实表中的空值4. 一致性事实5. 事务事实表6. …...

内核调试之Panic-Oops日志分析
这部分我们接着之前的思考,看看内核异常日志的分析。 1 Panic 调试 2 Oops调试 内核出现Panic或Oops错误,如何分析定位问题原因? 首先,保留现场,如下所示为一次非法虚拟地址访问错误。 EXT4-fs (sdc3): recovery c…...
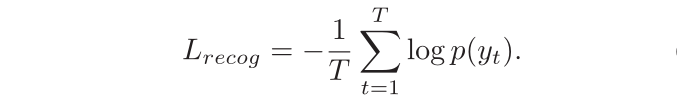
论文解读 | [AAAI2020] 你所需要的是边界:走向任意形状的文本定位
目录 1、研究背景 2、研究的目的 3、方法论 3.1 Boundary Point Detection Network(BPDN) 3.2 Recognition Network 3.3 Loss Functions 4、实验及结果 论文连接:https://ojs.aaai.org/index.php/AAAI/article/view/6896 1、研究背景 最近,旨在…...

数据挖掘流程简单示例10min
数据挖掘流程简单示例10min 套路: 准备数据实现算法测试算法 任务1:亲和性分析 如果一个顾客买了商品X,那么他们可能愿意买商品Y衡量方法: 支持度support : 所有买X的人数 置信度confidence : 所有买X和Y的人数所有买X的人数…...
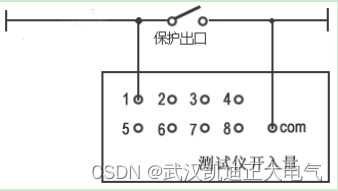
KDJB1200六相继电保护测试仪
一、概述 KDJB1200继电保护测试仪是在参照电力部颁发的《微机型继电保护试验装置技术条件(讨论稿)》的基础上,广泛听取用户意见,总结目前国内同类产品优缺点,充分使用现代新的的微电子技术和器件实现的一种新型小型化微机继电保护测试仪。可…...
从WEB到PWA 开发-发布-安装
见意如题!本文主要来说说PWA开发!作为一个前端程序员,在没有任何Android/IOS的开发情况下,想想我们有多少种方法来开发一个原生移动应用程序!我们可以有非原生、混合开发,PWA等等手段。类似uniappÿ…...

FPGA纯vhdl实现MIPI CSI2 RX视频解码输出,OV13850采集,提供工程源码和技术支持
目录1、前言2、Xilinx官方主推的MIPI解码方案3、纯Vhdl方案解码MIPI4、vivado工程介绍5、上板调试验证6、福利:工程代码的获取1、前言 FPGA图像采集领域目前协议最复杂、技术难度最高的应该就是MIPI协议了,MIPI解码难度之高,令无数英雄竞折腰…...

《NFL橄榄球》:卡罗来纳黑豹·橄榄1号位
卡罗来纳黑豹(英语:Carolina Panthers)是一支位于北卡罗来纳州夏洛特的职业美式橄榄球球队。他们是国家美式橄榄球联合会的南区其中一支球队。他们与杰克逊维尔美洲虎在1995年加入NFL,成为扩充球队。 2018年球队市值为23亿美元&am…...
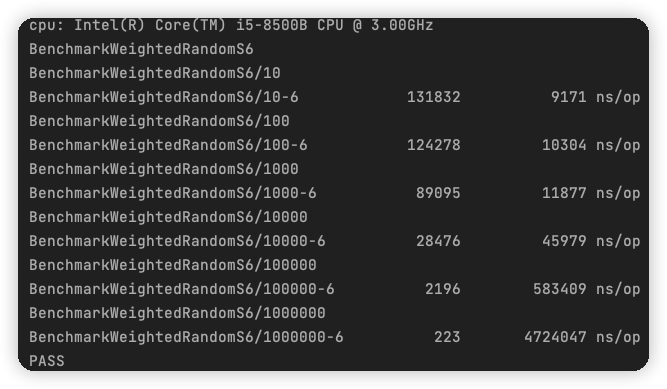
我说我为什么抽不到SSR,原来是这段代码在作祟...
本文是龚国玮所写,熊哥有所新增修改删减,原文见文末。 我说我为什么抽不到SSR,原来是加权随机算法在作祟 阅读本文需要做好心理准备,建议带着深究到底的决心和毅力进行学习! 灵魂拷问 为什么有 50% 的几率获得金币&a…...

MySQL MGR 集群新增节点
前言 服务器规划现状(CentOS7.x) IP地址主机名部署角色192.168.x.101mysql01mysql192.168.x.102mysql02mysql192.168.x.103mysql03mysql192.168.x.104proxysql01proxysql、keepalived192.168.x.105proxysql02proxysql、keepalived 新增服务器IP&#x…...

【单目标优化算法】蜣螂优化算法(Dung beetle optimizer,DBO)(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
【C++】类和对象入门必知
面向过程和面向对象的初步认识类的引入类的定义类的访问限定符封装类的作用域类的实例化类对象模型this指针C语言和C实现Stack的对比面向过程和面向对象的初步认识 C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解…...

day38 动态规划 | 509、斐波那契数 70、爬楼梯 746、使用最小花费爬楼梯
题目 509、斐波那契数 斐波那契数,通常用 F(n) 表示,形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0,F(1) 1 F(n) F(n - 1) F(n - 2),其…...

2023年备考软考必须知道的6件事
不知不觉,距离2023年上半年软考也只有不到100天的时间了,报名入口也将在3月13日正式开通,你是正在犹豫是否参加考试? 还是已经开始着手准备复习? 关于软考考试你还有哪些疑问? 2023年备考软考必须知道的6件事,建议收藏…...

GLOG如何控制输出的小数点位数
1 问题 在小白的蹩脚翻译演绎型博文《GLOG从入门到入门》中,有位热心读者提问说:在保存日志时,浮点型变量的小数位数如何设置? 首先感谢这位“嘻嘻哈哈的地球人”赏光阅读了小白这不太通顺的博客文章,并提出了一个很…...
2022年全国职业院校技能大赛(中职组)网络安全竞赛试题A(6)
目录 模块A 基础设施设置与安全加固 一、项目和任务描述: 二、服务器环境说明 三、具体任务(每个任务得分以电子答题卡为准) A-1任务一:登录安全加固(Windows) 1.密码策略 a.密码策略必须同时满足大小…...
搞定RPG游戏中的等级成长与回复效果)
UE5 GAS实战:用一张曲线表格(Curve Table)搞定RPG游戏中的等级成长与回复效果
UE5 GAS实战:用曲线表格构建动态RPG成长系统在角色扮演游戏的开发中,数值成长系统往往是最考验设计功底的环节之一。想象一下,当玩家从1级升到10级的过程中,如果每次升级带来的属性提升都是固定数值,这种线性增长很快就…...

AssetStudio深度原理与Unity资源逆向实战指南
1. 这不是“又一个Unity资源提取教程”,而是我三年里反复重装AssetStudio的总结AssetStudio、Unity资源提取、Unity游戏逆向、Unity AssetBundle解析——这几个词,几乎是我过去三年在独立游戏开发、MOD社区支持和老游戏存档修复工作中出现频率最高的关键…...
)
别再死磕OFDMA了!用Python+PyTorch手把手复现NOMA的SIC接收机(附代码)
用PythonPyTorch实战NOMA的SIC接收机:从理论到代码实现在5G和后5G时代,非正交多址接入(NOMA)技术因其卓越的频谱效率而备受关注。与传统的正交多址(OFDMA)不同,NOMA允许用户在相同时频资源上叠加传输,通过功率域复用和先进的接收机…...

Linux渗透测试实战命令指南:从信息收集到横向移动
1. 这不是命令手册,而是一张渗透测试现场的“作战地图”你有没有过这样的经历:坐在靶机前,刚扫出一个Web服务,脑子里立刻蹦出七八个工具名——nmap、gobuster、sqlmap、hydra……可手一伸向键盘,却卡在了第一个参数上&…...

上位机知识篇---安装包文件名各部分的含义
torch-2.5.0a0872d972e41.nv24.08.17622132-cp310-cp310-linux_aarch64.whl这个长长的文件名是一个为特定平台预编译的 PyTorch 安装包(.whl 文件) 的名字。它遵循 Python 的 PEP 427 命名规范,每一部分都精确描述了该软件包的兼容性信息。我…...

权威测评!2026年顶尖AI论文写作软件榜单,高质初稿轻松写
2026 年实测 10 款主流 AI 论文工具,千笔AI以全流程覆盖 语义级降重 免费查重领跑综合榜;ThouPen 稳坐留学生毕业全流程工具头把交椅;免费工具中DeepSeek Scholar、豆包学术版表现亮眼,30 分钟即可生成万字高质量初稿࿰…...

[特殊字符] Lucky从零到一的系统搭建里程碑 | 写给后人的初心与使命
🌱 从零到一的足迹 写给未来的你们: 这不是炫耀,不是宣传。 这是一个普通人,一个退伍军人,一个什么都不懂的人,和AI一起创造的故事。 如果这个系统让你们受益,请记住:初心、根、使命…...

IPXWrapper完整教程:让经典游戏在现代Windows系统重获联机能力
IPXWrapper完整教程:让经典游戏在现代Windows系统重获联机能力 【免费下载链接】ipxwrapper 项目地址: https://gitcode.com/gh_mirrors/ip/ipxwrapper 你是否怀念《星际争霸》《帝国时代》《红色警戒2》等经典游戏的局域网对战乐趣?在现代Windo…...

kkFileView在Linux服务器上安装踩坑全记录:从字体乱码到Office组件报错的保姆级排错指南
kkFileView部署实战:Linux服务器疑难问题深度排查手册当你在凌晨两点收到服务器告警,发现刚部署的kkFileView服务又崩溃了——这已经是本周第三次。日志里那些晦涩的报错信息像是一道道密码,而生产环境的文件预览功能明天早上就要交付。这不是…...
)
用ChatGPT写投资人邮件:72小时内获3家TS的实测框架(含Prompt工程+合规校验清单)
更多请点击: https://codechina.net 第一章:用ChatGPT写投资人邮件:72小时内获3家TS的实测框架(含Prompt工程合规校验清单) 在融资关键期,一封精准、可信、有温度的投资人邮件,往往比BP更早决定…...