pandas 筛选数据的 8 个骚操作
日常用Python做数据分析最常用到的就是查询筛选了,按各种条件、各种维度以及组合挑出我们想要的数据,以方便我们分析挖掘。
东哥总结了日常查询和筛选常用的种骚操作,供各位学习参考。本文采用sklearn的boston数据举例介绍。
from sklearn import datasets
import pandas as pdboston = datasets.load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
1. []
第一种是最快捷方便的,直接在dataframe的[]中写筛选的条件或者组合条件。比如下面,想要筛选出大于NOX这变量平均值的所有数据,然后按NOX降序排序。
df[df['NOX']>df['NOX'].mean()].sort_values(by='NOX',ascending=False).head()

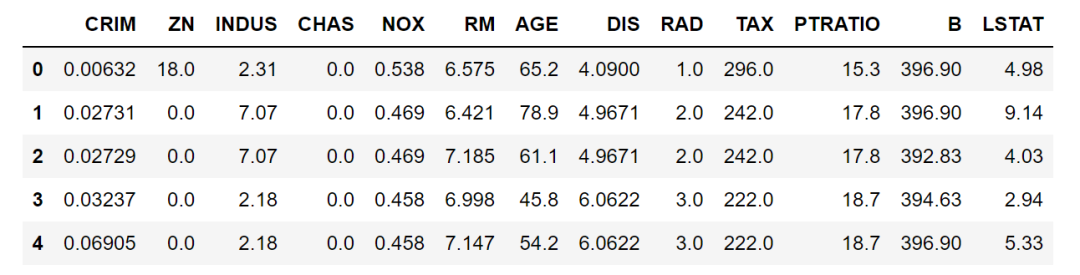
当然,也可以使用组合条件,条件之间使用逻辑符号& |等。比如下面这个例子除了上面条件外再加上且条件CHAS为1,注意逻辑符号分开的条件要用()隔开。
df[(df['NOX']>df['NOX'].mean())& (df['CHAS'] ==1)].sort_values(by='NOX',ascending=False).head()
2. loc/iloc
除[]之外,loc/iloc应该是最常用的两种查询方法了。loc按标签值(列名和行索引取值)访问,iloc按数字索引访问,均支持单值访问或切片查询。除了可以像[]按条件筛选数据以外,loc还可以指定返回的列变量,从行和列两个维度筛选。
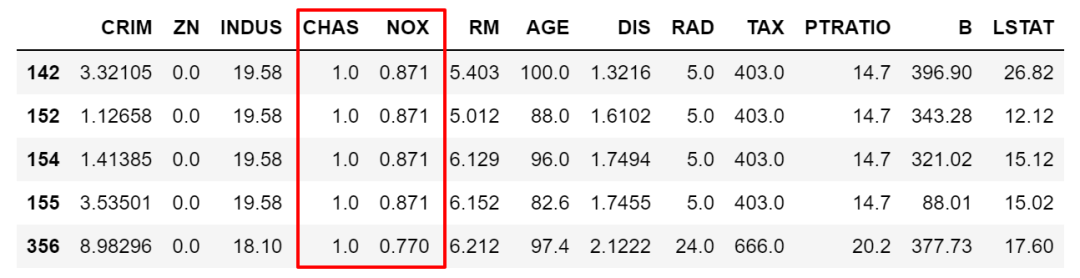
比如下面这个例子,按条件筛选出数据,并筛选出指定变量,然后赋值。
df.loc[(df['NOX']>df['NOX'].mean()),['CHAS']] = 2
3. isin
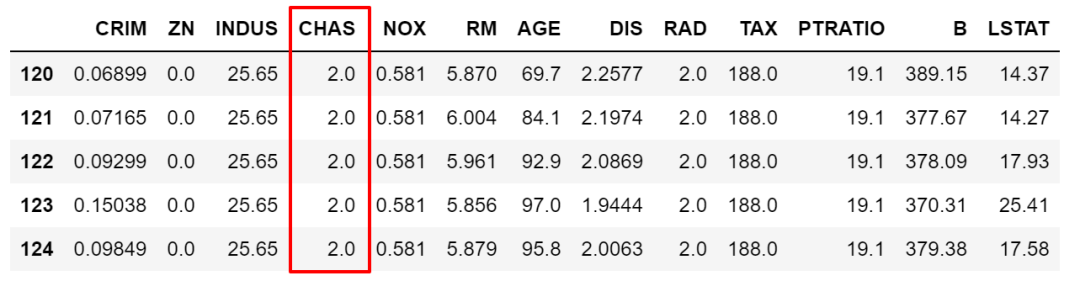
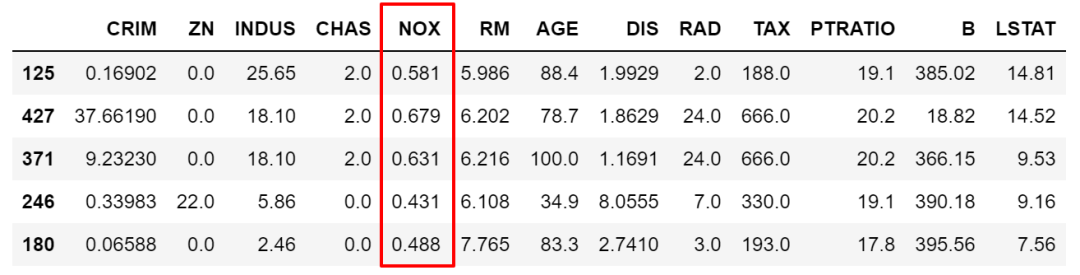
上面我们筛选条件< > == !=都是个范围,但很多时候是需要锁定某些具体的值的,这时候就需要isin了。比如我们要限定NOX取值只能为0.538,0.713,0.437中时。
df.loc[df['NOX'].isin([0.538,0.713,0.437]),:].sample(5)
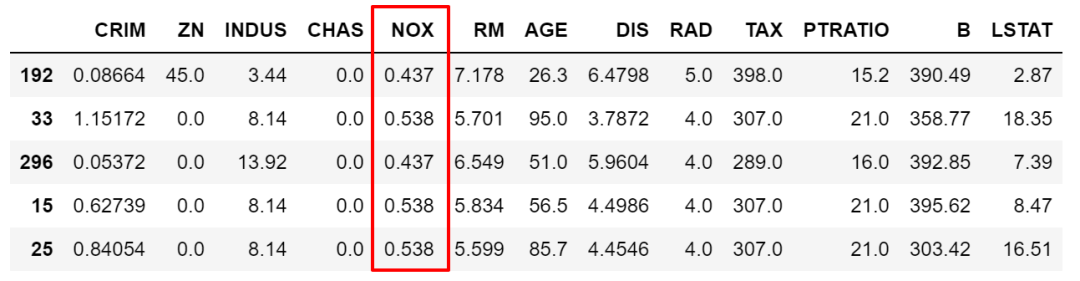
当然,也可以做取反操作,在筛选条件前加~符号即可。
df.loc[~df['NOX'].isin([0.538,0.713,0.437]),:].sample(5)
4. str.contains
上面的举例都是数值大小比较的筛选条件,除数值以外当然也有字符串的查询需求。pandas里实现字符串的模糊筛选,可以用.str.contains()来实现,有点像在SQL语句里用的是like。
下面利用titanic的数据举例,筛选出人名中包含Mrs或者Lily的数据,|或逻辑符号在引号内。
train.loc[train['Name'].str.contains('Mrs|Lily'),:].head()

.str.contains()中还可以设置正则化筛选逻辑。
- case=True:使用case指定区分大小写
- na=True:就表示把有NAN的转换为布尔值True
- flags=re.IGNORECASE:标志传递到re模块,例如re.IGNORECASE
- regex=True:regex :如果为True,则假定第一个字符串是正则表达式,否则还是字符串
5. where/mask
在SQL里,我们知道where的功能是要把满足条件的筛选出来。pandas中where也是筛选,但用法稍有不同。
where接受的条件需要是布尔类型的,如果不满足匹配条件,就被赋值为默认的NaN或其他指定值。举例如下,将Sex为male当作筛选条件,cond就是一列布尔型的Series,非male的值就都被赋值为默认的NaN空值了。
cond = train['Sex'] == 'male'
train['Sex'].where(cond, inplace=True)
train.head()

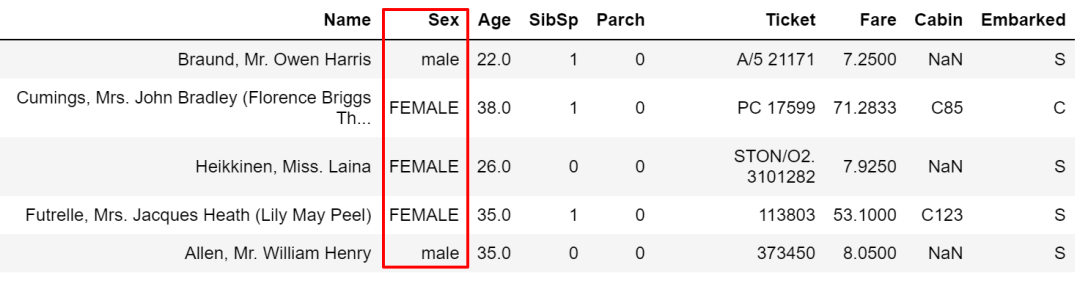
也可以用other赋给指定值。
cond = train['Sex'] == 'male'
train['Sex'].where(cond, other='FEMALE', inplace=True)
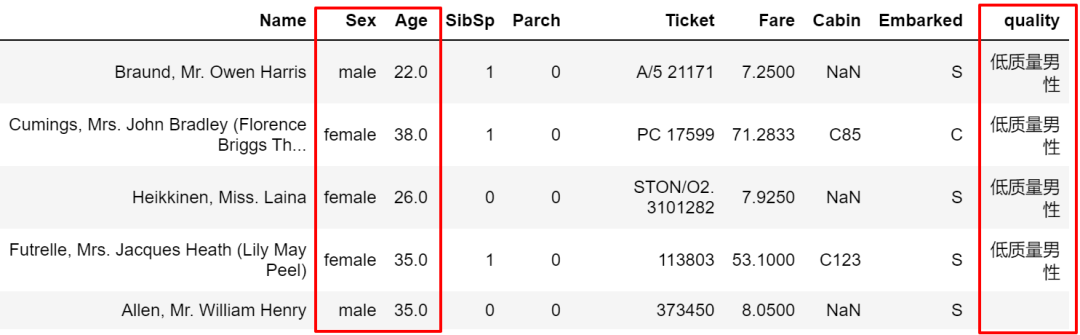
甚至还可以写组合条件。
train['quality'] = ''
traincond1 = train['Sex'] == 'male'
cond2 = train['Age'] > 25train['quality'].where(cond1 & cond2, other='低质量男性', inplace=True)
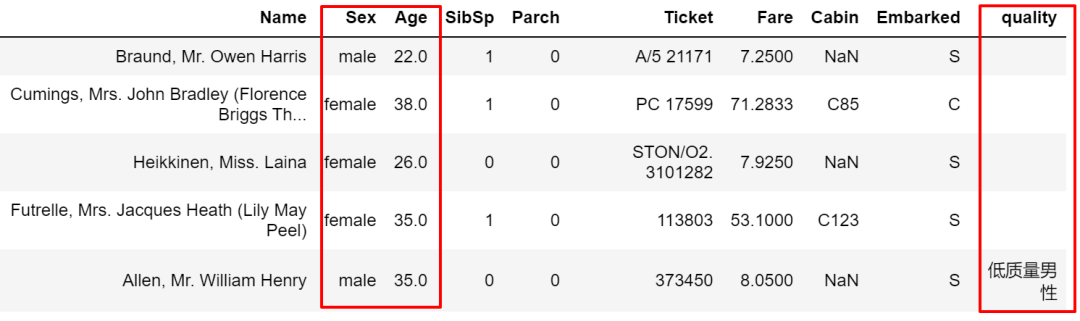
mask和where是一对操作,与where正好反过来。
train['quality'].mask(cond1 & cond2, other='低质量男性', inplace=True)
6. query
这是一种非常优雅的筛选数据方式。所有的筛选操作都在''之内完成。
# 常用方式
train[train.Age > 25]
# query方式
train.query('Age > 25')
上面的两种方式效果上是一样的。再比如复杂点的,加入上面的str.contains用法的组合条件,注意条件里有''时,两边要用""包住。
train.query("Name.str.contains('William') & Age > 25")
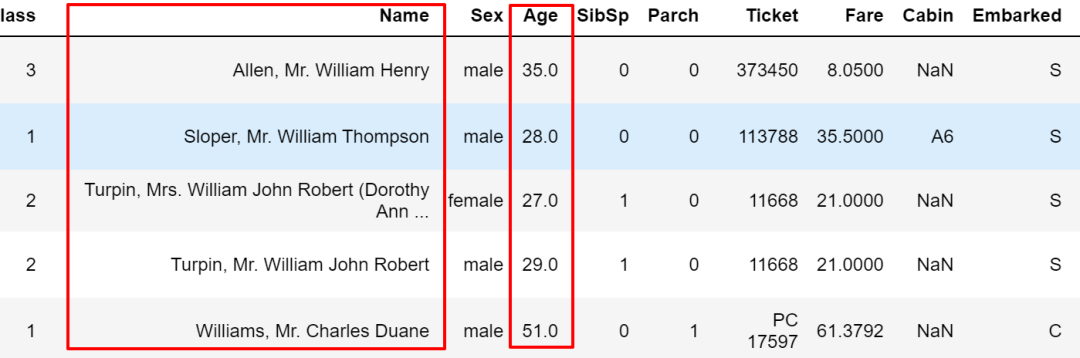
在query里还可以通过@来设定变量。
name = 'William'
train.query("Name.str.contains(@name)")
7. filter
filter是另外一个独特的筛选功能。filter不筛选具体数据,而是筛选特定的行或列。它支持三种筛选方式:
- items:固定列名
- regex:正则表达式
- like:以及模糊查询
- axis:控制是行index或列columns的查询
下面举例介绍下。
train.filter(items=['Age', 'Sex'])

train.filter(regex='S', axis=1) # 列名包含S的
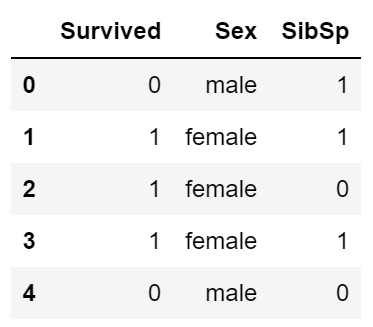
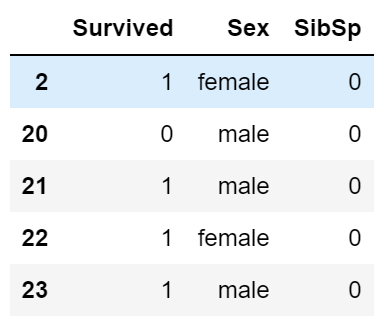
train.filter(like='2', axis=0) # 索引中有2的

train.filter(regex='^2', axis=0).filter(like='S', axis=1)
8. any/all
any方法意思是,如果至少有一个值为True结果便为True,all需要所有值为True结果才为True,比如下面这样。
>> train['Cabin'].all()
>> False
>> train['Cabin'].any()
>> True
any和all一般是需要和其它操作配合使用的,比如查看每列的空值情况。
train.isnull().any(axis=0)

再比如查看含有空值的行数。
>>> train.isnull().any(axis=1).sum()
>>> 708
e
`any`和`all`一般是需要和其它操作配合使用的,比如查看每列的空值情况。train.isnull().any(axis=0)
[外链图片转存中...(img-QYyk6pc2-1694485667807)]再比如查看含有空值的行数。train.isnull().any(axis=1).sum()
708
相关文章:
pandas 筛选数据的 8 个骚操作
日常用Python做数据分析最常用到的就是查询筛选了,按各种条件、各种维度以及组合挑出我们想要的数据,以方便我们分析挖掘。 东哥总结了日常查询和筛选常用的种骚操作,供各位学习参考。本文采用sklearn的boston数据举例介绍。 from sklearn …...
【随想】每日两题Day.3(实则一题)
题目:59.螺旋矩阵|| 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 示例 1: 输入:n 3 输出:[[1,2,3],[8,9,4],[7,6,5]]示例 2: …...

阿里后端开发:抽象建模经典案例【文末送书】
文章目录 写作前面1.抽象思维2.软件世界中的抽象3. 经典抽象案例4. 抽象并非一蹴而就!需要不断假设、验证、完善5. 推荐一本书 写作末尾 写作前面 在互联网行业,软件工程师面对的产品需求大都是以具象的现实世界事物概念来描述的,遵循的是人…...
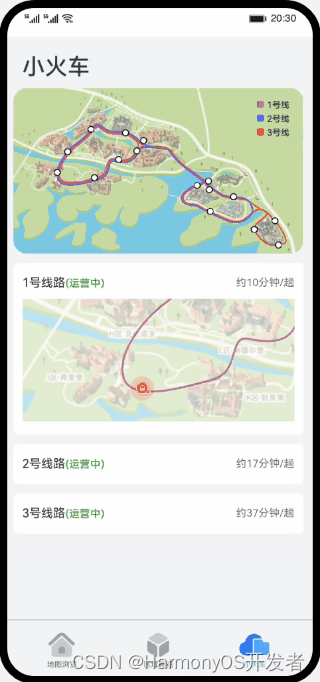
HarmonyOS Codelab 优秀样例——溪村小镇(ArkTS)
一、介绍 溪村小镇是一款展示溪流背坡村园区风貌的应用,包括园区内的导航功能,小火车行车状态查看,以及各区域的风景展览介绍,主要用于展示HarmonyOS的ArkUI能力和动画效果。具体包括如下功能: 打开应用时进入启动页&a…...

Mybatis---第二篇
系列文章目录 文章目录 系列文章目录一、#{}和${}的区别是什么?二、简述 Mybatis 的插件运行原理,如何编写一个插件一、#{}和${}的区别是什么? #{}是预编译处理、是占位符, KaTeX parse error: Expected EOF, got # at position 27: …接符。 Mybatis 在处理#̲{}时,会将…...
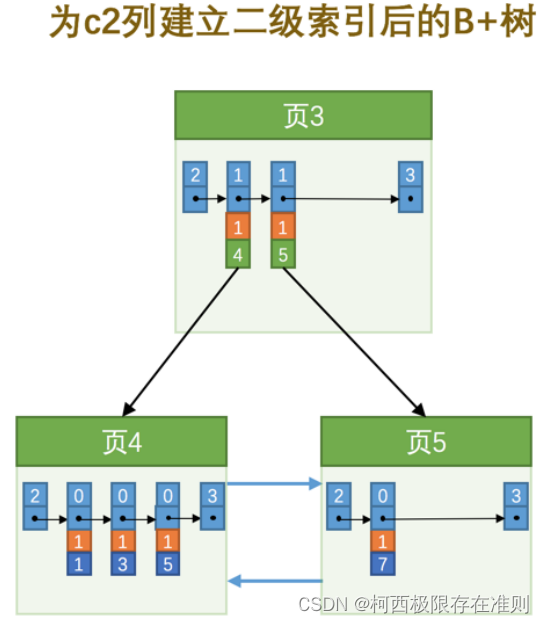
6.2.3 【MySQL】InnoDB的B+树索引的注意事项
6.2.3.1 根页面万年不动窝 B 树的形成过程是这样的: 每当为某个表创建一个 B 树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个 根节点 页面。最开始表中没有数据的时候,每个 B 树…...
)
前端面试话术集锦第 12 篇:高频考点(Vue常考基础知识点)
这是记录前端面试的话术集锦第十二篇博文——高频考点(Vue常考基础知识点),我会不断更新该博文。❗❗❗ 这一章节我们将来学习Vue的一些经常考到的基础知识点。 1. 生命周期钩子函数 在beforeCreate钩子函数调用的时候,是获取不到props或者data中的数据的,因为这些数据的…...

骨传导耳机危害有哪些?值得入手吗?
事实上,只要是正常使用,骨传导耳机并不会对身体造成伤害,并且在众多耳机种类中,骨传导耳机可以说是相对健康的一种耳机,这种耳机最独特的地方便是声波不经过外耳道和鼓膜, 而是直接将人体骨骼结构作为传声介…...

网络爬虫-----初识爬虫
目录 1. 什么是爬虫? 1.1 初识网络爬虫 1.1.1 百度新闻案例说明 1.1.2 网站排名(访问权重pv) 2. 爬虫的领域(为什么学习爬虫 ?) 2.1 数据的来源 2.2 爬虫等于黑客吗? 2.3 大数据和爬虫又有啥关系&…...

vue 功能:点击增加一项,点击减少一项
功能介绍: 默认为一列,当点击右侧"" 号,增加一列;点击 “-” 号,将当前列删除; 功能截图: 功能代码: //HTML <el-col :span"24"><el-form-item lab…...

我的编程学习笔记
1. 引言: 在开始编写任何代码之前,都需要理解编程的基本概念。编程是人与计算机进行交流的方式,它让计算机可以理解和执行特定的任务。编程语言是这种交流的工具,而学习编程就是学习如何用特定的语言表达出我们想要的计算机行为。…...

页面静态化、Freemarker入门
页面静态化介绍 页面的访问量比较大时,就会对数据库造成了很大的访问压力,并且数据库中的数据变化频率并不高。 那需要通过什么方法为数据库减压并提高系统运行性能呢?答案就是页面静态化。页面静态化其实就是将原来的动态网页(例如通过ajax…...

PCL (再探)点云配准精度评价指标——均方根误差
目录 一、算法原理二、代码实现三、代码解析四、备注本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、算法原理 见: 点云配准精度评价指标——均方根误差PCL 点云配准精度评价——点到面的均方根误差Open3D(C++) 点…...

【Redis速通】基础知识1 - 虚拟机配置与踩坑
Ubuntu 配置 Redis 下载 redis 找到 redis 官网界面,下载 redis6.2LTS 点击前往 用 mobax 连接到 ubuntu 虚拟机,把下载好的 tar.gz 文件丢到任意一个文件夹下面 进入该文件夹,于此处打开终端,进行解压操作:tar -z…...
我的创作纪念日---从考研调剂到研一的旅程
文章目录 一、前言二、机缘三、收获四、日常五、憧憬 一、前言 大家好,我是小馒头学Python,小馒头学Python就是我,今天是我第一次收到创作纪念日的私信,去年的今天我还在考研,那个时候整天浑浑噩噩的,迷茫…...

Python-实现邮件发送:flask框架或django框架可以直接使用
在项目中,会使用到发送邮件的功能。不同框架的配置可能有所不同,直接写一个不依赖框架配置的邮件发送模块。 使用的功能: 1、可以发送给多个邮箱 2、可以实现抄送多个邮箱 3、可以添加多个文件附件 一、不使用多线程 import smtplib from…...

使用亚马逊云科技Amazon SageMaker,为营销活动制作广告素材
广告公司可以使用生成式人工智能和文字转图像根基模型,制作创新的广告素材和内容。在本篇文案中,将演示如何使用亚马逊云科技Amazon SageMaker从现有的基本图像生成新图像,这是一项完全托管式服务,用于大规模构建、训练和部署机器…...

conda环境安装opencv带cuda版本
主要是cmake编译选项需要修改 以下两个选项按照自己情况修改 -D OPENCV_EXTRA_MODULES_PATH../opencv_contrib/modules \ -D CUDA_TOOLKIT_ROOT_DIR/usr/local/cuda-12.2 \ 其中/home/lixin/anaconda3/envs/stereo 改成你自己的conda环境 cmake -D CMAKE_BUILD_TYPER…...

R语言中的数据结构----矩阵
目录 (1)创建矩阵 (2) 线性代数运算 (3)矩阵索引 (4)矩阵元素的筛选 (5)增加或删除矩阵的行或列 (6)apply()函数 (…...
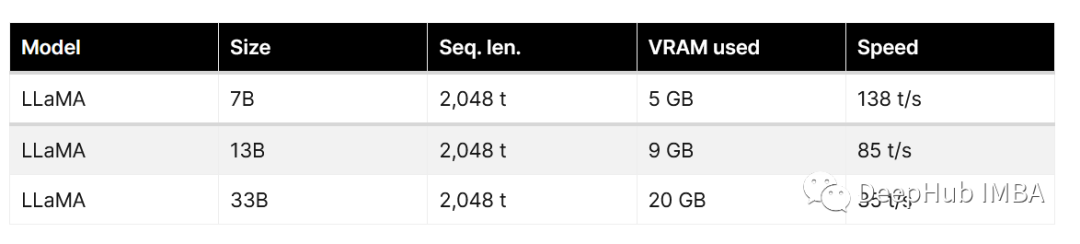
Llama-2 推理和微调的硬件要求总结:RTX 3080 就可以微调最小模型
大语言模型微调是指对已经预训练的大型语言模型(例如Llama-2,Falcon等)进行额外的训练,以使其适应特定任务或领域的需求。微调通常需要大量的计算资源,但是通过量化和Lora等方法,我们也可以在消费级的GPU上…...

终极指南:5分钟快速修复Windows更新问题的完整解决方案
终极指南:5分钟快速修复Windows更新问题的完整解决方案 【免费下载链接】Script-Reset-Windows-Update-Tool This script reset the Windows Update Components. 项目地址: https://gitcode.com/gh_mirrors/sc/Script-Reset-Windows-Update-Tool 当Windows更…...

网络安全AI智能体实战指南:从GPTs到高效安全运营
1. 项目概述与价值定位如果你是一名网络安全从业者、安全研究员,或者正在学习渗透测试、威胁分析,那么你肯定对“效率”和“知识广度”有着近乎偏执的追求。每天,我们都要面对海量的漏洞情报、复杂的攻击手法、不断更新的安全工具以及写不完的…...

告别付费困扰:Linux与Windows双平台免费获取Typora全攻略
1. Typora收费后的免费替代方案 Typora作为一款广受欢迎的Markdown编辑器,突然宣布收费让很多用户措手不及。作为一名长期使用Typora的技术写作者,我完全理解大家的心情。好消息是,我们完全可以在不违反软件许可协议的前提下,继续…...

AI代理如何革新领导力评估:从隐藏档案任务到低成本高效测量
1. 项目概述:当AI成为你的“面试官”,领导力评估正在发生什么?如果你是一位人力资源总监,或者是一位正在为团队选拔继任者而头疼的部门负责人,那么下面这个场景你一定不陌生:为了评估一个候选人的真实领导潜…...

10个无状态服务构建技巧:解锁gh_mirrors/awe/awesome-sre中的水平扩展最佳实践
10个无状态服务构建技巧:解锁gh_mirrors/awe/awesome-sre中的水平扩展最佳实践 【免费下载链接】awesome-sre A curated list of Site Reliability and Production Engineering resources. 项目地址: https://gitcode.com/gh_mirrors/awe/awesome-sre 在现代…...

AI应用治理平台ZLAR:从网关到统一架构的演进与实践
1. 项目概述:从单一工具到统一平台的演进最近在折腾AI应用开发,特别是涉及到多模型调用、安全审计和策略执行这块,发现很多开源项目都是“各自为政”。比如,你需要一个网关来管理AI模型的访问,又需要一个独立的日志系统…...

use Hyperf\View\View;的生命周期的庖丁解牛
它的本质是:Hyperf\View\View 不是一个简单的工具类,而是一个由 Hyperf DI 容器管理的 服务实例 (Service Instance)。它的生命周期始于 容器启动时的元数据注册,经历 请求触发时的懒加载/实例化,执行 模板解析与渲染,…...

为OpenClaw智能体工作流配置Taotoken作为核心模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为核心模型提供商 OpenClaw是一个流行的智能体开发框架,它允许开发者构建和编排…...

DAB的TPS控制闭环到底怎么调?从开环公式到稳定PI调节的实战心得
DAB的TPS控制闭环调试实战:从开环公式到稳定PI调节 调试双有源桥(DAB)变换器的三重移相(TPS)控制闭环,就像在高速公路上同时操控三辆并排行驶的赛车——任何一个小失误都可能导致系统失控。本文将带您深入理…...

对比直接使用官方 API 体验 Taotoken 聚合接入在配置简化上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API 体验 Taotoken 聚合接入在配置简化上的优势 对于需要调用多种大模型能力的开发者而言,直接与各家…...