Python 多线程、线程池、进程池
线程间的通讯机制
消息队列
event 事件对象
当线程创建完成之后,并不会马上执行线程,而是等待某一事件发生,线程才会启动
import threading# # 创建 event 对象
# event = threading.Event()
# # 重置代码中的 event 对象,使得所有该event事件都处于待命状态
# event.clear()
# # 阻塞线程,等待 event 指令
# event.wait()
# # 发送 event 指令,使得所有设置该 event 事件的线程执行
# event.set()class MyThreading(threading.Thread):def __init__(self, event):super().__init__()self.event = eventdef run(self):print('线程{}已经初始化完成,随时准备启动...'.format(self.name))# 阻塞线程,让线程等待指令后再启动self.event.wait()print('{}开始执行...'.format(self.name))if __name__ == '__main__':event = threading.Event()# 创建 10 个自定义线程对象并放入列表threads = [MyThreading(event) for i in range(10)]# 重置代码中的 event 对象,使得所有该event事件都处于待命状态event.clear()# 执行线程# 执行到 run 方法中 self.event.wait() 位置,即打印了:线程{}已经初始化完成...[t.start() for t in threads]# 发送 event 指令,使得所有设置该 event 事件的线程执行# 即启动 threads 列表中的所有线程# 接着执行 run 方法中 self.event.wait() 后面的代码,即打印了:{}开始执行...event.set()[t.join() for t in threads]condition 条件对象
import threading# condition 对象适用于线程轮流执行,或一个线程等待另一个线程的情况,如两个人的对话等# 创建 condition 对象
cond = threading.Condition()class ThreadA(threading.Thread):def __init__(self, cond, name):super().__init__(name=name)self.cond = conddef run(self):# 获取锁self.cond.acquire()# 线程A说了第一句话print(self.getName(), ':一二三四五')# 唤醒其他处于 wait 状态的线程(通知线程B可以说话了)self.cond.notify()# 线程A进入 wait 状态,等待线程B通知(唤醒)self.cond.wait()# 被线程A唤醒后说了第二句话print(self.name, ':山无棱,天地合,乃敢与君绝')self.cond.notify() # 通知线程Bself.cond.wait() # 等待线程B通知# 被线程A唤醒后说了第三句话,最后一句话print(self.name, ':有钱吗?借点')self.cond.notify() # 通知线程Bself.cond.release() # 释放锁class ThreadB(threading.Thread):def __init__(self, cond, name):super().__init__(name=name)self.cond = conddef run(self):# 获取锁self.cond.acquire()self.cond.wait() # 由于它不是第一个说话的人,所以一开始等待通知# 线程B说了第一句话print(self.getName(), ':上山打老虎')# 唤醒其他处于 wait 状态的线程(通知线程A可以说话了)self.cond.notify()# 线程B进入 wait 状态,等待线程A通知(唤醒)self.cond.wait()# 被线程B唤醒后说了第二句话print(self.name, ':海可枯,石可烂,激情永不散')self.cond.notify() # 通知线程Aself.cond.wait() # 等待线程A通知# 被线程B唤醒后说了第三句话,最后一句话print(self.name, ':没有,滚')# self.cond.notify() # 已经是最后一句话,不需要通知线程Aself.cond.release() # 释放锁if __name__ == '__main__':a = ThreadA(cond, 'AAA')b = ThreadB(cond, 'BBB')# 线程A先说话,但是不能先启动线程A# 因为如果启动了线程A,然后线程A说完第一句话后,通知线程B# 但是此时线程B没有启动,就接收不了A的通知,B就会一直处于 wait 状态,即说不了话,也通知不了A# A等不到B的通知,也会一直处于 wait 状态# a.start()# b.start()b.start()a.start()线程间的消息隔离机制
使用场景
在使用多线程的过程中,会有一种变量的使用场景: 一个变量会被所有的线程使用,但是每个线程都会对该变量设置不同的值, threading.local() 提供了这种变量
使用方法
"""
在使用多线程的过程中,会有一种变量的使用场景:一个变量会被所有的线程使用,但是每个线程都会对该变量设置不同的值threading.local() 提供了这种变量假设有一个场景:设置一个 threading.local 变量,然后新建两个线程分别设置这两个 threading.local 的值再分别打印这两个 threading.local 的值看每个线程打印出来的 threading.local 值是否不一样
"""
import threading# local_data 实际上是一个对象
local_data = threading.local()
# 设置 local_data 的名字
local_data.name = 'local_data'class MyThread(threading.Thread):def run(self):print('赋值前-子线程:', threading.currentThread(), local_data.__dict__)# 在子线程中修改 local_data.name 的值local_data.name = self.getName()print('赋值后-子线程:', threading.currentThread(), local_data.__dict__)if __name__ == '__main__':print('开始前-主线程:', local_data.__dict__)t1 = MyThread()t1.start()t1.join()t2 = MyThread()t2.start()t2.join()print('结束后-主线程:', local_data.__dict__)"""
输出结果:
开始前-主线程: {'name': 'local_data'}
赋值前-子线程: <MyThread(Thread-1, started 8480)> {}
赋值后-子线程: <MyThread(Thread-1, started 8480)> {'name': 'Thread-1'}
赋值前-子线程: <MyThread(Thread-2, started 2572)> {}
赋值后-子线程: <MyThread(Thread-2, started 2572)> {'name': 'Thread-2'}
结束后-主线程: {'name': 'local_data'}
"""线程池
线程池中存放多个线程,当有业务需要线程来执行时,可以直接从线程池中获取一个线程来执行该业务, 业务执行完毕之后,线程不会释放,而是被放回线程池中,从而节省了线程的创建以及销毁的时间。 Python concurrent.futures 模块中的 ThreadPoolExecutor 就提供了线程池,该线程池有以下特点:
- 主线程可以获取某一个线程或任务的状态,以及返回值
- 当一个线程完成的时候,主线程能够立即知道
- 让多线程和多进程的编码接口一致
线程池的简单应用
from concurrent.futures import ThreadPoolExecutor
import time# 创建线程池对象,并指定线程池中最大的线程数为 3
# 当业务数不超过 3 的时候,ThreadPoolExecutor 就会创建一个新的线程来执行业务
# 当超过 3 时,ThreadPoolExecutor 不会创建新的线程,而是等待执行其他业务的线程执行完毕后返回
# 再将返回的线程分配给需要的业务
executor = ThreadPoolExecutor(max_workers=3)# 定义一个业务
# 假设这里模拟一个爬虫,爬取一个网页页面
def get_html(timers):time.sleep(timers) # 模拟耗时操作print('获取网页信息{}完毕'.format(timers))return timers# 提交要执行的函数,即要完成的业务到线程池中,然后线程池就会自动分配线程去完成对应的业务
# submit 方法会立即返回,不会阻塞主线程
# get_html 的参数放在后面,即 1 会作为参数传递给 get_html() 中的 timers
# 以下创建了四个任务
task1 = executor.submit(get_html, 1)
task2 = executor.submit(get_html, 2)
task3 = executor.submit(get_html, 3)
task4 = executor.submit(get_html, 4)bool1 = task1.done() # 检查任务是否完成,完成返回 True
bool2 = task2.cancel() # 取消任务执行,只有该任务没有被放入线程池中才能取消成功,成功返回 True# 拿到任务执行的结果,如 get_html 的返回值
# timeout 参数用于设置等待结果的最长等待时间,单位为秒
# result 方法是一个阻塞方法
timers = task3.result(timeout=10)
print(timers)
print(111)线程池中常用的方法
- as_complete
# 线程池的简单应用
from concurrent.futures import ThreadPoolExecutor, as_completed
import time# 创建线程池对象,并指定线程池中最大的线程数为 3
# 当业务数不超过 3 的时候,ThreadPoolExecutor 就会创建一个新的线程来执行业务
# 当超过 3 时,ThreadPoolExecutor 不会创建新的线程,而是等待执行其他业务的线程执行完毕后返回
# 再将返回的线程分配给需要的业务
executor = ThreadPoolExecutor(max_workers=3)# 定义一个业务
# 假设这里模拟一个爬虫,爬取一个网页页面
def get_html(timers):time.sleep(timers) # 模拟耗时操作print('获取网页信息{}完毕'.format(timers))return timers# 模拟要爬取的 url
urls = [1, 2, 3]
# 通过列表推导式构造多线程任务
all_tasks = [executor.submit(get_html, url) for url in urls]
# as_completed 接收一个可迭代对象
# as_completed 是一个生成器,当任务没有完成时,它会阻塞,只有当任务结束返回结果时才会继续往下执行
# as_completed 函数的作用:拿到所有任务执行完毕之后的结果
# 不需要我们手动调用 done 方法不停地判断任务是否完成
for item in as_completed(all_tasks):data = item.result()print('主线程中获取任务的返回值是{}'.format(data))
"""
执行结果:
获取网页信息1完毕
主线程中获取任务的返回值是1
获取网页信息2完毕
主线程中获取任务的返回值是2
获取网页信息3完毕
主线程中获取任务的返回值是3
"""- map
from concurrent.futures import ThreadPoolExecutor
import time# 创建线程池对象,并指定线程池中最大的线程数为 3
# 当业务数不超过 3 的时候,ThreadPoolExecutor 就会创建一个新的线程来执行业务
# 当超过 3 时,ThreadPoolExecutor 不会创建新的线程,而是等待执行其他业务的线程执行完毕后返回
# 再将返回的线程分配给需要的业务
executor = ThreadPoolExecutor(max_workers=3)# 定义一个业务
# 假设这里模拟一个爬虫,爬取一个网页页面
def get_html(timers):time.sleep(timers) # 模拟耗时操作print('获取网页信息{}完毕'.format(timers))return timers# 模拟要爬取的 url
urls = [4, 2, 3]# map 方法和 as_complete 类似
# map 也是一个生成器,当任务没有完成时,它会阻塞,只有当任务结束返回结果时才会继续往下执行
# map 会自动映射 urls 中的每一个元素传递给 get_html 函数,并自动提交 ,不需要通过 submit 方法提交任务
# map 方法直接拿到任务执行的结果
# as_complete 和 map 都可以拿到线程池中各个线程执行的结果,但有以下区别:
# as_complete 会根据任务完成的快慢得到结果,即哪个任务先完成就会先得到该任务的结果
# 而 map 会严格按照任务的顺序得到结果,比如按照 urls 列表中的映射顺序得到对应的结果
# 所以两种适用于不同的场景
for data in executor.map(get_html, urls):print('主线程中获取任务的返回值是{}'.format(data))
"""
获取网页信息2完毕
获取网页信息3完毕
获取网页信息4完毕
主线程中获取任务的返回值是4
主线程中获取任务的返回值是2
主线程中获取任务的返回值是3
"""- wait
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED, FIRST_COMPLETED
import time# 创建线程池对象,并指定线程池中最大的线程数为 3
# 当业务数不超过 3 的时候,ThreadPoolExecutor 就会创建一个新的线程来执行业务
# 当超过 3 时,ThreadPoolExecutor 不会创建新的线程,而是等待执行其他业务的线程执行完毕后返回
# 再将返回的线程分配给需要的业务
executor = ThreadPoolExecutor(max_workers=3)# 定义一个业务
# 假设这里模拟一个爬虫,爬取一个网页页面
def get_html(timers):time.sleep(timers) # 模拟耗时操作print('获取网页信息{}完毕'.format(timers))return timers# 模拟要爬取的 url
urls = [4, 2, 3]all_tasks = [executor.submit(get_html, url) for url in urls]# 让主线程阻塞,直到参数里的条件成立
# 根据 wait 函数的参数,条件成立的情况是:所有任务执行完毕
# ALL_COMPLETED 表示所有任务都执行完成
# 还有其他的参数,如 FIRST_COMPLETED 表示只要有一个任务完成就条件成立
wait(all_tasks, return_when=FIRST_COMPLETED)# 如果想等代码执行完毕之后再打印下列语句,可以使用 wait 语句
print('代码执行完毕')进程池
使用 concurrent.future 模块提供的 ProcessPoolExecutor 来实现进程池,用法和线程池完全一致,参考上述线程池的使用(建议使用该种方式使用进程池)
下面是基于 Pool 类实现的进程池的使用
import multiprocessing
import time# 定义一个业务
# 假设这里模拟一个爬虫,爬取一个网页页面
def get_html(n):time.sleep(n) # 模拟耗时操作print('子进程{}获取内容成功'.format(n))return nif __name__ == '__main__':# 设置进程数,一般设置为和 CPU 数量一致的比较合理# multiprocessing.cpu_count() 获取当前主机的 CPU 核心数pool = multiprocessing.Pool(multiprocessing.cpu_count())# apply_async 是一个异步方法# apply 是一个同步方法# 作用类似于 submit 方法result = pool.apply_async(get_html, args=(2,))pool.close() # 必须在 join 方法前调用,否则会抛出异常# join 方法会等待所有的子进程执行完毕之后,才会继续往下执行主进程的代码# 即 join 会阻塞主进程代码pool.join()# result.get() 拿到子进程执行结果, get 方法是一个阻塞方法print(result.get())print('end...')print()# map 方法的使用pool = multiprocessing.Pool(multiprocessing.cpu_count())# imap 方法会按照列表顺序输出# imap_unordered 方法则不会按照列表顺序执行,而是按照任务执行的快慢输出for result in pool.imap(get_html, [1, 2, 3]):print('{}休眠执行成功'.format(result))
线程同步信号量(semaphore)的使用
同步信号量的作用是用于控制同时工作的线程数量,如读文件时只能同时允许两个线程读,在爬虫时控制同时爬虫的线程,防止触发网站反扒机制
import threading
import time# 还是模拟一个爬虫
# HtmlSpider 类负责根据给定的 URL 去爬取网页内容
class HtmlSpider(threading.Thread):def __init__(self, url, sem):super().__init__()self.url = urlself.sem = semdef run(self):time.sleep(2)print('网页内容获取完成')self.sem.release() # 线程完成任务,释放锁# UrlProducer类负责给 HtmlSpider 类提供网页的 URL
class UrlProducer(threading.Thread):def __init__(self, sem):super().__init__()self.sem = semdef run(self):for i in range(10):self.sem.acquire() # 获取锁,获取成功才能执行线程html_thread = HtmlSpider('url{}'.format(i), self.sem) # 创建HtmlSpider线程html_thread.start() # 启动线程if __name__ == '__main__':# 创建线程同步信号量# 参数 value 指定允许同时工作的线程数sem = threading.Semaphore(value=3)url_producer = UrlProducer(sem)url_producer.start()相关文章:

Python 多线程、线程池、进程池
线程间的通讯机制 消息队列 event 事件对象 当线程创建完成之后,并不会马上执行线程,而是等待某一事件发生,线程才会启动 import threading# # 创建 event 对象 # event threading.Event() # # 重置代码中的 event 对象,使得所…...

深入浅出了解华为端到端交付流程的概念和5个关键点
如果您或您所在的组织在学习和研究华为,那么对“端到端”这个词语就一点都不陌生。 今天华研荟带着您了解华为端到端的交付流程的思想和一些做法,如果了解了这个,那么对于华为在其他领域提出的端到端要求或做法就一通百通了。 一、什么是端…...
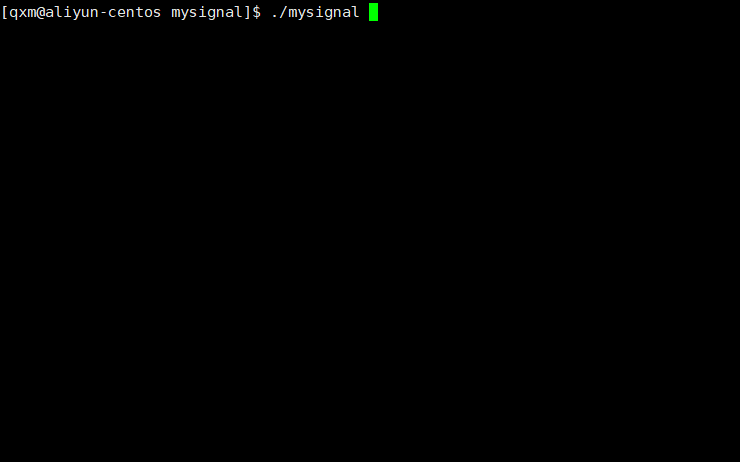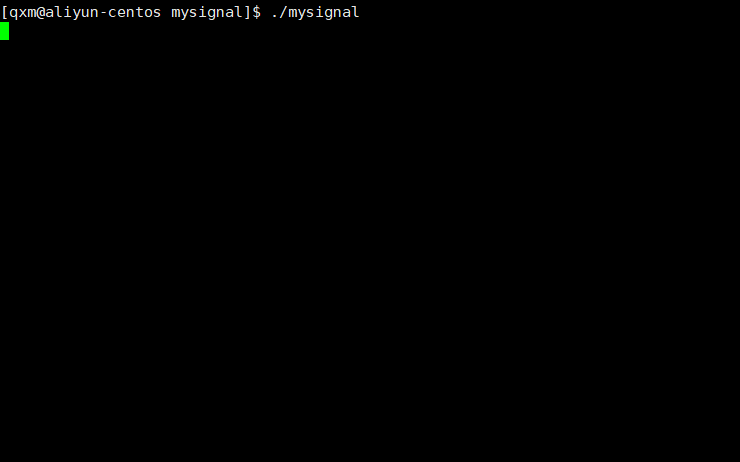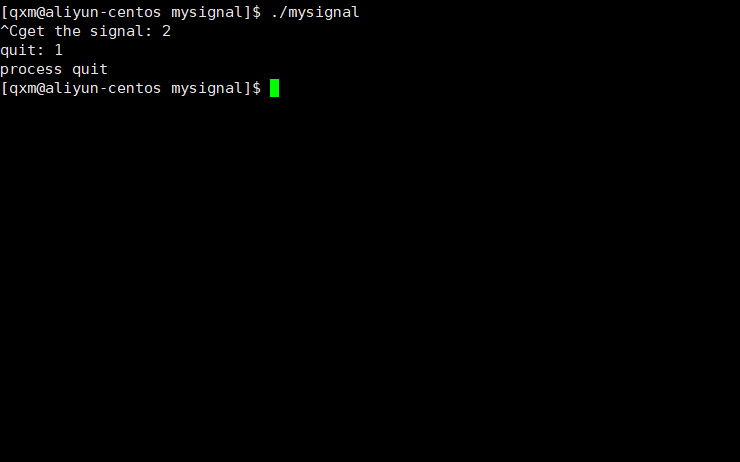
[Linux]进程信号
[Linux]进程信号 文章目录 [Linux]进程信号进程信号的定义信号的特点信号的生命过程发送信号的原理进程处理信号的方式分类使用指令查看Linux系统定义的信号信号产生使用终端按键产生信号使用指令向进程发送信号调用系统调用向进程发送信号由软件条件产生信号硬件异常产生信号 …...
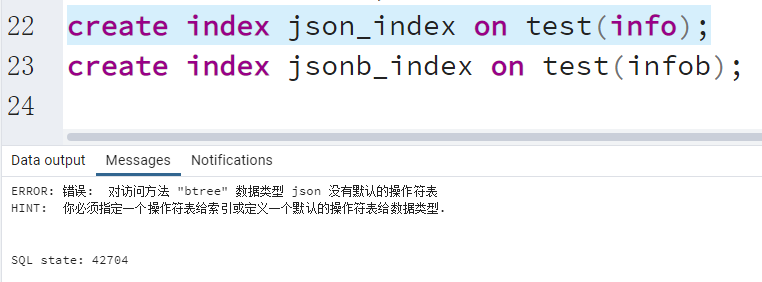
PostgreSQL 数据类型
文章目录 PostgreSQL数据类型说明PostgreSQL数据类型使用单引号和双引号数据类型转换布尔类型数值类型整型浮点型序列数值的常见操作 字符串类型日期类型枚举类型IP类型JSON&JSONB类型复合类型数组类型 PostgreSQL数据类型说明 PGSQL支持的类型特别丰富,大多数…...

智慧港口4G+UWB+GPS/北斗RTK人员定位系统解决方案
港口人员定位系统能够帮助企业实现对港口作业人员的全面监控和管理,不仅可以保障人员的人身安全,还可以提高人员的作业效率,为港口的可持续发展提供有力保障。接下来为大家分享智慧港口人员定位系统解决方案。 方案背景 1、港口作业人员多&a…...
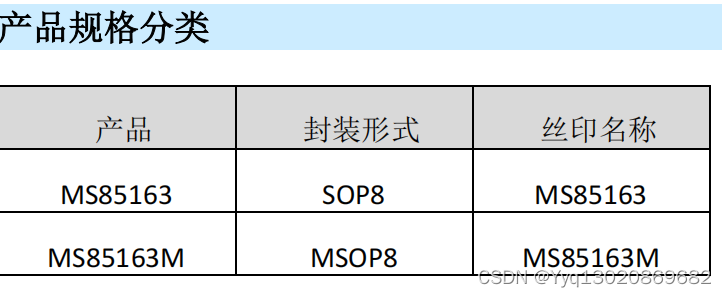
实时时钟和日历电路芯片MS85163/MS85163M
MS85163/MS85163M 是一款 CMOS 实时时钟 (RTC) 和 日历电路,针对低功耗进行了优化,内置了可编程的时钟输出、中断输出和低电压检测器。所有寄存器地址和数据都通过两线双向I 2 C 总线进行串行传输,最大总线传输速度为 400kbit/s 。采用SOP8…...

【Java从入门到精通】这也许就是Java火热的原因吧!
前言:Java是一种高级的、面向对象的、可跨平台的程序设计语言。Java根据技术类别可划分为以下几类:JavaSE(Standard Edition,标准版):支持面向桌面、嵌入式和移动设备的应用程序开发;JavaEE&…...
zTasker—简洁易用强大的定时热键一体自动化工具,效率倍增器
软件名称 zTasker 应用平台 PC Windows7及以上 一句简介 市面上定时类软件很多,但无一例外功能都很单一,要完成不同的任务,需要不同的软件 市面上的热键软件,要么功能少,要么像是AutoHotKey这样对于一般用户太专业…...

惊艳时装界!AIGC风暴来袭,从设计到生产的全新体验
时尚是一个不断演进的领域,充满创新和独创性,但现在,创新迈入了一个崭新的境界——人工智能生成内容(AIGC)。这个革命性的技术,改变了时装设计的游戏规则。在过去的几年里,人工智能已经深刻地改…...
element -ui table表格内容无限滚动 使用插件vue-seamless-scroll
使用插件 一、安装组件依赖 npm install vue-seamless-scroll 二、引入组件 import vueSeamlessScroll from "vue-seamless-scroll"; components: { vueSeamlessScroll }, <div class"table-list "><vue-seamless-scroll :class-option"…...
如何在windows环境下编译T
一, 安装MYSYS2 1. 去https://www.msys2.org下载 msys2-x86_64-xxxxx.exe; 2. 按照msys2.org主页提示的步骤安装; 3.安装完默认起来的是 UCRT的, 可以根据环境的需要选择, 我选择的 MSYS2 MINGW64 4. 搭建编译环境, 安装对应的软…...
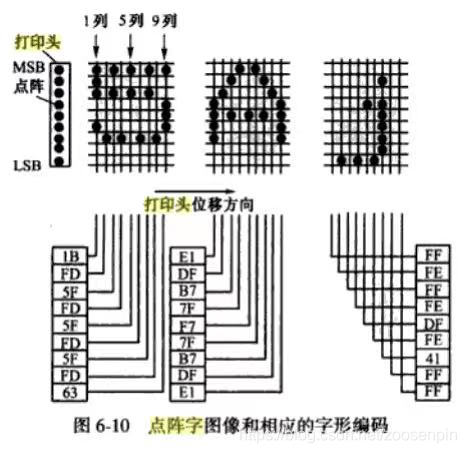
USB接口针式打印机
1 针式打印机原理 - 针式打印机16针是纵向排列,每次打印垂直的16bit,然后右移一bit,继续下列打印;字节的MSB表示最上面的点,字节LSB表示最下面的点 - 由于汉字字模的点阵是横向排列的,而提供给打印头的信息…...

外贸建站教程步骤有哪些?独立站怎么搭建?
推荐的外贸建站教程?制作国际贸易网站的流程? 对于那些希望将产品或服务推向全球市场的企业来说,建立一个专业、具有吸引力的网站是至关重要的。下面115SHOP将介绍外贸建站教程的关键步骤,帮助您更好地了解如何在国际市场上建立您…...
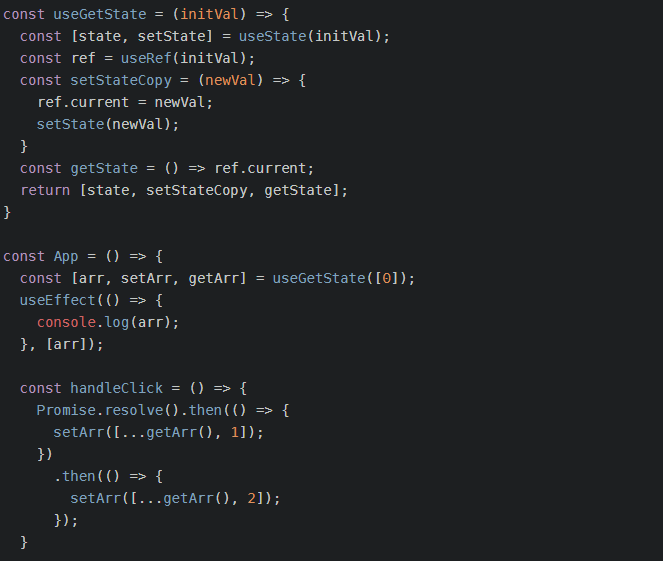
useGetState自定义hooks解决useState 异步回调获取不到最新值
setState 的两种传参方式 1、直接传入新值 setState(options); const [state, setState] useState(0); setState(state 1); 2、传入回调函数 setState(callBack); const [state, setState] useState(0); setState((prevState) > prevState 1); // prevState 是改变之…...
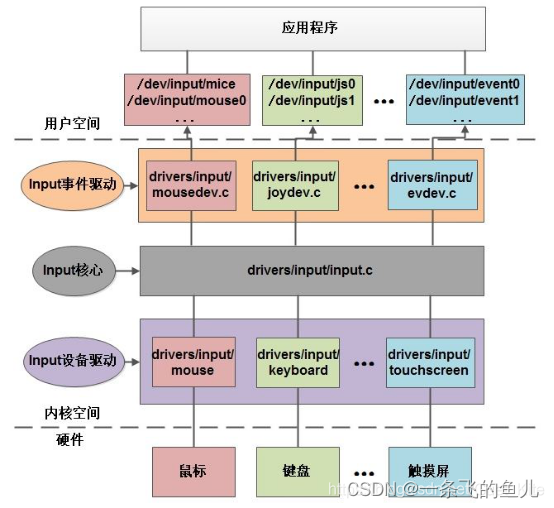
input子系统框架、外设驱动开发
一、input子系统基本框架 Linux内核为了两个目的: 简化纯输入类外设(如:键盘、鼠标、游戏杆、轨迹球、触摸屏。。。等等)的驱动开发统一输入类外设产生的数据格式(struct input_event),更加方…...

Google Chrome 浏览器以全屏模式打开
目录 前言以全屏模式打开禁止弹出无法更新的提示窗禁止翻译网页Chrome设置禁止翻译网页可能1可能2可能3 网页添加指令禁止Chrome翻译网页 禁用脚本气泡浏览器解决办法html解决办法方法1:鼠标滑过超链接时,使状态栏不出现超链接方法2:方法3&am…...
安装torch113、cuda116并运行demo【Transformer】
文章目录 01. 导读02. 显卡驱动版本03. 创建环境、下载安装必要包04. 运行参考代码: 01. 导读 安装torch113、cuda116并运行demo【Transformer】 02. 显卡驱动版本 C:\Users\Administrator>nvidia-smi -l 10 Wed Sep 13 23:35:08 2023 ----------------------…...

基于scRNA-seq的GRN分析三阴性乳腺癌的肿瘤异质性
三阴性乳腺癌即TNBC是一种肿瘤异质性高的乳腺癌亚型。最近的研究表明,TNBC患者可能包含具有不同分子亚型的细胞。此外,基于scRNA-seq数据构建的GRN已经证明了对关键调控因子研究的重要性。作者使用scRNA-seq对TNBC患者的GRN进行了全面分析。从scRNA-seq数…...

Python:二进制文件实现等间隔取相同数据量并合并
举例:每3byte为一页,每3页为一wl。将所有wl的第一页/第二页/第三页分别合并为一个文件。 data b\x01\x02\x03\x04\x05\x06\x07\x08\x09\x01\x02\x03\x04\x05\x06\x07\x08\x09\x01\x02\x03\x04\x05\x06\x07\x08\x09\x01\x02\x03\x04\x05\x06\x07\x08\x0…...

python使用openvc库进行图像数据增强
以下是使用Python和OpenCV库实现图像数据增强的简单示例代码,其中包括常用的数据增强操作: import cv2 import numpy as np import os# 水平翻转 def horizontal_flip(image):return cv2.flip(image, 1)# 垂直翻转 def vertical_flip(image):return cv2…...
)
用STM32的TIM1和GPIO中断,手把手教你实现带霍尔BLDC的平稳启动与调速(附PID代码)
STM32实战:基于霍尔传感器的BLDC电机六步换相与PID调速全解析 在工业自动化、无人机和机器人等领域,无刷直流电机(BLDC)凭借其高效率、长寿命和低噪音特性成为首选驱动方案。本文将深入探讨如何利用STM32的TIM1高级定时器和GPIO中断实现带霍尔传感器的BL…...

VS Code图表神器:零配置用代码画UML、流程图与架构图
1. 项目概述:在VS Code里优雅地“画”图作为一名长期在技术文档、架构设计和日常笔记中与图表打交道的老兵,我深知一个痛点:从想法到一张清晰可用的图表,中间往往隔着“安装Java环境”、“配置GraphViz路径”、“折腾渲染引擎”等…...
)
Hack The Box注册失败?别慌,可能是你的‘上网姿势’不对(附最新可用方案)
Hack The Box注册问题排查与解决方案全指南 注册Hack The Box时遇到各种报错提示是许多技术爱好者共同的困扰。作为全球知名的网络安全实战平台,其注册流程确实存在一些技术门槛需要跨越。本文将系统性地分析注册失败的深层原因,并提供多种经过验证的解决…...

AI时代来临,键盘布局将迎来怎样的变革?
1. AI时代的硬件探索智能手机统治了过去十几年的数字生态,它是注意力的黑洞,是人们最私密的随身之物。但手机从设计之初就是为「人盯着它」而生的,其全部逻辑止于屏幕。而AI的需求却恰恰相反,它需要持续感知物理世界,见…...

Qt 委托模式实战:QItemDelegate 赋能 QTableView 单元格交互控件
1. 为什么需要委托模式 在Qt开发中,表格视图(QTableView)是最常用的数据展示控件之一。但很多开发者都遇到过这样的困扰:当我们需要在表格单元格中嵌入交互控件时,直接调用setIndexWidget方法会导致控件始终显示,不仅影响界面美观…...

从荧光灯到充电器:剖析MJE13001高压小功率三极管的实战选型与参数验证
1. MJE13001三极管的前世今生 第一次见到MJE13001这颗三极管是在修理一台老式荧光灯电子镇流器时。当时电路板上那颗黑乎乎的小元件已经烧得发黄,但依稀能看到"13001"的标识。拆下来用万用表测量发现CE结已经击穿,换上新的MJE13001后…...

联想刃7000k BIOS解锁终极指南:安全释放隐藏性能的3种方法
联想刃7000k BIOS解锁终极指南:安全释放隐藏性能的3种方法 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 对于联想刃7…...

从CelebA数据集到落地应用:一份给新手的MTCNN训练数据制作与模型训练全指南
从CelebA数据集到落地应用:MTCNN训练数据制作与模型训练全指南 人脸检测作为计算机视觉的基础任务,其精度直接影响后续的人脸识别、表情分析等应用效果。MTCNN(Multi-task Cascaded Convolutional Networks)作为经典的多任务级联人…...

技术Leader的困境:为什么你越努力,团队越依赖你?
在软件测试领域,我们比任何角色都更懂“依赖”这个词。测试环境依赖稳定、测试数据依赖真实、测试用例依赖需求文档。但有一种依赖,最致命却也最容易被忽视——团队对你的依赖。很多从一线测试骨干晋升为测试Leader的人,都会陷入一个怪圈&…...

从微波炉到激光加工:手把手教你用COMSOL搞定4种电磁加热的仿真设置
从微波炉到激光加工:COMSOL电磁加热仿真实战指南 电磁加热技术早已渗透进现代工业与生活的每个角落——从家用微波炉的磁控管震荡,到新能源汽车电池的感应焊接,再到精密医疗器械的激光切割。这些看似迥异的应用背后,都遵循着相同…...