kafka学习
概念:
- broker: 1台服务器的kafka进程,它是kafka的工作者。类似Hbase的regionServer,hdfs的Datanode
- topic: 订阅发布模式的kafka中有消息主题
- producer:生产者
- customer:消费者
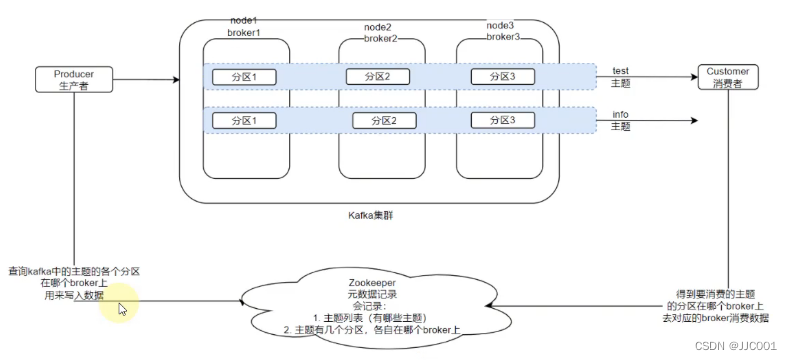
基础架构:
- 元数据:kafka的部分元数据保存在ZK中
- 数据写入:生产者将它产生的数据按照顺序挨个写入对应主题的各个分区
- 数据读取:消费者会监听它感兴趣的主题的全部分区,从这些分区中取出最新消息
消费的顺序:
kafka一个分区内的消息是按顺序消费的
kafka多个分区之间的消息,消费顺序是无法保证的(因为网络波动)
Kafka Shell
- 查看kafka中有哪些Topic
kafka-topics.sh --list --zookeeper zk地址
Zk地址可以一台可以多台
- 创建topic
kafka-topics.sh --create --zookeeper zk地址 --topic topic名 --partitions num --replication-factor num
--replication-factor 表示副本数。 一个副本最快,2个副本安全好一点,性能下降一点,3个副本安全性最好
--partitions 分区。 分区数量建议是Broker数量的n倍 
- 查看topic详情
kafka-topics.sh --describe --zookeeper zk --topic topicname
- 删除topic
kafka-topics.sh --delete --zookeeper zk --topic topicname
kafka默认只是标记删除,物理实体没有被删除,如果想要物理清除,那么需要在config/server.properties配置:delete.topic.enable=true。
- 修改topic
只能增加分区数,无法修改副本数
kafka-topics.sh --alter --zookeeper zk --topic topicname --partitions num
- 开启一个模拟的生产者
我们可以使用kafka内置的脚本,来模拟生产者发送消息(用于测试)
前提:需要在防火墙开放9092端口
kafka-console-producer.sh --broker-list broker列表 --topic topicname
--broker-list: 如hadoop101:9092,hadoop102:9092,hadoop103:9092
如:kafka-console-producer.sh --broker-list hadoop101:9092,hadoop102:9092,hadoop103:9092 --topic bj61
- 开启一个模拟的消费者
kafka-console-consumer.sh --bootstrap-server broker列表 --topic topicname --from-beginning
--bootstrap-server: 如hadoop101:9092,hadoop102:9092,hadoop103:9092
--from-beginning: 可选配置,表示启动从头开始消费。不选,表示接着上一次消费的地方继续消费
如:kafka-console-consumer.sh --bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 --topic bj61 --from-beginningKafka基准测试
测试集群的吞吐量
- 生产者测试:
kafka-producer-perf-test.sh --topic topicname --num-records num --throughput -1 --record-size num --producer-props
--num-records: 测试写入多少条数据
--throughput:指定吞吐量的限流,-1表示不限制
--record-size:每条数据的大小,单位是字节
--producer-props:生产者的属性,可以在这里指定集群的地址和ACK的机制,如:bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092 acks=1
测试1万条数据,每条数据1000Byte大小
kafka-producer-perf-test.sh --topic bj60 --num-records 10000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092 acks=1
- 消费者测试:
kafka-consumer-perf-test.sh --topic topicname --broker-list brokerlist --fetch-size num --messages num
--fetch-size:一次抓取多少
--messages num:总共测试多少条数据
一般情况下,消费者速率比生产快很多。
Python API
- 安装库
pip install kafka-python -i https://pypi.tuna.tsinghua.edu.cn/simple- 生产者
from kafka import KafkaProducer
p = KafkaProducer(bootstrap_servers=['192.168.100.101:9092'])
p.send("bj61", b'nihao')
p.flush()这边有个问题:本地机器必须配置hosts文件,要不然发送失败,不知为何!
- 消费者
from kafka import KafkaConsumer
c = KafkaConsumer("bj61",
group_id="group_id",
bootstrap_servers=['hadoop101:9092'],
auto_offset_reset='earliest',
enable_auto_commit=True)
for msg in c:# 这个for循环不会停topic=msg.topicpartition=msg.partitionoffset=msg.offsetkey=msg.keyvalue=msg.value.decode("UTF-8") #value是byte,需要解码print("topic是:%s,分区是:%s,offset:%s,key:%s,value:%s" % (topic,partition,offset,key,value))
Kafka的数据存储和消费者重复消费的问题
Kafka的数据是不会主动删除的,数据会默认保存7天。可以在server.properties中log.retention.hours=168配置
如果数据不删除,作为消费者来说,肯定不想消费到重复的数据,如:发短信。
这就靠消费者offset记录机制。
enable_auto_commit=True:
表示每隔一段时间就提交一次,记录一下消费到的offset,默认5秒钟一次。如果是False,则需要自己写代码提交。c.commit()
auto_offset_reset='earliest':
假设系统宕机重新启动,表示启动的时候接着上次消费的地方继续消费。如果不设置默认是latest表示之前的数据都不管,只接受启动后收到的数据。
这边需要指定消费者组,要不然会从头开始消费,如果不指定,有可能是程序启动的时候消费者组变了,所以从头开始消费了。
如何确保不重复消费数据
消费者会将当前消费的offset记录下来。有两种方式:
(1)存到内置主题:_consumer_offsets:给消费者去记录自己消费到哪里了。宕机后可以接着上次offset继续消费。
记录机制:(1)每消费一条数据记录一次,性能差 (2)每隔一段时间记录一次,默认5秒钟,适用于对重复消费不敏感的业务。如:业务做了幂等性操作的。
(2)自己管理,自己记录offset,比如记录到mysql,启动的时候,自行提供本次启动从哪个offset开始
Kafka高级----分区和副本
kafka-topics.sh --create --zookeeper zk地址 --topic topic名 --partitions num --replication-factor num
--replication-factor 表示副本数。 一个副本最快,2个副本安全好一点,性能下降一点,3个副本安全性最好
--partitions 分区。 分区数量建议是Broker数量的n倍如上shell,在创建主题的时候,我们可以通过:
--replication-factor 来设置一个主题的分区有多少副本
分区和副本的架构

如图:
- 在Kafka中,一个主题,可以有多个分区
- 每一个分区都会有副本,如上图,一个分区有3个副本
Kafka为了安全性,只要broker的数量足够,就会确保副本之间不在同一台机器上。
Broker的数量和副本数量是有关系的。如果有1个broker,就无法设置超过1个副本。因为副本都在同一台机器上,丢了就全部都丢了,没有意义。
- 副本之间会做选举,内部推选出一个leader,剩下的作为follow
数据写入
在多分区,多副本的场景下,数据写入:
- 在分区的选择上,跟随客户端的意愿(代码中可以指定具体写入哪个分区),kafka-python库策略是随机分发。
- 选择好分区后,写入哪个副本?这是固定的,只会写入Leader
- 写入Leader后,Leader和Follow之间同步数据
客户端ACK 如何确保生产者数据不丢失
1. 客户端只能写入Leader
2. Kafka自己会确保Leader和Follow之间的数据同步
那么客户端在写入数据到Leader之后,有3中选择:
- 当写入Leader成功,客户端认为成功(ACK=1),安全性较好。如果Leader磁盘坏了,有可能丢失数据。大多数场景推荐,能接受1%数据丢失的风险。
- 当写入Leader成功,并和Follow同步成功,客户端才认为数据写入成功(ACK=-1)。安全性极佳
- 压根不管是否写入成功,随缘(ACK=0),几乎没有安全性,性能最好,生产环境中,不推荐使用
小总结
- 客户端通过ACK来确保数据写入的过程安全
- 一旦数据进入kafka,kafka本身通过多副本,确保数据在Kafka内的存储安全
- 消费者没有丢失数据的风险,只要数据还在kafka,就能N次消费,只要保证记录的offset别乱就行了
消费者的数据均衡
消费者组
我们的程序在启动的时候,可以告知自己是哪一个消费者组
这是主动的行为(你自己设置)
结论
从分区的视角看:
kafka的一个分区只能给同一个消费者组的一个消费者提供数据。
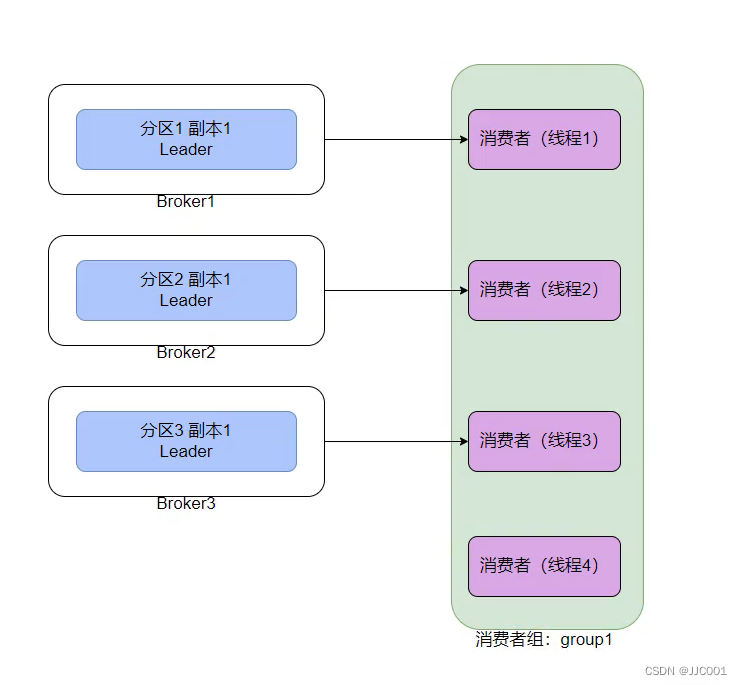
如图,假设有一个python程序,将自己标记为:group1组,开启了4个线程,那么线程4就没有数据
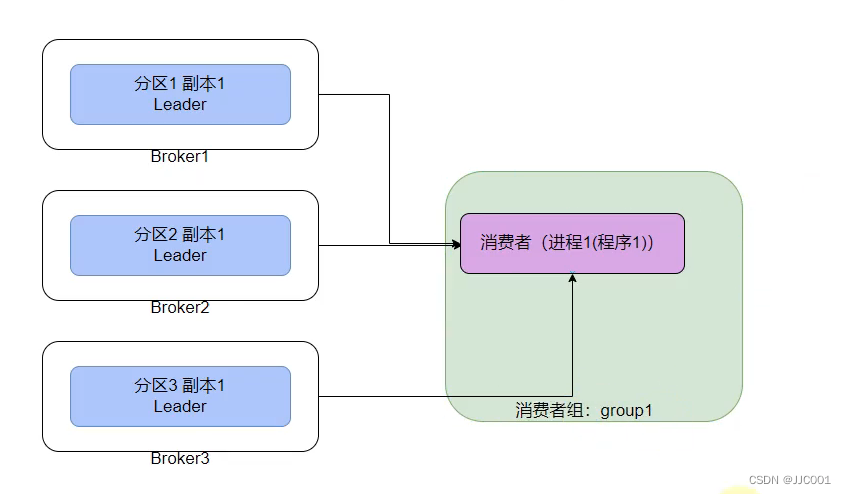
如图,在只有1个消费者的情况下,可以消费多个分区。从分区的角度看,它是1对1的。
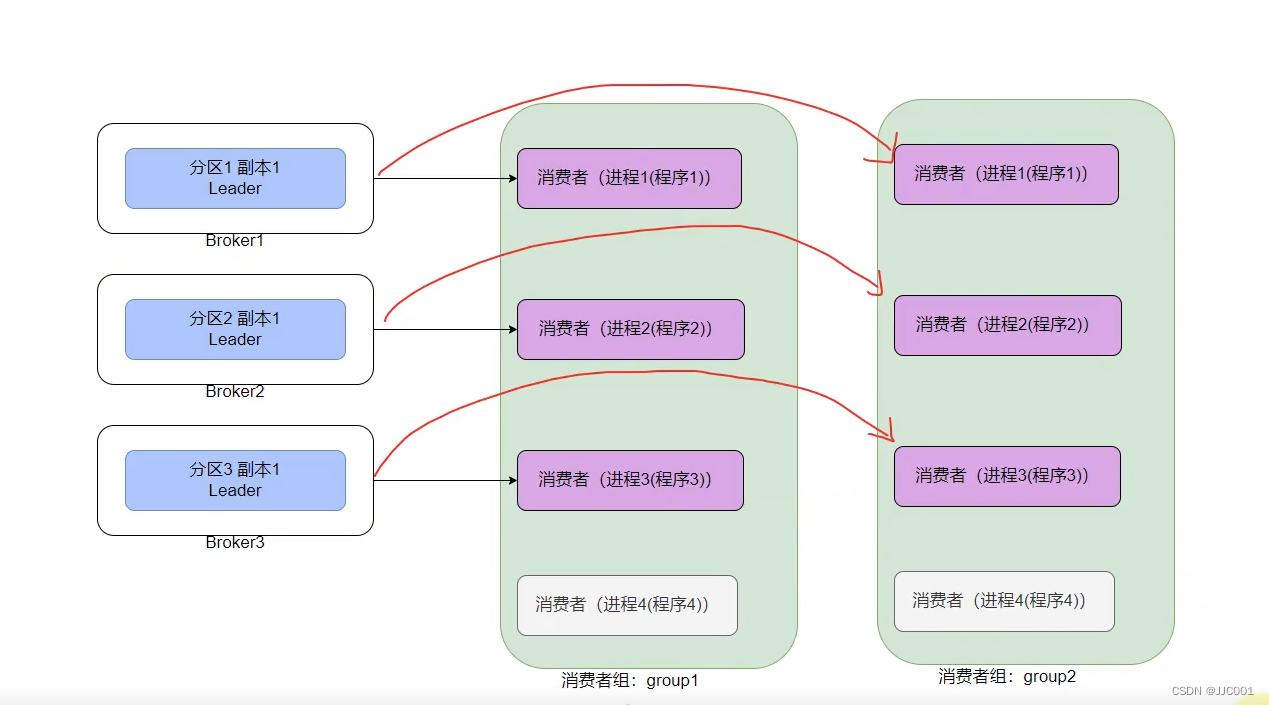
如图:如果消费者组是多个,那么一个分区可以给多个组的消费者提供数据,但依旧要满足只给同一个组的一个消费者提供数据
注意:
在企业内,消费kafka的时候,一定要注意,不要和别人使用的组是同名的。
查看消费者组列表
kafka-consumer-groups.sh --bootstrap-server hadoop101:9092 --list 
查看消费者组详情
./kafka-consumer-groups.sh --bootstrap-server hadoop101:9092 --group group_id --describe
图中LAG,表示在这个组内有数据堆压
计算方法是:当前分区最新的offset - 当前分区已提交的消费的offset
相关文章:
kafka学习
概念: broker: 1台服务器的kafka进程,它是kafka的工作者。类似Hbase的regionServer,hdfs的Datanodetopic: 订阅发布模式的kafka中有消息主题producer:生产者customer:消费者 基础架构: 元数据:…...
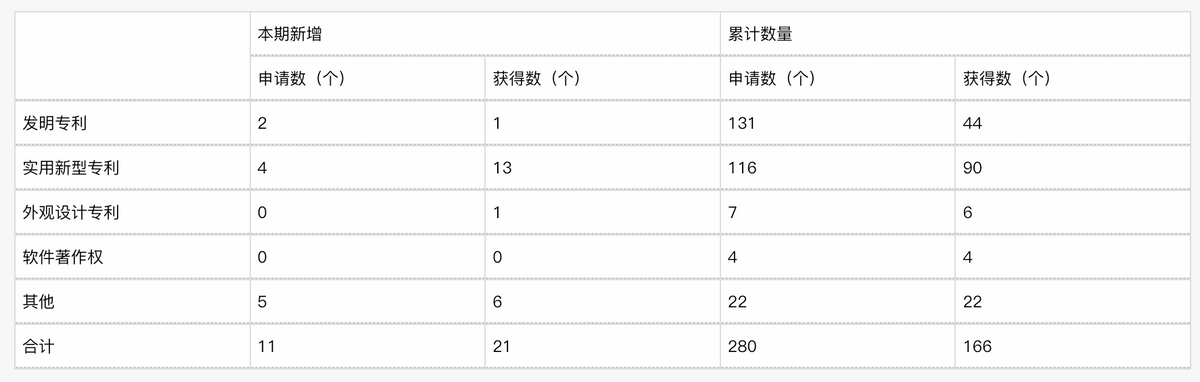
坐拥两条黄金赛道,爱博医疗未来必是星辰大海!
尽管2022年疫情反复,但爱博医疗仍交出了亮眼的“答卷”。图源:爱博医疗2023年2月14日晚间,爱博医疗披露了2022年度业绩快报,营收5.79亿元,同比增长33.81%;归母净利润2.32亿元,同比增长35.27%&am…...
DEV C++的使用入门程序做算术运算
DEV C Dev-C (有时候也称为 Dev-Cpp)是一个免费软件,最早是由 BloodShed 公司开发的,在版本 4.9.2 之后该公司停止开发并开放源代码。然后由 Orwell 接手进行维护,陆续开发了几个版本,后来也有其他开发人员…...
)
华为OD机试真题Python实现【商人买卖】真题+解题思路+代码(20222023)
商人买卖 题目 商人经营一家店铺,有number种商品, 由于仓库限制每件商品的最大持有数量是item[index] 每种商品的价格是item-price[item_index][day] 通过对商品的买进和卖出获取利润 请给出商人在days天内能获取的最大的利润 注:同一件商品可以反复买进和卖出 🔥🔥�…...
随想录二刷(数组二分法)leetcode 704 35 34 69 367
第一题 leetcode 704.二分查找 二分法的思路 二分法的思路很简单 数组必须有序先查找中间元素进行比较得出大小再考虑向左比较还是向右比较 代码实现 class Solution { public:int search(vector<int>& nums, int target) {int left 0;int right nums.size() -…...

【微信小程序】--WXML WXSS JS 逻辑交互介绍(四)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &#…...
c/c++开发,无可避免的模板编程实践(篇八)
一、借用标准库模板构造自己的模板 通常,模板设计是遵循当对象的类型不影响类中函数的行为时就使用模板。这也就是为何标准库提供大部分的模板都是与容器、迭代器、适配器、通用算法等有关,因为这些主要是除了对象集合行为,如读写、增删、遍历…...

Leetcode13. 罗马数字转整数
一、题目描述: 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。 字符数字I1V5X10L50C100D500M1000 例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII &…...

元宇宙对营销方式的影响
营销方式的变化通常伴随着技术的发展。我们已经看到营销方式从印刷媒体、电视、广播到互联网的转变。而现在,我们又处在下一个营销方式大跃进的风口浪尖上。关于元宇宙及其潜在的变革性影响,人们已经讨论了很多。虽然与元宇宙相关的大多数东西在很大程度…...

PERCCLI命令行程序说明
Dell EMC PowerEdge RAID控制器(PERC)命令行界面(CLI)实用程序用于管理RAID卡相关的配置和信息,命令的子命令和选项如下所示: help - lists all the commands with their usage. E.g. perccli help <command> help - gives details about a parti…...
系统架构——分布式架构负载均衡系统设计实战
摘要 关于“负载均衡”的解释,百度词条里:负载均衡,英文叫Load Balance,意思就是将请求或者数据分摊到多个操作单元上进行执行,共同完成工作任务。负载均衡(Load Balance)建立在现有网络结构之…...
机器学习算法: AdaBoost 详解
1. 集成学习概述 1.1. 定义 集成学习(Ensemble learning)就是将若干个弱分类器通过一定的策略组合之后产生一个强分类器。 弱分类器(Weak Classifier)指的就是那些分类准确率只比随机猜测略好一点的分类器,而强分类器&…...

6.824lab1总结
目录总体概要核心结构体coordinator思路:任务池管理RPC函数worker思路:实现细节总体概要 程序主要由mrcoordinator.go、mrworker.go为启动模块。 mrcoordinator.go: 启动rpc服务,循环等待m.Done()为true时退出。mrwoker.go:调用mr.worker(mapf, reduce…...

NIO蔚来 面试——IP地址你了解多少?
目录 前言 1、IP地址 1.1、什么是IP地址 1.2、IP地址的格式 1.2.1、32位二进制数表示IP地址,够用吗? 1.3、IP地址的组成 1.4、为什么会出现IPv6 1.4.1、为什么IPv6还没有大量普及呢? 1.5、子网掩码 1.6、特殊的IP地址 2、路由选择 …...

Gluten 首次开源技术沙龙成功举办,更多新能力值得期待
2023年2月17日,由 Kyligence 主办的 Gluten 首次开源技术沙龙在上海成功举办,本期沙龙特邀来自 Intel、BIGO、eBay、阿里、华为和 Kyligence 等行业技术专家齐聚一堂,共同探讨了向量化执行引擎框架 Gluten 现阶段社区的重点开发成果和未来的发…...

springboot+redis+lua实现限流
Redis 除了做缓存,还能干很多很多事情:分布式锁、限流、处理请求接口幂等性。。。太多太多了~今天想和小伙伴们聊聊用 Redis 处理接口限流。1. 准备工作首先我们创建一个 Spring Boot 工程,引入 Web 和 Redis 依赖,同时…...

线段树总结
文章目录参考文档题目线段树实现单点修改,区间求值模板题目308. 二维区域和检索 - 可变区间修改,区间求值1. 掉落的方块(区间开点)2. 维护序列3. 一个简单的问题24. 天际线问题动态开点1. 区间和个数(单点修改开点)问题以及注意事…...
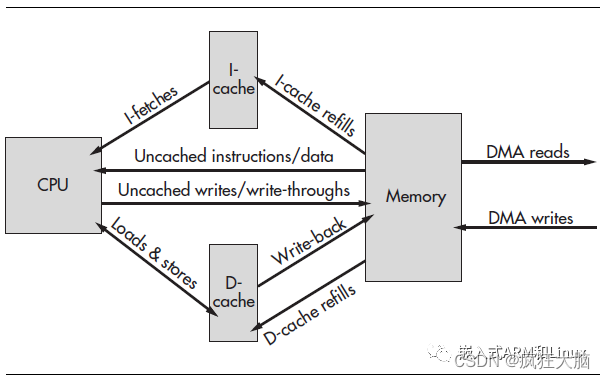
龙芯GS232(MIPS 32)架构cache管理笔记
1 mips32架构 MIPS架构是一种基于精简指令集(Reduced Instruction Set Computer,RISC)的计算机处理器架构。MIPS架构由MIPS Technologies公司在1981年开发,并在1984年发布了第一款MIPS处理器。 MIPS架构的特点包括: …...

js去重
<script>let arr [{ id: 0, name: "张三" },{ id: 1, name: "李四" },{ id: 2, name: "王五" },{ id: 3, name: "赵六" },{ id: 1, name: "孙七" },{ id: 2, name: "周八" },{ id: 2, name: "吴九&qu…...
小白都能看懂的C语言入门教程
文章目录C语言入门教程1. 第一个C语言程序HelloWorld2. C语言的数据类型3. 常量变量的使用4. 自定义标识符#define5. 枚举的使用6. 字符串和转义字符7. 判断和循环8. 函数9. 数组的使用10. 操作符的使用11. 结构体12. 指针的简单使用C语言入门教程 1. 第一个C语言程序HelloWor…...

ComfyUI-VideoHelperSuite视频工作流完整指南:从图像序列到专业视频的5个关键步骤
ComfyUI-VideoHelperSuite视频工作流完整指南:从图像序列到专业视频的5个关键步骤 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite ComfyUI-VideoHelpe…...

AI代理实战能力评估:MLE-Bench基准测试深度解析与工程启示
1. 项目概述与核心价值最近在跟进AI代理(AI Agent)领域的发展,特别是它们在自动化复杂工作流方面的潜力。作为一个在机器学习工程一线摸爬滚打了十来年的从业者,我深知从数据清洗、特征工程、模型调优到实验管理的全流程ÿ…...

张量网络机器学习:从平均风险下界看量子模型泛化极限
1. 项目概述:当张量网络遇见机器学习如果你和我一样,既对量子多体物理中的张量网络着迷,又对机器学习模型的泛化能力充满好奇,那么“张量网络机器学习模型平均风险的理论分析”这个课题,无疑是一个能将两者完美结合的宝…...

在ubuntu开发机上体验taotoken分钟级接入多种大模型的过程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Ubuntu 开发机上体验 Taotoken 分钟级接入多种大模型的过程 1. 准备工作与环境确认 在开始之前,我使用的是一台运行…...

QQ空间数据备份:3步完成永久保存青春记忆的终极指南
QQ空间数据备份:3步完成永久保存青春记忆的终极指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾担心QQ空间里那些珍贵的青春记忆会随着时间流逝而消失ÿ…...

孟加拉语作者画像基准测试:朴素贝叶斯与SVM在低资源语言NLP中的表现分析
1. 项目概述:当机器学习遇见孟加拉语社交媒体在社交媒体无处不在的今天,我们每天都会产生海量的文本数据。你有没有想过,仅仅通过一个人写的几段文字,就能大致猜出他的性别和年龄?这听起来有点像数字时代的“读心术”&…...

Fastboot Enhance:革新Android设备管理的智能图形化解决方案
Fastboot Enhance:革新Android设备管理的智能图形化解决方案 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance 你是否曾为Android设备的…...

告别环境配置焦虑:用 Bochs 2.6.10 在 Ubuntu 上快速搭建你的第一个‘自制操作系统’实验台
从零构建操作系统实验环境:Bochs 2.6.10在Ubuntu下的实战指南当我在大学第一次尝试编写引导扇区代码时,花了整整三天时间才让屏幕上显示出"Hello World"。这段经历让我深刻意识到:环境配置的复杂度往往比算法本身更令人崩溃。本文将…...

5分钟掌握qmcdump:解锁QQ音乐加密音频的终极指南
5分钟掌握qmcdump:解锁QQ音乐加密音频的终极指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否曾经…...

微信直连 OpenClaw,手机发指令操控电脑,效率炸裂
下载地址:OpenClaw Windows 一键部署包 https://xiake.yun/api/download/package/16?promoCodeIV9D9D5198DC OpenClaw 绑定微信教程 1:软件下载完成界面 2:选择右上角设置 3:选择聊天配置 4:选择右边展开ÿ…...