Python用若干列的数据多条件筛选、去除Excel数据并批量绘制直方图
本文介绍基于Python,读取Excel数据,以一列数据的值为标准,对这一列数据处于指定范围的所有行,再用其他几列数据数值,加以筛选与剔除;同时,对筛选与剔除前、后的数据分别绘制若干直方图,并将结果数据导出保存为一个新的Excel表格文件的方法。
首先,我们来明确一下本文的具体需求。现有一个Excel表格文件,在本文中我们就以.csv格式的文件为例;其中,如下图所示,这一文件中有一列(在本文中也就是days这一列)数据,我们将其作为基准数据,希望首先取出days数值处于0至45、320至365范围内的所有样本(一行就是一个样本),进行后续的操作。

其次,对于取出的样本,再依据其他4列(在本文中也就是blue_dif、green_dif、red_dif与inf_dif这4列)数据,将这4列数据不在指定数值区域内的行删除。在这一过程中,我们还希望绘制在数据删除前、后,这4列(也就是blue_dif、green_dif、red_dif与inf_dif这4列)数据各自的直方图,一共是8张图。最后,我们还希望将删除上述数据后的数据保存为一个新的Excel表格文件。
知道了需求,我们就可以撰写代码。本文所用的代码如下所示。
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 12 07:55:40 2023@author: fkxxgis
"""import numpy as np
import pandas as pd
import matplotlib.pyplot as pltoriginal_file_path = "E:/01_Reflectivity/99_Model/02_Extract_Data/26_Train_Model_New/Train_Model_0715_Main_Over_NIR.csv"
# original_file_path = "E:/01_Reflectivity/99_Model/02_Extract_Data/26_Train_Model_New/TEST.csv"
result_file_path = "E:/01_Reflectivity/99_Model/02_Extract_Data/26_Train_Model_New/Train_Model_0715_Main_Over_NIR_New.csv"df = pd.read_csv(original_file_path)blue_original = df[(df['blue_dif'] >= -0.08) & (df['blue_dif'] <= 0.08)]['blue_dif']
green_original = df[(df['green_dif'] >= -0.08) & (df['green_dif'] <= 0.08)]['green_dif']
red_original = df[(df['red_dif'] >= -0.08) & (df['red_dif'] <= 0.08)]['red_dif']
inf_original = df[(df['inf_dif'] >= -0.1) & (df['inf_dif'] <= 0.1)]['inf_dif']mask = ((df['days'] >= 0) & (df['days'] <= 45)) | ((df['days'] >= 320) & (df['days'] <= 365))
range_min = -0.03
range_max = 0.03df.loc[mask, 'blue_dif'] = df.loc[mask, 'blue_dif'].apply(lambda x: x if range_min <= x <= range_max else np.random.choice([np.nan, x]))
df.loc[mask, 'green_dif'] = df.loc[mask, 'green_dif'].apply(lambda x: x if range_min <= x <= range_max else np.random.choice([np.nan, x]))
df.loc[mask, 'red_dif'] = df.loc[mask, 'red_dif'].apply(lambda x: x if range_min <= x <= range_max else np.random.choice([np.nan, x]))
df.loc[mask, 'inf_dif'] = df.loc[mask, 'inf_dif'].apply(lambda x: x if range_min <= x <= range_max else np.random.choice([np.nan, x], p =[0.9, 0.1]))
df = df.dropna()blue_new = df[(df['blue_dif'] >= -0.08) & (df['blue_dif'] <= 0.08)]['blue_dif']
green_new = df[(df['green_dif'] >= -0.08) & (df['green_dif'] <= 0.08)]['green_dif']
red_new = df[(df['red_dif'] >= -0.08) & (df['red_dif'] <= 0.08)]['red_dif']
inf_new = df[(df['inf_dif'] >= -0.1) & (df['inf_dif'] <= 0.1)]['inf_dif']plt.figure(0)
plt.hist(blue_original, bins = 50)
plt.figure(1)
plt.hist(green_original, bins = 50)
plt.figure(2)
plt.hist(red_original, bins = 50)
plt.figure(3)
plt.hist(inf_original, bins = 50)plt.figure(4)
plt.hist(blue_new, bins = 50)
plt.figure(5)
plt.hist(green_new, bins = 50)
plt.figure(6)
plt.hist(red_new, bins = 50)
plt.figure(7)
plt.hist(inf_new, bins = 50)df.to_csv(result_file_path, index=False)
首先,我们通过pd.read_csv函数从指定路径的.csv文件中读取数据,并将其存储在名为df的DataFrame中。
接下来,通过一系列条件筛选操作,从原始数据中选择满足特定条件的子集。具体来说,我们筛选出了在blue_dif、green_dif、red_dif与inf_dif这4列中数值在一定范围内的数据,并将这些数据存储在名为blue_original、green_original、red_original和inf_original的新Series中,这些数据为我们后期绘制直方图做好了准备。
其次,创建一个名为mask的布尔掩码,该掩码用于筛选满足条件的数据。在这里,它筛选出了days列的值在0到45之间或在320到365之间的数据。
随后,我们使用apply函数和lambda表达式,对于days列的值在0到45之间或在320到365之间的行,如果其blue_dif、green_dif、red_dif与inf_dif这4列的数据不在指定范围内,那么就将这列的数据随机设置为NaN,p =[0.9, 0.1]则是指定了随机替换为NaN的概率。这里需要注意,如果我们不给出p =[0.9, 0.1]这样的概率分布,那么程序将依据均匀分布的原则随机选取数据。
最后,我们使用dropna函数,删除包含NaN值的行,从而得到筛选处理后的数据。其次,我们依然根据这四列的筛选条件,计算出处理后的数据的子集,存储在blue_new、green_new、red_new和inf_new中。紧接着,使用Matplotlib创建直方图来可视化原始数据和处理后数据的分布;这些直方图被分别存储在8个不同的图形中。
代码的最后,将处理后的数据保存为新的.csv文件,该文件路径由result_file_path指定。
运行上述代码,我们将得到8张直方图,如下图所示。且在指定的文件夹中看到结果文件。
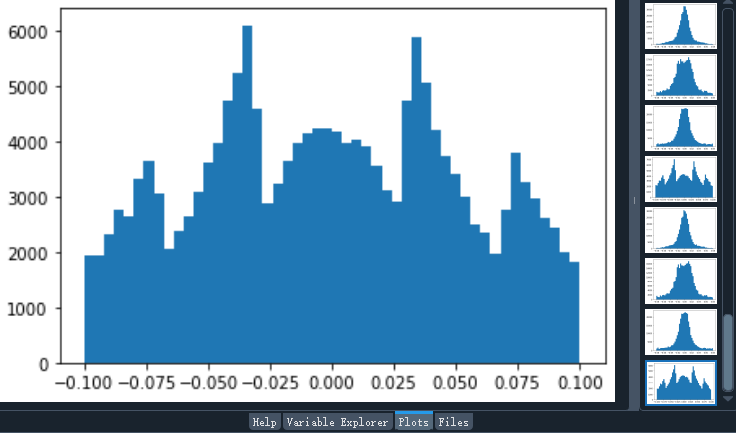
至此,大功告成。
欢迎关注:疯狂学习GIS
相关文章:
Python用若干列的数据多条件筛选、去除Excel数据并批量绘制直方图
本文介绍基于Python,读取Excel数据,以一列数据的值为标准,对这一列数据处于指定范围的所有行,再用其他几列数据数值,加以筛选与剔除;同时,对筛选与剔除前、后的数据分别绘制若干直方图ÿ…...
驱动开发,IO多路复用实现过程,epoll方式
1.框架图 被称为当前时代最好用的io多路复用方式; 核心操作:一棵树(红黑树)、一张表(内核链表)以及三个接口; 思想:(fd代表文件描述符) epoll要把检测的事件…...
java在mysql中查询内容无法塞入实体类中,报错 all elements are null
目录 一、问题描述二、解决方案 一、问题描述 java项目中整体配置了mysql的驼峰式字段匹配规则。 mybatis.configuration.map-underscore-to-camel-casetrue由于项目需求,需要返回字段为file_id,file_url,并且放入实体类中,实体…...
Linux 挂载
挂载需要挂载源和挂载点 虚拟机本身就有的挂源 添加硬件 重启虚拟机 操作程序 sudo fdisk -l //以管理员权限查看电脑硬盘使用情况sudo mkfs.ext4 /dev/sdb //以管理员身份格式化硬盘sudo mkdir guazai //创建挂载文件夹 sudo mount /dev/sdb/guazai //将挂载源接上挂载点 s…...

[面试] 15道最典型的k8s面试题
文章目录 在 Kubernetes 中,有以下常见的资源对象:1.什么是 Kubernetes?它的主要特点是什么?2. Kubernetes 中的 Pod 是什么?它的作用是什么?3.Kubernetes 中的 Deployment 和 StatefulSet 有何区别&#x…...

lintcode 552 · 创建最大数 【算法 数组 贪心 hard】
题目 https://www.lintcode.com/problem/552/description 描述 给出两个长度分别是m和n的数组来表示两个大整数,数组的每个元素都是数字0-9。从这两个数组当中选出k个数字来创建一个最大数,其中k满足k < m n。选出来的数字在创建的最大数里面的位置…...
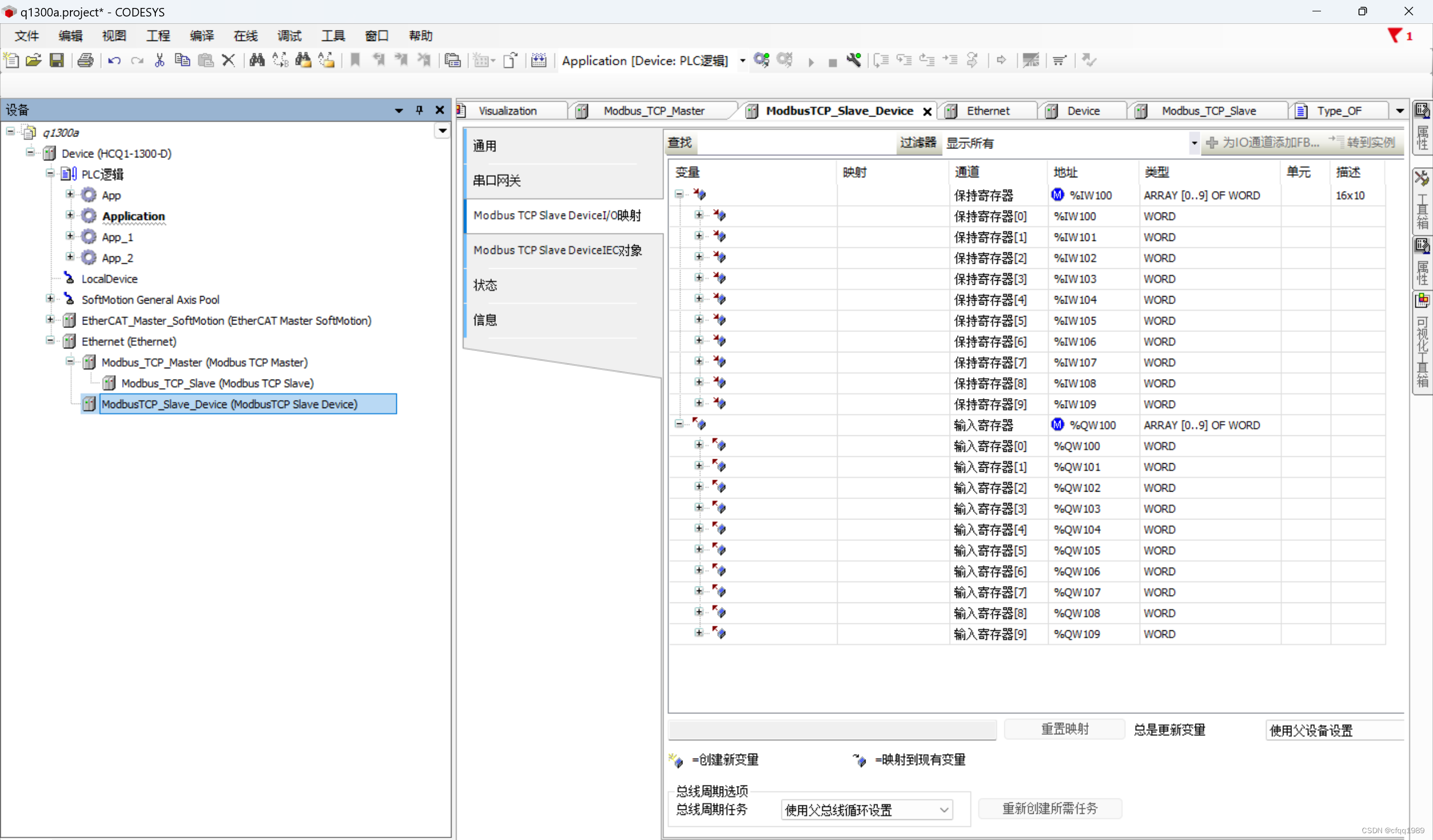
ModbusTCP服务端
1在Device下,添加设备net: 公交车。 2在net下添加 ModbusTCP...

Middleware ❀ Hadoop功能与使用详解(HDFS+YARN)
文章目录 1、服务概述1.1 HDFS1.1.1 架构解析1.1.1.1 Block 数据块1.1.1.2 NameNode 名称节点1.1.1.3 Secondary NameNode 第二名称节点1.1.1.4 DataNode 数据节点1.1.1.5 Block Caching 块缓存1.1.1.6 HDFS Federation 联邦1.1.1.7 Rack Awareness 机架感知 1.1.2 读写操作与可…...
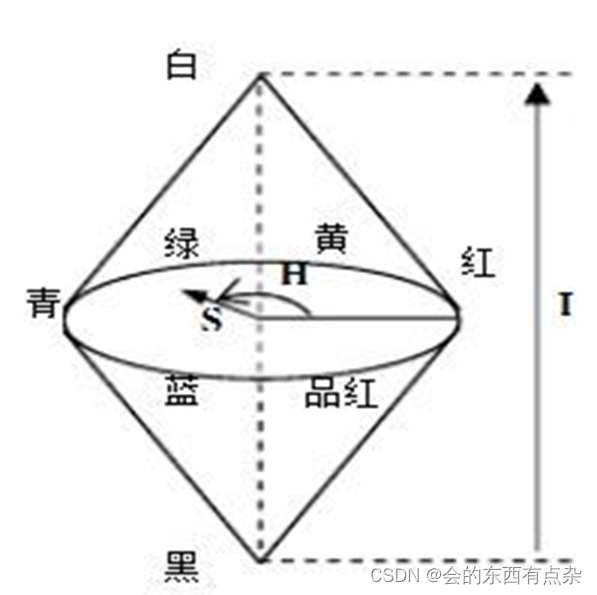
Matlab图像处理-从RGB转换为HSV
从RGB转换为HSV HSV彩色系统基于圆柱坐标系。从RGB转换为HSV需要开发将(笛卡儿坐标系中的)RGB值映射到圆柱坐标系的公式。多数计算机图形学教材中已详细推导了这一公式,故此处从略。 从RGB转换为HSV的MATLAB函数是rgb2hsv,其语法为: hsv_imag…...

iOS Error Domain=PHPhotosErrorDomain Code=3300
AVCapturePhoto的数据保存到 PHPhotoLibrary的时候报错Error DomainPHPhotosErrorDomain Code3300解决代码(也可以使用addResourceWithType:data:options:来添加数据到request,JEPG的实测可以,raw的不确定): [PHPhoto…...

LeetCode(力扣)435. 无重叠区间Python
LeetCode435. 无重叠区间 题目链接代码 题目链接 https://leetcode.cn/problems/non-overlapping-intervals/ 代码 class Solution:def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:if not intervals:return 0intervals.sort(keylambda x: x[0])co…...

opencv c++实现鼠标框选区域并显示选择的图片区域
OpenCV可以使用setMouseCallback设置鼠标事件的回调函数,从而然后根据需要进行处理。 setMouseCallback原型为: void cv::setMouseCallback(const cv::String& windowName, MouseCallback onMouse, void* userData = 0); 其中,参数说明如下:windowName:窗口名称 onMo…...

Python实现自主售卖机
1 问题 在python中我们常常使用到条件判断,if语句时常见的条件判断语句之一。那么如何使用if语句实现根据情况自动选择商品进行售卖呢? 2 方法 根据if语句执行时从上往下执行的特点,使用if语句、dict和list来实现整个流程。 代码清单 1 drink…...

任务复杂度与人机
任务复杂度计算是指根据任务的难易程度和需要的资源投入来评估任务的复杂程度。一般来说,任务复杂度计算会考虑以下几个因素: 难度程度:任务的难度程度是指完成任务所需要的知识、技能和经验等的要求。较高的难度程度会增加任务的复杂度。任务…...

Windows关闭zookeeper、rocketmq日志输出以及修改rocketmq的JVM内存占用大小
JDK-1.8zookeeper-3.4.14rocketmq-3.2.6 zookeeper 进入到zookeeper的conf目录 清空配置文件,只保留下面这一行。zookeeper关闭日志输出相对简单。 log4j.rootLoggerOFFrocketmq 进入到rocketmq的conf目录 logback_broker.xml <?xml version"1.0&q…...
Convai:让虚拟游戏角色更智能的对话AI人工智能平台
【产品介绍】 名称 Convai 具体描述 Convai是一款专为虚拟世界而设计的对话人工智能平台,它可以让你为你的游戏或应用中的角色 赋予人类般的对话能力。Convai利用了最先进的生成式对话人工智能技术,让你的角色可以…...

【送书活动】大模型赛道如何实现华丽的弯道超车
文章目录 导读前言AI/ML 模型训练任务对数据平台的需求01 具备对海量小文件的频繁数据访问的 I/O 效率02 提高 GPU 利用率,降低成本并提高投资回报率03 支持各种存储系统的原生接口04 支持单云、混合云和多云部署 核心密码01 通过数据抽象化统一数据孤岛02 通过分布…...
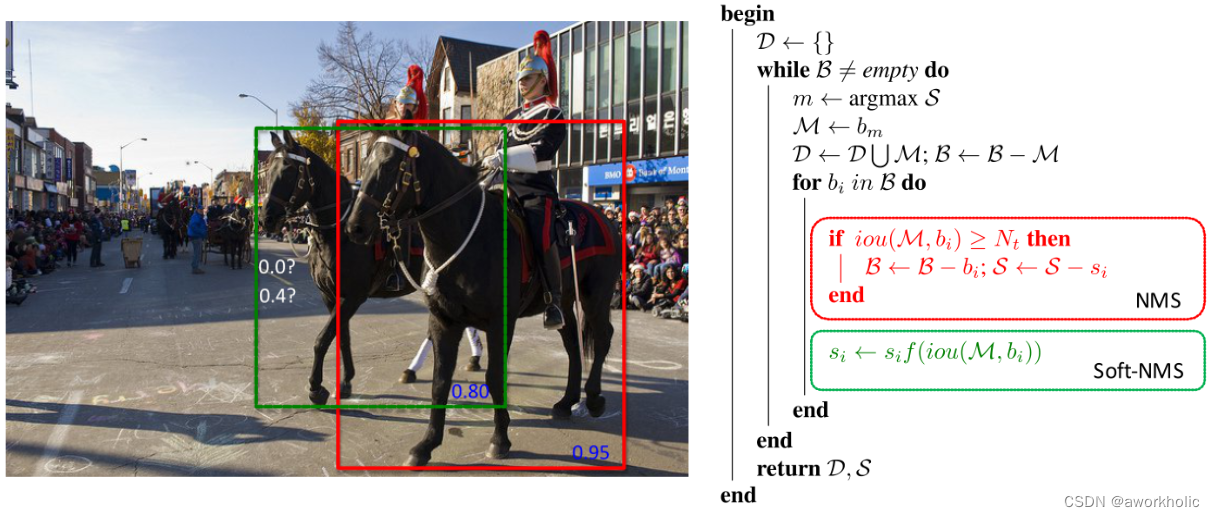
opencv dnn模块 示例(16) 目标检测 object_detection 之 yolov4
博客【opencv dnn模块 示例(3) 目标检测 object_detection (2) YOLO object detection】 测试了yolov3 及之前系列的模型,有在博客【opencv dnn模块 示例(15) opencv4.2版本dnn支持cuda加速(vs2015异常解决)】 说明了如何使用dnn模块进行cuda…...
Python提取JSON数据中的键值对并保存为.csv文件
本文介绍基于Python,读取JSON文件数据,并将JSON文件中指定的键值对数据转换为.csv格式文件的方法。 在之前的文章Python提取JSON文件中的指定数据并保存在CSV或Excel表格文件内(https://blog.csdn.net/zhebushibiaoshifu/article/details/132…...

使用IDEA开发Servlet
一、新建工程 二、填写新工程的基本信息 javaee8的项目可以运行在tomcat9 三、配置tomcat 1、编辑server信息 “On frame deactivation”的意思是idea窗口发生切换时。 2、编辑部署信息 war exploded方式,这种方式是以文件夹方式部署的,支持热加载。 …...

IEA-15-240-RWT:15MW海上风机开源模型的完整入门指南
IEA-15-240-RWT:15MW海上风机开源模型的完整入门指南 【免费下载链接】IEA-15-240-RWT 15MW reference wind turbine repository developed in conjunction with IEA Wind 项目地址: https://gitcode.com/gh_mirrors/ie/IEA-15-240-RWT 你是否曾经想要研究海…...

pyecharts-assets终极指南:告别网络依赖,打造本地可视化环境
pyecharts-assets终极指南:告别网络依赖,打造本地可视化环境 【免费下载链接】pyecharts-assets 🗂 All assets in pyecharts 项目地址: https://gitcode.com/gh_mirrors/py/pyecharts-assets 还在为pyecharts图表加载慢而烦恼吗&…...

Wwise音频处理完整指南:从游戏音效解包到个性化替换的终极方案
Wwise音频处理完整指南:从游戏音效解包到个性化替换的终极方案 【免费下载链接】wwiseutil Tools for unpacking and modifying Wwise SoundBank and File Package files. 项目地址: https://gitcode.com/gh_mirrors/ww/wwiseutil 还在为游戏音频文件无法编辑…...

【Unity进阶实战】将PC端EXE打包与压缩一体化:从项目设置到单文件发布
1. Unity项目打包前的关键设置 第一次用Unity打包PC端应用时,我踩过不少坑。记得有个项目打包后死活运行不起来,折腾半天才发现是场景没正确添加。所以打包前的准备工作特别重要,咱们一步步来。 打开Build Settings窗口(File >…...

终极指南:Xmake构建缓存清理策略,彻底解决缓存一致性问题
终极指南:Xmake构建缓存清理策略,彻底解决缓存一致性问题 【免费下载链接】xmake 🔥 A cross-platform build utility based on Lua 项目地址: https://gitcode.com/gh_mirrors/xm/xmake 在软件开发过程中,构建工具的缓存机…...
)
从“瞎猜”到“精准打击”:我的Qt项目Debug效率提升笔记(附GDB命令行技巧)
从“瞎猜”到“精准打击”:我的Qt项目Debug效率提升笔记(附GDB命令行技巧) 在大型Qt/C项目中,调试往往像在迷宫中摸索——图形化界面提供了便利,但当问题隐藏在动态库或第三方代码深处时,频繁点击"下一…...

BilibiliDown:5步快速下载B站视频的免费跨平台神器
BilibiliDown:5步快速下载B站视频的免费跨平台神器 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/B…...

从原理图到GDS:半定制数字反相器版图实战全流程解析
1. 半定制数字反相器版图设计入门 刚接触IC设计的朋友们,看到"从原理图到GDS"这个流程可能会觉得头大。别担心,咱们今天就用最接地气的方式,手把手带你完成一个数字反相器的版图设计。这个看似简单的反相器,其实包含了M…...

如何高效应用思源宋体:设计师的5个专业字体应用技巧
如何高效应用思源宋体:设计师的5个专业字体应用技巧 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版设计烦恼吗?思源宋体CN作为一款免费开源的专…...

自适应算法研究与应用综述
ArticleObjectiveMethodComments基于深度学习的领域自适应语义分割算法的综述与评论介绍最新的基于深度学习的领域自适应语义分割算法,并对未来的研究方向进行探讨通过对比实验,使用GTA5、Cityscapes和SYNTHIA等数据集进行性能评估无监督领域自适应语义分…...