Java手写堆排序(Heap Sort)和案例
Java手写堆排序(Heap Sort)
1. 思维导图
下面是使用Mermaid代码绘制的思维导图,用于解释堆排序算法的实现思路原理:
2. 手写堆排序的必要性
堆排序是一种高效的排序算法,它的时间复杂度为O(nlogn),具有以下几个方面的优势:
- 相对于其他基于比较的排序算法(如快速排序、归并排序),堆排序是一种原地排序算法,不需要额外的辅助空间;
- 堆排序是稳定的排序算法,不会改变相同元素之间的顺序;
- 堆排序在最坏情况下仍具有较好的性能,因此在一些对排序稳定性要求较高的场景中,堆排序是一个不错的选择。
3. 市场调研
据市场调研,堆排序在实际应用中广泛使用,特别是在以下场景中:
- 大规模数据的排序:由于堆排序的时间复杂度较低且具备稳定性,因此在需要对大规模数据进行排序的场景中,堆排序是一种常用的选择;
- 优先级队列:堆排序的基础是堆这种数据结构,而堆被广泛用于实现优先级队列。优先级队列是一种可以动态地插入和删除元素,并且每次操作都能高效地找到最大(或最小)值的数据结构,而堆正是实现这一特性的关键;
- 排名统计:堆排序在一些需要对数据进行排名统计的场景中也有应用,例如按照成绩对学生进行排名、按照销售额对商品进行排名等。
4. 实现步骤
堆排序的实现步骤包括以下几个部分:
4.1 建立最大堆
首先,我们需要构建一个最大堆,以便后续的排序操作。建立最大堆的步骤如下:
- 从最底层的非叶子节点开始,逐层向上调整,使得每个节点都满足最大堆的性质;
- 对于当前节点,比较其与左右子节点的大小,如果存在比当前节点更大的子节点,则交换两者的位置;
- 重复上述比较和交换的步骤,直到当前节点满足最大堆的性质或成为叶子节点。
以下是建立最大堆的Java代码:
// 建立最大堆
public static void buildMaxHeap(int[] array, int length) {for (int i = length / 2 - 1; i >= 0; i--) {heapify(array, length, i);}
}
4.2 交换堆顶和最后一个元素
建立最大堆之后,最大堆的堆顶元素即为数组中的最大值。我们将堆顶元素与数组中的最后一个元素进行交换。
以下是交换堆顶和最后一个元素的Java代码:
// 交换堆顶和最后一个元素
public static void swap(int[] array, int i, int j) {int temp = array[i];array[i] = array[j];array[j] = temp;
}
4.3 维护最大当交换堆顶和最后一个元素后,我们需要维护最大堆的性质,以保证新的堆顶元素是剩下元素中的最大值。
维护最大堆的步骤如下:
- 将交换后的堆顶元素(原数组的最后一个元素)下沉到合适的位置,以满足最大堆的性质;
- 每次将当前节点与其子节点进行比较,如果存在比当前节点更大的子节点,则将其与其中较大的子节点进行交换;
- 重复上述比较和交换的步骤,直到当前节点满足最大堆的性质或成为叶子节点。
以下是维护最大堆的Java代码:
// 维护最大堆性质
public static void heapify(int[] array, int length, int i) {int largest = i; // 当前节点int left = 2 * i + 1; // 左子节点int right = 2 * i + 2; // 右子节点// 如果左子节点比当前节点大if (left < length && array[left] > array[largest]) {largest = left;}// 如果右子节点比当前节点大if (right < length && array[right] > array[largest]) {largest = right;}// 如果最大值不是当前节点,交换它们的位置并继续调整if (largest != i) {swap(array, i, largest);heapify(array, length, largest);}
}
4.4 排序
在建立最大堆和维护最大堆的基础上,我们可以进行堆排序了。
堆排序的步骤如下:
- 通过调用建立最大堆的函数,构建一个最大堆;
- 从最后一个元素开始,依次将堆顶元素与当前元素进行交换,并缩小堆的范围以排除已排序的元素;
- 重复上述交换和缩小堆范围的操作,直到只剩下一个元素。
以下是堆排序的Java代码:
// 堆排序
public static void heapSort(int[] array) {int length = array.length;// 建立最大堆buildMaxHeap(array, length);// 从最后一个元素开始,依次交换堆顶和当前元素,并调整堆for (int i = length - 1; i >= 0; i--) {swap(array, 0, i);heapify(array, i, 0);}
}
5. 手写总结
堆排序是一种高效稳定的排序算法,适用于大规模数据的排序和优先级队列的实现。它的实现步骤包括建立最大堆、交换堆顶和最后一个元素、维护最大堆性质以及排序操作。通过合理地利用最大堆的性质,堆排序能够在O(nlogn)的时间复杂度下完成排序任务。
6. 拓展案例代码
按照成绩对学生进行排名
假设有一个学生列表,每个学生包含姓名和成绩两个属性。我们可以使用堆排序按照成绩对学生进行排名。
class Student {String name;int score;// 构造函数和其他方法省略...
}public static void heapSortByScore(Student[] students) {int length = students.length;// 建立最大堆,按照成绩进行比较buildMaxHeapByScore(students, length);// 从最后一个学生开始,依次交换堆顶和当前学生,并调整堆for (```java
int i = length - 1; i >= 0; i--) {swap(students, 0, i);heapifyByScore(students, i, 0);}
}// 建立最大堆,按照成绩进行比较
public static void buildMaxHeapByScore(Student[] students, int length) {for (int i = length / 2 - 1; i >= 0; i--) {heapifyByScore(students, length, i);}
}// 维护最大堆性质,按照成绩进行比较
public static void heapifyByScore(Student[] students, int length, int i) {int largest = i;int left = 2 * i + 1;int right = 2 * i + 2;if (left < length && students[left].score > students[largest].score) {largest = left;}if (right < length && students[right].score > students[largest].score) {largest = right;}if (largest != i) {swap(students, i, largest);heapifyByScore(students, length, largest);}
}// 交换两个学生的位置
public static void swap(Student[] students, int i, int j) {Student temp = students[i];students[i] = students[j];students[j] = temp;
}
使用示例:
Student[] students = new Student[5];
students[0] = new Student("Alice", 80);
students[1] = new Student("Bob", 75);
students[2] = new Student("Charlie", 90);
students[3] = new Student("David", 85);
students[4] = new Student("Eve", 70);heapSortByScore(students);for (Student student : students) {System.out.println(student.name + ": " + student.score);
}
输出结果:
Charlie: 90
Alice: 80
David: 85
Bob: 75
Eve: 70
按照成绩从高到低排名的结果就是Charlie、Alice、David、Bob、Eve。
这是一个基于堆排序的简单拓展案例,可以根据具体需求进行进一步的扩展和优化。希望对你有帮助!
相关文章:
和案例)
Java手写堆排序(Heap Sort)和案例
Java手写堆排序(Heap Sort) 1. 思维导图 下面是使用Mermaid代码绘制的思维导图,用于解释堆排序算法的实现思路原理: #mermaid-svg-cFIgsLSm5LOBm5Gl {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size…...
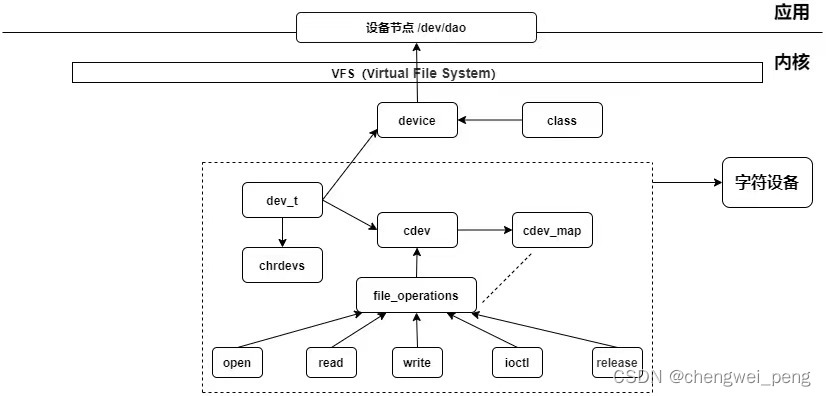
Linux设备驱动模型之字符设备
Linux设备驱动模型之字符设备 前面我们有介绍到Linux的设备树,这一节我们来介绍一下字符设备驱动。字符设备是在IO传输过程中以字符为单位进行传输的设备,而字符设备驱动则是一段可以驱动字符设备驱动的代码,当前Linux中,字符设备…...
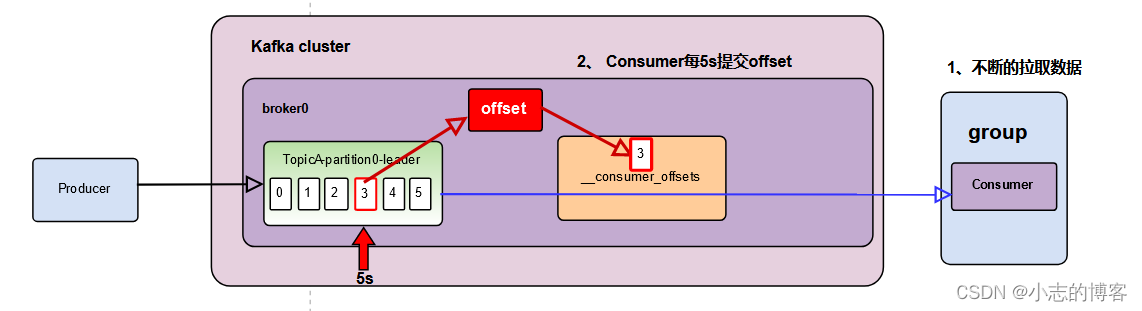
Kafka3.0.0版本——消费者(自动提交 offset)
目录 一、自动提交offset的相关参数二、消费者(自动提交 offset)代码示例 一、自动提交offset的相关参数 官网文档 参数解释 参数描述enable.auto.commi默认值为 true,消费者会自动周期性地向服务器提交偏移量。auto.commit.interval.ms如果…...

【业务功能116】微服务-springcloud-springboot-Kubernetes集群-k8s集群-KubeSphere-公共服务 DNS
kubernetes集群公共服务 DNS 一、软件安装 # yum -y install bind二、软件配置 # vim /etc/named.conf # cat -n /etc/named.conf1 //2 // named.conf3 //4 // Provided by Red Hat bind package to configure the ISC BIND named(8) DNS5 // server as a caching only…...
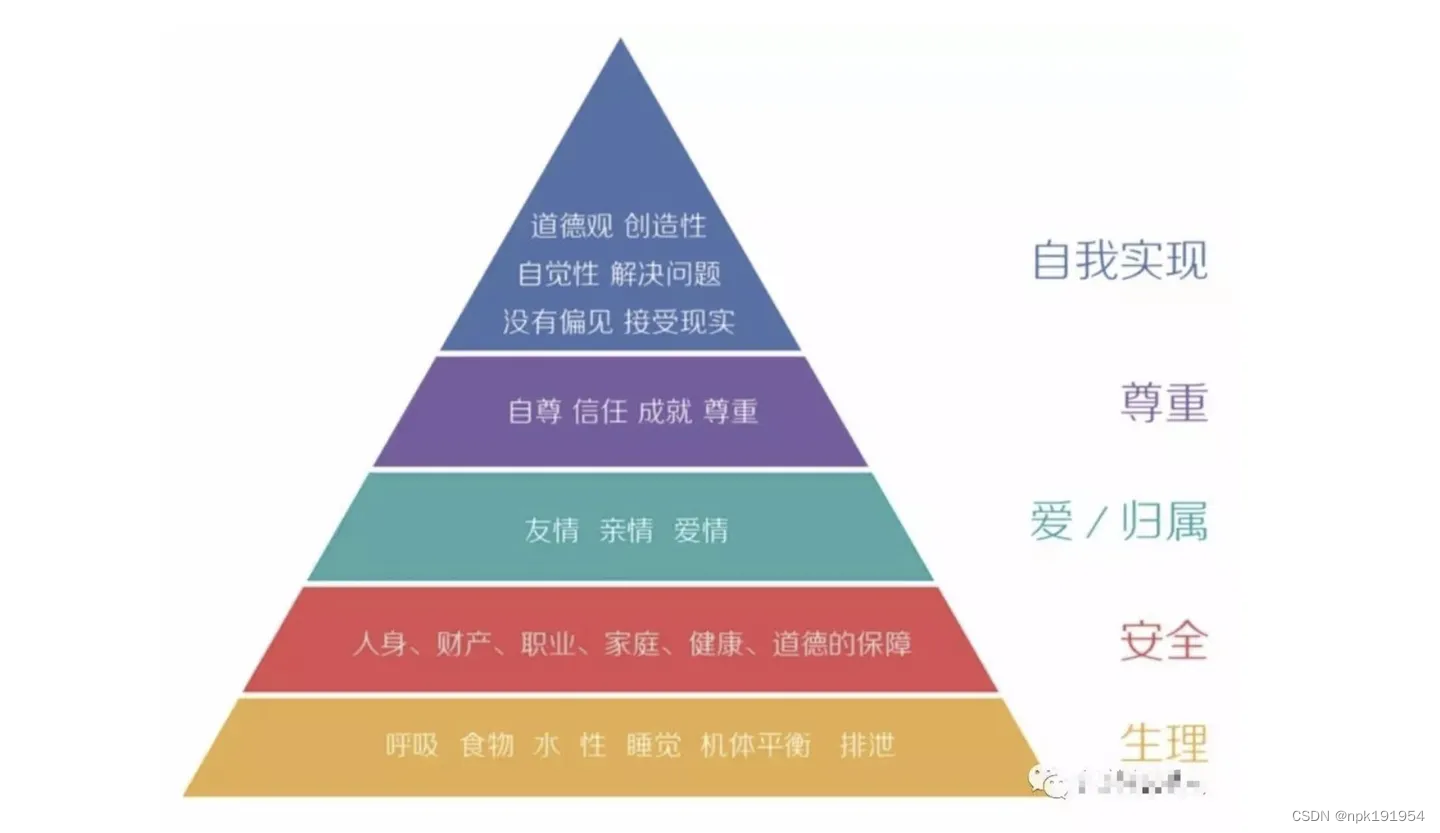
马斯洛的动机与人格、需求层次理论
马斯洛是在研究动机(Motivation)时,才提出需求层次作为理论基础来支持动机理论的。所谓动机,就是人类的行为到底是由什么驱动,其实是对人类行为的当下原动力,区别于过去、未来或者是有可能起作用的动力。 …...

TCP/IP网络传输模型及协议
文章目录 前言一、TCP/IP协议二、协议层报文间的封装与拆封1.发送数据2.接收数据前言 TCP/IP模型由OSI七层模型演变而来: 国际标准化组织 1984年提出了模型标准,简称 OSI(Open Systems Interconnection Model)七层模型: 物理层(Physics) :提供机械、电气、功能和过程特性…...
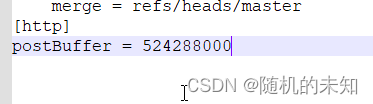
git 推送出现fatal: The remote end hung up unexpectedly解决方案
在使用git更新或提交项目时候出现 "fatal: The remote end hung up unexpectedly " 的报错; 报错的原因原因是推送的文件太大。 下面给出解决方法 方法一: 修改提交缓存大小为500M,或者更大的数字 git config --global http.po…...
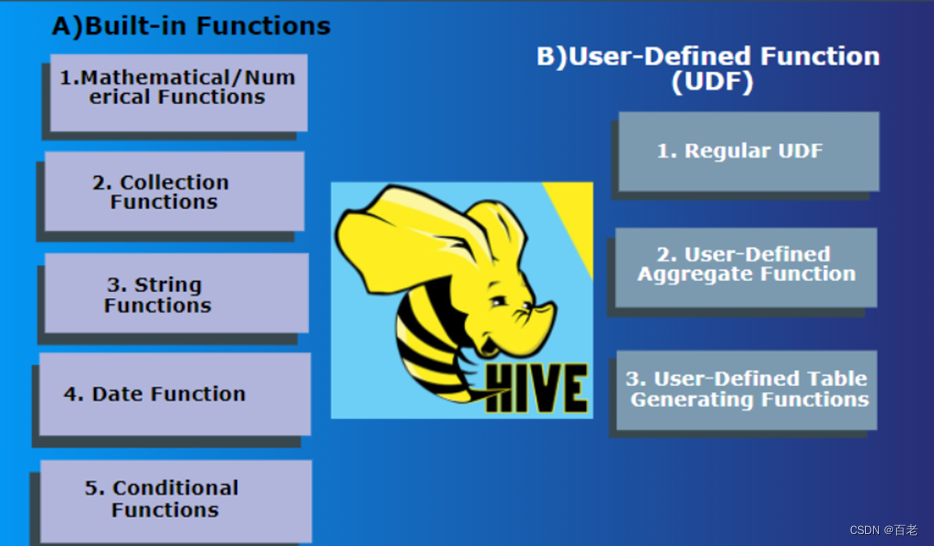
Hive内置函数字典
写在前面:HQL同SQL有很多的类似语法,同学熟悉SQL后一般学习起来非常轻松,写一篇文章列举常用函数,方便查找和学习。 1. 执行模式 1.1 Batch Mode 批处理模式 当使用-e或-f选项运行$ HIVE_HOME / bin / hive时,它将以…...

svg 知识点总结
1. 引用 svg,直接用 img 标签 <img src"帐篷.svg" alt"露营">2. 画 svg 各种图形。 矩形 rect圆角矩形 rect圆圈 circle椭圆 ellipse线段 line折线 polyline多边形 polygon路径 path <svg width"200" height"250&qu…...
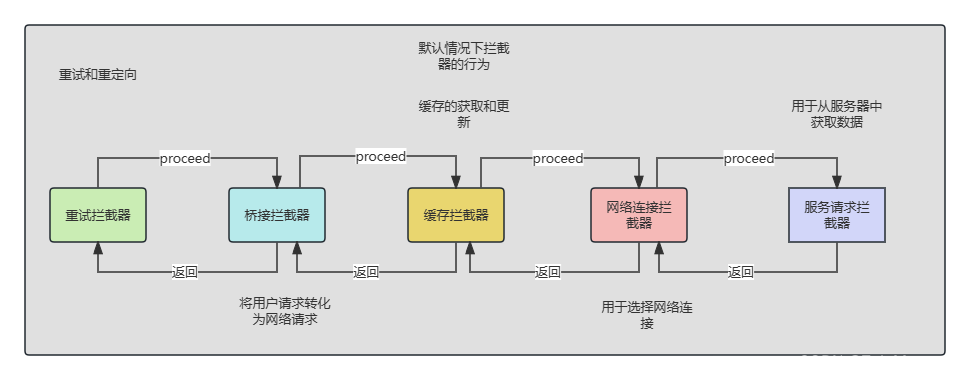
开源库源码分析:OkHttp源码分析(二)
开源库源码分析:OkHttp源码分析(二) 导言 上一篇文章中我们已经分析到了OkHttp对于网络请求采取了责任链模式,所谓责任链模式就是有多个对象都有机会处理请求,从而避免请求发送者和接收者之间的紧密耦合关系。这篇文章…...

校园地理信息系统的设计与实现
校园地理信息系统的设计与实现 摘 要 与传统的地图相比较,地理信息系统有着不可比拟的优势,信息量大,切换方便,可扩展性强。本文阐述了研究地理信息系统的背景、目的、方法,介绍了一个实用的、方便可靠的校园地理信息…...
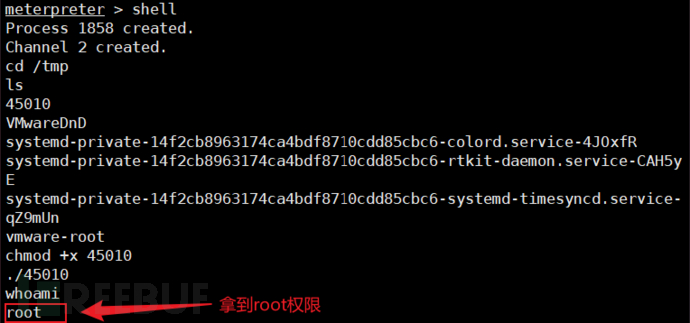
Vulnhub实战-prime1
前言 VulnHub 是一个面向信息安全爱好者和专业人士的虚拟机(VM)漏洞测试平台。它提供了一系列特制的漏洞测试虚拟机镜像,供用户通过攻击和漏洞利用的练习来提升自己的安全技能。本次,我们本次测试的是prime1。 一、主机发现和端…...

Scala学习笔记
Scala学习笔记 Scala笔记一、学习Scala的目的二、Scala的基本概念2.1 JDK1.8版本的新特性2.2 Scala的运行机制 三、Scala的基本语法3.1 Scala中输出语句、键盘输入、注释语法3.1.1 Scala注释三种,和Java一模一样的3.1.2 Scala键盘输入3.1.3 Scala输出 3.2 Scala变量…...
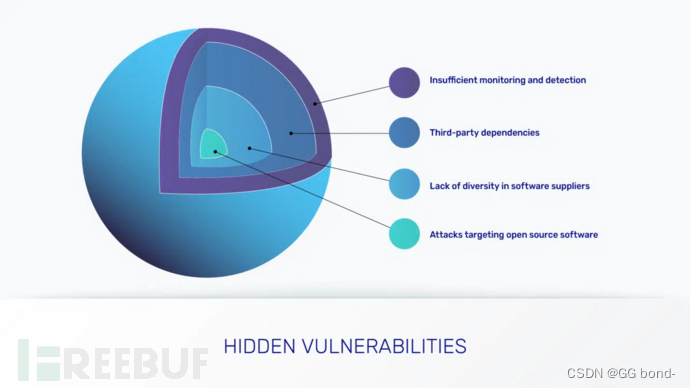
虹科分享 | 软件供应链攻击如何工作?如何评估软件供应链安全?
说到应用程序和软件,关键词是“更多”。在数字经济需求的推动下,从简化业务运营到创造创新的新收入机会,企业越来越依赖应用程序。云本地应用程序开发更是火上浇油。然而,情况是双向的:这些应用程序通常更复杂…...

gRpc入门和springboot整合
gRpc入门和springboot整合 一、简介 1、gprc概念 gRpc是有google开源的一个高性能的pc框架,Stubby google内部的rpc,2015年正式开源,云原生时代一个RPC标准。 tips:异构系统,就是不同编程语言的系统。 2、grpc核心设计思路 grpc核心设计…...

基于FPGA点阵显示屏设计-毕设
本设计是一1616点阵LED电子显示屏的设计。整机以EP2C5T144C8N为主控芯片,介绍了以它为控制系统的LED点阵电子显示屏的动态设计和开发过程。通过该芯片控制一个行驱动器74HC154和两个列驱动器74HC595来驱动显示屏显示。该电子显示屏可以显示各种文字或单色图像,采用4块8 x 8点…...

Rocky9.2基于http方式搭建局域网yum源
当前负责的项目有几十台Linux服务器,在安装各类软件的时候需要大量依赖包,而项目部署的环境属于内网环境,与Internet网完全隔离,无法采用配置网络yum源的方式安装rpm包,直接在每台linux服务器上配置本地yum源也比较麻烦,而采用直接下载rpm包用rpm命令安装更是费时费力。所…...

Android 串口通讯
Serial Port Android 串口通讯 arm64-v8a、armeabi-v7a、x86、x86_64 AAR 名称操作serial.jar下载arm64-v8a下载armeabi-v7a下载x86下载x86_64下载arm-zip下载x86-zip下载 Maven 1.build.grade | setting.grade repositories {...maven { url https://jitpack.io } }2./a…...

论如何在Android中还原设计稿中的阴影
每当设计稿上注明需要添加阴影时,Android上总是显得比较棘手,因为Android的阴影实现方式与Web和iOS有所区别。 一般来说阴影通常格式是有: X: 在X轴的偏移度 Y: 在Y轴偏移度 Blur: 阴影的模糊半径 Color: 阴影的颜色 何为阴影 但是在A…...
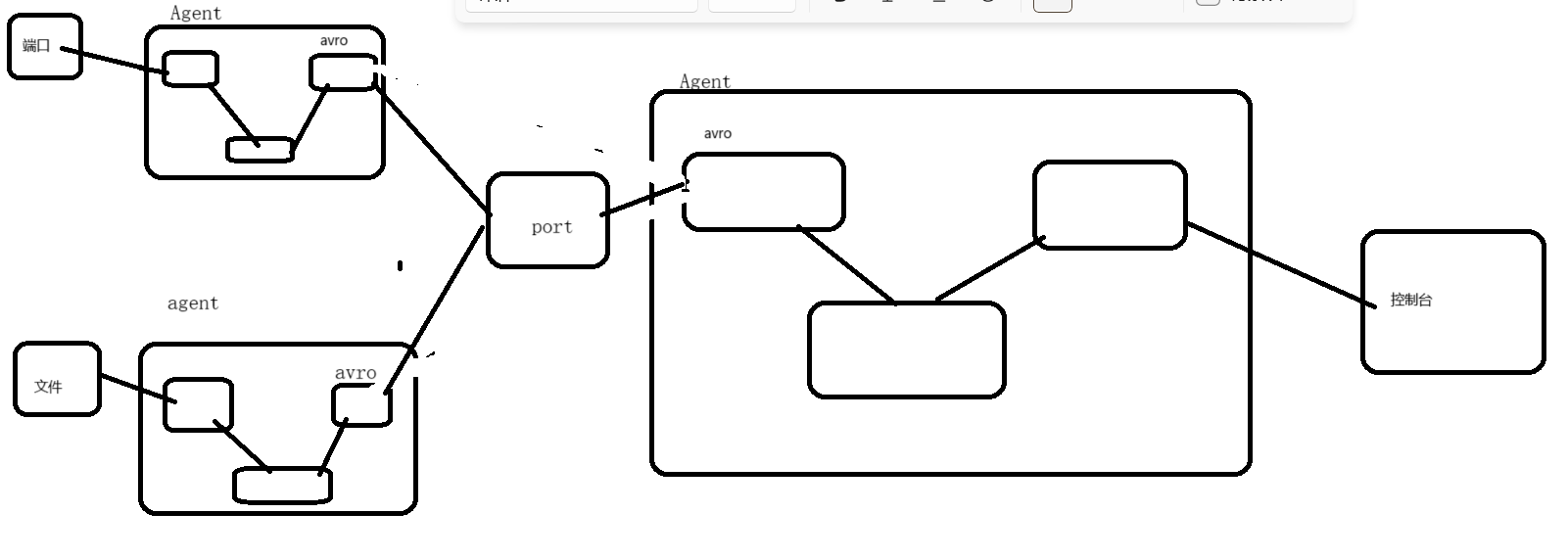
Hadoop生态圈中的Flume数据日志采集工具
Hadoop生态圈中的Flume数据日志采集工具 一、数据采集的问题二、数据采集一般使用的技术三、扩展:通过爬虫技术采集第三方网站数据四、Flume日志采集工具概述五、Flume采集数据的时候,核心是编写Flume的采集脚本xxx.conf六、Flume案例实操1、采集一个网络…...

不只是连线:用立创EDA做PCB布局时,这5个提升电路板可靠性的细节你注意了吗?
不只是连线:用立创EDA做PCB布局时,这5个提升电路板可靠性的细节你注意了吗? 在电子设计领域,PCB布局的质量往往决定了产品的最终表现。许多工程师能够完成基本的电路连接,却容易忽视那些看似微小却至关重要的设计细节。…...

智能汽车纵向行车辅助分层控制【附程序】
✨ 长期致力于交通事故场景分析、智能跟车、自动紧急制动、分层控制、联合仿真测试研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于真实事故场景的…...

语音合成的性能巅峰:深度拆解 supertonic,构建极速、私有化的端侧多语言 TTS
发布日期: 2026-05-14标签: #TTS #ONNX #端侧AI #边缘计算 #supertonic #多语言语音合成一、 引言在实时交互应用中,语音合成(TTS)的延迟往往是决定用户体验的生死线。依赖云端 API 不仅面临网络波动的风险,…...

【CentOS 7.6】打造现代化C/C++开发环境:Neovim配置、插件生态与智能补全实战
1. 环境准备与工具链搭建 在CentOS 7.6上构建现代化C/C开发环境,首先需要确保基础工具链的完整性。不同于桌面环境,服务器环境往往需要从源码编译安装最新版本的开发工具,这对系统兼容性和依赖管理提出了更高要求。 1.1 GCC编译器升级实战 Ce…...

边缘AI推理芯片选型指南:从吞吐量到延迟的实战评估
1. 从数据中心到边缘:AI推理范式的根本性转变如果你正在为你的下一个AI项目选型硬件,尤其是在考虑将模型部署到摄像头、汽车或者医疗设备上,那么“边缘AI推理”这个词你一定不陌生。但很多人,包括一些经验丰富的工程师,…...

从0到1构建DeepSeek抗注入能力:97.3%拦截率验证的5层LLM网关架构设计
更多请点击: https://intelliparadigm.com 第一章:从0到1构建DeepSeek抗注入能力:97.3%拦截率验证的5层LLM网关架构设计 为应对Prompt注入、越狱指令与上下文污染等高阶对抗攻击,我们设计并落地了一套轻量级、可插拔的5层LLM网关…...

基于Next.js 14与Sanity构建高性能个人博客:全栈技术栈解析与实践
1. 项目概述:一个现代、高性能的个人博客系统 最近在折腾个人博客,发现了一个非常亮眼的开源项目——CaliCastle/cali.so。这不仅仅是一个博客模板,更是一个集成了当前前端最佳实践的完整个人网站解决方案。原作者Cali(Calvin&am…...

Claude Code Session 实战指南:AI 结对编程效能提升手册
1. 项目概述:Claude Code Session 的实战效能提升手册如果你和我一样,日常开发中重度依赖 Claude 这类 AI 编程助手,那你肯定遇到过这样的场景:面对一个复杂的重构任务,你向 Claude 描述了半天需求,它给出的…...

降AI率软件9平台覆盖测评:嘎嘎降自研稳定vs套壳工具单平台!
降AI率软件9平台覆盖测评:嘎嘎降自研稳定vs套壳工具单平台! 「支持知网维普」实际只能稳定降一个平台,这是怎么回事? 我是双学位本科生,毕业论文 3.5 万字。学校规定送知网做 AIGC 检测,但导师建议我自己…...

终极指南:3分钟学会用Video-subtitle-extractor高效提取视频硬字幕
终极指南:3分钟学会用Video-subtitle-extractor高效提取视频硬字幕 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检…...