tensorflow的unet模型
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Dropout, UpSampling2D, concatenate# 定义 U-Net 模型
def unet(input_size=(256, 256, 3)):inputs = Input(input_size)# 编码器部分conv1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(inputs)conv1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv1)pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)conv2 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool1)conv2 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv2)pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)conv3 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool2)conv3 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv3)pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)conv4 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool3)conv4 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv4)drop4 = Dropout(0.5)(conv4)pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)# 中间层conv5 = Conv2D(1024, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool4)conv5 = Conv2D(1024, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv5)drop5 = Dropout(0.5)(conv5)# 解码器部分up6 = Conv2D(512, 2, activation='relu', padding='same', kernel_initializer='he_normal')(UpSampling2D(size=(2, 2))(drop5))merge6 = concatenate([drop4, up6], axis=3)conv6 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge6)conv6 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv6)up7 = Conv2D(256, 2, activation='relu', padding='same', kernel_initializer='he_normal')(UpSampling2D(size=(2, 2))(conv6))merge7 = concatenate([conv3, up7], axis=3)conv7 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge7)conv7 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv7)up8 = Conv2D(128, 2, activation='relu', padding='same', kernel_initializer='he_normal')(UpSampling2D(size=(2, 2))(conv7))merge8 = concatenate([conv2, up8], axis=3)conv8 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge8)conv8 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv8)up9 = Conv2D(64, 2, activation='relu', padding='same', kernel_initializer='he_normal')(UpSampling2D(size=(2, 2))(conv8))merge9 = concatenate([conv1, up9], axis=3)conv9 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge9)conv9 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv9)outputs = Conv2D(1, 1, activation='sigmoid')(conv9)model = tf.keras.Model(inputs=inputs, outputs=outputs)return model# 创建 U-Net 模型
model = unet()
model.summary()
一个简单的 U-Net 模型的 TensorFlow 2.x 代码示例。U-Net 模型通常用于图像分割任务。
import tensorflow as tf
import numpy as np
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Dropout, UpSampling2D, concatenate
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split# 定义 U-Net 模型
def unet(input_size=(256, 256, 3)):inputs = Input(input_size)# 编码器部分...# 解码器部分...# 输出层...#请看上述代码model = Model(inputs=inputs, outputs=outputs)return model# 准备训练数据和标签
# 这里假设你已经有了医学图像数据集,以及相应的分割标签
# 请根据你的数据集的格式来加载和预处理数据
# 假设训练数据和标签分别存储在 train_images 和 train_masks 中# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(train_images, train_masks, test_size=0.2, random_state=42)# 创建 U-Net 模型
model = unet()# 编译模型
model.compile(optimizer=Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, batch_size=4, epochs=10, validation_data=(X_val, y_val))# 保存模型
model.save("unet_medical_segmentation.h5")
在加载和预处理医学图像数据时,可以使用 Python 中的图像处理库如 OpenCV 或 Pillow。调整大小和预处理医学图像的示例代码
import cv2
import numpy as np
def load_and_preprocess_image(image_path, target_size=(256, 256)):# 读取图像image = cv2.imread(image_path)# 如果需要,调整图像大小if target_size is not None:image = cv2.resize(image, target_size)# 预处理图像(根据你的需求进行进一步的预处理,如归一化)image = image / 255.0 # 归一化到 [0, 1] 范围return image
# 示例用法:
image_path = "your_image.jpg" # 替换成你的图像文件路径
target_size = (256, 256) # 替换成你想要的目标大小
# 加载和预处理图像
preprocessed_image = load_and_preprocess_image(image_path, target_size)
# 打印图像的形状(用于验证)
print("Image shape:", preprocessed_image.shape)
它遍历目录中的图像文件,加载并预处理这些图像,然后将它们转换为 TensorFlow 张量
import tensorflow as tf
import os
import cv2
import numpy as npdef load_and_preprocess_image(image_path, target_size=(256, 256)):# 读取图像image = cv2.imread(image_path)# 如果需要,调整图像大小if target_size is not None:image = cv2.resize(image, target_size)# 预处理图像(根据你的需求进行进一步的预处理,如归一化)image = image / 255.0 # 归一化到 [0, 1] 范围return imagedef load_and_preprocess_images_in_directory(directory, target_size=(256, 256)):images = []# 遍历目录中的图像文件for filename in os.listdir(directory):if filename.endswith(".jpg") or filename.endswith(".png"):image_path = os.path.join(directory, filename)preprocessed_image = load_and_preprocess_image(image_path, target_size)images.append(preprocessed_image)# 将图像列表转换为 TensorFlow 张量images = np.array(images)images = tf.convert_to_tensor(images, dtype=tf.float32)return images# 示例用法:
image_directory = "your_image_directory" # 替换成包含图像的目录路径
target_size = (256, 256) # 替换成你想要的目标大小# 加载和预处理图像
image_tensor = load_and_preprocess_images_in_directory(image_directory, target_size)# 打印图像张量的形状(用于验证)
print("Image tensor shape:", image_tensor.shape)
相关文章:

tensorflow的unet模型
import tensorflow as tf from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Dropout, UpSampling2D, concatenate# 定义 U-Net 模型 def unet(input_size(256, 256, 3)):inputs Input(input_size)# 编码器部分conv1 Conv2D(64, 3, activationrelu, padding…...
(2023 最新版)IntelliJ IDEA 下载安装及配置教程
IntelliJ IDEA下载安装教程(图解) IntelliJ IDEA 简称 IDEA,由 JetBrains 公司开发,是 Java 编程语言开发的集成环境,具有美观,高效等众多特点。在智能代码助手、代码自动提示、重构、J2EE 支持、各类版本…...

react 实现拖动元素
demo使用create-react-app脚手架创建 删除一些文件,创建一些文件后 结构目录如下截图com/index import Movable from ./move import { useMove } from ./move.hook import * as Operations from ./move.opMovable.useMove useMove Movable.Operations Operationse…...

【EI会议】第二届声学,流体力学与工程国际学术会议(AFME 2023)
第二届声学,流体力学与工程国际学术会议 2023 2nd International Conference on Acoustics, Fluid Mechanics and Engineering(AFME 2023) 声学、流体力学两个古老的学科发展至今,无时无刻都在影响着我们的生活。小到日常使用的耳…...

Android StringFog 字符串自动加密
一、StringFog 作用 一款自动对dex/aar/jar文件中的字符串进行加密Android插件工具,正如名字所言,给字符串加上一层雾霭,使人难以窥视其真面目。可以用于增加反编译难度,防止字符串代码重复。 支持java/kotlin。支持app打包生成…...

上四休三,未来的期许
近日“少上一天班,究竟香不香”引发关注,英国媒体2月21日报道,一项全世界目前为止参加人数最多的“四天工作制”试验,不久前在英国取得了成功。很多人表示上过四天班之后,给多少钱也回不去五天班的时代了。 来百度APP畅…...
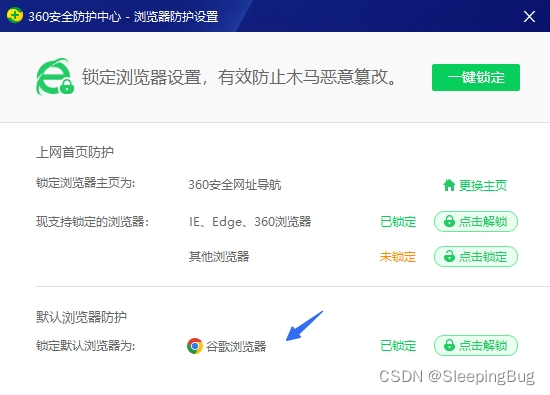
怎么防止360安全卫士修改默认浏览器?
默认的浏览器 原先选项是360极速浏览器(如果有安装的话),我这里改成了Chrome。 先解锁 才能修改。...

调整参数提高mysql读写速度
要提升MySQL的写入速度,您可以采取一些参数调整和优化措施,这些措施可以根据您的具体应用和环境进行调整。以下是一些常见的参数和优化建议: InnoDB存储引擎: 如果您使用的是InnoDB存储引擎,确保以下参数被设置得合理: innodb_buffer_pool_size:增加内存池大小,以便更多…...

Go expvar包
介绍与使用 expvar 是 exposed variable的简写 expvar包[1]是 Golang 官方为暴露Go应用内部指标数据所提供的标准对外接口,可以辅助获取和调试全局变量。 其通过init函数将内置的expvarHandler(一个标准http HandlerFunc)注册到http包ListenAndServe创建的默认Serve…...

Yolo v8代码逐行解读
train.py文件 1.FILE Path(__file__).resolve() __file__代表的是train.py文件,Path(__file__).resolve()结果是train.py文件的绝对路径。 2.ROOT FILE.parents[0] 获得train.py父目录的绝对路径 3.sys.path 是一个列表list,里面包含了已经添加到系…...

9.18号作业
完善登录框 点击登录按钮后,判断账号(admin)和密码(123456)是否一致,如果匹配失败,则弹出错误对话框,文本内容“账号密码不匹配,是否重新登录”,给定两个按钮…...
)
Spring源码阅读(spring-framework-5.2.24)
spring-aop spring-aspects spring-beans spring-context 等等 第一步: Tags spring-projects/spring-framework GitHub 找到相应的release版本 第二步: 下载相应版本的gardle,如何看版本 spring-framework/gradle/wrapper /gradl…...
【SpringMVC】文件上传与下载、JREBEL使用
目录 一、引言 二、文件的上传 1、单文件上传 1.1、数据表准备 1.2、添加依赖 1.3、配置文件 1.4、编写表单 1.5、编写controller层 2、多文件上传 2.1、编写form表单 2.2、编写controller层 2.3、测试 三、文件下载 四、JREBEL使用 1、下载注册 2、离线设置 一…...

数据结构 第二章作业 线性表 西安石油大学
在顺序表中插入和删除一个结点需平均移动多少个结点?具体的移动次数取决于 哪两个因素? 在顺序表中插入和删除一个结点时,平均移动的结点数量取决于两个因素:插入/删除位置和当前顺序表的长度。 插入/删除位置:如果要…...

vue.mixin全局混合选项
在Vue.js中,Vue.mixin 是一个用来全局混合(mixin)选项的方法。它允许你在多个组件中共享相同的选项,例如数据、方法、生命周期钩子等。这可以用来在组件之间重复使用一些逻辑或共享一些通用的功能 Vue.mixin({// 在这里定义混合的选项data() {return {s…...
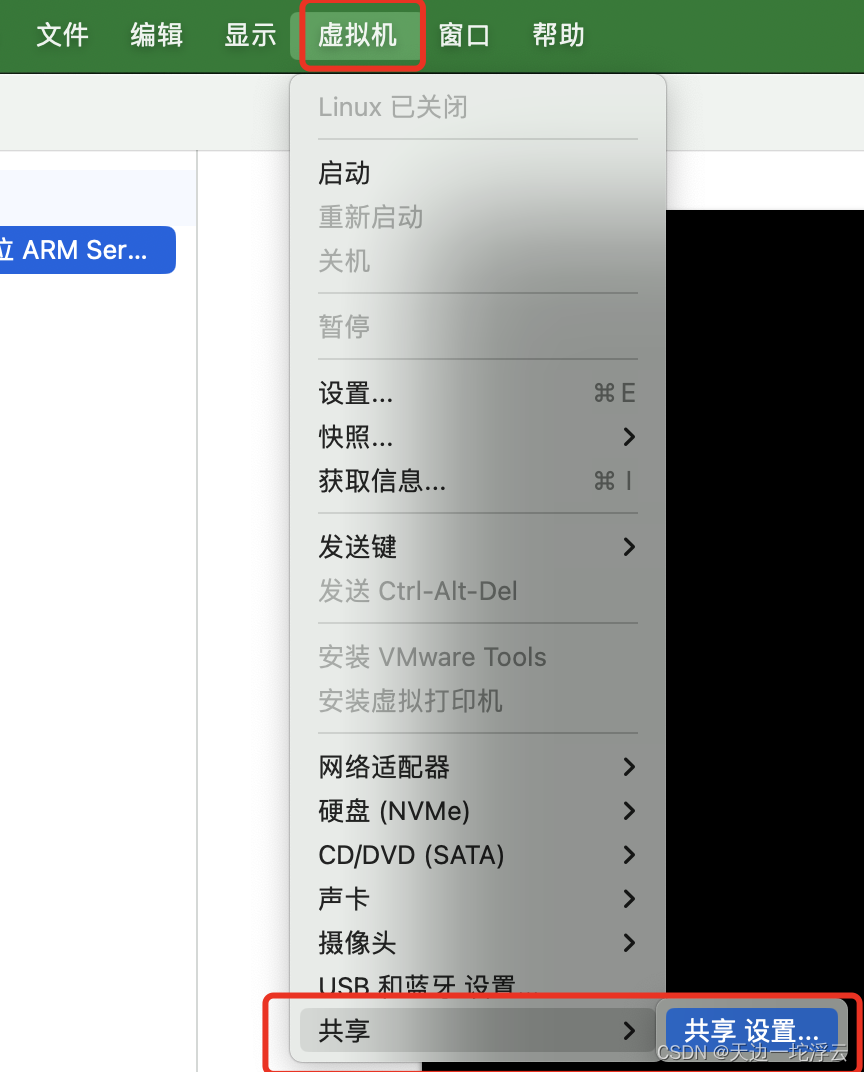
VMware Fusion 13+Ubuntu ARM Server 22.04.3在M2芯片的Mac上共享文件夹
因为Server版没有桌面,VMware Tools不能直接装,导致没办法共享文件。 Ubuntu中的包如果需要更新,先执行下面的步骤 sudo apt update 再执行 sudo apt upgrade 不需要更新的话,直接执行下面的步骤 先把open-vm-tools卸载了 …...

PostgreSQL serial类型
serial类型和序列 postgresql序列号(SERIAL)类型包括 smallserial(smallint,short),serial(int)bigserial(bigint,long long int) 不管是smallserial,serial还是bigserial,其范围都是(1,9223372036854775807)&#…...

[创业之路-76] - 创业公司如何在长期坚持中顺势而为?诚迈科技参观交流有感
目录 一、创业环境 1.1. VUCA乌卡时代:易变、复杂、不确定性、模糊的时代 1.2. 中国用了四十年的时间完成了三次工业革命:机械化、电气化、数字化 1.3. 中国正在经历着第四次工业革命:智能化、生态化、拟人化 1.4 国产替代:国…...

人脸修复祛马赛克算法CodeFormer——C++与Python模型部署
一、人脸修复算法 1.算法简介 CodeFormer是一种基于AI技术深度学习的人脸复原模型,由南洋理工大学和商汤科技联合研究中心联合开发,它能够接收模糊或马赛克图像作为输入,并生成更清晰的原始图像。算法源码地址:https://github.c…...

Go语言AI Agent框架goclaw:模块化架构与技能系统实战
1. 项目概述:一个用Go语言构建的现代化AI Agent框架如果你正在寻找一个功能全面、架构清晰,并且能让你快速上手构建智能助理的Go语言框架,那么goclaw(狗爪)绝对值得你花时间研究。我最近在评估几个开源的AI Agent框架&…...

uHabits习惯追踪应用完整指南:从入门到精通的5个实用技巧
uHabits习惯追踪应用完整指南:从入门到精通的5个实用技巧 【免费下载链接】uhabits Loop Habit Tracker, a mobile app for creating and maintaining long-term positive habits 项目地址: https://gitcode.com/gh_mirrors/uh/uhabits uHabits习惯追踪应用是…...
为你的五子棋项目加个‘智能大脑’)
从AlphaGo到你的小游戏:如何用MCTS(蒙特卡洛树搜索)为你的五子棋项目加个‘智能大脑’
从AlphaGo到你的小游戏:如何用MCTS为五子棋项目构建智能决策引擎 当你在手机上下棋输给AI时,是否好奇过这些"电子大脑"如何思考?2016年AlphaGo击败李世石的关键技术之一——蒙特卡洛树搜索(MCTS),…...
)
Proteus仿真入门:手把手教你用51单片机点亮共阳数码管(附完整代码与电路图)
Proteus仿真入门:51单片机驱动共阳数码管全流程解析 第一次接触单片机仿真时,看着那些闪烁的数码管总觉得神奇又遥远。记得我大三那年,为了完成课程设计,在实验室熬了三个通宵才让数码管显示出正确的数字。今天,我们就…...

在Windows上直接安装Android应用:APK安装器的三大优势与完整使用指南
在Windows上直接安装Android应用:APK安装器的三大优势与完整使用指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经希望在Windows电脑上直接运…...
)
华为eNSP模拟企业网:用VRRP+MSTP搞定500人公司的网络冗余与隔离(附排错记录)
华为eNSP实战:构建500人企业级网络的高可用架构 当一家企业发展到500人规模时,网络架构的稳定性和可靠性就成为业务连续性的关键保障。作为网络工程师,我们经常面临这样的挑战:如何在有限的预算下,设计出既满足部门隔离…...

SkillPilot:AI编程助手技能一键管理与安全部署实战
1. 项目概述与核心价值最近在折腾AI编程助手的时候,发现了一个挺有意思的痛点:虽然Claude Code、Cursor这些工具都支持通过SKILL.md文件来扩展功能,但每次想找个新技能,都得手动去GitHub上翻找、下载、配置,还得担心代…...
)
别再复制粘贴了!用LabVIEW 2023实现TCP/IP通讯的保姆级教程(附完整DEMO下载)
LabVIEW 2023 TCP/IP通讯实战:从原理到健壮性设计的深度解析 在工业自动化与测试测量领域,稳定可靠的通讯系统如同设备的神经系统。许多LabVIEW开发者虽然能够通过复制粘贴完成基础通讯功能,却在真实项目中频繁遭遇数据丢失、连接不稳定等&qu…...

基于MCP架构构建营销数据管道:打通Google Ads、Meta Ads与GA4的数据孤岛
1. 项目概述:打通营销数据孤岛的“瑞士军刀” 如果你在数字营销领域摸爬滚打过几年,尤其是在同时操盘谷歌广告和Meta广告,并且数据后台用的是Google Analytics 4,那你一定对下面这个场景深恶痛绝:老板或客户要一份整体…...

AI原生创意协作框架Muse:从网状思维管理到自动化工作流实战
1. 项目概述:一个为创意工作者打造的AI原生工具最近在探索AI辅助创作工具时,我遇到了一个让我眼前一亮的项目:myths-labs/muse。乍一看这个名字,你可能会联想到艺术女神缪斯,而它的定位也确实如此——旨在成为创意工作…...