爬虫框架Scrapy学习笔记-2
前言
Scrapy是一个功能强大的Python爬虫框架,它被广泛用于抓取和处理互联网上的数据。本文将介绍Scrapy框架的架构概览、工作流程、安装步骤以及一个示例爬虫的详细说明,旨在帮助初学者了解如何使用Scrapy来构建和运行自己的网络爬虫。
爬虫框架Scrapy学习笔记-1
文章目录
- 前言
- Scrapy架构概览
- Scrapy工作流程
- 更形象的Scrapy工作流程
- 角色对应
- 工作流程
- Scrapy安装
- Scrapy的工作流程
- 实例
- 创建
- xyx/xyx/spiders/xiaoyx.py
- yield和return
- xyx/xyx/pipelines.py
- Pipeline详解
- 运行
- 总结
Scrapy架构概览
Scrapy由以下主要组件构成:
- 引擎(Engine):负责控制数据流在各个组件之间的流动,触发事务。
- 调度器(Scheduler):接收引擎发过来的Request请求,去重后入队列,并在合适时机返回请求给引擎。
- 下载器(Downloader):负责获取Scrapy引擎发送的Request请求对应的响应,并返回Response给引擎。
- 爬虫(Spider):解析响应内容,提取Item字段数据或生成额外的Request请求。
- 项目管道(Pipeline):处理爬虫提取出的Item,进行后续处理,例如数据清洗、存储等。
- 下载器中间件(Downloader Middlewares):可以自定义扩展下载器的功能和行为。
- 爬虫中间件(Spider Middlewares):可以自定义扩展爬虫的功能和行为。
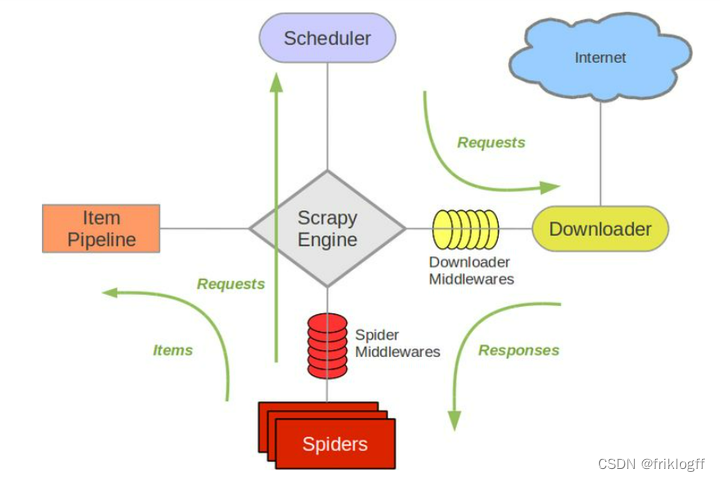
Scrapy工作流程
- Engine打开一个网站(启动请求)并将其交给Scheduler入队
- Scheduler处理后出队,通过Downloader Middlewares发送给Downloader执行
- Downloader获取网页数据,并通过Downloader Middlewares返回Response
- Response经过Spider Middlewares发送给Spider
- Spider解析Response,提取Item和生成Request
- Item经过Spider Middlewares,发送给Item Pipeline处理
- Request经过Spider Middlewares,发送给Scheduler入队
- Scheduler发送新的Request给Downloader,重复2-7步
更形象的Scrapy工作流程
Scrapy就是一个采集工厂,组件对应如下:
角色对应
- Engine - 主管
- Scheduler - 仓库管理员
- Downloader - 采购员
- Spider - 加工组装工人
- Item Pipeline - 质检部门和成品仓库
- Downloader Middlewares - 采购助手
- Spider Middlewares - 流水线管理工程师
工作流程
- 主管指示仓库管理员提供原材料 —— Engine打开网站,交给Scheduler
- 仓库管理员按顺序取出原材料清单 —— Scheduler处理后出队
- 将原材料清单给采购员采购 —— 通过Downloader Middlewares发送给Downloader
- 采购员出去采购,并由助手进行预处理 —— Downloader获取数据,通过Downloader Middlewares返回Response
- 将采购回来的原材料给工人加工组装 —— Response经Spider Middlewares发送给Spider
- 工程师检查工作流程的合规性,并优化 —— Spider解析Response,提取Item和生成Request
- 产品送到质检和成品仓库 —— Item经Spider Middlewares发送给Item Pipeline
- 工人反馈还需要原材料清单 —— Request经Spider Middlewares发送给Scheduler
- 重复2-8步,直到订单完成 —— Scheduler发送Request给Downloader,进入下一个循环
Scrapy安装
建议单独开新环境,使用Virtualenv环境或Conda环境
半自动化使用.bat手动打包迁移python项目
python3.9
scrapy 2.5.1 -> scrapy-redis(0.7.2)
注意, 由于scrapy的升级.
导致scrapy-redis无法正常使用.所以这里我们选择2.5.1这个版本作为学习.
后期可以根据scrapy-redis的升级而跟着升级
安装完成后. 请调整OpenSSL的版本.
总之, 最终你的控制台输入scrapy version和crapy version --verbose
能显示版本号. 就算成功了
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy==2.5.1
pip install pyopenssl==22.0.0
pip install cryptography==36.0.2
scrapy version
scrapy version --verbose
Scrapy的工作流程
- 需要创建项目
scrapy startproject 项目名 - 进入到项目目录
cd 项目名 - 生成spider
scrapy genspider 爬虫的名字 网站的域名 - 调整spider
给出start_urls
以及如何解析数据. parse
例如,你可以运行:
scrapy startproject demo
cd demo
scrapy genspider example example.com
你会得到
demo/demo/spiders/example.py
# 导入scrapy框架
import scrapy# 定义爬虫类 ExampleSpider,继承自scrapy.Spider
class ExampleSpider(scrapy.Spider):# 定义爬虫名称name = 'example' # 允许爬取的域名列表allowed_domains = ['example.com']# 起始URL列表start_urls = ['http://example.com/']# 解析响应内容的回调函数def parse(self, response):pass# 简单打印一下响应内容# print(response.text)# 可以在这里使用提取器提取数据# 使用yield关键字yield Request生成其他请求- 调整settings配置文件
干掉日志的信息(想留下有用的内容), 只需要调整日志记录级别.
LOG_LEVEL = “WARNING”
demo/demo/settings.py# Scrapy项目的设置
#
# 为了简单起见,这个文件只包含了被认为重要或常用的设置。您可以在文档中找到更多设置:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'demo' # 机器人名称SPIDER_MODULES = ['demo.spiders'] # 爬虫模块位置
NEWSPIDER_MODULE = 'demo.spiders' # 新建爬虫的模块位置# 通过在User-Agent中标识自己(和自己的网站)来负责任地爬取
# USER_AGENT = 'demo (+http://www.yourdomain.com)'# 遵守robots.txt规则
ROBOTSTXT_OBEY = True# 配置Scrapy执行的最大并发请求数量(默认值: 16)(Scrapy默认是携程人物)
# CONCURRENT_REQUESTS = 32# 为相同网站的请求配置延迟(默认值: 0)建议打开调大
# 请参阅 https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# 还请参阅自动限速设置和文档
# DOWNLOAD_DELAY = 3# 下载延迟设置只会考虑以下之一:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16# 禁用Cookies(默认启用)
# COOKIES_ENABLED = False# 禁用Telnet控制台(默认启用)
# TELNETCONSOLE_ENABLED = False# 覆盖默认的请求头:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# }# 启用或禁用爬虫中间件
# 请参阅 https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'demo.middlewares.DemoSpiderMiddleware': 543,
# }# 启用或禁用下载器中间件
# 请参阅 https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'demo.middlewares.DemoDownloaderMiddleware': 543,
# }# 启用或禁用扩展
# 请参阅 https://docs.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }# 配置Item管道
# 请参阅 https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# ITEM_PIPELINES = {
# 'demo.pipelines.DemoPipeline': 300,
# }# 启用并配置自动限速扩展(默认禁用)
# 请参阅 https://docs.scrapy.org/en/latest/topics/autothrottle.html# 初始下载延迟
# AUTOTHROTTLE_START_DELAY = 5# 在高延迟情况下设置的最大下载延迟
# AUTOTHROTTLE_MAX_DELAY = 60# Scrapy应该并行发送到每个远程服务器的平均请求数
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0# 启用显示每个接收到的响应的限速统计信息:
# AUTOTHROTTLE_DEBUG = False# 启用并配置HTTP缓存(默认禁用)
# 请参阅 https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'- 运行scrapy程序
scrapy crawl 爬虫的名字
实例
创建
scrapy startproject xyx
cd xyx
scrapy genspider xiaoyx 4399.com
xyx/xyx/spiders/xiaoyx.py
import scrapyclass XiaoyxSpider(scrapy.Spider):name = 'xiaoyx' # 爬虫的名称allowed_domains = ['4399.com'] # 允许爬取的域名start_urls = ['http://www.4399.com/flash/'] # 初始爬取的URL地址def parse(self, response):# 使用 XPath 提取数据li_list = response.xpath("//ul[@class='n-game cf']/li") # 选择包含游戏信息的 li 元素列表for li in li_list:name = li.xpath("./a/b/text()").extract_first() # 提取游戏名称fenlei = li.xpath("./em/a/text()").extract_first() # 提取分类信息shijian = li.xpath("./em/text()").extract_first() # 提取时间信息# 使用 yield 返回提取的数据yield {"name": name, # 游戏名称"fenlei": fenlei, # 分类信息"shijian": shijian # 时间信息}
这段代码是一个使用 Scrapy 框架编写的网络爬虫,用于从 ‘http://www.4399.com/flash/’ 网站上提取游戏信息。以下是代码的详细解释:
-
import scrapy:导入 Scrapy 框架的模块。 -
class XiaoyxSpider(scrapy.Spider):定义了一个名为 ‘xiaoyx’ 的 Scrapy 爬虫类。 -
name = 'xiaoyx':指定了爬虫的名称。 -
allowed_domains = ['4399.com']:设置允许爬取的域名,确保只爬取指定域名下的页面。 -
start_urls = ['http://www.4399.com/flash/']:指定初始爬取的 URL 地址,爬虫将从这个地址开始运行。 -
def parse(self, response)::定义了处理响应的方法,Scrapy 会自动调用这个方法来处理从初始 URL 获取的响应。 -
li_list = response.xpath("//ul[@class='n-game cf']/li"):使用 XPath 选择器选取包含游戏信息的li元素列表。 -
在循环中,使用 XPath 从每个
li元素中提取游戏名称、分类信息和时间信息。 -
yield语句将提取的数据以字典形式返回,每个字典代表一个游戏信息。
这个爬虫的主要功能是从指定网页上提取游戏信息,并将这些信息以字典的形式输出。这只是爬虫项目的一部分,通常你还需要配置其他设置和数据处理管道来保存或进一步处理爬取到的数据。
yield和return
Scrapy引擎内部是一个不停在执行next()的循环。Scrapy的引擎是一个事件驱动的异步框架,其核心工作方式可以概括为事件循环。这个事件循环就是一个不断迭代的过程,它负责以下工作:
-
调度请求(Scheduling Requests):引擎从爬虫的起始URL开始,生成初始的请求并将它们放入请求队列中。
-
请求下载(Downloading Requests):下载器(Downloader)从请求队列中获取请求,并通过下载器中间件(Downloader Middleware)发送HTTP请求,然后等待响应。
-
处理响应(Handling Responses):一旦下载器获取到响应,引擎会将响应发送给爬虫中间件(Spider Middleware)和爬虫回调函数(Spider Callback)。这是爬虫代码实际处理和解析页面内容的地方。
-
生成新请求(Generating New Requests):在爬虫回调函数中,可以生成新的请求并将它们放入请求队列中,以便后续处理。
-
重复上述过程:引擎会不断循环执行上述步骤,直到请求队列中没有更多的请求,或者达到了预定的爬取深度或其他终止条件。
这种事件循环的方式使得Scrapy能够高效地爬取数据,并在异步操作下执行多个请求。通过生成器的方式,Scrapy能够实现非阻塞的爬取,即当一个请求等待响应时,引擎可以继续处理其他请求,而不必等待当前请求完成。
这个事件循环和异步操作是Scrapy的关键特性,它有助于高效地处理大量的HTTP请求并提高爬虫的性能。同时,Scrapy还提供了许多配置选项和中间件,使得用户可以灵活地控制和定制爬取过程。
在这个Scrapy爬虫中,使用yield而不是return的原因是因为Scrapy框架是异步的。当使用yield时,它允许你以生成器的方式产生数据并将其返回给Scrapy引擎,然后Scrapy引擎可以将数据逐个处理并传递给后续的管道(pipelines)进行处理、保存或者其他操作。这种异步方式对于爬取大量数据或需要耗费较长时间的请求非常有用,因为它不会阻塞爬虫的执行,而是在数据准备好时才进行处理。
相比之下,如果使用return,它将会立即返回数据并结束parse方法的执行。这可能导致爬虫不够高效,因为它会等待数据处理完成后才能继续执行下一个请求。这样可能会导致爬虫的性能下降,尤其在需要爬取大量页面或需要等待一些异步操作完成时。
总之,使用yield允许你以异步的方式处理数据,从而提高了爬虫的效率和性能。使用return则会阻塞爬虫,可能导致效率低下。因此,在Scrapy爬虫中通常建议使用yield来生成和返回数据。
xyx/xyx/pipelines.py
注意!若使用管道settings.py中的ITEM_PIPELINES 需要打开
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'xyx.pipelines.XyxPipeline': 300,
}
这是一个 Scrapy 数据处理管道(pipeline)的代码示例,用于处理从爬虫中提取的数据并将其保存到一个名为 “data.csv” 的 CSV 文件中。以下是代码的详细解释:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass XyxPipeline:def process_item(self, item, spider):print("我是管道,我看到的东西是", item)with open("data.csv", mode="a", encoding="utf-8") as f:f.write(f"{item['name']},{item['fenlei']},{item['shijian']}\n")return item
这个代码是一个自定义的Scrapy管道,主要功能是将爬虫提取的数据保存到名为 “data.csv” 的CSV文件中,并在控制台打印出数据。
解释如下:
-
class XyxPipeline::定义了一个名为XyxPipeline的管道类。 -
process_item(self, item, spider)::这个方法是Scrapy管道必须实现的方法,它会被自动调用来处理从爬虫中传递过来的数据。在这个例子中,它接受两个参数:item表示从爬虫传递过来的数据项,spider表示正在执行的爬虫实例。 -
print("我是管道,我看到的东西是", item):这行代码会在处理数据时在控制台打印出数据项,用于调试和查看数据。 -
with open("data.csv", mode="a", encoding="utf-8") as f::这是一个文件操作,它会打开一个名为 “data.csv” 的CSV文件,用于将数据写入。mode="a"表示以追加模式打开文件,确保不会覆盖之前的数据。 -
f.write(f"{item['name']},{item['fenlei']},{item['shijian']}\n"):这行代码将提取的数据按照CSV格式写入文件。 -
return item:最后,process_item方法返回item,表示数据处理完成。
要使用这个管道,你需要在Scrapy的设置中将它添加到 ITEM_PIPELINES 列表中,并配置合适的优先级。这样,当爬虫提取数据时,数据将被传递给该管道进行处理和保存。
Pipeline详解
在Scrapy的Pipeline中,数据项(item)是从爬虫传递到Pipeline的,而Pipeline的process_item方法接收两个参数:item和spider。下面重点说明这些参数的含义:
-
item:
item参数是一个包含了从爬虫中提取的数据的Python字典(或类似对象)。这个数据项包括了爬取到的各种字段和数据。在Pipeline的process_item方法中,你可以访问和处理这些字段,对数据进行清洗、验证、转换或存储等操作。例如:
def process_item(self, item, spider):name = item['name'] # 访问数据项的字段# 对数据进行处理# ...return item # 可选:返回处理后的数据项 -
spider:
spider参数代表当前正在执行的爬虫实例。虽然在大多数情况下,Pipeline中的数据处理不需要使用spider参数,但它可以提供关于当前爬虫状态和配置的信息,以便更加灵活地处理数据。
总结:Pipeline的process_item方法接收爬虫提取的数据项(item)作为参数,对这些数据进行处理后,可选择性地返回处理后的数据项。返回的数据项将传递给下一个Pipeline(如果有多个Pipeline)或者用于最终的存储和输出。Pipeline的作用是在爬虫和存储之间进行数据处理和转换。
运行
干掉日志的信息(想留下有用的内容), 只需要调整日志记录级别.
LOG_LEVEL = “WARNING”
scrapy crawl xiaoyx你也可以创建xyx/runner.py
# -*- coding = utf-8 -*-
"""
# @Time : 2023/9/16 22:55
# @Author : FriK_log_ff 374591069
# @File : runner.py
# @Software: PyCharm
# @Function: 请输入项目功能
"""
from scrapy.cmdline import executeif __name__ == "__main__":execute("scrapy crawl xiaoyx".split())
这段代码的作用是调用Scrapy命令行工具来运行名为 “xiaoyx” 的Scrapy爬虫。在执行之前,请确保你已经正确配置了Scrapy项目并且已经定义了名为 “xiaoyx” 的爬虫。
要运行此脚本,可以在命令行中执行它,确保你的工作目录位于包含Scrapy项目的根目录,并且已经安装了Scrapy。一旦执行,它将启动爬虫并开始抓取网页上的数据。
总结
Scrapy是一个强大的网络爬虫框架,适用于各种抓取数据的场景。通过理解其架构和工作流程,你可以更好地利用Scrapy来构建自己的爬虫项目。在本文中,我们介绍了Scrapy的基本概念,提供了安装步骤和示例爬虫代码,希望能够帮助你入门Scrapy,并在实际项目中应用这个强大的工具来获取所需的数据。在使用Scrapy时,记得遵循网站的规则和道德准则,以确保合法和道德的数据采集行为。
特别声明:
此教程为纯技术分享!本教程的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本教程的目的记录分享学习技术的过程
相关文章:
爬虫框架Scrapy学习笔记-2
前言 Scrapy是一个功能强大的Python爬虫框架,它被广泛用于抓取和处理互联网上的数据。本文将介绍Scrapy框架的架构概览、工作流程、安装步骤以及一个示例爬虫的详细说明,旨在帮助初学者了解如何使用Scrapy来构建和运行自己的网络爬虫。 爬虫框架Scrapy学…...
6.1 使用scikit-learn构建模型
6.1 使用scikit-learn构建模型 6.1.1 使用sklearn转换器处理数据6.1.2 将数据集划分为训练集和测试集6.1.3 使用sklearn转换器进行数据预处理与降维1、数据预处理2、PCA降维算法 代码 scikit-learn(简称sklearn)库整合了多种机器学习算法,可以…...
React 全栈体系(十一)
第五章 React 路由 五、向路由组件传递参数数据 1. 效果 2. 代码 - 传递 params 参数 2.1 Message /* src/pages/Home/Message/index.jsx */ import React, { Component } from "react"; import {Link, Route} from react-router-dom import Detail from ./Detai…...
AI 时代的向量数据库、关系型数据库与 Serverless 技术丨TiDB Hackathon 2023 随想
TiDB Hackathon 2023 刚刚结束,我仔细地审阅了所有的项目。 在并未强调项目必须使用人工智能(AI)相关技术的情况下,引人注目的项目几乎一致地都使用了 AI 来构建自己的应用。 大规模语言模型(LLM)的问世使得…...

Vue的路由使用,Node.js下载安装及环境配置教程 (超级详细)
前言: 今天我们来讲解关于Vue的路由使用,Node.js下载安装及环境配置教程 一,Vue的路由使用 首先我们Vue的路由使用,必须要导入官方的依赖的。 BootCDN - Bootstrap 中文网开源项目免费 CDN 加速服务https://www.bootcdn.cn/ <…...

vue修改node_modules打补丁步骤和注意事项
当我们使用 npm 上的第三方依赖包,如果发现 bug 时,怎么办呢? 想想我们在使用第三方依赖包时如果遇到了bug,通常解决的方式都是绕过这个问题,使用其他方式解决,较为麻烦。或者给作者提个issue,然…...

CSS 响应式设计:媒体查询
文章目录 媒体查询添加断点为移动端优先设计其他断点方向:横屏/竖屏 媒体查询 CSS中的媒体查询是一种用于根据不同设备的屏幕尺寸和分辨率来定义样式表的方法。在CSS中,我们可以使用媒体查询来根据不同的设备类型和屏幕尺寸来应用不同的样式,…...
Qt开发 - Qt基础类型
1.基础类型 因为Qt是一个C 框架, 因此C中所有的语法和数据类型在Qt中都是被支持的, 但是Qt中也定义了一些属于自己的数据类型, 下边给大家介绍一下这些基础的数类型。 QT基本数据类型定义在#include <QtGlobal> 中,QT基本数据类型有: 虽然在Qt中…...
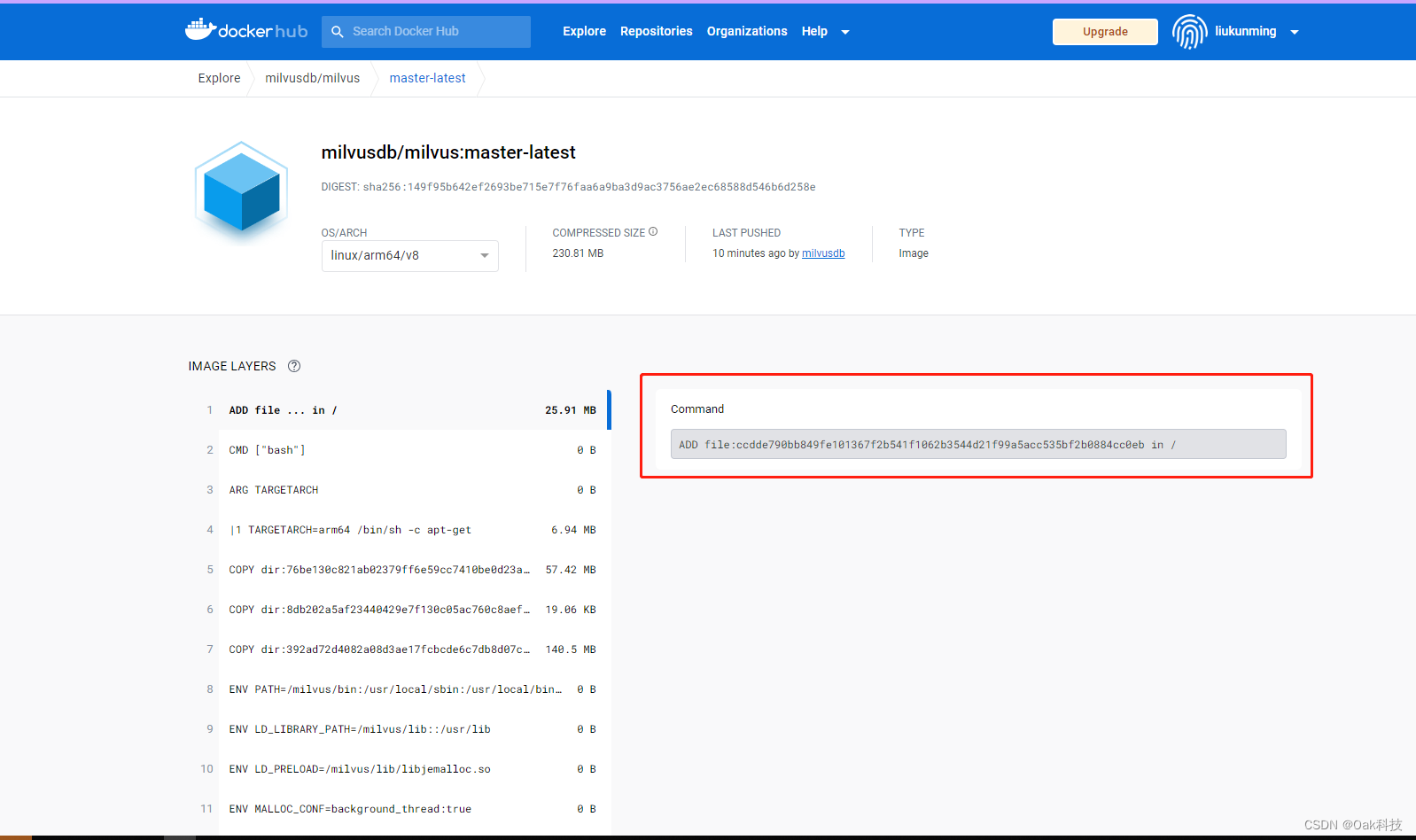
Docker-如何获取docker官网x86、ARM、AMD等不同架构下的镜像资源
文章目录 一、概要二、资源准备三、环境准备1、环境安装2、服务器设置代理3、注册docker账号4、配置docker源 四、查找资源1、服务器设置代理2、配置拉取账号3、查找对应的镜像4、查找不同版本镜像拉取 小结 一、概要 开发过程中经常会使用到一些开源的资源,比如经…...

Vuex状态管理最佳实践
文章目录 单一状态树使用模块使用常量定义Mutation类型使用Actions处理异步操作使用Getters计算属性严格模式分模块管理Getter、Mutation和Action:注释和文档:Vue Devtools ✍创作者:全栈弄潮儿 🏡 个人主页: 全栈弄潮…...

platform和led中断项目
设备树根节点下添加 myledIrqPlatform{compatible"hqyj,myledIrqPlatform";reg<0x22334455 59>;interrupt-parent<&gpiof>;interrupts<9 0>;led1-gpio<&gpioe 10 0>;//10表示使用的gpioe第几个管脚 0,表示gpio默认属性…...
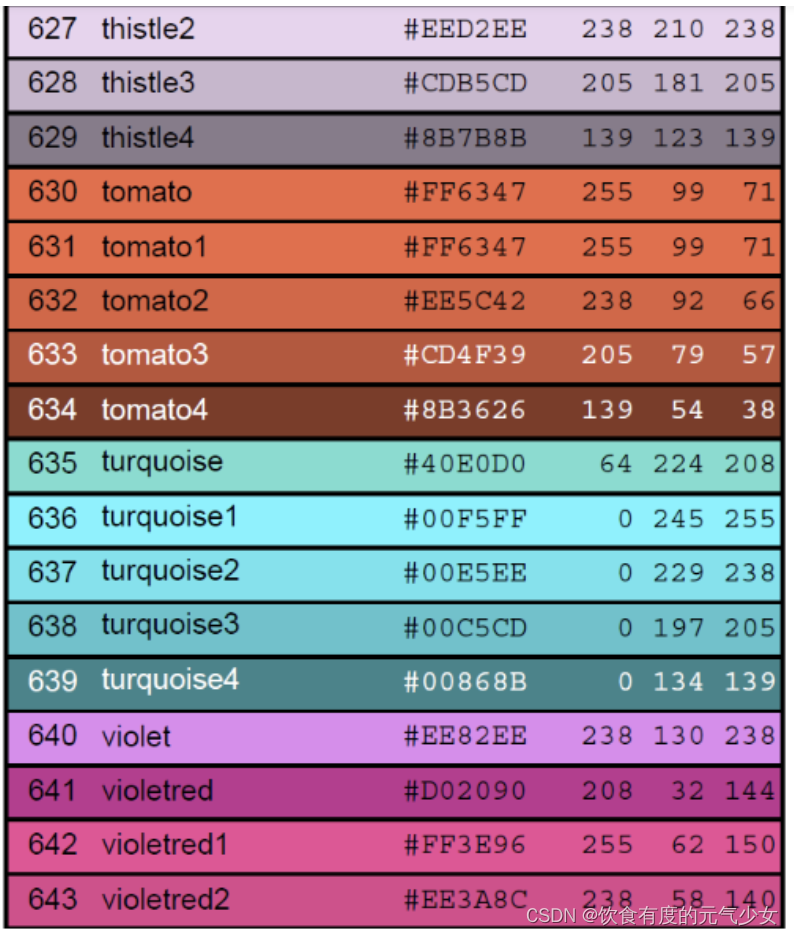
R语言-关于颜色
目录 颜色 示例 R 颜色板 参考: 颜色 什么场景会用到颜色?比如在绘图过程中,为了让图更好看,有的时候,需要选择使用不同的颜色进行绘制或者填充。本文提供了R颜色的相关参数。 在R中,可以通过颜色下标…...

抖音seo优化排名源码搭建
抖音seo优化排名技术开发源码搭建: 思路:看上去比较简单,貌似使用 get、set 这两个 trap 就可以,但实际上并不是。实际上还需要实现 has, ownKeys , getOwnPropertyDescriptor 这些 trap,这样就能最大限度的限制私有属…...
pytorch的卷积层池化层和非线性变化 和机器学习线性回归
卷积层: 两个输出的情况 就会有两个通道 可以改变通道数的 最简单的神经网络结构: nn.Mudule就是继承父类 super执行的是 先执行父类函数里面的 forward执行的就是前向网络,就是往前推进的,当然也有反向转播,那就是…...

Java手写快速选择算法应用拓展案例
Java手写快速选择算法应用拓展案例 1. 引言 快速选择算法是一种高效的选择算法,可以用于在数组中找到第K小/大的元素。除了基本的应用场景外,快速选择算法还可以应用于其他问题,如查找中位数、查找最大/最小值等。本文将介绍两个拓展应用案…...

js制作柱状图的x轴时间, 分别展示 月/周/日 的数据
背景 有个需求是要做一个柱状图, x 轴是时间, y 轴是数量. 其中 x 轴的时间有三种查看方式: 月份/周/日, 也就是分别查看从当前日期开始倒推的最近每月/每周/每日的数量. 本篇文章主要是用来制作三种不同的 x 轴 从当前月开始倒推月份 注意 getMonth() 函数可以获取当前月份…...

安防监控/视频汇聚/云存储/AI智能视频分析平台EasyCVR下级海康设备无法级联是什么原因?
安防视频监控平台/视频集中存储/云存储/磁盘阵列EasyCVR可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。 有用户反馈&…...

HttpUtils带连接池
准备祖传了,有问题欢迎大家指正。 HttpUtil import com.txlc.cloud.commons.exception.ServiceException; import com.txlc.dwh.common.constants.MyErrorCode; import org.ssssssss.script.annotation.Comment;import java.io.UnsupportedEncodingException; impo…...
智慧养殖:浅谈视频监控与AI智能识别技术助力奶牛高效、智慧养殖
一、方案背景 随着科技的飞速发展,智能化养殖逐渐成为现代畜牧业的发展趋势。人工智能技术、物联网、视频技术、云计算、大数据等新兴技术,正在为奶牛养殖业带来全新的变革。越来越多的牧场、养殖场开始运用新技术来进行智能监管、提高生产效率、降低生…...

一文总结提示工程框架,除了CoT还有ToT、GoT、AoT、SoT、PoT
夕小瑶科技说 原创 编译 | 谢年年 大语言模型LLM被视为一个巨大的知识库,它可以根据你提出问题或陈述的方式来提供答案。就像人类可能会根据问题的不同提供不同的答案一样,LLM也可以根据输入的不同给出不同的答案。因此,你的问题或陈述方式就…...

从零到一:DPDK高性能网络开发实战指南
1. 为什么你需要了解DPDK? 如果你正在开发需要处理高吞吐量网络数据的应用,比如视频流服务器、金融交易系统或者云计算平台,传统的Linux网络栈可能会成为性能瓶颈。我亲身经历过一个项目,用传统方式开发的网关每秒只能处理30万包…...
)
告别报错!保姆级教程:在PyCharm 2023.3上完美安装ManimCE(附国内镜像加速)
在PyCharm 2023.3中零失败安装ManimCE的终极指南 当数学可视化遇上Python,ManimCE无疑是当前最强大的工具之一。但对于许多开发者来说,从环境配置到成功运行第一个动画,这段旅程往往充满坎坷。本文将彻底解决安装过程中的所有痛点,…...

基于视觉大模型的桌面自动化:Screen Vision技能实现AI操控电脑
1. 项目概述:让AI成为你的“数字双手” 你有没有想过,有一天你可以像指挥一个真人助手一样,用自然语言告诉AI:“帮我把桌面上的那个PDF文件拖到‘已处理’文件夹里”,或者“打开浏览器,搜索一下今天北京的…...

终极指南:Windows上无需模拟器安装安卓应用的完整教程
终极指南:Windows上无需模拟器安装安卓应用的完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行安卓应用,但厌倦了…...

D3KeyHelper:5个技巧让暗黑破坏神3操作效率翻倍的智能宏工具完全指南
D3KeyHelper:5个技巧让暗黑破坏神3操作效率翻倍的智能宏工具完全指南 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破…...

浏览器扩展开发实战:KeepChatGPT会话保持原理与实现
1. 项目概述:一个浏览器扩展的诞生与使命 最近在和一些做AI应用开发的朋友交流时,大家普遍反映了一个痛点:在使用一些大型语言模型(LLM)的在线服务时,对话经常会被意外中断。这种中断可能源于网络波动、服…...
)
Perplexity×NEJM文献交叉验证协议(NIH资助项目内部文档首次公开:含4层可信度打分矩阵与人工校验SOP)
更多请点击: https://intelliparadigm.com 第一章:PerplexityNEJM文献交叉验证协议的起源与战略意义 PerplexityNEJM文献交叉验证协议并非传统意义上的软件接口规范,而是一种面向临床研究可信度增强的元认知对齐框架。其诞生源于2023年大型语…...

从夏普IGZO技术授权看显示面板产业的技术转移与战略博弈
1. 从一则旧闻看显示产业的全球棋局:技术、资本与生存的博弈2013年夏天,一则来自日本的消息在科技产业圈,特别是显示面板和半导体供应链领域,激起了不小的涟漪。全球知名的消费电子品牌夏普公司,宣布了一项与中国国有企…...

《心核驱动:基于本质定义的AI性格自进化架构》
前言:拒绝表面调参,直击AI性格本质当前市面上的AI性格定制,大多停留在“表层调参”阶段——试图通过调整温度、Top-p等概率参数来模拟情感,结果往往顾此失彼,要么机械生硬,要么逻辑崩塌。真正的智能性格&am…...

【限时开放】DeepSeek内部调试工具集首次对外披露:含Request ID全链路追踪、模型响应热力图与异常模式识别器
更多请点击: https://intelliparadigm.com 第一章:DeepSeek API接入开发教程 DeepSeek 提供了稳定、高性能的大模型 API 接口,支持文本生成、对话补全与函数调用等多种能力。接入前需在官方控制台申请 API Key,并确保账户已开通对…...