linux搭建单机ES,集成ik分词器,文本抽取,Kibana可视化平台
Elasticsearch单机(Linux)
准备工作
第一项:
创建运行Elasticsearch和Kibana专用的普通用户,因为 elasticsearch 和 kibana 不允许使用 root用户启动,所以需要创建新用户启动。
linux用root权限创建一个用户赋权即可,注意权限要给足
第二项(启动没有报相关错误此项可以不做调整):
设置linux的虚拟内存
vim /etc/sysctl.conf
修改参数(自定义,我这里是设置成1024*256这么大)
vm.max_map_count=262144
虚拟内存生效
sysctl -p
第三项(启动没有报相关错误此项可以不做调整):
修改linux系统句柄配置,通过以下命令
vim /etc/security/limits.conf
修改或添加配置(一定要放在# End of file之前)
nofile - 打开文件的最大数目
noproc - 进程的最大数目
soft 指的是当前系统生效的设置值
hard 表明系统中所能设定的最大值
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 65536
使配置生效
source /etc/security/limits.conf
开始部署
第一步:
下载地址:官网下载地址
我这里下载的是7.16.0版本(下面网盘自取)
链接: https://pan.baidu.com/s/1GT47H3gdiYI361eYD6l5EA?pwd=abb2 提取码: abb2
第二步:
将下载的包放到服务器上,使用解压命令解压
解压命令
tar -zxvf 需要解压的包路径
如果需要解压其他目录,用命令
tar -zxvf 需要解压的包路径 -C 目标路径
第三步:
在服务器上创建两个文件夹用于ES修改配置时使用
一个存放es的data,一个存放es的log
Path to directory where to store the data (separate multiple locations by comma)
存储数据的目录的路径(用逗号分隔多个位置)
path.data: esdata的路径
Path to log files:
日志文件路径:
path.logs: eslog的路径
第四步:
修改配置文件内容
配置文件在ES的解压目录下的config目录下的elasticsearch.yml文件,修改配置文件
#集群名称
cluster.name: es-app
#集群节点名称
node.name: node-1
#存储数据的路径
path.data: /usr/local/esdata
#日志文件路径
path.logs: /usr/local/eslog
#网络公开的IP地址(设置为0.0.0.0表示所有IP都可以访问)
network.host: 0.0.0.0
#http端口
http.port: 9200
#集群节点IP列表
discovery.seed_hosts: ["127.0.0.1"]
#集群节点名称列表
cluster.initial_master_nodes: ["node-1"]
第五步:
修改ES的JVM
该配置文件在解压目录下的config目录下的jvm.options文件,修改以下配置
-Xms1g
-Xmx1g
第六步:
配置ES的java环境
从ES7.0之后,ES就自带jdk了,因为项目的正式环境所用的java环境有可能不适用于ES的java环境变量,ES从6.0就支持JAVA11了,如果项目正式环境的java环境符合ES的java环境,此步骤可以略过。
在解压目录下有一个jdk目录,这里就是ES自带的java环境,我们需要在解压目录下的bin目录下的elasticsearch-env文件,修改JAVA_HOME为ES自带的java环境
# now set the path to java
if [ ! -z "$ES_JAVA_HOME" ]; thenJAVA="$ES_JAVA_HOME/bin/java"JAVA_TYPE="ES_JAVA_HOME"
elif [ ! -z "$JAVA_HOME" ]; then# fallback to JAVA_HOMEecho "warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME" >&2#JAVA="$JAVA_HOME/bin/java"#修改这一块********************************************JAVA="/usr/local/elasticsearch-7.16.0/jdk/bin/java"JAVA_TYPE="JAVA_HOME"#end*************************************************
else# use the bundled JDK (default)if [ "$(uname -s)" = "Darwin" ]; then# macOS has a different structureJAVA="$ES_HOME/jdk.app/Contents/Home/bin/java"elseJAVA="$ES_HOME/jdk/bin/java"fiJAVA_TYPE="bundled JDK"
fiif [ ! -x "$JAVA" ]; thenecho "could not find java in $JAVA_TYPE at $JAVA" >&2exit 1
fi
修改完保存即可
注意:如果修改了还会出现JAVA环境变量的问题,可以把这一段的所有有关java的路径全都修改了
第七步:
启动ES
在解压目录下的bin目录下执行下面命令(后台启动)
./elasticsearch -d
查看日志:在自己配置的ES的log目录下的logs目录下查看日志
验证是否启动成功(如访问不到,请先开放linux防火墙的端口)
浏览器访问地址:IP+端口
出现以下信息即为启动成功
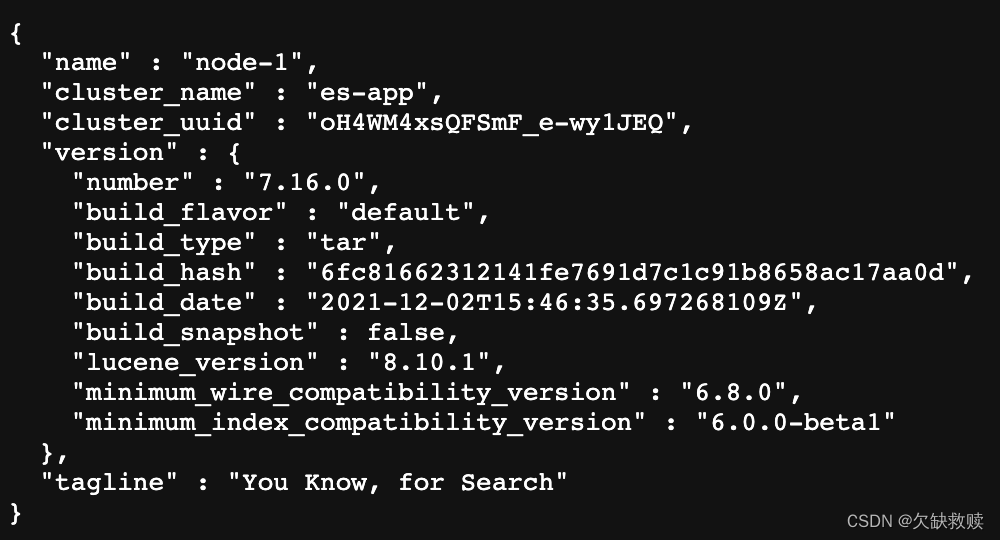
集成ik分词器
准备工作:
Elasticsearch部署成功
有maven环境可以使用mvn命令
在ES解压目录下的plugins目录下创建ik文件夹(mkdir ik)
第一步:
下载ik分词器,这里也准备了配套的ik分词器zip包,用的7.16.2版本,解压后与ES的版本一致,下面网盘自取
链接: https://pan.baidu.com/s/1ZISaAqK476DNl0RG8RPaqA?pwd=qr4f 提取码: qr4f
第二步:
把下载好的ik分词器zip包放到服务器上,方便操作可以放在在ES解压目录下的plugins目录下,通过下面命令解压
unzip ik分词器的zip包
第二步:
进入到解压后的ik分词器的目录中,执行下面命令打包
mvn clean install
第三步:
打包成功后可以在ik分词器解压目录下看到target目录,找到releases目录下的zip,移动到提前在ES解压目录下的plugins目录下创建好的ik目录下,我这里通过mv命令移动
mv releases目录下的zip 目标目录路径
第四步:
在ES解压目录下的plugins目录下的ik目录下解压刚才移动过来的zip包(使用unzip命令解压),解压后会看到如下图所示
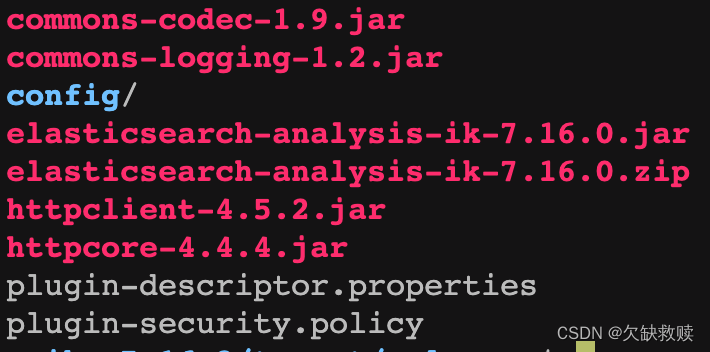
把这里面的zip包删除,最后ik目录下的文件就下图所示即可
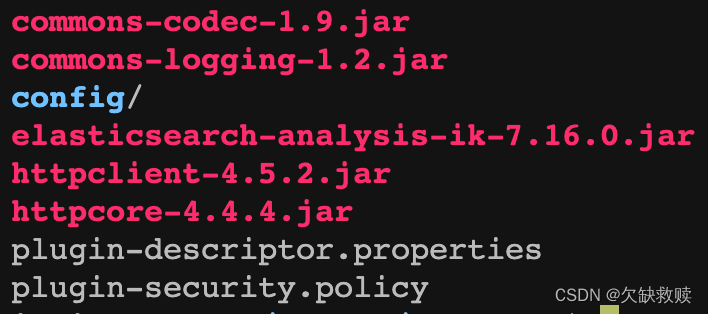
最后把与ik目录同级的ik分词器的zip包及其解压后的包删除
第五步:
重新启动ES,查看ik分词器插件是否集成成功
查看ES进程命令
ps -ef|grep elasticsearch
ES启动后会有两个进程,通过PPID的进程号kill掉就能停止ES
ES停止后在解压目录下的bin目录下执行下面命令重启ES(后台启动)
./elasticsearch -d
第六步:
检查插件是否安装,在ES解压目录下的bin目录下执行下面命令
./elasticsearch-plugin list
执行命令后出现以下内容即为ik分词器集成成功

文本抽取
准备工作
Elasticsearch部署成功
文本抽取是为了抽取上传的文件里面的内容,类似于文件内容的识别,可抽取word、excel、txt,pdf文件的内容,用于ES查询的时候可以对文件内容做模糊匹配查询
在ES解压目录下的bin目录下执行下面命令进行文本抽取插件的安装
elasticsearch-plugin install ingest-attachment
安装后同ik分词器一样需要重启ES以及通过插件查询命令查看是否集成成功
Kibana可视化平台(Linux)
准备工作:
Elasticsearch部署成功
第一步:
下载地址:官方下载地址
我这里下载的是7.16.0版本(下面网盘自取)
链接: https://pan.baidu.com/s/19N0RNifc0fxj7eoUUZQEKA?pwd=mmxt 提取码: mmxt
第二步:
将下载的包放到ES解压目录下并进行解压,解压命令参考ES部署的第二步
第三步:
修改Kibana配置
在Kibana的解压目录下的config目录下的kibana.yml文件,修改配置文件
#Kibana提供服务的端口
server.port: 5601
#指定Kibana服务器将绑定到的地址,设置为0.0.0.0表示所有IP都可以访问
server.host: "0.0.0.0"
#用于所有查询的Elasticsearch实例的url
elasticsearch.hosts: ["http://127.0.0.1:9200"]
#设置语言:英文 en,默认为中文 zh-CN。
i18n.locale: "zh-CN"
第四步:
启动Kibanaq启动命令如下:
nohup ./kibana &
查找Kibana进程的命令:
ps -ef|grep node
有 node 不一定就是 kibana 的进程。kibana 对外的 tcp 端口是 5601,如果改了自行调整命令,所以可以进一步使用如下命令查到进程号
netstat -tunlp|grep 5601
关闭命令,通过kill -9 杀死即可
第五步:
访问Kibana,通过IP+Kibana端口进行访问,如果访问不了,先查看下linux防火墙有没有开放端口
相关文章:
linux搭建单机ES,集成ik分词器,文本抽取,Kibana可视化平台
Elasticsearch单机(Linux) 准备工作 第一项: 创建运行Elasticsearch和Kibana专用的普通用户,因为 elasticsearch 和 kibana 不允许使用 root用户启动,所以需要创建新用户启动。 linux用root权限创建一个用户赋权即可…...
金融和大模型的“两层皮”问题
几年前,我采访一位产业专家,他提到了一个高科技到产业落地的主要困惑:两层皮。 一些特别牛的技术成果在论文上发表了,这是一层皮。企业的技术人员,将这些成果产品化、商品化的时候,可能出于工程化的原因&am…...

智能生活从这里开始:数字孪生驱动的社区
数字孪生技术,这个近年来备受瞩目的名词,正迅速渗透到社区发展领域,改变着我们居住的方式、管理的方式以及与周围环境互动的方式。它不仅仅是一种概念,更是一种变革,下面我们将探讨数字孪生技术如何推动社区智能化发展…...

Python计算机二级知识点整理
1.当一个进程在运行过程中释放了系统资源后要调用 唤醒进程原语 唤醒进程原语是把进程从等待队列里移出到就绪队列并设置进程为就绪状态,当一个进程在运行过程中释放了系统资源后进入就绪状态,调用唤醒进程原语。 2. 3. 4.在希尔排序法中&#x…...

双系统ubuntu20.04(neotic版本)从0实现Gazebo仿真slam建图
双系统ubuntu20.04(neotic版本)从0实现Gazebo仿真slam建图 昨晚完成了ROS的多机通讯,还没来得及整理相关操作步骤,在进行实际小车的实验之前,还是先打算在仿真环境中进行测试,熟悉相关的操作步骤,计划通过虚拟机&…...

(JavaEE)(多线程案例)线程池 (简单介绍了工厂模式)(含经典面试题ThreadPoolExector构造方法)
线程诞生的意义,是因为进程的创建/销毁,太重了(比较慢),虽然和进程比,线程更快了,但是如果进一步提高线程创建销毁的频率,线程的开销就不能忽视了。 这时候我们就要找一些其他的办法…...

单播与多播mac地址
MAC 地址(Media Access Control Address)是一个用于识别网络设备的唯一标识符。每个网络设备都有一个独特的 MAC 地址,用于在局域网中进行通信。 单播MAC地址:单播MAC地址用于单播通信,即一对一的通信模式。当设备发送…...
反向动力学Ik学习
参考文章:(非本人原创) 英文原文:Inverse Kinematics Techniques in Computer Graphics: A Survey (andreasaristidou.com) 知乎翻译文章: 【游戏开发】逆向运动学(IK)详解 - 知乎 (zhihu.co…...

基于Levenberg-Marquardt算法的声源定位matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 .................................................................... %ML if (bML1)varxs…...

vscode的Emmet语法失效
解决方案:设置 -> 搜索Emmet -> 勾选 Emmet:Trigger Expansion On Tab和Emmet: Use Inline Completions -> 重启 注:Emmet语法是vscode自带的语法,可以快速生成HTML结构/CSS样式/格式化语法 Emmet语法 参考:关于vscode使…...

堆排序(大根堆)
堆的定义如下,n个关键字序列[1...n]称为堆,当且仅当满足: a(i)>a(2i)且a(i)>a(2i1) 这个为大根堆 a(i)<a(2i)且a(i)<a(2i 1) 这个为小根堆 通过建堆得到大根堆 大根堆 87,45,78,32,17,65,53,9 可以看成 …...
Mybatis学习笔记3 在Web中应用Mybatis
Mybatis学习笔记2 增删改查及核心配置文件详解_biubiubiu0706的博客-CSDN博客 技术栈:HTMLServletMybatis 学习目标: 掌握mybatis在web应用中如何使用 Mybatis三大对对象的作用域和生命周期 关于Mybatis中三大对象的作用域和生命周期、 官网说明 ThreadLocal原理及使用 巩…...

软件测试之功能测试详解
一、功能测试概述 1)功能测试就是对产品的各功能进行验证,根据功能测试用例,逐项测试,检查产品是否达到用户要求的功能。 2)功能测试,根据产品特性、操作描述和用户方案,测试一个产品的特性和…...

javascript选取元素的范围,可以包含父级,也可以不包含父级
//函数可以选取元素的范围,对于要选取文本的非常方便,或选取特定的子节点 function getRange(element){//判断是否支持range范围选取var supdocument.implementation.hasFeature("Range","2.0");var also(typeof document.createRan…...

QGIS怎么修改源代码?持续更新...
修改配置文件保存位置 修改目的:放着和本地安装的其他QGIS共用一份配置文件 修改文件:core/qgsuserprofilemanager.cpp 修改位置:第37行 return basePath QDir::separator() "my_profiles";修改完毕后,再次生成一下…...
dev board sig技术文章:轻量系统适配ARM架构芯片平台
摘要:本文简单介绍OpenHarmony轻量系统移植,会分多篇 适合群体:想自己动手移植OpenHarmony轻量系统的朋友 开始尝试讲解一下系统的移植,主要是轻量系统,也可能会顺便讲下L1移植。 1.1移植类型 OpenHarmony轻量系统的…...

MyBatis之增删查改功能
文章目录 一、创建各种类二、MyBatis的各种功能 1、查询<select>2、增加<insert>3、修改<update>4、删除<delete>三、总结 前言 在MyBatis项目中编写代码实现对MySql数据库的增删查改 一、创建各种类 1、在Java包的mapper文件下创建一个接口 我创建…...

Leetcode算法入门与数组丨5. 数组二分查找
文章目录 1 二分查找算法2 二分查找细节3 二分查找两种思路3.1 直接法3.2 排除法 1 二分查找算法 二分查找算法是一种常用的查找算法,也被称为折半查找算法。它适用于有序数组的查找,并通过将待查找区间不断缩小一半的方式来快速定位目标值。 算法思想…...
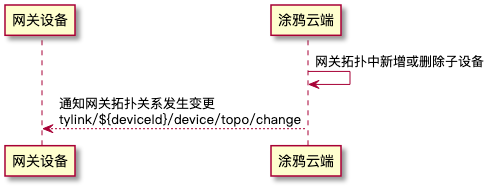
拓扑关系如何管理?
在设备对接涂鸦的云端过程中,一部分设备由于自身资源或硬件配置,无法直接连接云端。而是需要通过网关进行中转,由网关代理实现和云端进行数据交互,间接实现设备接入云端。这样的设备也称为子设备。 要想实现网关代理子设备接入云…...

vue的由来、vue教程和M-V-VM架构思想、vue的使用、nodejs
vue vue的由来 vue教程和M-V-VM架构思想 vue的初步简单使用 nodejs vue的由来 # 1 HTML(5)、CSS(3)、JavaScript(ES5、ES6、ES11):编写一个个的页面 -> 给后端(PHP、Python、Go、Java) -> 后端嵌入模板语法 -> 后端渲染完数据 -> 返回数据给前端 ->…...

告别AT指令!用nRF52832的BLE NUS服务,5分钟搞定手机与开发板的双向通信
用nRF52832的BLE NUS服务实现高效蓝牙串口通信 在嵌入式开发中,设备与移动端的双向通信一直是个痛点。传统AT指令虽然简单,但效率低下、扩展性差,每次通信都需要复杂的握手流程。而基于nRF52832的BLE NUS(Nordic UART Service&…...

Odoo开源频道应用:构建企业级内容管理系统的完整指南
1. 项目概述:一个为Odoo生态注入活力的开源频道应用如果你是一名Odoo开发者或实施顾问,肯定遇到过这样的场景:客户需要一个功能强大、界面现代的“新闻”或“博客”模块,但Odoo原生的“网站博客”应用要么功能过于基础,…...

CodeContext:基于MCP协议与AI模式检测,让AI编程助手深度适配你的代码库
1. 项目概述:让AI助手真正“懂”你的代码库如果你和我一样,每天都在用Cursor或者GitHub Copilot这类AI编程助手,那你肯定也经历过这种时刻:AI给你生成了一段看起来功能正确的代码,但它的错误处理方式、导入风格、命名习…...

智能体集成德国铁路实时信息:无需API的Node.js工具箱openclaw-bahn详解
1. 项目概述:一个为智能体打造的德国铁路工具箱如果你经常在德国乘坐火车,或者像我一样,需要为一些自动化流程(比如智能体)集成实时交通信息,那么你肯定对德国铁路(Deutsche Bahn, DB࿰…...

从零搭建ROS Gazebo仿真小车:集成摄像头与YOLO目标检测实现视觉感知
1. 环境准备与ROS安装 在开始构建仿真小车之前,我们需要先搭建好开发环境。ROS(Robot Operating System)是目前机器人开发最流行的框架之一,它提供了硬件抽象、设备驱动、库函数、可视化工具等丰富功能。我推荐使用Ubuntu 20.04 L…...

React Native Expo样板项目:集成导航、状态管理与样式的最佳实践
1. 项目概述:一个为React Native开发者准备的“开箱即用”脚手架 如果你是一名React Native开发者,或者正打算踏入这个领域,那么你一定对项目启动初期那些繁琐的配置工作深有体会。从搭建开发环境、配置路由、集成状态管理,到设置…...

Nitric本地开发环境搭建:快速测试和调试的完整流程
Nitric本地开发环境搭建:快速测试和调试的完整流程 【免费下载链接】nitric Nitric is a multi-language framework for cloud applications with infrastructure from code. 项目地址: https://gitcode.com/gh_mirrors/ni/nitric Nitric是一个多语言框架&am…...
)
别再对着乱码发愁了!手把手教你用Python解码AIS VDM暗码(附完整代码)
从AIS暗码到可读数据:Python实战解析指南 当你第一次看到类似!AIVDM,1,1,,A,169DvlgP1R8KPtvFBfOCt3?h0RT,0*03这样的字符串时,可能会感到一头雾水。这串看似随机的字符实际上是AIS(船舶自动识别系统)传输的VDM(VHF Data-link Message)报文,…...

Unity游戏任务系统框架解析:数据驱动与事件架构实战
1. 项目概述:一个为游戏开发者准备的灵活任务系统如果你正在开发一款RPG、开放世界或者任何需要任务驱动的游戏,那么“任务系统”绝对是你绕不开的核心模块。最近我在GitHub上发现了一个名为shomykohai/quest-system的开源项目,它不是一个完整…...

Crush性能优化指南:如何利用半懒惰流处理大数据集
Crush性能优化指南:如何利用半懒惰流处理大数据集 【免费下载链接】crush Crush is a command line shell that is also a powerful modern programming language. 项目地址: https://gitcode.com/gh_mirrors/cr/crush Crush是一个革命性的命令行shell和现代…...