scrapy框架--
Scrapy是一个用于爬取数据的Python框架。下面是Scrapy框架的基本操作步骤:
-
安装Scrapy:首先,确保你已经安装好了Python和pip。然后,在命令行中运行以下命令安装Scrapy:
pip install scrapy -
创建Scrapy项目:使用Scrapy提供的命令行工具创建一个新的Scrapy项目。在命令行中切换到你想要创建项目的目录,并执行以下命令:
scrapy startproject project_name。其中,project_name是你自己定义的项目名称。 -
定义爬虫:进入项目目录,并在命令行中执行以下命令创建一个新的爬虫:
scrapy genspider spider_name website.com。其中,spider_name是你自己定义的爬虫名称,website.com是你要爬取数据的目标网站的域名。 -
编写爬虫代码:在项目目录下的
spiders文件夹中找到你创建的爬虫文件(以.py结尾),使用文本编辑器打开该文件。在爬虫代码中,你可以定义如何发送请求、处理响应和提取数据等操作。你可以参考Scrapy官方文档来了解更多关于编写爬虫代码的详细信息。 -
配置爬虫:如果需要,你可以在项目目录下的
settings.py文件中配置爬虫的相关设置,例如设置请求头、设置User-Agent等。 -
启动爬虫:在命令行中进入项目目录,并执行以下命令启动爬虫:
scrapy crawl spider_name。其中,spider_name是你之前定义的爬虫名称。 -
处理爬虫数据:爬虫运行后,它会自动访问目标网站,并根据你定义的规则提取数据。你可以在爬虫代码中定义如何处理这些数据,例如保存到文件、存储到数据库
import scrapyclass ItcastSpider(scrapy.Spider):name = "itcast"allowed_domains = ["itcast.cn"]# 修改起始urlstart_urls = ["https://www.itcast.cn/channel/teacher.shtml#ajavaee"]# 在这个方法中实现爬取逻辑def parse(self, response):# 定义对于网站的相关操作# with open('itcast.html','wb') as f:# f.write(response.body)
#/html/body/div[1]/div[6]/div/div[2]/div[6]/div/div[2]/div[1]/ul/li/div
# /html/body/div[1]/div[6]/div/div[2]/div[6]/div/div[2]/div[2]/ul/li[1]/div# 获取所有教师节点node_list=response.xpath('/html/body/div[1]/div[6]/div/div[2]/div[6]/div/div[2]/div/ul/li/div')print(len(node_list))# 遍历for node in node_list:temp={}## xpath 方法之后返回是选择器对象列表,,,extract()从选择器中提取数据temp['name']=node.xpath('./h3/text()').extract_first()temp['title'] = node.xpath('./h4/text()')[0].extract()temp['desc'] = node.xpath('./p/text()')[0].extract()# print(temp)# {'name': [<Selector query='./h3/text()' data='杨老师'>], 'title': [<Selector query='./h4/text()' data='高级讲师'>], 'desc': [<Selector query='./h3/text()' data='杨老师'>]}yield temp
response的用法
-
获取响应内容:可以使用
response.body属性获取响应的原始内容,通常以字节形式表示。如果需要获取解码后的文本内容,可以使用response.text属性。 -
获取响应头:可以使用
response.headers属性获取响应头信息。它返回一个Headers对象,你可以通过调用其方法或属性来获取特定的头信息,例如response.headers.get('Content-Type')获取Content-Type头的值。 -
获取状态码:可以使用
response.status属性获取响应的状态码。 -
提取数据:可以使用XPath表达式或CSS选择器从响应中提取感兴趣的数据。Scrapy提供了
response.xpath()和response.css()方法,你可以传入相应的表达式或选择器来提取数据。例如,response.xpath('//title/text()').get()可以获取网页中的标题文本。 -
提取链接:可以使用
response.follow()方法跟踪和提取链接。你可以将一个链接作为参数传递给该方法,Scrapy将会发送一个新的请求并返回一个新的response对象。
相关文章:

scrapy框架--
Scrapy是一个用于爬取数据的Python框架。下面是Scrapy框架的基本操作步骤: 安装Scrapy:首先,确保你已经安装好了Python和pip。然后,在命令行中运行以下命令安装Scrapy:pip install scrapy 创建Scrapy项目:…...

算法通关村第十五关——从40亿个数中产生一个不存在的数的处理方法
1.从40个亿中产生一个不存在的整数 题目要求:给定一个输入文件,包含40亿个非负整数,请设计一个算法,产生一个不存在该文件中的整数,假设你有1GB的内存来完成这项任务。**** 解题中心思想:存储的不是这40亿…...

软件项目开发的流程及关键点
软件项目开发的流程及关键点 graph LR A[需求分析] --> B[系统设计] B --> C[编码开发] C --> D[测试验证] D --> E[部署上线] E --> F[运维支持]在项目开发的流程中,首先是进行需求分析,明确项目的目标和功能要求。接下来是系统设计&am…...
)
全球变暖问题(floodfill 处理联通块问题)
全球变暖问题 文章目录 全球变暖问题前言题目描述题目分析边界问题的考虑岛屿是否被淹没判断:如何寻找联通块: 代码预告 前言 之前我们介绍了 bfs算法在二维,三维地图中的应用,现在我们接续进行拓展,解锁floodfill 算…...

由于找不到vcruntime140_1.dll怎么修复,详细修复步骤分享
在使用电脑过程中,可能会遇到一些错误提示,其中之一是找不到vcruntime140_1.dll的问题。这使得许多用户感到困扰,不知道该如何解决这个问题。小编将详细介绍vcruntime140_1.dll的作用以及解决找不到该文件的方法,帮助你摆脱困境。…...
)
算法 三数之和-(双指针)
牛客网: BM54 题目: 数组中所有不重复的满足三数之和等于0的数,非递减形式。 思路: 数组不小于3。不重复非递减,需先排序。使用idx从0开始遍历到n-2, 如果出现num[idx]num[idx-1]的情况,忽略继续下一个idx;令left idx1, right …...
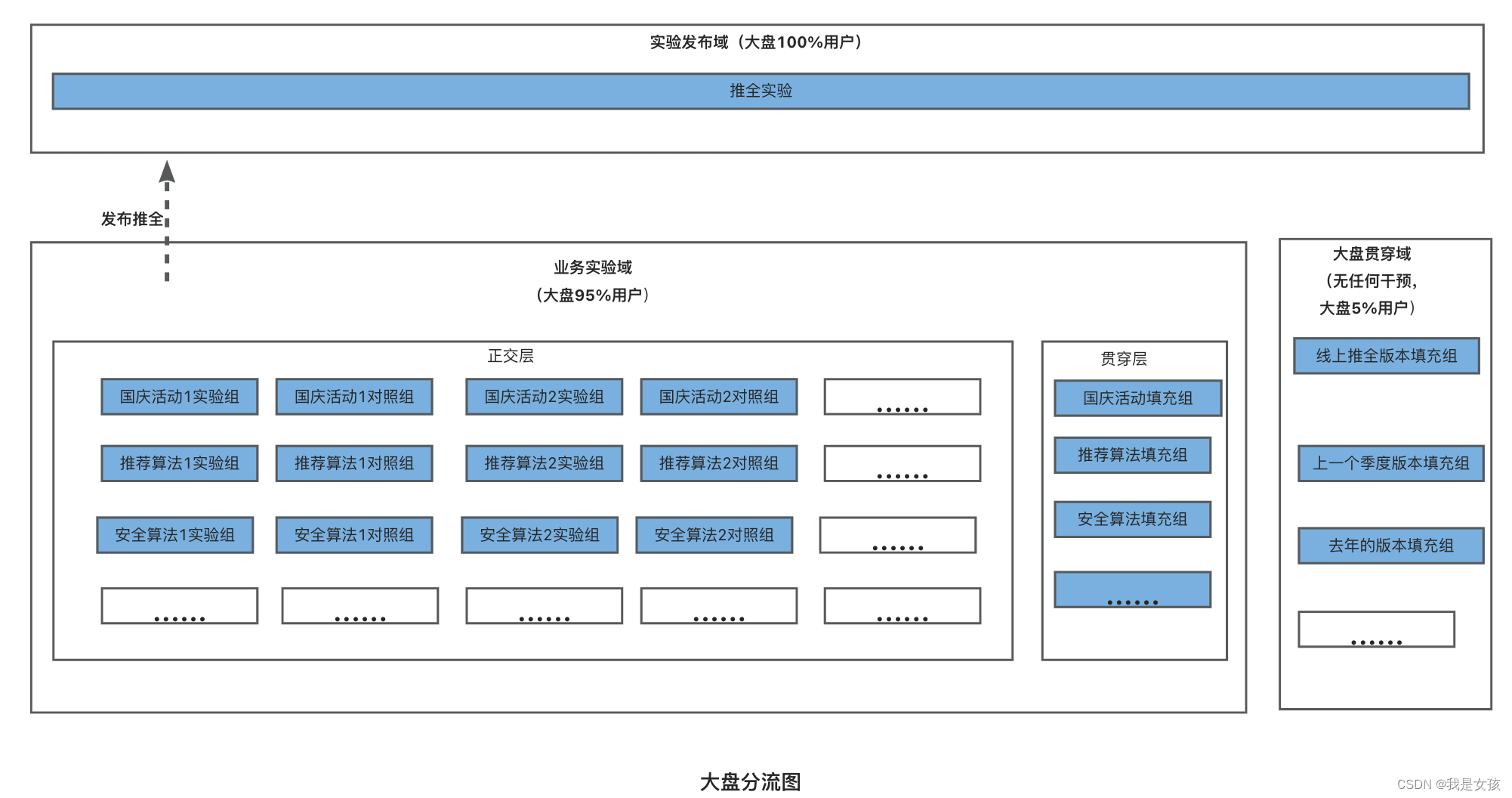
AB实验总结
互联网有线上系统,可做严格的AB实验。传统行业很多是不能做AB实验的。 匹配侧是采用严格的AB实验来进行模型迭代,而精细化定价是不能通过AB实验来评估模型好坏,经历过合成控制法、双重差分法,目前采用双重差分法来进行效果评估。…...

sklearn包中对于分类问题,如何计算accuracy和roc_auc_score?
1. 基础条件 import numpy as np from sklearn import metricsy_true np.array([1, 7, 4, 6, 3]) y_prediction np.array([3, 7, 4, 6, 3])2. accuracy_score计算 acc metrics.accuracy_score(y_true, y_prediction)这个没问题 3. roc_auc_score计算 The binary and mul…...

python温度转换程序
1.使用pycharm运行温度转换程序,尝试将温度单位设在前面 2.参照温度转换程序,自己写一个关于货币转换、长度转换、重量转换或者面积转换的程序 循环函数 def convertemperature():temperature ""while (temperature ! "q"):temperature in…...

Vue2中10种组件通信方式和实践技巧
目录 1,props / $emit1.1,一个需求方法1方法2 1.2,v-model 和 .syncv-model.sync 2,$children / $parent3,ref4,$attrs / $listeners$attrs$listenersinheritAttrs1.1 的问题的第3种解决方法 5,…...
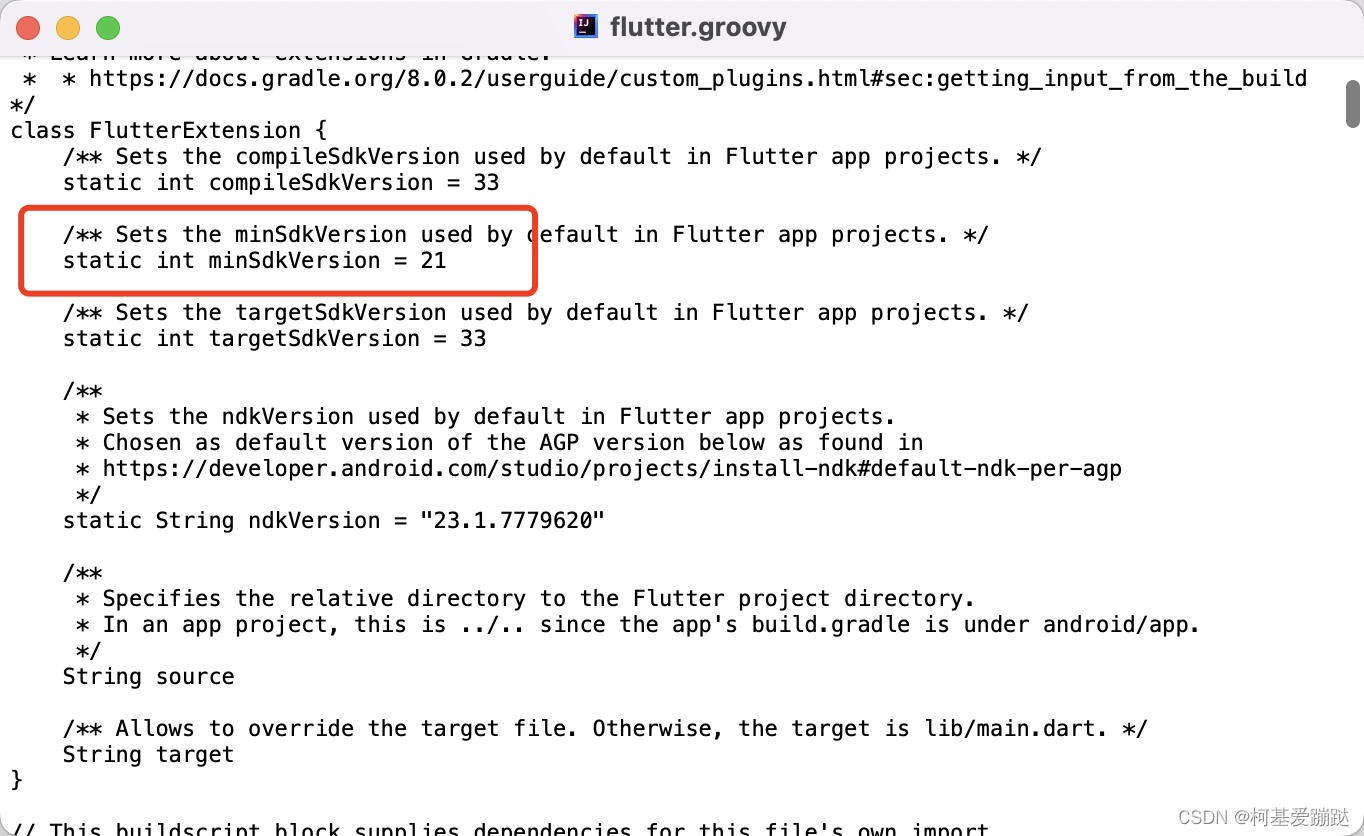
Flutter flutter.minSdkVersion的实际文件位置
Flutter 项目的Android相关版本号配置: flutter.minSdkVersion 的版本号配置文件实际路径: …/flutter_sdk/packages/flutter_tools/gradle/src/main/groovy/flutter.groovy Flutter版本号如下: bzbMacBook-Pro ccsmec % flutter --version …...
python生成PDF报告
前言 最近接到了一个需求-将项目下的样本信息汇总并以PDF的形式展示出来,第一次接到这种PDF的操作的功能,还是有点慌的,还好找到了reportlab这个包,可以定制化向PDF写内容! 让我们由简入深进行讲解 一、reportlab是…...
在visual studio里安装Python并创建python工程
在2009年,云计算开始发力,Python、R、Go这些天然处理批量计算的语言也迅猛发展。微软在2010年,把Python当成一个语言包插件,集成到了visual studio 2010里。在"云优先,移动优先"的战略下,于2015年…...
试用 6 -- 从简单到复杂)
AIGC(生成式AI)试用 6 -- 从简单到复杂
从简单到复杂,这样的一个用例该如何设计? 之前浅尝试用,每次尝试也都是由浅至深、由简单到复杂。 一点点的“喂”给生成式AI主题,以测试和验证生成式AI的反馈。 AIGC(生成式AI)试用 1 -- 基本文本_Role…...
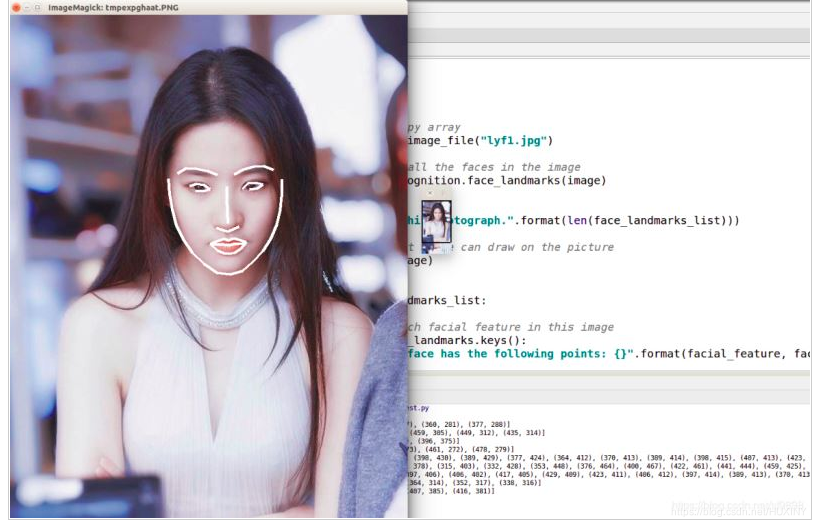
竞赛 基于深度学习的人脸识别系统
前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的人脸识别系统 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/…...

uniapp:APP开发,后台保活
前言: 在ios中,软件切换至后台、手机息屏,过了十来秒软件就会被系统挂起,APP内的任务就不能继续执行;在android中,默认情况下,软件在后台运行的时候,触发某些特定条件的情况下&…...
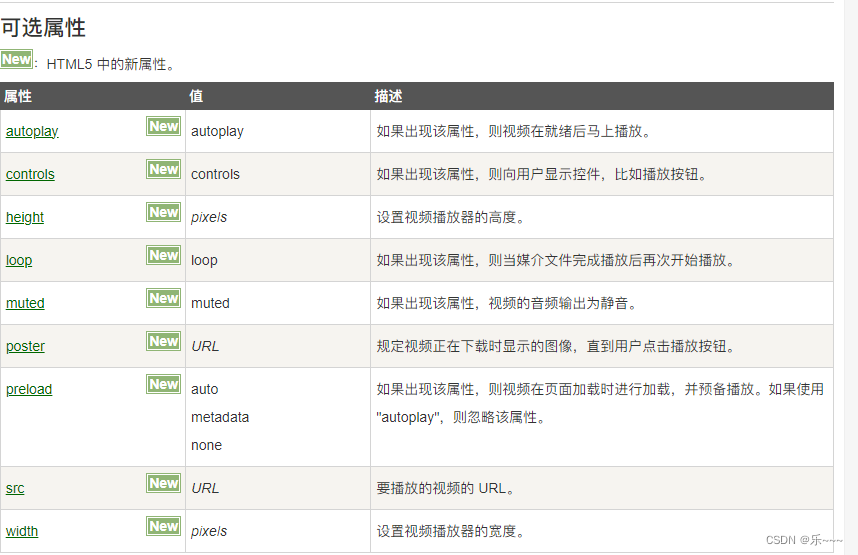
vue2 项目中嵌入视频
案例: 代码: <template><div class"schematicDiagramIndex"><el-container><el-aside width"20rem"> <!-- <h4 style"font-size: 18px">视频演示</h4>--><div styl…...

第二章 进程与线程 十二、进程同步与进程互斥
目录 一、进程同步 1、定义 二、进程互斥 1、定义 2、四个部分 3、原则 一、进程同步 1、定义 进程同步是指在多个进程之间协调执行顺序的一种机制,使得进程按照一定的顺序执行,以避免出现不一致的情况。常见的实现方式有信号量、管程、屏障等。…...
移植到任意平台)
Linux内核链表(list)移植到任意平台
一、前言 linux内核链表在include/linux/list.h文件中,内核中实现的链表比较简洁,实用性很强,因此想把它单独移植出来使用。 内核中的代码只能使用gnuc编译器编译,stdc编译器编译是会报错的,主要是因为typeof这个宏是…...

【操作系统】聊聊什么是CPU上下文切换
对于linux来说,本身就是一个多任务运行的操作系统,运行远大于CPU核心数的程序,从用户视角来看是并发执行,而在CPU视角看其实是将不同的CPU时间片进行分割,每个程序执行一下,就切换到别的程序执行。那么这个…...

5分钟实现电脑风扇智能控制:FanControl.HWInfo终极指南
5分钟实现电脑风扇智能控制:FanControl.HWInfo终极指南 【免费下载链接】FanControl.HWInfo FanControl plugin to import HWInfo sensors. 项目地址: https://gitcode.com/gh_mirrors/fa/FanControl.HWInfo 想要告别电脑风扇的噪音困扰吗?FanCon…...

自动化营销系统:高效破解市场-SDR销售线索流转堵点
在B2B营销中,线索从“获取”到“转化”的过程,往往伴随着大量的手动操作、信息断层和跟进滞后。尤其是市场团队与SDR(销售开发代表)之间的协作,常常成为线索流转的“瓶颈”。如何高效、规范地将市场获取的Leads转化为可…...
)
别再傻傻在线等了!手把手教你用命令行精准定制VS2022离线安装包(附.NET/C++/MFC组件命令)
精准定制VS2022离线安装包:命令行高效配置指南 在开发团队协作或特殊网络环境下,Visual Studio 2022的离线安装成为刚需。但直接下载完整离线包不仅耗时(超过25GB),还会占用大量存储空间——而实际上,90%的…...

Python包安装全攻略:从pip、conda到离线安装,总有一种方法适合你
Python包安装全攻略:从pip、conda到离线安装,总有一种方法适合你 在Python开发中,依赖管理是每个开发者必须掌握的核心技能。无论是数据科学家搭建机器学习环境,还是Web开发者部署Django应用,都离不开Python包的安装与…...
 的剪辑软件合集来啦)
实测好用、真正免费(无水印/无强制付费) 的剪辑软件合集来啦
剪辑小白看过来!2026年实测好用、真正免费(无水印/无强制付费) 的剪辑软件合集来啦!????不管你是学生党、自媒体新人,还是电脑配置不高,这篇笔记帮你按设备(手机/电脑/网页) 精准…...

基于MCP协议的Shopify数据AI分析:自动化广告优化实战指南
1. 项目概述:用AI打通Shopify数据与广告投放的任督二脉 如果你在运营一个Shopify独立站,并且正在为Google、Meta(Facebook/Instagram)或TikTok广告投放而头疼,那么你很可能正经历着所有电商卖家的共同困境:…...

BetterOCR:融合多引擎OCR与LLM的智能文档理解方案
1. 项目概述:当OCR遇上AI,一场关于“理解”的进化 最近在折腾一个文档自动化的项目,发现传统的OCR(光学字符识别)工具虽然能把图片里的文字“读”出来,但效果总差那么点意思。比如,一张随手拍的…...

ensp关闭完美世界运行时显示权限不够
Windows PowerShell 版权所有(C) Microsoft Corporation。保留所有权利。安装最新的 PowerShell,了解新功能和改进!https://aka.ms/PSWindowsPS C:\Users\Administrator> net stop MessageTransfer 发生系统错误 5。拒绝访问。…...

嵌入式软件在医疗设备开发中的关键技术与实践
1. 嵌入式软件如何重塑现代医疗设备开发作为一名在医疗电子行业摸爬滚打十余年的嵌入式系统工程师,我亲眼见证了嵌入式技术如何彻底改变医疗设备的形态与功能。2008年参与第一台便携式心电监护仪开发时,设备体积还像个手提箱,如今同样功能的设…...

AI自主报告正常胸片:技术原理、临床价值与英国NHS实践挑战
1. 项目概述:当AI开始“读”胸片作为一名在医学影像和人工智能交叉领域摸爬滚打了十多年的从业者,我亲眼见证了AI从实验室里的新奇玩具,逐渐成长为临床医生案头一个值得信赖的“第二双眼睛”。最近,一个特别的应用场景正在全球范围…...