【深度学习】卷积神经网络(LeNet)【文章重新修改中】
卷积神经网络 LeNet
- 前言
- LeNet 模型
- 代码实现
- MINST
- 代码分块解析
- 1 构建 LeNet 网络结构
- 2 加载数据集
- 3 初始化模型和优化器
- 4 训练模型
- 5 训练完成
- 完整代码
- Fashion-MINST
- 代码分块解析
- 1 构建 LeNet 网络结构
- 2 初始化模型参数
- 3 加载数据集
- 4 定义损失函数和优化器
- 5 训练模型
- 完整代码
- 参考与更多阅读材料
前言
全连接神经网络,也称多层感知机, M L P MLP MLP,是深度学习最基本的神经网络之一。它包含输入层,多个隐藏层和输出层,每一层都与前一层的每个神经元相连接。尽管全连接神经网络具有一定的表达能力,其并不是解决所有问题的最佳工具。
e . g . e.g. e.g. 假设我们有一张 1000 ∗ 1000 1000 * 1000 1000∗1000 像素的彩色照片,假设全连接层输出个数为 256 256 256,那么该层权重参数的形状是 3000000 ∗ 256 3 000 000 * 256 3000000∗256,即会占用 3 G B 3GB 3GB 的内存或显存。会导致复杂的模型与过高的存储开销。

卷积层试图解决这个问题。卷积层通过滑动窗口将同一卷积核与不同位置的输入重复计算,从而避免参数尺寸过大。而卷积神经网络,就是包含卷积层的网络。
LeNet 作为早期用来识别手写数字图像的卷积神经网络,名称来源于 Yann LeCun。其展示了通过梯度下降训练卷积神经网络可以达到手写数字识别在当时最先进的结果。
LeNet 模型

LeNet 模型分为卷积层块和全连接层块两个部分;
卷积层块里的基本单位是卷积层后接最大池化层:卷积层用来识别图像里的空间模式,如线条和物体局部,之后的最大池化层则是用来降低卷积层对位置的敏感性。卷积层,由这两个基本单位重复堆叠构成。

具体来说,在每个卷积层块中,每个卷积层都使用 5 ∗ 5 5*5 5∗5 的窗口,并在输出上使用 s i g m o i d sigmoid sigmoid 激活函数;第一个卷积层输出通道数为 6 6 6,第二个卷积层输出通道数增加到 16 16 16。卷积层块的两个最大池化层的窗口形状均为 2 ∗ 2 2*2 2∗2,且步幅为 2 2 2。
代码实现
MINST

代码分块解析
1 构建 LeNet 网络结构
class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Conv2d(1, 6, 5) # 1个输入通道,6个输出通道,卷积核大小为5x5self.pool = nn.MaxPool2d(2, 2) # 最大池化层,2x2窗口self.conv2 = nn.Conv2d(6, 16, 5) # 6个输入通道,16个输出通道,卷积核大小为5x5self.fc1 = nn.Linear(16*4*4, 120) # 全连接层1self.fc2 = nn.Linear(120, 84) # 全连接层2self.fc3 = nn.Linear(84, 10) # 输出层,10个类别def forward(self, x):x = self.pool(torch.relu(self.conv1(x)))x = self.pool(torch.relu(self.conv2(x)))x = x.view(-1, 16*4*4)x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)x = torch.softmax(x, dim=1)return x
- 代码解释
super(LeNet, self).__init__() 是 python 中用于调用父类(或超类)的构造函数的一种方式。在上述定义中,用于在子类 LeNet 的构造函数中调用父类 nn.model 的构造函数。
具体来说:
super(LeNet, self)使用了super()函数创建了一个与子类LeNet相关联的super对象。这个super对象可以用来访问父类的方法和属性。.__init__()调用super对象的构造函数,即调用父类nn.model的构造函数。确保子类super继承父类nn.model的所有属性和方法。
总之,super(LeNet, self).__init__() 目的是在子类 LeNet 的构造函数中初始化父类 nn.model。这是面向对象编程中用于构建继承层次结构中的子类。
- 代码解释
forward(self, x) 是神经网络中定义前向传播的方法。这个方法定义了一个张量 x,按照 LeNet 网络的结构将其传递给不同层,最终计算出网络的输出。
具体来说:
x = self.pool(torch.relu(self.conv1(x)))首先,输入x经过第一个卷积层self.conv1(x),然后使用 ReLU 激活函数进行激活,接着使用self.pool进行最大池化操作;x = self.pool(torch.relu(self.conv2(x)))然后,将前一步的输出再次经过第二个卷积层self.conv2,然后使用 ReLU 激活函数进行激活,接着使用self.pool进行最大池化操作;x = x.view(-1, 16*5*5)在进入到全连接层前,需要将池化层的输出展平为一维向量,通过view函数实现方法:
e . g . e.g. e.g. 如果x的形状是 [ 64 , 16 , 5 , 5 ] [64, 16, 5, 5] [64,16,5,5](其中 batch_size 是 64,num_channels 是16,height 和 width 都是 5 ),那么x.view(-1, 16 * 5 * 5)将会将x的形状调整为 [ 64 , 16 ∗ 5 ∗ 5 ] [64, 16 * 5 * 5] [64,16∗5∗5],也就是 [ 64 , 400 ] [64, 400] [64,400],作为全连接层的输入。x = torch.relu(self.fc1(x))将展平后的数据传递给第一个全连接层self.fc1,然后使用 ReLU 函数进行激活;x = torch.relu(self.fc2(x))将第一个全连接层的输出传递给第二个全连接层self.fc2,然后使用 ReLU 函数进行激活;x = self.fc3(x)x = torch.softmax(x, dim=1)最后将第二个全连接层的输出传递给输出层self.fc3,使用 softmax 获得概率分布;Softmax 将网络的原始输出值转化为 0 到 1 之间的概率值,以表示每个类别的预测概率。
2 加载数据集
# 数据标准化处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# 加载数据集
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
# 创建数据加载器 Loader
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
- 代码解释
transforms.ToTensor() 将图像从 PIL 图像对象转换为 PyTorch 张量,深度学习模型使用张量作为输入;
- 代码解释
transforms.Normalize((0.5,), (0.5,)) 对图像进行归一化操作。
参数 (0.5,) 与 (0.5,) 表示均值和标准差,将图像像素值从 0 到 255 缩放到 -1 到 1 之间,以加速模型的训练过程。对于 MINST 数据集来说,因为只有一个通道(灰度图像),因此只有一个均值和一个标准差。
3 初始化模型和优化器
# 实例化网络对象
net = LeNet()
# 损失函数使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 优化器,使用随机梯度下降
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
- 代码解释
CrossEntropyLoss() 交叉熵损失函数:通常用于多类别分类任务,例如图像分类。
- 代码解释
optim.SGD 即使用随机梯度下降作为优化器,SGD(Stochastic Gradient Descend)
net.parameters() 代表优化器会将神经网络中所有可学习参数不断更新权重;
lr 即 learning rate 学习率,控制优化器每次权重更新的步长;
momentum=0.9 动量,关于动量的概念将在后期单独出一期博文解析,读者在这里可以得知的是动量是一种加速优化过程的技巧,有助于跳出局部最小值。
4 训练模型
for epoch in range(10): # 遍历数据集 10 次running_loss = 0.0 # 损失值for i, data in enumerate(trainloader, 0):# 每个批次中,数据data包含了输入inputs和相应的标签labelsinputs, labels = data# zero_grad 方法将优化器中的梯度清零,计算新的梯度optimizer.zero_grad()# 将输入数据传递给神经网络 net 进行前向传播,计算模型的输出 outputsoutputs = net(inputs)# 计算模型的输出与真实标签之间的损失loss = criterion(outputs, labels)# 根据损失值计算梯度,使用反向传播算法loss.backward()# 使用优化器 optimizer 更新网络的参数,减小损失值optimizer.step()# 将损失值累积到 running_loss 中running_loss += loss.item()if i % 200 == 199: # 每 200 批次打印一次损失# {i + 1:5d} 是一种字符串格式化的语法,用于将整数 i + 1 格式化为宽度为5的右对齐整数。print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 200:.3f}')running_loss = 0.0
5 训练完成
print('Finished Training')
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms# 定义LeNet模型
class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Conv2d(1, 6, 5) # 1个输入通道,6个输出通道,卷积核大小为5x5self.pool = nn.MaxPool2d(2, 2) # 最大池化层,2x2窗口self.conv2 = nn.Conv2d(6, 16, 5) # 6个输入通道,16个输出通道,卷积核大小为5x5self.fc1 = nn.Linear(16*4*4, 120) # 全连接层1self.fc2 = nn.Linear(120, 84) # 全连接层2self.fc3 = nn.Linear(84, 10) # 输出层,10个类别def forward(self, x):x = self.pool(torch.relu(self.conv1(x)))x = self.pool(torch.relu(self.conv2(x)))x = x.view(-1, 16*4*4)x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)x = torch.softmax(x, dim=1)return x# 加载数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)# 初始化模型和优化器
net = LeNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)# 训练模型
for epoch in range(10): # 遍历数据集10次running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = dataoptimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()if i % 200 == 199: # 每200批次打印一次损失print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 200:.3f}')running_loss = 0.0print('Finished Training')
Fashion-MINST

代码分块解析
1 构建 LeNet 网络结构
net = nn.Sequential()
net.add(nn.Conv2D(channels=6, kernel_size=5, activation='sigmoid'),nn.MaxPool2D(pool_size=2, strides=2),nn.Conv2D(channels=16, kernel_size=5, activation='sigmoid'),nn.MaxPool2D(pool_size=2, strides=2),nn.Dense(120, activation='sigmoid'),nn.Dense(84, activation='sigmoid'),nn.Dense(10)
)
使用 nn.Sequential() 创建 LeNet 模型,包括卷积层、池化层和全连接层,其中激活函数为 sigmoid。
2 初始化模型参数
ctx = d2l.try_gpu()
# force_reinit在初始化之前强制重新初始化模型参数
# init.Xavier有助于避免梯度消失和梯度爆炸,提高模型的收敛速度
net.initialize(force_reinit=True, ctx=ctx, init=init.Xavier())
3 加载数据集
# 加载Fashion-MNIST数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size, resize=96)
4 定义损失函数和优化器
# 定义损失函数和优化器
loss = gloss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.9})
使用交叉熵损失函数来计算损失,使用梯度随机下降优化器 sgd 进行模型参数的优化。
5 训练模型
# 训练模型
num_epochs = 10
d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx, num_epochs)
完整代码
import d2lzh as d2l
from mxnet import autograd, gluon, init, nd
from mxnet.gluon import loss as gloss, nn# 定义LeNet模型
net = nn.Sequential()
net.add(nn.Conv2D(channels=6, kernel_size=5, activation='sigmoid'),nn.MaxPool2D(pool_size=2, strides=2),nn.Conv2D(channels=16, kernel_size=5, activation='sigmoid'),nn.MaxPool2D(pool_size=2, strides=2),nn.Dense(120, activation='sigmoid'),nn.Dense(84, activation='sigmoid'),nn.Dense(10)
)# 初始化模型参数
ctx = d2l.try_gpu()
net.initialize(force_reinit=True, ctx=ctx, init=init.Xavier())# 加载Fashion-MNIST数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size, resize=96)# 定义损失函数和优化器
loss = gloss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.9})# 训练模型
num_epochs = 10
d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx, num_epochs)
参考与更多阅读材料
- https://www.analyticsvidhya.com/blog/2021/03/the-architecture-of-lenet-5/
- https://zhuanlan.zhihu.com/p/459616884
相关文章:
【深度学习】卷积神经网络(LeNet)【文章重新修改中】
卷积神经网络 LeNet 前言LeNet 模型代码实现MINST代码分块解析1 构建 LeNet 网络结构2 加载数据集3 初始化模型和优化器4 训练模型5 训练完成 完整代码 Fashion-MINST代码分块解析1 构建 LeNet 网络结构2 初始化模型参数3 加载数据集4 定义损失函数和优化器5 训练模型 完整代码…...
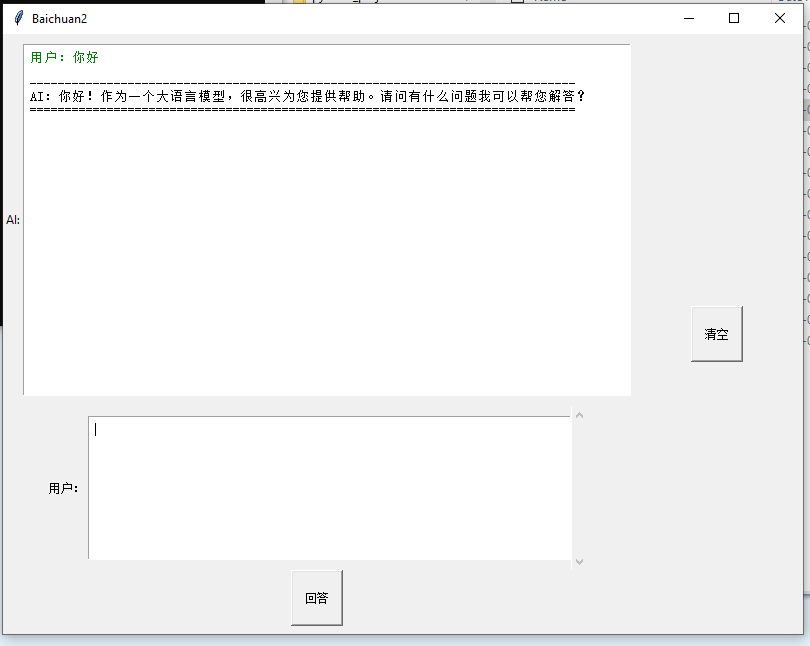
win10 Baichuan2-7B-Chat-4bits 上部署 百川2-7B-对话模型-4bits量化版
搞了两天才搞清楚跑通 好难呢,个人电脑 win10 ,6GB显存 个人感觉 生成速度很慢,数学能力不怎么行 没有ChatGLM2-6B 强,逻辑还行, 要求: 我的部署流程 1.下载模型 ,下载所有文件 然后 放到新建的model目录 https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat-4bits/tr…...
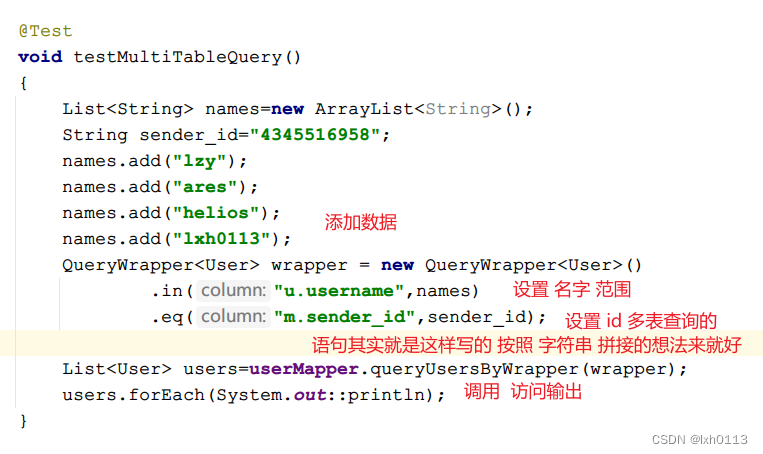
2023/9/20总结
maven maven本质是 一个项目管理工具 将项目开发 和 管理过程 抽象成 一个项目对象模型(POM) POM (Project Object Model) 项目对象模型 作用 项目构建 提供标准的自动化 项目构建 方式依赖管理 方便快捷的管理项目依赖的资源…...

【Git】git 分支或指定文件回退到指定版本
目录 一、分支回滚 1. 使用 git reset 命令 2.使用 git revert 命令 3.使用 git checkout 命令 二、某个文件回滚 1.查看哪些文件发生修改 2.然后查看提交记录(最近几次提交) 3.执行提交命令 一、分支回滚 1. 使用 git reset 命令 命令可以将当前分支的 HEAD 指针指向指…...
Java 消息策略的实现 - Kafak 是怎么设计的
这个也是开放讨论题,主要讨论下 Kafka 在消息中是如何进行实现的。 1_cCyPNzf95ygMFUgsrleHtw976506 21.4 KB 总结 这个题目的开发性太强了。 Kafka 可以用的地方非常多,我经历过的项目有 Kafka 用在消息处理策略上的。这个主要是 IoT 项目,…...
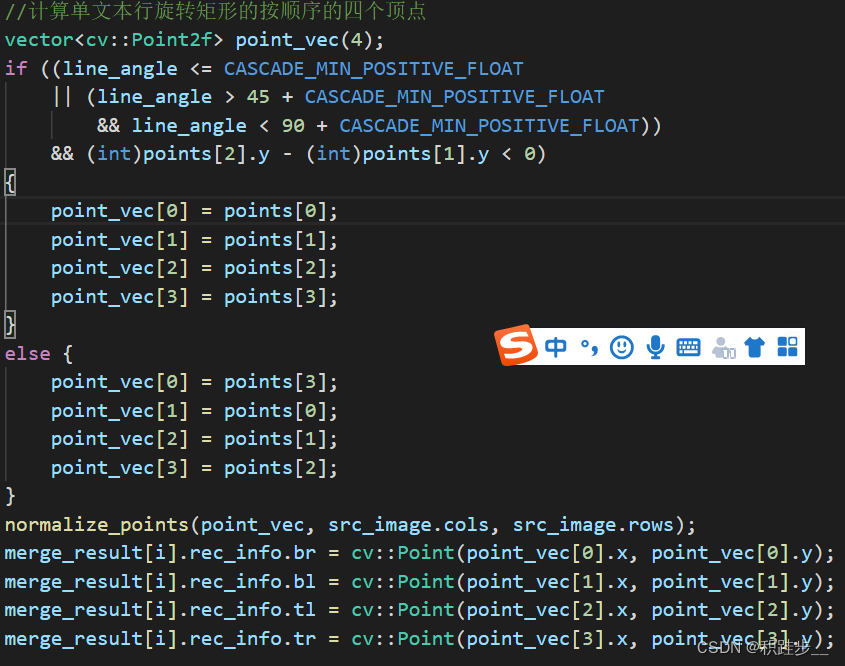
c++opencv RotatedRect 旋转矩形角度转换和顶点顺序转换
这里写自定义目录标题 以下代码记录主要是完成轮廓点求解最小外接矩形之后计算该文本行的角度和旋转矩形的左下(bl),左上(tl),右上(tr),右下(br)的坐标点。 RotatedRect rtminAreaRect(contours…...
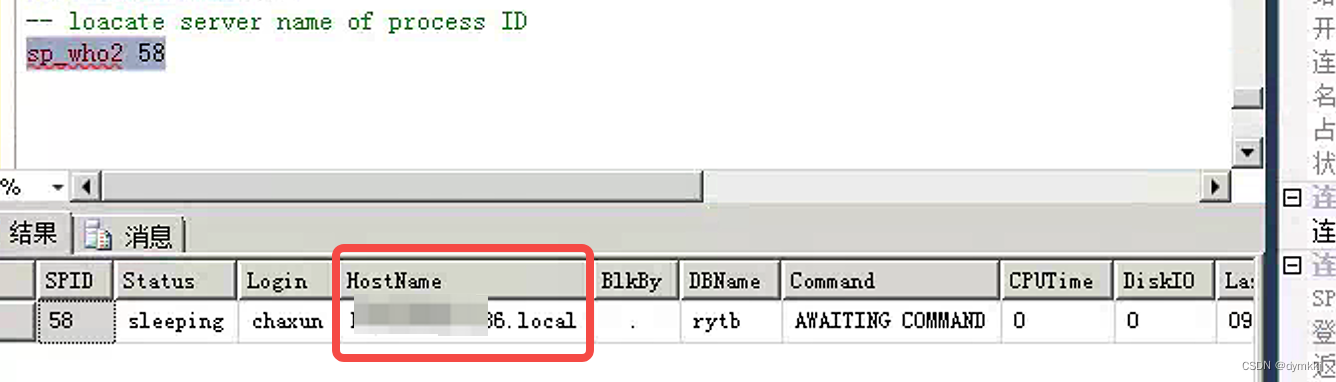
Flink-CDC 抽取SQLServer问题总结
Flink-CDC 抽取SQLServer问题总结 背景 flink-cdc 抽取数据到kafka 中,使用flink-sql进行开发,相关问题总结flink-cdc 配置SQLServer cdc参数 1.创建CDC 使用的角色, 并授权给其查询待采集数据数据库 -- a.创建角色 create role flink_role;-- b.授权…...
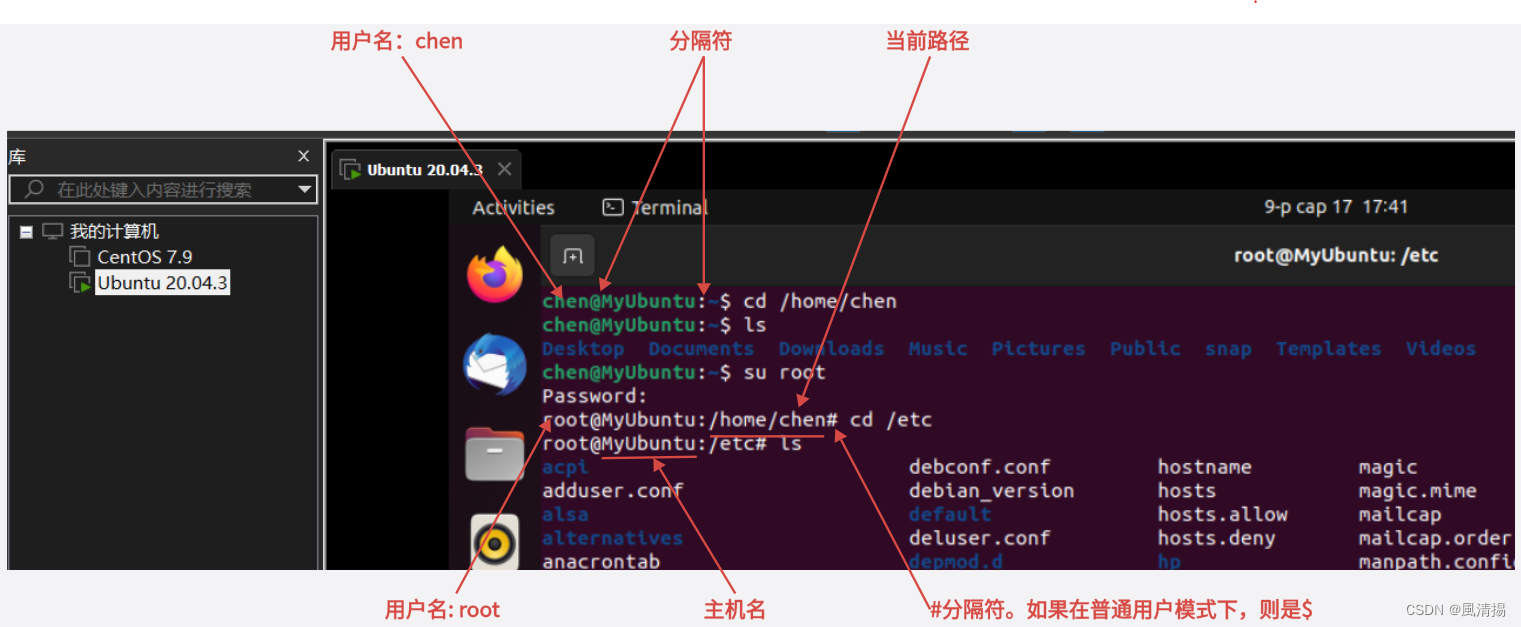
Linux 系统目录结构 终端
系统目录结构 Linux 或 Unix 操作系统中,所有文件和目录呈一个以根节点为始的倒置的树状结构。文件系统的最顶层是根目录,用 / 来表示根目录。在根目录之下的既可以是目录,也可以是文件,而每一个目录中又可以包含子目录文件。如此…...

Layui + Flask | 实现注册、登录功能(案例篇)(08)
此案例内容比较多,建议滑到最后点击阅读原文,阅读体验更佳。后续也会录制案例视频,将在本周内上传到同名的 b 站账号。 已经看了 layui 表单相关的知识,接下来就可以实现注册功能,功能逻辑如下: 项目创建 新建 flask 项目下载 layui 文件,解压之后复制到指定文件编写前…...

GitLab数据迁移后出现500错误
一、背景 去年做GitLab数据迁移时,写过一篇文章《GitLab的备份与还原》。后来发现新创建的项目没问题,但对于迁移过来的项目,修改名称等信息,或者删除该项目时,会出现500错误,以为是系统问题&#…...
音乐随行,公网畅享,群辉Audiostation给你带来听歌新体验!
文章目录 本教程解决的问题是:按照本教程方法操作后,达到的效果是本教程使用环境:1 群晖系统安装audiostation套件2 下载移动端app3 内网穿透,映射至公网 很多老铁想在上班路上听点喜欢的歌或者相声解解闷儿,于是打开手…...

机器学习入门:从算法到实际应用
机器学习入门:从算法到实际应用 机器学习入门:从算法到实际应用摘要引言机器学习基础1. 什么是机器学习?2. 监督学习 vs. 无监督学习 机器学习算法3. 线性回归4. 决策树和随机森林 数据准备和模型训练5. 数据预处理6. 模型训练与调优 实际应用…...

【Vue.js】vue-cli搭建SPA项目并实现路由与嵌套路由---详细讲解
一,何为SPA SPA(Single Page Application)是一种 Web 应用程序的开发模式,它通过使用 AJAX 技术从服务器异步加载数据,动态地更新页面内容,实现在同一个页面内切换不同的视图,而无需整页刷新 1.…...
Node.js 调用 fluent-ffmpeg
最近开发H5资源在线裁剪,最终在资源合成的步骤,选择 ffmpeg 作为合成的插件,记录下使用方式。 一、介绍 ffmpeg 一款跨平台多媒体处理工具,可以进行视频转码、裁剪、合成、音视频提取、推流等操作。 二、安装 Node js 可以利用…...

scrapy框架--
Scrapy是一个用于爬取数据的Python框架。下面是Scrapy框架的基本操作步骤: 安装Scrapy:首先,确保你已经安装好了Python和pip。然后,在命令行中运行以下命令安装Scrapy:pip install scrapy 创建Scrapy项目:…...

算法通关村第十五关——从40亿个数中产生一个不存在的数的处理方法
1.从40个亿中产生一个不存在的整数 题目要求:给定一个输入文件,包含40亿个非负整数,请设计一个算法,产生一个不存在该文件中的整数,假设你有1GB的内存来完成这项任务。**** 解题中心思想:存储的不是这40亿…...

软件项目开发的流程及关键点
软件项目开发的流程及关键点 graph LR A[需求分析] --> B[系统设计] B --> C[编码开发] C --> D[测试验证] D --> E[部署上线] E --> F[运维支持]在项目开发的流程中,首先是进行需求分析,明确项目的目标和功能要求。接下来是系统设计&am…...
)
全球变暖问题(floodfill 处理联通块问题)
全球变暖问题 文章目录 全球变暖问题前言题目描述题目分析边界问题的考虑岛屿是否被淹没判断:如何寻找联通块: 代码预告 前言 之前我们介绍了 bfs算法在二维,三维地图中的应用,现在我们接续进行拓展,解锁floodfill 算…...

由于找不到vcruntime140_1.dll怎么修复,详细修复步骤分享
在使用电脑过程中,可能会遇到一些错误提示,其中之一是找不到vcruntime140_1.dll的问题。这使得许多用户感到困扰,不知道该如何解决这个问题。小编将详细介绍vcruntime140_1.dll的作用以及解决找不到该文件的方法,帮助你摆脱困境。…...
)
算法 三数之和-(双指针)
牛客网: BM54 题目: 数组中所有不重复的满足三数之和等于0的数,非递减形式。 思路: 数组不小于3。不重复非递减,需先排序。使用idx从0开始遍历到n-2, 如果出现num[idx]num[idx-1]的情况,忽略继续下一个idx;令left idx1, right …...

国家中小学智慧教育平台电子课本下载工具:教育资源获取的完整解决方案
国家中小学智慧教育平台电子课本下载工具:教育资源获取的完整解决方案 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内…...

某恶意软件样本逆向分析报告
1.概述样本来源:微步在线恶意软件名称:刘文博-关于北京体彩中心的问题反馈.exesha256:c28d23d8658abc1f5683c6b50239d5593eb7a274a3abec56124d7fb43fec1b642.行为分析该程序图标设为word文档图标,实际为exe文件,诱骗受…...
为你的五子棋项目加个‘智能大脑’)
从AlphaGo到你的小游戏:如何用MCTS(蒙特卡洛树搜索)为你的五子棋项目加个‘智能大脑’
从AlphaGo到你的小游戏:如何用MCTS为五子棋项目构建智能决策引擎 当你在手机上下棋输给AI时,是否好奇过这些"电子大脑"如何思考?2016年AlphaGo击败李世石的关键技术之一——蒙特卡洛树搜索(MCTS),…...

从磁路对称性到电感差异:深度解析永磁同步电机凸极与隐极的本质
1. 永磁同步电机的两种面孔:凸极与隐极 第一次拆解永磁同步电机时,我被转子铁芯上那些凹凸有致的磁极结构吸引了——有的像连绵的山丘(凸极),有的则平整得像镜面(隐极)。这两种结构看似只是外观…...

Ruby纳米机器人框架:构建高内聚低耦合的自动化任务管道
1. 项目概述:当Ruby遇上纳米机器人最近在GitHub上闲逛,发现了一个名为icebaker/ruby-nano-bots的项目。这个标题本身就充满了想象力——Ruby,一门以优雅和生产力著称的动态语言;Nano-Bots,一个源自科幻、代表微观自动化…...

3分钟快速搞定Windows苹果设备驱动安装:Apple-Mobile-Drivers-Installer终极指南
3分钟快速搞定Windows苹果设备驱动安装:Apple-Mobile-Drivers-Installer终极指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: h…...

【20年架构老兵亲授】:SITS 2026服务边界定义三原则、8类AI上下文耦合陷阱及动态治理沙盒实测数据
更多请点击: https://intelliparadigm.com 第一章:AI原生微服务架构:SITS 2026服务拆分与治理策略 AI原生微服务并非传统微服务的简单升级,而是以模型生命周期、推理上下文感知和实时反馈闭环为驱动的服务边界重构。SITS 2026&am…...
)
从零封装Cesium测量工具:我踩过的3个坑和性能优化心得(鼠标事件、坐标拾取、内存泄漏)
从零封装Cesium测量工具:我踩过的3个坑和性能优化心得 第一次在项目中集成Cesium测量工具时,我天真地以为这不过是调用几个API的简单工作。直到用户反馈地图越来越卡、测量结果偶尔出现诡异偏差时,我才意识到自己掉进了多少陷阱。本文将分享三…...

如何快速提取B站CC字幕:面向新手的完整工具指南
如何快速提取B站CC字幕:面向新手的完整工具指南 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 你是否曾经为了获取B站视频的字幕而烦恼?想…...

3分钟实现Zotero与Notion双向联动:Notero完整使用指南
3分钟实现Zotero与Notion双向联动:Notero完整使用指南 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 你是否曾为学术研究中的文献管理而烦恼?Zotero中精…...