Mysql高级——索引优化和查询优化(1)
索引优化
1. 数据准备
学员表插50万条, 班级表插1万条。
建表
CREATE TABLE `class` (`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,`className` VARCHAR ( 30 ) DEFAULT NULL,`address` VARCHAR ( 40 ) DEFAULT NULL,`monitor` INT NULL,PRIMARY KEY ( `id` )
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
CREATE TABLE `student` (`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,`stuno` INT NOT NULL,`name` VARCHAR ( 20 ) DEFAULT NULL,`age` INT ( 3 ) DEFAULT NULL,`classId` INT ( 11 ) DEFAULT NULL,PRIMARY KEY ( `id` ) #CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
设置参数
- 命令开启:允许创建函数设置:
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
创建函数
保证每条数据都不同。
#随机产生字符串DELIMITER //
CREATE FUNCTION rand_string ( n INT ) RETURNS VARCHAR ( 255 ) BEGINDECLAREchars_str VARCHAR ( 100 ) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';DECLAREreturn_str VARCHAR ( 255 ) DEFAULT '';DECLAREi INT DEFAULT 0;WHILEi < n DOSET return_str = CONCAT(return_str,SUBSTRING( chars_str, FLOOR( 1+RAND ()* 52 ), 1 ));SET i = i + 1;END WHILE;RETURN return_str;END //
DELIMITER;#假如要删除
#drop function rand_string;
随机产生班级编号
#用于随机产生多少到多少的编号DELIMITER //
CREATE FUNCTION rand_num ( from_num INT, to_num INT ) RETURNS INT ( 11 ) BEGINDECLAREi INT DEFAULT 0;SET i = FLOOR(from_num + RAND()*(to_num - from_num + 1 ));RETURN i;END //
DELIMITER;#假如要删除
#drop function rand_num;
创建存储过程
#创建往stu表中插入数据的存储过程DELIMITER //
CREATE PROCEDURE insert_stu ( START INT, max_num INT ) BEGINDECLAREi INT DEFAULT 0;SET autocommit = 0;#设置手动提交事务REPEAT#循环SET i = i + 1;#赋值INSERT INTO student ( stuno, NAME, age, classId )VALUES((START + i ),rand_string ( 6 ),rand_num ( 1, 50 ),rand_num ( 1, 1000 ));UNTIL i = max_num END REPEAT;COMMIT;#提交事务END //
DELIMITER;#假如要删除
#drop PROCEDURE insert_stu;
创建往class表中插入数据的存储过程
#执行存储过程,往class表添加随机数据DELIMITER //
CREATE PROCEDURE `insert_class` ( max_num INT ) BEGINDECLAREi INT DEFAULT 0;SET autocommit = 0;REPEATSET i = i + 1;INSERT INTO class ( classname, address, monitor )VALUES(rand_string ( 8 ),rand_string ( 10 ),rand_num ( 1, 100000 ));UNTIL i = max_num END REPEAT;COMMIT;END //
DELIMITER;#假如要删除
#drop PROCEDURE insert_class;
调用存储过程
class
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
stu
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);
删除某表上的索引
创建存储过程
DELIMITER //
CREATE PROCEDURE `proc_drop_index` (dbname VARCHAR ( 200 ),tablename VARCHAR ( 200 )) BEGINDECLAREdone INT DEFAULT 0;DECLAREct INT DEFAULT 0;DECLARE_index VARCHAR ( 200 ) DEFAULT '';DECLARE_cur CURSOR FOR SELECTindex_name FROMinformation_schema.STATISTICS WHEREtable_schema = dbname AND table_name = tablename AND seq_in_index = 1 AND index_name <> 'PRIMARY';#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束DECLARECONTINUE HANDLER FOR NOT FOUND SET done = 2;#若没有数据返回,程序继续,并将变量done设为2OPEN _cur;FETCH _cur INTO _index;WHILE_index <> '' DOSET @str = CONCAT( "drop index ", _index, " on ", tablename );PREPARE sql_str FROM@str;EXECUTE sql_str;DEALLOCATE PREPARE sql_str;SET _index = '';FETCH _cur INTO _index;END WHILE;CLOSE _cur;END //
DELIMITER;
执行存储过程
CALL proc_drop_index("dbname","tablename");
2. 索引失效案例
2.1 全值匹配我最爱
2.2 最佳左前缀法则
拓展:Alibaba《Java开发手册》
索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
2.3 主键插入顺序
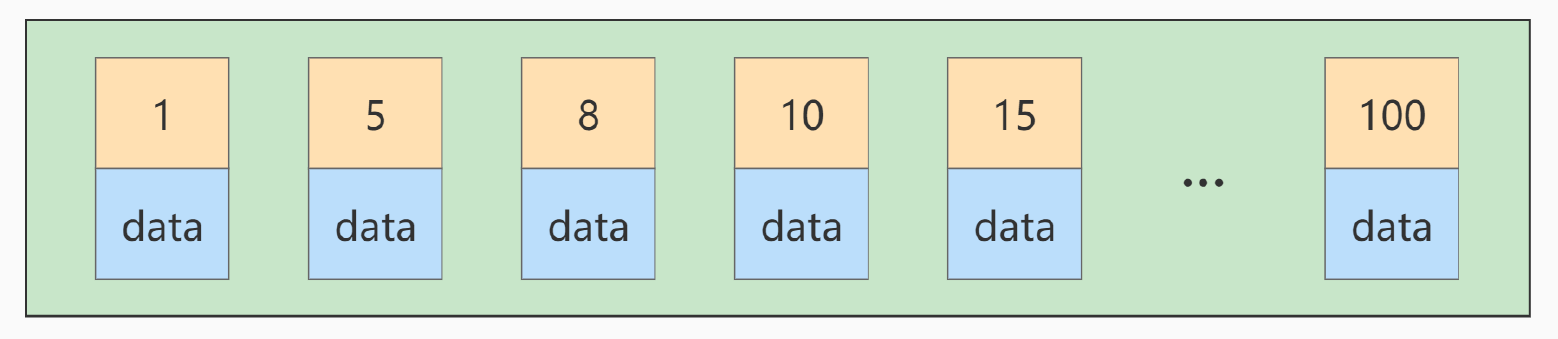
如果此时再插入一条主键值为9 的记录,那它插入的位置就如下图:
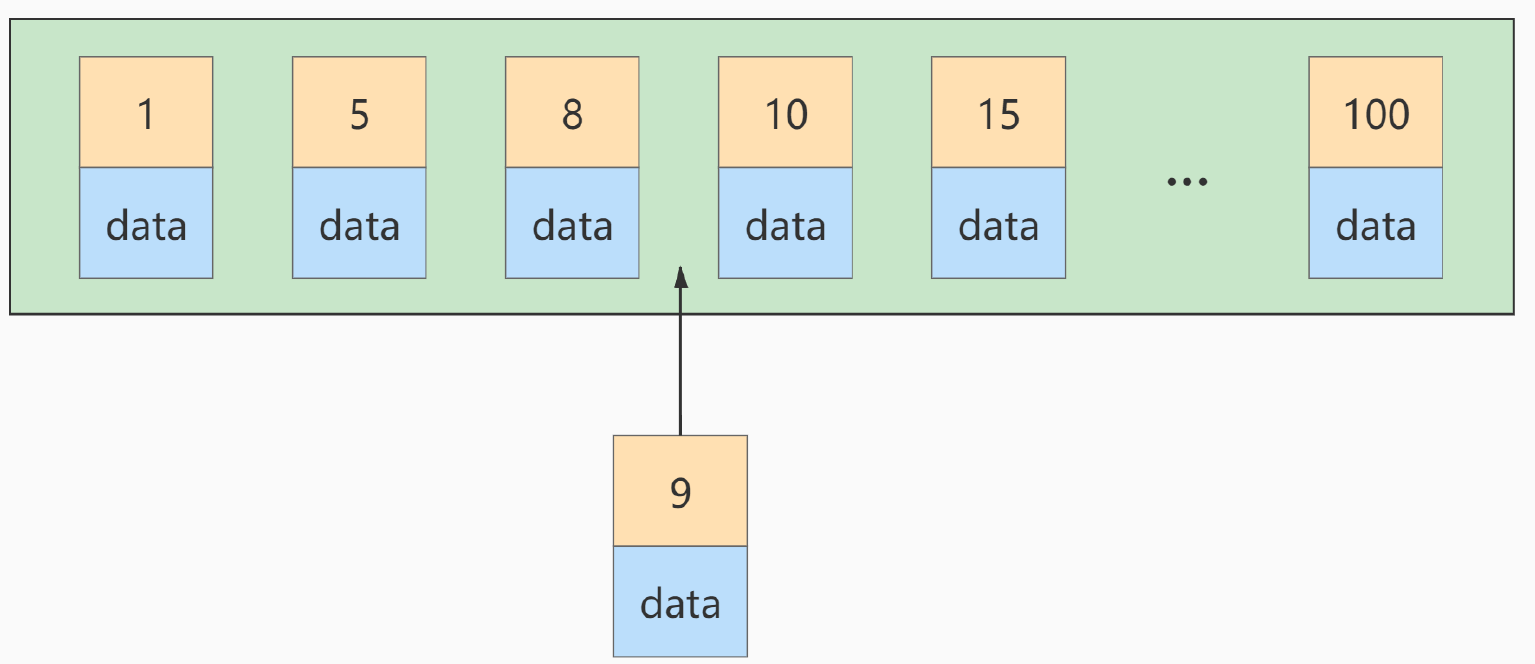
可这个数据页已经满了,再插进来咋办呢?我们需要把当前页面分裂成两个页面,把本页中的一些记录移动到新创建的这个页中。页面分裂和记录移位意味着什么?意味着: 性能损耗!所以如果我们想尽量避免这样无谓的性能损耗,最好让插入的记录的主键值依次递增,这样就不会发生这样的性能损耗了。所以我们建议:让主键具有AUTO_INCREMENT ,让存储引擎自己为表生成主键,而不是我们手动插入 ,比如: person_info 表:
CREATE TABLE person_info (id INT UNSIGNED NOT NULL AUTO_INCREMENT,NAME VARCHAR ( 100 ) NOT NULL,birthday DATE NOT NULL,phone_number CHAR ( 11 ) NOT NULL,country VARCHAR ( 100 ) NOT NULL,PRIMARY KEY ( id ),
KEY idx_name_birthday_phone_number ( NAME ( 10 ), birthday, phone_number )
);
我们自定义的主键列id 拥有AUTO_INCREMENT 属性,在插入记录时存储引擎会自动为我们填入自增的主键值。这样的主键占用空间小,顺序写入,减少页分裂。
2.4 计算、函数、类型转换(自动或手动)导致索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
创建索引
CREATE INDEX idx_name ON student(NAME);
第一种:索引优化生效
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
第二种:索引优化失效
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 498917 | 100.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
mysql> SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
+--------+--------+--------+------+---------+
| id | stuno | name | age | classId |
+--------+--------+--------+------+---------+
| 399 | 100399 | ABcKtL | 24 | 198 |
| 16470 | 116470 | ABcJlg | 47 | 251 |
| 27952 | 127952 | ABcJmj | 10 | 397 |
| 54809 | 154809 | aBClvu | 37 | 495 |
| 61540 | 161540 | abclUS | 30 | 374 |
| 83160 | 183160 | aBCjpV | 34 | 593 |
| 89664 | 189664 | aBCjmJ | 34 | 350 |
| 240498 | 340498 | aBCksj | 41 | 491 |
| 245214 | 345214 | abciJU | 23 | 568 |
| 258459 | 358459 | aBClxC | 23 | 566 |
| 300169 | 400169 | aBClxC | 21 | 412 |
| 300328 | 400328 | ABcJnn | 27 | 870 |
| 324684 | 424684 | aBCkrg | 30 | 566 |
| 416907 | 516907 | ABcHgI | 46 | 607 |
| 424459 | 524459 | abclVU | 39 | 192 |
| 445547 | 545547 | ABcJpw | 16 | 180 |
| 454772 | 554772 | AbCHFf | 37 | 313 |
| 466466 | 566466 | abckRF | 26 | 725 |
| 475708 | 575708 | abclWY | 4 | 415 |
| 486611 | 586611 | ABcLwb | 41 | 948 |
| 490152 | 590152 | ABcHfC | 24 | 717 |
+--------+--------+--------+------+---------+
21 rows in set, 1 warning (0.12 sec)
type为“ALL”,表示没有使用到索引
2.5 类型转换导致索引失效
下列哪个sql语句可以用到索引。(假设name字段上设置有索引)
# 未使用到索引
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_name | NULL | NULL | NULL | 498917 | 10.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 4 warnings (0.00 sec)
# 使用到索引
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | student | NULL | ref | idx_name | idx_name | 63 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 2 warnings (0.00 sec)
- name=123发生类型转换,索引失效。
2.6 范围条件右边的列索引失效
ALTER TABLE student DROP INDEX idx_name;
ALTER TABLE student DROP INDEX idx_age;
ALTER TABLE student DROP INDEX idx_age_classid;
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId>20 AND student.name = 'abc' ;
create index idx_age_name_classid on student(age,name,classid);
- 将范围查询条件放置语句最后:
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name =-> 'abc' AND student.classId>20 ;
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | range | idx_age_name_classid | idx_age_name_classid | 73 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
1 row in set, 2 warnings (0.00 sec)
2.7 不等于(!= 或者<>)索引失效
2.8 is null可以使用索引,is not null无法使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
2.9 like以通配符%开头索引失效
拓展:Alibaba《Java开发手册》
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
2.10 OR 前后存在非索引的列,索引失效
# 未使用到索引
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_age_name_classid | NULL | NULL | NULL | 498917 | 11.88 | Using where |
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
# 使用到索引
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR name = 'Abel';
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_age_name_classid | NULL | NULL | NULL | 498917 | 11.88 | Using where |
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
2.11 数据库和表的字符集统一使用utf8mb4
统一使用utf8mb4( 5.5.3版本以上支持)兼容性更好,统一字符集可以避免由于字符集转换产生的乱码。不同的字符集进行比较前需要进行转换会造成索引失效。
3. 关联查询优化
3.1 数据准备
CREATE TABLE IF NOT EXISTS `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
#图书
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);#向分类表中添加20条记录
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));#向图书表中添加20条记录
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
3.2 采用左外连接
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 2 warnings (0.00 sec)
结论:type 有All
添加索引优化
ALTER TABLE book ADD INDEX Y ( card); #【被驱动表】,可以避免全表扫描mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.type.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
可以看到第二行的 type 变为了 ref,rows 也变成了优化比较明显。这是由左连接特性决定的。LEFT JOIN
条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要建立索引。
ALTER TABLE `type` ADD INDEX X (card); #【驱动表】,无法避免全表扫描mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | index | NULL | X | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.type.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
DROP INDEX Y ON book;mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | type | NULL | index | NULL | X | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 2 warnings (0.00 sec)
3.3 采用内连接
drop index X on type;
drop index Y on book;
换成 inner join(MySQL自动选择驱动表)
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 2 warnings (0.00 sec)
添加索引优化
ALTER TABLE book ADD INDEX Y ( card);mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.type.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
ALTER TABLE type ADD INDEX X (card);mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | index | X | X | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.type.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
接着:
DROP INDEX X ON `type`;mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM TYPE INNER JOIN book ON type.card=book.card;
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | TYPE | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.TYPE.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
接着:
ALTER TABLE `type` ADD INDEX X (card);mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | index | X | X | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.type.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
3.4 join语句原理
Index Nested-Loop Join
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a=t2.a);
如果直接使用join语句,MySQL优化器可能会选择表t1或t2作为驱动表,这样会影响我们分析SQL语句的执行过程。所以,为了便于分析执行过程中的性能问题,我改用straight_join 让MySQL使用固定的连接方式执行查询,这样优化器只会按照我们指定的方式去join。在这个语句里,t1 是驱动表,t2是被驱动表。
可以看到,在这条语句里,被驱动表t2的字段a上有索引,join过程用上了这个索引,因此这个语句的执行流程是这样的:
- 从表t1中读入一行数据 R;
- 从数据行R中,取出a字段到表t2里去查找;
- 取出表t2中满足条件的行,跟R组成一行,作为结果集的一部分;
- 重复执行步骤1到3,直到表t1的末尾循环结束。
这个过程是先遍历表t1,然后根据从表t1中取出的每行数据中的a值,去表t2中查找满足条件的记录。在形式上,这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引,所以我们称之为“Index Nested-Loop Join”,简称NLJ。
它对应的流程图如下所示:
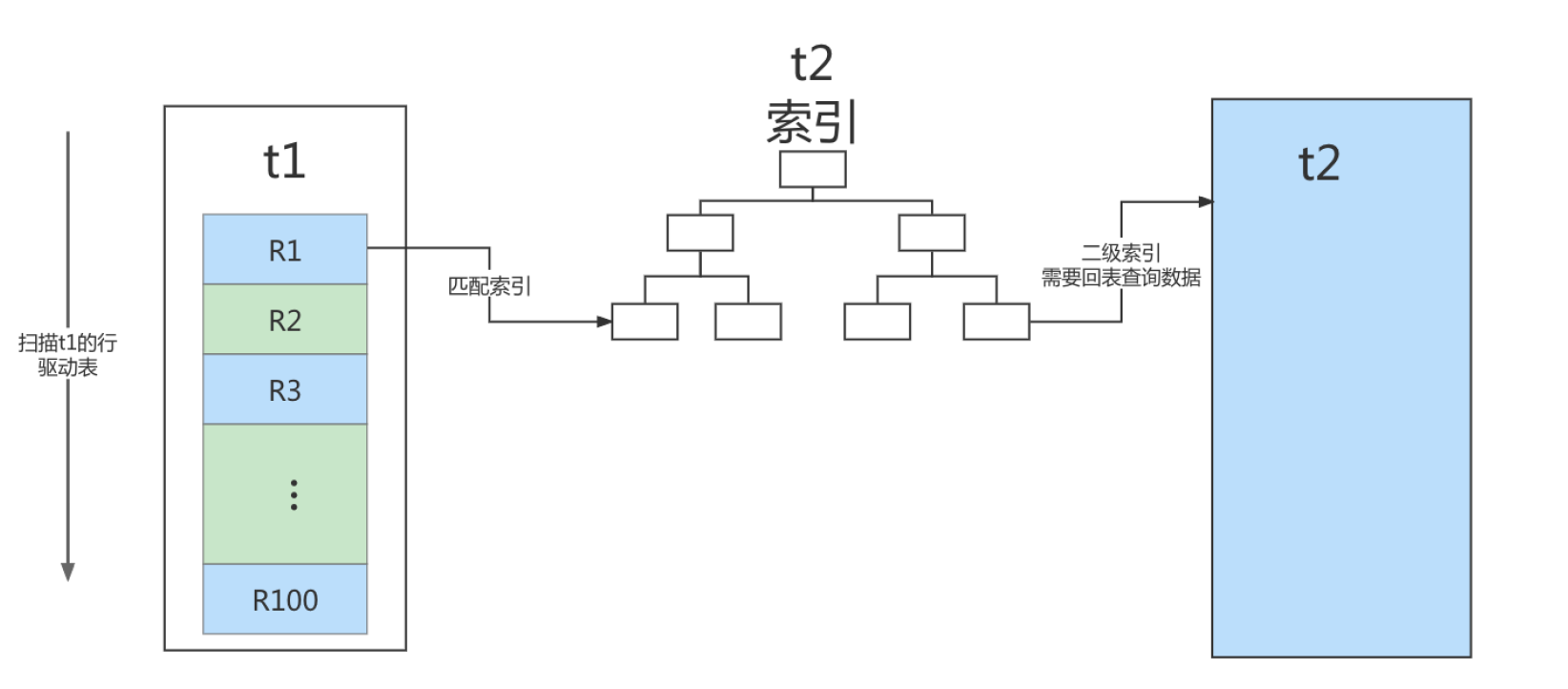
在这个流程里:
- 对驱动表t1做了全表扫描,这个过程需要扫描100行;
- 而对于每一行R,根据a字段去表t2查找,走的是树搜索过程。由于我们构造的数据都是一一对应的,因此每次的搜索过程都只扫描一行,也是总共扫描100行;
- 所以,整个执行流程,总扫描行数是200。
两个结论:
- 使用join语句,性能比强行拆成多个单表执行SQL语句的性能要好;
- 如果使用join语句的话,需要让小表做驱动表。
Simple Nested-Loop Join
Block Nested-Loop Join
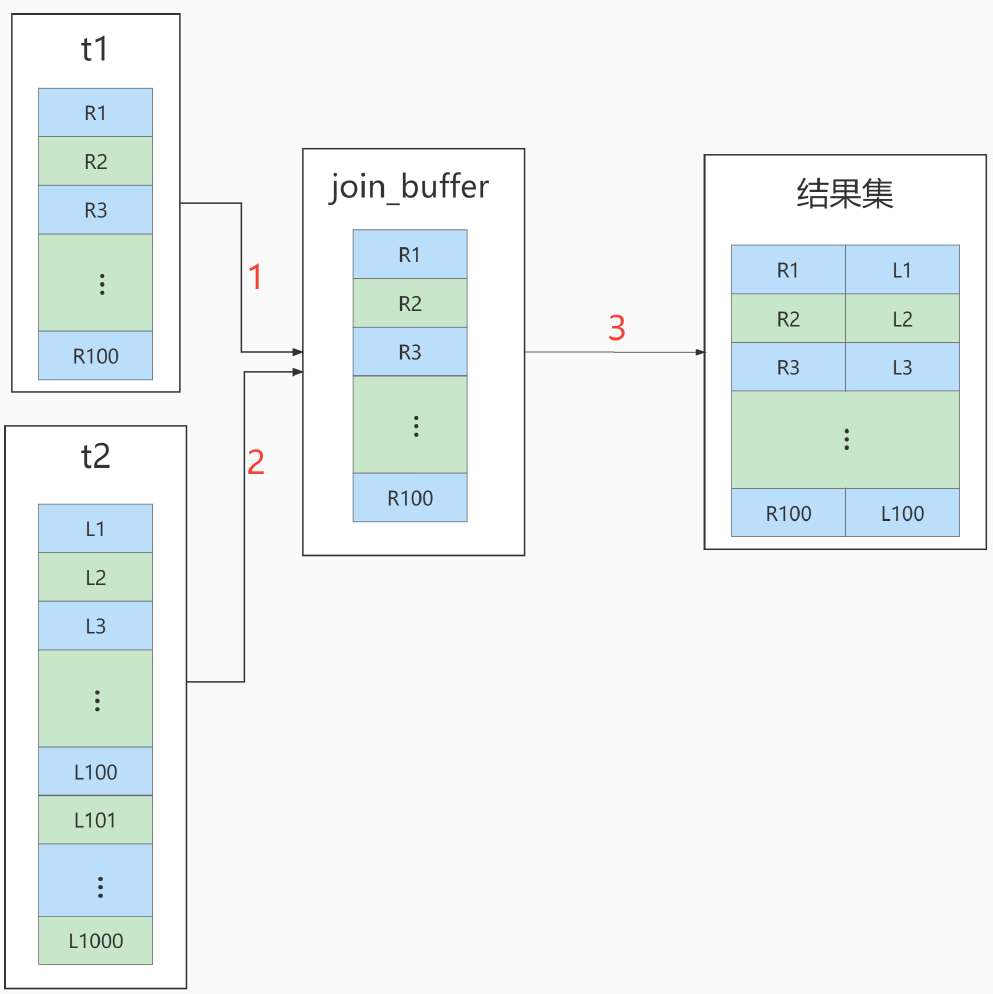
执行流程图也就变成这样:
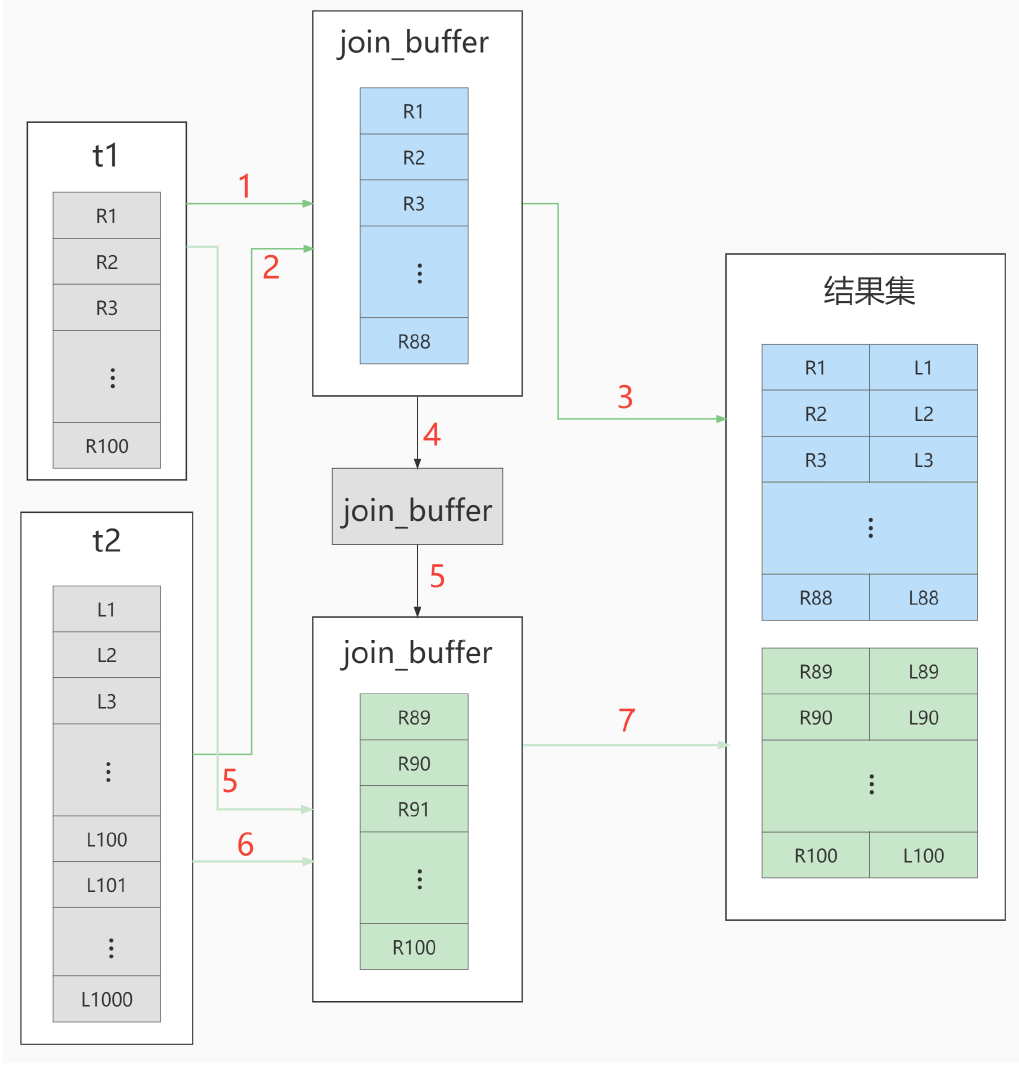
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与join的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
总结
- 保证被驱动表的JOIN字段已经创建了索引
- 需要JOIN 的字段,数据类型保持绝对一致。
- LEFT JOIN 时,选择小表作为驱动表,
大表作为被驱动表。减少外层循环的次数。 - INNER JOIN 时,MySQL会自动将
小结果集的表选为驱动表。选择相信MySQL优化策略。 - 能够直接多表关联的尽量直接关联,不用子查询。(减少查询的趟数)
- 不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用 JOIN 来代替子查询。
- 衍生表建不了索引
4. 子查询优化
MySQL从4.1版本开始支持子查询,使用子查询可以进行SELECT语句的嵌套查询,即一个SELECT查询的结果作为另一个SELECT语句的条件。子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作。
子查询是 MySQL 的一项重要的功能,可以帮助我们通过一个 SQL 语句实现比较复杂的查询。但是,子查询的执行效率不高
① 执行子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。这样会消耗过多的CPU和IO资源,产生大量的慢查询。
② 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。
③ 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。在MySQL中,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表,其速度比子查询要快,如果查询中使用索引的话,性能就会更好。
结论:尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代
相关文章:
Mysql高级——索引优化和查询优化(1)
索引优化 1. 数据准备 学员表插50万条, 班级表插1万条。 建表 CREATE TABLE class (id INT ( 11 ) NOT NULL AUTO_INCREMENT,className VARCHAR ( 30 ) DEFAULT NULL,address VARCHAR ( 40 ) DEFAULT NULL,monitor INT NULL,PRIMARY KEY ( id ) ) ENGINE INNO…...
Oracle for Windows安装和配置——Oracle for Windows数据库创建及测试
2.2. Oracle for Windows数据库创建及测试 2.2.1. 创建数据库 1)启动数据库创建助手(DBCA) 进入%ORACLE_HOME%\bin\目录并找到“dbca”批处理程序,双击该程序。具体如图2.1.3-1所示。 图2.1.3-1 双击“%ORACLE_HOME%\bin\dbca”…...

【1993. 树上的操作】
来源:力扣(LeetCode) 描述: 给你一棵 n 个节点的树,编号从 0 到 n - 1 ,以父节点数组 parent 的形式给出,其中 parent[i] 是第 i 个节点的父节点。树的根节点为 0 号节点,所以 par…...

LeetCode【1. 两数之和】
穷通有命无须卜,富贵何时乃济贫;角逐名场今已久,依然一幅旧儒巾。 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输…...
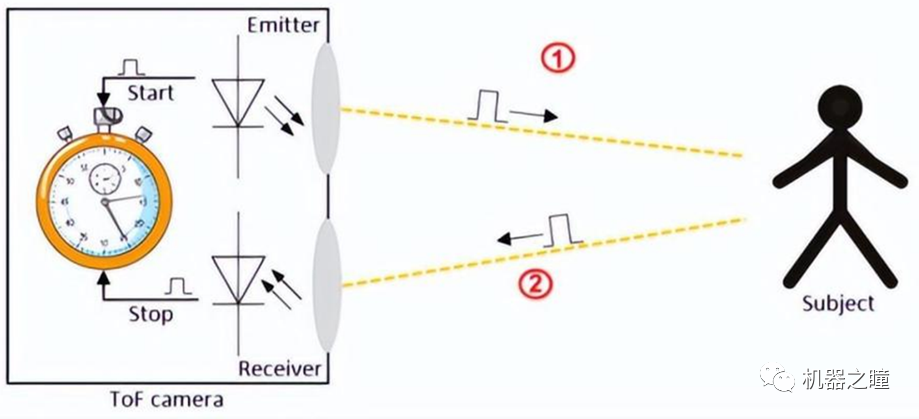
3D成像技术概述
工业4.0时代,三维机器视觉备受关注,目前,三维机器视觉成像方法主要分为光学成像法和非光学成像法,这之中,光学成像法是市场主流。 飞行时间3D成像 飞行时间成像(Time of Flight),简称TOF,是通过给目标连续发送光脉冲,然后用传感器接收从物体返回的光,通过探测光脉…...
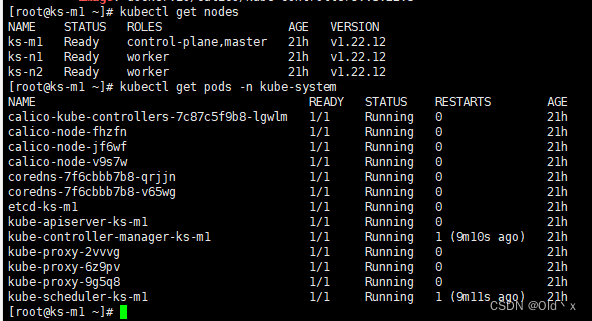
Centos7 安装部署 Kubernetes(k8s) 高可用集群
1:基础环境准备 宿主机系统集群角色服务器IP主机名称容器centos7.6master192.168.2.150ks-m1dockercentos7.6master192.168.2.151ks-n1dockercentos7.6master192.168.2.152ks-n2docker 1.1 服务器初始化及网络配置 VMware安装Centos7并初始化网络使外部可以访问*…...

c++加速方法大全
我们平常写代码的时候,经常超时,非常难受,所以,我写了这篇文章,让你的代码提升速度(这些方法作者亲测有效,用了这些方法,足足提升了1秒!虽然最后题目还是没过)…...

【国科大卜算】Truck History 最小生成树Prim
Truck History 文章目录 Truck Historyproblem descriptionInputOutputSample个人理解 problem description Advanced Cargo Movement, Ltd. uses trucks of different types. Some trucks are used for vegetable delivery, other for furniture, or for bricks. The company…...

SQLAlchemy映射表结构和对数据的CRUD
目录 ORM模型映射到数据库中 SQLAlchemy对数据的增删改查操作编辑 构建session对象 添加对象 查找对象 修改对象 删除对象 ORM模型映射到数据库中 用declarative_base根据engine创建一个ORM基类 from sqlalchemy.ext.declarative import declarative_base engine cr…...
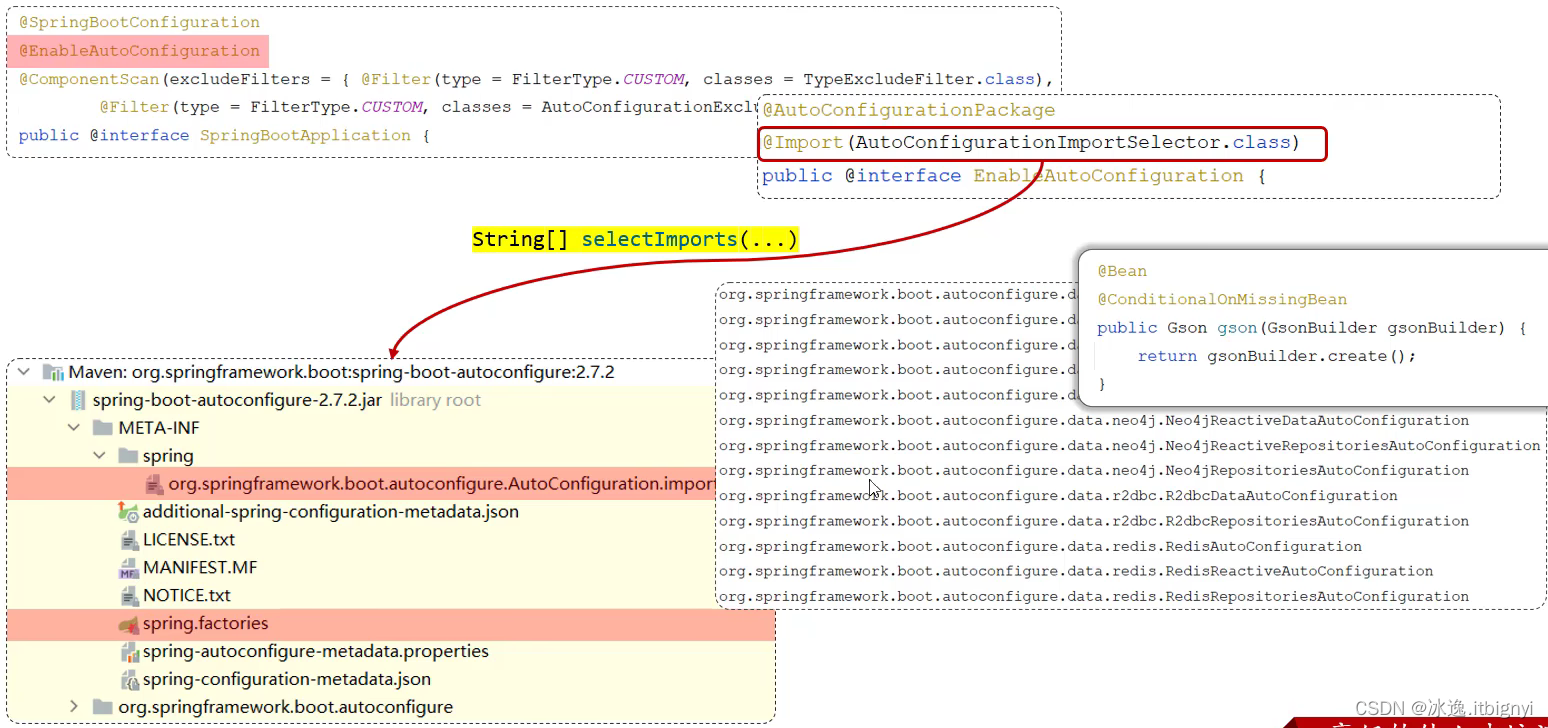
Spring boot原理
起步依赖 Maven的传递依赖 自动配置 Springboot的自动配置就是当spring容器启动后,一些配置类、bean对象就自动存入到IOC容器中,不需要我们手动去声明,从而简化了开发,省去了繁琐的配置操作。 自动配置原理: 方案一…...
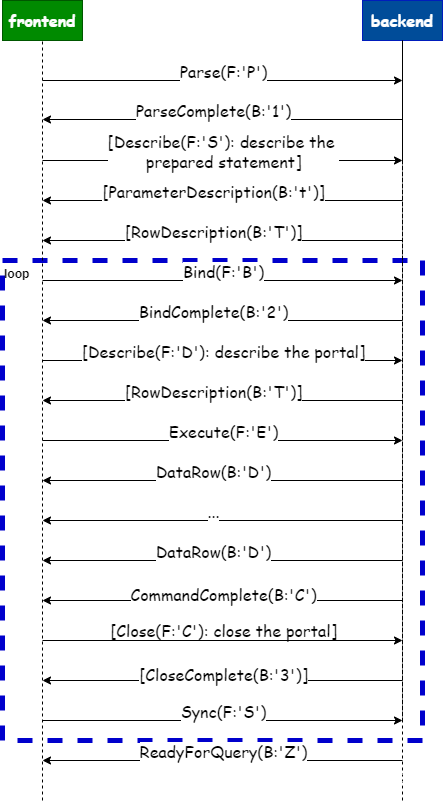
技术贴 | 深度解析 PostgreSQL Protocol v3.0(二)— 扩展查询
引言 PostgreSQL 使用基于消息的协议在前端(客户端)和后端(服务器)之间进行通信。该协议通过 TCP/IP 和 Unix 域套接字支持。 《深度解析 PostgreSQL Protocol v3.0》系列技术贴,将带大家深度了解 PostgreSQL Protoc…...
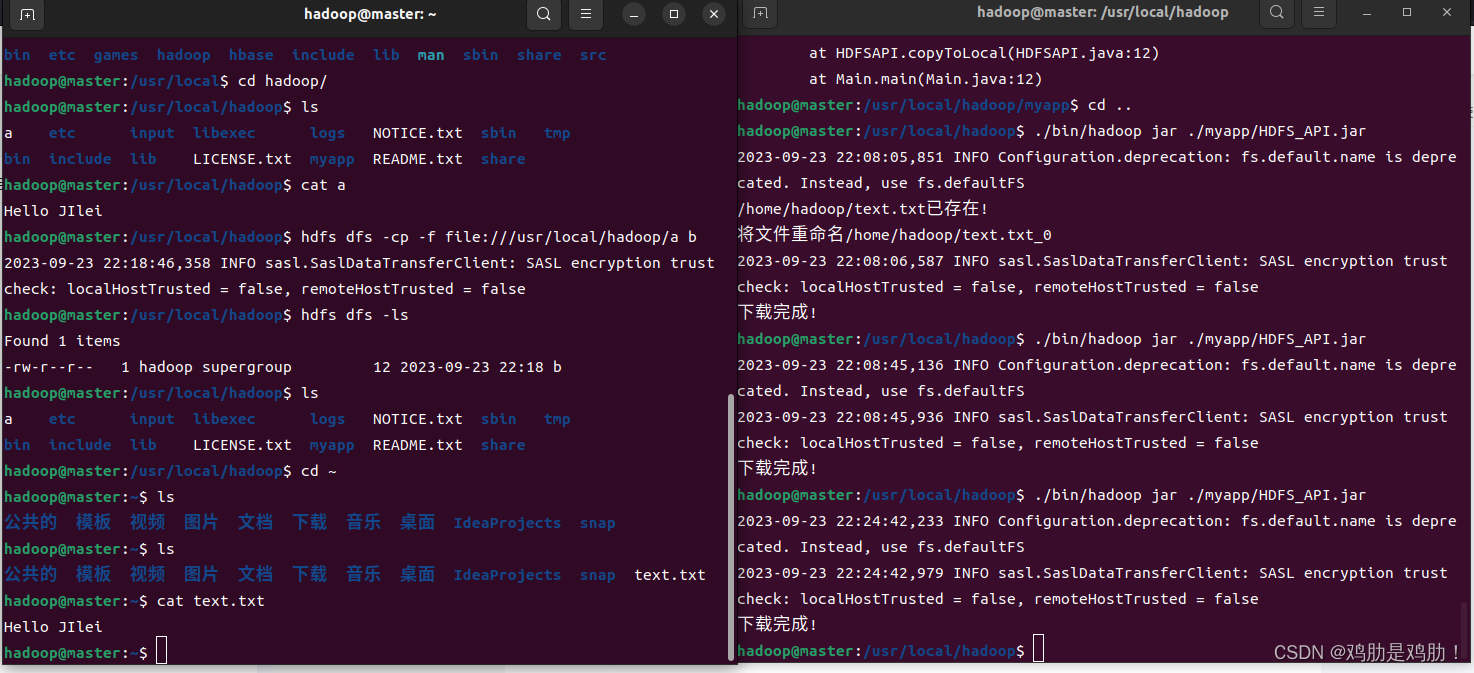
HDFS编程实践-从HDFS中下载指定文件到本地
前言:Hadoop采用java语言开发,提供了Java Api与HDFS进行交互 先要把hadoop的jar包导入到idea中去 为了能编写一个与hdfs交互的java应用程序,一般需要向java工程中添加以下jar包 1)/usr/local/hadoop/share/hadoop/common目录下…...

安防监控视频AI智能分析网关:人流量统计算法的应用场景汇总
TSINGSEE青犀人流量检测算法是内置在智能分析网关中的一种能够通过AI分析和计算人群数量以及密度的算法技术,在提升城市管理效率、改善用户体验和增加安全性方面发挥着重要作用。人流量检测算法在许多领域都有广泛的应用,如智慧城市、智慧交通、智慧景区…...

第一百五十二回 自定义组件综合实例:游戏摇杆三
文章目录 内容回顾优化性能示例代码我们在上一章回中介绍了 如何实现游戏摇杆相关的内容,本章回中将继续介绍这方面的知识.闲话休提,让我们一起Talk Flutter吧。 内容回顾 我们在前面章回中介绍了游戏摇杆的概念以及实现方法,并且通过示例代码演示了实现游戏摇杆的整个过程…...
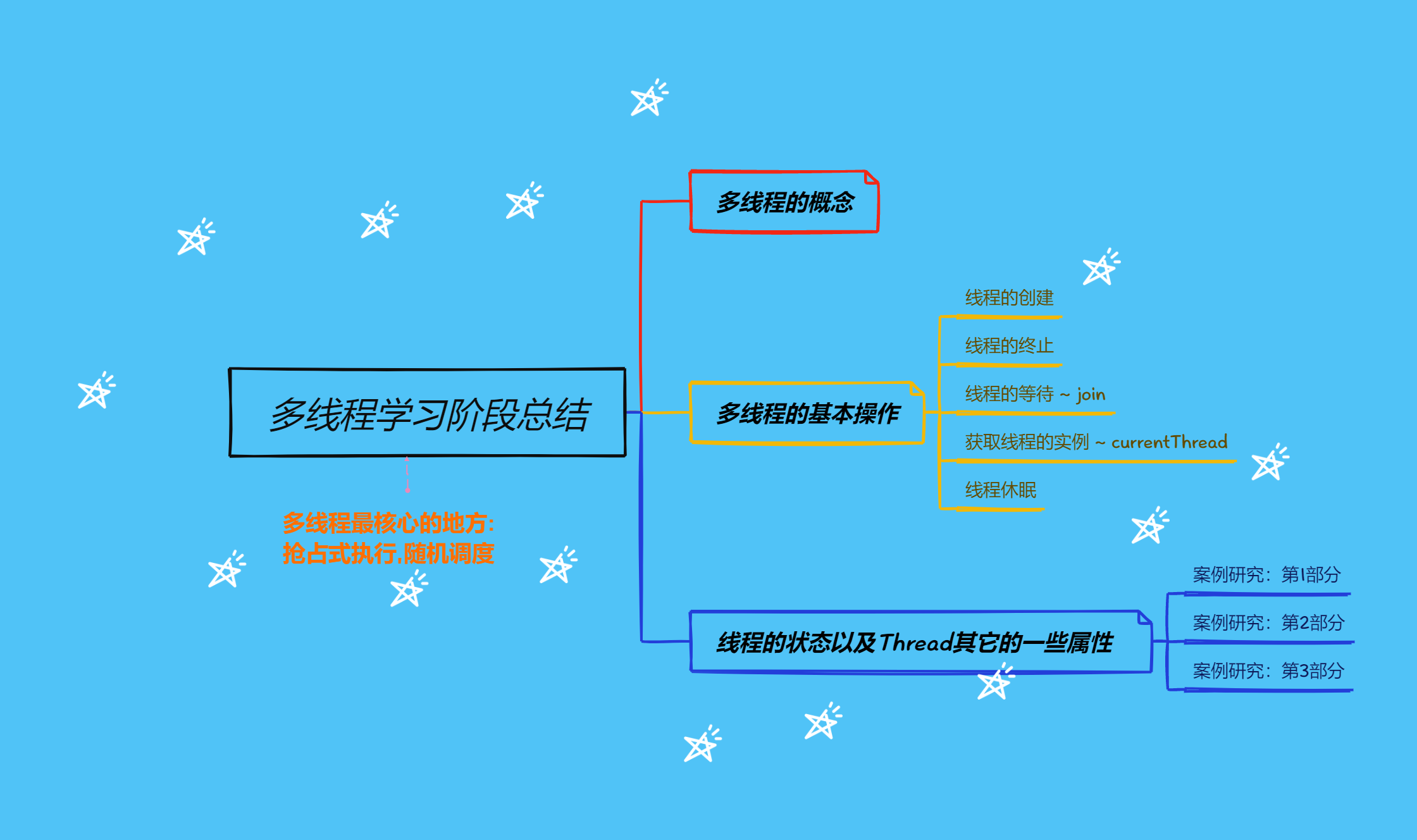
多线程的学习中篇上
终其一生,满是遗憾 知足且坚定,温柔且上进 总之岁月漫长,然而值得等待 获取当前线程引用 方法说明public static Thread currentThread();返回当前线程对象的引用 currentThread() > 在那个线程中, 就能获取到那个线程的实例. static关键…...

非标准化套利
交易对象:目前使用非标准化组合进行交易。(即黄金远近月,焦煤焦炭等等) 交易平台:易盛极星极星产品网 手续费研究:白糖期货手续费和保证金2023年09月更新 - 九期网 本人使用的期货交易公司:中信期货&…...

从CNN(卷积神经网络),又名CAM获取热图
一、说明 卷积神经网络(CNN)令人难以置信。如果你想知道它如何看待世界(图像),有一种方法是可视化它。 这个想法是,我们从最后的密集层中得到权重,然后乘以最终的CNN层。这需要全局平均…...
kafka消费者多线程开发
目录 前言 kafka consumer 设计原理 多线程的方案 参考资料 前言 目前,计算机的硬件条件已经大大改善,即使是在普通的笔记本电脑上,多核都已经是标配了,更不用说专业的服务器了。如果跑在强劲服务器机器上的应用程序依然是单…...

布局设计和实现:计算器UI【TableLayout、GridLayout】
一、使用TableLayout实现计算器UI 1.新建一个空白项目布局 根据自己的需求输入其他信息 填写完成后,点击Finish即可 2. 设计UI界面 在res/layout文件夹中的XML文件中创建UI界面。在这个XML文件中,您可以使用TableLayout来设计计算器界面。 2.1 创建l…...
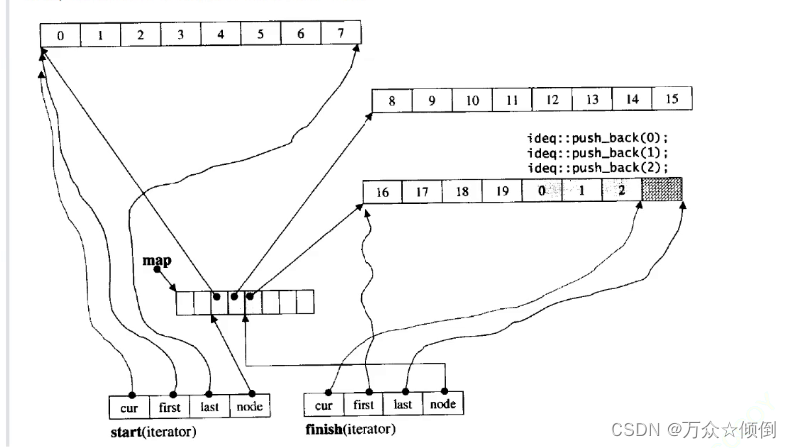
stack与queue的简单封装
前言: stack与queue即栈和队列,先进后出/先进先出的特性我们早已了然于心, 在学习数据结构时,我们利用c语言实现栈与队列,从结构体写起,利用数组或指针表示他们的数据成员,之后再一个个实现他们…...
)
从‘Hello World’到打开PRT文件:一个完整的NX C++外部exe开发入门实战(VS2015 + NX12)
从‘Hello World’到打开PRT文件:一个完整的NX C外部exe开发入门实战(VS2015 NX12) 在工业设计领域,NX(原Unigraphics)作为一款功能强大的CAD/CAM/CAE软件,其二次开发能力为工程师提供了极大的…...
ElementUI Transfer穿梭框数据回填全攻略:编辑时如何优雅地还原选中状态?
ElementUI Transfer穿梭框数据回填实战:编辑场景下的状态还原艺术 在后台管理系统开发中,权限配置、内容关联等场景频繁使用穿梭框组件。ElementUI的Transfer组件凭借直观的双栏设计和丰富的API,成为这类需求的首选解决方案。但许多开发者在编…...

基于大语言模型的网页自动化智能体:Elsa OpenClaw 实战指南
1. 项目概述与核心价值 最近在折腾一些自动化流程,发现很多重复性的网页操作,比如数据抓取、表单填写、状态监控,手动来做不仅耗时,还容易出错。于是我开始寻找一个能真正理解网页结构、像人一样操作浏览器的工具。市面上有不少自…...

2026届毕业生推荐的降重复率平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下AIGC产业落地的进程里面,冗余算力的消耗,以及无效生成输出所导…...

Windows驱动存储深度管理:DriverStore Explorer专业指南
Windows驱动存储深度管理:DriverStore Explorer专业指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 在Windows系统维护的众多任务中,驱动程序管理往往是最容…...
)
艾尔登法环黑夜君临修改器2026.5.11最新中文汉化版免费下载 转存后自动更新 (看到请立即转存 资源随时失效)
在《艾尔登法环》的庞大世界观下,一款名为《艾尔登法环:黑夜君临》(ELDEN RING NIGHTREIGN)的衍生作品于 2025 年正式登场。它并非单纯的续作或大型 DLC,而是一款基于原作设定、专注于多人协作生存与浓缩化 RPG 体验的…...
实战对比:我们团队为什么最终选了它?)
Davinci vs. 其他开源BI工具(Superset/Metabase)实战对比:我们团队为什么最终选了它?
Davinci vs. 其他开源BI工具实战对比:技术选型的深度思考 在数据驱动决策的时代,企业级BI工具的选择直接影响着数据分析的效率和深度。当我们团队面临开源BI工具选型时,Davinci、Apache Superset和Metabase成为了主要候选对象。经过三个月的实…...
)
Red Cabbage印相仅限Pro订阅者访问?不!本文泄露未公开的--raw+--v 6.2双模触发密钥(含Base64校验码验证)
更多请点击: https://intelliparadigm.com 第一章:Red Cabbage印相的技术本质与社区误读 Red Cabbage印相(Red Cabbage Cyanotype)并非传统蓝晒法的简单变体,而是一种基于花青素pH响应特性的光化学显影体系。其核心反…...

NCM音乐解锁终极指南:3步实现网易云音乐格式自由转换
NCM音乐解锁终极指南:3步实现网易云音乐格式自由转换 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密文件无法在其他播放器使用而烦恼吗?ncmdump解密工具让你轻松突破格式限制&…...

基于Python的Discord机器人开发:从自动化管理到插件化架构实战
1. 项目概述:一个为Discord社区量身打造的智能助手 如果你在运营一个Discord服务器,无论是游戏公会、技术社区还是兴趣小组,肯定遇到过这样的场景:新成员加入后,需要手动发送欢迎消息、引导他们阅读规则;成…...