R语言绘制PCA双标图、碎石图、变量载荷图和变量贡献图
1、原论文数据双标图
代码:
setwd("D:/Desktop/0000/R") #更改路径#导入数据
df <- read.table("Input data.csv", header = T, sep = ",")# -----------------------------------
#所需的包:
packages <- c("ggplot2", "tidyr", "dplyr", "readr", "ggrepel", "cowplot", "factoextra")
#安装你尚未安装的R包
installed_packages <- packages %in% rownames(installed.packages())
if (any(installed_packages == FALSE)) {install.packages(packages[!installed_packages])
}
invisible(lapply(packages, library, character.only = TRUE))# -----------------------------------
# 设置一些颜色、文字的基础设置
# Colors:
CatCol <- c(CSH = "#586158", DBF = "#C46B39", EBF = "#4DD8C0", ENF = "#3885AB", GRA = "#9C4DC4",MF = "#C4AA4D", OSH = "#443396", SAV = "#CC99CC", WET = "#88C44D", WSA = "#AB3232"
)
Three_colorblind <- c("#A8AD6F", "#AD6FA8", "#6FA8AD") #c("#809844", "#4f85b0", "#b07495")
graph_elements_dark <- "black"
plot_elements_light <- "gray75"
plot_elements_dark <- "gray25"# Transparency:
boot_alpha_main <- 0.9
boot_alpha_small <- 0.05# Text:
# if (n_pcs > 3) {x_angle <- 270; x_adjust <- 0.25} else {x_angle <- 0; x_adjust <- 0} # option to change orientation of x axis text
x_angle <- 0; x_adjust <- 0
title_text <- 9 # Nature Communications: max 7 pt; cowplot multiplier: 1/1.618; 7 pt : 1/1.618 = x pt : 1; x = 7 / 1/1.618; x = 11.326 (round up to integer)
subtitle_text <- 9
normal_text <- 9 # Nature Communications: min 5 pt; cowplot multiplier: 1/1.618; 5 pt : 1/1.618 = x pt : 1; x = 5 / 1/1.618; x = 8.09 (round up to integer)# Element dimensions:
plot_linewidth <- 0.33
point_shape <- 18
point_size <- 1.5# Initialize figure lists:
p_biplot <- list(); p_r2 <- list(); p_load <- list(); p_contr <- list(); col_ii <- list()# Labels:
veg_sub_labels <- c("All Sites", "All Forests", "Evergreen Needle-Forests") # -----------------------------------
#选择PCA所需的数据
codes_4_PCA <- c("SITE_ID", "IGBP", "GPPsat", "wLL", "wNmass", "wLMA", "RECOmax") # 选择需要的列数据
#执行筛选
df_subset <- df %>%dplyr::select(all_of(codes_4_PCA))
#运行PCA。dplyr::select(-species):将不需要的列数据去除
pca_result <- FactoMineR::PCA(df_subset %>% dplyr::select(-SITE_ID, -IGBP), scale.unit = T, ncp = 10, graph = F)# -----------------------------------
#绘图
p1<- fviz_pca_biplot(pca_result,axes = c(1, 2),col.ind = df_subset$IGBP, #"grey50",# col.ind = NA, #plot_elements_light, #"white",geom.ind = "point",palette = CatCol,#'futurama',label = "var",col.var = plot_elements_dark,labelsize = 3,repel = TRUE,pointshape = 16,pointsize = 2,alpha.ind = 0.67,arrowsize = 0.5)# -----------------------------------
# 它是ggplot2对象,我们在此基础上进一步修改一下标注。
p1<-p1+labs(title = "",x = "PC1",y = "PC2",fill = "IGBP") +guides(fill = guide_legend(title = "")) +theme(title = element_blank(),text = element_text(size = normal_text),axis.line = element_blank(),axis.ticks = element_blank(),axis.title = element_text(size = title_text, face = "bold"),axis.text = element_text(size = normal_text),#plot.margin = unit(c(0, 0, 0, 0), "cm"),# legend.position = "none"legend.text = element_text(size = subtitle_text),legend.key.height = unit(5, "mm"),legend.key.width = unit(2, "mm"))
p1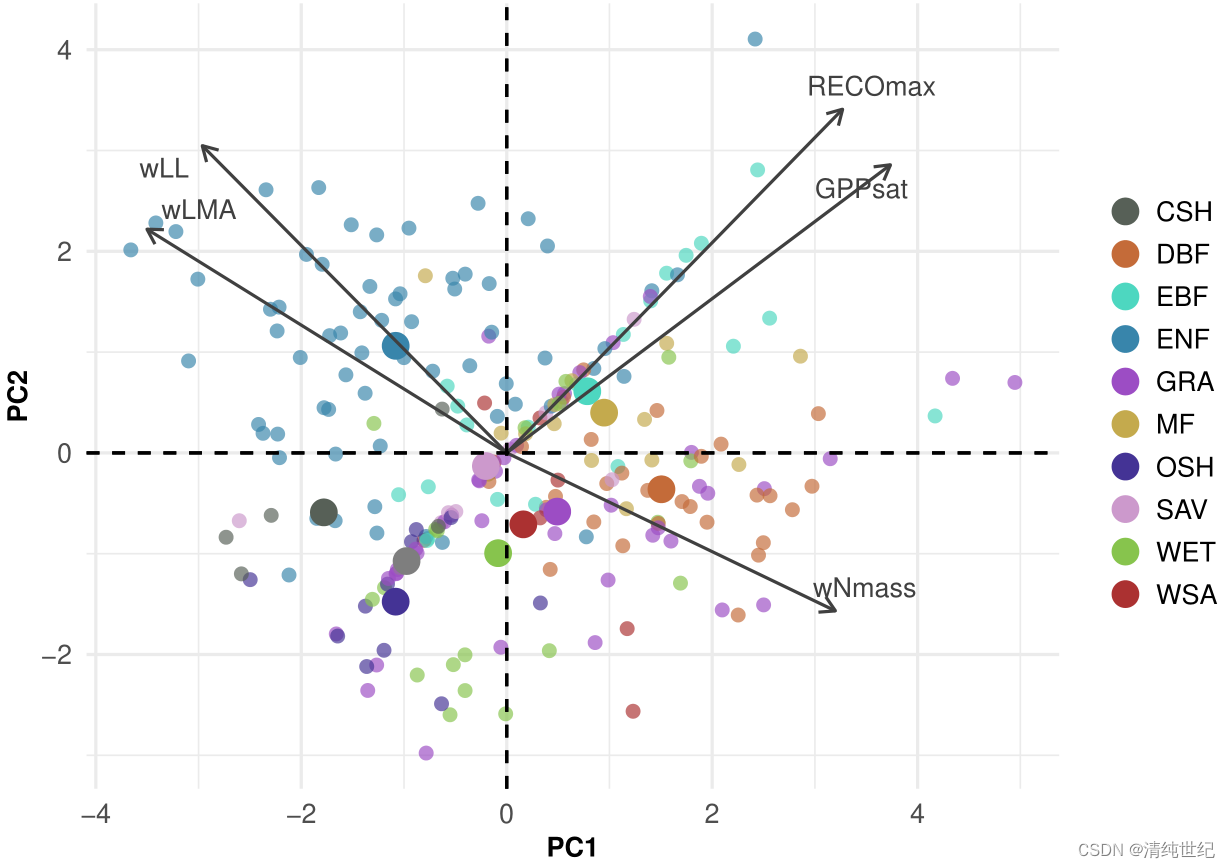
参考:Leaf-level coordination principles propagate to the ecosystem scale (https://doi.org/10.1038/s41467-023-39572-5)、主成分分析图。
2、我选用iris数据进行重新绘制测试双标图
代码:
setwd("D:/Desktop/0000/R") #更改路径#导入数据
df <- read.table("iris1.csv", header = T, sep = ",")# -----------------------------------
#所需的包:
packages <- c("ggplot2", "tidyr", "dplyr", "readr", "ggrepel", "cowplot", "factoextra")
#安装你尚未安装的R包
installed_packages <- packages %in% rownames(installed.packages())
if (any(installed_packages == FALSE)) {install.packages(packages[!installed_packages])
}
invisible(lapply(packages, library, character.only = TRUE))# -----------------------------------
# 设置一些颜色、文字的基础设置
# Colors:
CatCol <- c(setosa = "#586158", versicolor = "#C46B39", virginica = "#4DD8C0") # 设置类别颜色
Three_colorblind <- c("#A8AD6F", "#AD6FA8", "#6FA8AD") #c("#809844", "#4f85b0", "#b07495")
graph_elements_dark <- "black"
plot_elements_light <- "gray75"
plot_elements_dark <- "gray25"# Transparency:
boot_alpha_main <- 0.9
boot_alpha_small <- 0.05# Text:
# if (n_pcs > 3) {x_angle <- 270; x_adjust <- 0.25} else {x_angle <- 0; x_adjust <- 0} # option to change orientation of x axis text
x_angle <- 0; x_adjust <- 0
title_text <- 9 # Nature Communications: max 7 pt; cowplot multiplier: 1/1.618; 7 pt : 1/1.618 = x pt : 1; x = 7 / 1/1.618; x = 11.326 (round up to integer)
subtitle_text <- 9
normal_text <- 9 # Nature Communications: min 5 pt; cowplot multiplier: 1/1.618; 5 pt : 1/1.618 = x pt : 1; x = 5 / 1/1.618; x = 8.09 (round up to integer)# Element dimensions:
plot_linewidth <- 0.33
point_shape <- 18
point_size <- 1.5# Initialize figure lists:
p_biplot <- list(); p_r2 <- list(); p_load <- list(); p_contr <- list(); col_ii <- list()# Labels:
veg_sub_labels <- c("All Sites", "All Forests", "Evergreen Needle-Forests") # -----------------------------------
#选择PCA所需的数据
codes_4_PCA <- c("sepal_length", "sepal_width", "petal_length", "petal_width", "species") # 选择需要的列数据
#执行筛选
df_subset <- df %>%dplyr::select(all_of(codes_4_PCA))
#运行PCA。dplyr::select(-species):将不需要的列数据去除
pca_result <- FactoMineR::PCA(df_subset %>% dplyr::select(-species), scale.unit = T, ncp = 10, graph = F)# -----------------------------------
#绘图
p1<- fviz_pca_biplot(pca_result,axes = c(1, 2),col.ind = df_subset$species, #"grey50",# col.ind = NA, #plot_elements_light, #"white",geom.ind = "point",palette = CatCol,#'futurama',label = "var",col.var = plot_elements_dark,labelsize = 3,repel = TRUE,pointshape = 16,pointsize = 2,alpha.ind = 0.67,arrowsize = 0.5)# -----------------------------------
# 它是ggplot2对象,我们在此基础上修改一下标注。
p1<-p1+labs(title = "",x = "PC1",y = "PC2",fill = "IGBP") +guides(fill = guide_legend(title = "")) +theme(title = element_blank(),text = element_text(size = normal_text),axis.line = element_blank(),axis.ticks = element_blank(),axis.title = element_text(size = title_text, face = "bold"),axis.text = element_text(size = normal_text),#plot.margin = unit(c(0, 0, 0, 0), "cm"),# legend.position = "none"legend.text = element_text(size = subtitle_text),legend.key.height = unit(5, "mm"),legend.key.width = unit(2, "mm"))
p1
3、iris数据进行绘制碎石图、变量载荷图、变量贡献图
代码:
#加载包
library(dplyr) #用于数据预处理
library(tidyr) #用于数据预处理
library(stringr) #用于字符串处理
library(modelr) #用于自助法重抽样
library(FactoMineR) #用于PCA
library(ade4) #用于PCA
library(factoextra) #用于PCA结果提取及绘图
#所需的包:
packages <- c("ggplot2", "tidyr", "dplyr", "readr", "ggrepel", "cowplot", "factoextra")
#安装你尚未安装的R包
installed_packages <- packages %in% rownames(installed.packages())
if (any(installed_packages == FALSE)) {install.packages(packages[!installed_packages])
}
invisible(lapply(packages, library, character.only = TRUE))setwd("D:/Desktop/0000/R") #更改路径
# 加载数据
df <- read.csv("iris.csv",header = T, row.names = 1) # row.names = 1: 第一列为标签,这时赋值给df时就没有这列了#重抽样
set.seed(123) #设置随机种子
tt=99 #设置重抽样的次数。iris[,-5]:表示去除第5列,因为这是类别
df_boot <- iris[,-5] %>% modelr::bootstrap(n = tt) #重抽样,结果是一个列表,包含499个数据框#使用循环对每一个数据集进行PCA
#初始化3个空变量
N_PCS <- tibble() #使用维数检验保留的PC数量
pca_stats <- tibble() #变量的贡献和载荷
R2 <- c() #解释方差占比#使用循环对每一个数据集进行PCA
#初始化3个空变量
N_PCS <- tibble() #使用维数检验保留的PC数量
pca_stats <- tibble() #变量的贡献和载荷
R2 <- c() #解释方差占比#循环
for (j in 1:tt) {##提取第j次bootstrap的数据dat <- df_boot %>% slice(j) %>% # 选择第j行pull(strap) %>% # 提取列表as.data.frame() # 提取数据集#使用FactoMineR包执行PCApca_result <- FactoMineR::PCA(dat, scale.unit = T, ncp = 4, graph = F) # ncp = 4:降维几个主成分,设置最大即为全部#使用ade4包执行PCA# center:指定是否对数据进行中心化,默认为 TRUE。中心化意味着将数据减去各自的均值,使得数据在每个维度上的平均值为零。# scale:指定是否对数据进行缩放,默认为 TRUE。缩放意味着将数据除以各自的标准差,使得数据在每个维度上的标准差为一。# scannf:指定是否计算特征值和特征向量,默认为 FALSE。如果设置为 TRUE,则会计算特征值和特征向量。pca1 <- ade4::dudi.pca(dat, center = TRUE, scale = TRUE, scannf = FALSE, nf = 4) # nf= 4:降维几个主成分,设置最大即为全部#检测不确定性和显著性#执行维数检验pc_tested <-testdim(pca1, nrepet = 999)###提取bootstrap数据集的PCA结果N_PCS <- N_PCS %>% bind_rows(tibble(strap = j, n_pcs = pc_tested$nb.cor)) #第j次运行的PCApca_stats <- bind_rows(pca_stats,pca_result$var$contrib %>% # add contributionsas_tibble(rownames = "var") %>%pivot_longer(cols = !var, names_to = "PC", values_to = "contrib") %>% left_join(pca_result$var$coord %>% # add loadingsas_tibble(rownames = "var") %>%pivot_longer(cols = !var, names_to = "PC", values_to = "loading"),by = c("var", "PC")) %>% mutate(PC = str_sub(PC, start = 5), #提取PC名称中的数字strap = j) # bootstrap run number) #得到变量贡献和载荷R2 <- bind_rows(R2,tibble(PC = pca_result[["eig"]]%>% rownames(),exp_var = pca_result[["eig"]][,2],strap = j) %>% mutate(PC = str_sub(PC, start = 6)) #提取PC名称中的数字)
}#保留的PC数量
N_PCS <- N_PCS %>%group_by(n_pcs) %>% summarise(n_rep = n()) %>% #对重复值进行计数mutate(retained = n_rep / tt * 100) #计算运行次数百分比
pc_ret <- N_PCS %>% filter(retained == max(retained))
#输出结果的摘要
print(paste0("Number of statistical significant components according to Dray method (Dray et al., 2008) was ",pc_ret[1,1], " in ", round(pc_ret[1,3], digits = 1), "% of runs."))n_pcs <- NA #保留PC数的初始设置
# n_pcs <- 2 #可以手动设置保留PC数
if (is.na(n_pcs)) {n_pcs <- N_PCS %>% filter(retained == max(retained)) %>% select(n_pcs) %>% unlist() %>% unname()
} #按照Dray等人的方法设置保留PC数##变量贡献和载荷
pca_stats <- pca_stats %>% group_by(PC, var) %>% mutate(contrib_mean = mean(contrib),contrib_median = median(contrib),contrib_std = sd(contrib),# contrib_q25 = quantile(contrib, 0.25), contrib_q75 = quantile(contrib, 0.75),loading_mean = mean(loading),loading_median = median(loading),loading_std = sd(loading),# loading_q25 = quantile(loading, 0.25), loading_q75 = quantile(loading, 0.75)) %>% ungroup() %>% dplyr::rename(contrib_boot = contrib, loading_boot = loading) #重命名以免后续的匹配过程出现混乱##修改PC名称
pca_stats <- pca_stats %>%mutate(PC_name = paste0("PC", PC))##解释方差占比
R2 <- R2 %>% group_by(PC) %>% mutate(R2_mean = mean(exp_var),R2_median = median(exp_var),R2_std = sd(exp_var),# R2_q25 = quantile(exp_var, 0.25), R2_q75 = quantile(exp_var, 0.75)) %>% ungroup() %>% dplyr::rename(R2_boot = exp_var) #重命名以免后续的匹配过程出现混乱##添加到pca_stats的表格中
pca_stats <- pca_stats %>% left_join(R2, by = c("PC", "strap"))#对原始数据的PCA
pca_result <- FactoMineR::PCA(iris[,-5], scale.unit = T, ncp = 4, graph = F)#添加原始数据计算得到的实际值
pca_stats <- pca_stats %>% dplyr::left_join( #添加原始数据的R2(不是bootstrapping的均值)tibble(PC = pca_result[["eig"]] %>% rownames(),R2 = pca_result[["eig"]][,2]) %>% mutate(PC = str_sub(PC, start = 6)), #提取PC数by = "PC") %>% dplyr::left_join( #添加原始数据的变量贡献(不是bootstrapping的均值)pca_result$var$contrib %>% #添加贡献as_tibble(rownames = "var") %>%pivot_longer(cols = !var, names_to = "PC", values_to = "contrib") %>% mutate(PC = str_sub(PC, start = 5)), #提取PC数by = c("PC", "var")) %>%dplyr::left_join( #添加原始数据的变量载荷(不是bootstrapping的均值)pca_result$var$coord %>% #添加载荷as_tibble(rownames = "var") %>%pivot_longer(cols = !var, names_to = "PC", values_to = "loading") %>% mutate(PC = str_sub(PC, start = 5)), # extract PC numbersby = c("PC", "var"))## 添加PC数的保留百分比(在自助法中PC被保留得有多频繁)
pca_stats <- pca_stats %>% dplyr::left_join(N_PCS %>% dplyr::mutate(PC = n_pcs %>% as.character) %>% dplyr::select(PC, retained),by = "PC") # -----------------------------------
# 绘制图碎石图
dat_boot <- pca_stats %>%dplyr::select(PC_name, PC, R2_boot) %>% unique()%>% #去除重复dplyr::mutate(PC = as.character(PC))dat_true <- pca_stats %>%dplyr::select(PC_name, PC, R2, R2_median, R2_std) %>% unique() %>% #去除重复dplyr::mutate(PC = as.character(PC))p2 <- ggplot(data = dat_true, aes(x = PC_name, y = R2, group = 1)) + # x = PC -> only numbers on axis, x = PC_name -> can give problems with PC10 being ordered before PC2;# group 1 是用来避免某些warning/error的geom_errorbar(aes(ymin = R2 - R2_std, ymax = R2 + R2_std),color = Three_colorblind[1], linewidth = plot_linewidth, width = 0.4) + # bootstrapping的标准差# geom_bar(stat = "identity", position = position_dodge(), fill = Three_colorblind[1], width = 0.61) + #b07a4f, #9c6a5e, #643c3cgeom_line(color = Three_colorblind[1]) +geom_point(color = Three_colorblind[1], size = point_size) + #实际值geom_jitter(data = dat_boot, aes(x = PC_name, y = R2_boot, group = 1), alpha = 0.1,color = "black", shape = point_shape, size = 0.5, width = 0.1) + #每次自助样本的值geom_point(aes(x = PC_name, y = R2_median), color = plot_elements_dark,alpha = boot_alpha_main, shape = point_shape, size = point_size) + #添加自助法得到的中位数值geom_text(aes(x = PC_name, y = R2 + R2_std + 2, label = paste0(R2 %>% round(digits = 1), "%")),nudge_x = 0.33, size = 2) + #添加数值标注labs(title = "", x = "", y = "Explained variance") +theme_classic() +theme(title = element_blank(),text = element_text(size = normal_text),axis.line = element_line(color = graph_elements_dark),axis.ticks.x = element_line(color = graph_elements_dark),axis.ticks.y = element_blank(),axis.title = element_text(size = title_text, face = "bold"),# axis.title.x = element_blank(), #已经在'labs'中指定axis.text = element_text(size = normal_text),axis.text.y = element_blank(),plot.margin = unit(c(0, 1, 0, 1), "cm"),legend.position = "none") +NULL
p2# -----------------------------------
# 绘制变量载荷图
dat_boot <- pca_stats %>%dplyr::filter(PC <= n_pcs[1]) %>% #去除额外的PCdplyr::select(PC_name, var, loading_boot) %>% unique() #去除重复dat_true <- pca_stats %>%dplyr::filter(PC <= n_pcs[1]) %>% #去除额外的PCdplyr::select(PC_name, var, loading, loading_median, loading_std) %>% unique() #去除重复p3 <- ggplot(data = dat_true, aes(x = var, y = loading)) +facet_grid(. ~ PC_name, scales = "free_y") +geom_errorbar(aes(ymin = loading - loading_std, ymax = loading + loading_std), # loading_q25, ymax = loading_q75color = Three_colorblind[2], linewidth = plot_linewidth, width = 0.9) + # standard error = std from bootstrappinggeom_bar(stat = "identity", position = position_dodge(), fill = Three_colorblind[2]) + #b07a4f, #9c6a5e, #643c3cgeom_hline(yintercept = 0, color = graph_elements_dark) +geom_jitter(data = dat_boot, aes(x = var, y = loading_boot), alpha = boot_alpha_small, color = plot_elements_dark,shape = point_shape, size = 0.2, width = 0.1) + #每次自助抽样的值geom_point(aes(x = var, y = loading_median), alpha = boot_alpha_main, shape = point_shape,size = point_size, color = plot_elements_dark) + #添加自助法得到的中位数值coord_flip() + #对调坐标轴以更好地展示图形scale_y_continuous(breaks = waiver(), n.breaks = 4) + #修改x轴(对调后,这就是y轴)labs(y = "Loadings", x = "", title = "") +theme_classic() +theme(title = element_text(size = normal_text, face = "bold"),text = element_text(size = normal_text),axis.line.x = element_line(color = graph_elements_dark),axis.line.y = element_blank(),axis.ticks.x = element_line(color = graph_elements_dark),axis.ticks.y = element_blank(),axis.title = element_text(size = title_text),axis.text = element_text(size = normal_text),axis.text.x = element_text(angle = x_angle, vjust = x_adjust),legend.position = "none",legend.title = element_text(size = title_text),legend.text = element_text(size = subtitle_text),legend.key.height = unit(1.0, "mm"),legend.key.width = unit(1.0, "mm"),plot.margin = unit(c(0, 0, 0, 0), "cm"),strip.text = element_text(face = "bold", size = title_text),strip.background = element_blank()) +NULL
p3# -----------------------------------
# 绘制变量贡献图
dat_boot <- pca_stats %>%dplyr::filter(PC <= n_pcs[1]) %>% #去除额外的PCdplyr::select(PC_name, var, contrib_boot) %>% unique() #去除重复dat_true <- pca_stats %>%dplyr::filter(PC <= n_pcs[1]) %>% # remove additional PCsdplyr::select(PC_name, var, contrib, contrib_median, contrib_std) %>% unique() #去除重复p4<- ggplot(data = dat_true, aes(x = var, y = contrib)) +facet_grid(. ~ PC_name, scales = "free_y") +geom_errorbar(aes(ymin = contrib_median - contrib_std, ymax = contrib_median + contrib_std), # ymin = contrib_q25, ymax = contrib_q75color = Three_colorblind[3], linewidth = plot_linewidth, width = 0.9) + # standard error = standard deviation from bootstrappinggeom_bar(stat = "identity", position = position_dodge(), fill = Three_colorblind[3]) + #4f85b0, #59918e, #3c6464geom_hline(yintercept = 0, color = graph_elements_dark) +geom_jitter(data = dat_boot, aes(x = var, y = contrib_boot), alpha = boot_alpha_small, color = plot_elements_dark,shape = point_shape, size = 0.2, width = 0.1) + #每次自助抽样的值geom_point(aes(x = var, y = contrib_median), alpha = boot_alpha_main, shape = point_shape,size = point_size, color = plot_elements_dark) + #添加自助法得到的中位数值coord_flip() + #对调坐标轴以更好地展示图形scale_y_continuous(breaks = waiver(), n.breaks = 4) + #添加自助法得到的中位数值labs(y = "Contribution [%]", x = "", title = "") +theme_classic() +theme(title = element_text(size = normal_text, face = "bold"),text = element_text(size = normal_text),axis.line.x = element_line(color = graph_elements_dark),axis.line.y = element_blank(),axis.ticks.x = element_line(color = graph_elements_dark),axis.ticks.y = element_blank(),axis.title = element_text(size = title_text),axis.text = element_text(size = normal_text),axis.text.x = element_text(angle = x_angle, vjust = x_adjust),legend.position = "none",legend.title = element_text(size = title_text),legend.text = element_text(size = subtitle_text),legend.key.height = unit(1.0, "mm"),legend.key.width = unit(1.0, "mm"),# plot.margin = unit(c(0, 0, 0, 0), "cm"),strip.text = element_text(face = "bold", size = title_text),strip.background = element_blank()) +NULL
p4# -----------------------------------
# 拼图
library(patchwork)
p2+p3/p4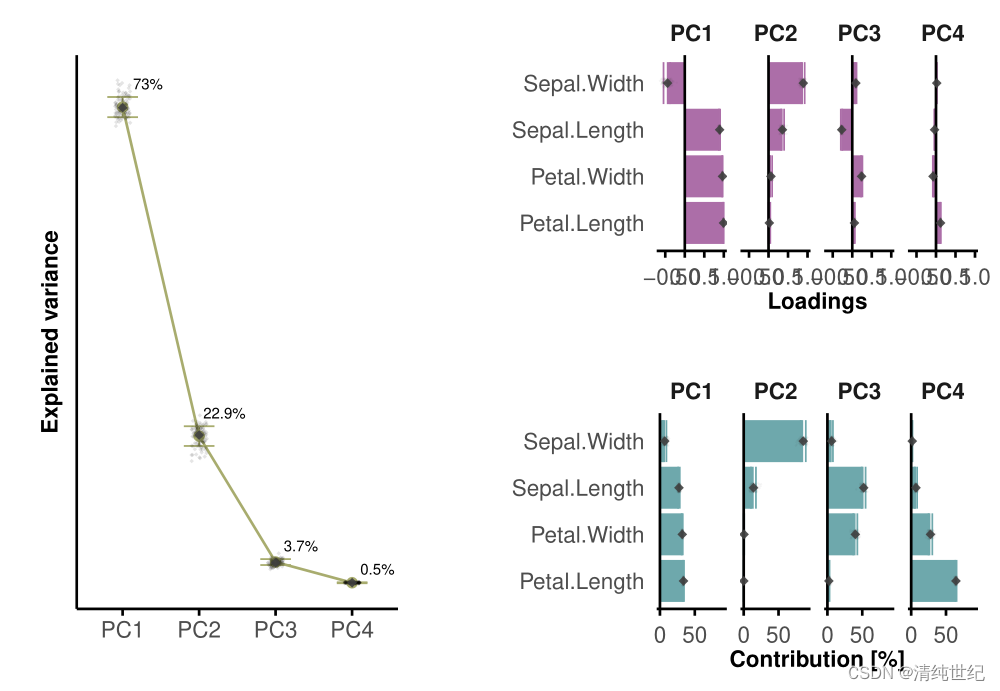
文中用到的数据代码:R语言绘制 PCA 双标图、碎石图、变量载荷图和变量贡献图(self).zip - 蓝奏云
相关文章:
R语言绘制PCA双标图、碎石图、变量载荷图和变量贡献图
1、原论文数据双标图 代码: setwd("D:/Desktop/0000/R") #更改路径#导入数据 df <- read.table("Input data.csv", header T, sep ",")# ----------------------------------- #所需的包: packages <- c("ggplot2&quo…...
)
Jolokia 笔记 (Kafka/start/stop)
目录 1. Jolokia 笔记 (Kafka/start/stop) 1. Jolokia 笔记 (Kafka/start/stop) java -javaagent:agent.jarport8778,hostlocalhostJolokia 是作为 Kafka 的 Java agent, 基于 HTTP 协议提供了一个使用 JSON 作为数据格式的外部接口, 提供给 DataKit 使用。 Kafka 启动时, 先配…...
Qt5开发及实例V2.0-第十九章-Qt.QML编程基础
Qt5开发及实例V2.0-第十九章-Qt.QML编程基础 第19章 QML编程基础19.1 QML概述19.1.1 第一个QML程序19.1.2 QML文档构成19.1.3 QML基本语法 19.2 QML可视元素19.2.1 Rectangle(矩形)元素19.2.2 Image(图像)元素19.2.3 Text…...

固定开发板的ifconfig的IP地址
背景 由于我是使用vsocode的ssh插件远程连接我的开发板, 所以我每次开机就要重新连上屏幕看一下这个ifconfig的ip地址然后更改我的ssh config文件 这里提供一个使用nmcli设置静态IP的方法 请确保使用你的实际连接名称替换Wi-Fi connection 1 使用nmcli设置静态IP相对直接&a…...

停车场系统源码
源码下载地址(小程序开源地址):停车场系统小程序,新能源电动车充电系统,智慧社区物业人脸门禁小程序: 【涵盖内容】:城市智慧停车系统,汽车新能源充电,两轮电动车充电,物…...

R语言贝叶斯MCMC:GLM逻辑回归、Rstan线性回归、Metropolis Hastings与Gibbs采样算法实例...
原文链接:http://tecdat.cn/?p23236 在频率学派中,观察样本是随机的,而参数是固定的、未知的数量(点击文末“阅读原文”获取完整代码数据)。 相关视频 什么是频率学派? 概率被解释为一个随机过程的许多观测…...
若依前后端分离如何解决匿名注解启动报错?
SpringBoot2.6.0默认是ant_path_matcher解析方式,但是2.6.0之后默认是path_pattern_parser解析方式。 所以导致读取注解类方法需要对应的调整,当前若依项目默认版本是2.5.x,如果使用大于2.6.x,需要将info.getPatternsCondition().getPatterns()修改为info.getPathPatterns…...

Spring面试题4:面试官:说一说Spring由哪些模块组成?说一说JDBC和DAO之间的联系和区别?
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:说一说Spring由哪些模块组成? Spring是一个开源的Java框架,由多个模块组成,每个模块都提供不同的功能和特性。下面是Spring框架的主要模块: S…...
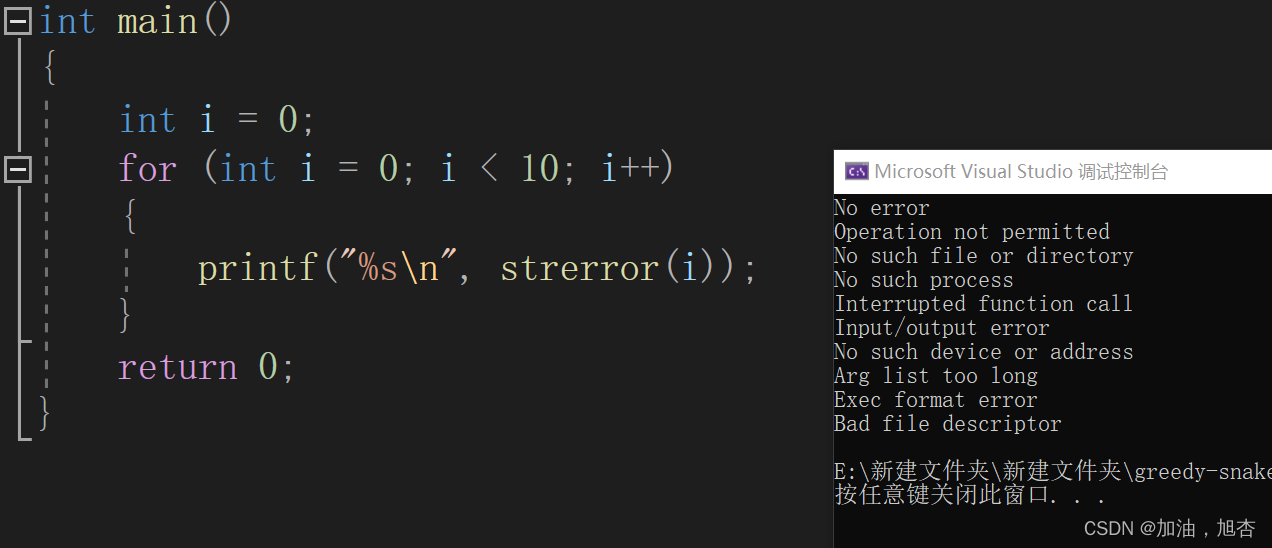
【再识C进阶3(上)】详细地认识字符串函数、进行模拟字符串函数以及拓展内容
小编在写这篇博客时,经过了九一八,回想起了祖国曾经的伤疤,勿忘国耻,振兴中华!加油,逐梦少年! 前言 💓作者简介: 加油,旭杏,目前大二,…...

docker启动mysql8目录挂载改动
5.7版本: 拉取mysql镜像 docker pull mysql:5.7启动 docker run -p 3306:3306 --name mysql5 \ -v /Users/zhaosichun/data/dockerData/log:/var/log/mysql \ -v /Users/zhaosichun/data/dockerData/data:/var/lib/mysql \ -v /Users/zhaosichun/data/dockerData…...
CHATGPT中国免费网页版有哪些-CHATGPT中文版网页
CHATGPT中国免费网页版,一个强大的人工智能聊天机器人。如果你曾经感到困惑、寻求答案,或者需要一些灵感,那么CHATGPT国内网页版可能会成为你的好朋友。 CHATGPT国内免费网页版:你的多面“好朋友” 随着人工智能技术的不断发展&a…...

docker network create命令
docker network create命令用于创建一个新的网络连接。 DRIVER接受内置网络驱动程序的桥接或覆盖。如果安装了第三方或自己的自定义网络驱动程序,则可以在此处指定DRIVER。 如果不指定--driver选项,该命令将为您自动创建一个桥接网络。 当安装Docker Eng…...
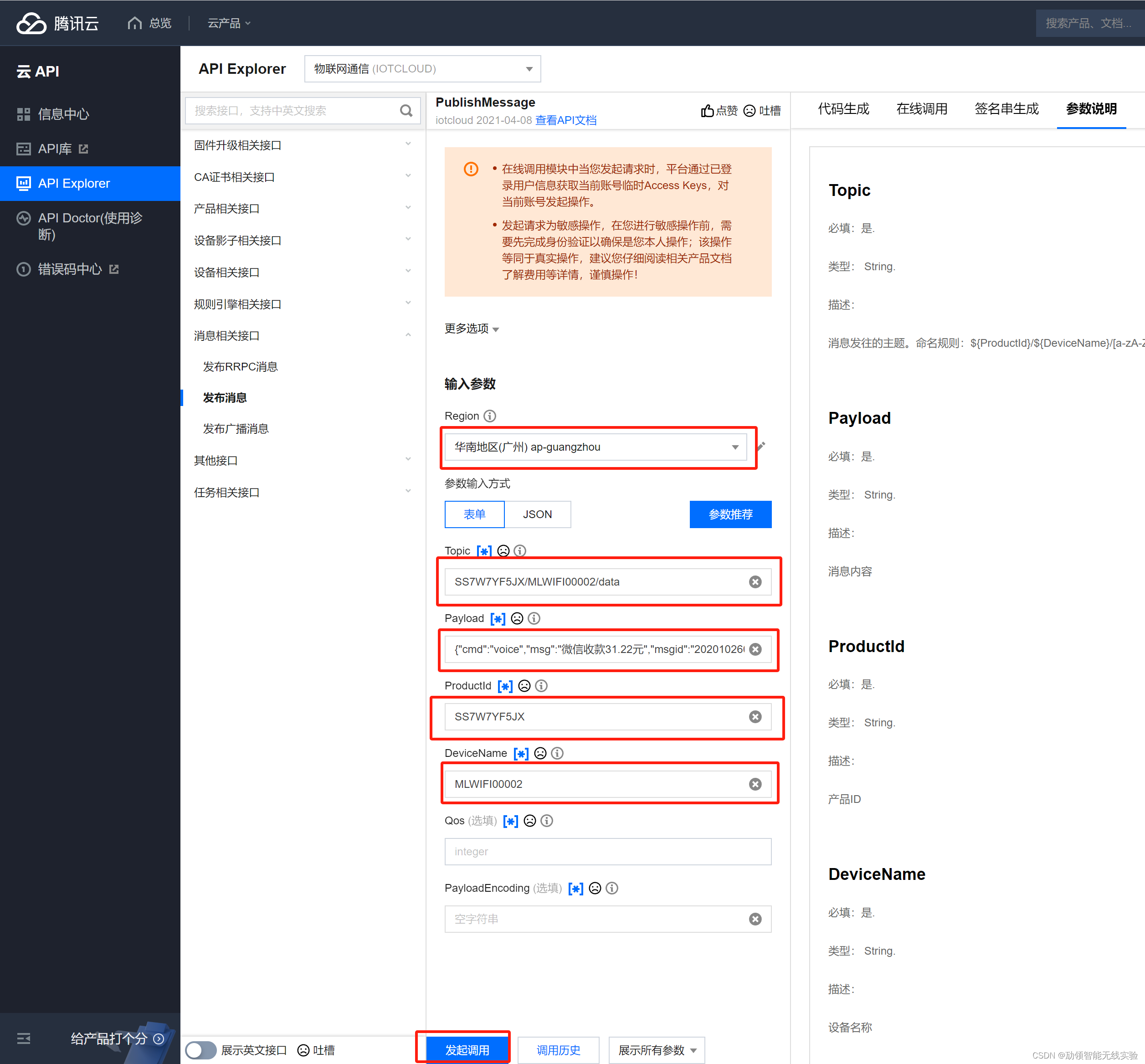
4G版本云音响设置教程腾讯云平台版本
文章目录 4G本云音响设置教程介绍一、申请设备三元素1.腾讯云物联网平台2.创建产品3.设置产品参数4.添加设备5.获取三元素 二、设置设备三元素1.打开MQTTConfigTools2.计算MQTT参数3.使用USB连接设备4.设置参数 三、腾讯云物联网套件协议使用说明1.推送协议信息2.topic规则说明…...
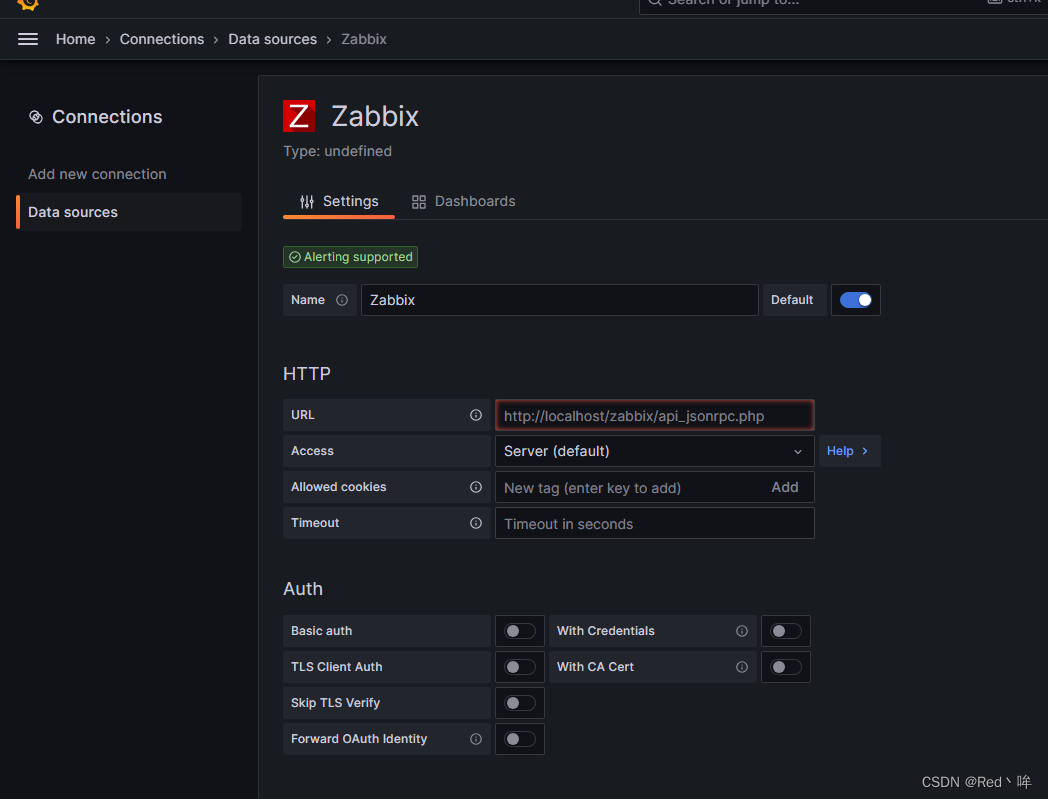
Grafana离线安装部署以及插件安装
Grafana是一个可视化面板(Dashboard),有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持Graphite、zabbix、InfluxDB、Prometheus和OpenTSDB作为数据源。Grafana主要特性:灵活丰富的图形…...

非独立随机变量的概率上界估计
目前的概率论或者随机变量书籍过分强调对独立随机变量的大数定律,中心极限定理,遗憾上界的估计。而对于非独立随机变量的研究很少,在《概率论的极限定理》中曾给出过一般随机变量求和的渐进分布簇的具体形式,然而形式却太过复杂。…...

常见电子仪器及其用途
常见电子仪器及其用途包括: 示波器:示波器是一种用途十分广泛、易于使用且功能强大的电子测量仪器。它能把肉眼看不见的电信号变换成看得见的图像,便于我们研究各种电现象的变化过程。示波器可以直接用来测量电信号的波形,是电子…...

配置测试ip、正式ip、本地ip
目的:npm run serve启动本地服务,npm run test打包测试环境,npm run build打包正式环境。 具体做法如下: 一、在项目中新增三个环境的文件 .env.development VITE_BASE_URLhttp://192.168.1.12:8080/ .env.production VITE_…...
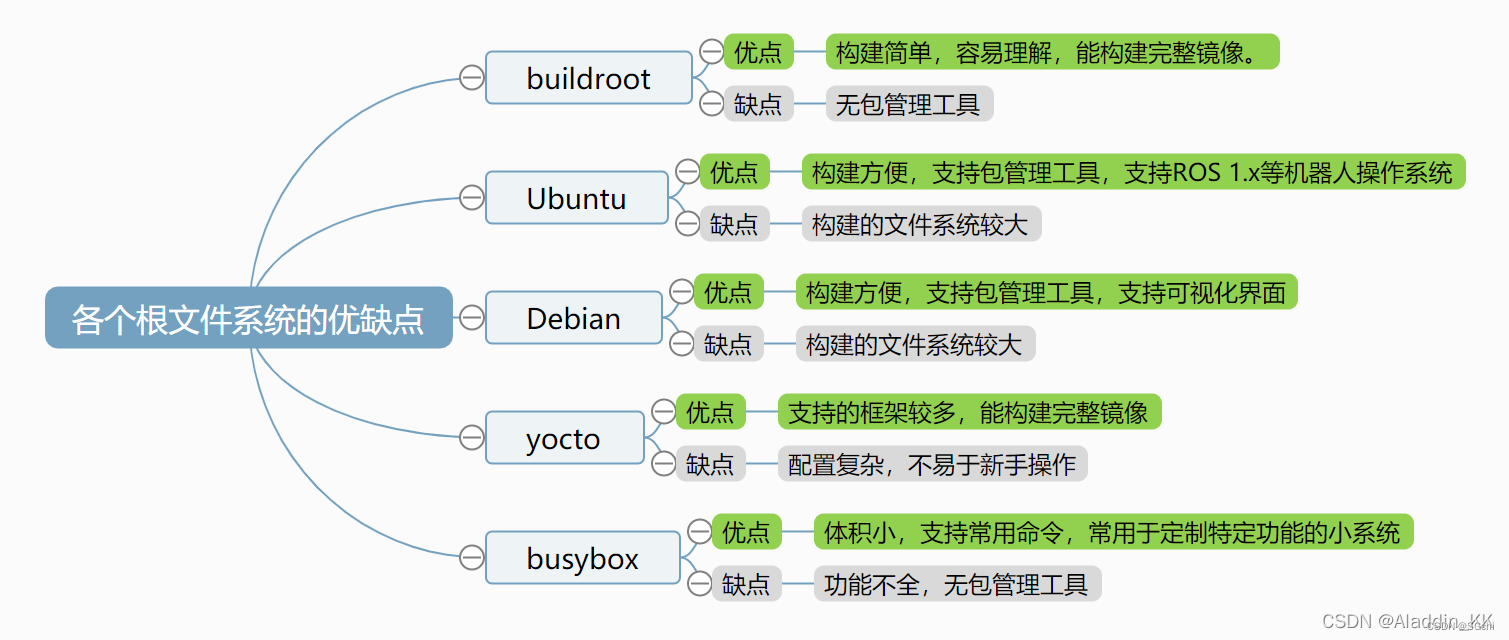
Linux 系统移植(一)-- 系统组成
参考资料: linux系统移植篇(一)—— linux系统组成【野火Linux移植篇】1-uboot初识与编译/烧录步骤 文章目录 一、linux系统组成二、Uboot三、Linux内核四、设备树 本篇为Linux系统移植系列的第一篇文章,介绍了一个完整可运行的L…...

利用git的贮藏功能
可以将自己分支的当前状态贮藏切换到其它分支再切换回来的时候,应用就行了...

第52节:cesium 3DTiles模型特效+选中高亮(含源码+视频)
结果示例: 完整源码: <template><div class="viewer"><vc-viewer @ready="ready" :logo="false"><vc-navigation...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...

Altium Designer实战:用xSignals搞定DDR4内存的等长布线,告别时序烦恼
Altium Designer实战:用xSignals实现DDR4内存精准等长布线 在高速PCB设计中,DDR4内存接口的布线一直是硬件工程师面临的技术高地。当信号速率突破2400MHz时,地址、命令与数据线之间哪怕几个ps的时序偏差都可能导致系统不稳定。传统手工计算网…...

Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案
Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费…...

如何快速解密网易云NCM文件:终极免费转换工具指南
如何快速解密网易云NCM文件:终极免费转换工具指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲,…...

Godot游戏集成Discord状态:RPC插件原理与实战指南
1. 项目概述:在Godot引擎中点亮你的Discord状态 如果你是一名独立游戏开发者,或者正在用Godot引擎捣鼓一些有趣的个人项目,你可能会想让你的朋友或社区成员知道你现在正在“玩”什么。不是通过截图发到社交媒体,而是更实时、更优…...

飞书自动化开发实战:从脚本编写到事件驱动架构设计
1. 项目概述:飞书自动化,从“手动挡”到“自动驾驶”的进化 如果你每天的工作,有超过30%的时间是在飞书里重复着“点击-填写-发送”的枯燥操作,比如手动拉取数据生成日报、定时向群聊推送消息、或者根据特定条件审批流程…...

Python自动化股票分析工具:从数据采集到可视化报告全流程实战
1. 项目概述:一个面向个人投资者的自动化股票分析工具如果你和我一样,是个对A股市场有点兴趣,但又没时间天天盯盘的上班族,那你肯定也经历过这种纠结:早上开盘前想看看心仪的几只股票有没有什么异动,结果一…...

MCP服务器自动发现与管理工具mcpfinder详解
1. 项目概述:一个用于发现与管理MCP服务器的工具如果你正在构建或使用基于模型上下文协议(Model Context Protocol, 简称MCP)的应用,那么你很可能遇到过这样的困扰:手头有几个不同功能的MCP服务器ÿ…...

PAC技术演进与核心趋势:从多域控制到边缘智能的工业自动化平台
1. 项目概述:为什么今天还要聊PAC?如果你在工业自动化、楼宇控制或者任何涉及逻辑控制的领域工作,那么“PAC”这个词对你来说应该不陌生。但很多时候,它就像一个熟悉的陌生人——大家好像都知道它,但真要细说它现在发展…...