李航老师《统计学习方法》第1章阅读笔记
1.1 统计学习
-
统计学习的特点
统计学习:计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析
现在人们提及机器学习时,往往指统计机器学习,所以可以认为本书介绍的是机器学习方法 -
统计学习的对象
统计学习研究的对象是数据(data),统计学习关于数据的基本假设是同类数据具有一定的统计规律性,这是统计学习的前提。
e.g.用随机变量描述数据的特征,用概率分布描述数据的统计规律
在统计学习中,以变量或变量组表示数据,数据分为连续变量或离散变量,本书主要讨论离散变量的方法且本书只关注利用数据构建模型及利用模型对数据进行分析与预测,对数据的观测和收集等问题不讨论 -
统计学习的目的
统计学习的总目标就是考虑学习什么样的模型和如何学习模型,使模型能对数据进行准确的预测与分析(也要考虑学习效率) -
统计学习的方法
统计学习方法可以概括如下:从给定的、有限的、用于学习的训练数据(training
data)集合出发,假设数据是独立同分布产生的;并且假设要学习的模型属于某
个函数的集合,称为假设空间(hypothesis space);
应用某个评价准则(evaluation criterion),从假设空间中选取一个最优模型,使它对已知的训练数据及未知的测试数据(test data)在给定的评价准则下有最优的预测;最优模型的选取由算法实现。
这样统计学习方法包括模型的假设空间、模型选择的准则以及模型学习的算法。称其为统计学习方法的三要素,简称为模型(model)、策略(strategy)和算法(algorithm)。
1.2 统计学习的分类
1.2.1 基本分类
统计学习或机器学习一般包括监督学习、无监督学习、强化学习。有时还包括半监督学习、主动学习。
- 监督学习
监督学习(supervised learning)是指从标注数据中学习预测模型的机器学习问
题。标注数据表示输入输出的对应关系,预测模型对给定的输入产生相应的输出。监督学习的本质是学习输入到输出的映射的统计规律。
我们要弄清楚以下几个名词
(1)输入空间、特征空间和输出空间
在监督学习中,把输入和输出所有可能取值的集合分别称为输入空间(input space)和输出空间(output space)
每个具体的输入是一个实例(instance),通常由特征向量(feature vector)表示。所有特征向量存在的空间称为特征空间(feature space),特征空间的每一维对应于一个特征。(有时是假设输入空间等同于特征空间,有的时候不是)
在监督学习中,把输入和输出看作是定义在输入(特征)空间与输出空间上的随机变量的取值。输入输出变量用大写字母表示(习惯上输入变量为X,输出变量为Y),输入输出变量的取值用小写字母表示(输入变量取值为x,输出变量取值为y),变量可以是标量或向量,都用相同类型的字母表示,本书中的向量除非特别声明,否则均为列向量
输入实例 x x x的特征向量记作
x = ( x ( 1 ) , x ( 2 ) , . . . , x ( i ) , . . . , x ( n ) ) T x=(x^{(1)},x^{(2)},...,x^{(i)},...,x^{(n)} )^T x=(x(1),x(2),...,x(i),...,x(n))T
输入实例x的特征向量是指描述这个输入实例的特征的数值表示。在机器学习和深度学习中,我们通常将每个输入样本表示为一个特征向量,其中每个特征是样本的一个属性或特征。这些特征可以是任何与问题相关的信息,例如图像中的像素值、文本中的单词出现次数、声音信号中的频谱分布等等。特征向量是一个数值列表,其中每个元素对应一个特征,并且特征的顺序通常是固定的。例如,如果我们正在处理手写数字识别任务,每个输入图像可以表示为一个特征向量,其中每个元素对应一个像素的灰度值。如果图像的大小是28x28像素,那么特征向量将包含28x28=784个元素,每个元素代表一个像素的灰度值。在深度学习中,神经网络的输入通常是这些特征向量,网络的目标是学习从这些特征向量到相应的输出(例如,图像分类中的类别标签)的映射关系。因此,特征向量的选择和表示对于机器学习和深度学习任务至关重要,它们决定了模型的输入信息和性能。
x ( i ) x^{(i)} x(i)表示 x x x的第 i i i个特征。注意 x ( i ) x^{(i)} x(i)与 x i x_i xi不同,本书通常用 x i x_i xi表示多个输入变量中的第 i i i个变量
x i = ( x i ( 1 ) , x i ( 2 ) , . . . , x i ( i ) , . . . , x i ( n ) ) T x_i=(x_i^{(1)},x_i^{(2)},...,x_i^{(i)},...,x_i^{(n)} )^T xi=(xi(1),xi(2),...,xi(i),...,xi(n))T
监督学习从训练数据(training data)集合中学习模型,对测试数据(test data)进行预测,训练数据由输入(或特征向量)与输出对组成,训练集通常表示为
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)}
测试数据也由输入和输出对组成,输入和输出对又称为样本(sample)或样本点
根据输入变量X和Y的不同类型(连续或离散),预测任务有不同名称
| X和Y | 预测任务 |
|---|---|
| 均为连续变量 | 回归问题 |
| 输出为有限个离散变量 | 分类问题 |
| 均为变量序列 | 标注问题 |
(2)联合概率分布
监督学习假设输入与输出的随机变量 X X X和 Y Y Y遵循联合概率分布 P ( X , Y ) P(X,Y) P(X,Y)
P ( X , Y ) P(X,Y) P(X,Y)表示分布函数或分布密度函数
训练数据与测试数据被看作是依概率分布 P ( X , Y ) P(X,Y) P(X,Y)独立同分布产生的
分布函数(Distribution Function)和分布密度函数(Probability Density Function)是概率论和统计学中用于描述随机变量的两种不同方式。1. **分布函数(Distribution Function)**:- 分布函数通常表示为F(x),它描述了随机变量X小于或等于某个特定值x的概率。数学上,分布函数可以定义为:```F(x) = P(X <= x)```- 分布函数的值范围在0到1之间,且对于任何x,都有0 <= F(x) <= 1。- 分布函数是一个累积概率函数,它可以用来计算随机变量X在某个范围内的累积概率。2. **分布密度函数(Probability Density Function)**:- 分布密度函数通常表示为f(x),它描述了随机变量X在某个特定值x处的概率密度,即概率密度函数在x处的导数。数学上,分布密度函数可以定义为:```f(x) = dF(x)/dx```- 分布密度函数的值通常用来表示概率密度,而不是概率本身。因此,对于连续随机变量,概率密度函数在某个点x处的值并不代表概率,而是在附近范围内的概率密度。- 分布密度函数通常用于描述连续随机变量的概率分布,例如正态分布、指数分布等。总的来说,主要区别在于随机变量是连续的还是离散的。对于离散随机变量,我们使用分布函数来描述概率分布,而对于连续随机变量,我们使用分布密度函数来描述概率分布。分布函数提供了累积概率信息,而分布密度函数提供了在某一点附近的概率密度信息。
(3)假设空间
模型属于有输入空间到输出空间的映射的集合,这个集合就是假设空间(hypothesis space),假设空间的确定意味着学习的范围的确定。
映射可以是多对一、一对多、一对一等不同类型的关系。
函数是映射的一种特例,它是一对一关系。
监督学习的模型可以是概率模型或非概率模型,由条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)或决策函数(decision function) Y = f ( X ) Y=f(X) Y=f(X)表示,随具体学习方法而定。对具体的输入进行相应的输出预测时,写作 P ( y ∣ x ) P(y|x) P(y∣x)或 y = f ( x ) y=f(x) y=f(x)
这句话是在讨论监督学习模型的两种常见表示方式。
-
概率模型:在监督学习中,概率模型是一种常见的表示方式,它使用条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)来表示模型。这表示给定输入 X X X的情况下,目标变量 Y Y Y的概率分布。概率模型通常用于分类问题,其中 Y Y Y表示类别标签。例如,在图像分类任务中, X X X可以是图像数据, Y Y Y可以是图像所属的类别。模型通过学习 P ( Y ∣ X ) P(Y|X) P(Y∣X)的参数来进行预测和分类。
-
非概率模型:另一种常见的表示方式是使用决策函数(也称为预测函数或映射函数) Y = f ( X ) Y=f(X) Y=f(X)来表示模型。这表示模型直接映射输入 X X X到输出 Y Y Y,而不涉及概率分布。非概率模型通常用于回归问题,其中 Y Y Y表示连续数值。例如,在房价预测任务中, X X X可以是房屋的特征, Y Y Y可以是房价的预测值。模型通过学习适当的函数 f ( X ) f(X) f(X)来进行回归预测。
总之,监督学习的模型可以根据任务和问题的性质选择不同的表示方式。概率模型适用于分类和概率估计问题,而非概率模型适用于回归问题。选择哪种表示方式取决于具体的应用场景和建模需求。
(4)问题的形式化
监督学习的监督一词是由于标注的训练数据集往往是人工给出的
监督学习分为学习和预测两个过程
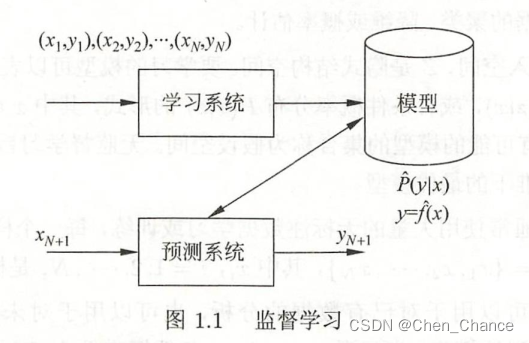
首先给定一个训练数据集
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)}
其中 ( x i , y i ) , i = 1 , 2 , . . . , N (x_i,y_i),i=1,2,...,N (xi,yi),i=1,2,...,N称为样本或样本点。 x i x_i xi是输入的观测值,也称为输入或实例, y i y_i yi是输出的观测值,也称为输出。
在学习过程中,学习系统通过给定的训练数据集,通过学习(或训练)得到一个模型,表示为条件概率分布 P ^ ( Y ∣ X ) \hat{P}(Y|X) P^(Y∣X)或决策函数 Y = f ^ ( X ) Y=\hat{f}(X) Y=f^(X)
在预测过程中,预测系统通过给定的 x N + 1 x_{N+1} xN+1,通过模型 y N + 1 = a r g max y P ^ ( y ∣ x N + 1 ) y_{N+1} = arg \underset{y}{\text{max}} \hat{P}(y|x_{N+1}) yN+1=argymaxP^(y∣xN+1)或 y N + 1 = f ^ ( x N + 1 ) y_{N+1}=\hat{f}(x_{N+1}) yN+1=f^(xN+1)给出对应的输出 y N + 1 y_{N+1} yN+1
这段话描述了在预测过程中,预测系统如何根据输入 x N + 1 x_{N+1} xN+1生成对应的输出 y N + 1 y_{N+1} yN+1,有两种不同的方式:
-
使用条件概率分布:
- 在第一种方式中,模型通过条件概率分布 P ^ ( y ∣ x N + 1 ) \hat{P}(y|x_{N+1}) P^(y∣xN+1)来生成输出。这表示系统会考虑给定输入 x N + 1 x_{N+1} xN+1的情况下,每个可能的输出 y y y的概率。然后,它会选择具有最高概率的 y y y作为输出。这个过程使用了"arg max"操作,表示选择使概率最大化的 y y y值。
- "arg max"是一个数学和计算机科学中常用的术语,它表示寻找一个函数或集合中能够使函数取得最大值的参数或元素。
- 例如,如果模型是一个文本分类器, x N + 1 x_{N+1} xN+1是一段文本,而 y N + 1 y_{N+1} yN+1是文本所属的类别,那么 P ^ ( y ∣ x N + 1 ) \hat{P}(y|x_{N+1}) P^(y∣xN+1)表示模型给出文本属于每个类别的概率分布。模型会选择具有最高概率的类别作为输出 y N + 1 y_{N+1} yN+1。
-
使用决策函数:
- 在第二种方式中,模型通过一个决策函数 f ^ ( x N + 1 ) \hat{f}(x_{N+1}) f^(xN+1)来生成输出。这表示系统会直接将输入 x N + 1 x_{N+1} xN+1传递给一个函数 f ^ \hat{f} f^,该函数会将 x N + 1 x_{N+1} xN+1映射到一个输出 y N + 1 y_{N+1} yN+1。
- 例如,如果模型是一个图像分类器, x N + 1 x_{N+1} xN+1是一张图像,而 y N + 1 y_{N+1} yN+1是图像所属的类别,那么 f ^ ( x N + 1 ) \hat{f}(x_{N+1}) f^(xN+1)可以是一个深度神经网络,它将图像作为输入并输出类别标签。
在监督学习中,假设训练数据与测试数据是依联合概率分布 P ( X ∣ Y ) P(X|Y) P(X∣Y)独立同分布产生的
对输入 x i x_i xi,通过模型可以产生一个输出 f ( x i ) f(x_i) f(xi),而训练数据集中对应的输出是 y i y_i yi,如果模型预测能力好,则 f ( x i ) f(x_i) f(xi)和 y i y_i yi之间的差应当足够小
- 无监督学习
无监督学习指从无标注数据中学习预测模型的机器学习问题
无监督学习的本质是学习数据中的统计规律或潜在结构
模型的输入与输出的所有可能取值的集合分别称为输入空间和输出空间,每个输入是一个实例,由特征向量表示,每一个输出是对输入的分析结果,由输入的类别、转换或概率表示(输出可以是类别标签,表示输入属于哪个类别;也可以是一种转换,表示输入数据的变换结果;还可以是一个概率分布,表示输入属于不同类别的概率)。模型可以实现对数据的聚类、降维或概率估计。
假设 X X X是输入空间, Z Z Z是隐式结构空间。要学习的模型可以表示为函数 z = g ( x ) z=g(x) z=g(x),条件概率分布 P ( z ∣ x ) P(z|x) P(z∣x),或者条件概率分布 P ( x ∣ z ) P(x|z) P(x∣z)的形式,其中 x x x是输入, z z z是输出。包含所有可能的模型的集合称为假设空间,无监督学习旨在从假设空间中选出在给定评价标准下的最优模型
2个问题:
1.为什么不叫输出空间,叫隐式结构空间?:
在无监督学习中,我们通常关注的是从输入数据中学习出的潜在结构或特征,这些潜在结构可能并不是直接可观察到的输出。因此,将其称为"隐式结构"强调了这些特征的隐藏性质,与常规的输出不同。输出通常是指直接可观察到的结果,而这里的 Z Z Z表示的是学习到的潜在表示。
2.为什么还有条件概率分布 P ( x ∣ z ) P(x|z) P(x∣z)的形式?:
这表示模型可以在不同的角度进行建模。 P ( z ∣ x ) P(z|x) P(z∣x)表示在给定输入 x x x的情况下 z z z的分布,通常用于表示数据的编码或降维过程。
P ( x ∣ z ) P(x|z) P(x∣z)表示在给定 z z z的情况下,生成输入 x x x的分布,通常用于生成模型或数据重建。
这两种表示方式在不同的无监督学习任务中都有应用,取决于任务的性质和目标。
无监督学习通常用大量的无标注数据进行学习或训练,每一个样本都是一个实例。
训练数据表示为 U = { x 1 , x 2 , . . . , x N } U=\{x_1,x_2,...,x_N\} U={x1,x2,...,xN},其中, x i , i = 1 , 2 , . . . , N x_i,i=1,2,...,N xi,i=1,2,...,N是样本。

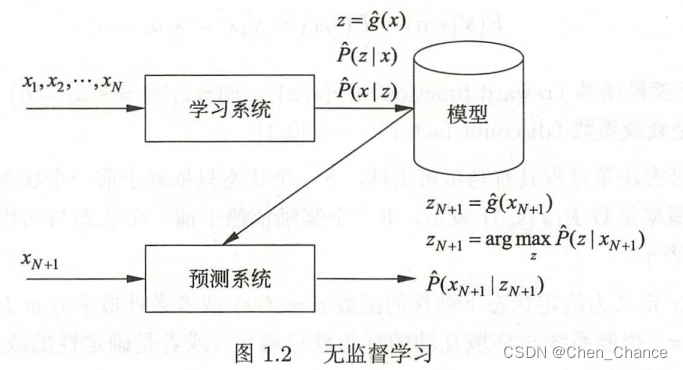
- 强化学习
强化学习(reinforcement learning) 是指智能系统在与环境的连续互动中学习最优行为策略的机器学习问题。
假设智能系统与环境的互动基于马尔可夫决策过程(Markov decision process),智能系统能观测到的是与环境互动的得到的数据序列。
强化学习的本质是学习最优的序贯决策
智能系统通俗来说就是一种能够自动地执行任务、做出决策、或者从数据中学习并改进自己的计算机程序或机器。这些系统通常被设计成能够模仿人类智慧的一些方面,比如理解语言、识别图像、解决问题等等。
举例来说,智能系统可以是:
- 虚拟助手:比如Siri、Alexa或Google助手,它们能够理解你的声音命令,回答问题,或者执行任务。
- 自动驾驶汽车:这些汽车能够利用传感器和计算机技术来感知道路上的情况,做出驾驶决策,从而在没有人类驾驶员的情况下行驶。
- 机器学习算法:这些算法可以从大量的数据中学习并进行预测,比如根据用户的购物历史预测他们可能喜欢的产品。
- 工业机器人:这些机器人可以执行重复性任务,如汽车制造中的焊接或装配工作,而无需人类操作。
智能系统的关键特征是它们能够根据输入数据做出决策或执行任务,并且通常能够从经验中学习,以不断改进它们的性能。这些系统的应用范围非常广泛,涵盖了许多不同的领域和行业。
马尔可夫决策过程(Markov Decision Process,简称MDP)是一种用于建模决策制定的数学工具,通常在人工智能和强化学习中使用。它可以被理解为描述一个智能体(也就是决策制定者)在与环境互动时如何做决策的框架。
在通俗的方式下,你可以把MDP看作是一个智能体与它所处的环境之间的互动游戏。这个游戏有以下几个要素
- 状态(State):状态表示了在某一时刻环境的特定情况或状态,可以是任何信息,比如一个棋盘上的棋子位置,一个房间的温度,或者一个机器人所在的位置。
- 行动(Action):行动是智能体可以采取的决策或动作,它们可以是移动、采购、购买等等,取决于具体的问题。
- 奖励(Reward):在每个状态和采取每个行动后,智能体会收到一个奖励信号,表示这个决策是好还是坏。奖励可以是正数表示好的结果,负数表示不好的结果,或者零表示中立的结果。
- 转移概率(Transition Probability):这是一个规定在某一状态下采取某个行动后下一个状态是什么的概率分布。它表示环境的不确定性,因为有时候相同的行动可能会导致不同的结果。
MDP的目标是找到一种策略(Policy),也就是一种决策规则,告诉智能体在每个状态下应该采取哪个行动,以最大化累积的奖励。智能体的任务就是根据这个策略来做决策,同时考虑到当前状态、可能的行动、奖励以及转移概率。
总之,MDP是一个用于描述智能体如何在不确定的环境中做出决策的框架,它帮助我们理解如何选择最优策略以达到特定目标。这个概念在很多领域,尤其是强化学习中,都非常有用。
智能系统观测到的是与环境互动的数据序列,这是因为在强化学习中,决策制定者(智能系统)需要根据先前的经验和互动结果来学习并改进其决策策略。这个经验包括了一系列的数据点,通常以时间序列的形式记录下来,因此被称为数据序列。
以下是为什么这些数据通常呈现为序列的原因:
- 历史信息的重要性:在强化学习中,以前的决策和互动结果通常对当前和未来的决策有重要影响。因此,将这些历史数据以序列的形式记录下来,有助于智能系统理解过去的经验,并在未来的决策中考虑这些信息。
- 状态的变化:环境的状态通常会随着时间而变化,而智能系统需要根据不同的状态采取不同的行动。通过记录数据序列,智能系统可以跟踪状态的演变,以更好地适应环境的变化。
- 学习与改进:强化学习的目标是通过不断地学习和改进来寻找最佳策略。数据序列允许智能系统回顾过去的行动和结果,从中提取有关什么工作和什么不工作的信息,并相应地调整未来的策略。
- 奖励信号的累积:在每个时间步,智能系统会收到奖励信号,这些奖励信号在序列中累积,以衡量智能系统的性能。通过记录整个序列,可以计算总奖励,从而评估策略的质量。
因此,数据序列在强化学习中起着关键作用,帮助智能系统理解环境、学习经验、做出更好的决策,并最终找到最优的行为策略。
序贯决策是一种决策方法,通常用于描述在一系列连续的决策点上如何做出决策的过程。这种决策方法涉及到在时间上连续的一系列决策步骤,每个步骤都基于之前的决策和可能的情况来做出。
序贯决策的特点包括:
- 时序性:每个决策都在前一个决策之后,且在下一个决策之前进行。这意味着每个决策都考虑了时间上的顺序和历史信息。
- 条件性:每个决策通常依赖于之前的决策结果和环境的当前状态。决策制定者需要根据之前的经验和当前情况来选择下一步的行动。
- 累积性:决策的结果通常会积累,影响后续决策和最终的结果。这意味着之前的决策可能会对整个决策序列的成功产生重要影响。
序贯决策在许多领域中都有应用,特别是在强化学习、控制系统、金融投资和自动化领域。在这些领域,决策制定者需要考虑如何在连续的时间步骤中采取行动,以实现某种目标或最大化某种性能指标。序贯决策方法提供了一种框架,帮助解决这些复杂的问题,并优化决策序列以获得最佳结果。
智能系统和环境的互动如图
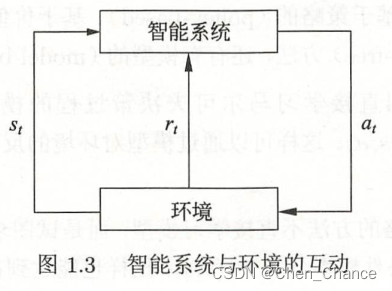
在每一步 t t t,智能系统从环境中观测到一个状态(state) s t s_t st与一个奖励(reward) r t r_t rt,采取一个动作(action) a t a_t at。环境根据智能系统选择的动作,决定下一步 s t + 1 s_{t+1} st+1和 r t + 1 r_{t+1} rt+1。要学习的策略表示为给定的状态下采取的动作。智能系统的目标不是短期奖励的最大化,而是长期累积奖励的最大化,在这过程中,系统不断试错(trial and error),以达到学习最优策略的目的。
强化学习的马尔可夫决策过程是状态、奖励、动作序列上的随机过程,有五元组 < S , A , P , r , γ > <S,A,P,r,\gamma> <S,A,P,r,γ>组成
S S S是有限状态(state)的集合
A A A是有限动作(action)的集合
P P P是状态转移概率(transition probability)函数:
P ( s ′ ∣ s , a ) = P ( s t + 1 = s ′ ∣ s t = s , a t = a ) P(s^{'}|s,a)=P(s_{t+1}=s^{'}|s_t=s,a_t=a) P(s′∣s,a)=P(st+1=s′∣st=s,at=a)
r r r是奖励函数(reward function): r ( s , a ) = E ( r t + 1 ∣ s t = s , a t = a ) r(s,a)=E(r_{t+1}|s_t=s,a_t=a) r(s,a)=E(rt+1∣st=s,at=a)
γ \gamma γ是衰减系数(discount factor): γ ∈ [ 0 , 1 ] \gamma \in[0,1] γ∈[0,1]
马尔可夫决策过程具有马尔可夫性,下一个状态只依赖于前一个状态和动作,由状态转移概率函数 P ( s ′ ∣ s , a ) P(s^{'}|s,a) P(s′∣s,a)表示。下一个奖励依赖于前一个状态与动作,由奖励函数 r ( s , a ) r(s,a) r(s,a)表示。
策略 π \pi π定义为给定状态下动作的函数 a = f ( s ) a=f(s) a=f(s)或者条件概率分布 P ( a ∣ s ) P(a|s) P(a∣s)。给定一个策略 π \pi π,智能系统与环境互动的行为就已确定(或者是确定性的或者是随机性的)
价值函数(value function)或状态价值函数(state value function)定义为策略 π \pi π从某一个状态s开始的长期累积奖励的数学期望:
v π ( s ) = E π [ r t + 1 + γ r t + 2 + γ 2 r t + 3 + . . . ∣ s t = s ] v_{\pi}(s)=E_{\pi}[r_{t+1}+\gamma r_{t+2}+\gamma^2 r_{t+3}+...|s_t=s] vπ(s)=Eπ[rt+1+γrt+2+γ2rt+3+...∣st=s]
动作价值函数(action value function)定义为策略 π \pi π的从某一个状态s和动作a开始开始的长期累积奖励的数学期望
q π ( s , a ) = E π [ r t + 1 + γ r t + 2 + γ 2 r t + 3 + . . . ∣ s t = s , a t = a ] q_{\pi}(s,a)=E_{\pi}[r_{t+1}+\gamma r_{t+2}+\gamma^2 r_{t+3}+...|s_t=s,a_t=a] qπ(s,a)=Eπ[rt+1+γrt+2+γ2rt+3+...∣st=s,at=a]
强化学习的目标就是在所有可能的策略中选出价值函数最大的策略 π ∗ \pi^* π∗,而在实际学习中往往从具体的策略出发,不断优化已有策略,这里 γ \gamma γ表示未来的奖励会有衰减。
1.2.2按模型分类
1.2.3按算法分类
1.2.4 按技巧分类
1.3统计学习方法的三要素
1.3.1模型
1.3.2 策略
1.3.3算法
1.4模型评估与模型选择
1.4.1 训练误差与测试误差
1.4.2 过拟合与模型选择
1.5正则化与交叉验证
1.5.1正则化
正则化项和L1范数和L2范数的关系
1.5.2 交叉验证
1.6泛化能力
1.6.1泛化误差
1.6.2泛化误差上界
1.7生成模型与判别模型
监督学习的任务就是学习一个模型,应用这一个模型,对给定的输入预测相应的输出,这个模型一般形式为决策函数 Y = f ( X ) Y=f(X) Y=f(X)或者条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)
监督学习方法又可以分为生成方法和判别方法,所学到的模型分别称为生成模型和判别模型
生成模型和判别模型是机器学习中两种不同类型的模型,它们的主要区别在于它们建模的是什么。
-
生成模型:
- 生成模型试图建模数据的生成过程,即它们尝试了解数据是如何被生成的。它们关注的是数据的整体分布和特征之间的关系。
- 生成模型可以生成新的数据点,因为它们对数据的生成过程有了深刻的理解。例如,一些生成模型可以生成逼真的图像、文本或声音样本。
- 常见的生成模型包括生成对抗网络(GANs)、隐马尔可夫模型(HMMs)和变分自编码器(VAEs)等。
-
判别模型:
- 判别模型不试图建模数据的生成过程,而是专注于建立一个决策边界或者一个映射函数,以将输入数据映射到标签或类别。
- 判别模型关注的是如何将输入数据映射到输出标签,即它们关注的是条件概率分布 P(Y|X),其中 Y 表示输出标签,X 表示输入数据。
- 判别模型通常用于分类任务,例如图像分类、文本分类、情感分析等。
- 常见的判别模型包括支持向量机(SVM)、逻辑回归(Logistic Regression)、决策树(Decision Trees)和神经网络(Neural Networks)等。
简而言之,生成模型关注数据的生成过程,可以生成新的数据,而判别模型关注将输入映射到输出,用于分类等任务。在实际应用中,选择使用哪种模型取决于具体的任务和数据性质。
1.8 监督学习应用
1.8.1分类问题
评价分类器性能的指标一般是分类准确率(accuracy),指对于给定的测试数据集,分类器正确分类的样本数与总样本数之比
对于二分类问题常用的评价指标是精确率P(precision)与召回率R(recall),以关注的类为正类,其余为负类
| 符号 | 含义 |
|---|---|
| TP | 将正类预测为正类数 |
| FN | 将正类预测为负类数 |
| FP | 将负类预测为正类数 |
| TN | 将负类预测为负类数 |
P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP
R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP
此外还有 F 1 F_1 F1,为P和R的调和均值
2 F 1 = 1 P + 1 R \frac{2}{F_1}=\frac{1}{P}+\frac{1}{R} F12=P1+R1
F 1 = 2 T P 2 T P + F P + F N F_1=\frac{2TP}{2TP+FP+FN} F1=2TP+FP+FN2TP
精确率和召回率都高时,F_1也会高
1.8.2标注问题
1.8.3回归问题
相关文章:
李航老师《统计学习方法》第1章阅读笔记
1.1 统计学习 统计学习的特点 统计学习:计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析 现在人们提及机器学习时,往往指统计机器学习,所以可以认为本书介绍的是机器学习方法 统计学习的对象 统计学习研究的对象是数据(data)…...

基于微信小程序的背单词学习激励系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言用户微信端的主要功能有:管理员的主要功能有:具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉…...
VScode调试复杂C/C++项目
以前都是用的VScode调试c/cpp的单个文件的编译和执行, 但是一遇到大型项目一般就用gdb了, gdb的调试效率和VScode差距还是比较大的, 但最近发现VScode其实也能调试复杂的cpp项目, 所以记录一下. 首先明确一下几点: 首先cpp文件需要经过编译, 生成可执行文件, 然后通过运行/调…...

【Hash表】字母异位词分组-力扣 49 题
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kuan 的首页,持续学…...
展示日志log4.properties
log4.properties 1.log4.properties 此时文件主要用于展示日志的输出的级别的信息。 # Set root category priority to INFO and its only appender to CONSOLE. #log4j.rootCategoryINFO, CONSOLE debug info warn error fatal log4j.rootCategoryinfo, CONSO…...
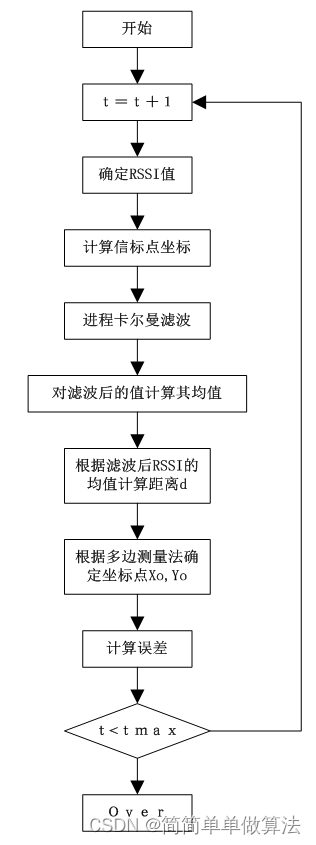
基于PLE结合卡尔曼滤波的RSSI定位算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 MATLAB2022a 3.部分核心程序 ............................................................... for Num_xb Num_xb2Num_…...
版本更新和热更新实现方法)
uniapp项目实践总结(十九)版本更新和热更新实现方法
导语:当一个 APP 应用开发完成以后,就要上架应用商店,但有时候修改一些小问题或者推出一些活动,又不想频繁地提交应用商店审核,那么就可以使用应用内更新功能来进行应用的版本升级更新或热更新,下面就介绍一下实现的方法。 目录 准备工作原理分析实战演练案例展示准备工作…...
一起学数据结构(8)——二叉树中堆的代码实现
在上篇文章中提到,提到了二叉树中一种特殊的结构——完全二叉树。对于完全二叉树,在存储时,适合使用顺序存储。对于非完全二叉树,适合用链式存储。本文将给出完全二叉树的顺序结构以及相关的代码实现: 1. 二叉树的结构…...
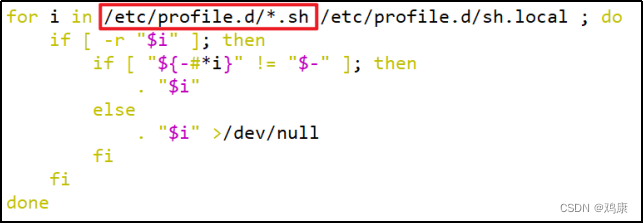
Linux环境变量配置说明(配置jdk为例-摘录自尚硅谷技术文档)
配置环境变量的不同方法 Linux的环境变量可在多个文件中配置,如/etc/profile,/etc/profile.d/.sh,~/.bashrc,~/.bash_profile等,下面说明上述几个文件之间的关系和区别。 bash的运行模式可分为login shell和non-login shell。 例…...

idea常用插件笔记
文章目录 Free Mybatis Toollombok插件idea插件导出导入 idea提供了很多好用的插件,之前都装了的,但是换了下电脑,什么都没了,所以记录下方便以后用。 Free Mybatis Tool mybatis跳转插件,再也不用费力的找xml了。 l…...
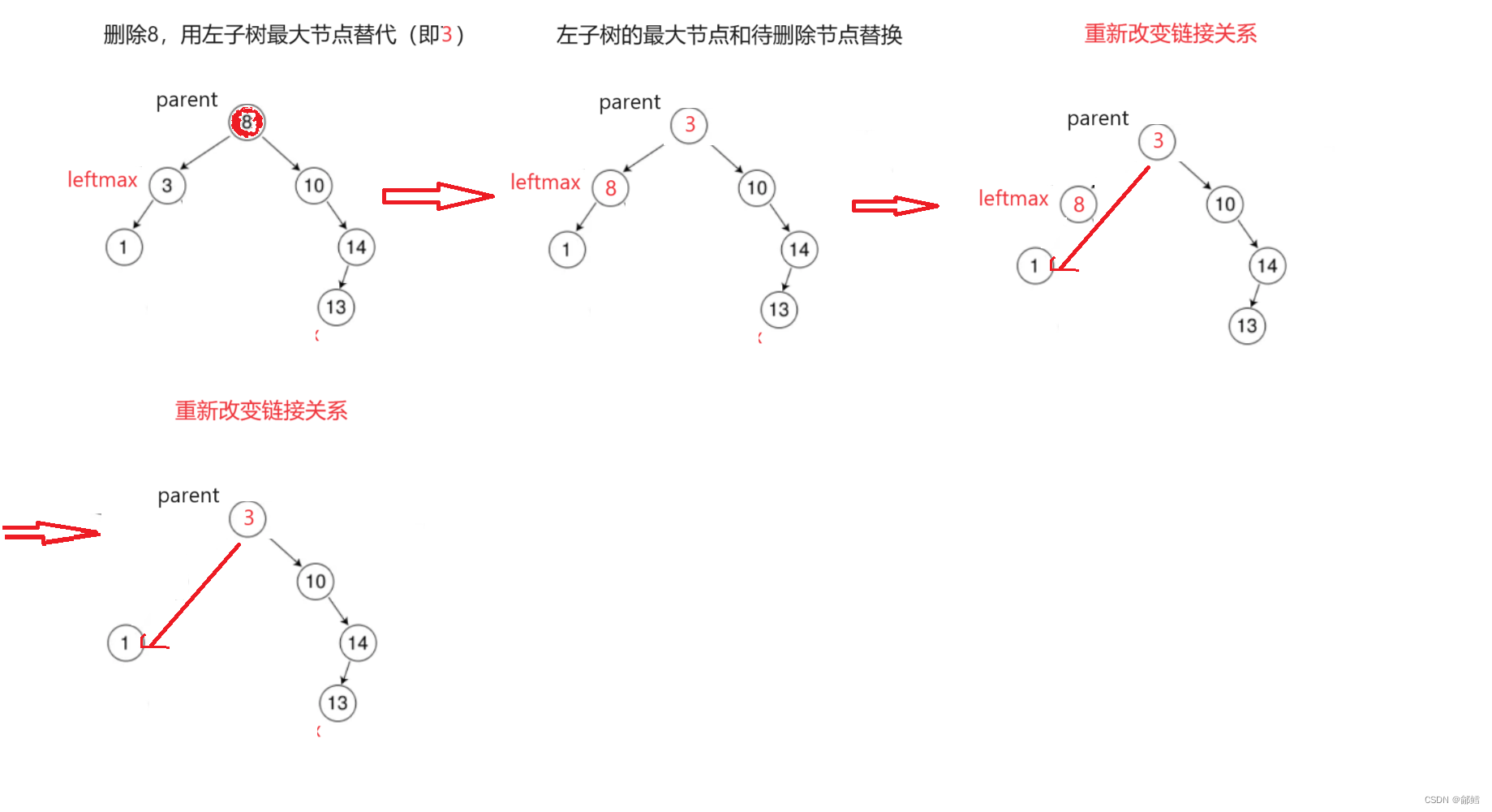
搜索二叉树【C++】
文章目录 二叉搜索树二叉搜索树的模拟实现构造函数拷贝构造函数赋值运算符重载函数析构函数Insert循环递归 Erase循环递归 Find循环递归 二叉搜索树的应用K模型KV模型 完整代码普通版本递归版本 二叉搜索树 二叉搜索树又称为二叉排序树,它或者是一棵空树࿰…...
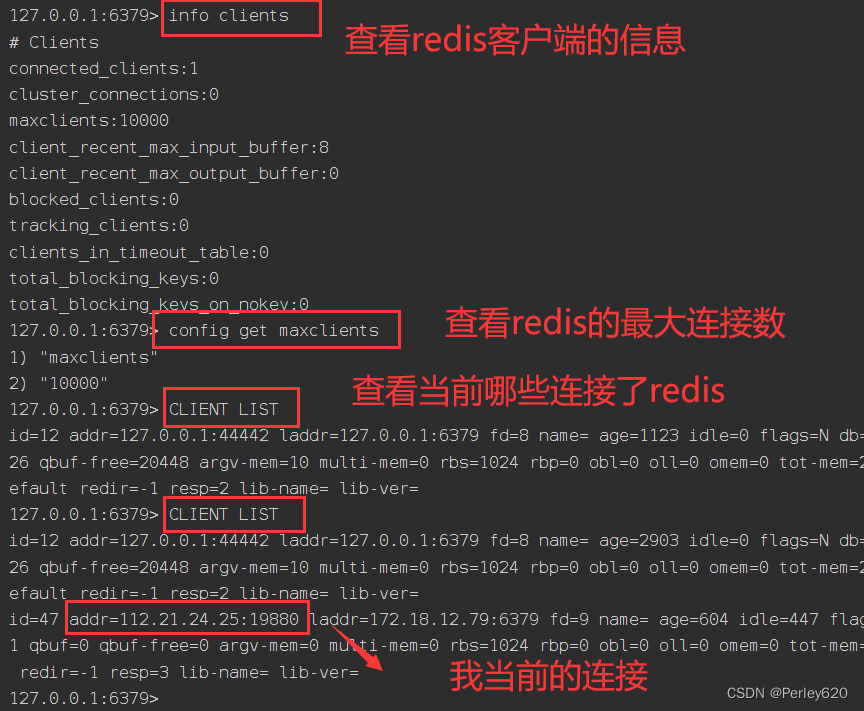
华为云云耀云服务器L实例评测|认识redis未授权访问漏洞 漏洞的部分复现 设置连接密码 redis其他命令学习
前言 最近华为云云耀云服务器L实例上新,也搞了一台来玩,期间遇到过MySQL数据库被攻击的情况,数据丢失,还好我有几份备份,没有造成太大的损失。昨天收到华为云的邮箱提醒,我的redis数据库没有设置密码&…...

快速安装NGINX
快速安装NGINX #安装依赖包 yum -y install gcc pcre pcre-devel zlib zlib-devel openssl openssl-devel#下载NGINX curl -O https://nginx.org/download/nginx-1.21.6.tar.gz#解压NGINX tar -zxvf nginx-1.21.6.tar.gz cd nginx-1.21.6.tar.gz#配置 ./configure --prefix/…...
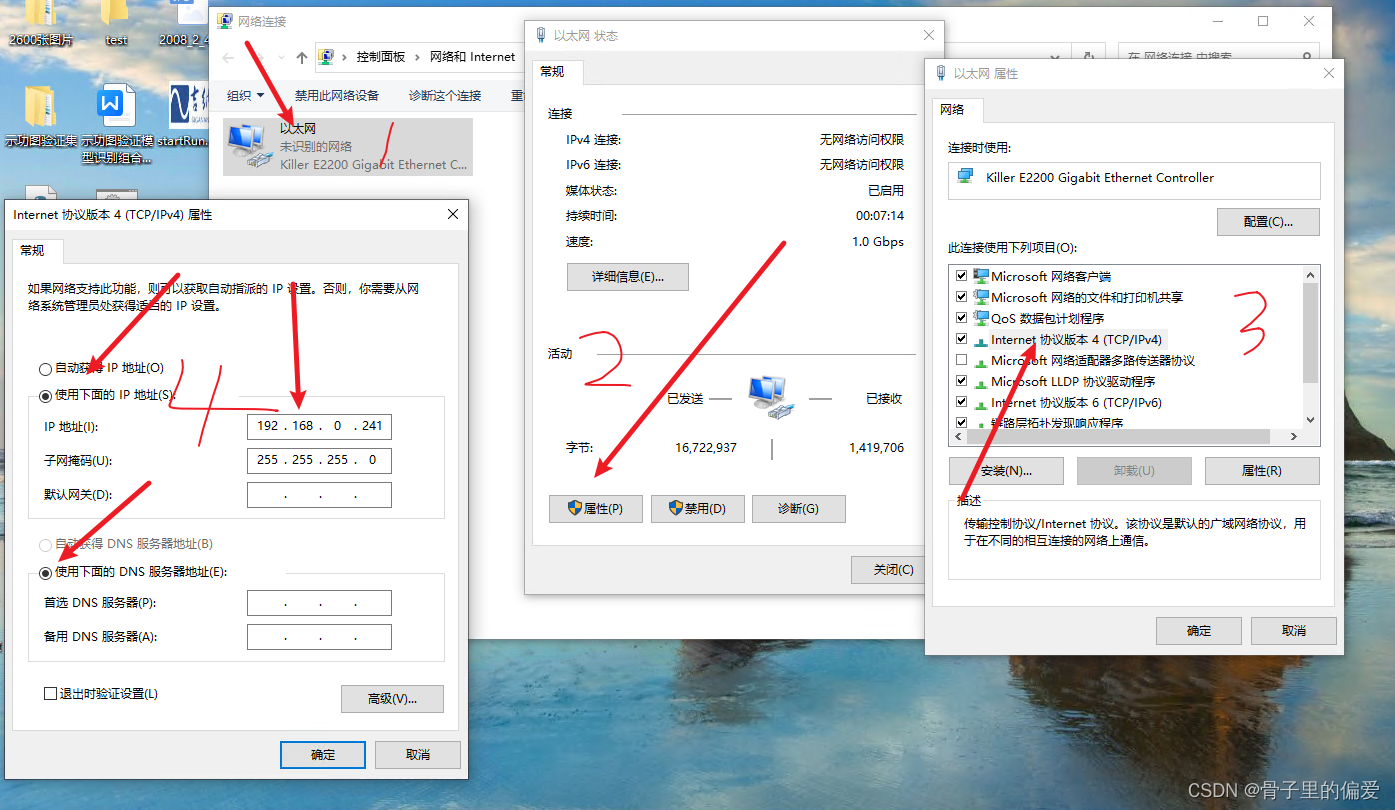
一台电脑远程内网的另外一台电脑,禁止远程的电脑连接外网,只允许内网连接
一台电脑远程内网的另外一台电脑,禁止远程的电脑连接外网,只允许内网连接 1.找到右下角网卡图标,右键图标选择“打开网络和共享中心”。 3、点击“更改适配器设置”。 4、右键正在使用的网卡“本地连接”打开属性 5、找到“internet协…...

山西电力市场日前价格预测【2023-09-24】
日前价格预测 预测说明: 如上图所示,预测明日(2023-09-24)山西电力市场全天平均日前电价为496.09元/MWh。其中,最高日前电价为705.54元/MWh,预计出现在14: 30。最低日前电价为333.70元/MWh,预计…...

MQ---第二篇
系列文章目录 文章目录 系列文章目录一、RabbitMQ事务消息二、RabbitMQ死信队列、延时队列一、RabbitMQ事务消息 通过对信道的设置实现 channel.txSelect();通知服务器开启事务模式;服务端会返回Tx.Select-Okchannel.basicPublish;发送消息,可以是多条,可以是消费消息提交…...

C++ 创建文件并写入内容
文章目录 1.问题2.filesystem3.示例参考文献 1.问题 C 如何向指定路径的文件写入内容呢? 这里有几点要求: 如果目录不存在需要自动创建。如果文件不存在需要自动创建。以覆盖的方式写入内容。 2.filesystem C17 带来了一个新的库:filesy…...

微信小程序rich-text里面写多行溢出显示省略号在ios中不显示的问题
问题:微信小程序rich-text里面写多行溢出显示省略号在ios中不显示的问题 解决方法:需要给一个默认的div标签,在div写行内样式 overflow : hidden; text-overflow: ellipsis; display: -webkit-box; -webkit-line-clamp: 3; -webkit-box-o…...
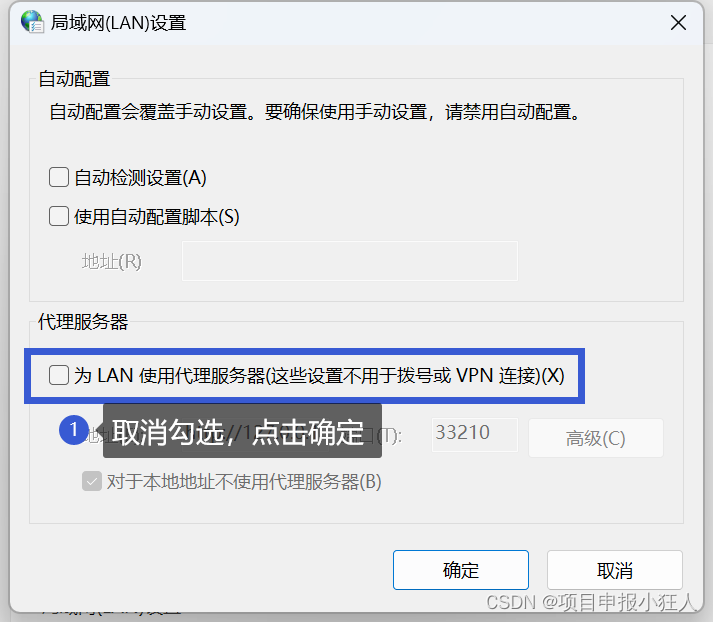
解决Win11/10中Edge浏览器页面加载不出来、打不开问题|有网但是打不开,加载不了
问题症状 edge浏览器打不开,有网络能正常上网,但是edge浏览器无法浏览。网络质量很高,但是页面就是加载不出来,详情如下: (我是在科学上网后造成这样子的原因,现在将我的方法分享一下ÿ…...

【DRAM存储器五】DRAM存储器的架构演进-part2
👉个人主页:highman110 👉作者简介:一名硬件工程师,持续学习,不断记录,保持思考,输出干货内容 参考书籍:《Memory Systems - Cache, DRAM, Disk》 目录 以提升吞吐…...

OpenClaw异常处理:Qwen2.5-VL-7B任务中断自动恢复方案
OpenClaw异常处理:Qwen2.5-VL-7B任务中断自动恢复方案 1. 当自动化遇上不稳定:我的深夜崩溃实录 凌晨2点17分,我的显示器突然亮起——OpenClaw正在执行的周报生成任务中断了。这个本该在后台安静运行的自动化流程,因为Qwen2.5-V…...

IPXWrapper:让经典游戏在Windows 11重获联机能力的技术解析
IPXWrapper:让经典游戏在Windows 11重获联机能力的技术解析 【免费下载链接】ipxwrapper 项目地址: https://gitcode.com/gh_mirrors/ip/ipxwrapper 在现代Windows 11系统中,许多经典游戏因缺乏IPX协议支持而无法实现局域网联机,IPXW…...

突破式4大技术实现99%硬字幕提取准确率:video-subtitle-extractor全解析
突破式4大技术实现99%硬字幕提取准确率:video-subtitle-extractor全解析 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕…...

实测分享:Retinaface+CurricularFace镜像,人脸识别准确率超乎想象
实测分享:RetinafaceCurricularFace镜像,人脸识别准确率超乎想象 1. 测试背景与目标 在当今数字化时代,人脸识别技术已成为身份验证、安防监控和智能设备交互的核心组件。然而,面对市场上众多的人脸识别解决方案,开发…...

SEO_解读最新搜索引擎算法,调整你的SEO策略
SEO:解读最新搜索引擎算法,调整你的SEO策略 在当今数字营销的世界里,搜索引擎优化(SEO)始终是提升网站流量和品牌知名度的关键。每当搜索引擎更新其算法,SEO策略就需要相应调整。今天我们将深入解读最新的搜索引擎算法…...

大模型全链路解析:技术演进、能力边界与落地实践 - 【收藏必看】
本节概览: 1、机器学习、深度学习和大模型的技术演进 2、模型能力来源、缺陷根源 3、落地模型:模型的轻量化、算力利用率1 机器学习、深度学习与大模型 很多人会把机器学习、深度学习和大模型当成三个平行概念,但从技术发展的角度看ÿ…...

Phi-3-Mini-128K快速上手:无需网络依赖的本地化AI对话工具实操手册
Phi-3-Mini-128K快速上手:无需网络依赖的本地化AI对话工具实操手册 1. 工具概览 Phi-3-Mini-128K是一款基于微软Phi-3-mini-128k-instruct模型开发的轻量化对话工具。它最大的特点是可以在普通电脑上本地运行,不需要连接网络就能使用AI对话功能。这个工…...

Phi-4-mini-reasoning助力C语言项目:代码逻辑分析与缺陷检测
Phi-4-mini-reasoning助力C语言项目:代码逻辑分析与缺陷检测 1. 为什么C语言开发者需要AI辅助 在嵌入式系统、操作系统内核等对性能要求极高的领域,C语言依然是无可替代的选择。但随之而来的是复杂的内存管理、指针操作和并发控制带来的挑战。一个看似…...

OpenClaw飞书机器人进阶:Qwen3.5-9B-AWQ-4bit实现图片自动分析
OpenClaw飞书机器人进阶:Qwen3.5-9B-AWQ-4bit实现图片自动分析 1. 为什么需要图片自动分析助手 上周整理项目资料时,我发现自己电脑里堆满了会议白板照片、产品截图和手写笔记。手动整理这些图片不仅耗时,还经常漏掉关键信息。直到发现Open…...

SEO_本地商家必备的SEO实战方法
SEO对本地商家的重要性 在当今数字化时代,为了在竞争激烈的市场中脱颖而出,本地商家必须掌握一些SEO(搜索引擎优化)技巧。SEO不仅可以提升网站的搜索引擎排名,还能够有效地吸引更多的本地客户。本文将详细探讨本地商家…...