SpringCloud Alibaba 入门到精通 - Sentinel
SpringCloud Alibaba 入门到精通 - Sentinel
- 一、基础结构搭建
- 1.父工程创建
- 2.子工程创建
- 二、Sentinel的整合SpringCloud
- 1.微服务可能存在的问题
- 2.SpringCloud集成Sentinel搭建Dashboard
- 3 SpringCloud 整合Sentinel
- 三、服务降级
- 1 服务降级-Sentinel
- 2 Sentinel 整合 OpenFeign
- 3 OpenFeign定义服务降级
- 四、限流-熔断规则:DegradeRule
- 1.慢调用比例熔断-页面
- 1.慢调用比例熔断-API
- 2.异常比例熔断-页面
- 2.异常比例熔断-API
- 3.异常数熔断-页面和API
- 4.补充其他关键点
- 4.1 增加@SentinelResource注解后,默认降级不生效
- 4.2 统一降级处理
- 4.3 抛出BLockException不会触发熔断规则
- 4.4 配置spring.cloud.sentinel.eager:true
- 五、限流-流控规则:FlowRule
- 1.QPS流控-页面
- 1.QPS流控-API
- 2.并发线程数-页面/API
- 3.流控模式-关联(使用QPS)-页面/API
- 4.流控模式-链路(使用并发线程数)-页面/API
- 5.流控效果-预热-页面/API
- 6.流控效果-排队等待-页面/API
- 7.针对来源进行流控
- 8.集群配置
- 六、限流-授权规则:AuthorityRule
- 1.授权规则-页面/API
- 七、限流-热点规则:ParamFlowRule
- 1.热点规则-页面
- 2.热点规则-API
- 八、限流-系统规则:SystemRule
- 1.系统规则-页面/API
- 九、总结
一、基础结构搭建
这里通过maven的父子工程来管理本次展示的demo。使用父子观察管理的好处是:
- 1.代码集中方便集中管理,下载
- 2.集中化管理学习成本更低项目易于接受
1.父工程创建
使用IDEA。file–>new–>project–>maven 来进行创建父工程,父工程一定得是pom的,这样我们编译时父工程才可以实现管理子工程的目的,如果不是pom的我们是无法在父工程下正确创建子工程的。
本次demo采用集中的版本管理,我们只需要限定以下三个版本即可,只需要将他们放在dependencyManagement中进行指明版本,同时声明type和scope就可以做到全局的组件版本控制了,功能类似于parent标签,不过parent只能声明一个父工程来管理版本依赖,而放在dependencyManagement的dependency却可以支持多个。
- SpringBoot 版本:2.6.11
- SpringCloud 版本:2021.0.4
- SpringCould Alibaba 版本:2021.0.4.0
若是对alibaba与cloud和boot的版本对应关系不清晰,可以看这里:SpringCloud组件版本依赖关系
<dependencyManagement><dependencies><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${Spring-cloud-alibaba-version}</version><type>pom</type><scope>import</scope></dependency><dependencies>
</dependencyManagement>
下面是父工程的完整pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><!--这里不使用parent来管理整体的jar的版本,统一放在dependencymanager中进行管理--><!--<parent>--><!--<groupId>org.springframework.boot</groupId>--><!--<artifactId>spring-boot-starter-parent</artifactId>--><!--<version>3.1.3.RELEASE</version>--><!--<relativePath/> <!– lookup parent from repository –>--><!--</parent>--><groupId>com.cheng</groupId><artifactId>spring-cloud-alibaba-base</artifactId><packaging>pom</packaging><version>1.0.0</version><modules><module>order-server</module><module>stock-server</module></modules><name>spring-cloud-alibaba-base</name><description>alibaba父工程</description><properties><java.version>8</java.version><Spring-boot-version>2.6.11</Spring-boot-version><Spirng-cloud-version>2021.0.4</Spirng-cloud-version><Spring-cloud-alibaba-version>2021.0.4.0</Spring-cloud-alibaba-version></properties><dependencyManagement><!--通过此模块来规范boot和cloud的所有组件版本,所有的子工程将不需要考虑组件的版本问题--><dependencies><!--这种写法和写在parent中作用一样,注意type和scope不可省略--><!--这种写法的优点是可以声明多个父级的项目包版本依赖,而parent只能由一个--><!--这是springboot相关包的版本管理--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>${Spring-boot-version}</version><type>pom</type><scope>import</scope></dependency><!--这是alibaba组件的版本管理--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${Spring-cloud-alibaba-version}</version><type>pom</type><scope>import</scope></dependency><!--这是cloud的组件的版本管理,也可以使用pring-cloud-dependencies-parent,但是使用下面的更好--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${Spirng-cloud-version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><!--dependencies中的包会直接被子工程继承,而dependencyManagement的包不手动引入,则不会继承--><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
2.子工程创建
子工程创建都是一样的,这里展示一个例子:父工程右键–>new–>module–>spring-initializr,这里不使用spring-initializr,使用maven也是可以的,只是使用spring-initializr会方便一些,无需我们自己创建启动类、配置文件等。若是你的IDEA比较新(据我所知IDEA2021以下好像用不了)还可以使用spring-initializr指定三方的脚手架,三方脚手架地址推荐使用阿里的。https://start.aliyun.com,这个脚手架对Springcloud组件支持的更友好,也包含更多的阿里系的组件
(注意:社区版的IDEA不支持Spring Initializr功能)
下面是子工程的pom文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>com.cheng</groupId><artifactId>spring-cloud-alibaba-base</artifactId><version>1.0.0</version></parent><groupId>com.cheng</groupId><artifactId>order-server</artifactId><version>1.0.0</version><name>order-server</name><description>Demo project for Spring Boot</description><properties><java.version>17</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>到这里就简单搭建了一个架子出来,后面就是为每个服务进行引入不同的组件和依赖了。
若是感觉以上父子工程创建不够详细,推荐看这里:Maven创建父子工程详解
二、Sentinel的整合SpringCloud
Sentinel详细介绍参见官方文档:
Sentinel官方网址
Sentinel的github 这里会更详细一些
1.微服务可能存在的问题
- 1.流量激增CPU符合过高无法正常处理请求
- 2.数据未进行预热导致的缓存击穿
- 3.消息太多导致消息积压
- 4.慢sql导致数据库连接占满
- 5.三方系统无响应重复点击导致线程卡满
- 6.系统异常内存无法正常释放OOM
- 7.服务器内存瓶颈,程序异常退出
以上的问题都可能导致服务的单点故障,在不给服务增加额外处理时,一旦某个系统挂掉了,那么依赖他的系统也会出现异常,从而多米诺骨牌一样服务机会接连出现问题,最终导致大面积服务不可用,这就是常说的服务雪崩了。服务雪崩是无法忍受的,一旦出现将导致系统基本不可用,对于使用者来说很不友好,将会导致大面积的用户流失。
所以服务不可用的问题我们是需要分场景进行解决的,Sentinel就是做这个使用的,它被称为分布式系统的流量防卫兵,他的主要作用就是保证系统的稳定性(reliability)和恢复性(resilience),他支持多种系统的容错机制,常见的有:
- 1.超时机制
设置超时时间,在指定的时间内处理,超时以后处理超时逻辑 - 2.限流机制
可根据QPS来对服务进行流程管控 - 3.线程隔离机制
利用线程池来对请求进行管理,超出部分可定义其他处理策略 - 4.服务熔断
当服务到达定义的熔断标准或者降级标准时对服务进行次一级的信息处理,可能是消息排队处理,可能是入库等待最终一致性的处理 - 5.服务降级
感觉这个感念其实和服务熔断类似,只是服务异常处理颗粒度的问题,都是需要对服务进行次一级处理。
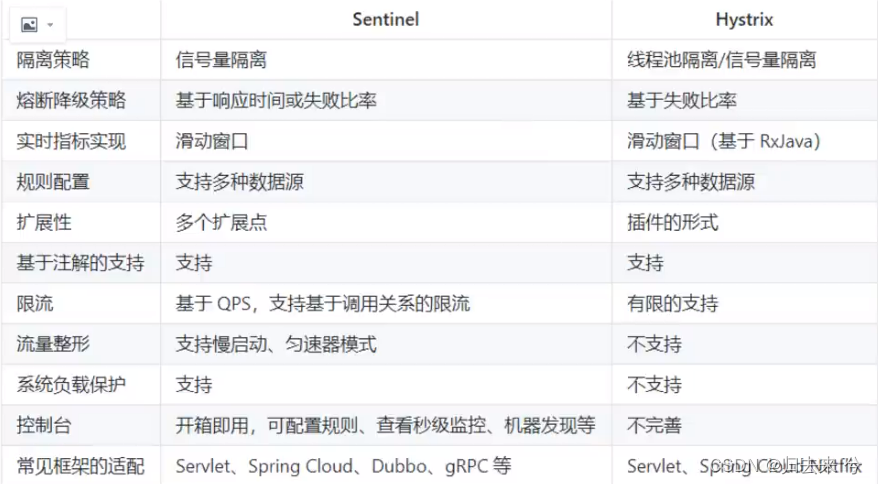
Sentiael针对以上场景都做了很好的处理,可以很好的的保障服务高并发场景下的可用性、稳定性。阿里出品必属精品,用就完事了。目前市面上开源的也就Sentinel了,作为前辈的hystrix已经停更了,下面做个小小的比对:
2.SpringCloud集成Sentinel搭建Dashboard
sentinel可以集成在任何的Springboot项目内,同时alibaba也提供了对应的starter方便我们快速集成sentinel,阿里提供的starter内部包含了我们需要使用的所有jar包(不包含集成OpenFeign、Gateway等的jar)。一起来体验下吧。这里使用的版本无需声明与顶层限定的版本保持一致即可。实际使用的是Sentinel1.8.5
Dashboard官方文档地址:Sentinel控制台
Dashboard下载地址:Sentinel-Dashboard下载
Dashboard默认的账号密码:sentinel/sentinel
搭建的话很简单我们只需要从官网下载自己对应的jar即可,dashboard是一个标准的SpringBoot项目,所以这里直接使用java命令就可以启动了。
java -Dserver.port=8080 \
-Dcsp.sentinel.dashboard.server=localhost:8080 \
-Dproject.name=sentinel-dashboard \
-jar sentinel-dashboard-1.8.5.jar
如果想要更改默认的用户名密码,可以增加用户名和密码的传参:
java -Dserver.port=8080 \
-Dcsp.sentinel.dashboard.server=localhost:8080 \
-Dproject.name=sentinel-dashboard \
-Dsentinel.dashboard.auth.username=admin \
-Dsentinel.dashboard.auth.password=admin \
-jar sentinel-dashboard-1.8.5.jar
如果想要快速验证,可以在本地先用Git Bash 进行启动,即可进行快速验证了
此外若是不想要在dashboard中出现dashboard自己(控制自己使用的,其实没啥用)可以直接取消project.name和csp.sentinel.dashboard.server的配置就OK了,如下:
java -Dserver.port=8080 \
-Dsentinel.dashboard.auth.username=admin \
-Dsentinel.dashboard.auth.password=admin \
-jar sentinel-dashboard-1.8.5.jar
真正使用时,使用功这个其实就ok了

内部的各种配置先不细说,后面会卓一进行介绍。
3 SpringCloud 整合Sentinel
- 1 引入相关的 jar
<!--sentinel依赖--> <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> - 2 添加配置
这一步是指明Dashboard的地址,这样Sentinel才可以和Dashboard正常通信# 已省略关系不大的配置 spring:application:# sennel使用该名称注册到Dashboardname: stock-server cloud:sentinel:transport:port: 8719 # dashboard控制面版与sentinel通信的本地端口dashboard: 127.0.0.1:8080 # sentinel控制面板地址 - 3 测试服务是否正常注册到了Dashboard
默认情况下服务启动以后是不会直接注册到Dashboard的,只有当有请求进来以后,服务才会注册到Dashboard,所以我们需要进行模拟一次服务请求,然后就可以正常在Dashboard看到服务了,每个服务下都会有以下的配置监控的菜单。我这里自己点了几次请求,所以是可以看到实时监控的数据的,若是没有实时数据这里是没有任何展示的。
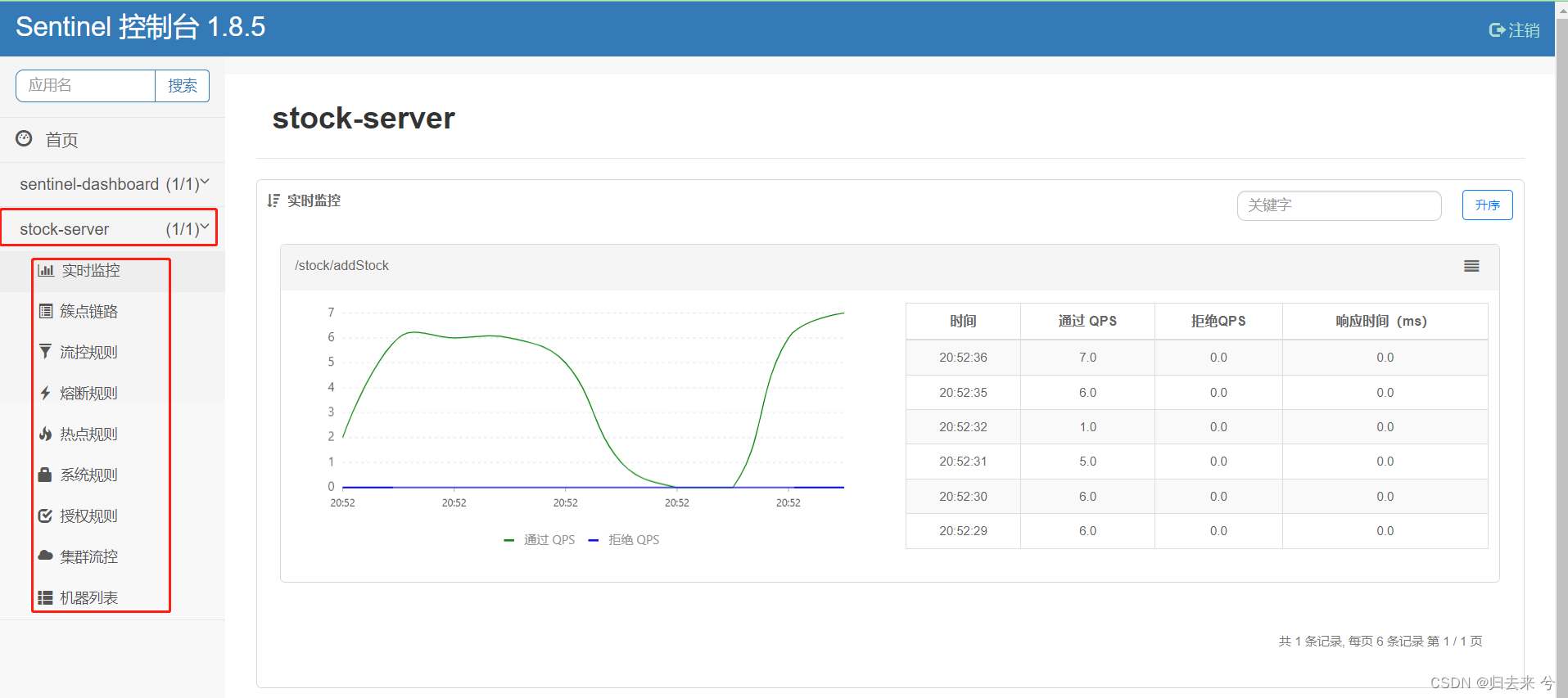
这样我们就简单完成了Sentinel和Dashboard的搭建。
三、服务降级
五大规则细说之前,必须得先说一下服务降级。服务降级是一种提升用户体验的方式,当用户的请求因系统原因被拒以后,系统返回一个事先设定好的、用户可以接受的,但又令用户并不满意的结果,这种请求处理方式称为服务降级。当服务降级达到阈值以后,就会触发熔断,先来看下目前SpringCloud中常见的降级处理方式有哪些。
1 服务降级-Sentinel
这里需要使用Sentinel的注解@SentinelResource,这个注解是Sentinel的核心注解,这里先简单说下后面会详细介绍这个注解的使用及各个参数的释义。该注解这里只是用于做服务降级,可以不去注册资源(声明value才会注册)。该注解有四个属性和服务降级有关:
关于@SentinelResource注解的官方详细介绍:注解@SentinelResource
- fallback和fallbackClass降级
- defaultFallback和fallbackClass降级
- exceptionsToIgnore属性:忽略异常,被忽略的异常不会触发降级
-
1.降级:fallback
fallback需要传入一个字符串,这个字符串就是我们降级的处理方法的方法名。那这个方法我们应该如何写呢,降级方法必须遵循以下规则- ① 返回值类型必须与原函数返回值类型一致
- ② 方法参数列表需要和原函数一致,或者可以额外多一个 Throwable 类型的参数用于接收对应的异常。
- ③ fallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定 fallbackClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数(使用fallbackClass时),否则无法解析
下面是示例代码,这里无需新增任何配置,还是基于2.2的配置来的。
import com.alibaba.csp.sentinel.annotation.SentinelResource; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.context.config.annotation.RefreshScope; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController;/*** @author pcc*/ @Slf4j @RefreshScope // 动态刷新nacos配置注解 @RestController @RequestMapping("/stock") public class StockController {@Value("${name}")String name;@RequestMapping("/addStock")@SentinelResource(fallback = "addStockFallBack")public void addStock() throws Exception{int i = 1/0;log.info("add stock start: {}",name);}/*** 这是方法降级的 方法* 这里可以不使用 static* @param throwable 触发的异常*/public static void addStockFallBack(Throwable throwable){log.info("addStock 触发方法降级: {}", throwable.getMessage());}}下面是运行截图:

-
2 降级:fallback配合fallbackClass、exceptionsToIgnore
若是接口比较多,所有的降级方法都放在接口里肯定是不合适的,会看着特别的乱,所以真实场景中我们都是将一个controller的降级方法放到一个单独的类中,然后使用@SentinelResource的fallbackClass指明对应的类,使用fallback指明降级的方法,这样就可以解开降级方法和接口类的耦合了,这里配合使用下exceptionsToIgnore属性。
这是服务降级的类/*** @author pcc* 这是降级类*/ @Slf4j public class StockDegrade {/*** 这是类降级的 方法* @param a 触发的异常*/public static void addStock(Throwable a) {log.info("add stock 类级降级: {}",a.getMessage());} }这是接口中使用降级:
import com.alibaba.csp.sentinel.annotation.SentinelResource; import com.cheng.stockserver.sentineldegrade.StockDegrade; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.context.config.annotation.RefreshScope; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController;/*** @author pcc*/ @Slf4j @RefreshScope @RestController @RequestMapping("/stock") public class StockController {@Value("${name}")String name;@SentinelResource(fallback = "addStock",fallbackClass = StockDegrade.class,exceptionsToIgnore = {ArithmeticException.class})@RequestMapping("/addStock")public void addStock() throws Exception{log.info("add stock start: {}",name);throw new RuntimeException("运行时异常");}}如上所示,通过fallbackClass指定降级方法所在类,使用fallback指定对应的降级方法。这样就可以将降级方法分离到单独的降级类中了。上面代码中是手动throw了一个RuntimeException异常,若是抛出的是ArithmeticException异常,则不会进入服务降级的方法中,而是会直接向上抛出,服务直接异常(假设没有统一异常处理的话)。而这里因为只忽略了ArithmeticException所以,还是会进入到降级方法内部。
特别注意:指定降级类时,降级方法必须是static的,否则无法解析 -
3 降级:defaultFallback 配合 fallback、fallbackClass、exceptionsToIgnore
defaultFallback应用在方法上时和fallback的用法完全一致,需要规则等也都一致,上面的两个例子将fallback换成defaultFallback是完全可行的。这里需要说两点defaultFallback的特殊之处- defaultFallback可以修饰类(官方文档说1.8.0开始支持,应该是支持所有接口的默认降级方法吧,经测试并没有这么支持)
- defaultFallback若是和fallback同时设置,则fallback生效,defaultFallback失效
下面展示defaultFallbck和fallback同时修饰一个接口时是谁生效
import com.alibaba.csp.sentinel.annotation.SentinelResource; import com.cheng.stockserver.sentineldegrade.StockDefaultDegrade; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.context.config.annotation.RefreshScope; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController;/*** @author pcc*/ @Slf4j @RefreshScope @RestController @RequestMapping("/stock") public class StockController {@Value("${name}")String name;/*** 这里同时使用了fallback 、defaultFallback* 当同时使用时,只有fallback生效**/@SentinelResource(defaultFallback = "stockDefaultFallback",fallback = "addStockFallback",fallbackClass = StockDefaultDegrade.class,exceptionsToIgnore = ArithmeticException.class)@RequestMapping("/addStock")public void addStock(){log.info("add stock start: {}",name);throw new RuntimeException("运行时异常1");}}下面是降级类及对应的方法:
import lombok.extern.slf4j.Slf4j;/*** @author pcc* 这是defaultFallback的降级类*/ @Slf4j public class StockDefaultDegrade {/*** 这是默认降级方法* @param throwable*/public static void stockDefaultFallback(Throwable throwable){log.info("触发defaultFallback的降级方法:" + throwable.getMessage() + " ");}/*** 这是fallback用的指定降级方法* @param throwable*/public static void addStockFallback(Throwable throwable){log.info("触发addStockFallback的降级方法:" + throwable.getMessage() + " ");} }调用对应接口时,可以发现真正触发的降级方法只有fallback指定的降级方法:

2 Sentinel 整合 OpenFeign
这里OpenFeign整合Sentinel只为了展示服务降级的处理,不做其他功能的延伸。OpenFeign整合Sentinel只需要两小步即可。
- 1 导入Sentinel的依赖
<!--sentinel依赖--> <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> - 2 开启Sentinel对OpenFeign的支持
在yml或者properties中配置即可
我们无需为Sentinel增加额外的配置就可以直接使用了# 已省略关系不大的配置 feign:sentinel:enabled: true # 开启sentinel对feign的支持
3 OpenFeign定义服务降级
OpenFeign支持两种服务降级的方式,不过需要整合Sentinel或者Hystrix,这里以整合Sentinel为例
- 1 FeignClient中使用fallback指定降级类
- 2 FeignClient中使用fallbackFactory指定降级类
既然支持了两种,那他们肯定有区别,最主要的区别是fallback获取不到异常,而fallbackFactory是可以知道具体异常的,因为知道了具体异常就可以根据不同异常做不同的处理,所以真实场景中大部分是使用fallbackFactory(也有少量用fallback的)。下面对他们进行详细说明:
-
- fallback服务降级
使用fallback必须满足以下条件
-
- fallback指定的类必须交给Spring容器管理
-
- fallback指定的类必须实现FeignClient修饰的feign接口
如此我们就可以将类交给fallback了,这是一旦有异常发生,就会引入到我们重写的对应方法中了。下面是测试代码:
这是feign接口代码:import org.springframework.cloud.openfeign.FeignClient; import org.springframework.web.bind.annotation.RequestMapping;/*** @author pcc* url: 用于指定三方接口,通过url指定的接口不会从注册中心获取服务列表,而是直接通过接口名拼接地址* name:用以声明feign调用的服务,这个必须与注册中心服务名保持一致* path:控制器上的类路径,如果不写path在方法上写全路径也是一样的* configuration:配置类,可以配置一些公共的参数,只对当前类下的接口生效,属于局部配置* fallback : 声明降级类**/ @FeignClient(name = "stock-server",path = "/stock",fallback = StockFeignControllerDegrade.class) public interface StockFeignController {@RequestMapping("/addStock")void addStock(); }下面是降级类的代码,很简单,就是无法知道因何种异常导致的服务降级
import lombok.extern.slf4j.Slf4j; import org.springframework.stereotype.Component;/*** @author pcc*/ @Slf4j @Component public class StockFeignControllerDegrade implements StockFeignController{@Overridepublic void addStock() {log.info("addStock: 降级方法处理中。。。");} }然后我们来测试下,可以发现服务端异常时正常进入到了降级方法内部(服务提供方代码就是抛出了一个异常)。

- fallback服务降级
-
- fallbackFactory服务降级
使用fallbackFactory需要遵循以下规则
- 1 实现类需要交给Spring管理
- 2 实现类需要实现FallbackFactory接口并传入Feign接口的泛型
以下是Feign接口的代码
/*** @author pcc* url: 用于指定三方接口,通过url指定的接口不会从注册中心获取服务列表,而是直接通过接口名拼接地址* name:用以声明feign调用的服务,这个必须与注册中心服务名保持一致* path:控制器上的类路径,如果不写path在方法上写全路径也是一样的* configuration:配置类,可以配置一些公共的参数,只对当前类下的接口生效,属于局部配置* fallback : 声明降级类* fallbackFactory: 声明降级工厂类**/ @FeignClient(name = "stock-server",path = "/stock",fallbackFactory = StockFeignCallBackFactory.class) public interface StockFeignController {@RequestMapping("/addStock")void addStock(); }下面是降级工厂实现类
import lombok.extern.slf4j.Slf4j; import org.springframework.cloud.openfeign.FallbackFactory; import org.springframework.stereotype.Component;/*** @author pcc*/ @Slf4j @Component public class StockFeignCallBackFactory implements FallbackFactory<StockFeignController> {@Overridepublic StockFeignController create(final Throwable cause) {return new StockFeignController() {@Overridepublic void addStock() {log.info("addStock:fallbackFactroy降级中:{}",cause.getMessage());}};} }上面代码为了演示异常的明细,把Throwable cause 改成了 final Throwable cause,不然内部类无法操作变量cause(经常写lambda这个问题应该不会陌生)。执行后可以看到下图中我们在降级方法中拿到了远端接口的异常信息。

需要补充说的一点是服务降级和统一异常处理的关系:
被服务降级处理的异常,自然是无法被全局异常处理捕获的。全局异常处理可以看成是一个兜底降级处理 - fallbackFactory服务降级
四、限流-熔断规则:DegradeRule
注意:当前使用环境为SringCloud,若环境不同使用熔断会有略微区别
说熔断之前先说说降级的处理。服务的降级处理我们是通过声明降级方法来实现的,上一个小节介绍了两种处理方法:使用@SentinelResource或者@FeignClient来实现。他们都可以实现服务异常时触发降级方法。那熔断和服务降级是什么关系呢?服务熔断我们需要配置一些规则,比如1s中内的请求有如果有10个,其中5个出了异常我们就熔断。触发熔断时就会调用降级方法。到这里可能会有疑问?普通异常调用降级方法,熔断也调用异常方法,那我为什么还要设置熔断呢,都默认走降级方法不就行了吗?答案肯定是不行的,不然要熔断干啥,熔断更多应用场景是在高并发场景下,防止服务在异常场景或者资源受限场景下占用过多请求资源而存在的(若是调用异常还接着调用其实是一种线程资源的浪费;若是响应比较慢,多个服务还一直在调用这个接口,也是一种资源浪费,当然若是核心服务就得另说了)。所以熔断提供了一个熔断时间的概念,在触发熔断时给一个熔断时间,在熔断时间内当前接口或者资源收到的请求都会直接进入降级方法,而不会进入方法内部。这样是可以解决很多问题的,比如服务处于异常状态就没有必要去做一些列的处理而占用资源,只需要做一个降级的处理即可。当时间达到熔断时间的限定后,下一次请求就会进入到方法,若是当前方法有一次触发降级,则会直接熔断而不是去判断熔断规则。若是正常则会退出熔断。
Sentinel的熔断支持三种策略分别是:慢调用比例、异常比例、异常数三种,下面针对这三种熔断规则。分别从页面配置和API配置两种形式进行详细说明。
1.慢调用比例熔断-页面
慢调用比例就是字面意思,根据请求中慢调用所占有的总请求数的比例来进行熔断,以下是使用页面配置的注意点:
- 页面配置熔断规则,方法上可以不增加@SentinelResource注解,不增加就走默认的降级方法
- 页面配置的熔断规则,无论是重启dashboard还是重启目标服务,都会导致熔断规则的消失
下面来配置慢调用比例的熔断规则,首先需要进入到“簇点链路”页面中(簇点链路里展示的其实就是我们产生了请求的接口,对于Sentinel来说就是资源),如下:
可以看到,上面是未添加任何配置时的截图,此时我们点击“熔断”就可以添加熔断规则了。
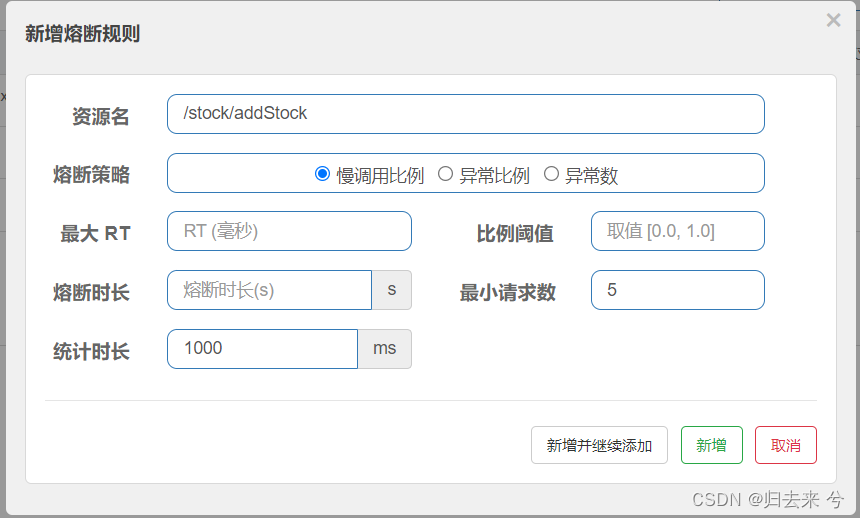
上图是一个慢调用比例的熔断规则的配置页面,可以看到总共就五个业务参数(除了慢调用比例):
- 最大RT:单位ms,接口最大相应时间,超过这个时间被认为是慢调用
- 比例阈值:慢调用请求数/总请求数,允许的最大值
- 熔断时长:触发熔断后,接口或者资源进入熔断状态的时间
- 请求最小数:并发的请求数,只有并发达到这个数量才会对慢调用比例进行计算,然后达到阈值就会触发熔断
- 统计时长:统计并发请求数的时间
如上图我们可以做如下配置,配置的意义就是:
统计1s内并发请求数有没有达到3,如果达到了再去根据最大RT计算这些请求里慢调用的比例,比例计算完毕后与比例阈值进行比对,若是达到阈值,则触发熔断,熔断时间为10s,在10s内所有的请求都不会进入方法,而是会直接进入降级方法内部,这里没有声明降级方法,则会进入默认的降级方法内部。当熔断时间结束后,下一次请求若是成功则会重新开始计算,若是失败则直接进入再一次熔断
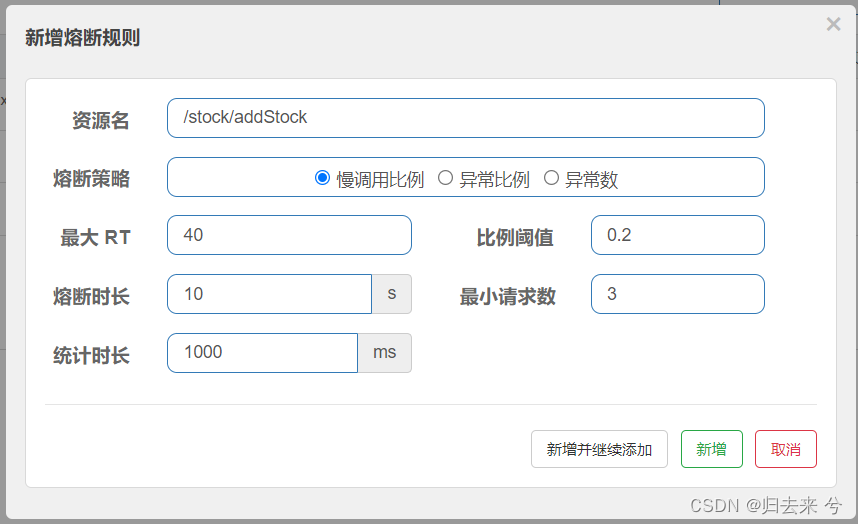
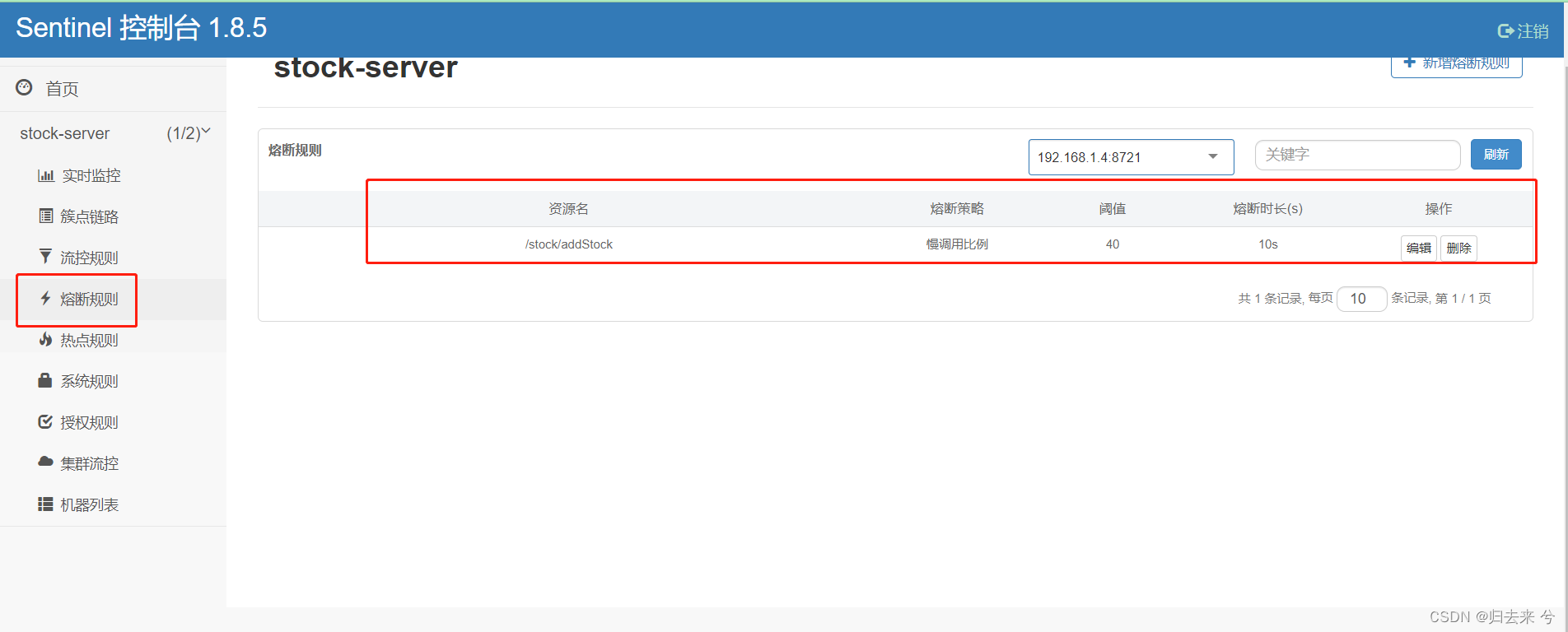
上面配置完成后就可以在“熔断规则”菜单里看到我们刚刚配置的熔断规则了
然后就可以测试了,这里需要模拟慢调用,我们可以产生一个100以内的随机数然后进行sleep,来模拟慢调用
@RequestMapping("/addStock")public void addStock() throws Exception{log.info("add stock start: {}",name);// 随机休眠100ms以内的时间-用于测试: 熔断规则-慢调用String s = String.valueOf(Math.floor(Math.random() * 100));Thread.sleep(Integer.parseInt(s.split("\\.")[0]));}
然后看下触发结果:
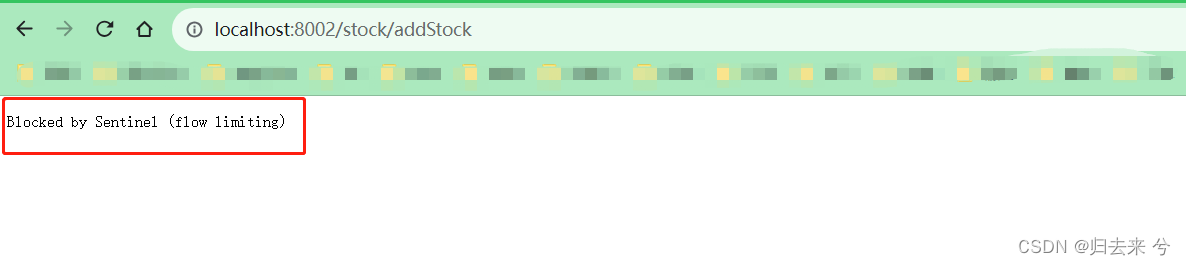
这个就是默认的降级方法的返回了。
上面展示的例子是没有使用@SentinelResource,同时也没有指定降级方法的例子。下面说下使用@SentinelResource同时指定降级方法。使用@SentinelResource指定降级方法上一节也说了,可以直接使用fallback或者fallback+fallbackClass一起来指定降级方法。这里还需要使用@SentinelResource的另外一个属性value,这个属性的作用是将方法注册为Sentinel中的资源,java代码如下(使用@SentinelResource必须指定降级方法,一定使用了该注解,系统就不会走默认降级方法了):
// 使用注解,表明Sentinel资源,同时指明降级方法@SentinelResource(value = "addStock",fallback = "addStockFallback",fallbackClass = StockDefaultDegrade.class,exceptionsToIgnore = ArithmeticException.class)@RequestMapping("/addStock")public void addStock() throws Exception{log.info("add stock start: {}",name);// 随机休眠100ms以内的时间-用于测试: 熔断规则-慢调用String s = String.valueOf(Math.floor(Math.random() * 100));Thread.sleep(Integer.parseInt(s.split("\\.")[0]));}
下面是降级方法的代码:
@Slf4j
public class StockDefaultDegrade {/*** 这是fallback用的指定降级方法* @param throwable*/public static void addStockFallback(Throwable throwable){log.info("触发addStockFallback的降级方法:" + throwable.getMessage() + " ");}
}
页面配置规则和上一次使用默认降级方法的配置相同,如下:
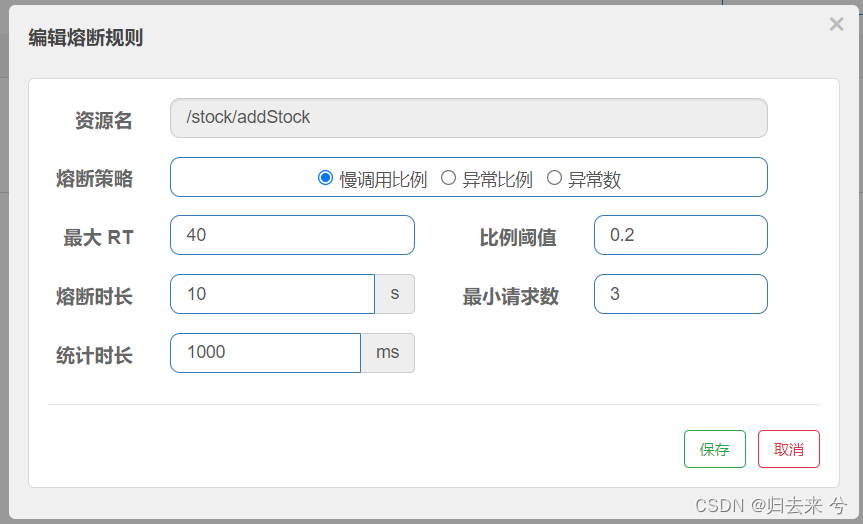
此时当我们再次出发降级方法时,就不会有默认的降级删除了,就会进入到我们自己的降级方法内部:
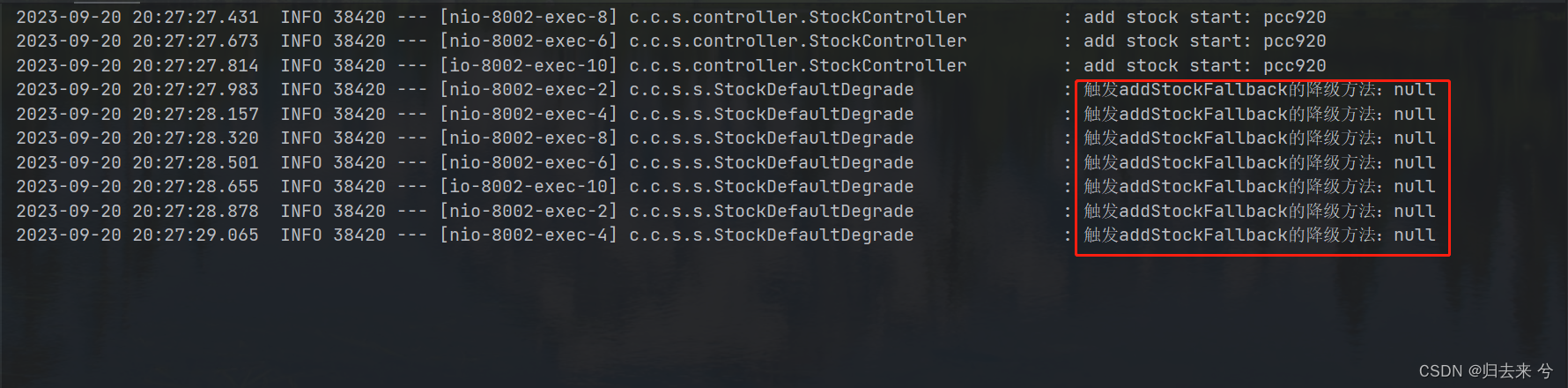
特别注意:这里只有标红框的才是真正出发熔断时执行的降级方法,可以看到这里获取到的异常都是null,为什么呢?因为熔断后我们的请求会直接进入到降级方法内部,此时方法并没有报错,所以这里会有null,此时要是给方法内部随机进行抛出异常,可能还会有打印异常的降级方法出发,不过那个就不是熔断触发的了,熔断触发的降级方法无论是慢调用比例还是异常数还是异常比例,他的异常信息肯定都是null,以此也可以区分是方法异常出发的降级还是熔断触发的降级
1.慢调用比例熔断-API
上面介绍了使用dashboard进行配置慢调用比例的熔断,介绍了不使用SentinelResource注解时的降级,和自定义降级方法的熔断。这里说下如何使用API来配置熔断,真实场景里大部分还是使用API来进行配置,然后在特殊场景下配合dashboard进行调整。使用API注意以下问题:
- 使用API配置熔断,可以完全不适用dashboard,使用dashboard完全是为了更清晰的看到API的配置结果
- 配置熔断规则时需要三步:设置资源名和熔断策略,配置参数,将规则交给规则管理器
- 使用API配置的熔断,如果使用了dashboard,dashboard启动后就可以看到规则
- 使用API配置的熔断,dashboard也可以修改,修改后会生效,但是服务或者dashboard重启就会失效了
- 最后不要忘记需要将对象交给Spring容器进行管理
降级方法的代码和接口的方法和上面没有区别,这里就不重复贴了,这里展示下慢调用比例熔断规则的配置,这里展示了三种的写法便于对比三种写法的区别,其实都是需要三步,只是后面的两种第二步只有四个参数,其他都没有区别。
/*** @author pcc* 三种熔断规则不可以同时设置到一个资源上,若是同时作用到一个资源上,最后加载的规则会覆盖之前的规则* 最终只有一个生效*/
@Configuration
public class FuseConfig {// 熔断规则-慢调用比例@Beanpublic DegradeRule degradeRule(){DegradeRule degradeRule = new DegradeRule();// 资源名,资源名是唯一的degradeRule.setResource("addStock");// 熔断策略-0 慢调用比例 ,1 异常比例 ,2 异常数degradeRule.setGrade(RuleConstant.DEGRADE_GRADE_RT);// 熔断时长,单位为 sdegradeRule.setTimeWindow(10);// 触发熔断的最小请求数,需要配合下面的时间一起,默认5degradeRule.setMinRequestAmount(3);// 触发熔断的最小请求数的单位时间ms默认1000ms(这个时间内请求数达到最小请求,才会进行计算时间超过阈值的请求,然后计算比例,比例达到后才会进行熔断)degradeRule.setStatIntervalMs(1000);// 慢调用比例模式下为慢调用临界 RT,单位ms(超出该值计为慢调用);异常比例/异常数模式下为对应的阈值degradeRule.setCount(40);// 慢调用比例阈值默认1.0,sentinel1.8.0加入,0.0-1.0 之间degradeRule.setSlowRatioThreshold(0.2);// 将熔断规则交给熔断规则管理器List<DegradeRule> rules = new ArrayList<DegradeRule>();rules.add(degradeRule);DegradeRuleManager.loadRules(rules);return degradeRule;}// 熔断规则-异常比例@Beanpublic DegradeRule exceptionRatioRule(){DegradeRule degradeRule = new DegradeRule();// 该熔断规则对应资源名degradeRule.setResource("addStock");// 熔断策略-异常比例degradeRule.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO);// 异常比例阈值20%degradeRule.setCount(0.2);// 熔断时间单位sdegradeRule.setTimeWindow(10);// 触发熔断的最小请求数,需要配合下面的时间一起,默认5degradeRule.setMinRequestAmount(3);// 触发熔断的最小请求数的单位时间ms默认1000ms(这个时间内请求数达到最小请求,才会进行计算时间超过阈值的请求,然后计算比例,比例degradeRule.setStatIntervalMs(1000);// 将熔断规则交给熔断规则管理器-这里可以使用单例集合,因为无论在哪里声明的规则都是要交给管理器的// 即使在这里将别的规则也加载了也没问题,所以可以使用单例集合DegradeRuleManager.loadRules(Collections.singletonList(degradeRule));return degradeRule;}// 熔断规则-异常数@Beanpublic DegradeRule execptionCountRule(){DegradeRule degradeRule = new DegradeRule();// 熔断资源degradeRule.setResource("addStock");// 熔断策略-异常数degradeRule.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_COUNT);// 异常数的阈值degradeRule.setCount(2);// 熔断触发最小请求数degradeRule.setMinRequestAmount(3);// 熔断最小请求书的统计时长,默认1000msdegradeRule.setStatIntervalMs(1000);// 熔断时间degradeRule.setTimeWindow(10);// 将熔断规则交给熔断规则管理器-这里可以使用单例集合,因为无论在哪里声明的规则都是要交给管理器的DegradeRuleManager.loadRules(Collections.singletonList(degradeRule));return degradeRule;}
}
结果的话和上面没有区别,就不重复贴了。
2.异常比例熔断-页面
除了页面的配置有略微区别,其他都和慢调用比例的页面配置一样。
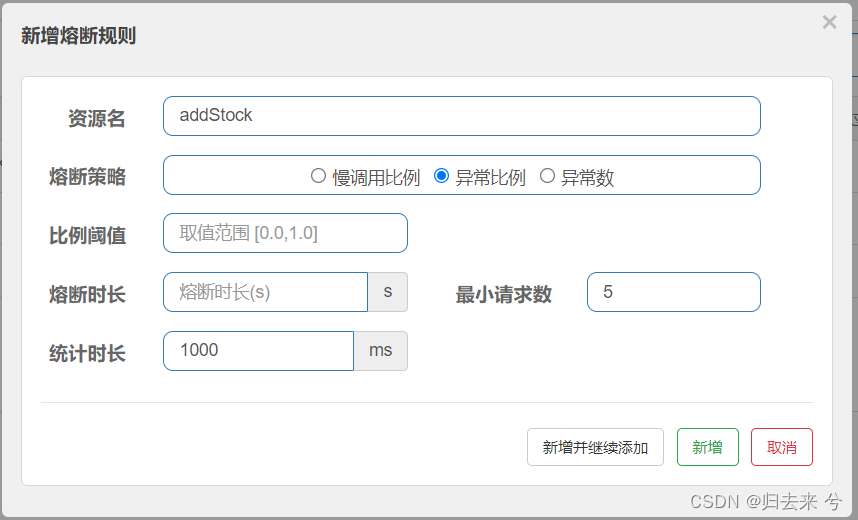
页面也很好理解,就是配置异常比例的阈值,达到了阈值就会触发熔断,然后全部执行降级方法。这里验证的话直接根据随机跑异常就行,下面是java代码:
/*** 这里同时使用了fallback 、defaultFallback* 当同时使用时,只有fallback生效**/@SentinelResource(value = "addStock",defaultFallback = "stockDefaultFallback",fallback = "addStockFallback",fallbackClass = StockDefaultDegrade.class,exceptionsToIgnore = ArithmeticException.class)@RequestMapping("/addStock")public void addStock() throws Exception{log.info("add stock start: {}",name);// 随机休眠100ms以内的时间-用于测试: 熔断规则-慢调用String s = String.valueOf(Math.floor(Math.random() * 100));Thread.sleep(Integer.parseInt(s.split("\\.")[0]));// 随机产生异常用于测试:熔断规则-异常比例/异常数if(Integer.parseInt(s.split("\\.")[0])>50){throw new RuntimeException("运行异常哈");}}
这样就会有一定比例的请求抛出RuntimeException,主要点的够快就会触发熔断了。触发后没有区别了。这里使用的降级方法都是一个(同一个资源只能由一个降级方法)。
2.异常比例熔断-API
这里需要说的是setCount方法,其他没啥需要说的了。这个方法在三种熔断策略中都有,但是代表的含义却是不一样的,需要特别注意。在RT中代表慢调用的时长单位是ms,在异常比例中代表的是异常比例没有单位取值是0.0-1.0之间,在异常数中代表的异常的个数。其他则没有好说的了,这里还是贴下三种API的全部代码:
/*** @author pcc* 三种熔断规则不可以同时设置到一个资源上,若是同时作用到一个资源上,最后加载的规则会覆盖之前的规则* 最终只有一个生效*/
@Configuration
public class FuseConfig {// 熔断规则-慢调用比例@Beanpublic DegradeRule degradeRule(){DegradeRule degradeRule = new DegradeRule();// 资源名,资源名是唯一的degradeRule.setResource("addStock");// 熔断策略-0 慢调用比例 ,1 异常比例 ,2 异常数degradeRule.setGrade(RuleConstant.DEGRADE_GRADE_RT);// 熔断时长,单位为 sdegradeRule.setTimeWindow(10);// 触发熔断的最小请求数,需要配合下面的时间一起,默认5degradeRule.setMinRequestAmount(3);// 触发熔断的最小请求数的单位时间ms默认1000ms(这个时间内请求数达到最小请求,才会进行计算时间超过阈值的请求,然后计算比例,比例达到后才会进行熔断)degradeRule.setStatIntervalMs(1000);// 慢调用比例模式下为慢调用临界 RT,单位ms(超出该值计为慢调用);异常比例/异常数模式下为对应的阈值degradeRule.setCount(40);// 慢调用比例阈值默认1.0,sentinel1.8.0加入,0.0-1.0 之间degradeRule.setSlowRatioThreshold(0.2);// 将熔断规则交给熔断规则管理器List<DegradeRule> rules = new ArrayList<DegradeRule>();rules.add(degradeRule);DegradeRuleManager.loadRules(rules);return degradeRule;}// 熔断规则-异常比例@Beanpublic DegradeRule exceptionRatioRule(){DegradeRule degradeRule = new DegradeRule();// 该熔断规则对应资源名degradeRule.setResource("addStock");// 熔断策略-异常比例degradeRule.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO);// 异常比例阈值20%degradeRule.setCount(0.2);// 熔断时间单位sdegradeRule.setTimeWindow(10);// 触发熔断的最小请求数,需要配合下面的时间一起,默认5degradeRule.setMinRequestAmount(3);// 触发熔断的最小请求数的单位时间ms默认1000ms(这个时间内请求数达到最小请求,才会进行计算时间超过阈值的请求,然后计算比例,比例degradeRule.setStatIntervalMs(1000);// 将熔断规则交给熔断规则管理器-这里可以使用单例集合,因为无论在哪里声明的规则都是要交给管理器的// 即使在这里将别的规则也加载了也没问题,所以可以使用单例集合DegradeRuleManager.loadRules(Collections.singletonList(degradeRule));return degradeRule;}// 熔断规则-异常数@Beanpublic DegradeRule execptionCountRule(){DegradeRule degradeRule = new DegradeRule();// 熔断资源degradeRule.setResource("addStock");// 熔断策略-异常数degradeRule.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_COUNT);// 异常数的阈值degradeRule.setCount(2);// 熔断触发最小请求数degradeRule.setMinRequestAmount(3);// 熔断最小请求书的统计时长,默认1000msdegradeRule.setStatIntervalMs(1000);// 熔断时间degradeRule.setTimeWindow(10);// 将熔断规则交给熔断规则管理器-这里可以使用单例集合,因为无论在哪里声明的规则都是要交给管理器的DegradeRuleManager.loadRules(Collections.singletonList(degradeRule));return degradeRule;}
}
3.异常数熔断-页面和API
这里区别不大,相比于上面改动量也很小,不值得分开说了,就一起看下即可,下面是配置页面的内容:
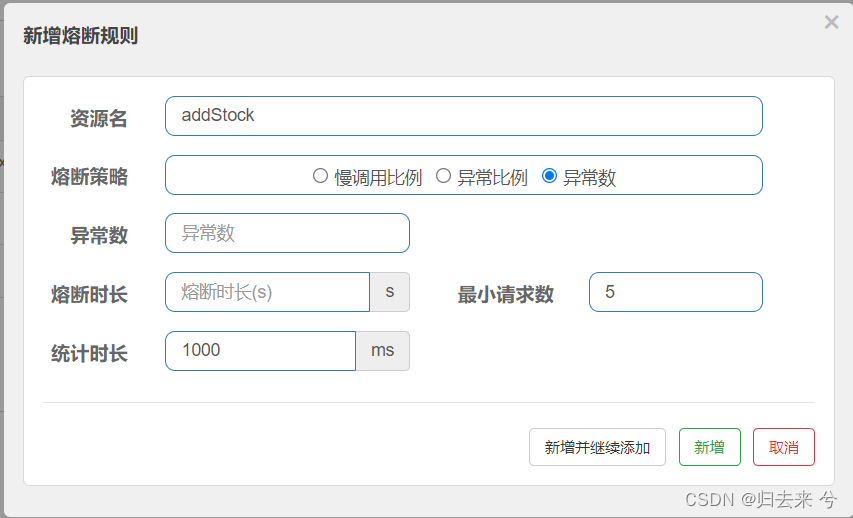
可以看到相比于异常比例来说,只是异常比例换成了异常数,甚至在API的写法中。异常比例中的比例阈值与异常数中的异常数都是用count来表示的。因此API的区别就是一个熔断策略的区别,这里就不重复展示了。
4.补充其他关键点
4.1 增加@SentinelResource注解后,默认降级不生效
上面其实已经阐述过这个问题了其实,当我们不使用@SentinelResource注解时,一旦触发熔断,走的是默认的降级方法,但是当我们一旦增加了这个注解后,则必须声明降级方法了,否则会报500,而不会走系统默认的降级方法。当然真实场景中不会有人使用熔断而不使用降级方法的,这个只需要在自己验证功能时进行注意即可。
4.2 统一降级处理
上面说的默认的降级方法,其实就是Sentinel提供的统一的异常处理(有点类似全局异常处理器),这个也是可以改变的,而且我们可以通过这个统一异常处理来指定返回信息、或者返回一个页面、或者重定向到一个指定的网站或静态资源上都是可以的。这是默认的统一降级处理方法:
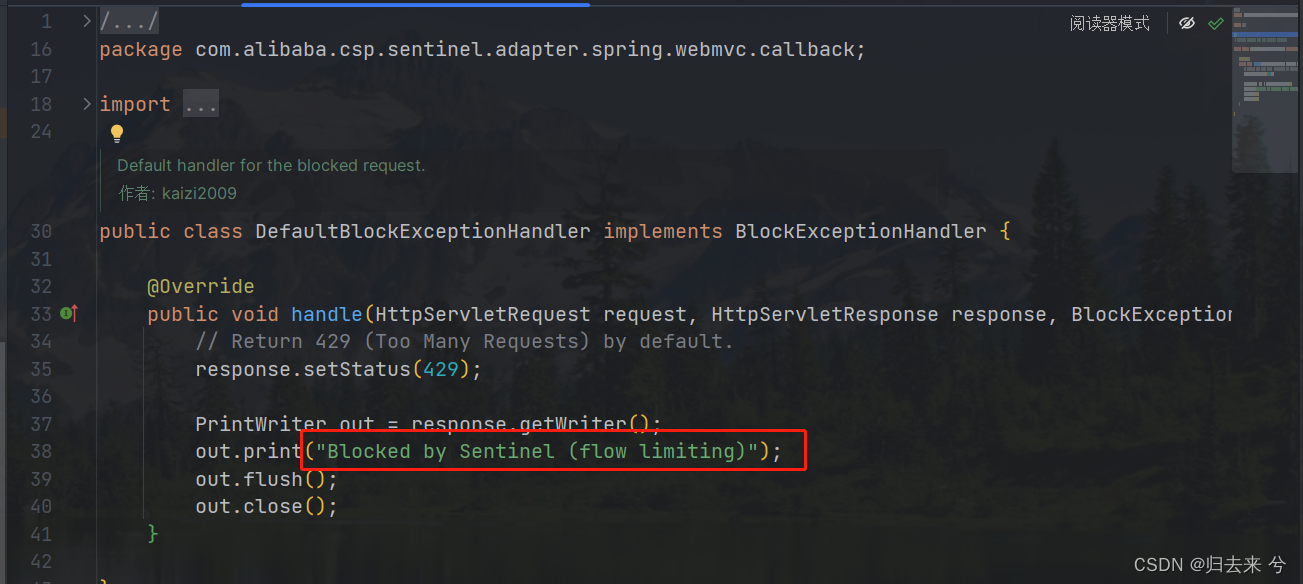
那如果我们自己实现这个统一异常处理,该如何做呢,其实只需要参照他的写法即可如下:
import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.BlockExceptionHandler;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import org.springframework.stereotype.Component;import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;/*** @author pcc*/
@Component
public class GlobalDegradeConfig implements BlockExceptionHandler {@Overridepublic void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {response.setStatus(429);response.setHeader("Content-Type", "application/json");response.setCharacterEncoding("UTF-8");response.getWriter().write("{\"code\":429,\"msg\":\"请求过于频繁,请稍后再试\"}");response.getWriter().flush();}
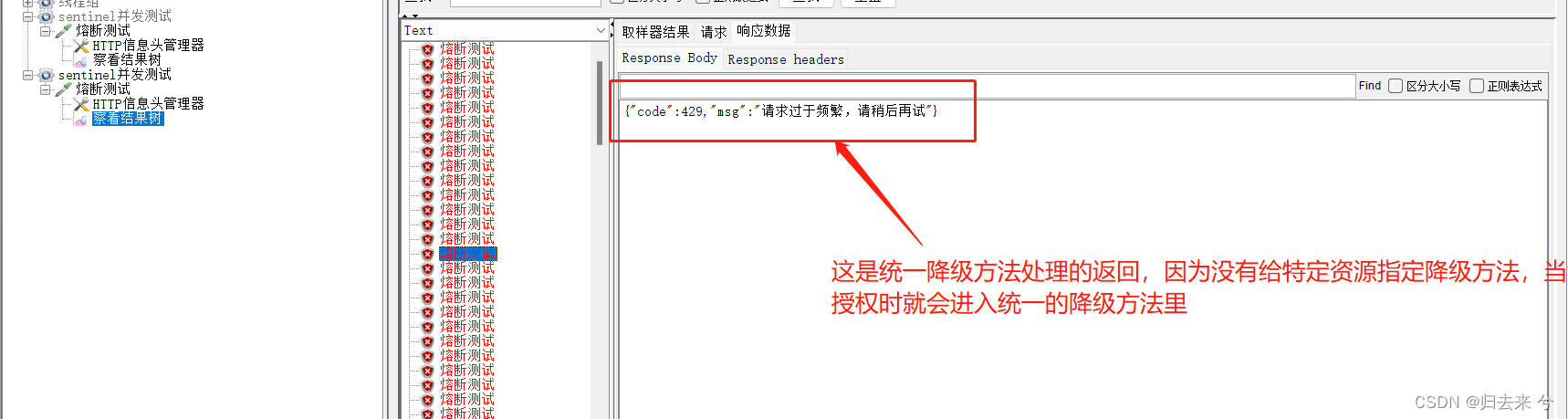
}验证的话也很简单,只需要我们把接口上的@SentinelResource注解去掉即可,然后在页面从新配置熔断规则,此时就可以测试了,结果如图:

不过使用这种统一的降级处理,会有一个问题,那就是若是发生异常时没有降级方法,则会直接抛出到用户这里了,因为这个统一的只适用于熔断触发的降级场景。所以还是不建议使用这种统一的熔断降级处理,而是使用@SentinelResource来指定降级方法。这样才不会有普通异常无法处理的场景。
4.3 抛出BLockException不会触发熔断规则
这个场景在真实业务场景中应该很少会碰到,但是自己测试时是可能会碰到的,若是我们使用的是异常比例和异常数的熔断策略,而代码中往上抛的是BlockException的子类异常(五种规则对应的异常)则是无法正常触发熔断规则的。有兴趣的可以验证下
4.4 配置spring.cloud.sentinel.eager:true
开启Sentinel加载服务的饥饿模式,默认情况下只有服务的接口被调用之后,Sentinel才会加载目标服务,开启饥饿加载后,服务启动会直接加载,不过若是没有请求进来,我们在“实时监控”和“簇点链路”中还是无法看到数据的。
五、限流-流控规则:FlowRule
限流和熔断是Sentinel的最重要的两个规则,熔断保证的是服务在异常场景下的正确返回,而流控则保证的是服务在高并发下的稳定性,我们通过设置合适的流控策略来保证高并发场景下服务不会被冲垮。
可以设想下无论任何公司都不可能无节制的扩充服务器,那么在有限的服务器资源内我们就需要考虑如何保证超出服务器集群允许的并发情况下的请求如何处理,这时候就需要使用流控规则了。Sentinel流控规则按照类型划分支持两大类:QPS(Queries Per Second)、并发线程数(可以把并发线程数看成TPS)。这也是当下最流行的两种解决方案。区别的话下面再细说吧。
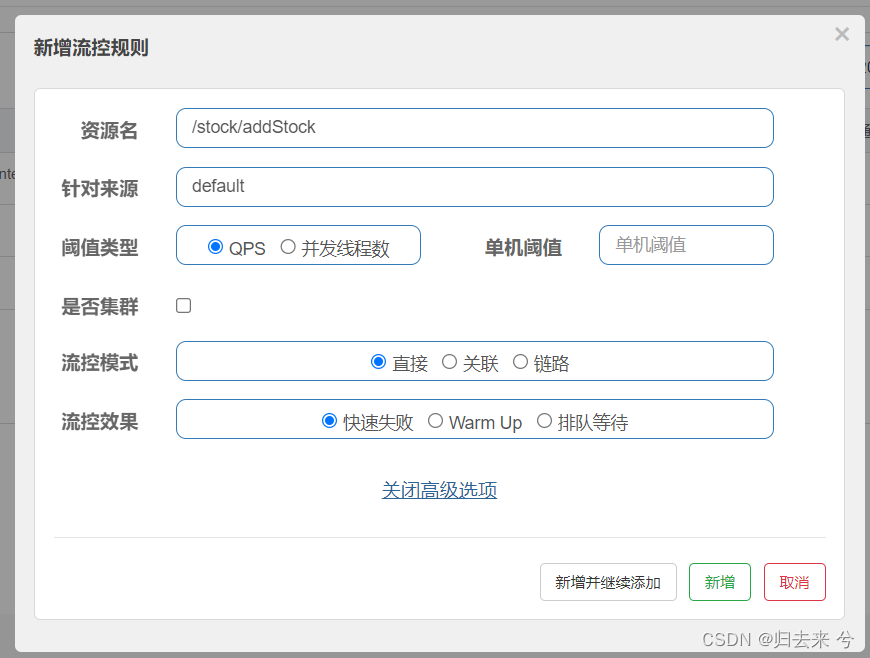
这是Sentinel Dashboard流控规则配置的页面。包含以下几块内容,初步一看会感觉各个参数的组合场景会很多,其实一般关注阈值类型、集群即可。如果有特殊需要场景可以在考虑流控模式和效果的设置。
- 资源名:注册到Sentinel中的资源,需要使用@SentinelResource来声明
- 针对来源:Sentinel支持针对不同来源来实现流控,比如我是一个服务提供商,有百度、阿里、腾讯都使用我的服务,我只给腾讯设置流控规则,此时就可以使用这个属性,不过这个需要代码上增加一些改动,会单独拿出来说,因为无论是QPS还是并发线程数都是支持针对来源的,这块会单独说下。
- 阈值类型和单机阈值:这个就是说的Sentinel支持的两种规则
- 是否集群:服务基本都是集群的,所以这个基本必选,不过需要我们设置集群模式下是单机均摊还是总体阈值,这块也会单独说,因为QPS和并发线程数都是支持的
- 流控模式:集群模式下不支持,这里支持设置直接、关联、链路,QPS和并发线程数都支持,会单独具体介绍
- 流控效果:集群模式下不支持,只有QPS支持,可以选择快速失败、预热(warm up)、排队等待,这个也会单独介绍。
上面已经说了有一些配置是支持QPS、并发线程数都可以设置的,这种参数就只会使用其中一个场景来演示了,比如:来源、集群、流控模式等。
1.QPS流控-页面
需要注意的是,当我们声明了流控规则后,如果使用的是fallback声明的降级方法,那么无论是熔断还是流控都是调用的是fallback中的降级方法,如果使用了blockhandler则无论是熔断还是流控都会调用blockhandler的方法,当然声明了blockhandler普通的降级还是会走fallback。还需要注意的点是,若是同时声明了熔断和流控,则只有流控生效,熔断不会生效。
- 1.使用fallback声明降级方法来处理降级、熔断、流控等
想要在页面配置流控规则,首先需要将方法交给Sentinel进行管理,然后还需要为他声明降级方法,无论是降级、熔断还是流控都可以正常进入到fallback方法内部。
这是Sentinel管理的资源代码:
package com.cheng.stockserver.flowrule.controller;import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.cheng.stockserver.flowrule.degradeclass.BlockMethod;
import com.cheng.stockserver.flowrule.degradeclass.DegradeMethod;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;/*** @author pcc* 正常情况下sentinel应该使用在customer端,而不是server端,这里只是测试一下就无所谓了*/
@Slf4j
@RestController
@RequestMapping("/flow")
public class controller {@Value("${name}")String name;@RequestMapping("/testFlowRule")@SentinelResource(value = "testFlowRule",fallback = "testFlowRule", // 降级配置fallbackClass = DegradeMethod.class)public String testFlowRule(){log.info("testFlowRule start, name : {}",name);// 产生一个100以内的随机数int i = Integer.parseInt(String.valueOf(Math.random() * 100).split("\\.")[0]);// 当随机数大于60时,抛出异常(值越大抛出异常概率越小) 方便验证降级、熔断if(i>60){throw new RuntimeException("testFlowRule error");}return "success";}}这是声明的fallback的方法,这里打印Throwable的真正类型可以知道到底是那种场景触发的该方法:有可能是降级、也有可能是熔断、也有可能是流控,通过异常类就可以区分了。
import lombok.extern.slf4j.Slf4j;/*** @author pcc*/
@Slf4j
public class DegradeMethod {public static String testFlowRule(Throwable th){log.info("触发降级方法: {},异常:{}",th.getMessage(),th.getClass().getName());return "降级方法返回:success";}
}
熔断规则配置和上面没有区别,这里使异常比例来配置熔断规则:
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeRule;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeRuleManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
import java.util.List;/*** @author pcc*/
@Configuration
public class DegradeConfig {/*** 如果有多个熔断规则应该这么写* 或者是使用一个单例list,把所有的熔断规则都放进去,最后一次交给* 熔断规则管理器* @return*/@Beanpublic DegradeRule getDegradeRule() {List<DegradeRule> lists = new ArrayList<DegradeRule>();/*** 这是第一个熔断规则,支持多个规则的配置*/// 这里使用熔断规则的异常比例规则来处理降级// 使用异常比例更容易看到是普通降级还是熔断导致的降级(看异常信息有没有值就知道了)DegradeRule degradeRule = new DegradeRule();// 声明熔断对应的资源、sentinelresource中value声明degradeRule.setResource("testFlowRule");// 降级策略使用异常比例degradeRule.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO);// 设置降级规则degradeRule.setCount(0.5); // 20%的异常会熔断degradeRule.setTimeWindow(10); // 熔断10sdegradeRule.setMinRequestAmount(2);// 最小请求数degradeRule.setStatIntervalMs(1000);// 最小请求数的统计时间1s// 将降级规则交由熔断管理器// 以上配置,1s内有两次请求,其中只要有一个异常就会熔断10slists.add(degradeRule);DegradeRuleManager.loadRules(lists);return degradeRule;}
}
熔断只需要这些,其实都是之前已经介绍过的东西,这里主要是演示熔断和流控同时设置的效果,所以需要把熔断再配置一遍。流控这里使用页面进行配置,我们针对刚刚熔断规则配置的资源testFlowRule,再配置下流控规则,如下:
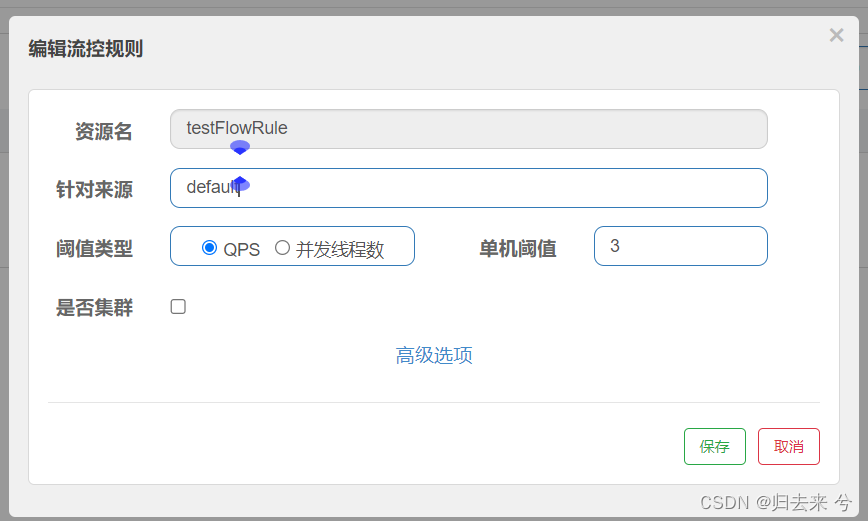
当配置了这个规则后,QPS大于3的请求就会直接进入到fallback方法,只要QPS不大于3请求都是可以正常进入到资源内部的。如下是运行截图:
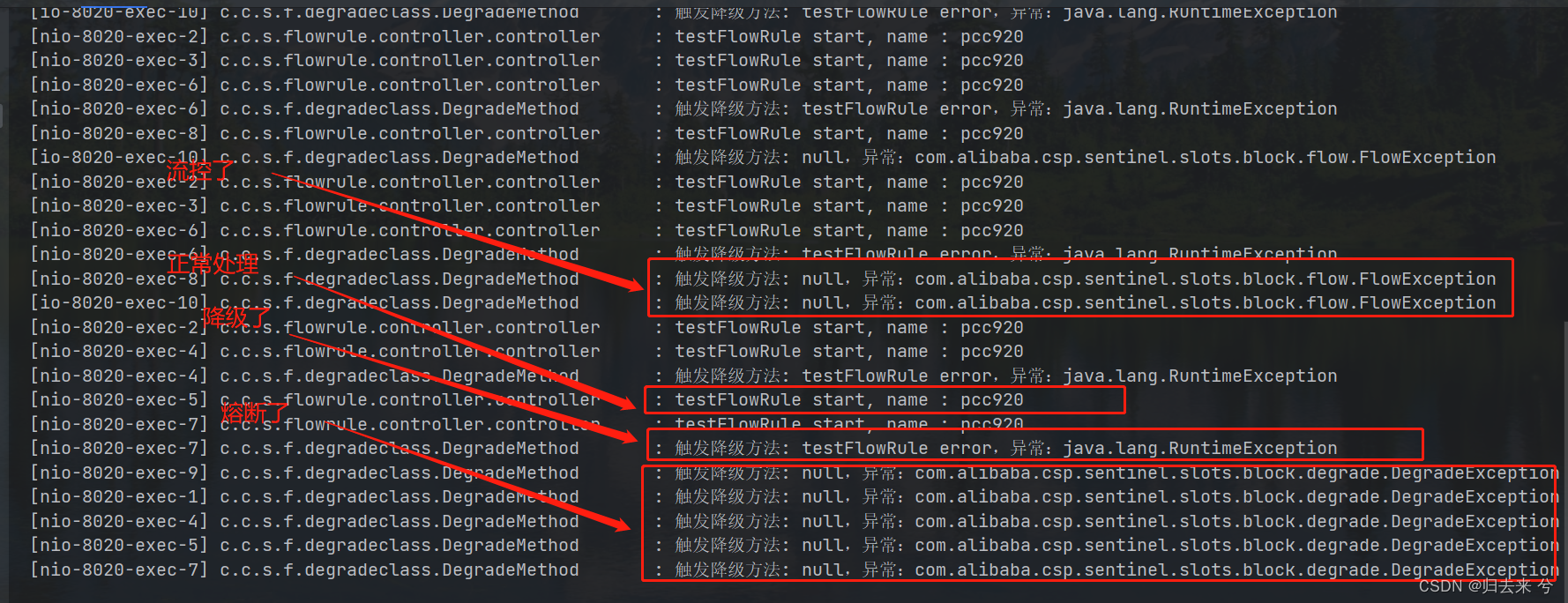
可以看到降级方法有三种输出分别是降级输出、流控输出、熔断输出。这里可以看到当熔断和降级同时作用于一个资源时的效果。
总结以下几点需要牢记:
①.fallback可以同时处理降级、熔断、流控等场景,内部可以通过instanceof来判断异常类实现不同场景的不同处理
②.当对于一个资源同时设置了熔断和流控时,流控规则的触发需要有个前提就是该资源不能熔断,熔断期间无法正常触发流控,这也是合理的,因为资源都异常了也没有必要去访问了,不访问更不需要流控。正常请求应该是下面这个流程:
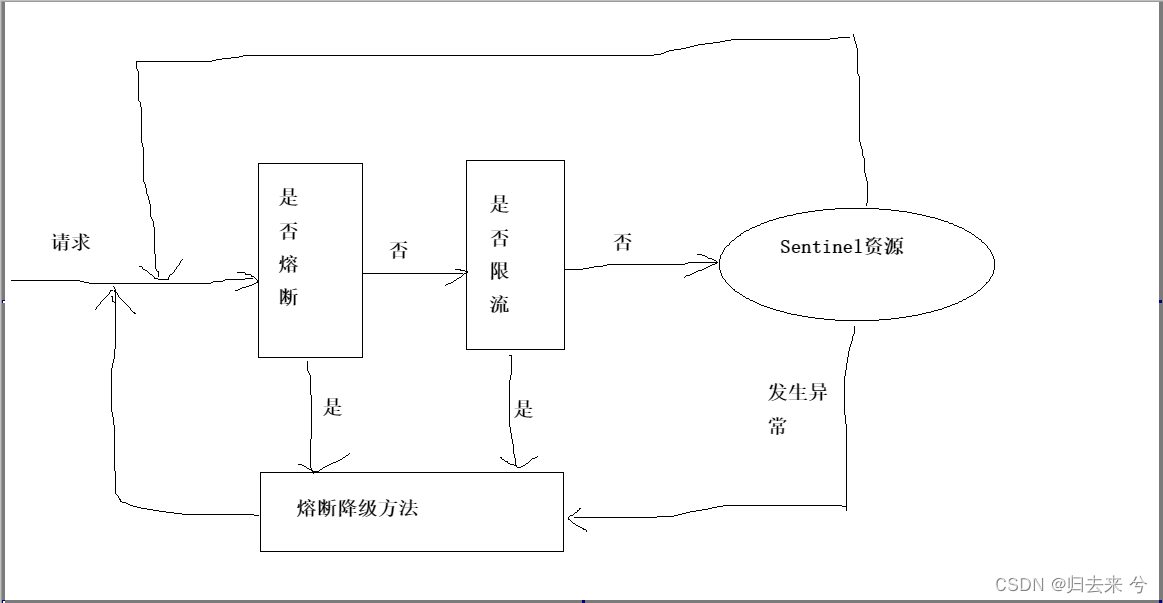
请求进来会先看资源是否熔断,熔断的话就会执行熔断方法,这里是fallback指定的方法,没有熔断才会判断是否应该流控,如果也没有流控才能进到资源中。
- 2.使用blockhandler声明降级方法
上面使用的是fallback来演示的熔断、流控,SentinelResource还提供了blockhandler来专门处理熔断流控等五种规则场景,所以我们最好的方式其实不是使用fallback处理流控和熔断而是使用blockhandler,而fallback则专门用于处理降级即可。blockhandler的使用和fallback没有任何区别。与上面使用fallback整体代码的差别是我们只需要增加blockhandler的配置即可其他完全和上面保持一致,下面是资源中新增配置的代码,只展示变动项:
@RequestMapping("/testFlowRule")@SentinelResource(value = "testFlowRule",fallback = "testFlowRule", // 降级配置fallbackClass = DegradeMethod.class,blockHandler = "testFlowRule", // 流控配置:配置熔断规则时若是增加了blockhandler,则熔断时进入的是该方法而不是fallbackblockHandlerClass = BlockMethod.class)
下面就是流控方法的实现了,注意这个方法必须传入BlockException,否则不会生效,这是强制要求,方法内部我们就可以根据真实的异常类型来判断是哪种场景触发的该方法了。
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeException;
import com.alibaba.csp.sentinel.slots.block.flow.FlowException;
import lombok.extern.slf4j.Slf4j;/*** @author pcc*/
@Slf4j
public class BlockMethod {/*** 流控方法这里必须声明BlockException的,不然是无法进入流控方法的* 流控也不会生效* @param blockException 流控异常* @return*/public static String testFlowRule(BlockException blockException){/*** 这里异常时没有异常信息的,只能通过异常的类型来判定是熔断还是流控等*/if(blockException instanceof DegradeException){// 处理熔断log.info("block-熔断-方法: {}","DegradeException");return "block-熔断-方法返回:success";}if(blockException instanceof FlowException){// 处理流控log.info("block-流控-方法: {}","FlowException");return "block-流控-方法返回:success";}return "block方法返回:success";}
}
其他代码都和上面使用fallback的例子一模一样,这里就不重复展示了,然后看下此时触发接口的结果:
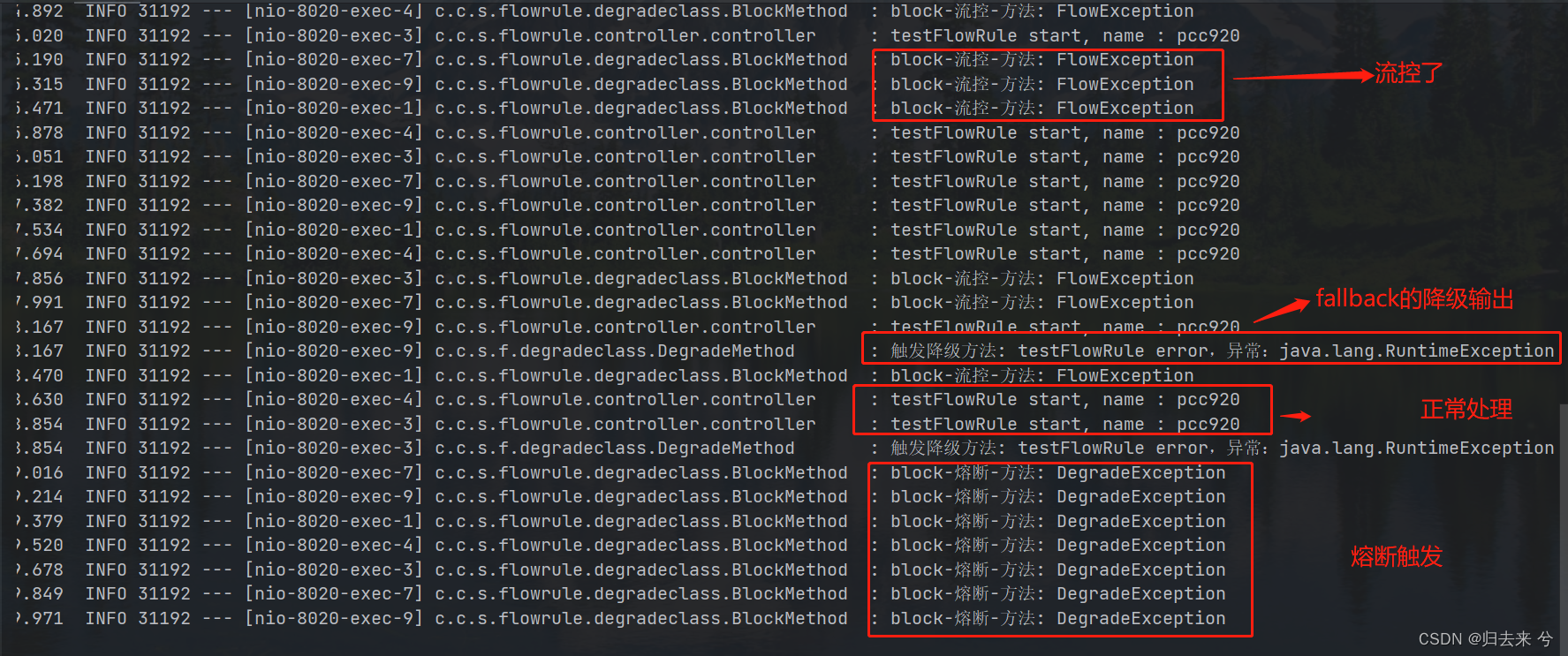
从上图可以看出服务降级还是走的fallback,而熔断、流控在增加了blockhandler以后就不会走fallback了,而是走的blockhandler指定的方法。
1.QPS流控-API
这里代码和改动是上面一个场景使用blockhandler的基础上进行增加如下配置,其实就是将页面上的配置规则放到了代码中,仅此而已,其他不变。
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Collections;/*** @author pcc*/
@Configuration
public class FlowConfig {@Beanpublic FlowRule getFlowRule() {FlowRule flowRule = new FlowRule();// 声明流控的资源flowRule.setResource("testFlowRule");// 声明使用的流控规则:0 并发线程数,1 QPSflowRule.setGrade(RuleConstant.FLOW_GRADE_QPS);// 流控规则设置-QPS阈值2flowRule.setCount(2);// 来源没有默认值,必须手动设定,default表示对所有来源生效flowRule.setLimitApp("default");// 将流控规则交给流控管理器FlowRuleManager.loadRules(Collections.singletonList(flowRule));return flowRule;}
}
增加以上配置后登录页面有可能会看不到配置的流控规则甚至之前的熔断规则都会看不到了,但是这些规则在客户端都是正常生效的,如果看到了应该展示如下:
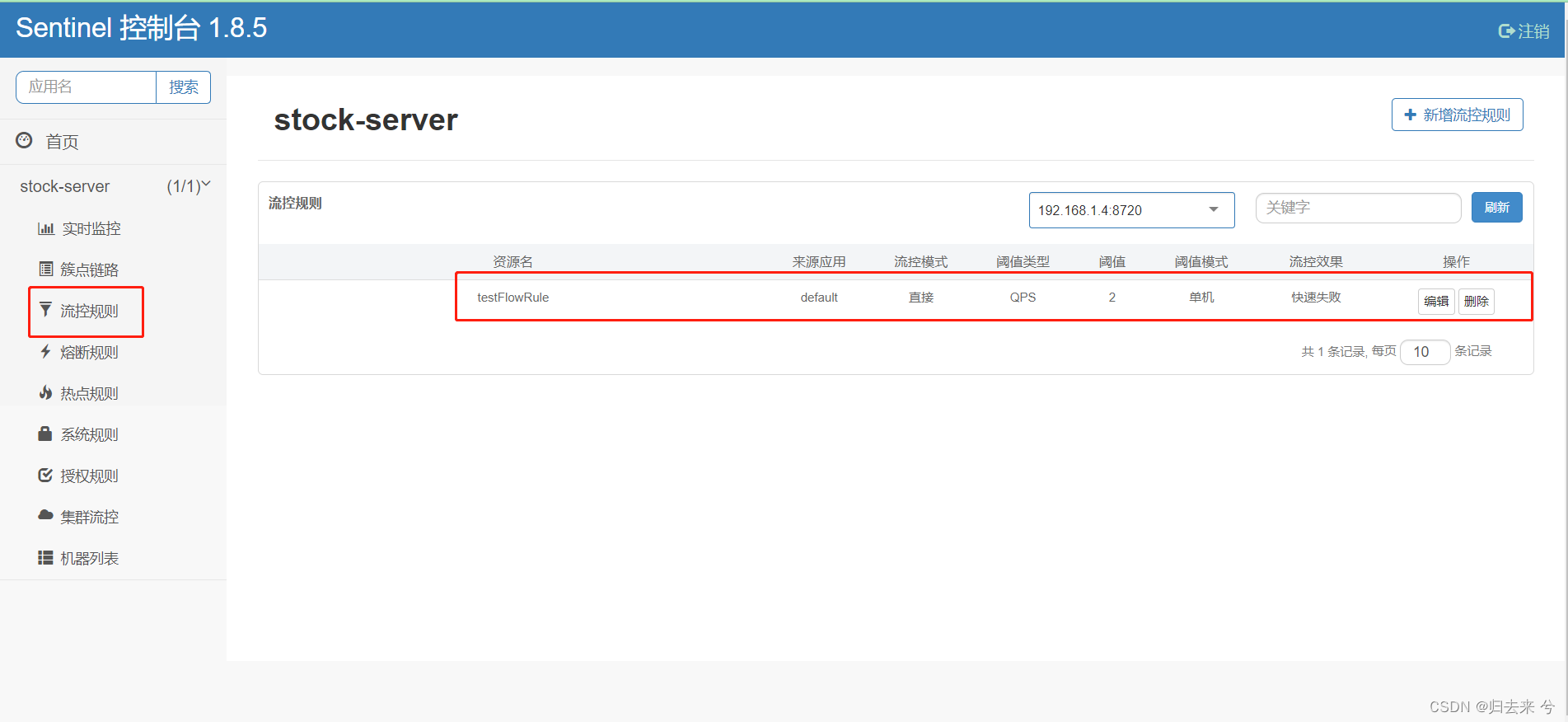
上面的dashboard的bug并不影响熔断规则和流控规则的生效,但是会导致偶尔在dashboard上无法看到我们的规则(怪不得不推荐dashbaord直接生产使用,bug不少啊)解决这个问题其实也简单,先把我们配置的FlowRule注释掉重启,然后再取消注释重启就可以绕过去了,具体啥原因导致的我也不知道
验证和上面都没有区别,这里就不重复说了。
2.并发线程数-页面/API
基于QPS的流控应该是很好理解的,统计单位时间内请求数即可。此外Sentinel还支持了并发线程数来进行流控。并发线程数最早有Hystrix提供过,Hystrix提供了两种并发线程数的是实现方式,一种是线程池隔离,一种是信号量隔离。线程池隔离是为资源预分配一个线程池,指定资源只可以使用指定线程池的线程,用完流控。信号量隔离是只统计线程进来的总数,总数到了我就流控。Sentinel的并发线程方案相当于是对两者(线程池隔离、信号量隔离)的一个整合。Sentinel与线程池隔离类似的是都是将请求线程与执行线程分隔开,与信号量类似的是Sentinel会统计总的现场量(这个量应该是执行线程的量)当线程数达到以后就会流控。
然后来看下并发线程数据的页面配置:
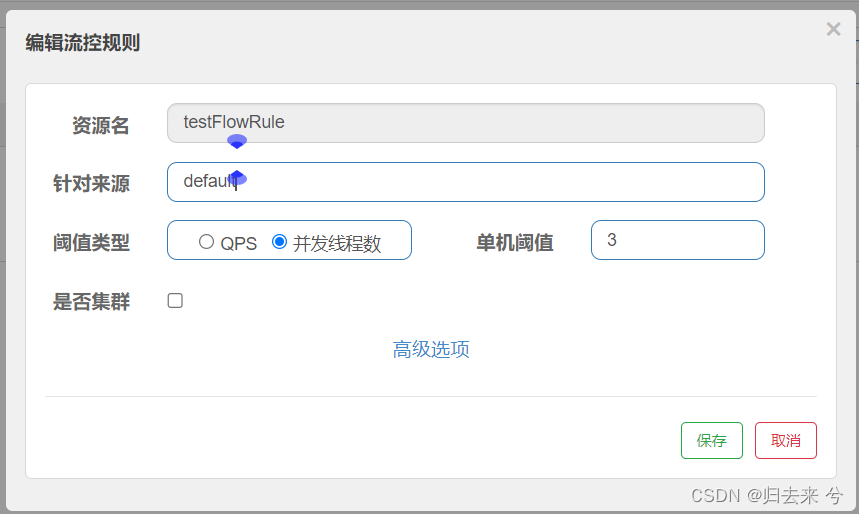
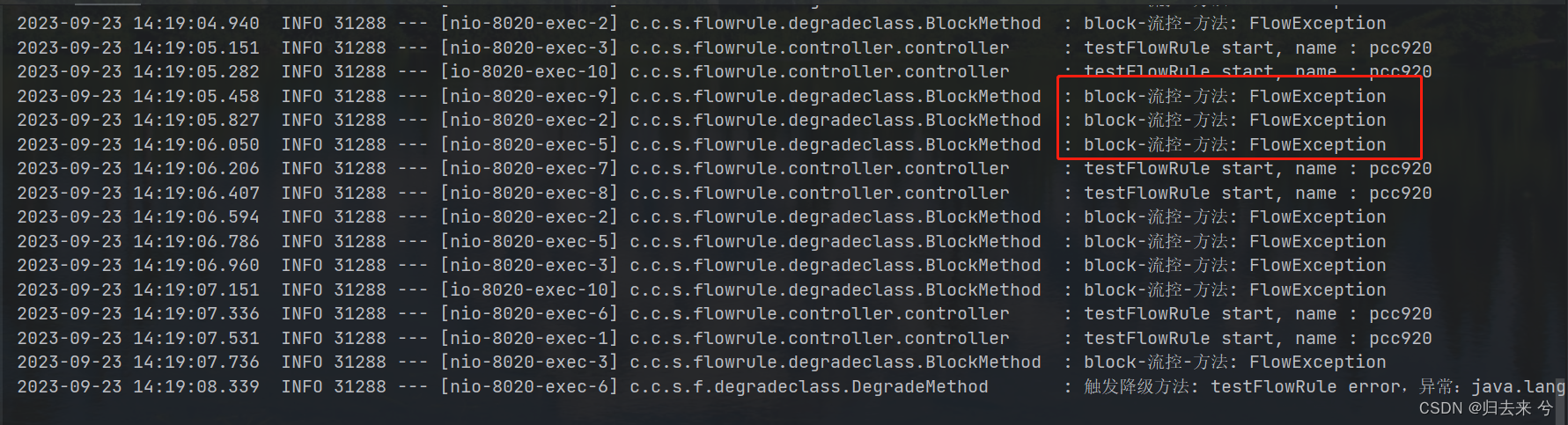
这里资源的代码需要略作调整才好去触发并发线程数的流控,需要手动让程序sleep一会,这样才能增加线程的并发数,不然请求进来就处理完了,是很难触发的(注意如果睡得时间超过了熔断的统计时间就会无法触发熔断)。
上面是页面的配置了,API也很简单,只需要把grade更改下即可,其他配置其实和QPS没有区别。其他代码和上面没有区别,这是将页面配置迁移到了API上,如下:
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Collections;/*** @author pcc*/
@Configuration
public class FlowConfig {@Beanpublic FlowRule getFlowRule() {FlowRule flowRule = new FlowRule();// 声明流控的资源flowRule.setResource("testFlowRule");// 声明使用的流控规则:0 并发线程数,1 QPSflowRule.setGrade(RuleConstant.FLOW_GRADE_THREAD);// 流控规则设置-线程并发阈值2flowRule.setCount(2);// 来源没有默认值,必须手动设定,default表示对所有来源生效flowRule.setLimitApp("default");// 将流控规则交给流控管理器FlowRuleManager.loadRules(Collections.singletonList(flowRule));return flowRule;}
}
注意:
QPS与并发线程数在一些场景下效果是类似的,但是大部分场景都是不同的。怎么说呢?
QPS是单位时间内进来的请求,只要单位时间内请求收到了最大阈值数量的请求,那其他的请求都进不来。
并发线程数强调的是当前请求占用的线程数,会存在这种场景1s内进来了3个请求,假设3个请求是QPS的阈值,那就会触发QPS的流控,3个请求进来了但是会有3个线程来执行这三个任务,但是有两种可能。①这三个请求服务端处理占用了10s,那么这10s内,如果还有这个请求进来就都会被流控,而QPS不会,他只看请求是否收到,不看处理了多少时间。②这三个请求服务端处理只用了0.5s,那么这1s内就最多可以进来6个请求。这就是QPS与并发线程数的区别。总结一句话就是QPS关注的是入口流量,并发线程数关注的资源内部的并发量
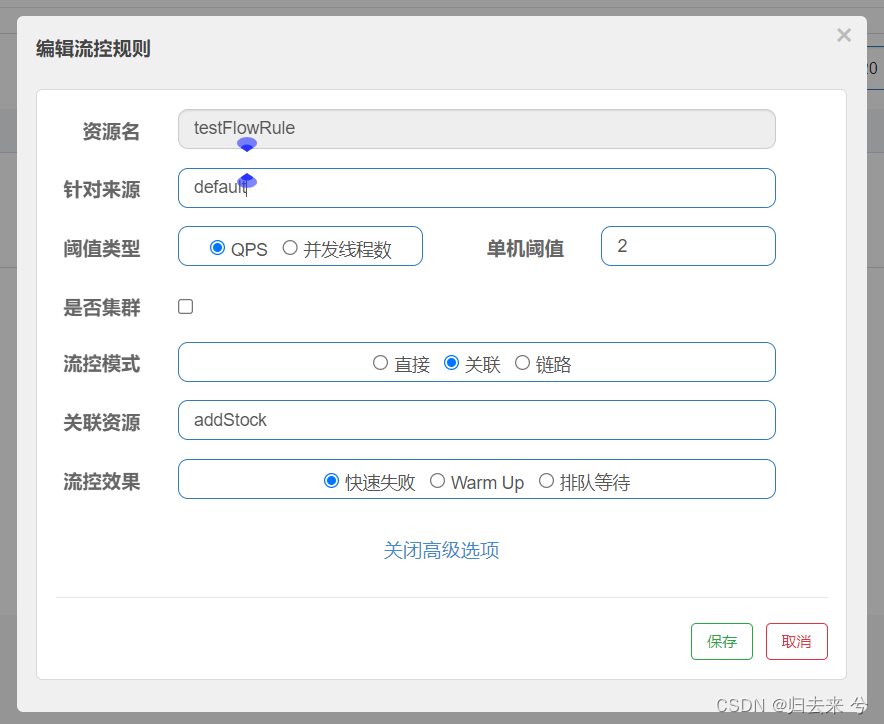
3.流控模式-关联(使用QPS)-页面/API
现实场景中肯定有这种场景,有些比较核心的接口是绝对不能停用的,而有些接口则是可以短时间不工作也没有问题的。
而针对于这种场景我们就可以使用关联流控模式,所谓关联流控模式就是如下图,需要在流控模式中选择关联,并输入关联资源,这样当我们访问资源addStock达到QPS阈值2时,就会对testFlowRule进行流控。
注意:别搞反了,是访问关联资源达到QPS阈值对第一行声明的资源进行流控。
这里验证的话我们可以借助Jemter(其他http客户端工具也可以)设置一个线程组然后每秒访问的次数需要达到2以上,做如下配置:
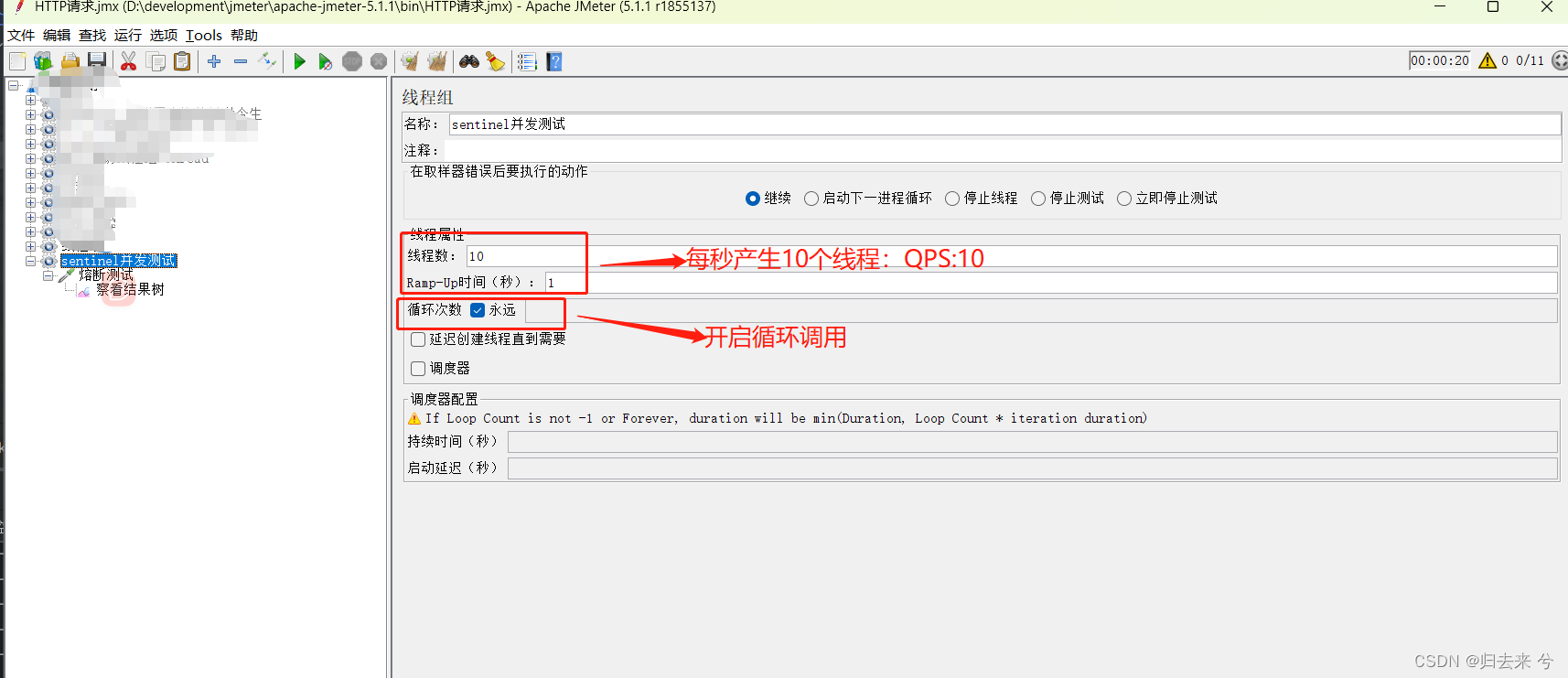
然后在访问addStock期间,我们访问testFlowRule应该是被流控的,如下图:
(这里的addStock接口就是普通接口没啥区别,代码就不贴了,需要注意的是必须注册为Sentinel的资源,声明资源名为addStock)

可以发现testFlowRule的访问请求完全被流控了,因为此时addStock的QPS是10,超过了我们设定的2所以所有的testFlowRule的访问都被流控。
思考:若是addStock触发熔断,testFlowRule是否会正常流控呢?
应该不会被流控,因为addStock熔断期间并不会消耗系统资源,此时流控没有意义,所以应该不会流控,而且判断是否应该流控上面其实还说了一个流程:先判断是否熔断,熔断自然不会流控。  由上面的输出方法我们可以看到testFlowRule是正常数据的并没有被流控,也是符合预想的。-----------------------------------------------------------------API配置----------------------------------------------------------------------------
上面已经介绍完了使用页面的所有操作,那使用API如何设置关联流控呢,如下改造即可,其他代码无任何差异就不贴了:
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Collections;/*** @author pcc*/
@Configuration
public class FlowConfig {@Beanpublic FlowRule getFlowRule() {FlowRule flowRule = new FlowRule();// 声明流控的资源flowRule.setResource("testFlowRule");// 声明使用的流控规则:0 并发线程数,1 QPSflowRule.setGrade(RuleConstant.FLOW_GRADE_THREAD);// 流控规则设置-线程并发阈值2flowRule.setCount(2);// 来源没有默认值,必须手动设定,default表示对所有来源生效flowRule.setLimitApp("default");// 流控模式-关联flowRule.setStrategy(RuleConstant.STRATEGY_RELATE);// 流控模式-关联-资源flowRule.setRefResource("addStock");// 将流控规则交给流控管理器FlowRuleManager.loadRules(Collections.singletonList(flowRule));return flowRule;}
}
测试啥的都没有区别,这里就不重复展示了。
4.流控模式-链路(使用并发线程数)-页面/API
流控资源通常是加在接口上,但是我们也可以加在普通方法上,假如有这种场景,A、B两个接口都同时调用同一个资源。如果A业务比较重要,B业务则没这么重要,我们可以在资源受限时将资源倾斜向A,把B进行流控。
这么一看链路流控是不是和关联流控差不多?使用链路流控能做的事使用关联流控也是可以的,只不过关联流控针对的是不同场景下的资源,而链路流控更多是针对同一资源的不同入口做限制。关联流控和链路流控还有一点不同的是:关联流控B资源达到阈值,流控A,而链路流控是B资源达到阈值,流控B的其中一个来源。
使用链路流控需要我们增加一个配置在application.yml中:spring.cloud.sentinel.web-context-unify=false,如下:
spring:application:# 阿里系的组件好像都会使用这个作为默认名称:nacos、sentinelname: stock-server # nacos配置中心和注册中心默认都是用这个作为默认名称cloud:sentinel:transport:port: 8719 # dashboard控制面版与sentinel通信的本地端口dashboard: 127.0.0.1:8088 # sentinel控制面板地址eager: true # 是否饥饿加载,默认为false,开启后启动项目就会初始化,而不是在第一次调用,dashboard也可以直接就可以看到服务,不用等待接口调用后才可以看到web-context-unify: false # 默认true,收敛资源访问的所有入口,若是想要使用链路流控,必须关闭有如下方法testChain,他同时被接口接口/testFlowRule1、/testFlowRule2引用,我们设置当testChainQPS或者并发线程达到阈值时,对/testFlowRule1进行流控,代码如下:
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.cheng.stockserver.flowrule.degradeclass.BlockMethod;
import lombok.extern.slf4j.Slf4j;/*** @author pcc*/
@Slf4j
@org.springframework.stereotype.Service
public class serviceImpl implements ChainService {@Override@SentinelResource(value = "testChain",blockHandler ="testChainFlow",blockHandlerClass = BlockMethod.class)public void testChain() {log.info("testChain start");// 使用并发线程数模拟流控-加大方法响应时间,提高线程并发数try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}
}
此外需要注意流控方法需要使用静态方法、且返回值保持一致且必须声明BlockException,这些都是使用blockhandler必须遵守的规定。下面是流控方法:
/*** 链路流控使用的流控方法*/public static void testChainFlow(BlockException blockException) {if(blockException instanceof DegradeException){// 处理熔断log.info("链路流控-熔断-方法: {}","DegradeException");}if(blockException instanceof FlowException){// 处理流控log.info("链路流控-流控-方法: {}","FlowException");}}
页面增加配置:
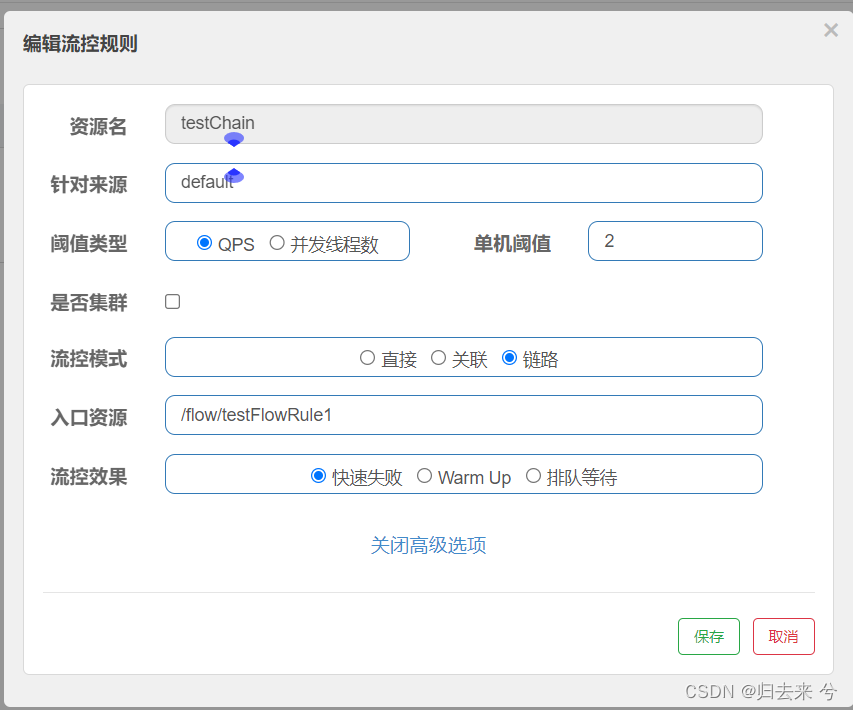
下面是测试截图,可以看到只有testFlowRule1接口调用testChain会被流控,而testFlowRule2调用是不会被流控的。
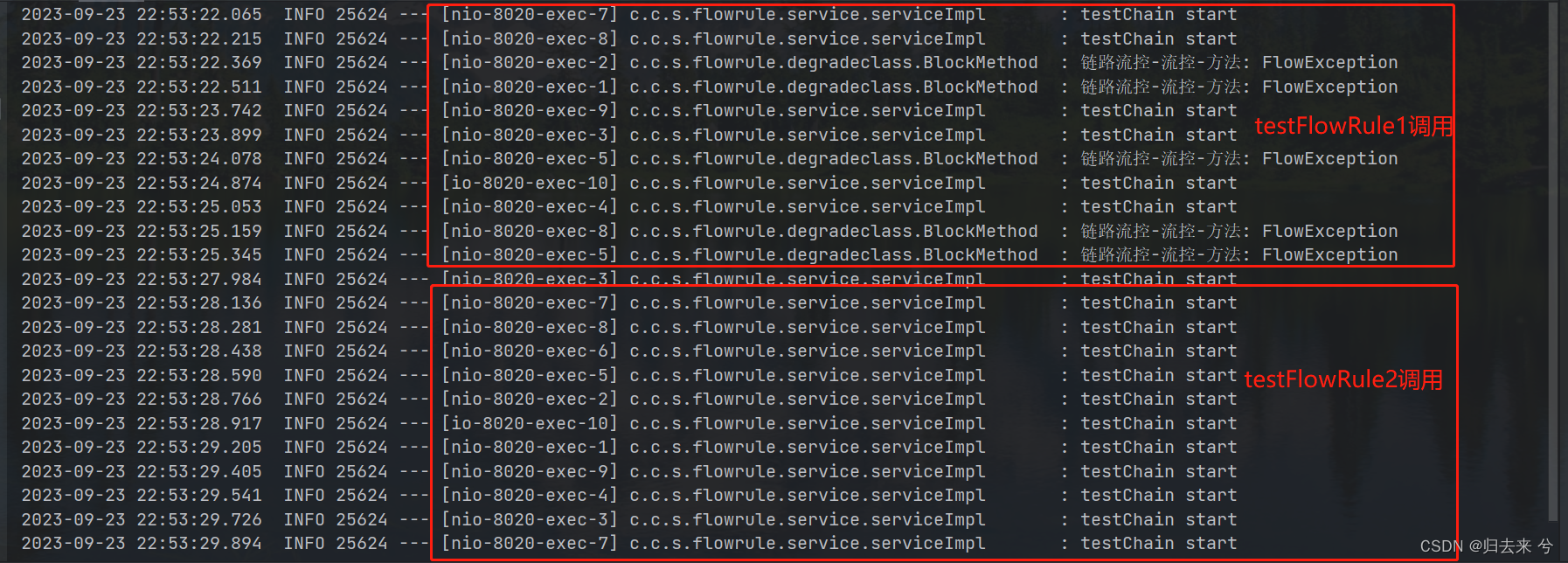
************************************************************ 下面是APIj介绍 ************************************************************
使用API相当于使用页面,唯一改变的就是把规则配置使用代码进行,其他的则全部相同,这里只展示代码,验证都无区别,使用API时操作的属性和关联模式都是一样的,只需要我们变更下属性值即可,如下:
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Collections;/*** @author pcc*/
@Configuration
public class FlowConfig {@Beanpublic FlowRule getFlowRule() {FlowRule flowRule = new FlowRule();// 声明流控的资源flowRule.setResource("testChain");// 声明使用的流控规则:0 并发线程数,1 QPSflowRule.setGrade(RuleConstant.FLOW_GRADE_THREAD);// 流控规则设置-线程并发阈值2flowRule.setCount(3);// 来源没有默认值,必须手动设定,default表示对所有来源生效flowRule.setLimitApp("default");// 流控模式-链路flowRule.setStrategy(RuleConstant.STRATEGY_CHAIN);// 流控模式-链路-路径flowRule.setRefResource("/flow/testFlowRule1");// 将流控规则交给流控管理器FlowRuleManager.loadRules(Collections.singletonList(flowRule));return flowRule;}
}
5.流控效果-预热-页面/API
流控效果默认是快速失败(只有QPS支持流控效果),快速失败就会调用我们指定的blockhandler方法,而服务器其实在QPS瞬间增大时可能会导致服务直接冲垮,即使压测时允许10w并发,但是真实业务如果是QPS从一个很低的水准一下来到10w,同样可能冲垮服务,此时我们就可以考虑使用预热的流控效果。预热流控会在预热时间内,将QPS缓步进行提升,给系统一个反应的时间,这样就可以保证系统不会在瞬时的高峰下被冲垮。
假如有这样的场景:正常情况下10的QPS,突然QPS达到了1000,我们使用了预热模式,预热时间是10s,那么Sentinel就会在10s内缓步提升我们的流控QPS值,第一秒可能只接收100的QPS其他的则进行失败处理,第二秒接收200的QPS其他的也做失败处理,第十秒则可以处理1000的QPS,此时就完成了预热。
预热模式会有个小缺点就是:预热时间内QPS的阈值其实不是我们设定的最大值,而是随着时间逐步增大到我们设置的最大值,页面配置如下:
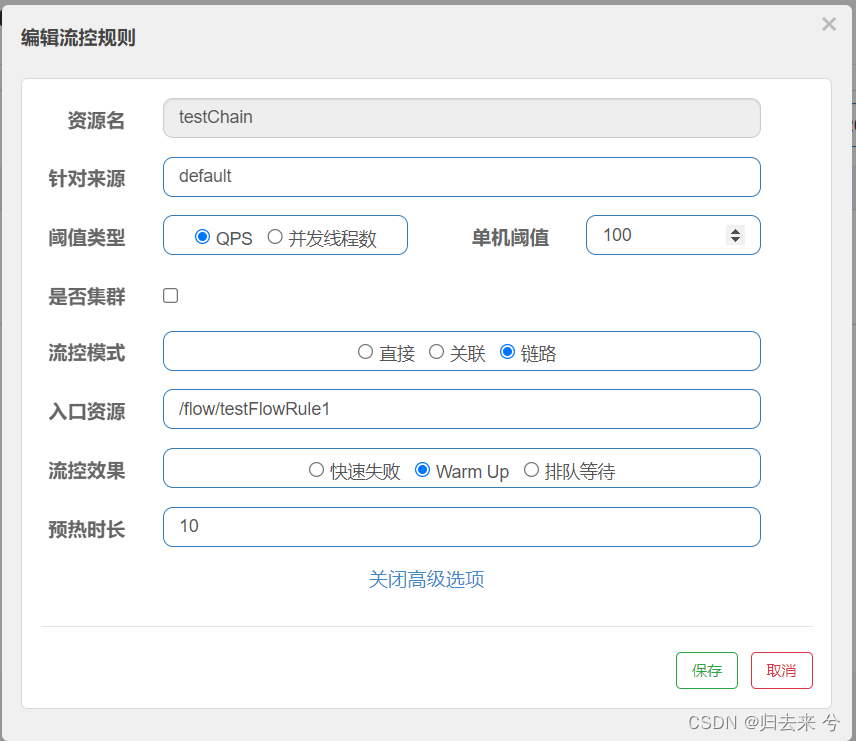
测试的话,这里需要使用Jemeter,因为100的QPS靠人是点不上去的,必须借助工具了。如上图,我们对testChain进行预热流控,预期效果:开始时会有部分请求提示被流控,10s后将所有请求都不会流控(jemeter设定并发100):
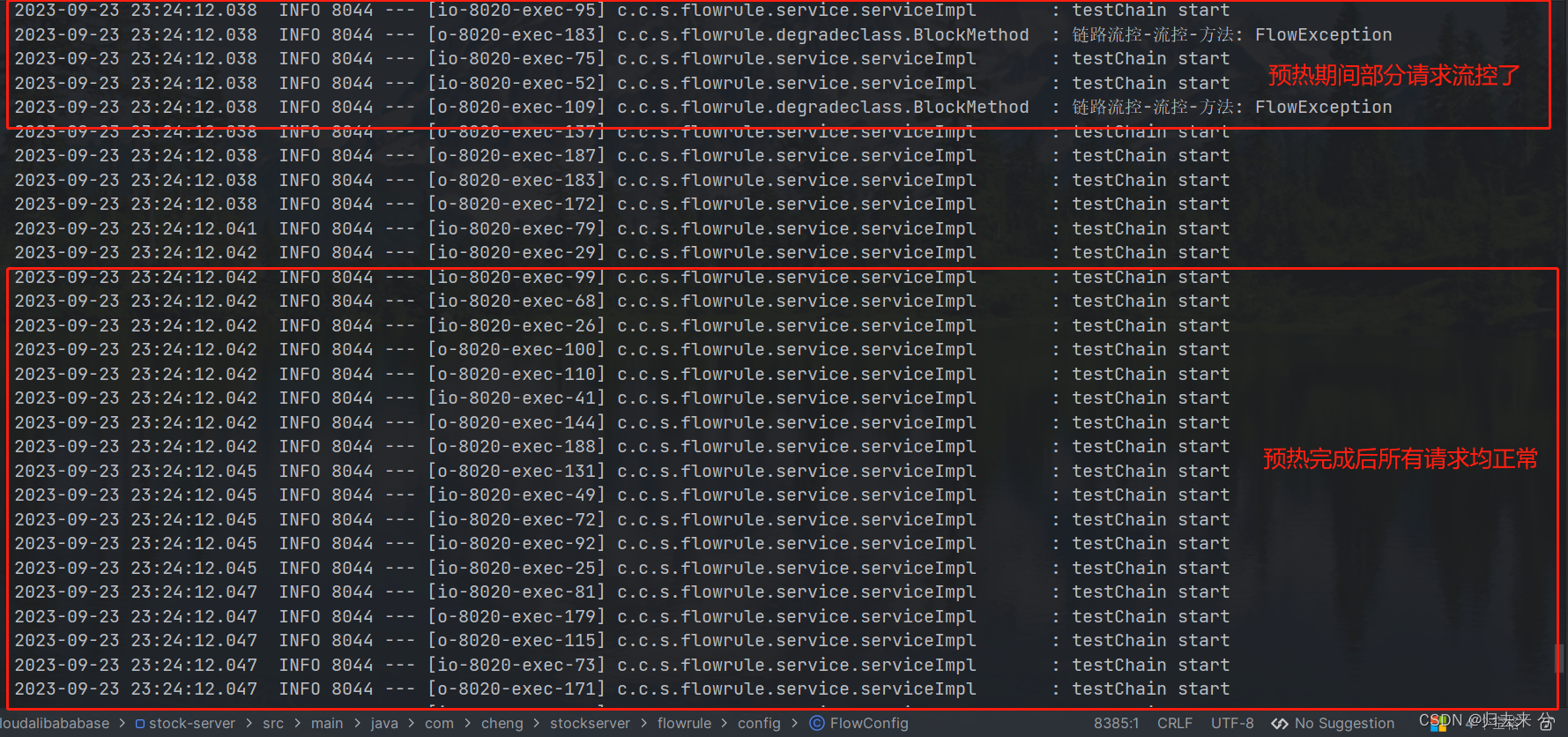
这里没有截动图实际效果和我们预想的其实非常接近,只是Sentinel的预热时间是10s,他在10s内QPS的阈值上升,并不是线性的,时间上可能也要不了10s就会完成预热,但他可以保证10s后系统的QPS一定是100.基本我们需要的他都满足了。
************************************************************ 下面是API介绍 ************************************************************
API相对于页面来说只是增加两行配置,很简单,其他没有任何不同:
注意:并发线程数不支持流控效果
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Collections;/*** @author pcc*/
@Configuration
public class FlowConfig {@Beanpublic FlowRule getFlowRule() {FlowRule flowRule = new FlowRule();// 声明流控的资源flowRule.setResource("testChain");// 声明使用的流控规则:0 并发线程数,1 QPSflowRule.setGrade(RuleConstant.FLOW_GRADE_QPS);// 流控规则设置-线程并发阈值2flowRule.setCount(100);// 来源没有默认值,必须手动设定,default表示对所有来源生效flowRule.setLimitApp("default");// 流控模式-链路flowRule.setStrategy(RuleConstant.STRATEGY_CHAIN);// 流控模式-链路-路径flowRule.setRefResource("/flow/testFlowRule1");// 流控效果-预热flowRule.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_WARM_UP);// 流控效果-预热-预热时间: 10sflowRule.setWarmUpPeriodSec(10);// 将流控规则交给流控管理器FlowRuleManager.loadRules(Collections.singletonList(flowRule));return flowRule;}
}
6.流控效果-排队等待-页面/API
这里是流控效果-排队等待,有可能会有这种场景。系统只能抗住1000的QPS但是最高时有1500的QPS,余下500在瞬间是处理不了的,但是高峰并不会持续太久,或者说高峰是和低估是交替出现的,那么这时候我们最好的解决方案就是使用排队等待的流控效果了。排队等待的效果类似于削峰填谷:把瞬时高的流量通过削峰把处理不了的请求放入到请求不多时在处理。当然也存在请求不多时可能也处理不完请求,那此时就会执行流控方法blockhandler了。
页面配置如下:
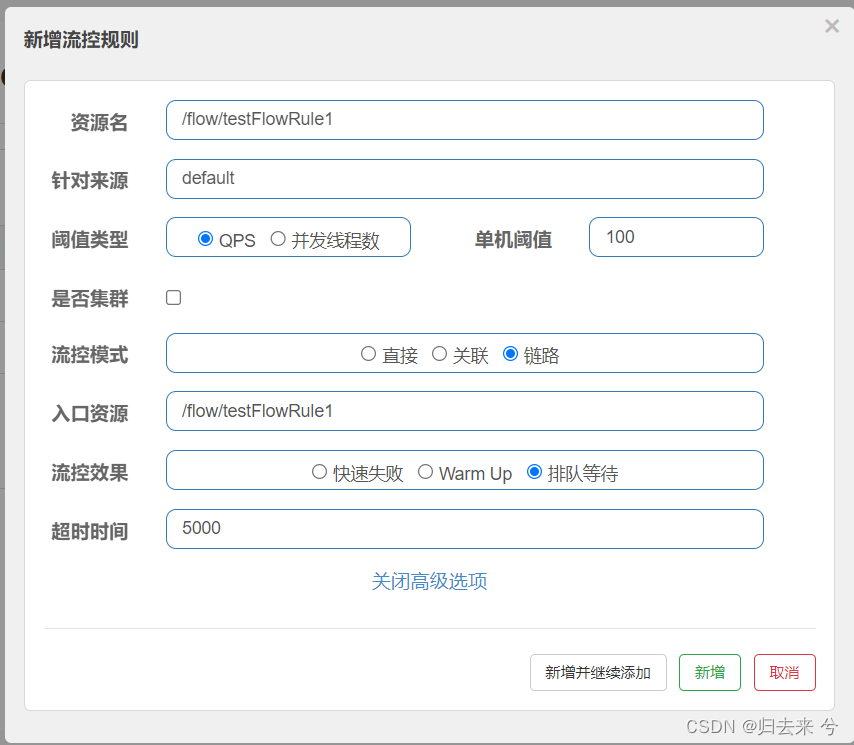
如上配置则表示,QPS大于100的请求会进入等待队列,然后等待系统去执行,等待超时时间最大5000ms,若是5s后还未处理,则执行流控方法。使用页面配置代码无需改动任何地方,验证同样需要借助jemeter,我们可以设置并发是150,执行1次,若是系统没有执行流控方法则说明我们超过100的请求被正常处理了,我们的排队等待也就生效了。
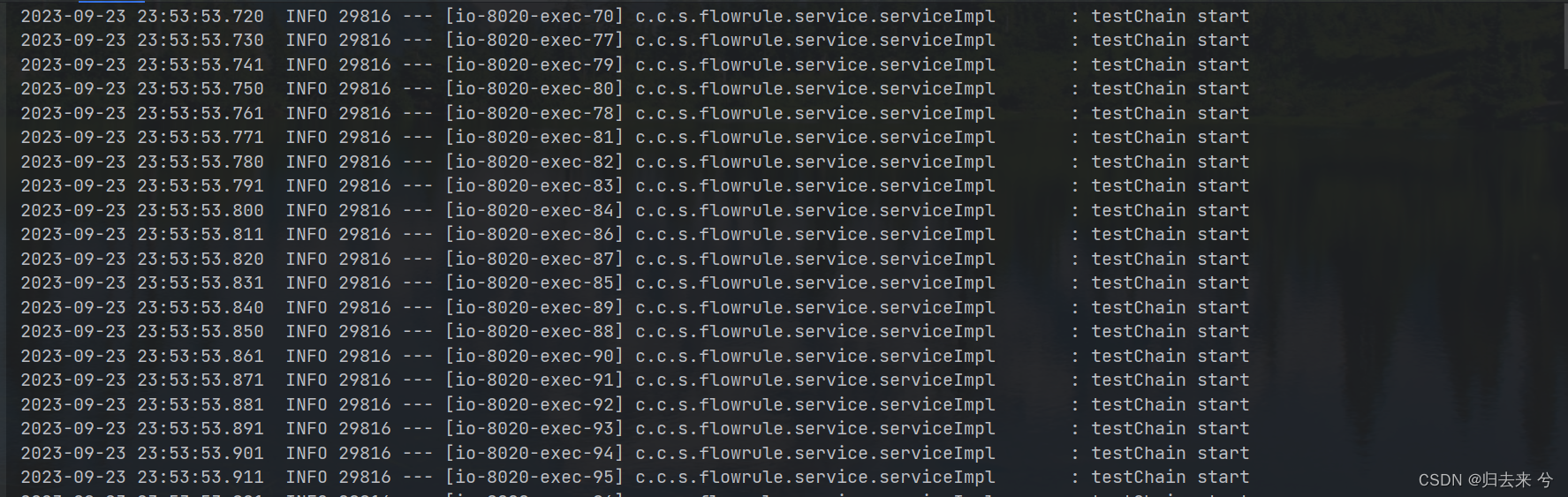
这里只截部分图,其实全部信息都是正常的,证明我们配置的排队等待是完全ok的。
************************************************************ 下面是API介绍 ************************************************************
和页面配置相比,唯一的变动是将流控效果-排队等待放入到代码里,其他无变化:
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Collections;/**
* @author pcc
*/
@Configuration
public class FlowConfig {@Beanpublic FlowRule getFlowRule() {FlowRule flowRule = new FlowRule();// 声明流控的资源flowRule.setResource("testChain");// 声明使用的流控规则:0 并发线程数,1 QPSflowRule.setGrade(RuleConstant.FLOW_GRADE_QPS);// 流控规则设置-线程并发阈值2flowRule.setCount(160);// 来源没有默认值,必须手动设定,default表示对所有来源生效flowRule.setLimitApp("default");// 流控模式-链路flowRule.setStrategy(RuleConstant.STRATEGY_CHAIN);// 流控模式-链路-路径flowRule.setRefResource("/flow/testFlowRule1");// 流控效果-排队等待flowRule.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER);// 流控效果-排队等待-超时时间: 5sflowRule.setMaxQueueingTimeMs(5000);// 将流控规则交给流控管理器FlowRuleManager.loadRules(Collections.singletonList(flowRule));return flowRule;}
}
7.针对来源进行流控
针对来源的流控和流控模式中的链路模式是有些相似的,不过他们作用的位置不一样。针对来源的会更靠前一些。这个来源我们可以在请求头中和服务调用方进行约定。然后我们就可以针对特定来源进行流控了。而之前说的流控模式中的链路则是服务内部针对不同接口调用同一个资源时进行的流控,当然我们也可以使用链路模式来达到对来源控制一样的效果,只需要为不同来源提供不用入口,这样就可以针对不同的入库进行链路流控了。但这无疑会增加一些代码量,所以若是想要对来源进行控制还是使用来源进行限定最好不过。
想要使用来源进行流控,我们需要借助Sentinel同的RequestOriginParser他提供了一个方法parseOrigin,供我们解析来源。来源具体怎么解析就随意我们自己指定了,我们可以根据Origin、也可以根据Referer等都是可以的,也可以自定义请求头等。
这里我们使用自定义请求头来指定来源,假设请求头中含有参数source:
import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.RequestOriginParser;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
import java.util.Optional;/*** @author pcc*/
@Component
public class SentinelOriginRequestOriginParser implements RequestOriginParser {@Overridepublic String parseOrigin(HttpServletRequest request) {String source = request.getHeader("source");/*** 当存在来源时我们直接设置来源为传入的值* 否则返回null*/if (Optional.ofNullable(source).isPresent()) {return source;}return null;}
}
如上代码我们获取请求头中的source作为来源,然后需要借助jemter来设置请求头参数source,我这里用了jemeter两个http请求,一个请求头source设置one,一个source设置two,下面是页面配置:
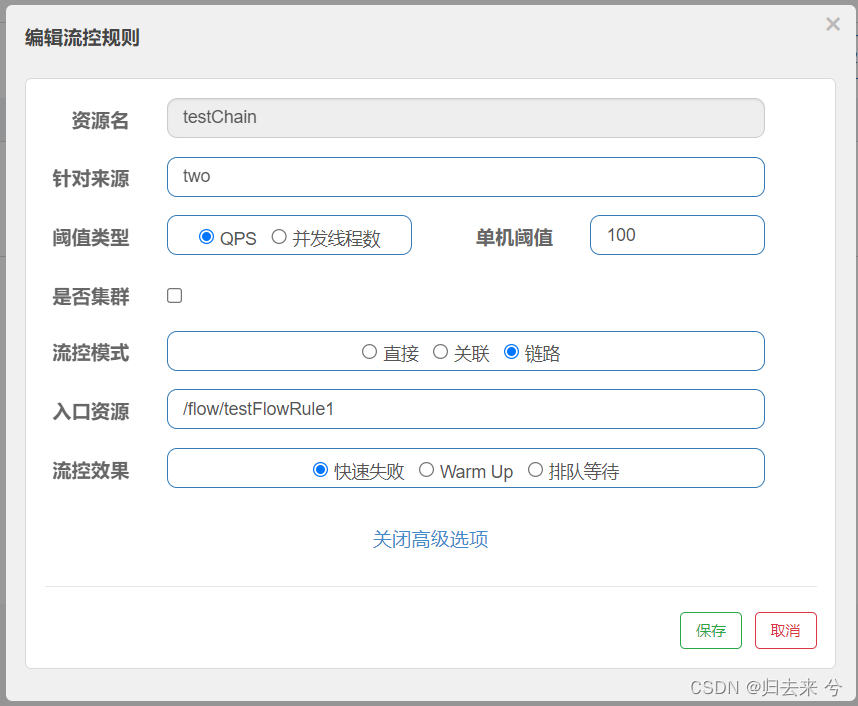
如上配置,当QPS大于100,会对testFlowRule1进行流控,而此时也只流控来源为two的请求,也就是说来源不是two即使QPS大于100也不会流控。
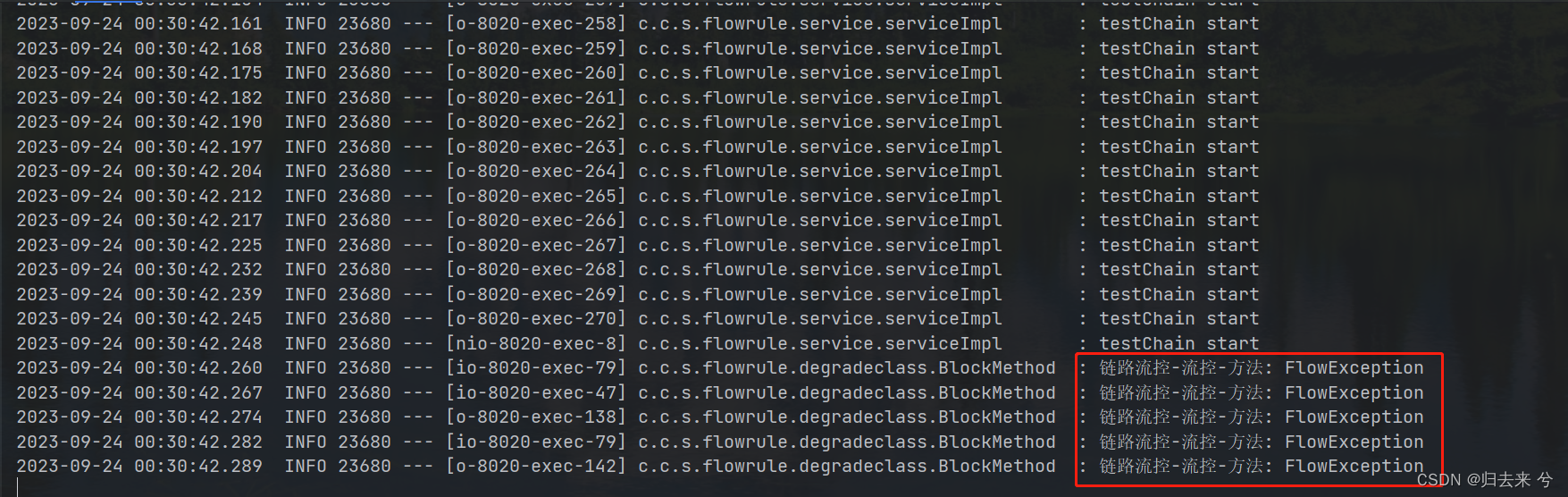
如上是设置请求头里soruce=two时的请求,并发请求数设置的是160.如预期发生了流控,当测试source=one,并发也是160时则不会流控。
************************************************************ 下面是API介绍 ************************************************************
API则只需要改动稍微的代码即可,其他相对于页面配置都无需改动:
import com.alibaba.csp.sentinel.slots.block.RuleConstant;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.Collections;/**
* @author pcc
*/
@Configuration
public class FlowConfig {@Beanpublic FlowRule getFlowRule() {FlowRule flowRule = new FlowRule();// 声明流控的资源flowRule.setResource("testChain");// 声明使用的流控规则:0 并发线程数,1 QPSflowRule.setGrade(RuleConstant.FLOW_GRADE_QPS);// 流控规则设置-线程并发阈值2flowRule.setCount(100);// 来源没有默认值,必须手动设定,default表示对所有来源生效flowRule.setLimitApp("one");// 流控模式-链路flowRule.setStrategy(RuleConstant.STRATEGY_CHAIN);// 流控模式-链路-路径flowRule.setRefResource("/flow/testFlowRule1");// 将流控规则交给流控管理器FlowRuleManager.loadRules(Collections.singletonList(flowRule));return flowRule;}
}
8.集群配置
不使用集群模式,如果我们是集群服务,那么我们设置的规则就是针对单个节点的。
使用功集群模式,如果我们是集群服务,那么我们设置的规则就可以针对整个集群,单节点的流控就可以作为兜底方案,这其实才是微服务该用的模式(如果集群的负载是轮询则使用集群模式和单机模式差别就不是特别大,如果不是轮询则差距就会很大了)。
这个模式需要单独拎出来说,因为东西太多放在这里会很臃肿,这里暂时不做介绍。
集群模式官方介绍:Sentinel流控集群模式
六、限流-授权规则:AuthorityRule
授权规则其实就是针对资源配置黑名单和白名单,如果针对一个资源配置了白名单,那么未配置的来源就是黑名单。相反也是一样,如果针对一个资源配置了黑名单,那么未配置的来源就是白名单。
1.授权规则-页面/API
使用授权规则有个前提就是需要获取数据来源:这个和流控里面说的来源是一个东西,借助RequestOriginParser即可,这里的RequestOriginParser和流控里的没有任何区别,就不重复贴代码了,然后我们需要配置的页面也很简单
注意:笔者验证授权时,对与接口的授权都是成功的,但是对于普通方法的授权是不适用的,其实想想也对接口都进来了,不让访问方法就很奇怪,所以正常我们也应该是在接口层面就进行拦截
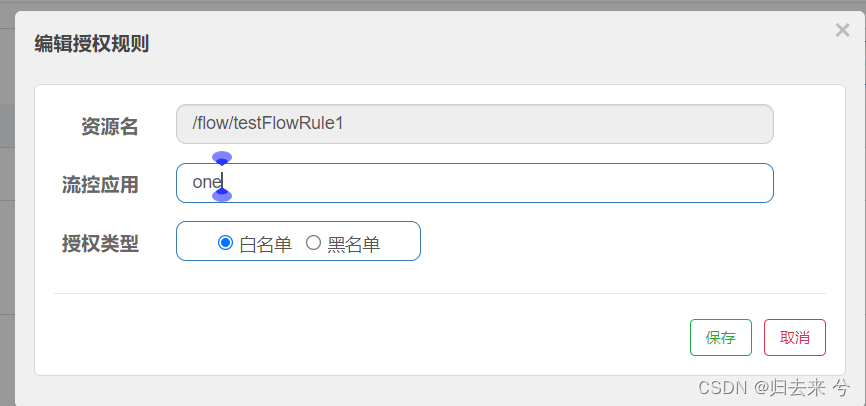
如果配置了这个就代表,访问当前接口时只有source为one的请求才可以进来,其他的都会被拒绝,如下:
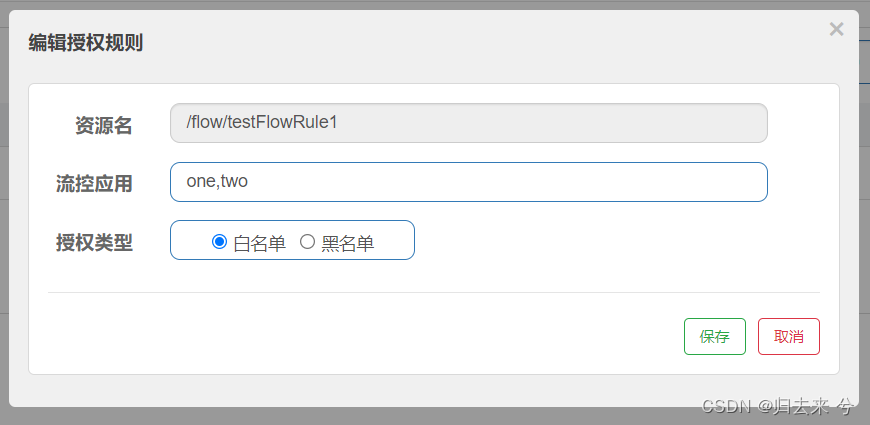
那如果白名单不止一个怎么办?我们可以在配置时使用逗号隔开多个白名单(或者黑名单)资源即可,如下:
************************************************************ 下面是API介绍 ************************************************************
API相当于页面配置来说,只是将配置移动到了代码中,其他无增加任何变化,新增代码如下:
@Beanpublic AuthorityRule getAuthorityRule(){AuthorityRule rule = new AuthorityRule();// 授权规则管理的资源rule.setResource("/flow/testFlowRule1");// 授权策略:白名单0,黑名单1rule.setStrategy(RuleConstant.AUTHORITY_WHITE);//rule.setLimitApp("one,two");// 将授权规则交给授权管理器AuthorityRuleManager.loadRules(Collections.singletonList(rule));return rule;}
七、限流-热点规则:ParamFlowRule
热点规则其实应该算在流控规则里面,因为热点规则是在资源流控的基础上对于资源的请求参数进行流控的,其实是将流控更细粒度了。所以他其实应该算在流控规则内。而且热点规则只支持QPS模式的热点,不支持并发线程数,有意思的是他还支持排除项。
热点规则的应用场景主要是某些数据被访问频次太高或者对服务器压力比较大,就需要控制这个数据的访问频率,比如有一个比较大的查询操作,传入了type=10,可能type=10数据特别的多,我们不希望他们一直这么查,就可以单独针对type做流控,当type=10时进行流控,等于其他值时则不需要流控,或者允许通过的QPS更大些
1.热点规则-页面
这是热点规则的配置页面,假设有一个接口有参数type和name:
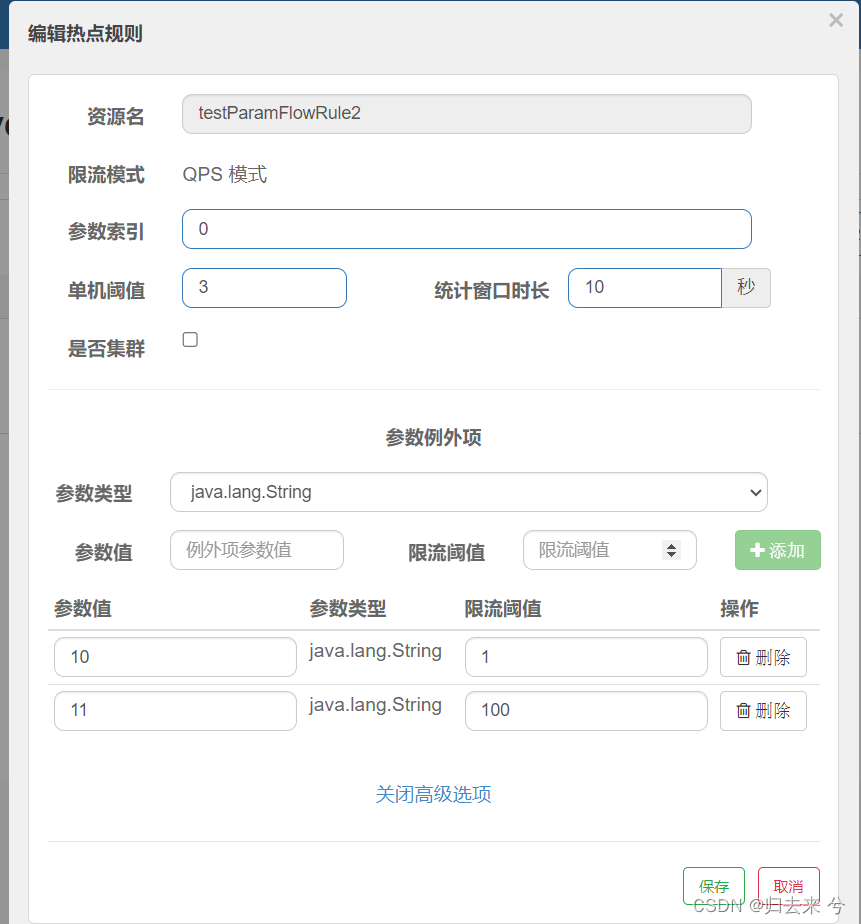
解释下上面的参数:
- 参数索引:接口的参数列表的下标,type这里是第一个下标是0
- 单机阈值:QPS的阈值
- 统计窗口时间:这里的QPS默认是每秒的请求数,但是我们也可以更改统计的单位时间,这里改为10s,意思是10s内有3次请求参数携带了type就会触发流控
- 是否集群:这里的集群模式与流控的集群模式一样,没有任何区别,这里不细说了
- 参数例外项:这里相当于配置例外规则,也就是说上面的流控规则需要在例外规则的基础上运行
- 参数类型:必须保持和参数索引 这里是type的类型保持一致,这里type的类型是String
- 限流阈值:参数值具体的阈值,我们可以通过这个配置具体值的阈值,比如type为10的时候我想要并发控制到1,那就可以为他设置阈值为1。而别的值则不受这个限制。
参数就这些比较好理解,我们需要增加一个接口将它注册到sentinel中:
@RequestMapping("/testParamFlowRule2")
@SentinelResource(value = "testParamFlowRule2",blockHandler = "testParamFlowRule2",blockHandlerClass = BlockMethod.class
)
public String testParamFlowRule2(@RequestParam("type") String type,@RequestParam("name") String name) throws Exception{log.info("{},{}",type,name);service.testChain();return "testFlowRule1 : success";
}
然后还需要提供该资源的blockhandler方法如下:
注意:必须static、必须有BlockException
/*** 热点流控* @param type* @param name* @return* @throws Exception*/
public static String testParamFlowRule2(String type,String name,BlockException blockException) throws Exception{log.info("热点流控方法:{},{}",type,name);return "热点流控了 : success";
}
然后按照上面的配置,应该展现的效果是如果type是11,则每10s醉倒访问100次(这个手速很难点到),如果type是10则每10s最多访问一次,如果是其他则每10s可访问醉倒3次。

可以看到刚开始传type=11,手动点不会流控,当传10时,第四次就流控了。
2.热点规则-API
API配置和页面的区别就是将配置项前移到了代码中,其他没有任何区别,这里只展示代码的书写,验证和上面没有任何区别:
注意:API配置大部分支持的功能都会比页面稍微多一些,有兴趣可以研究下,但基本都是相同的。
@Beanpublic ParamFlowRule getParamFlowRule(){ParamFlowRule paramFlowRule = new ParamFlowRule();// 热点流控-资源paramFlowRule.setResource("testParamFlowRule2");// 限流模式-必须QPS,默认就是QPSparamFlowRule.setGrade(RuleConstant.FLOW_GRADE_QPS);// 参数索引: 方法参数列表下标paramFlowRule.setParamIdx(0);// 单机阈值paramFlowRule.setCount(3);// 单机阈值的统计时间:默认1s,支持更改单位秒paramFlowRule.setDurationInSec(10);// 参数例外项ParamFlowItem paramFlowItem = new ParamFlowItem();// 参数例外项-参数类型:必须与setParamIdx对应的参数保持一致paramFlowItem.setClassType("java.lang.String");// 参数例外项-参数值paramFlowItem.setObject("10");// 参数例外项-限流阈值paramFlowItem.setCount(1);ParamFlowItem paramFlowItem2 = new ParamFlowItem();// 参数例外项-参数类型:必须与setParamIdx对应的参数保持一致paramFlowItem2.setClassType("java.lang.String");// 参数例外项-参数值paramFlowItem2.setObject("11");// 参数例外项-限流阈值paramFlowItem2.setCount(101);List<ParamFlowItem> list = new ArrayList<>();list.add(paramFlowItem);list.add(paramFlowItem2);paramFlowRule.setParamFlowItemList(list);// 加载热点流控规则ParamFlowRuleManager.loadRules(Collections.singletonList(paramFlowRule));return paramFlowRule;}
八、限流-系统规则:SystemRule
前面介绍的各种规则都是对于单个资源或者单个接口的,那系统整体的限流他们是无法保证的,而系统规则j就是为了从整体上对系统进行一个更高层级的保护来进行的,此时单个资源的流控就可以作为兜底方案,系统规则可以作为整体的方案(有些和集群模式类似,但并不相同)。
1.系统规则-页面/API
下面是系统规则的配置页面:
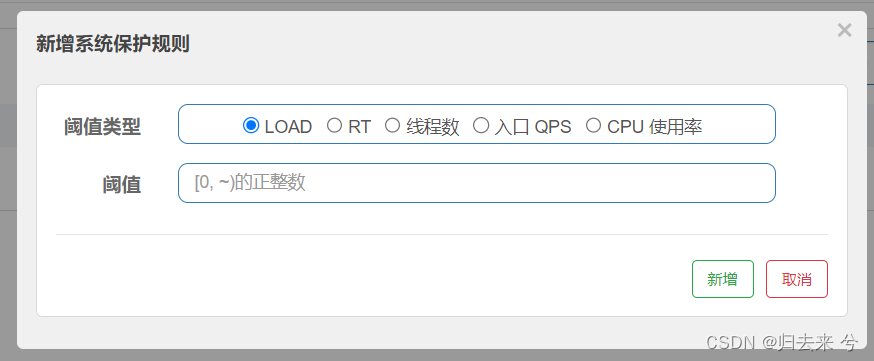
先来看下各个参数的释义:
系统规则官方文档:系统自适应限流
-
LOAD:系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的阈值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护。
注意:
1.系统当前的并发线程数:maxQps * minRt 可以由这个粗略计算得出
2.系统容量:一般设置为CPU cores*2.5
3.只有linux系统才有load1参数,使用uptime可以查看系统负载
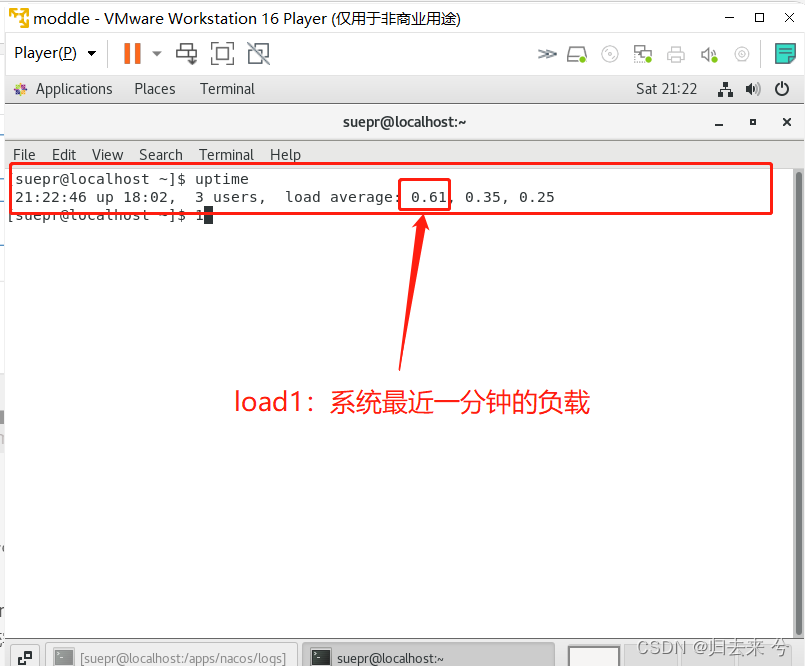
-
RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
-
线程数:单台机器上所有入口流量的并发线程数达到阈值即触发系统保护
-
入口QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护
-
CPU使用率:当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏
以上就是系统规则支持的所有参数了,它支持同时设置不同策略的系统规则,比如及设置load也设置RT等。系统规则是从系统服务器层面对服务器进行保护,上面说的流控、热点、授权、熔断等都是基于资源或者接口的,这是他们最主要的区别。
下面是设置的RT规则:
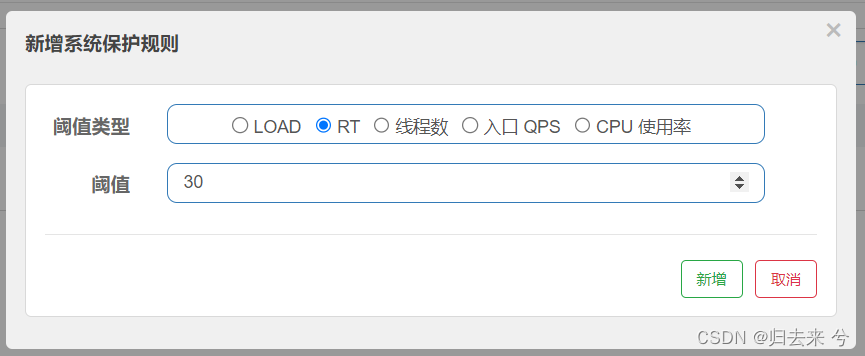
预想结果:当接口的平均RT超过30ms就会触发流控了。
下面是新增的一个接口:
@RequestMapping("/testSystemRule")@SentinelResource(value = "testSystemRule",blockHandler = "testSystemRule",blockHandlerClass = BlockMethod.class)public String testSystemRule(@RequestParam("type") String type,@RequestParam("name") String name) throws Exception{log.info("{},{}",type,name);// 等待40ms,模仿RT超过30msThread.sleep(400);return "testSystemRule : success";}
下面是他的流控blockhandler方法:
/*** 系统规则*/public static String testSystemRule(String type, String name,BlockException blockException) throws Exception{log.info("{},{}",type,name);return "系统规则-流控 : success";}
注意:
1.经验证系统规则不会完全按照设定的值进行触发,部分参数灵敏度不高,这里使用RT验证灵敏度不高
2.系统限流,不会调用访问的接口或者资源对应的限流方法,而是走的统一限流方法:实现BlockExceptionHandler 即可,详细请看本文第四节的4.2的介绍
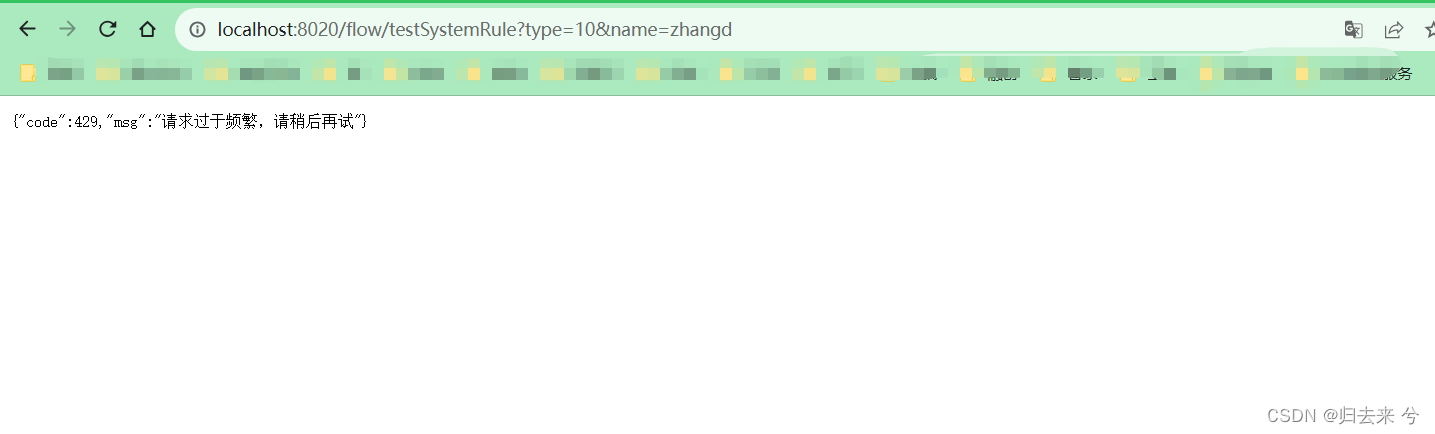
即使我们设定了blockhandler,系统限流一样还是走的是统一的限流方法。这种应该是可以理解的,因为此时请求并没有进入到接口而是在系统层面就被拦截了,自然应该走的是系统层面的限流方法。
************************************************************ 下面是API介绍 ************************************************************
/*** 系统限流*/@Beanpublic SystemRule getSystemRule() {SystemRule systemRule = new SystemRule();// 平均RT:2mssystemRule.setAvgRt(2);// 加载规则SystemRuleManager.loadRules(Collections.singletonList(systemRule));return systemRule;}
其他配置与验证与页面均无区别,这里不重复说了。
九、总结
其实这篇文章里有好几块还没有写:集群、sentinel整合gateway进行流控、生产部署时Sentinel的代码改造等。但是写到这里一篇文章已经5万子如果再写下去就会太长了,成了裹脚布反而不好,笔者会在另外一篇文章再去更新Sentinel的其他信息。
Sentinel最主要的作用就是用来做降级、熔断、流控、授权等了。流控里面其实又可以分为普通流控、热点数据流控、系统流控等。最主要的还是普通流控这个应用会最普通编写。普通流控支持QPS、并发线程数(可以看成TPS但不是TPS)两种策略,每种策略又支持了三种不同的流控模式:直接、关联、链路。而在QPS场景下每种流控模式还支持编辑不同的流控效果:失败、预热、排队等待等,其实Sentinel虽然不难但是知识量还是不少的,本文可以作为比官方文档更加详尽的学习文档使用,希望帮助到各位路过的同学。
相关文章:
SpringCloud Alibaba 入门到精通 - Sentinel
SpringCloud Alibaba 入门到精通 - Sentinel 一、基础结构搭建1.父工程创建2.子工程创建 二、Sentinel的整合SpringCloud1.微服务可能存在的问题2.SpringCloud集成Sentinel搭建Dashboard3 SpringCloud 整合Sentinel 三、服务降级1 服务降级-Sentinel2 Sentinel 整合 OpenFeign3…...

【深度学习实验】前馈神经网络(三):自定义多层感知机(激活函数logistic、线性层算Linear)
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. 构建数据集 2. 激活函数logistic 3. 线性层算子 Linear 4. 两层的前馈神经网络MLP 5. 模型训练 一、实验介绍 本实验实现了一个简单的两层前馈神经网络 激活函数…...

HJ68 成绩排序
描述 给定一些同学的信息(名字,成绩)序列,请你将他们的信息按照成绩从高到低或从低到高的排列,相同成绩 都按先录入排列在前的规则处理。 例示: jack 70 peter 96 Tom 70 smith 67 从高到低…...

FPGA——UART串口通信
文章目录 前言一、UART通信协议1.1 通信格式2.2 MSB或LSB2.3 奇偶校验位2.4 UART传输速率 二、UART通信回环2.1 系统架构设计2.2 fsm_key2.3 baud2.4 sel_seg2.5 fifo2.6 uart_rx2.7 uart_tx2.8 top_uart2.9 发送模块时序分析2.10 接收模块的时序分析2.11 FIFO控制模块时序分析…...
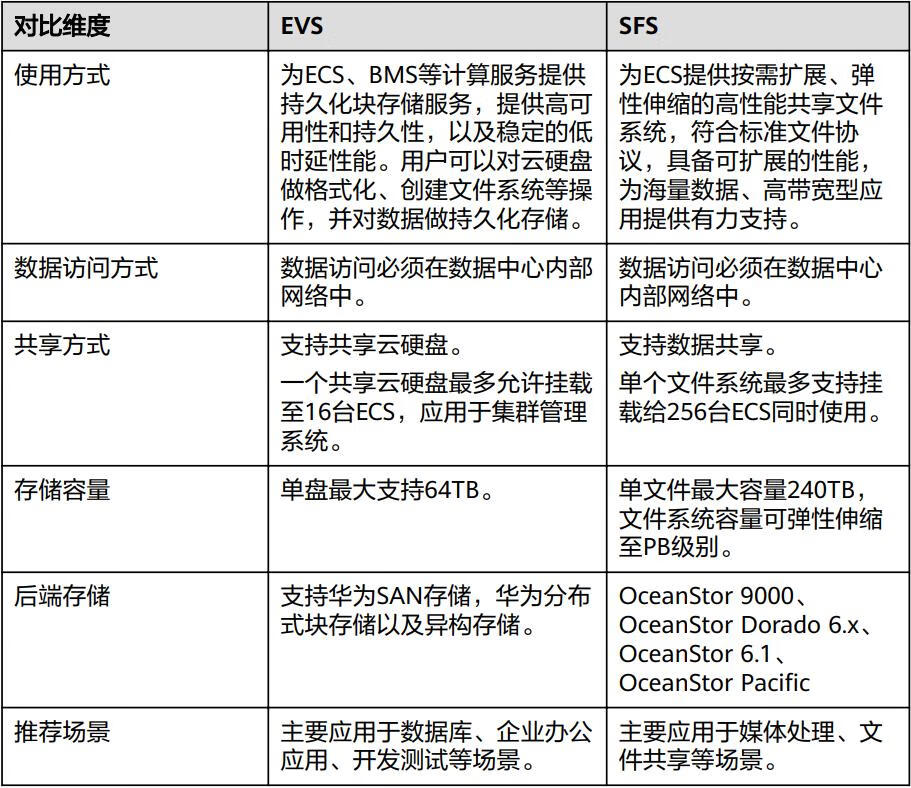
华为云Stack的学习(七)
八、华为云Stack存储服务介绍 1.云硬盘EVS 云硬盘(Elastic Volume Service,EVS),又名磁盘,是一种虚拟块存储服务,主要为ECS(Elastic Cloud Server)和BMS(Bare Metal Se…...

安装k8s集群
一、前置环境配置 安装两台centos 实验环境,一台pc配有docker环境,有两个centsos7容器,其中一个容器作为master,一个作为node。如果master与node都是用默认端口,会存在冲突,所以在此基础上做细微的调整。…...

C++中编写没有参数和返回值的函数
C中编写没有参数和返回值的函数 返回值为 void 函数不需要将值返回给调用者。为了告诉编译器函数不返回值,返回类型为 void。例如: #include <iostream>// void means the function does not return a value to the caller void printHi() {std…...
SWC 流程
一个arxml 存储SWC (可以存多个,也可以一个arxml存一个SWC)一个arxml 存储 composition (只能存一个)一个arxml 存储 system description (通过import dbc自动生成system) 存储SWC和composition的arxml文件分开&#…...

怒刷LeetCode的第10天(Java版)
目录 第一题 题目来源 题目内容 解决方法 方法一:两次拓扑排序 第二题 题目来源 题目内容 解决方法 方法一:分治法 方法二:优先队列(Priority Queue) 方法三:迭代 第三题 题目来源 题目内容…...

java框架-Springboot3-场景整合
文章目录 java框架-Springboot3-场景整合批量安装中间件NoSQL整合步骤RedisTemplate定制化 接口文档远程调用WebClientHttp Interface 消息服务 java框架-Springboot3-场景整合 批量安装中间件 linux安装中间件视频 NoSQL 整合redis视频 整合步骤 RedisTemplate定制化 Re…...
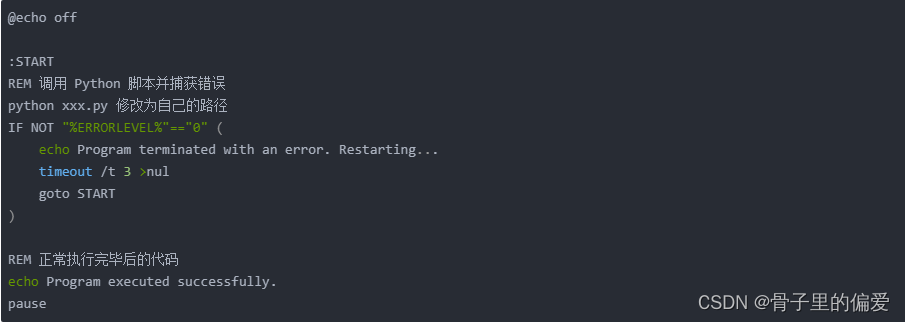
在Bat To Exe Converter,修改为当异常结束或终止时,程序重新启动执行
在Bat To Exe Converter,修改为当异常结束或终止时,程序重新启动执行 .bat中的代码部分: .bat中的代码echo offpython E:\python\yoloProjectTestSmallLarge\detect.pypause,我想你能帮在Bat To Exe Converter,修改成…...
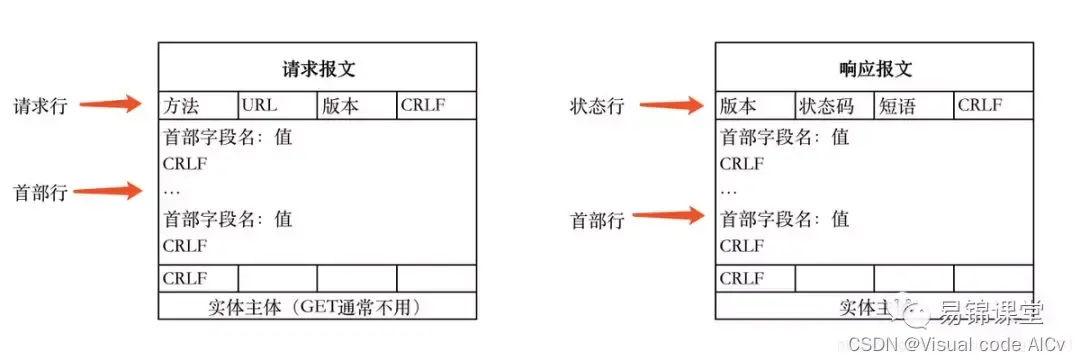
PythonWeb服务器(HTTP协议)
一、HTTP协议与实现原理 HTTP(Hypertext Transfer Protocol,超文本传输协议)是一种用于在网络上传输超文本数据的协议。它是Web应用程序通信的基础,通过客户端和服务器之间的请求和响应来传输数据。在HTTP协议中连接客户与服务器的…...
Northstar 量化平台
基于 B/S 架构、可替代付费商业软件的一站式量化交易平台。具备历史回放、策略研发、模拟交易、实盘交易等功能。兼顾全自动与半自动的使用场景。 已对接国内期货股票、外盘美股港股。 面向程序员的量化交易软件,用于期货、股票、外汇、炒币等多种交易场景ÿ…...

c语言进阶部分详解(经典回调函数qsort()详解及模拟实现)
大家好!上篇文章(c语言进阶部分详解(指针进阶2)_总之就是非常唔姆的博客-CSDN博客)我已经对回调函数进行了初步的讲解和一个简单的使用事例,鉴于篇幅有限没有进行更加详细的解释,今天便来补上。…...

win下 lvgl模拟器codeblocks配置
链接: 官方lvgl的codeblocks官方例子 下载慢的话,可能需要点工具。 需要下载的东西 https://github.com/lvgl/lv_port_win_codeblocks https://github.com/lvgl/lv_drivers/tree/4f98fddd2522b2bd661aeec3ba0caede0e56f96b https://github.com/lvgl/lvgl/tree/7a23…...
Quartus出租车计价器VHDL计费器
名称:出租车计价器VHDL计费器 软件:Quartus 语言:VHDL 要求: 启动键start表示汽车启动,起步价7元,同时路程开始计数,停止键stop表示熄火,车费和路程均为0,当暂停键pa…...
浅谈单元测试:测试和自动化中的利用
【软件测试面试突击班】如何逼自己一周刷完软件测试八股文教程,刷完面试就稳了,你也可以当高薪软件测试工程师(自动化测试) 浅谈单元测试是一件棘手的事情。我很确定测试人员在某个时候会抱怨开发人员没有正确地进行单元测试&…...

深度详解Java序列化
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
)
Linux下的网络编程——B/S模型HTTP(四)
前言: HTTP是基于B/S架构进行通信的,而HTTP的服务器端实现程序有httpd、nginx等,其客户端的实现程序主要是Web浏览器,例如Firefox、Internet Explorer、Google Chrome、Safari、Opera等,此外,客户端的命令…...

Go语言入门篇
目录 一、基础数据类型 1.1 变量的定义方式 1.2 用%T输出变量的类型 二、复合数据类型 2.1 数组 2.1.2、数组的遍历 2.1.3 数组传参 2.2. 切片slice 2.2.1. 初始化切片 2.2.2. append向切片中追加元素 2.2.3. 切片的截取 2.3. map 2.3.1. map初始化 2.3.2. 添加和…...

Ostrakon-VL像素终端实战:生成符合ISO 20252市场调研报告
Ostrakon-VL像素终端实战:生成符合ISO 20252市场调研报告 1. 项目背景与价值 在零售与餐饮行业,市场调研数据的采集和分析一直是一项耗时耗力的工作。传统方法需要人工记录货架商品、价格标签、店铺环境等信息,不仅效率低下,还容…...

LoongArch CPU设计中的内存接口实战:conver_ram.v模块详解与inout端口避坑指南
LoongArch CPU内存接口实战:conver_ram.v模块设计与三态总线控制精要 在CPU微架构设计中,内存子系统如同城市交通枢纽,其效率直接影响整体性能。本文将深入剖析LoongArch架构中BaseRAM/ExtRAM接口模块conver_ram.v的设计要点,特别…...

SenseVoice实战应用:将语音识别集成到你的Python项目中,快速调用API
SenseVoice实战应用:将语音识别集成到你的Python项目中,快速调用API 1. 引言:让Python项目听懂世界 想象一下,你的Python应用能够听懂用户说的话,理解他们的意图,甚至能感知他们的情绪。这在过去可能需要…...

清音刻墨Qwen3部署到使用:一条命令搭建,五分钟出成果
清音刻墨Qwen3部署到使用:一条命令搭建,五分钟出成果 1. 引言:重新定义字幕制作体验 在视频内容爆炸式增长的今天,字幕制作成为了许多创作者的心头之痛。传统的手动打字对时间轴不仅耗时耗力,而且很难达到专业级的精…...

YOLOv11检测头实战:在自定义数据集上提升小目标检测精度的保姆级调参指南
YOLOv11检测头实战:在自定义数据集上提升小目标检测精度的保姆级调参指南 当你在工业质检流水线上发现微小缺陷频繁漏检,或是遥感图像中的小型目标难以捕捉时,传统检测算法的局限性就暴露无遗。YOLOv11的检测头革新为这些痛点提供了专业级解决…...
)
constexpr + consteval + constinit 三重锁性能模型(工业级嵌入式系统内存占用压缩41%,启动时间缩短至23ms)
第一章:constexpr consteval constinit 三重锁性能模型概览C20 引入的 constexpr、consteval 和 constinit 构成了一套分层编译期约束体系,共同构成现代 C 静态性能保障的“三重锁”模型。它们并非替代关系,而是按语义强度递进:…...

大模型应用开发零基础教程:30分钟上手
大模型应用开发零基础教程:30分钟上手 标签:#人工智能、#大模型、#自然语言处理、#大模型开发、#智能体开发、#agent开发、#AI 系统封装学习规划(从玩具到产品) 用streamlit run xxx.py --server.port 8501本地测试免费部署&#…...

MacBook安装OpenClaw:M系列芯片运行Kimi-VL-A3B-Thinking优化指南
MacBook安装OpenClaw:M系列芯片运行Kimi-VL-A3B-Thinking优化指南 1. 为什么要在M系列MacBook上部署OpenClaw 去年我入手了M2 Max芯片的MacBook Pro,原本只是用来做日常开发,直到发现它能流畅运行多模态大模型。作为一个长期被Windows平台G…...

单片机开发:C语言与汇编的实战选择指南
1. 单片机编程语言的选择困境作为一名在嵌入式领域摸爬滚打多年的工程师,我经常被新手问到一个经典问题:"单片机开发到底该用C语言还是汇编?"这个问题看似简单,实则牵涉到开发效率、执行性能、维护成本等多个维度的权衡…...

Qtile配置终极指南:10个Python配置文件编写技巧
Qtile配置终极指南:10个Python配置文件编写技巧 【免费下载链接】qtile :cookie: A full-featured, hackable tiling window manager written and configured in Python (X11 Wayland) 项目地址: https://gitcode.com/gh_mirrors/qt/qtile Qtile是一款功能全…...