计算机视觉与深度学习-循环神经网络与注意力机制-Attention(注意力机制)-【北邮鲁鹏】
目录
- 引出Attention
- 定义
- Attention-based model
- 通俗解释
- 应用在图像领域
- 图像字幕生成(image caption generation)
- 视频处理
序列到序列学习:输入和输出都是长度不同的序列
引出Attention
传统的机器翻译是,将“机器学习”四个字都学习之后,拿着最后一个编码的信息去进行翻译。但是有个问题,就是在进行翻译的时候,“学习”两个字对“机器”翻译成“machine”并没有什么帮助。我们希望在进行前两个字翻译的时候,包含的学习的信息只有“机器”这两个字。
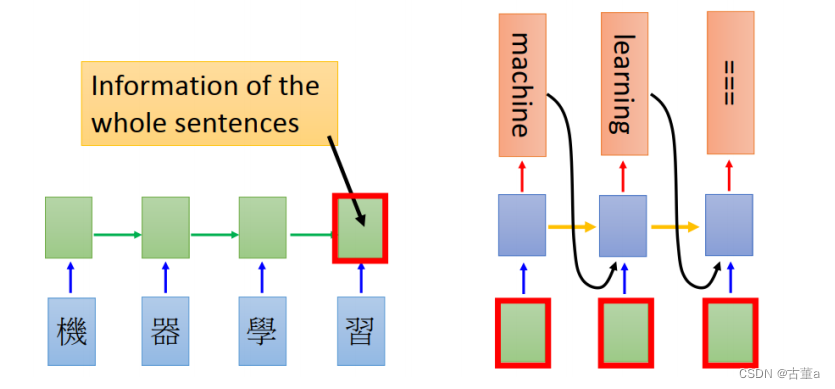
就是很多时候,特别当序列很长很长的时候,最后一个总编码,里面可能把前面信息都丢掉了,如果我有一些注意力机制的时候,我在翻译不同的词的时候,用这序列里面不同的位置的那些不同的位置的字,那可能信息翻译的准确度就会更高一些。
定义
注意力机制(Attention Mechanism)是一种用于增强神经网络模型在处理序列数据时的能力的技术。它在序列到序列(Sequence-to-Sequence)任务中特别常见,如机器翻译、语音识别和摘要生成等任务。
在传统的序列模型中,模型会对整个输入序列进行编码,然后使用编码的固定长度向量进行解码。然而,这种固定长度向量无法充分表示长序列中的所有信息,尤其是对于较长的输入序列,容易出现信息丢失或模糊的问题。
注意力机制通过在解码过程中动态选择性地聚焦(focus)输入序列的特定部分,使模型能够根据输入序列的不同部分调整其关注和权重分配。它允许模型根据当前解码步骤的需要,动态地分配不同的注意力或权重给输入序列的不同位置,以捕捉关键信息。
一般而言,注意力机制包含以下几个关键组成部分:
-
查询(Query):在解码过程中,当前的解码器状态会被用作查询向量,表示当前要生成的目标序列的部分。
-
键(Keys)和值(Values):输入序列经过编码器后得到的键和值。键和值的数量与输入序列的长度相同。
-
注意力权重(Attention Weights):通过计算查询向量与每个输入序列位置的关联程度,得到对应的注意力权重。注意力权重表示了解码器在解码时应该关注输入序列中的哪些部分。
-
上下文向量(Context Vector):将注意力权重与值进行加权求和,得到一个上下文向量。上下文向量是对输入序列的加权汇总,用于提供给解码器更丰富的信息。
注意力机制的引入使模型能够根据输入序列的不同部分调整其关注和重要性,从而提升模型的表现能力。它在序列任务中广泛应用,并取得了显著的效果改进。
Attention-based model
基于注意力机制的模型(Attention-based model)是一种神经网络架构,通常采用编码器-解码器(Encoder-Decoder)框架。编码器负责处理输入序列,并生成表示输入信息的隐藏状态或嵌入向量。解码器根据编码器的表示和先前生成的标记,生成输出序列。
注意力机制使解码器能够动态地聚焦输入序列的不同部分,根据当前解码步骤自适应地选择性地关注相关信息。这使得模型能够有选择地关注输入序列的重要部分,为解码器提供更丰富的上下文信息。
以下是基于注意力机制的模型的高级概述:
-
编码器:输入序列经过编码器网络处理,可以是循环神经网络(RNN)、卷积神经网络(CNN)或Transformer。编码器将输入序列转化为隐藏状态或嵌入向量,捕捉输入信息。
-
解码器:解码器网络以编码器的隐藏状态或嵌入向量为输入,并生成输出序列。在每个解码步骤中,解码器使用注意力机制关注输入序列的不同部分,以确定最相关的信息。
-
注意力计算:注意力机制计算注意力权重,表示每个输入位置对当前解码步骤的重要性或相关性。注意力权重是根据解码器的隐藏状态和编码器的隐藏状态计算得出的。
-
上下文向量:利用注意力权重对编码器的隐藏状态进行加权求和,得到上下文向量。上下文向量提供给解码器一个对输入序列相关部分的汇总表示。
-
解码和下一个标记生成:上下文向量、解码器的隐藏状态和先前生成的标记一起,用于生成输出序列中的下一个标记。这个过程迭代地重复,直到生成完整的输出序列。
假设我们存在一个可学习的向量,叫做 z 0 z^0 z0,还是机器学习这四个字,我希望翻译“machine”,我希望这个单词里面就是“机”和“器”,这两个的特征。希望他两个特征作为我的输入。则使用 z 0 z^0 z0和这四个字的向量 h 1 , h 2 , h 3 , h 4 h^1,h^2,h^3,h^4 h1,h2,h3,h4进行匹配。然后输出一个 0 − 1 0 - 1 0−1的实数。
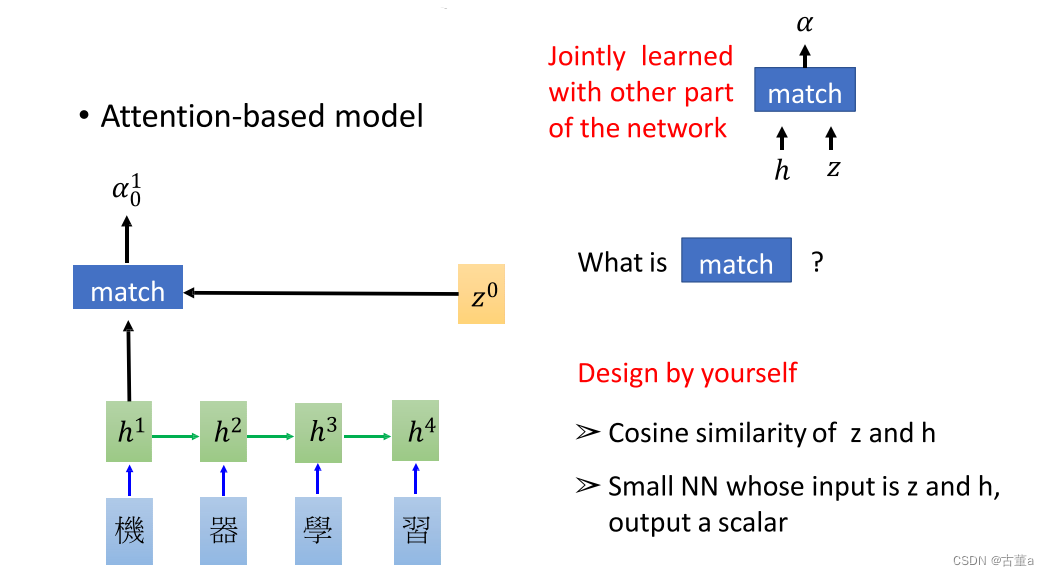
到我们真实做的时候,我们就直接算点乘,这个z向量,跟这个h向量,点乘,完了后得到一个值。
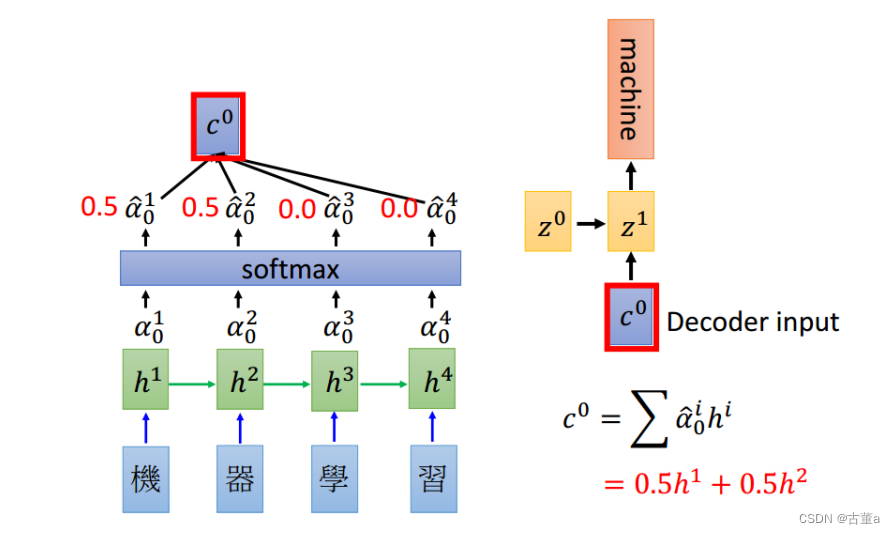
z 0 z^0 z0与四个h向量点乘后,得到四个值。然后使用softmax进行概率化,这四个数值概率化后总和为一,我们希望这个总和以后得到这样一组权重。这四个权值分别拿来跟四个字的向量进行相乘,我的总向量就是由权值和他对应的编码相乘。
因此在翻译“machine”的时候,特征里面只包含 h 1 , h 2 h^1,h^2 h1,h2。
同理,再把 z 1 z^1 z1拿出来,跟四个h向量进行点乘,也能得到一组权值。
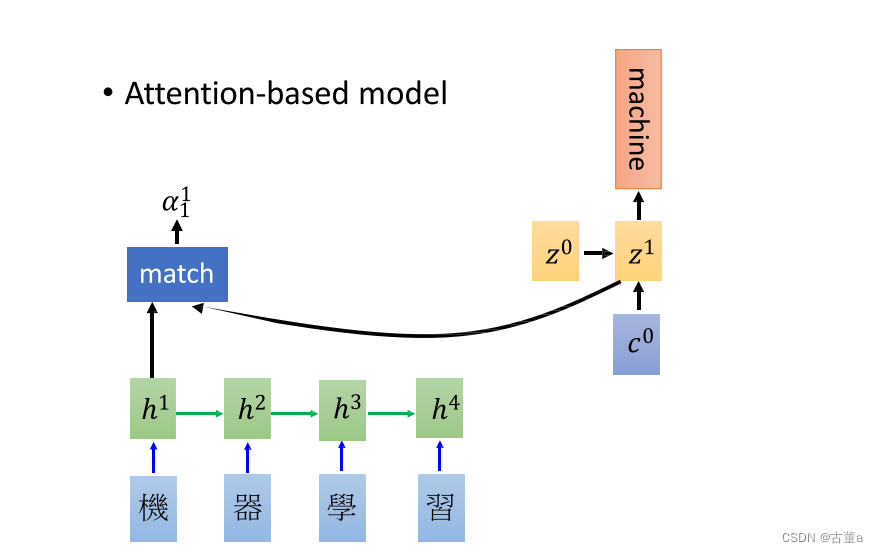
因此在翻译“learning”的时候,特征里面只包含 h 3 , h 4 h^3,h^4 h3,h4。
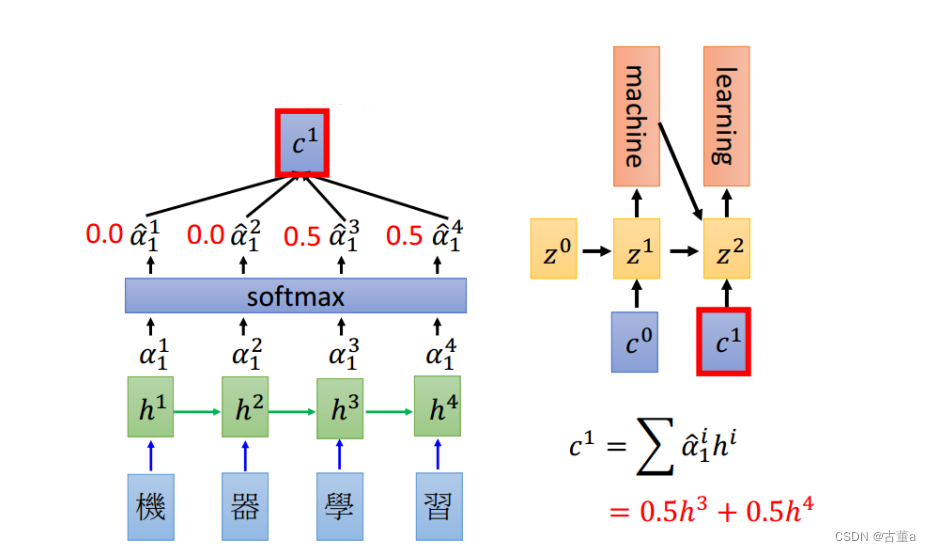
当然最后这个在这种预测任务里面 ,还是要加一个终止符。
就输入来说, c 0 c^0 c0和 c 1 c^1 c1就跟我们原来不一样,原来是把混合到最后一个时刻的都拿出来 ,现在不一样,最后一个时刻确实是包含着前面时刻,但是我不光用最后一个时刻,我还用前面这时刻的,只用attation了以后,我这个时候就更注重前面时刻的信息。
注重在我关注的哪个点。我就注重哪个点的信息
通俗解释
当我们处理信息时,往往需要选择性地关注某些部分而忽略其他部分。类比于人类的注意力,注意力机制就是一种模拟人类关注力的技术。
想象一下,当你在听某个人说话时,你会将注意力集中在他们的声音和表情上,而忽略其他背景噪音或其他人的讲话。这种集中注意力的能力使你能够更好地理解他们说的话并作出适当的回应。
在计算机模型中,注意力机制的作用类似。当模型处理序列数据时,比如一句话或一段文本,注意力机制能够帮助模型选择性地关注输入序列的不同部分,根据当前任务的需要给予不同部分不同的重要性。
具体而言,注意力机制通过计算每个输入位置与当前处理步骤的关联程度,得到对应的权重。这些权重表示了模型在解决当前问题时应该关注输入序列的哪些部分。根据这些权重,模型可以动态地调整对输入序列不同位置的关注程度,以捕捉到关键的信息。
注意力机制的好处是它能够帮助模型更好地处理长序列或复杂的信息。通过集中关注重要的部分,模型能够更准确地理解输入并做出更好的预测或生成结果。
应用在图像领域
图像字幕生成(image caption generation)
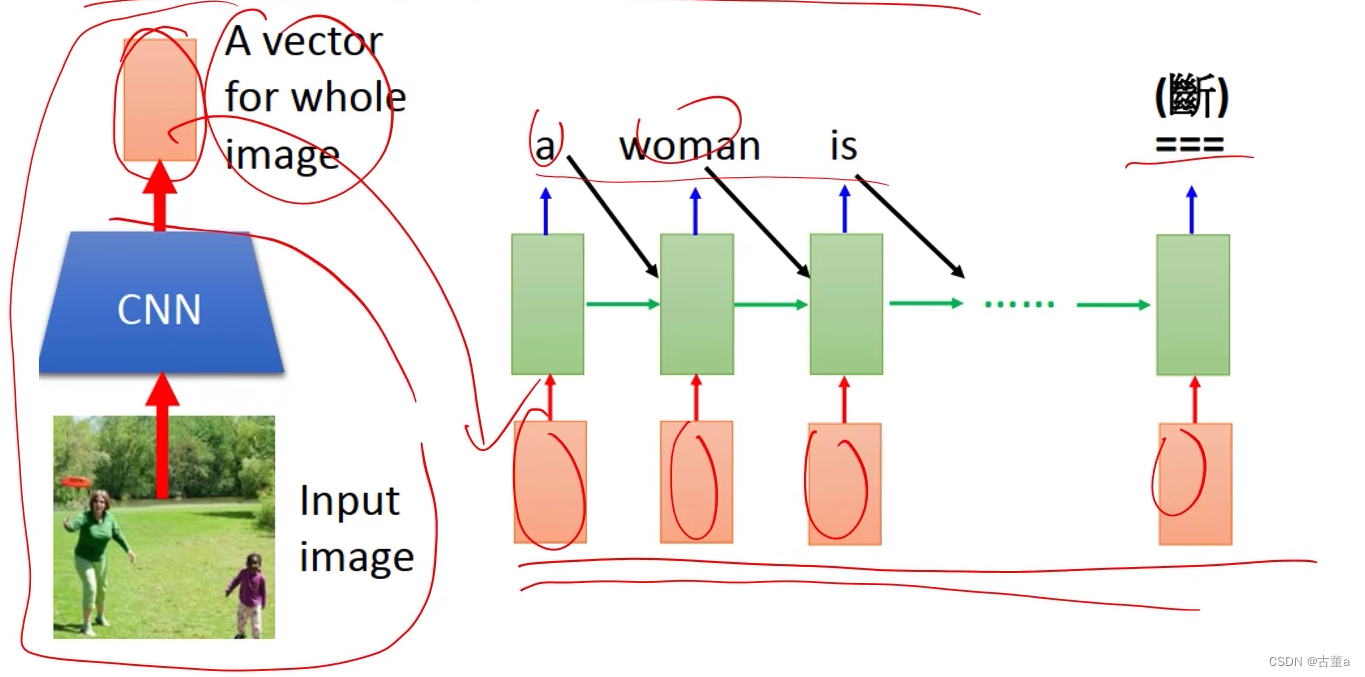
这一段文字产生可以用时序的,但是这个地方的这个特征,图像用cnn,可能提到一个特征,那时候这两个东西连接不到一起去 。使用attention机制。比如women这个单词,这个里面想跟图像的存在women这块区域有关,而跟其他那些地方没关。
怎么实现呢 ?
我们把图像打成六个区块或者八个或者16个或者24个或者64个区块,每个区块去提取一个特征,把这些特征按位置放起来 ,就得到了也是一个时序的东西。
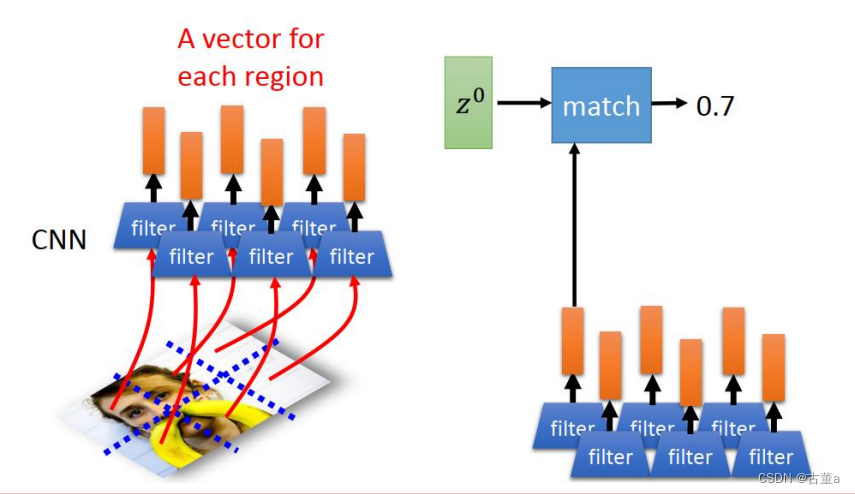
有了时序,使用 z 0 z^0 z0跟这个可以做match,match完了以后。z0跟这个所有特征做match得到一个权重。然后这个权重,就是由这些特征每个不同的图像位置的权重跟他的特征累加起来的。 然后去预测第一个单词
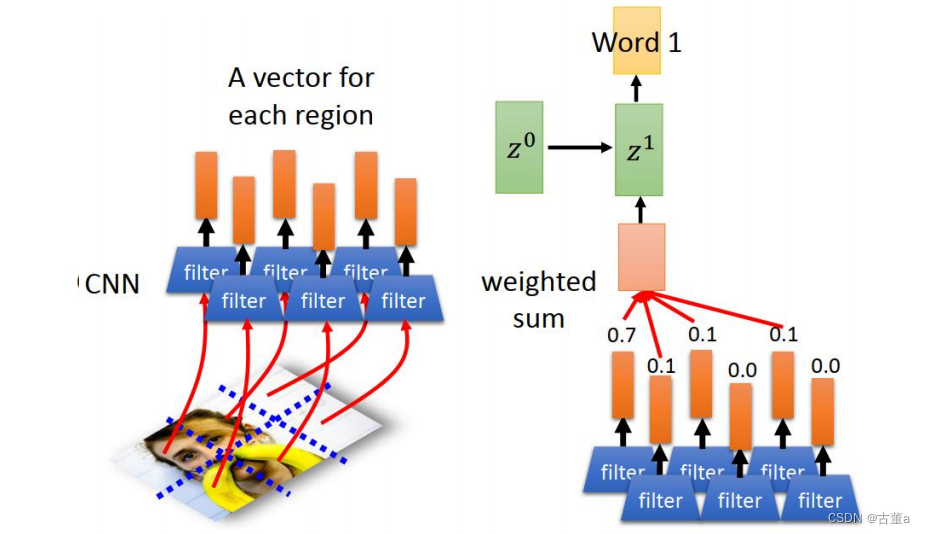
那反过来,第一个单词通过这几个权重,就能看出来这第一个单词跟图像的位置有关系
同理 z 1 z^1 z1继续进行match后预测
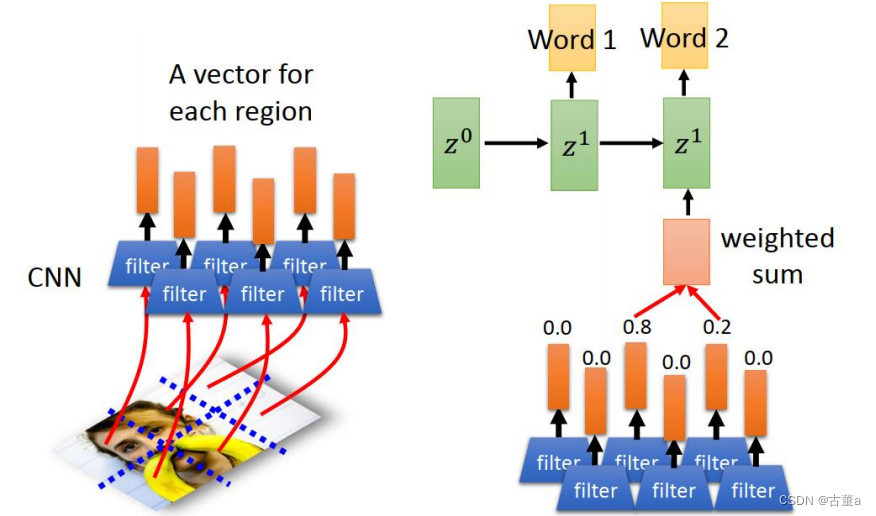
通过看这个单词看到的权重,就知道这个单词跟哪个区域相关。

当然权重不是只有一或者零,有的地方亮就是表示跟他相关度高,这暗的地方表示相关度低。
飞盘已经能知道,这个单词是靠图像的亮这块区域做的决定,狗是靠图像的这块区域做的
还有一些错误的,翻译都翻译错的了。

视频处理
把图像的一个视频序列,把图像的每一帧当做一个特征,每一帧是提取10个特征。
当把这个时间序列和这个语言序列,跟我的这个图像的时间序列就做对齐的时候,就做这种注意力相关的时候,发现单词和视频的某些帧有对应。

相关文章:
计算机视觉与深度学习-循环神经网络与注意力机制-Attention(注意力机制)-【北邮鲁鹏】
目录 引出Attention定义Attention-based model通俗解释应用在图像领域图像字幕生成(image caption generation)视频处理 序列到序列学习:输入和输出都是长度不同的序列 引出Attention 传统的机器翻译是,将“机器学习”四个字都学…...
Centos7安装wps无法打开及字体缺失的问题解决
在centos7上安装了最新的wps2019版本的wps-office-11.1.0.11704-1.x86_64.rpm,生成了桌面图标并信任,可以新建文件,但是软件无法打开。在终端执行如下命令,用命令行启动wps: cd /opt/kingsoft/wps-office/office6/ ./…...
)
华为OD机试真题-会议接待-2023年OD统一考试(B卷)
题目描述: 某组织举行会议,来了多个代表团同时到达,接待处只有一辆汽车,可以同时接待多个代表团,为了提高车辆利用率,请帮接待员计算可以坐满车的接待方案,输出方案数量。 约束: 1、一个团只能上一辆车,并且代表团人数(代表团数量小于30,每个代表团人数小于30)小于…...
mysql explain学习记录
参考了公司内相关博客,实践并记录下,为后面分析并优化索引做准备。 MySQL explain命令是查看MySQL查询优化器如何执行查询的主要方法,可以很好的分析SQL语句的执行情况。 每当遇到执行慢(在业务角度)的SQL,…...

电压放大电路的作用有哪些(电压放大器)
电压放大电路是电子电路中常见且重要的组件,其主要作用是将输入信号的电压放大到所需的输出电压级别,并保持输入信号的形状和准确度。电压放大电路广泛应用于各种电子设备和系统中,具有以下几个重要的作用: 信号放大:电…...

编译opencv-3.4.5 [交叉编译]
在unbuntu20.04环境下编译opencv3.4.5, cmake 版本:3.27.4 gcc 版本:11.4.0 g版本:11.4.0 在此环境下编译opencv4.5.4正常。 1. 编译时遇到的问题 (1) Built target libprotobuf make: *** [Makefile:163…...
Canal 实现MySQL与Elasticsearch7数据同步
1 工作原理 canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump协议 MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ) canal 解析 binary log 对象(原始为 byte 流) 优点&…...
网络安全攻防对抗之隐藏通信隧道技术整理
完成内网信息收集工作后,渗透测试人员需要判断流量是否出得去、进得来。隐藏通信隧道技术常用于在访问受限的网络环境中追踪数据流向和在非受信任的网络中实现安全的数据传输。 一、隐藏通信隧道基础知识 (一)隐藏通信隧道概述 一般的网络通…...
读书笔记:多Transformer的双向编码器表示法(Bert)-2
多Transformer的双向编码器表示法 Bidirectional Encoder Representations from Transformers,即Bert; 第2章 了解Bert模型(掩码语言模型构建和下句预测) 文本嵌入模型Bert,在许多自然语言处理任务上表现优秀&#…...
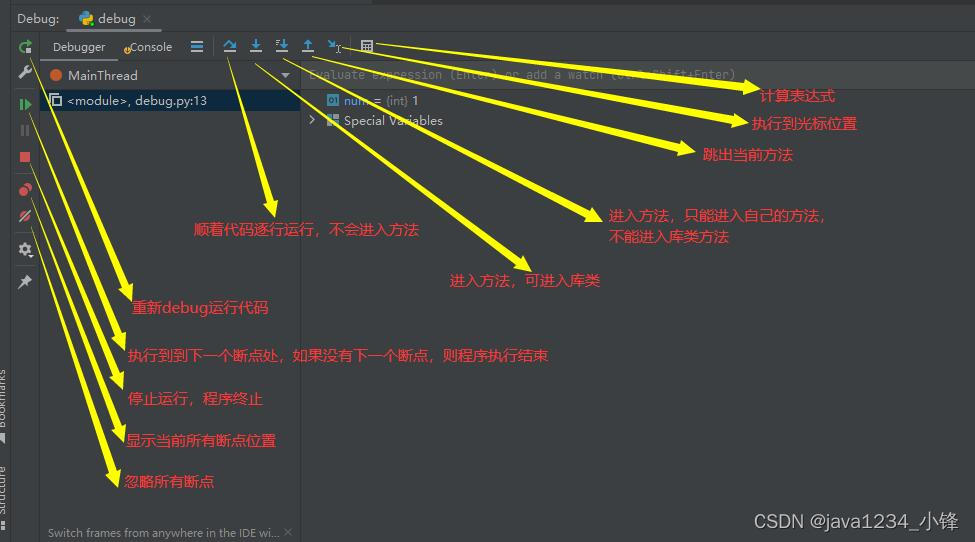
Python 基于PyCharm断点调试
视频版教程 Python3零基础7天入门实战视频教程 PyCharm Debug(断点调试)可以帮助开发者在代码运行时进行实时的调试和错误排查,提高代码开发效率和代码质量。 准备一段代码 def add(num1, num2):return num1 num2if __name__ __main__:f…...

spring security auth2.0实现
OAuth 2.0 的认证/授权流程 jwt只是认证中的一步 4中角色 资源拥有者(resource owner)、客户端(client 第三方)、授权服务器(authorization server)和资源服务器(resource server)。…...
LOCK和MVCC)
MySQL(6)LOCK和MVCC
一、锁的分类 按照锁的属性:读锁、写锁、共享锁、排它锁、悲观锁、乐观锁 按照锁的范围:表锁、页锁、间隙锁、临键锁、行锁 按照锁的作用:意向锁、意向共享锁、意向排它锁、IS锁、IX锁 二、MySQL为什么要有锁 锁是计算机协调多个进程或线程并…...
最新IDE流行度最新排名(每月更新)
2023年09月IDE流行度最新排名 顶级IDE排名是通过分析在谷歌上搜索IDE下载页面的频率而创建的 一个IDE被搜索的次数越多,这个IDE就被认为越受欢迎。原始数据来自谷歌Trends 如果您相信集体智慧,Top IDE索引可以帮助您决定在软件开发项目中使用哪个IDE …...

I2C的上拉电阻如何计算?
说明: 1、本文只说明I2C上拉电阻的最小值如何计算。 2、I2C最小值和最大值计算的详细原理可以参考这篇文章:https://mp.weixin.qq.com/s/ZvJJ0rPRd_STULj8g1H81A。 3、I2C最小值的计算方式比较简单,在实际应用中计算出最小值,然后…...

Centos下安装 oracle11g 博客2
[oraclewangmengyuan database]$ ./runInstaller -silent -responseFile /home/oracle/database/response/db_install.rsp -ignorePrereq ./runInstaller -silent -responseFile /home/oracle/database/response/db_install.rsp -ignorePrereq 正在启动 Oracle Universal Insta…...

记一次逆向某医院挂号软件的经历
背景 最近家里娃需要挂专家号的儿保,奈何专家号实在过于抢手,身为程序员的我也没有其他的社会资源渠道可以去弄个号,只能发挥自己的技术力量来解决这个问题了。 出师不利 首先把应用安装到我已经 Root 过的 Pixel 3 上面,点击应…...
Canal实现Mysql数据同步至Redis、Elasticsearch
文章目录 1.Canal简介1.1 MySQL主备复制原理1.2 canal工作原理 2.开启MySQL Binlog3.安装Canal3.1 下载Canal3.2 修改配置文件3.3 启动和关闭 4.SpringCloud集成Canal4.1 Canal数据结构
Kafka的消息传递保证和一致性
前言 通过前面的文章,相信大家对Kafka有了一定的了解了,那接下来问题就来了,Kafka既然作为一个分布式的消息队列系统,那它会不会出现消息丢失或者重复消费的情况呢?今天咱们就来一探。 实现机制 Kafka采用了一系列机…...

Docker 部署 Firefly III 服务
拉取最新版本的 Firefly III 镜像: $ sudo docker pull fireflyiii/core:latest在本地预先创建好 upload 和 export 目录, 用于映射 Firefly III 容器内的 /var/www/html/storage/upload 和 /var/www/html/storage/export 目录。 使用以下命令来运行 Firefly III …...
配置OSPFv3基本功能 华为笔记
1.1 实验介绍 1.1.1 关于本实验 OSPF协议是为IP协议提供路由功能的路由协议。OSPFv2(OSPF版本2)是支持IPv4的路由协议,为了让OSPF协议支持IPv6,技术人员开发了OSPFv3(OSPF版本3)。 无论是OSPFv2还是OSPFv…...

嵌入式系统中联合体的高效数据管理实践
1. 联合体在嵌入式系统中的高效数据管理实践在嵌入式系统开发中,如何高效地管理和传输数据一直是个值得深入探讨的话题。最近我在一个智能家居控制项目中遇到了一个典型场景:需要同时管理7个用电器的开关状态和4组电源线参数(电压、电流、有功…...

Vue3+Cesium实战避坑指南:从环境配置到坐标转换的常见问题解析
1. Vue3Cesium环境配置避坑指南 第一次在Vue3项目中集成Cesium时,我踩了不少坑。记得当时光是让地球显示出来就折腾了大半天,各种报错让人抓狂。现在回想起来,其实很多问题都有规律可循。 1.1 正确安装Cesium依赖 新手最容易犯的错误就是直接…...

HoRain云--OpenCod安装
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

轻量级代码编辑器Lapce从入门到精通:Rust驱动的极速开发体验
轻量级代码编辑器Lapce从入门到精通:Rust驱动的极速开发体验 【免费下载链接】lapce Lightning-fast and Powerful Code Editor written in Rust 项目地址: https://gitcode.com/GitHub_Trending/la/lapce 核心特性解析:为什么选择Rust编写的编辑…...

python jira
# 聊聊 Python JIRA 这个库 平时做项目管理和开发流程对接的时候,经常需要和 JIRA 这类工具打交道。如果每次都手动在网页上点来点去,效率实在太低。这时候 Python JIRA 库就派上用场了。 它到底是什么 简单来说,Python JIRA 是一个用来和 JI…...
)
保姆级教程:在Ubuntu 22.04上从源码编译安装Micro XRCE-DDS Agent(附虚拟机环境配置)
从零构建嵌入式通信桥梁:Ubuntu 22.04源码编译Micro XRCE-DDS Agent全指南 当AURIX Tricore这类嵌入式设备需要与复杂系统对话时,XRCE-DDS就像一位专业翻译官。想象一下,你的开发板是个只会说方言的本地向导,而云端服务是个讲标准…...

字符串匹配:KMP 不用死记,图解+一步一步推导
字符串匹配:KMP 不用死记,一步一步推导彻底理解 KMP 算法的设计思想,从此不再害怕手写 next 数组前言 字符串匹配是计算机科学中最基础、最常用的问题之一,广泛应用于搜索引擎、文本编辑、病毒检测、DNA序列分析等场景。其核心需求…...

如何将SHADERed着色器项目快速转换为C++代码:完整导出指南
如何将SHADERed着色器项目快速转换为C代码:完整导出指南 【免费下载链接】SHADERed Lightweight, cross-platform & full-featured shader IDE 项目地址: https://gitcode.com/gh_mirrors/sh/SHADERed SHADERed是一款轻量级、跨平台且功能齐全的着色器ID…...

gpu算力与图形处理
核心本质 图形处理(Graphics):GPU 天生本职工作 —— 画画面、渲染 3D、光栅化、纹理、着色、显示输出。GPU 算力(Compute / GPGPU):利用 GPU 超多小核心 做通用并行计算 —— AI、科学计算、挖矿、渲染、仿…...

运用AIBIYE的智能改写工具,掌握五大实用技巧,有效降低论文重复率至合规范围。
嘿,大家好!我是AI菌。今天咱们来聊聊一个让无数学生头疼的问题:论文重复率飙到30%以上怎么办?别慌,我这就分享5个实用降重技巧,帮你一次搞定,轻松压到合格线以下。这些方法都是我亲身试验过的&a…...