windows环境下安装logstash同步数据,注册系统服务
windows环境下安装logstash同步数据,注册系统服务
此方法适用于Windows环境,同一个配置文件配置多个管道,并且配置系统服务,防止程序被杀进程
一、安装logstash
(1)下载压缩包,解压后修改config文件夹中的logstash-sample.conf文件
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.input {
# 日志列表
jdbc {jdbc_driver_library => "D:\logstash-7.2.0\logstash-7.2.0\lib\ojdbc8-19.3.0.0.jar"jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"jdbc_connection_string => "jdbc:oracle:thin:@127.0.0.1:1521:orcl"jdbc_user => "admin"jdbc_password => "123456"# statement => "SELECT * FROM tb_hotel"statement_filepath => "D:\logstash-7.2.0\logstash-7.2.0\sql\admin_gatelog.sql"jdbc_paging_enabled => truejdbc_page_size => 10000jdbc_default_timezone => "Asia/Shanghai"schedule => "* * * * *"# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件record_last_run => true# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值use_column_value => true# 记录上一次追踪的结果值last_run_metadata_path => "D:\logstash-7.2.0\logstash-7.2.0\sync\last_run_gatelog.yml"# 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间tracking_column => "crtTime"# tracking_column 对应字段的类型tracking_column_type => "timestamp"# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录clean_run => false}
# 文件管理
jdbc {jdbc_driver_library => "D:\logstash-7.2.0\logstash-7.2.0\lib\ojdbc8-19.3.0.0.jar"jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"jdbc_connection_string => "jdbc:oracle:thin:@127.0.0.1:1521:orcl"jdbc_user => "mbbb"jdbc_password => "123456"# statement => "SELECT * FROM tb_hotel"statement_filepath => "D:\logstash-7.2.0\logstash-7.2.0\sql\admin_fileManage.sql"jdbc_paging_enabled => truejdbc_page_size => 10000jdbc_default_timezone => "Asia/Shanghai"schedule => "* * * * *"# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件record_last_run => true# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值use_column_value => true# 记录上一次追踪的结果值last_run_metadata_path => "D:\logstash-7.2.0\logstash-7.2.0\sync\last_run_file_manage.yml"# 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间tracking_column => "create_time"# tracking_column 对应字段的类型tracking_column_type => "timestamp"# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录clean_run => false
}
# 消息审计
jdbc {jdbc_driver_library => "D:\logstash-7.2.0\logstash-7.2.0\lib\ojdbc8-19.3.0.0.jar"jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"jdbc_connection_string => "jdbc:oracle:thin:@127.0.0.1:1521:orcl"jdbc_user => "admin"jdbc_password => "123456"# statement => "SELECT * FROM tb_hotel"statement_filepath => "D:\logstash-7.2.0\logstash-7.2.0\sql\admin_messageLog.sql"jdbc_paging_enabled => truejdbc_page_size => 10000jdbc_default_timezone => "Asia/Shanghai"schedule => "* * * * *"# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件record_last_run => true# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值use_column_value => true# 记录上一次追踪的结果值last_run_metadata_path => "D:\logstash-7.2.0\logstash-7.2.0\sync\last_run_message_log.yml"# 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间tracking_column => "createtime"# tracking_column 对应字段的类型tracking_column_type => "timestamp"# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录clean_run => false
}beats {port => 5044}stdin{}
}filter {}output {elasticsearch {hosts => ["http://127.0.0.1:9201","http://127.0.0.1:9202","http://127.0.0.1:9203"]# index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"index => "%{es_index}_index"document_type => "doc"document_id => "%{id}"user => "elastic"password => "elastic"}stdout{}
}(2)在sql文件夹中创建admin_gatelog.sql文件
select 'gate_log' as es_index, # 必须ROWNUM, # 必须ID, # 必须MENU,OPT,URI,to_char(CRT_TIME, 'YYYY-MM-DD HH24:MI:SS') as crtTime, # 必须 和tracking_column对应,任何时间字段都可CRT_USER as crtUser,CRT_NAME as crtName,CRT_HOST as crtHost,IS_SUCCESS as isSuccess,P_ID as pId,OPT_INFO as optInfo,ORG_NAME as orgName,ORG_CODE as orgCode,PATH_CODE as pathCode,PATH_NAME as pathName
from TABLE
where to_timestamp(to_char(CRT_TIME, 'YYYY-MM-DD HH24:MI:SS'), 'YYYY-MM-DD HH24:MI:SS') > :sql_last_value
(3)在symc文件夹中创建 某某.yml文件用来记录数据中最后同步的日期
(4)修改jvm.options的
-Xms5g
-Xmx5g
(5)查看lib 、sql、sync文件夹的配置(没有这些文件夹的请创建),其中:
lib里面放着oracle数据库连接的驱动。(mysql也可以)
sql里面放着配置的要执行的sql文件。
sync里面放着每条sql查询数据全部同步完成后的最新数据的的日期(指定字段的最新日期)
(6)进入到bin目录启动logstash
D:\logstash-7.2.0\logstash-7.2.0\bin>logstash -f D:\logstash-7.2.0\logstash-7.2.0\config\logstash-sample.conf
(7)windows环境下配置系统服务
详细配置请查看附属文档nssm将logstash注册系统服务.pdf
二、附加
影响插入性能的主要因素如下:
一. 服务端
1、磁盘写入速度:越快越好,最好是SSD以上。
2、CPU运算性能:越快越好,多核心可能有益处。
3、内存用量:内存用量大,分配更大容量较好。
4、分片数:与节点数相关,默认5个分片较好。尽量不要让主分片分布在低速节点上。若集群中节点是高低性能搭配的情况,则只分配1个主分片到高速节点上较好,低速节点可用于添加副本。初始导入大量数据前设置索引的副本数为0,导入完成后再开启期望副本数,副本的存在对导入效率的影响成倍提高。
二. 客户端
客户端提交数据采用bulk方式效率高,transport-client略快于rest-client。异步提交比同步提交更能压榨服务器性能。综合比较建议采用bulk+rest+async组合。
bulk批次大小,一般单笔1000条以上或传输数据量在5M-15M左右。实测当中,主要观察服务器处理能力,若服务器处理时间较长导致异步提交响应超时,则要降低单笔传送数据量。
关于分片和副本
1、若索引的分片数(shards)大于1,则索引数据将自动分布在多个分片上,若每个分片分布在不同的实体节点上,则大批量提交数据时可将写入操作分布到不同节点并发进行,从而会提高写入速度。分片数这个参数在创建索引时就固化下来,以后难以更改。
2、副本(replica)是分片的数据备份,同时也提供查询功能。若设置副本数为1,则每个分片都会有1个副本。大批量提交数据时,副本的存在会使得写入数据时间加倍。所幸副本数这个参数可以随时调整,在大批量导入操作开始时将其设置为0,待导入数据完成再修改为1即可,ES引擎会自动处理副本数据。
三、解决elasticsearch限制:
logstash.outputs.elasticsearch] retrying failed action with response code: 429 ({"type"=>"circuit_breaking_exception", "reason"=>"[parent] Data too large, data for [<transport_request>] would be [255226018/243.4mb], which is larger than the limit of [246546432/235.1mb], real usage: [255206808/243.3mb], new bytes reserved: [19210/18.7kb]", "bytes_wanted"=>255226018, "bytes_limit"=>246546432, "durability"=>"PERMANENT"})
添加或修改相关配置项:在 elasticsearch.yml 文件中,你可以添加或修改与数据大小限制有关的配置项。以下是一些常用的配置项:
-
indices.breaker.total.limit:这个配置项用于设置整个索引的数据大小限制。你可以将其设置为你希望的限制值。例如,将限制设置为 1GB:indices.breaker.total.limit: 1gb -
indices.breaker.total.use_real_memory:默认情况下,Elasticsearch 使用 Java 运行时环境的堆内存大小来计算数据大小限制。你可以将此配置项设置为false,以使用 Elasticsearch 自己的内存计算,这有助于更精确地控制限制。例如:indices.breaker.total.use_real_memory: false
相关文章:

windows环境下安装logstash同步数据,注册系统服务
windows环境下安装logstash同步数据,注册系统服务 此方法适用于Windows环境,同一个配置文件配置多个管道,并且配置系统服务,防止程序被杀进程 一、安装logstash (1)下载压缩包,解压后修改con…...
java服务内存说明及配置详解
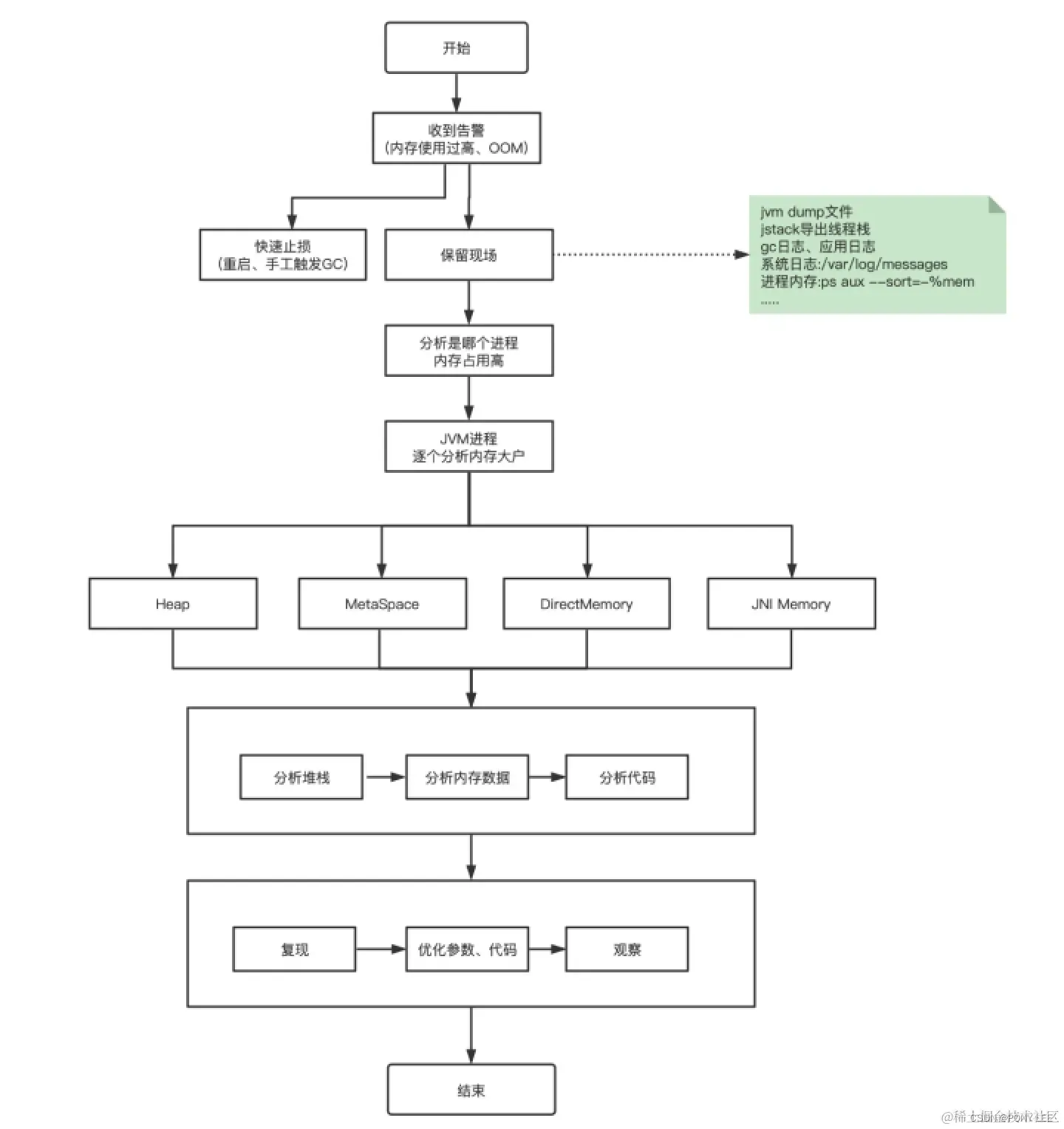
java进程内存 JVM内存分布图: 【java进程内存】【堆外内存】 【jvm堆内存】 【堆外内存】 【Metaspace】 【Direct Memory】【JNI Memory】【code_cache】 … 堆外内存泄漏的排查在于【本地内存(Native Memory)】【Direct Memory】【JNI Memory】 一般…...
Mybatis-MyBatis的缓存
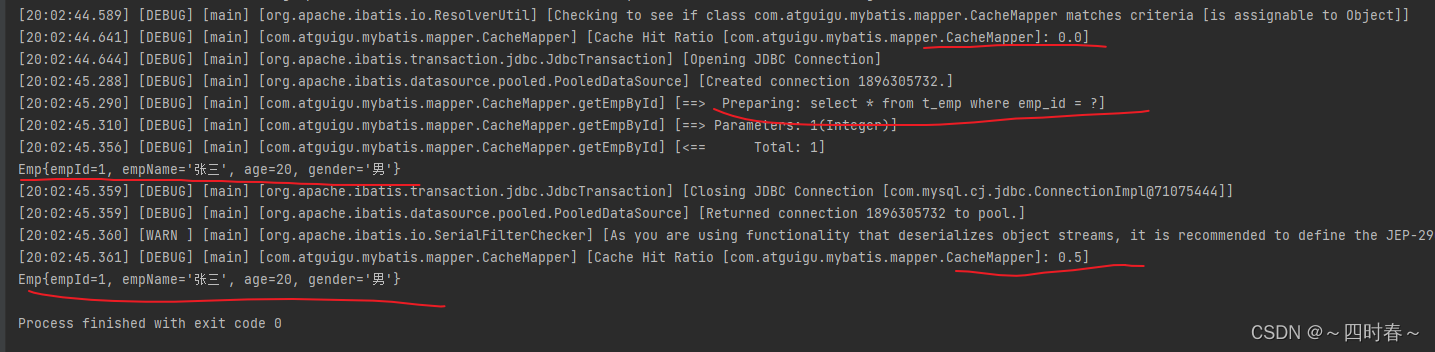
Mybatis-MyBatis的缓存 一、MyBatis的一级缓存二、MyBatis的二级缓存二级缓存的相关配置 三、MyBatis缓存查询的顺序 一、MyBatis的一级缓存 一级缓存是SqlSession级别的,通过同一个SqlSession查询的数据会被缓存,下次查询相同的数据,就 会从…...
计算机组成原理之硬件的基本组成,深入介绍两大计算机结构体系,从底层出发认识计算机。
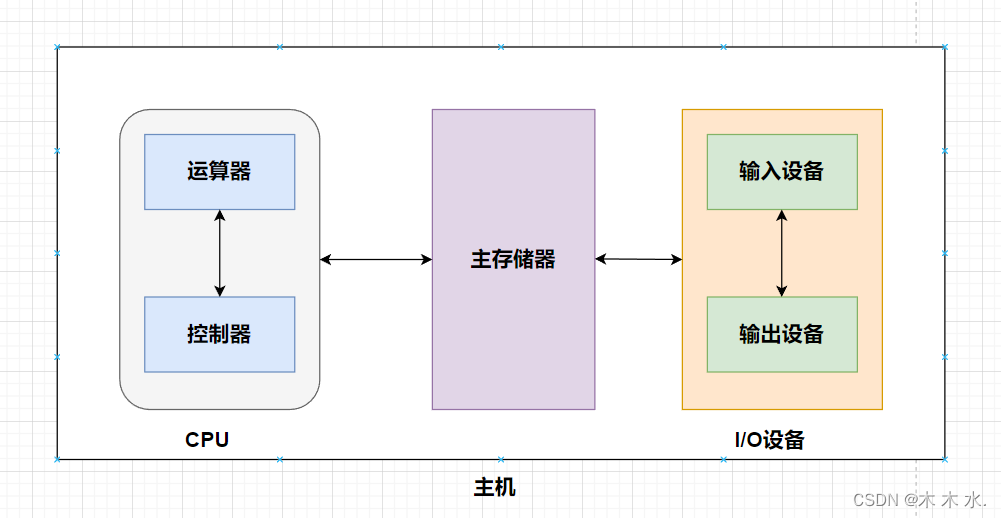
大家好,欢迎阅读《计算机组成原理》的系列文章,本系列文章主要的内容是从零学习计算机组成原理,内容通俗易懂,大家好好学习吧!!! 更多的优质内容,请点击以下链接查看哦~~ ↓ ↓ ↓ …...
二十五、MySQL事务的四大特性和常见的并发事务问题
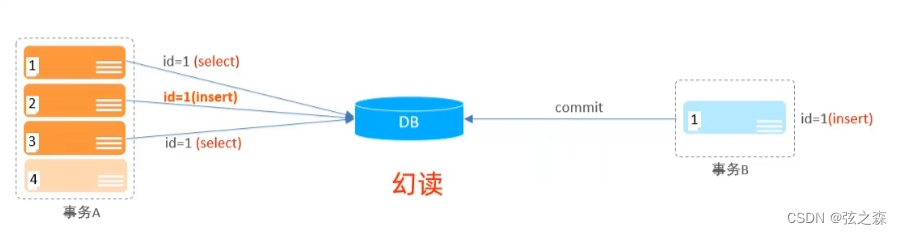
1、事务的四大特性 2、常见的并发事务问题 (1)并发事务问题分类: (2)脏读: 一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致的状态;…...
辨析常见的医学数据分析(相关性分析回归分析)
目录 1 常见的三种分类结果? 2 什么是相关性分析? 相关性分析的结果怎么看? 3 什么是回归分析? 1)前提 2)常见的回归模型 4 对于存在对照组实验的医学病例如何分析? 1)卡方检验…...

SpringBoot项目中只执行一次的任务写法
SpringBoot项目中只执行一次的任务写法 有时候我们需要进行初始化工作,就说明只要进行一次的工作,那么,在Springboot项目中如何做到任务只进行一次呢 利用定时任务 在Spring Boot项目中,你可以使用Spring框架提供的Scheduled注解…...

TCK、TMS、TDI、TDO的含义
这四个信号是JTAG(Joint Test Action Group)界面的一部分。JTAG是一种用于测试和验证集成电路和印刷电路板的技术,也用于进行设备编程和调试。这四个信号分别是: TCK (Test Clock): 意义:测试时钟ÿ…...

R语言RSTAN MCMC:NUTS采样算法用LASSO 构建贝叶斯线性回归模型分析职业声望数据...
全文链接:http://tecdat.cn/?p24456 如果你正在进行统计分析:想要加一些先验信息,最终你想要的是预测。所以你决定使用贝叶斯(点击文末“阅读原文”获取完整代码数据)。 相关视频 但是,你没有共轭先验。你…...
【PowerShell】PowerShell的Core版本的额外配置
在PowerShell 7.1 安装完成后,默认情况下打开PowerShell 会直接进入到系统内置的PowerShell,如果希望通过远程连接或者PowerShell Web Access 进入到PowerShell 7环境的界面,就需要进行环境的再配置才能实现PowerShell 7.1 的环境连接。需要为外部的环境提供连接的话需要按照…...

数据结构----链式栈
目录 前言 链式栈 操作方式 1.存储结构 2.初始化 3.创建节点 4.判断是否满栈 5.判断是否空栈 6.入栈 7.出栈 8.获取栈顶元素 9.遍历栈 10.清空栈 完整代码 前言 前面我们学习过了数组栈的相关方法,(链接:线性表-----栈(栈…...

实在智能携手40+央企,探索财务大模型及数智化实践与应用
“这次培训给我一个最大的感触就是,过去以为AI智能化、大模型技术是很高深的事情。但现在,我们通过RPA等数字化工具,自主根据自己的工作岗位,完成业务自动化流程的开发和设计。AI技术没有想象中的那么难入门。” 这是一位参加了“…...
upload-labs文件上传1-5关
第一关 编写一句话木马1.php,编写完成后将后缀名修改为png 将1.png上传,上传时使用bp抓包 抓包后将后缀名修改为png 连接蚁剑 第二关 上传1.php,显示文件类型不正确 使用bp抓包发送重发器,修改文件后缀名后点击发送,…...

git的基本使用
查看当前分支 git branch //查看本地分支 git branch -a // 查看本地和远程的分支切分支 git checkout -b 分支的名字从当前分支切换到其他分支 拉取远程分支到本地 拉取远程develop分支代码到本地develop分支 git checkout -b develop origin/developgit merge B分支合并…...

Mac台式电脑内存清理方法教程
对于一些小白用户,如果觉得以上的清理方法比较复杂却又想要更好的优化Mac电脑内存,专业的系统清理软件是一个不错的选择。比起花几个小时时间浏览文件夹、删除临时文件、缓存和卸载残留。Cleanmymac X,只需单击几下即可完成所有内存清理工作&…...

FL Studio怎么破解?2023年最新FL Studio 21图文安装激活教程?FL 21中文版下载 v21.1.1.3750 汉化 版
fl studio21中文解锁特别破解版是一款功能强大的编曲软件,也就是众所熟知的水果软件。它可以编曲、剪辑、录音、混音,让您的计算机成为全功能录音室。除此之外,这款软件功能非常强大,为用户提供了许多音频处理工具,包含…...

Zookeeper高级_四字命令
之前使用stat命令来验证ZooKeeper服务器是否启动成功,这里的stat命令就是ZooKeeper 中最为典型的命令之一。ZooKeeper中有很多类似的命令,它们的长度通常都是4个英文字母,因此我们称之为“四字命令”。 添加配置 vim zoo.cfg 4lw.commands…...

/usr/bin/ld: cannot find -lmysqlcllient
文章目录 1. question: /usr/bin/ld: cannot find -lmysqlcllient2. solution 1. question: /usr/bin/ld: cannot find -lmysqlcllient 2. solution 在 使用编译命令 -lmysqlclient时,如果提示这个信息。 先确认一下 有没有安装mysql-devel 执行如下命令 yum inst…...
折线图geom_line()参数选项
往期折线图教程 图形复现| 使用R语言绘制折线图折线图指定位置标记折线图形状更改 | 绘制动态折线图跟着NC学作图 | 使用python绘制折线图 前言 我们折线的专栏推出一段时间,但是由于个人的原因,一直未进行更新。那么今天,我们也参考《R语…...

百度SEO优化基本原理(掌握SEO基础,提高网站排名)
随着互联网的迅速发展,越来越多的企业开始意识到网站优化的重要性,其中百度SEO优化是企业不可忽视的一项工作。本文将介绍百度SEO优化的基本概念、步骤、原理、解决方法和提升网站标题优化的方法。蘑菇号-www.mooogu.cn 百度SEO优化是指针对百度搜索引擎…...

深入Anomalib:如何用Padim、PatchCore等算法为你的自定义数据集做异常定位?
深入Anomalib:如何用Padim、PatchCore等算法为你的自定义数据集做异常定位? 在工业质检和医疗影像领域,异常检测正从"有没有问题"的定性判断,升级到"问题在哪里"的精准定位。当你的数据集充满特殊纹理的PCB板…...
安装教程及下载)
Adobe Illustrator 2026 v30(AI2026)安装教程及下载
我用夸克网盘给你分享了「矢量绘图Adob...已激活版」,点击链接或复制整段内容,打开「夸克APP」即可获取。筷莱蜴蝮鰉鰗鰘夺郝/~b12b3Y1kyM~:/链接:https://pan.quark.cn/s/38566e6aec26Adobe矢量绘图软件Adobe Illustrator 2026(AI2026)是一款…...

终极密码恢复方案:ArchivePasswordTestTool帮你找回遗忘的压缩包密码
终极密码恢复方案:ArchivePasswordTestTool帮你找回遗忘的压缩包密码 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾遇…...
告别Pyscenedetect误判!用TransNet V2精准切割视频转场(附Python实战代码)
告别Pyscenedetect误判!用TransNet V2精准切割视频转场(附Python实战代码) 视频内容创作者和开发者们,是否曾为传统视频切割工具的误判而头疼?高速运动的赛车镜头被误认为转场,长达数秒的渐变过渡被完全忽…...

Super Qwen Voice World生产环境部署:Docker镜像构建与GPU透传配置
Super Qwen Voice World生产环境部署:Docker镜像构建与GPU透传配置 1. 引言 想象一下,你开发了一个超酷的复古像素风语音设计工具,用户只需要输入文字和语气描述,就能生成各种情绪饱满的AI配音。这个工具在本地测试时运行完美&a…...

让ai调试ai:在快马平台上实现rag提示词与检索策略的自动优化
让AI调试AI:在快马平台上实现RAG提示词与检索策略的自动优化 最近在开发一个基于RAG(检索增强生成)的问答系统时,我发现提示词优化和检索策略调优是个既关键又耗时的环节。传统的手动调试方式效率低下,于是尝试用AI来…...

如何用Hogan.js自动生成模板文档:提升项目维护效率的终极指南
如何用Hogan.js自动生成模板文档:提升项目维护效率的终极指南 【免费下载链接】hogan.js A compiler for the Mustache templating language 项目地址: https://gitcode.com/gh_mirrors/ho/hogan.js Hogan.js是一款高效的Mustache模板语言编译器,…...

用Python和Keras从零搭建疲劳驾驶检测器:MTCNN人脸对齐与CNN分类实战
用Python和Keras从零搭建疲劳驾驶检测器:MTCNN人脸对齐与CNN分类实战 在智能交通领域,驾驶员状态监测正成为保障道路安全的关键技术。本文将带您从零构建一个基于视觉分析的疲劳检测系统,通过MTCNN实现毫秒级人脸对齐,结合自定义C…...

Redis如何断开主从同步关系_使用REPLICAOF NO ONE命令将从节点提升为独立主节点
执行REPLICAOF NO ONE后从节点未真正独立,因状态切换有延迟、需确认同步完成、配置文件残留、版本兼容性(4.x用SLAVEOF)、集群模式不支持、提升后写入风险及原主无感知。执行 REPLICAOF NO ONE 后从节点没真正“独立”?命令本身没…...

高效优化Windows 11:Win11Debloat彻底提升系统性能与隐私保护指南
高效优化Windows 11:Win11Debloat彻底提升系统性能与隐私保护指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declu…...