Elasticsearch:与多个 PDF 聊天 | LangChain Python 应用教程(免费 LLMs 和嵌入)
在本博客中,你将学习创建一个 LangChain 应用程序,以使用 ChatGPT API 和 Huggingface 语言模型与多个 PDF 文件聊天。
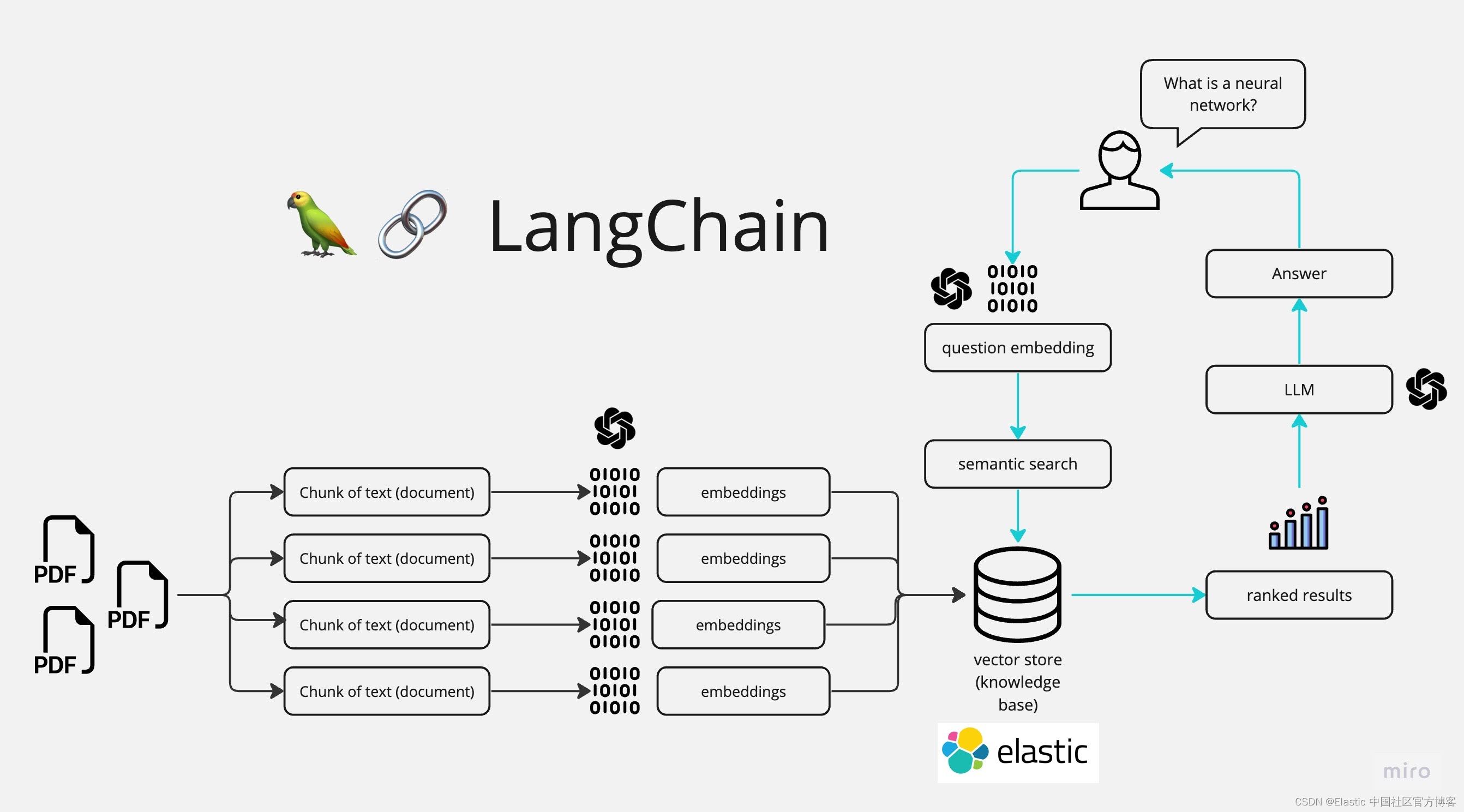
如上所示,我们在最最左边摄入 PDF 文件,并它们连成一起,并分为不同的 chunks。我们可以通过使用 huggingface 来对 chunks 进行处理并形成 embeddings。我们把 embeddings 写入到 Elasticsearch 向量数据库中,并保存。在搜索的时候,我们通过 LangChain 来进行向量化,并使用 Elasticsearch 进行向量搜索。在最后,我们通过大模型的使用,针对提出的问题来进行提问。我们最终的界面如下:
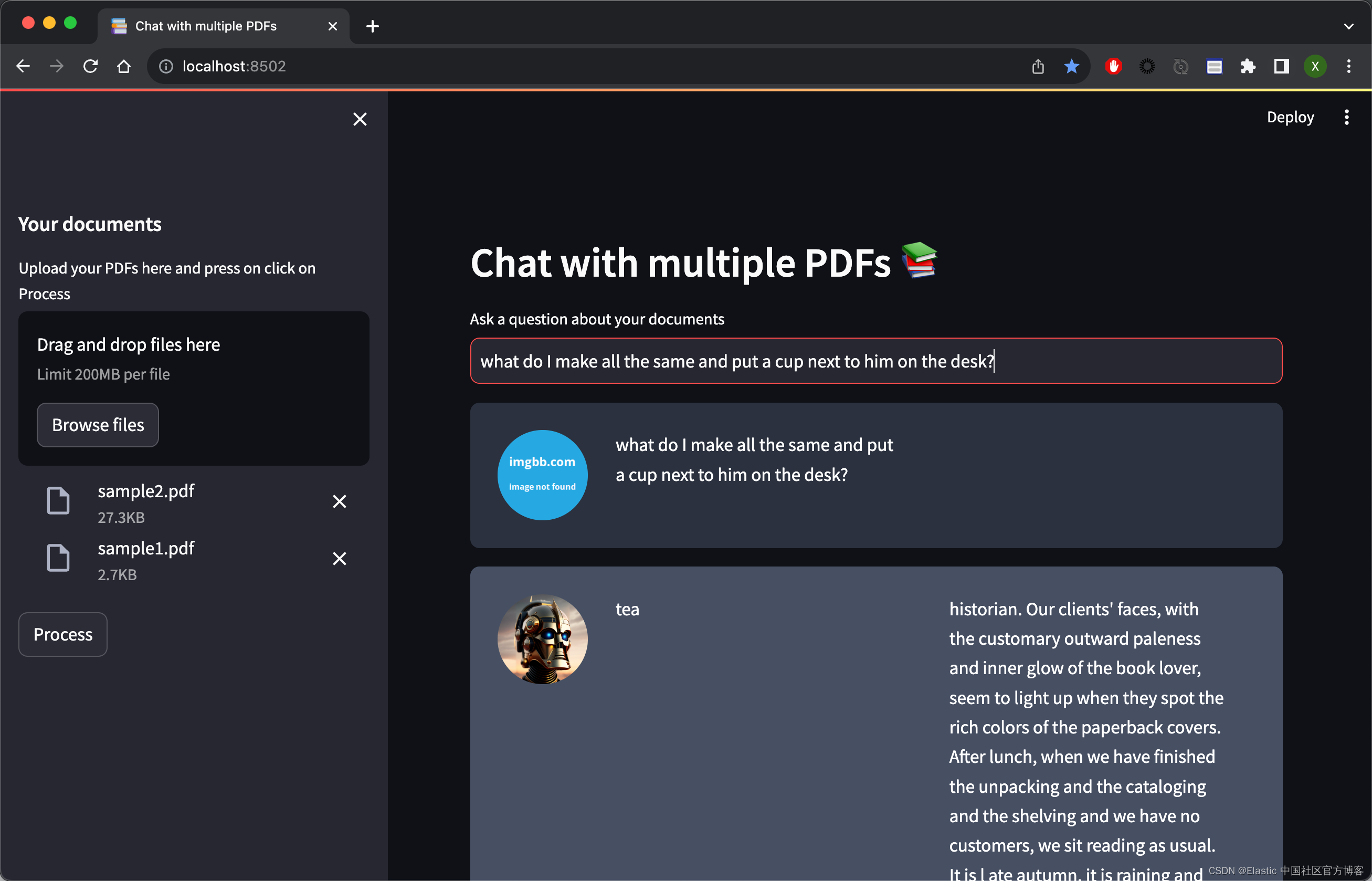
如上所示,它可以针对我们的问题进行回答。进一步阅读
- 使用 LangChain 和 Elasticsearch 对私人数据进行人工智能搜索
-
使用 LangChain 和 Elasticsearch 的隐私优先 AI 搜索
所有的源码可以在地址 GitHub - liu-xiao-guo/ask-multiple-pdfs: A Langchain app that allows you to chat with multiple PDFs 进行下载。
安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana 的话,那么请参考如下的链接:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 9.x 的安装指南来进行安装。在默认的情况下,Elasticsearch 集群的访问具有 HTTPS 的安全访问。
在安装时,我们可以在 Elasticsearch 的如下地址找到相应的证书文件 http_ca.crt:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.10.0/config/certs
$ ls
http.p12 http_ca.crt transport.p12我们需要把该证书拷贝到项目文件的根目录下:
$ tree -L 3
.
├── app.py
├── docs
│ └── PDF-LangChain.jpg
├── htmlTemplates.py
├── http_ca.crt
├── lib_embeddings.py
├── lib_indexer.py
├── lib_llm.py
├── lib_vectordb.py
├── myapp.py
├── pdf_files
│ ├── sample1.pdf
│ └── sample2.pdf
├── readme.md
├── requirements.txt
└── simple.cfg如上所示,我们把 http_ca.crt 拷贝到应用的根目录下。我们在 pdf_files 里放了两个用于测试的 PDF 文件。你可以使用自己的 PDF 文件来进行测试。我们在 simple.cfg 做如下的配置:
ES_SERVER: "localhost"
ES_PASSWORD: "vXDWYtL*my3vnKY9zCfL"
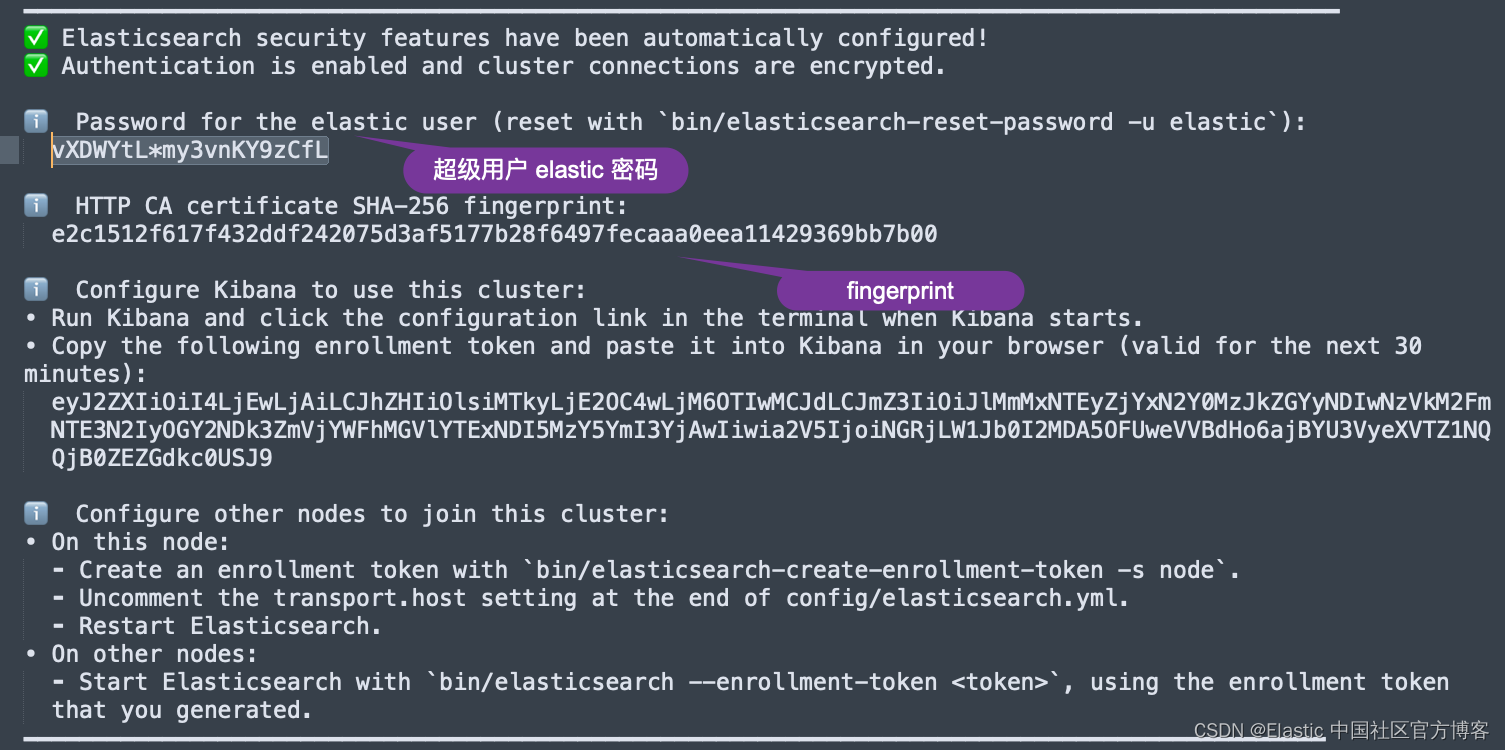
ES_FINGERPRINT: "e2c1512f617f432ddf242075d3af5177b28f6497fecaaa0eea11429369bb7b00"在上面,我们需要配置 ES_SERVER。这个是 Elasticsearch 集群的地址。这里的 ES_PASSWORD 是 Elasticsearch 的超级用户 elastic 的密码。我们可以在 Elasticsearch 第一次启动的画面中找到这个 ES_FINGERPRINT:
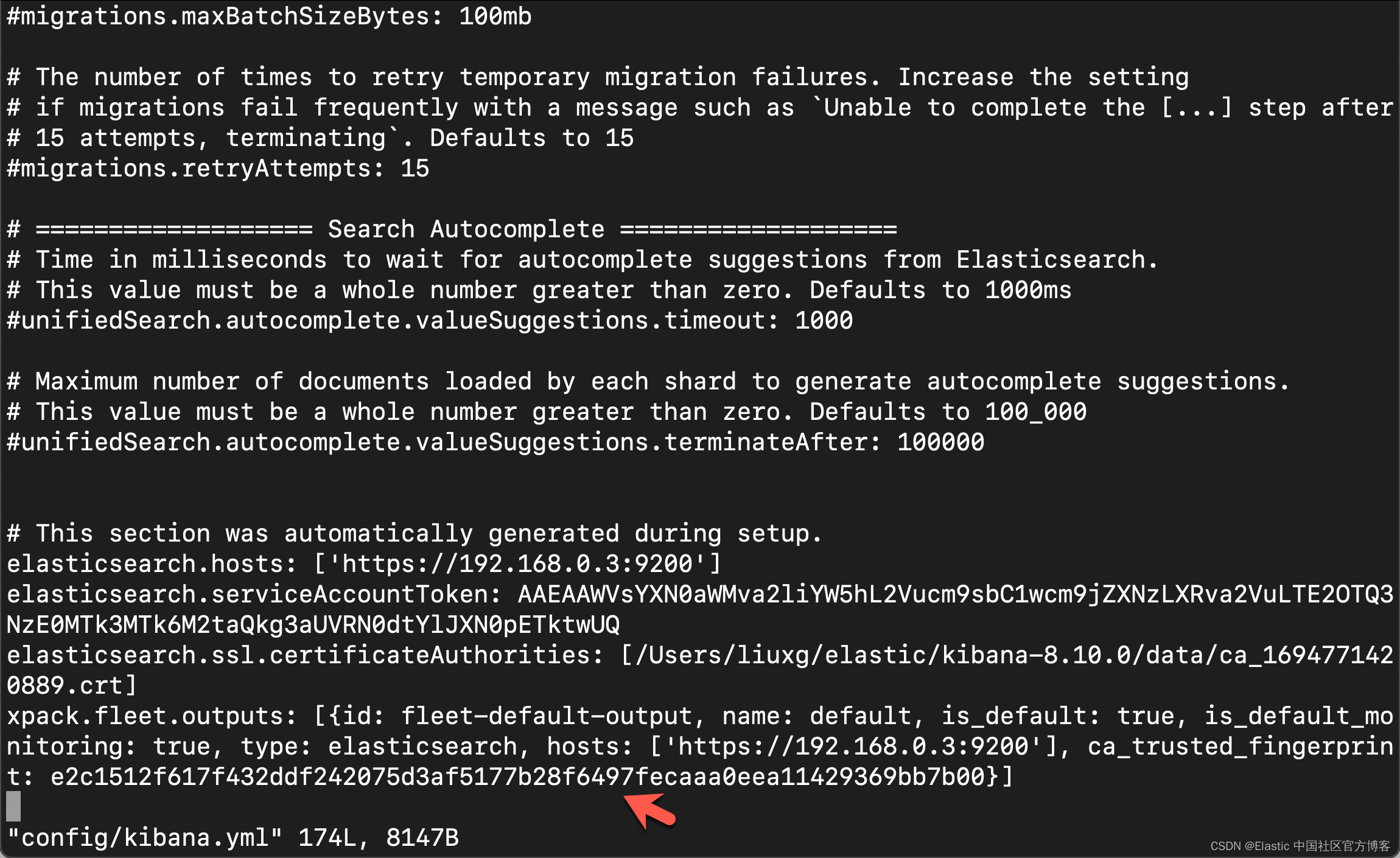
你还可以在 Kibana 的配置文件 confgi/kibana.yml 文件中获得 fingerprint 的配置:
在项目的目录中,我们还可以看到一个叫做 .env-example 的文件。我们可以使用如下的命令把它重新命名为 .env:
mv .env.example .env在 .env 中,我们输入 huggingface.co 网站得到的 token:
$ cat .env
OPENAI_API_KEY=your_openai_key
HUGGINGFACEHUB_API_TOKEN=your_huggingface_key在本例中,我们将使用 huggingface 来进行测试。如果你需要使用到 OpenAI,那么你需要配置它的 key。有关 huggingface 的开发者 key,你可以在地址获得。
运行项目
在运行项目之前,你需要做一下安装的动作:
python3 -m venv env
source env/bin/activate
python3 -m pip install --upgrade pip
pip install -r requirements.txt创建界面
本应用的界面,我们采用是 streamlit 来创建的。它的创建也是非常地简单。我们可以在 myapp.py 中看到如下的代码:
myapp.py
import streamlit as st
from dotenv import load_dotenv
from PyPDF2 import PdfReader
from htmlTemplates import css, bot_template, user_templatedef get_pdf_texts(pdf_docs):text = ""for pdf in pdf_docs:pdf_reader = PdfReader(pdf)for page in pdf_reader.pages:text += page.extract_text()return textdef main():load_dotenv()st.set_page_config(page_title="Chat with multiple PDFs", page_icon=":books:")st.write(css, unsafe_allow_html=True)st.header("Chat with multiple PDFs :books:")user_question = st.text_input("Ask a question about your documents")if user_question:passst.write(user_template.replace("{{MSG}}", "Hello, human").replace("{{MSG1}}", " "), unsafe_allow_html=True)st.write(bot_template.replace("{{MSG}}", "Hello, robot").replace("{{MSG1}}", " "), unsafe_allow_html=True)# Add a side barwith st.sidebar:st.subheader("Your documents")pdf_docs = st.file_uploader("Upload your PDFs here and press on click on Process", accept_multiple_files=True)print(pdf_docs)if st.button("Process"):with st.spinner("Processing"):# Get pdf text fromraw_text = get_pdf_texts(pdf_docs)st.write(raw_text)if __name__ == "__main__":main()在上面的代码中,我创建了一个 sidebar 用来选择需要的 PDF 文件。我们可以点击 Process 按钮来显示已经提取的 PDF 文本。我们可以使用如下的命令来运行应用:
(venv) $ streamlit run myapp.pyvenv) $ streamlit run myapp.pyYou can now view your Streamlit app in your browser.Local URL: http://localhost:8502Network URL: http://198.18.1.13:8502运行完上面的命令后,我们可以在浏览器中打开应用:
我们点击 Browse files,并选中 PDF 文件:

点击上面的 Process,我们可以看到:

在上面,我们为了显示的方便,我使用 st.write 直接把结果写到浏览器的页面里。我们接下来需要针对这个长的文字进行切分为一个一个的 chunks。我们需要按照模型的需要,不能超过模型允许的最大值。
上面我简单地叙述了 UI 的构造。最终完整的 myapp.py 的设计如下:
myapp.py
import streamlit as st
from dotenv import load_dotenv
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from htmlTemplates import css, bot_template, user_templateimport lib_indexer
import lib_llm
import lib_embeddings
import lib_vectordbindex_name = "pdf_docs"def get_pdf_text(pdf):text = ""pdf_reader = PdfReader(pdf)for page in pdf_reader.pages:text += page.extract_text()return textdef get_pdf_texts(pdf_docs):text = ""for pdf in pdf_docs:pdf_reader = PdfReader(pdf)for page in pdf_reader.pages:text += page.extract_text()return textdef get_text_chunks(text):text_splitter = CharacterTextSplitter(separator="\n", chunk_size=1000,chunk_overlap=200,length_function=len)chunks = text_splitter.split_text(text)# chunks = text_splitter.split_documents(text)return chunksdef get_text_chunks1(text):text_splitter = RecursiveCharacterTextSplitter(chunk_size=384, chunk_overlap=0)chunks = text_splitter.split_text(text)return chunksdef handle_userinput(db, llm_chain_informed, user_question):similar_docs = db.similarity_search(user_question)print(f'The most relevant passage: \n\t{similar_docs[0].page_content}')## 4. Ask Local LLM context informed prompt# print(">> 4. Asking The Book ... and its response is: ")informed_context= similar_docs[0].page_contentresponse = llm_chain_informed.run(context=informed_context,question=user_question)st.write(user_template.replace("{{MSG}}", user_question).replace("{{MSG1}}", " "), unsafe_allow_html=True)st.write(bot_template.replace("{{MSG}}", response).replace("{{MSG1}}", similar_docs[0].page_content),unsafe_allow_html=True)def main():# # Huggingface embedding setuphf = lib_embeddings.setup_embeddings()# # # ## Elasticsearch as a vector dbdb, url = lib_vectordb.setup_vectordb(hf, index_name)# # # ## set up the conversational LLMllm_chain_informed= lib_llm.make_the_llm()load_dotenv()st.set_page_config(page_title="Chat with multiple PDFs", page_icon=":books:")st.write(css, unsafe_allow_html=True)st.header("Chat with multiple PDFs :books:")user_question = st.text_input("Ask a question about your documents")if user_question:handle_userinput(db, llm_chain_informed, user_question)st.write(user_template.replace("{{MSG}}", "Hello, human").replace("{{MSG1}}", " "), unsafe_allow_html=True)st.write(bot_template.replace("{{MSG}}", "Hello, robot").replace("{{MSG1}}", " "), unsafe_allow_html=True)# Add a side barwith st.sidebar:st.subheader("Your documents")pdf_docs = st.file_uploader("Upload your PDFs here and press on click on Process", accept_multiple_files=True)print(pdf_docs)if st.button("Process"):with st.spinner("Processing"):# Get pdf text from# raw_text = get_pdf_text(pdf_docs[0])raw_text = get_pdf_texts(pdf_docs)# st.write(raw_text)print(raw_text)# Get the text chunkstext_chunks = get_text_chunks(raw_text)# st.write(text_chunks)# Create vector storelib_indexer.loadPdfChunks(text_chunks, url, hf, db, index_name)if __name__ == "__main__":main()创建嵌入模型
lib_embedding.py
## for embeddings
from langchain.embeddings import HuggingFaceEmbeddingsdef setup_embeddings():# Huggingface embedding setupprint(">> Prep. Huggingface embedding setup")model_name = "sentence-transformers/all-mpnet-base-v2"return HuggingFaceEmbeddings(model_name=model_name)创建向量存储
lib_vectordb.py
import os
from config import Config## for vector store
from langchain.vectorstores import ElasticVectorSearchdef setup_vectordb(hf,index_name):# Elasticsearch URL setupprint(">> Prep. Elasticsearch config setup")with open('simple.cfg') as f:cfg = Config(f)endpoint = cfg['ES_SERVER']username = "elastic"password = cfg['ES_PASSWORD']ssl_verify = {"verify_certs": True,"basic_auth": (username, password),"ca_certs": "./http_ca.crt",}url = f"https://{username}:{password}@{endpoint}:9200"return ElasticVectorSearch( embedding = hf, elasticsearch_url = url, index_name = index_name, ssl_verify = ssl_verify), url创建使用带有上下文和问题变量的提示模板的离线 LLM
lib_llm.py
## for conversation LLM
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoModelForSeq2SeqLMdef make_the_llm():# Get Offline flan-t5-large ready to go, in CPU modeprint(">> Prep. Get Offline flan-t5-large ready to go, in CPU mode")model_id = 'google/flan-t5-large'# go for a smaller model if you dont have the VRAMtokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForSeq2SeqLM.from_pretrained(model_id) #load_in_8bit=True, device_map='auto'pipe = pipeline("text2text-generation",model=model, tokenizer=tokenizer, max_length=100)local_llm = HuggingFacePipeline(pipeline=pipe)# template_informed = """# I know the following: {context}# Question: {question}# Answer: """template_informed = """I know: {context}when asked: {question}my response is: """prompt_informed = PromptTemplate(template=template_informed, input_variables=["context", "question"])return LLMChain(prompt=prompt_informed, llm=local_llm)写入以向量表示的 PDF 文件
以下是我的分块和向量存储代码。 它需要在 Elasticsearch 中准备好组成的 Elasticsearch url、huggingface 嵌入模型、向量数据库和目标索引名称
lib_indexer.py
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader## for vector store
from langchain.vectorstores import ElasticVectorSearch
from elasticsearch import Elasticsearch
from config import Configwith open('simple.cfg') as f:cfg = Config(f)fingerprint = cfg['ES_FINGERPRINT']
endpoint = cfg['ES_SERVER']
username = "elastic"
password = cfg['ES_PASSWORD']
ssl_verify = {"verify_certs": True,"basic_auth": (username, password),"ca_certs": "./http_ca.crt"
}url = f"https://{username}:{password}@{endpoint}:9200"def parse_book(filepath):loader = TextLoader(filepath)documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=384, chunk_overlap=0)docs = text_splitter.split_documents(documents)return docsdef parse_triplets(filepath):docs = parse_book(filepath)result = []for i in range(len(docs) - 2):concat_str = docs[i].page_content + " " + docs[i+1].page_content + " " + docs[i+2].page_contentresult.append(concat_str)return result#db.from_texts(docs, embedding=hf, elasticsearch_url=url, index_name=index_name)## load book utility
## params
## filepath: where to get the book txt ... should be utf-8
## url: the full Elasticsearch url with username password and port embedded
## hf: hugging face transformer for sentences
## db: the VectorStore Langcahin object ready to go with embedding thing already set up
## index_name: name of index to use in ES
##
## will check if the index_name exists already in ES url before attempting split and load
def loadBookTriplets(filepath, url, hf, db, index_name):with open('simple.cfg') as f:cfg = Config(f)fingerprint = cfg['ES_FINGERPRINT']es = Elasticsearch( [ url ], basic_auth = ("elastic", cfg['ES_PASSWORD']), ssl_assert_fingerprint = fingerprint, http_compress = True )## Parse the book if necessaryif not es.indices.exists(index=index_name):print(f'\tThe index: {index_name} does not exist')print(">> 1. Chunk up the Source document")results = parse_triplets(filepath)print(">> 2. Index the chunks into Elasticsearch")elastic_vector_search= ElasticVectorSearch.from_documents( docs,embedding = hf, elasticsearch_url = url, index_name = index_name, ssl_verify = ssl_verify)else:print("\tLooks like the pdfs are already loaded, let's move on")def loadBookBig(filepath, url, hf, db, index_name):es = Elasticsearch( [ url ], basic_auth = ("elastic", cfg['ES_PASSWORD']), ssl_assert_fingerprint = fingerprint, http_compress = True )## Parse the book if necessaryif not es.indices.exists(index=index_name):print(f'\tThe index: {index_name} does not exist')print(">> 1. Chunk up the Source document")docs = parse_book(filepath)# print(docs)print(">> 2. Index the chunks into Elasticsearch")elastic_vector_search= ElasticVectorSearch.from_documents( docs,embedding = hf, elasticsearch_url = url, index_name = index_name, ssl_verify = ssl_verify) else:print("\tLooks like the pdfs are already loaded, let's move on")def loadPdfChunks(chunks, url, hf, db, index_name): es = Elasticsearch( [ url ], basic_auth = ("elastic", cfg['ES_PASSWORD']), ssl_assert_fingerprint = fingerprint, http_compress = True )## Parse the book if necessaryif not es.indices.exists(index=index_name):print(f'\tThe index: {index_name} does not exist') print(">> 2. Index the chunks into Elasticsearch")print("url: ", url)print("index_name", index_name)elastic_vector_search = db.from_texts( chunks,embedding = hf, elasticsearch_url = url, index_name = index_name, ssl_verify = ssl_verify) else:print("\tLooks like the pdfs are already loaded, let's move on")
提问
我们使用 streamlit 的 input 来进行提问:
user_question = st.text_input("Ask a question about your documents")if user_question:handle_userinput(db, llm_chain_informed, user_question)当我们打入 ENTER 键后,上面的代码调用 handle_userinput(db, llm_chain_informed, user_question):
def handle_userinput(db, llm_chain_informed, user_question):similar_docs = db.similarity_search(user_question)print(f'The most relevant passage: \n\t{similar_docs[0].page_content}')## 4. Ask Local LLM context informed prompt# print(">> 4. Asking The Book ... and its response is: ")informed_context= similar_docs[0].page_contentresponse = llm_chain_informed.run(context=informed_context,question=user_question)st.write(user_template.replace("{{MSG}}", user_question).replace("{{MSG1}}", " "), unsafe_allow_html=True)st.write(bot_template.replace("{{MSG}}", response).replace("{{MSG1}}", similar_docs[0].page_content),unsafe_allow_html=True)首先它使用 db 进行相似性搜索,然后我们再使用大模型来得到我们想要的答案。
运行结果
我们使用命令来运行代码:
streamlit run myapp.py我们在浏览器中选择在 pdf_files 中的两个 PDF 文件:

在上面,我们输入想要的问题:
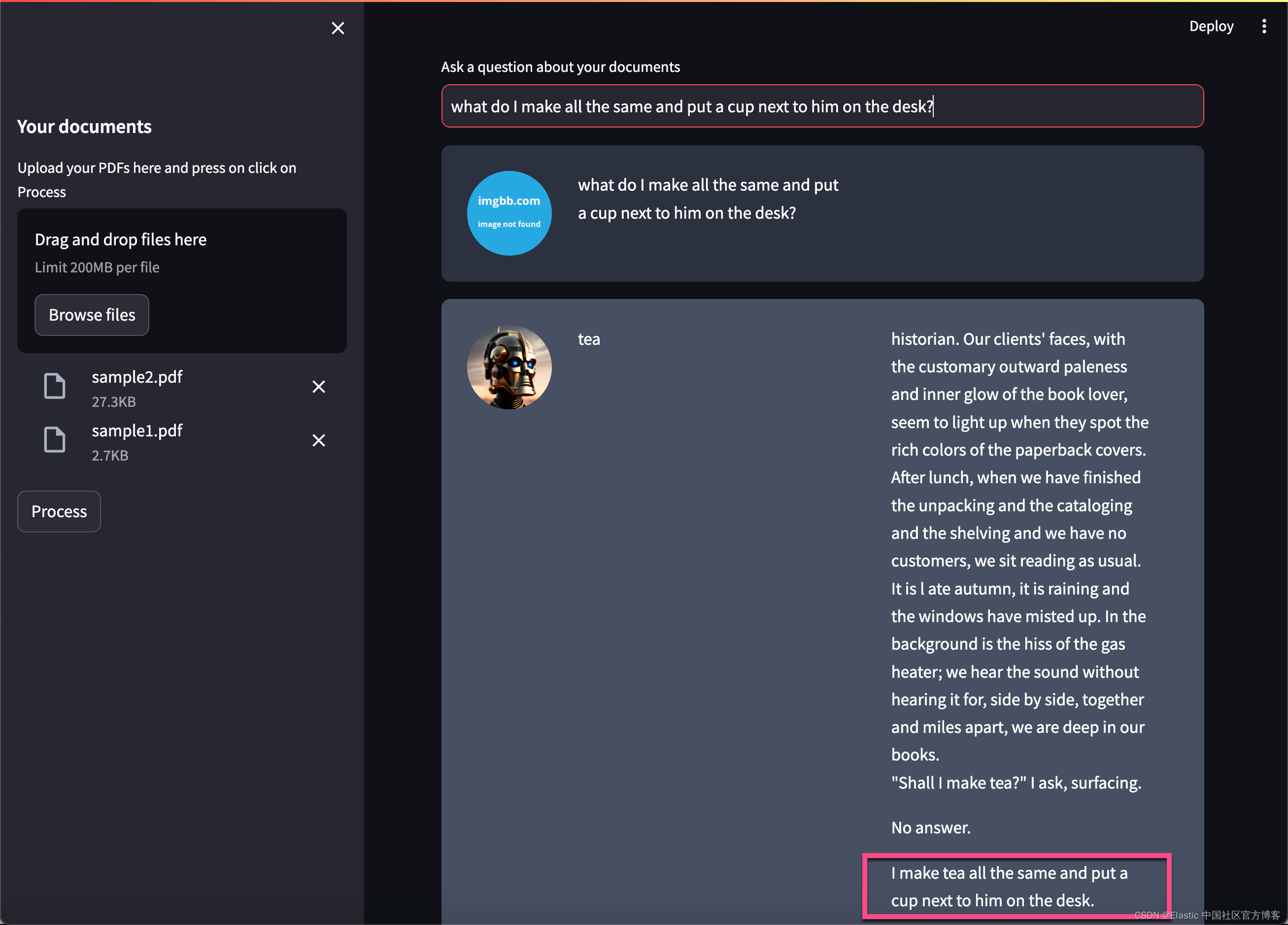
上面的问题是:
what do I make all the same and put a cup next to him on the desk?再进行提问:
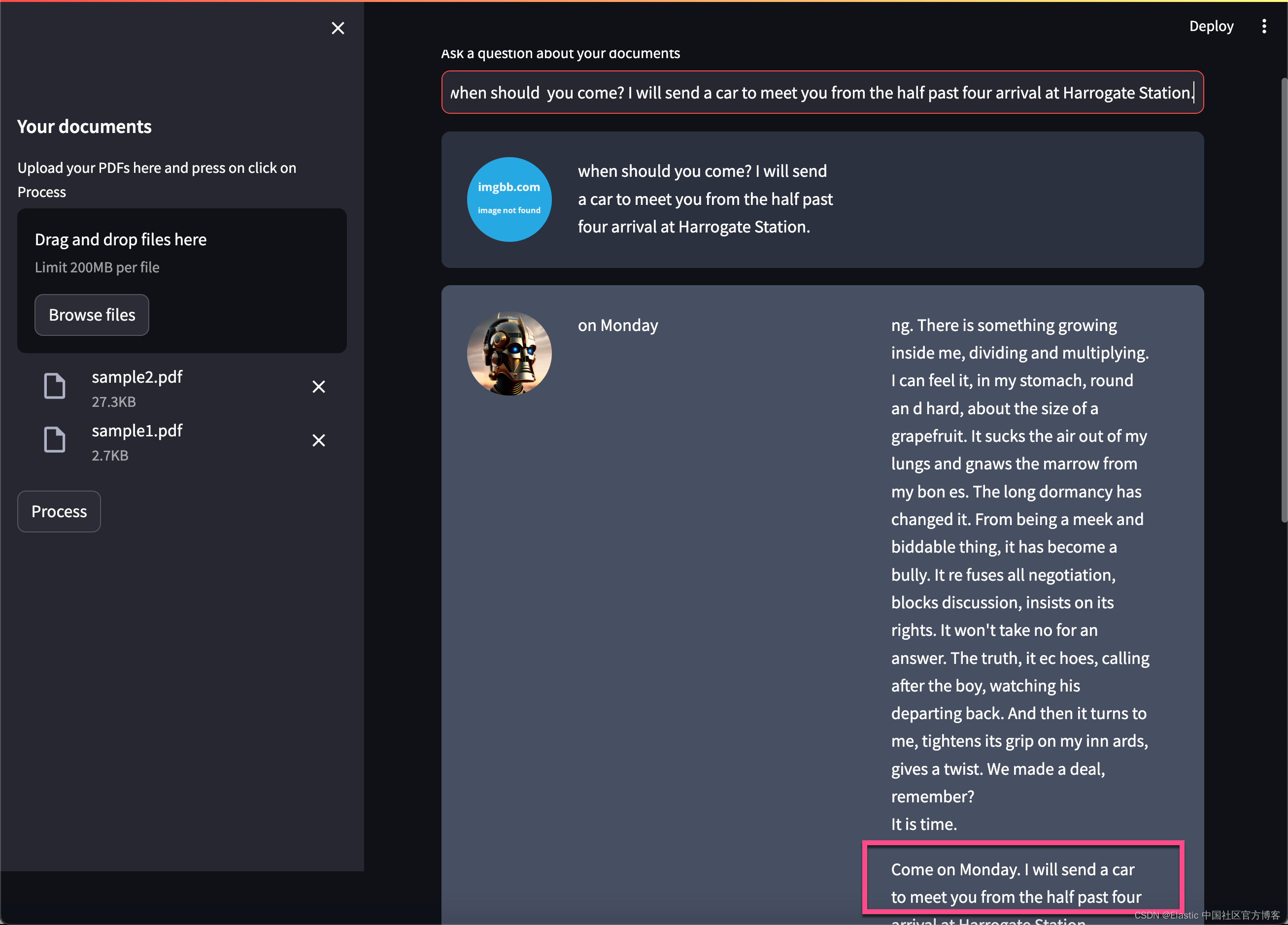
上面的问题是:
when should you come? I will send a car to meet you from the half past four arrival at Harrogate Station.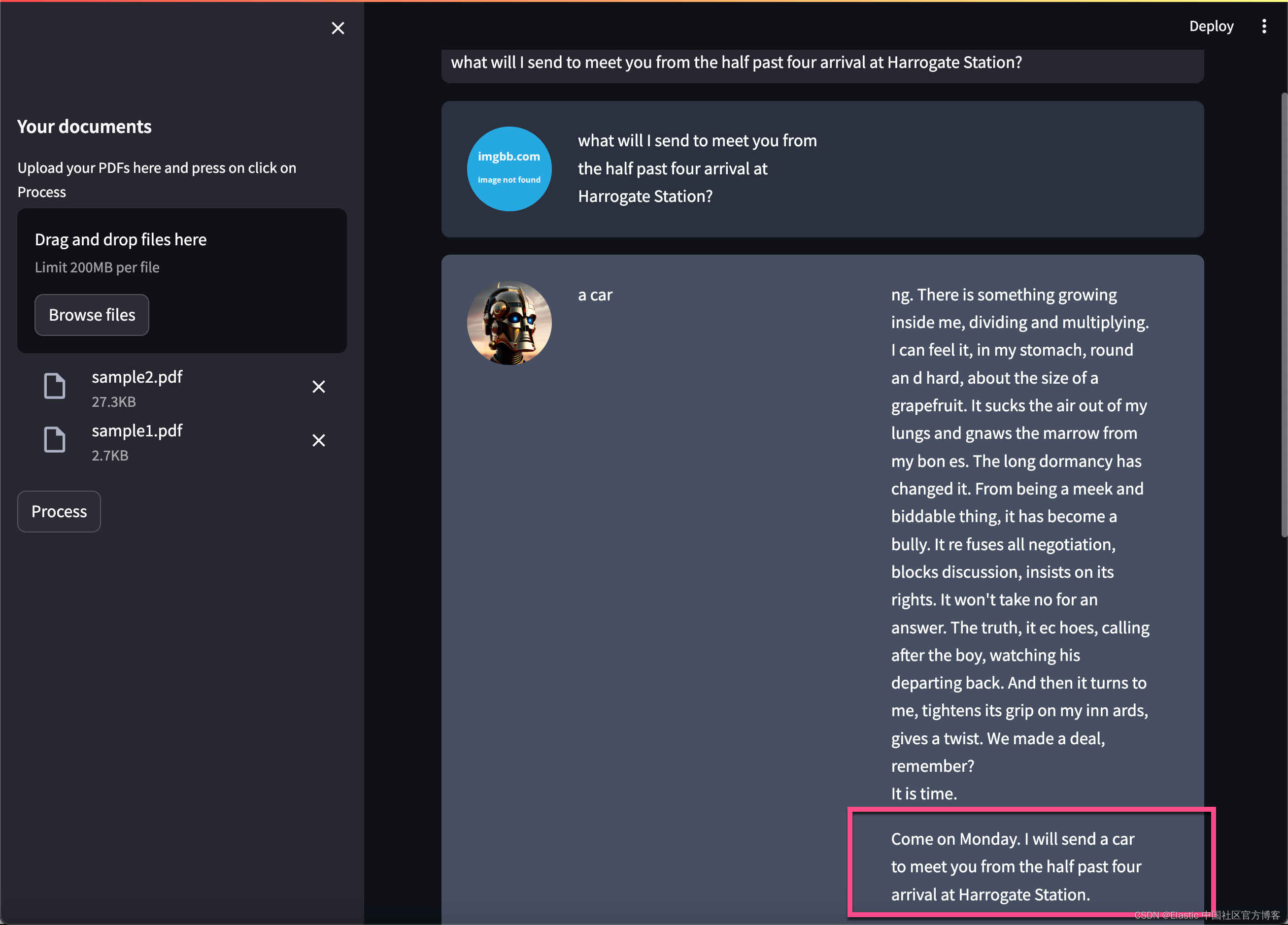
上面的问题是:
what will I send to meet you from the half past four arrival at Harrogate Station?你进行多次尝试其它的问题。Happy journery :)
有关 ChatGPT 的使用也是基本相同的。你需要使用 ChatGPT 的模型及其相应的 key 即可。在这里就不赘述了。
相关文章:
Elasticsearch:与多个 PDF 聊天 | LangChain Python 应用教程(免费 LLMs 和嵌入)
在本博客中,你将学习创建一个 LangChain 应用程序,以使用 ChatGPT API 和 Huggingface 语言模型与多个 PDF 文件聊天。 如上所示,我们在最最左边摄入 PDF 文件,并它们连成一起,并分为不同的 chunks。我们可以通过使用 …...

docker系列(7) - Dockerfile
文章目录 7. Dockerfile7.1 Dockerfile介绍7.2 指令规则7.3 指令说明7.3.1 RUN命令的两种格式7.3.1 CMD命令覆盖问题7.3.2 ENTRYPOINT命令使用7.3.3 ENV的使用 7.4 构建tomcat Dockerfile案例7.4.1 准备原始文件7.4.2 编写Dockerfile7.4.3 构建镜像7.4.4 验证镜像 7.5 构建jdk基…...

Spring面试题8:面试官:说一说Spring的BeanFactory
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:说一说Spring的BeanFactory Spring的BeanFactory是Spring框架的核心容器,负责管理和创建Bean对象。它是一个工厂类,用于实例化、配置和管理Bean的…...
Win10专业版系统一键重装怎么操作?
Win10专业版系统一键重装怎么操作?与传统的系统重装相比,一键重装不仅省去了繁琐的安装步骤,这一简单操作使得系统维护和恢复变得更加便捷,让用户不再为系统问题而烦恼。下面小编给大家详细介绍关于一键重装Win10专业版系统的操作…...
十大服装店收银系统有哪些 好用的服装收银软件推荐
服装店收银系统对于门店和服装卖场来说非常重要,可以提高工作效率。下面是推荐的十大服装店收银系统,供开设服装店的企业选择合适的收银软件用于经营管理。 1、核货宝收银系统 支持快速收银,同时适用于服装行业,能够支持多规格多…...
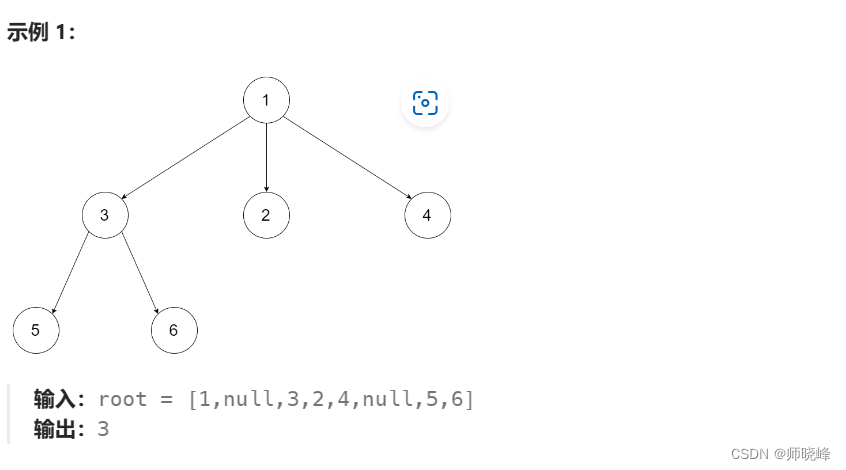
算法通过村第八关-树(深度优先)白银笔记|深度和高度问题
文章目录 前言1. 最大深度问题2. 判断平衡树3. 最小深度4. N叉树的最大深度总结 前言 提示:我的整个生命,只是一场为了提升社会地位的低俗斗争。--埃莱娜费兰特《失踪的孩子》 这一关我们看一些比较特别的题目,关于二叉树的深度和高度问题。这…...

Redis安装和使用
这里写目录标题 Redis安装和使用一.数据库类型1.关系型数据库2.非关系型数据库3.区别(1)数据存储方式不同(2)扩展方式不同(3)对事务性的支持不同 二.redis简介1.Redis 优点2.哪些数据适合放入缓存中&#x…...

UML基础与应用之面向对象
UML(Unified Modeling Language)是一种用于软件系统建模的标准化语言,它使用图形符号和文本来描述软件系统的结构、行为和交互。在面向对象编程中,UML被广泛应用于软件系统的设计和分析阶段。本文将总结UML基础与应用之面向对象的…...
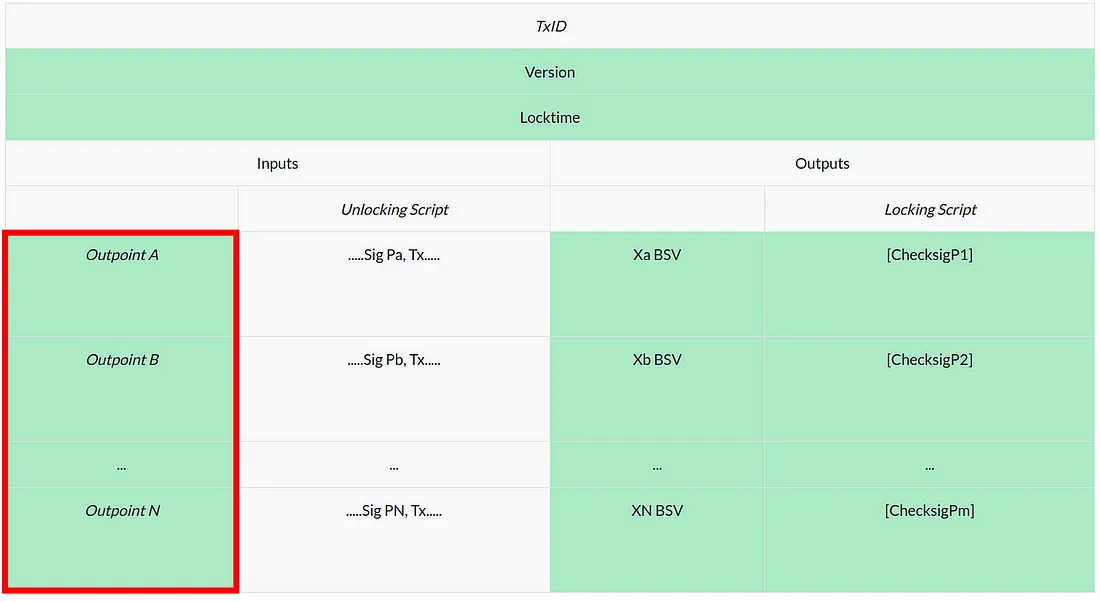
将 Ordinals 与比特币智能合约集成:第 2 部分
在上一篇文章中,我们展示了一种将 Ordinal 与智能合约集成的方法,即将Ordinal和合约放在同一个 UTXO 中。 今天,我们介绍了一种集成它们的替代方案,即它们位于单独的 UTXO 中。 作为展示,我们开发了一个智能合约&…...
)
PCL 法线空间采样(C++详细过程版)
法线空间采样 一、概述二、代码实现三、结果展示1、原始点云2、采样结果一、概述 法线空间采样在PCL里有现成的调用函数,具体算法原理和实现代码见:PCL 法线空间采样。为充分了解法线空间采样算法实现的每一个细节和有待改进的地方,使用C++代码对算法实现过程进行复现。 二…...

论文阅读:AugGAN: Cross Domain Adaptation with GAN-based Data Augmentation
Abstract 基于GAN的图像转换方法存在两个缺陷:保留图像目标和保持图像转换前后的一致性,这导致不能用它生成大量不同域的训练数据。论文提出了一种结构感知(Structure-aware)的图像转换网络(image-to-image translation network)。 Proposed Framework…...

CNC 3D浮雕 Aspire 11.55 Crack
Aspire 提供了功能强大且直观的软件解决方案,用于在 CNC 铣床上创建和切割零件。有用于 2D 设计和计算 2D 刀具路径的工具,例如仿形、型腔加工和钻孔以及 2.5D 刀具路径,包括:V 形雕刻、棱镜雕刻、成型刀具路径、凹槽、 倒角刀具路…...

【Clickhouse2022.02 查询优化】
一、现场场景概述 现场每天每张表入库数据量大约2-4亿条,页面涉及到自定义时间段查询(白天08:00-15:00,夜晚23:00-06:00)与不同时间段(最近一天、一周、一个月和全部)的统计指标查询。 二、主要问题 时间跨度大无查询或查询条件命中数据过多的分页查询场景速度慢 (主要是数据…...
PMP证书在国内已经泛滥了,还有含金量吗?
没有泛滥吧?这个证书现在就是趋向于项目管理人士要去考的呀,也不是考了没用,提升自身个人的能力、找工作方面和晋升加薪方面确实有用呀,不然报名费那么贵,为什么越来越多人考呢? 1、提升自身个人的能力 首…...

SolidJs节点级响应性
前言 随着组件化、响应式、虚拟DOM等技术思想引领着前端开发的潮流,相关的技术框架大行其道,就以目前主流的Vue、React框架来说,它们都基于组件化、响应式、虚拟DOM等技术思想的实现,但是具有不同开发使用方式以及实现原理&#…...
数据采集技术在MES管理系统中的应用及效果
在现代制造业中,MES生产管理系统已成为生产过程中不可或缺的一部分。MES管理系统能够有效地将生产计划、生产执行、质量管理等各个生产环节有机地衔接起来,从而实现生产过程的全面优化。本文将以某车间为例,探讨结合MES系统的数据采集技术的应…...
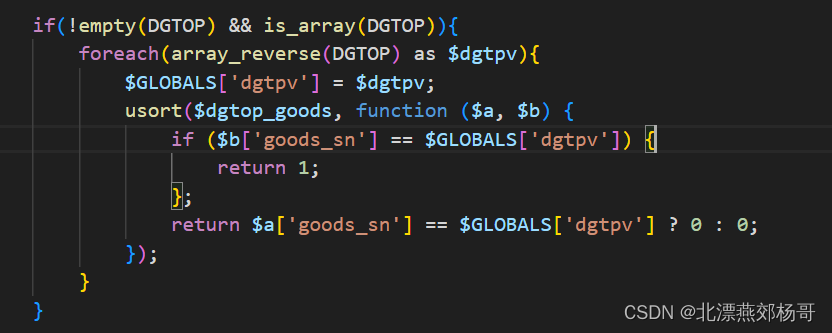
php函数usort使用方法
在 PHP 中,usort() 函数用于对数组进行排序,它允许你使用自定义的比较函数来确定元素的顺序。以下是 usort() 函数的使用方法: usort(array &$array, callable $cmp_function): bool参数说明: $array:要排序的数…...

35.浅谈贪心算法
概述 相信大家或多或少都对贪心算法有所耳闻,今天我们从一个应用场景展开 假设存在下面需要付费的广播台,以及广播台信号可以覆盖的地区。 如何选择最少的广播台,让所有的地区都可以接收到信号? 广播台覆盖地区k1北京、上海、天津…...
【QT基础入门 Demo篇】)
QT时间日期定时器类(1.QDate类)【QT基础入门 Demo篇】
使用时候需要包含头文件 创建一个 QDate 实例 设置 QDate 的日期 获取 QDate 的日期 获取当前是周几 判断 QDate 的有效性 格式化 QDate 的显示字符串 计算 QDate 的差值 QDate显示格式 年月日转换时间戳时间戳转换年月日 QDate相关…...
记一次实战案例
1、目标:inurl:news.php?id URL:https://www.lghk.com/news.php?id5 网站标题:趋时珠宝首饰有限公司 手工基础判断: And用法 and 11: 这个条件始终是为真的, 也就是说, 存在SQL注入的话, 这个and 11的返回结果必定是和正常页…...

免费专业速度跑计时工具LiveSplit:终极完整使用教程
免费专业速度跑计时工具LiveSplit:终极完整使用教程 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款为速度跑玩家设计的免费开源计时工具&#x…...

Unity 2D基础:Rigidbody2D刚体的运动控制
Unity 2D基础:Rigidbody2D刚体的运动控制📚 本章学习目标:深入理解Rigidbody2D刚体的运动控制的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《Unity工程师成长之路教程》Unity 2D基础篇…...

C51结构体内存分配限制与解决方案
1. C51结构体成员的内存空间限制解析在8051单片机开发中,C51编译器对结构体成员的内存分配有着严格限制。这个问题困扰过不少从标准C转向嵌入式开发的工程师。让我用一个实际案例来解释这个技术细节:struct sensor_data {float data temperature; // 试…...

KMS智能激活脚本:3分钟永久激活Windows和Office的终极指南
KMS智能激活脚本:3分钟永久激活Windows和Office的终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变…...

专业休闲卤味零食包装设计公司排名榜单盘点-哲仕设计上榜
专业休闲卤味零食包装设计公司排名榜单盘点-哲仕设计上榜休闲卤味零食属于大众刚需休闲食品,涵盖肉类卤制熟食、素菜卤味小吃、真空独立卤包、常温即食卤品、麻辣风干肉干、组合卤味礼盒等品类,广泛适用于居家休闲解馋、办公下午茶加餐、追剧娱乐食用、出…...

歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程
歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬(LRC Maker)是…...

【GitHub热门工具】TikTokDownloader深度体验:从零到一的抖音/TikTok视频下载实战
1. 为什么我们需要TikTokDownloader? 最近在社交媒体上看到一个超有趣的视频,想保存下来反复观看或者分享给朋友,却发现平台没有提供下载按钮?这种场景相信很多人都遇到过。TikTokDownloader就是为了解决这个痛点而生的开源工具&a…...

VolumetricLighting雾管理器系统:LightManagerFogLights与FogEllipsoid本地密度控制
VolumetricLighting雾管理器系统:LightManagerFogLights与FogEllipsoid本地密度控制 【免费下载链接】VolumetricLighting Lighting effects implemented for the Adam demo: volumetric fog, area lights and tube lights 项目地址: https://gitcode.com/gh_mirr…...

ETime:高效推动你的时间
我做了一个开源时间工作台:ETime 如果你也试过很多时间管理工具,可能会遇到同一种疲惫:记录本身变成了另一件需要坚持的事。 ETime 想解决的不是“怎样把每一分钟都管起来”,而是更朴素的一件事:让开始更轻ÿ…...

软件设计师下午题训练2-3题+2020下上午题错题解析 练习真题训练15
一、训练题2 1、2021上 (1) (2) a:团购点编号 b:客户电话 供货 主键 :(供货商编号,团购点编号) 外键:供货商编号、团购点编号 订单 主键:订单编号…...