rust字符串
标准库提供了String结构体表示字符串。
String实际上就是Vec<u8>的封装。唯一的不同是String的方法假定Vec<u8>中的二进制都是utf8编码的
pub struct String {vec: Vec<u8>,
}
一、定义String
1.使用new方法创建空字符串
let string = String::new();
2.使用from方法创建
let hello = String::from("Hello");
let hello = String::from("你好");
3.使用to_string方法创建
let one = 1.to_string(); // 整数到字符串
let float = 1.3.to_string(); // 浮点数到字符串
let slice = "hello".to_string(); // 字符串切片到字符串
4.使用format!宏
let s = format!("{}{}{}", 1, 'a', "bc");
二、使用String
因为String实现了Deref Target=str,所以String自动实现了str的所有方法。
(一)长度
有两个长度,字节数和字符数。
因为使用的utf8编码,所以一个字符可能有多个字节,所以字节数和字符数可能不相等。
1.字节数
len函数返回的是字节数
let s = "hello";
let len = s.len();
这里len的值是5。let s = "你好";
let len = s.len();
这里len的值是6。因为中文是UTF-8编码的,每个字符3个字节,所以长度为6。
2.字符数
想要获取字符数比较麻烦。先用chars()返回一个迭代器,然后再返回这个迭代器的长度。
chars
chars返回一个迭代器,元素类型是char。
例子
let s = "hello你好";
let len = s.chars().count();
这里len的值是7,因为一共有7个字符。
(二)获取字符
String不支持[]下标访问
为什么不支持呢?因为字符编码用的是utf8,一个字符占多个字节。而使用下标只能获得一个字节,显然这一个字节是不能代表字符的。
无效的Rust代码:
let hello = "你好";
let answer = &hello[0];
“你”是三个字节,而hello[0]只是一个字节,所以这是错误的。
那么该如何获取字符?
首先要明确获取字符还是字节。
1.获取字符,也就是char
(1)使用 chars 方法
获取单字符
先使用chars返回一个迭代器,然后使用迭代器的nth方法获取第n个字符,索引从0开始。
实例
fn main() {let s = String::from("EN中文");let a = s.chars().nth(2);println!("{:?}", a);
}
运行结果:
Some('中')
遍历所有字符
实例
fn main() {let s = String::from("hello中文");for c in s.chars() {println!("{}", c);}
}
(2)使用char_indices
返回一个迭代器,元素是(i, c),i是索引,c是字符。
例子
let word = "goodbye";
let count = word.char_indices().count();
assert_eq!(7, count);
let mut char_indices = word.char_indices();
assert_eq!(Some((0, 'g')), char_indices.next());
assert_eq!(Some((1, 'o')), char_indices.next());
assert_eq!(Some((2, 'o')), char_indices.next());
assert_eq!(Some((3, 'd')), char_indices.next());
assert_eq!(Some((4, 'b')), char_indices.next());
assert_eq!(Some((5, 'y')), char_indices.next());
assert_eq!(Some((6, 'e')), char_indices.next());
assert_eq!(None, char_indices.next());
for (i, c) in word.char_indices(){println!("{}", c);
}
2.获取字节,也就是u8
(1)使用 bytes 方法。
bytes
返回迭代器,元素是u8
例子
let s = String::from("你好");
let mut bytes = s.bytes();
for b in bytes {println!("{b}");
}
打印
228
189
160
229
165
189
(2)使用as_bytes
as_bytes
将String转换成&[u8]。
与此方法的相反的是from_utf8。
例子
let s = String::from("你好");
for i in s.as_bytes() {println!("{}", i);
}
(三)截取子串
1.通过字节位置截取
可以使用 [] 和一个range来创建含特定字节的字符串切片
实例
fn main() {let s = String::from("EN中文");let sub = &s[0..2];println!("{}", sub);
}
运行结果:
EN
使用这种方法截取时,必须保证字节位置是char的边界,否则会崩溃
实例
fn main() {let s = String::from("EN中文");let sub = &s[0..3]; //会崩溃println!("{}", sub);
}
2.通过字符位置截取
fn substr(s: &str, start: usize, length: usize) -> String {s.chars().skip(start).take(length).collect()
}
fn main() {let s1 = "中国-China";println!("{:?}", substr(s1, 1, 100));println!("{:?}", substr(s1, 0, 2));let s2 = String::from("中国-China");println!("{:?}", substr(&s2, 1, 100));println!("{:?}", substr(&s2, 0, 2));
}
(四)拼接
1.使用push追加char
let mut s = String::from("run");
s.push('!'); // 追加字符
2.使用push_str追加&str
let mut s = String::from("run");
s.push_str("oob"); // 追加字符串切片
3.用 + 号拼接String
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // 注意s1被移动了,不能继续使用
这个语法也可以拼接&str:
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;
4.使用format!宏
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{}-{}-{}", s1, s2, s3);
(五)插入
insert
在指定字节位置插入一个字符。
Panics
如果idx大于String的长度,或者它不在char边界上,就会出现panics。
例子
let mut s = String::with_capacity(3);
s.insert(0, 'f');
s.insert(1, 'o');
s.insert(2, 'o');
assert_eq!("foo", s);
insert_str
在指定字节位置处插入&str。
Panics
如果idx大于String的长度,或者它不在char边界上,就会出现panics。
例子
let mut s = String::from("bar");
s.insert_str(0, "foo");
assert_eq!("foobar", s);
(六)删除
truncate
将此String缩短为指定的字节长度。
如果new_len大于字符串的当前长度,则无效。
Panics
如果new_len不位于char边界上,就会出现panics。
例子
let mut s = String::from("hello");
s.truncate(2);
assert_eq!("he", s);
pop
删除最后一个字符并返回它。
如果String为空,则返回None。
例子
let mut s = String::from("foo");
assert_eq!(s.pop(), Some('o'));
assert_eq!(s.pop(), Some('o'));
assert_eq!(s.pop(), Some('f'));
assert_eq!(s.pop(), None);
remove
从指定字节位置删除char并将其返回。
Panics
如果idx大于或等于String的长度,或者它不位于char边界上,就会出现panics。
例子
let mut s = String::from("foo");
assert_eq!(s.remove(0), 'f');
assert_eq!(s.remove(1), 'o');
assert_eq!(s.remove(0), 'o');
retain
仅保留特定的字符。
换句话说,使f© 返回false,来删除所有字符c。
例子
let mut s = String::from("f_o_ob_ar");
s.retain(|c| c != '_');
assert_eq!(s, "foobar");
使用外部状态来确定要保留哪些元素。
let mut s = String::from("abcde");
let keep = [false, true, true, false, true];
let mut iter = keep.iter();
s.retain(|_| *iter.next().unwrap());
assert_eq!(s, "bce");
clear
删除所有内容。
虽然这意味着String的长度为零,但它并未触及其容量。
例子
let mut s = String::from("foo");
s.clear();
assert!(s.is_empty());
assert_eq!(0, s.len());
assert_eq!(3, s.capacity());
drain
批量删除指定范围,并以迭代器的形式返回所有删除的字符。
返回的迭代器在字符串上保留一个可变借用以优化其实现。
Panics
如果起始点或结束点不在char边界上,或超出边界,就会出现panic。
Leaking
如果返回的迭代器离开作用域而没有被丢弃 (例如,由于core::mem::forget),则字符串可能仍包含任何耗尽字符的副本,或者可能任意丢失字符,包括范围外的字符。
例子
let mut s = String::from("αis alpha, βis beta");
let beta_offset = s.find('β').unwrap_or(s.len());
// 删除范围直到字符串中的 β
let t: String = s.drain(..beta_offset).collect();
assert_eq!(t, "αis alpha, ");
assert_eq!(s, "βis beta");
// 全范围清除字符串,就像 `clear()` 一样
s.drain(..);
assert_eq!(s, "");
trim
返回除去前导和尾随空格的字符串切片。
‘Whitespace’ 是根据Unicode派生的核心属性White_Space的术语定义的,该属性包括换行符。
例子
let s = "\n Hello\tworld\t\n";
assert_eq!("Hello\tworld", s.trim());
trim_start
返回除去前导空格的字符串切片。
‘Whitespace’ 是根据Unicode派生的核心属性White_Space的术语定义的,该属性包括换行符。
文字方向性
字符串是字节序列。start在此上下文中表示该字节字符串的第一个位置; 对于从左到右的语言 (例如英语或俄语),这将是左侧; 对于从右到左的语言 (例如阿拉伯语或希伯来语),这将是右侧。
例子
let s = "\n Hello\tworld\t\n";
assert_eq!("Hello\tworld\t\n", s.trim_start());
Directionality:
let s = " English ";
assert!(Some('E') == s.trim_start().chars().next());
let s = " עברית ";
assert!(Some('ע') == s.trim_start().chars().next());
trim_end
返回除去尾随空格的字符串切片。
‘Whitespace’ 是根据Unicode派生的核心属性White_Space的术语定义的,该属性包括换行符。
文字方向性
字符串是字节序列。end在此上下文中表示该字节字符串的最后位置; 对于从左到右的语言 (例如英语或俄语),这将在右侧; 对于从右到左的语言 (例如阿拉伯语或希伯来语),将在左侧。
例子
let s = "\n Hello\tworld\t\n";
assert_eq!("\n Hello\tworld", s.trim_end());
Directionality:
let s = " English ";
assert!(Some('h') == s.trim_end().chars().rev().next());
let s = " עברית ";
assert!(Some('ת') == s.trim_end().chars().rev().next());
(七)转换
as_str
将String转换为&str。
例子
let s = String::from("foo");
assert_eq!("foo", s.as_str());
as_mut_str
将String转换为&mut str。
例子
let mut s = String::from("foobar");
let s_mut_str = s.as_mut_str();
s_mut_str.make_ascii_uppercase();
assert_eq!("FOOBAR", s_mut_str);
parse
将此字符串切片解析为另一种类型。
由于parse非常通用,因此可能导致类型推断问题。需要指定类型或使用turbofish语法
parse可以解析为任何实现FromStr trait的类型。
Errors
如果无法将此字符串切片解析为所需的类型,则将返回Err。
例子
let four: u32 = "4".parse().unwrap();
assert_eq!(4, four);
使用turbofish
let four = "4".parse::<u32>();
assert_eq!(Ok(4), four);
无法解析:
let nope = "j".parse::<u32>();
assert!(nope.is_err());
(八)替换
replace_range
删除字符串中的指定字节范围,并将其替换为给定的字符串。
Panics
如果起始点或结束点不在char边界上,或超出边界,就会出现panic。
例子
let mut s = String::from("αis alpha, βis beta");
let beta_offset = s.find('β').unwrap_or(s.len());
// 替换范围直到字符串中的 β
s.replace_range(..beta_offset, "Αis capital alpha; ");
assert_eq!(s, "Αis capital alpha; βis beta");
replace
用另一个字符串替换模式的所有匹配项。
例子
let s = "this is old";
assert_eq!("this is new", s.replace("old", "new"));
assert_eq!("than an old", s.replace("is", "an"));
当模式不匹配时,它将此字符串切片作为String返回:
let s = "this is old";
assert_eq!(s, s.replace("cookie monster", "little lamb"));
replacen
用另一个字符串替换模式的前N个匹配项
例子
let s = "foo foo 123 foo";
assert_eq!("new new 123 foo", s.replacen("foo", "new", 2));
assert_eq!("faa fao 123 foo", s.replacen('o', "a", 3));
assert_eq!("foo foo new23 foo", s.replacen(char::is_numeric, "new", 1));
当模式不匹配时,它将此字符串切片作为String返回:
let s = "this is old";
assert_eq!(s, s.replacen("cookie monster", "little lamb", 10));
(九)分割
split_off
在给定的字节索引处将字符串拆分为两个。
返回新分配的String。self包含字节 [0, at),返回的String包含字节 [at, len)。at必须位于UTF-8代码点的边界上。
请注意,self的容量不会改变。
Panics
如果at不在UTF-8代码点边界上,或者它超出字符串的最后一个代码点,就会出现panics。
例子
let mut hello = String::from("Hello, World!");
let world = hello.split_off(7);
assert_eq!(hello, "Hello, ");
assert_eq!(world, "World!");
split_whitespace
用空格分割字符串切片。
返回的迭代器将返回作为原始字符串切片的子切片的字符串切片,并以任意数量的空格分隔。
‘Whitespace’ 是根据Unicode派生核心属性White_Space的条款定义的。 如果只想在ASCII空格上分割,请使用split_ascii_whitespace。
例子
let mut iter = "A few words".split_whitespace();
assert_eq!(Some("A"), iter.next());
assert_eq!(Some("few"), iter.next());
assert_eq!(Some("words"), iter.next());
assert_eq!(None, iter.next());
考虑所有类型的空白:
let mut iter = " Mary had\ta\u{2009}little \n\t lamb".split_whitespace();
assert_eq!(Some("Mary"), iter.next());
assert_eq!(Some("had"), iter.next());
assert_eq!(Some("a"), iter.next());
assert_eq!(Some("little"), iter.next());
assert_eq!(Some("lamb"), iter.next());
assert_eq!(None, iter.next());
如果字符串为空或全为空白,则迭代器不产生字符串切片:
assert_eq!("".split_whitespace().next(), None);
assert_eq!(" ".split_whitespace().next(), None);
split_ascii_whitespace
用ASCII空格分割字符串切片。
返回的迭代器将返回作为原始字符串切片的子切片的字符串切片,并以任意数量的ASCII空格分隔。
要改为按Unicode Whitespace进行拆分,请使用split_whitespace。
例子
let mut iter = "A few words".split_ascii_whitespace();
assert_eq!(Some("A"), iter.next());
assert_eq!(Some("few"), iter.next());
assert_eq!(Some("words"), iter.next());
assert_eq!(None, iter.next());
考虑所有类型的ASCII空白:
let mut iter = " Mary had\ta little \n\t lamb".split_ascii_whitespace();
assert_eq!(Some("Mary"), iter.next());
assert_eq!(Some("had"), iter.next());
assert_eq!(Some("a"), iter.next());
assert_eq!(Some("little"), iter.next());
assert_eq!(Some("lamb"), iter.next());
assert_eq!(None, iter.next());
如果字符串为空或全部为ASCII空格,则迭代器不产生字符串切片:
assert_eq!("".split_ascii_whitespace().next(), None);
assert_eq!(" ".split_ascii_whitespace().next(), None);
(十)contains
如果包含模式,则返回true。否则返回false。
模式 可以是 &str,char,&[char],也可以是确定字符是否匹配的函数或闭包。
例子
let bananas = "bananas";
assert!(bananas.contains("nana"));
assert!(!bananas.contains("apples"));
starts_with
如果以模式开头,则返回true。否则返回false。
模式 可以是 &str,char,&[char],也可以是确定字符是否匹配的函数或闭包。
例子
let bananas = "bananas";
assert!(bananas.starts_with("bana"));
assert!(!bananas.starts_with("nana"));
ends_with
如果模式结尾,则返回true。否则返回false。
模式 可以是 &str,char,&[char],也可以是确定字符是否匹配的函数或闭包。
例子
let bananas = "bananas";
assert!(bananas.ends_with("anas"));
assert!(!bananas.ends_with("nana"));
(十一)其他
is_empty
如果此String的长度为零,则返回true,否则返回false。
let mut v = String::new();
assert!(v.is_empty());
v.push('a');
assert!(!v.is_empty());
lines
返回一个迭代器,迭代器元素是&str。
行以\n或\r\n结尾。最后一行的结尾是可选的。
迭代器返回的行中会去掉\n或\r\n。
例子
let text = "foo\r\nbar\n\nbaz\n";
let mut lines = text.lines();
assert_eq!(Some("foo"), lines.next());
assert_eq!(Some("bar"), lines.next());
assert_eq!(Some(""), lines.next());
assert_eq!(Some("baz"), lines.next());
assert_eq!(None, lines.next());let text = "foo\nbar\n\r\nbaz";
let mut lines = text.lines();
assert_eq!(Some("foo"), lines.next());
assert_eq!(Some("bar"), lines.next());
assert_eq!(Some(""), lines.next());
assert_eq!(Some("baz"), lines.next());
assert_eq!(None, lines.next());
相关文章:

rust字符串
标准库提供了String结构体表示字符串。 String实际上就是Vec<u8>的封装。唯一的不同是String的方法假定Vec<u8>中的二进制都是utf8编码的 pub struct String {vec: Vec<u8>, }一、定义String 1.使用new方法创建空字符串 let string String::new();2.使用…...

解析-BeautifulSoup
解析-BeautifulSoup 1.基本简介 1.BeautifulSoup简称:bs4 2.什么是Beatifulsoup?Beautifulsoup,和1xm1一样,是一个html的解析器,主要功能也是解析和提取数据 3.优缺点?缺点: 效率没有1xm1的效率高优点: 接口设计人性化,使用方…...

C++:数组
C中的数组是一种用于存储相同数据类型的元素的数据结构。以下是C数组的一些特点: 固定大小:数组在创建时需要指定其大小,而且无法在运行时改变大小。这意味着一旦数组被创建,其大小就是固定的,除非创建一个新的数组。 …...

结合Mockjs与Bus事件总线搭建首页导航和左侧菜单
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《ELement》。🎯🎯 …...

模拟桌面自动整理, 先顶左,再顶上。
5 6 **##** ****#* ***##* #***** ***#** ##**** ##**** #***** #***** #***** #include<iostream> using namespace std; #define MAX 1024char a[MAX][MAX]; void H(char arr[][MAX], int n,int idx) {//n列数 ,idx 某行int left 0;int right n - 1;char t;while (…...

新增MariaDB数据库管理、支持多版本MySQL数据库共存,1Panel开源面板v1.6.0发布
2023年9月18日,现代化、开源的Linux服务器运维管理面板1Panel正式发布v1.6.0版本。 在这个版本中,1Panel新增MariaDB数据库管理;支持多版本MySQL数据库共存;支持定时备份系统快照和应用商店中已安装应用;支持为防火墙…...
【dbeaver】win环境的kerberos认证和Clouders集群中Kerberos认证使用Dbeaver连接Hive和Phoenix
一、下载驱动 cloudera官网 1.1 官网页面下载 下载页面 的Database Drivers 挑选比较新的版本即可。 1.2 集群下载 Hive可能集群没有驱动包。驱动包名称:HiveJDBC42.jar。41结尾的包也可以使用的。注意Jar包的大小一定是十几MB的。几百KB的是thin包不可用。 …...
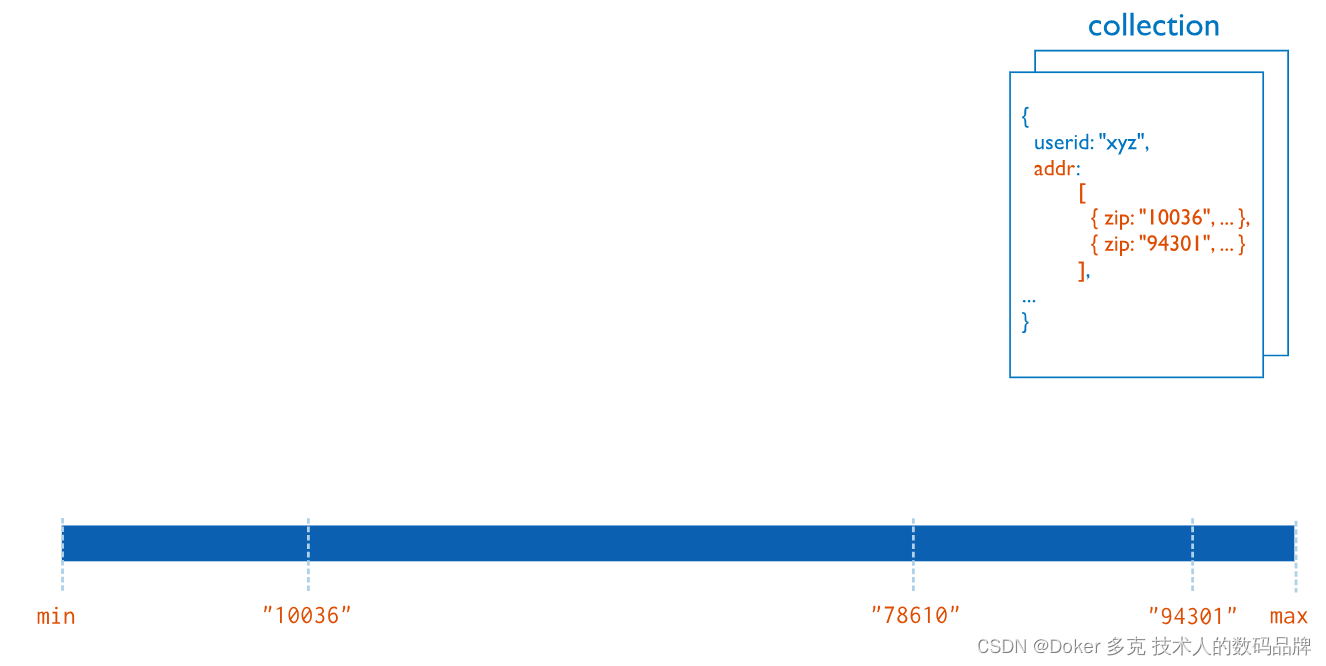
MongoDB索引
索引支持在MongoDB中高效执行查询。如果没有索引,MongoDB必须扫描集合中的每个文档才能返回查询结果。如果查询存在适当的索引,MongoDB将使用该索引来限制它必须扫描的文档数。 尽管索引提高了查询性能,但添加索引对写入操作的性能有负面影响…...

ChatGPT的问世给哪些行业带来了冲击?
目录 引言Chat GPT 对行业的影响在线客服和智能客服行业传统自动回复机器人的局限性Chat GPT 的提升能力 教育培训行业个性化学习需求的挑战Chat GPT 的个性化优势 金融保险行业客户服务的变革Chat GPT 的智能化应用 医疗健康领域自助诊断及咨询的便利性Chat GPT 在医疗领域的应…...
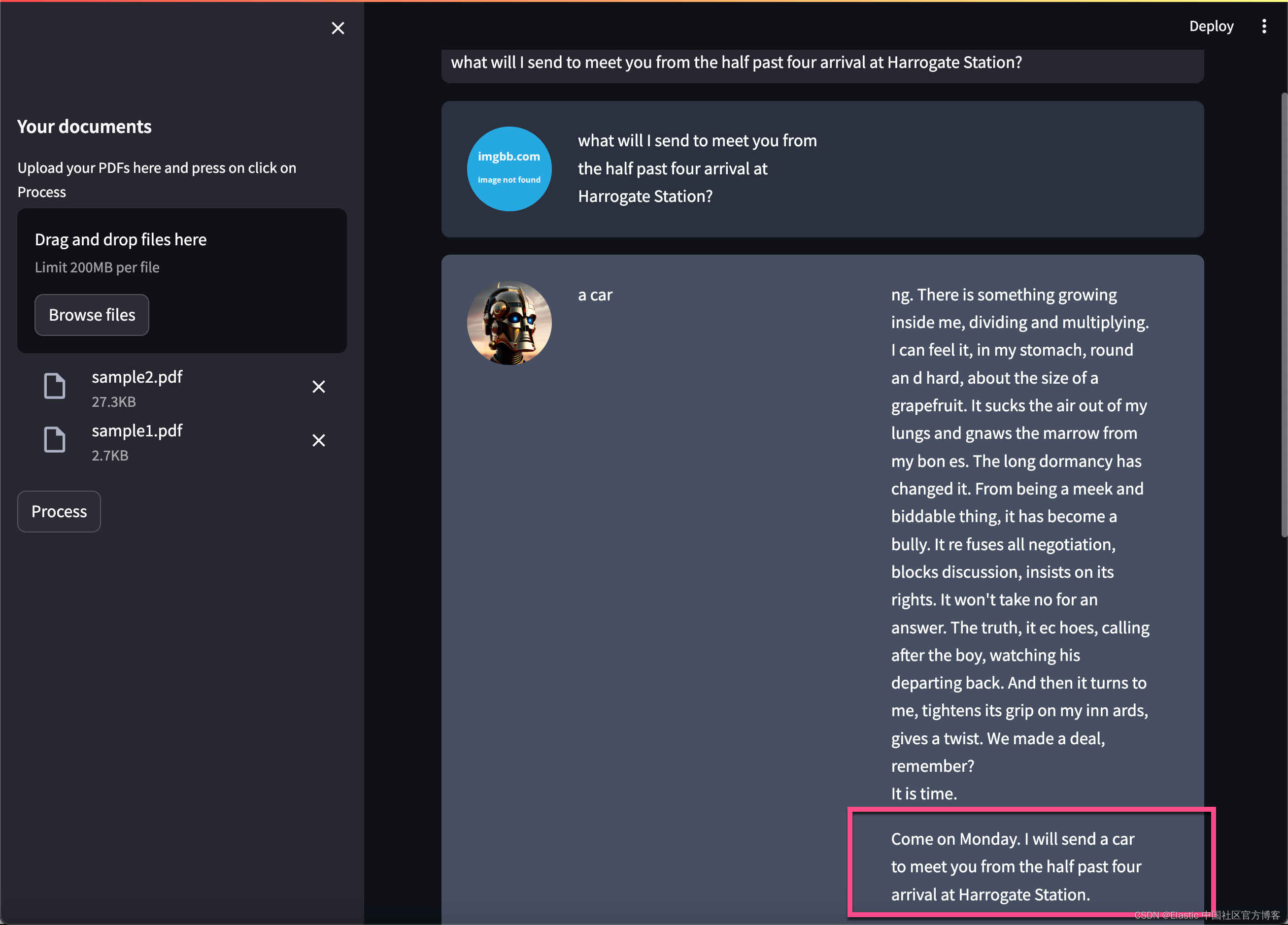
Elasticsearch:与多个 PDF 聊天 | LangChain Python 应用教程(免费 LLMs 和嵌入)
在本博客中,你将学习创建一个 LangChain 应用程序,以使用 ChatGPT API 和 Huggingface 语言模型与多个 PDF 文件聊天。 如上所示,我们在最最左边摄入 PDF 文件,并它们连成一起,并分为不同的 chunks。我们可以通过使用 …...

docker系列(7) - Dockerfile
文章目录 7. Dockerfile7.1 Dockerfile介绍7.2 指令规则7.3 指令说明7.3.1 RUN命令的两种格式7.3.1 CMD命令覆盖问题7.3.2 ENTRYPOINT命令使用7.3.3 ENV的使用 7.4 构建tomcat Dockerfile案例7.4.1 准备原始文件7.4.2 编写Dockerfile7.4.3 构建镜像7.4.4 验证镜像 7.5 构建jdk基…...

Spring面试题8:面试官:说一说Spring的BeanFactory
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:说一说Spring的BeanFactory Spring的BeanFactory是Spring框架的核心容器,负责管理和创建Bean对象。它是一个工厂类,用于实例化、配置和管理Bean的…...
Win10专业版系统一键重装怎么操作?
Win10专业版系统一键重装怎么操作?与传统的系统重装相比,一键重装不仅省去了繁琐的安装步骤,这一简单操作使得系统维护和恢复变得更加便捷,让用户不再为系统问题而烦恼。下面小编给大家详细介绍关于一键重装Win10专业版系统的操作…...
十大服装店收银系统有哪些 好用的服装收银软件推荐
服装店收银系统对于门店和服装卖场来说非常重要,可以提高工作效率。下面是推荐的十大服装店收银系统,供开设服装店的企业选择合适的收银软件用于经营管理。 1、核货宝收银系统 支持快速收银,同时适用于服装行业,能够支持多规格多…...
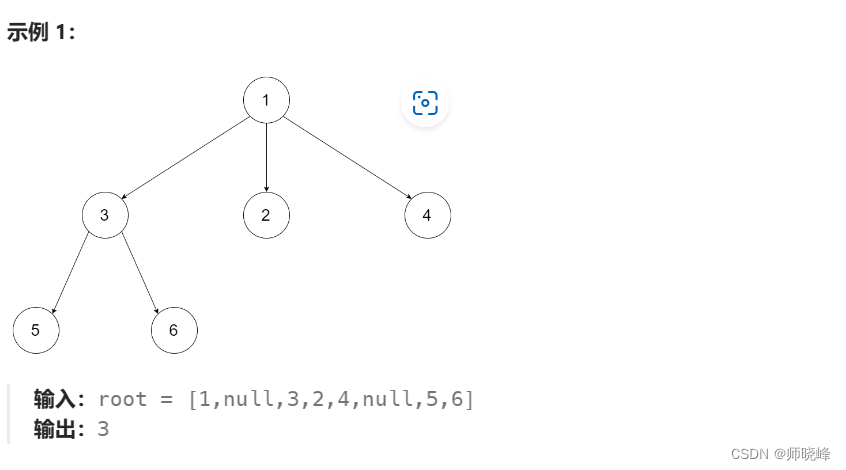
算法通过村第八关-树(深度优先)白银笔记|深度和高度问题
文章目录 前言1. 最大深度问题2. 判断平衡树3. 最小深度4. N叉树的最大深度总结 前言 提示:我的整个生命,只是一场为了提升社会地位的低俗斗争。--埃莱娜费兰特《失踪的孩子》 这一关我们看一些比较特别的题目,关于二叉树的深度和高度问题。这…...

Redis安装和使用
这里写目录标题 Redis安装和使用一.数据库类型1.关系型数据库2.非关系型数据库3.区别(1)数据存储方式不同(2)扩展方式不同(3)对事务性的支持不同 二.redis简介1.Redis 优点2.哪些数据适合放入缓存中&#x…...

UML基础与应用之面向对象
UML(Unified Modeling Language)是一种用于软件系统建模的标准化语言,它使用图形符号和文本来描述软件系统的结构、行为和交互。在面向对象编程中,UML被广泛应用于软件系统的设计和分析阶段。本文将总结UML基础与应用之面向对象的…...
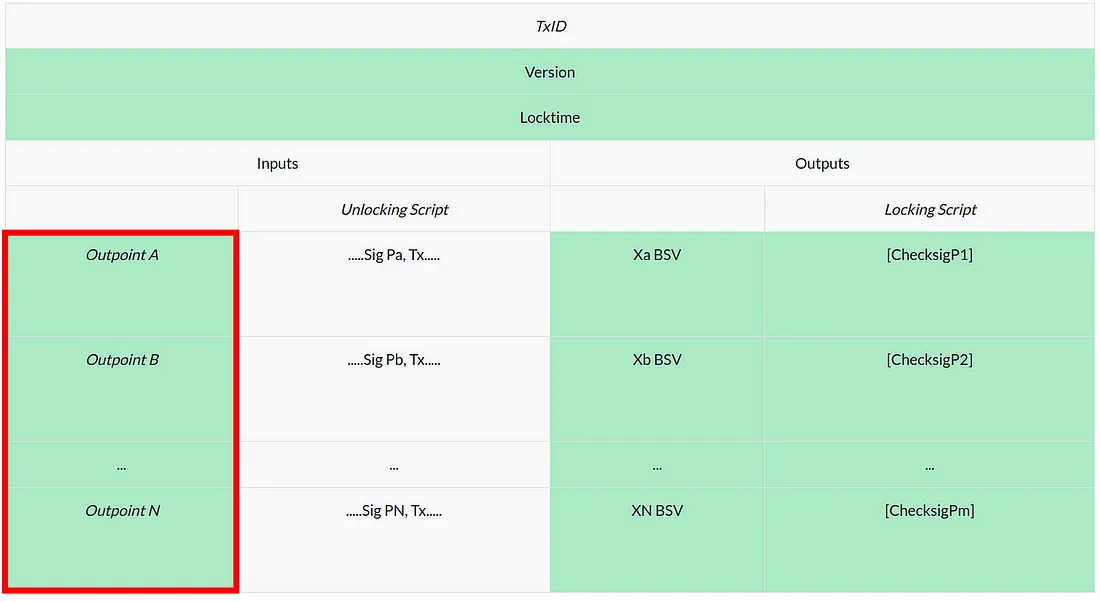
将 Ordinals 与比特币智能合约集成:第 2 部分
在上一篇文章中,我们展示了一种将 Ordinal 与智能合约集成的方法,即将Ordinal和合约放在同一个 UTXO 中。 今天,我们介绍了一种集成它们的替代方案,即它们位于单独的 UTXO 中。 作为展示,我们开发了一个智能合约&…...
)
PCL 法线空间采样(C++详细过程版)
法线空间采样 一、概述二、代码实现三、结果展示1、原始点云2、采样结果一、概述 法线空间采样在PCL里有现成的调用函数,具体算法原理和实现代码见:PCL 法线空间采样。为充分了解法线空间采样算法实现的每一个细节和有待改进的地方,使用C++代码对算法实现过程进行复现。 二…...

论文阅读:AugGAN: Cross Domain Adaptation with GAN-based Data Augmentation
Abstract 基于GAN的图像转换方法存在两个缺陷:保留图像目标和保持图像转换前后的一致性,这导致不能用它生成大量不同域的训练数据。论文提出了一种结构感知(Structure-aware)的图像转换网络(image-to-image translation network)。 Proposed Framework…...
)
Ubuntu 22.04 下 Nsight System/Compute 2023.3 保姆级安装与权限配置指南(解决libxcb/perf_event报错)
Ubuntu 22.04 下 Nsight System/Compute 2023.3 保姆级安装与权限配置指南 在深度学习与高性能计算领域,NVIDIA的Nsight工具套件是开发者不可或缺的性能分析利器。本文将手把手带你完成Ubuntu 22.04系统上最新版Nsight System 2023.3和Nsight Compute 2023.2的完整…...

告别COM Server!用Python+UDP给CANoe CAPL脚本开个“外挂”
突破CAPL封闭性:Python与CANoe的轻量级UDP通信实战 在汽车电子测试领域,CANoe作为行业标准工具,其内置的CAPL脚本语言为测试工程师提供了强大的自动化能力。然而,当我们需要将外部复杂算法(如机器学习模型)…...

终极免费方案:3分钟掌握Ofd2Pdf轻松转换OFD为PDF
终极免费方案:3分钟掌握Ofd2Pdf轻松转换OFD为PDF 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf 还在为OFD文件无法打开而烦恼吗?Ofd2Pdf是一款完全免费、简单易用的开源工具&…...

如何在Windows 11上免费安装安卓子系统:3步快速搭建跨平台应用中心
如何在Windows 11上免费安装安卓子系统:3步快速搭建跨平台应用中心 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 想在Windows电脑上无缝运行手…...
)
STM32F030 HAL库驱动W25Q16实战:从数据手册到SPI读写代码(附避坑指南)
STM32F030 HAL库驱动W25Q16实战:从数据手册到SPI读写代码(附避坑指南) 1. 理解W25Q16存储芯片的核心特性 W25Q16作为一款16Mbit容量的SPI Flash存储器,在嵌入式系统中扮演着重要角色。这款芯片采用标准的SPI接口,支持单…...

告别mmWaveStudio卡顿:手把手教你用DCA1000EVM CLI命令行录制IWR1642雷达数据
告别mmWaveStudio卡顿:手把手教你用DCA1000EVM CLI命令行录制IWR1642雷达数据 在雷达信号处理领域,数据采集的稳定性和效率直接影响后续算法开发的效果。传统图形界面工具mmWaveStudio虽然功能全面,但在长时间连续采集时容易出现卡顿、崩溃等…...

Perplexity不是越低越好!资深NLP架构师亲授:3类典型查询场景下的阈值黄金区间
更多请点击: https://kaifayun.com 第一章:Perplexity不是越低越好!资深NLP架构师亲授:3类典型查询场景下的阈值黄金区间 Perplexity(困惑度)常被误认为语言模型性能的“万能标尺”,但实际部署…...

2026年支持人民币计价的金价追踪APP有哪些
家人们谁懂啊!上周我发小蹲了3个月的50克古法金镯子终于下手,结账的时候才傻了眼:她之前用来盯金价的APP默认是美元离岸价,自己换算的时候忘了算汇率差和国内基础金价的浮动,预估的总价和实际付款差了快1800࿰…...
)
树莓派I2C保姆级教程:从命令行工具到Python脚本,一次搞定多个传感器(附避坑指南)
树莓派I2C实战指南:从硬件调试到Python自动化控制 第一次接触树莓派的I2C接口时,我对着密密麻麻的引脚和传感器数据手册发呆了半小时。直到成功读取到第一个温湿度数据,才意识到I2C这种看似复杂的通信协议,其实就像一位耐心的翻译…...

告别显示器!用VNC Viewer远程玩转树莓派4B的完整配置指南
无显示器玩转树莓派4B:VNC远程配置全攻略 当你刚拿到树莓派4B时,第一反应可能是找显示器、键盘鼠标来配置它。但现实情况往往是:手边没有多余的显示设备,或者你希望将树莓派作为服务器长期运行,根本不需要连接显示器。…...