关于ClickHouse的表引擎和SQL操作
目录
前言:
一.表引擎 (严格区分大小写)
1.TinyLog引擎
2.Memory
3.MergeTree
二.Sql操作
clickhouse 和 mysql 的比较
1 create
2 Insert
3 Update 和 Delete
前言:
在学习使用clickhouse时,首先就要先认识它的一大特点就是表引擎(在创建表时使用)。
表引擎是ClickHouse中用于存储和管理数据的一种技术,它定义了ClickHouse如何组织数据以及如何处理数据的方式。表引擎是ClickHouse的一个关键特性,因为它允许用户选择适合其数据需求的最佳存储方案。
不同的表引擎提供不同的功能和优缺点,用户可以根据其数据类型和使用情况选择最适合自己的表引擎。
例如,
针对日志类型的数据,ClickHouse的默认表引擎MergeTree可以提供更好的性能和扩展性;而针对时间序列数据,AggregatingMergeTree和SummingMergeTree则提供了更好的聚合计算功能。
表引擎可以帮助提高查询性能、节约存储空间、优化数据分区和满足不同数据类型的处理需求。ClickHouse的表引擎是其高性能和可扩展性的核心,因此选择合适的表引擎对于提高ClickHouse的性能和效率至关重要。
常用表引擎:
TinyLog 不支持索引
Memory 内存引擎
MergeTree 最强大的表引擎,支持索引和分区
一.表引擎 (严格区分大小写)
1.TinyLog引擎
TinyLog引擎 TinyLog是ClickHouse的一种表引擎,它提供了一种简单的方式来存储数据,并且能够支持高并发的写入操作。TinyLog表引擎将数据存储在磁盘上,并且支持压缩。TinyLog引擎可以用于存储实时数据流,或者用于在ClickHouse数据仓库中进行快速的筛选和排序操作。下面是使用TinyLog引擎的案例说明:
创建表并使用TinyLog引擎:
CREATE TABLE tinylog_example (id UInt32,name String,age UInt8
) ENGINE = TinyLog;
2.Memory
Memory引擎 Memory引擎是ClickHouse中非常常用的引擎之一,它将数据存储在RAM中,因此非常适用于需要快速处理的数据。Memory引擎不支持压缩,因此对于大量数据的存储和处理,它并不是最佳选择。下面是使用Memory引擎的案例说明:
创建表并使用Memory引擎:
CREATE TABLE memory_example (id UInt32,name String,age UInt8
) ENGINE = Memory;
3.MergeTree
MergeTree引擎 MergeTree是ClickHouse中最常用的引擎之一,它是一种支持分区和索引的表引擎,它使用了一种基于时间的分区方式,可以快速地进行数据查询和统计。MergeTree引擎支持多种类型的索引,例如BloomFilter和RangeIndex,可以快速地过滤和查找数据。下面是使用MergeTree引擎的案例说明:
创建表并使用MergeTree引擎:
CREATE TABLE mergetree_example (id UInt32,name String,age UInt8
) ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(created_at)
ORDER BY (created_at, id)
SETTINGS index_granularity = 8192;
注意:
partition by : 分区(可选)
order by : 排序(必选)
primary ky : 主键(可选)
二.Sql操作
clickhouse 和 mysql 的比较
共同点:
- 都是关系型数据库,支持SQL查询语言;
- 支持事务处理,具备 ACID 特性(原子性、一致性、隔离性、持久性);
- 可以使用索引来提高查询效率;
- 支持备份和恢复数据。
优点:
ClickHouse:
- 面向列的存储模式,在 OLAP 场景下查询速度更快;
- 支持高并发和大规模数据的处理;
- 可以快速地处理复杂的数据分析和聚合操作;
- 支持分布式部署。
MySQL:
- 支持 OLTP 场景下的高并发,适用于在线事务处理;
- 支持多种存储引擎,可以根据不同场景选择不同的存储引擎;
- 支持主从复制和集群部署;
- 有丰富的社区支持,应用广泛
1 create
在 ClickHouse 中创建表的 SQL 语句与 MySQL 类似,但是需要指定引擎类型,例如,使用 MergeTree 引擎存储数据:
CREATE TABLE example_table (column1 String,column2 Int32,column3 Float64
) ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(column3)
ORDER BY (column1, column2);解释:
example_table是表名;column1、column2、column3是表中的列名;String、Int32、Float64是列的数据类型;ENGINE指定了使用 MergeTree 引擎存储数据(还有TinyLog 和 memory)PARTITION BY根据日期分区,partition key 为 column3;ORDER BY指定了排序规则,按照 column1 和 column2 排序。
2 Insert
1.标准 INSERT
INSERT INTO example_table(column1, column2, column3)
VALUES ('value1', 123, 1.23), ('value2', 456, 4.56);
解释:
example_table是要插入数据的表名;column1、column2、column3是表中的列名;VALUES后跟着要插入的数据,多条数据用逗号分隔2
2 2.从表到表的插入
INSERT INTO example_table(column1, column2, column3)
SELECT column_a, column_b, column_c FROM example_table_2;
解释:
example_table是要插入数据的表名;column1、column2、column3是表中的列名;SELECT子句用于选取要插入的数据,从example_table_2表中选取column_a、column_b、column_c这三个列。
注意,使用 INSERT INTO 语句插入数据时,数据会先缓存在内存中,并不是立即写入磁盘,需要手动执行 optimize table 或等待后台自动执行。
3 Update 和 Delete
在 ClickHouse 中,Mutation 查询包括 Delete 和 Update 两种操作,并且不支持事务。Mutation 查询会导致目标数据的原有分区被放弃,重建新分区,因此最好进行批量的变更,避免频繁小数据的操作。
以下是 Delete 和 Update 的示例 SQL 语句:
3.1.删除操作
ALTER TABLE t_order_smt DELETE WHERE sku_id = 'sku_001';
解释:
t_order_smt是要删除数据的表名;sku_id = 'sku_001'为删除的过滤条件。
3.2.修改操作
ALTER TABLE t_order_smt UPDATE total_amount = toDecimal32(2000.00, 2) WHERE id = 102;
解释:
t_order_smt是要修改数据的表名;total_amount = toDecimal32(2000.00, 2)为修改的内容;id = 102为修改的过滤条件。
Mutation 查询的操作比较“重”,因此它分两步执行。同步执行的部分其实只是进行新增数据新增分区和把旧分区打上逻辑上的失效标记。直到触发分区合并的时候,才会删除旧数据释放磁盘空间。一般不会开放这样的功能给用户,由管理员完成。
示例:
-- 创建表 t_order_smt 并插入数据
CREATE TABLE t_order_smt
(id UInt32,sku_id String,total_amount Float32
)
ENGINE = MergeTree
PARTITION BY id
ORDER BY (id, sku_id);INSERT INTO t_order_smt VALUES (101, 'sku_001', 1000.00), (102, 'sku_002', 1500.00);-- 修改 id 为 102 的 total_amount
ALTER TABLE t_order_smt UPDATE total_amount = toDecimal32(2000.00, 2) WHERE id = 102;-- 删除 sku_id 为 'sku_001' 的数据
ALTER TABLE t_order_smt DELETE WHERE sku_id = 'sku_001';
相关文章:

关于ClickHouse的表引擎和SQL操作
目录 前言: 一.表引擎 (严格区分大小写) 1.TinyLog引擎 2.Memory 3.MergeTree 二.Sql操作 clickhouse 和 mysql 的比较 1 create 2 Insert 3 Update 和 Delete 前言: 在学习使用clickhouse时,首先就要先认识它的一大特点就是表…...

rust字符串
标准库提供了String结构体表示字符串。 String实际上就是Vec<u8>的封装。唯一的不同是String的方法假定Vec<u8>中的二进制都是utf8编码的 pub struct String {vec: Vec<u8>, }一、定义String 1.使用new方法创建空字符串 let string String::new();2.使用…...

解析-BeautifulSoup
解析-BeautifulSoup 1.基本简介 1.BeautifulSoup简称:bs4 2.什么是Beatifulsoup?Beautifulsoup,和1xm1一样,是一个html的解析器,主要功能也是解析和提取数据 3.优缺点?缺点: 效率没有1xm1的效率高优点: 接口设计人性化,使用方…...

C++:数组
C中的数组是一种用于存储相同数据类型的元素的数据结构。以下是C数组的一些特点: 固定大小:数组在创建时需要指定其大小,而且无法在运行时改变大小。这意味着一旦数组被创建,其大小就是固定的,除非创建一个新的数组。 …...

结合Mockjs与Bus事件总线搭建首页导航和左侧菜单
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《ELement》。🎯🎯 …...

模拟桌面自动整理, 先顶左,再顶上。
5 6 **##** ****#* ***##* #***** ***#** ##**** ##**** #***** #***** #***** #include<iostream> using namespace std; #define MAX 1024char a[MAX][MAX]; void H(char arr[][MAX], int n,int idx) {//n列数 ,idx 某行int left 0;int right n - 1;char t;while (…...

新增MariaDB数据库管理、支持多版本MySQL数据库共存,1Panel开源面板v1.6.0发布
2023年9月18日,现代化、开源的Linux服务器运维管理面板1Panel正式发布v1.6.0版本。 在这个版本中,1Panel新增MariaDB数据库管理;支持多版本MySQL数据库共存;支持定时备份系统快照和应用商店中已安装应用;支持为防火墙…...
【dbeaver】win环境的kerberos认证和Clouders集群中Kerberos认证使用Dbeaver连接Hive和Phoenix
一、下载驱动 cloudera官网 1.1 官网页面下载 下载页面 的Database Drivers 挑选比较新的版本即可。 1.2 集群下载 Hive可能集群没有驱动包。驱动包名称:HiveJDBC42.jar。41结尾的包也可以使用的。注意Jar包的大小一定是十几MB的。几百KB的是thin包不可用。 …...
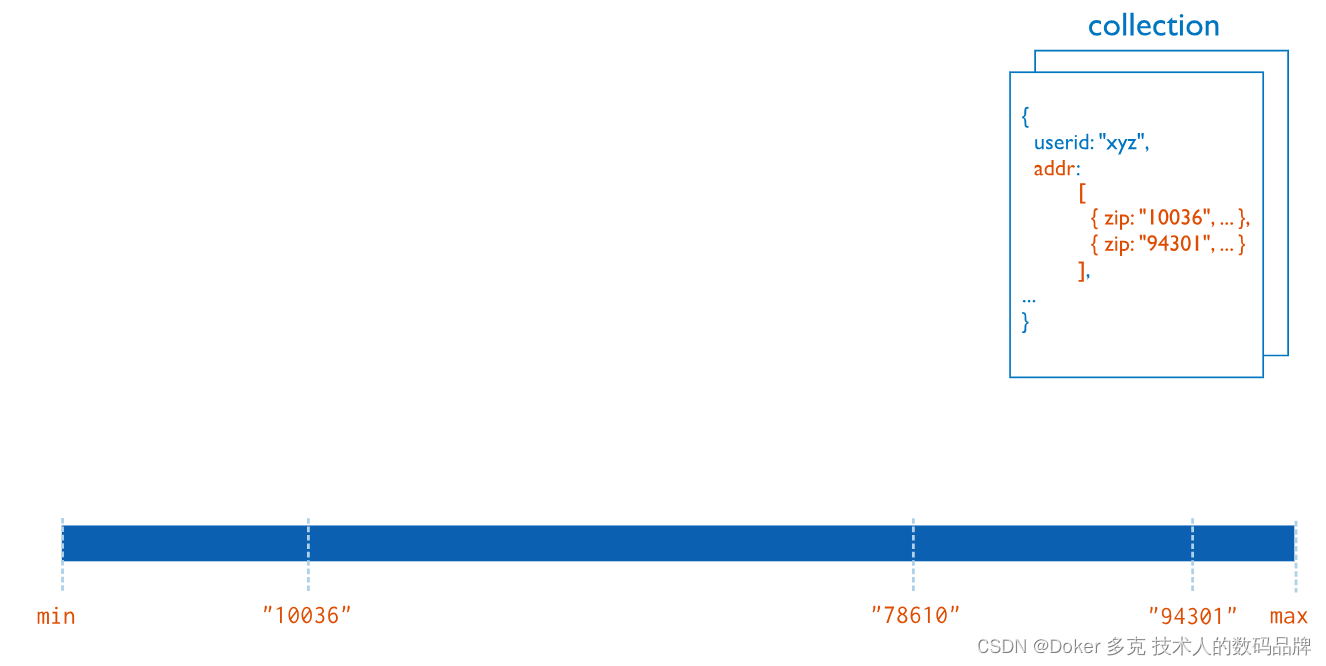
MongoDB索引
索引支持在MongoDB中高效执行查询。如果没有索引,MongoDB必须扫描集合中的每个文档才能返回查询结果。如果查询存在适当的索引,MongoDB将使用该索引来限制它必须扫描的文档数。 尽管索引提高了查询性能,但添加索引对写入操作的性能有负面影响…...

ChatGPT的问世给哪些行业带来了冲击?
目录 引言Chat GPT 对行业的影响在线客服和智能客服行业传统自动回复机器人的局限性Chat GPT 的提升能力 教育培训行业个性化学习需求的挑战Chat GPT 的个性化优势 金融保险行业客户服务的变革Chat GPT 的智能化应用 医疗健康领域自助诊断及咨询的便利性Chat GPT 在医疗领域的应…...
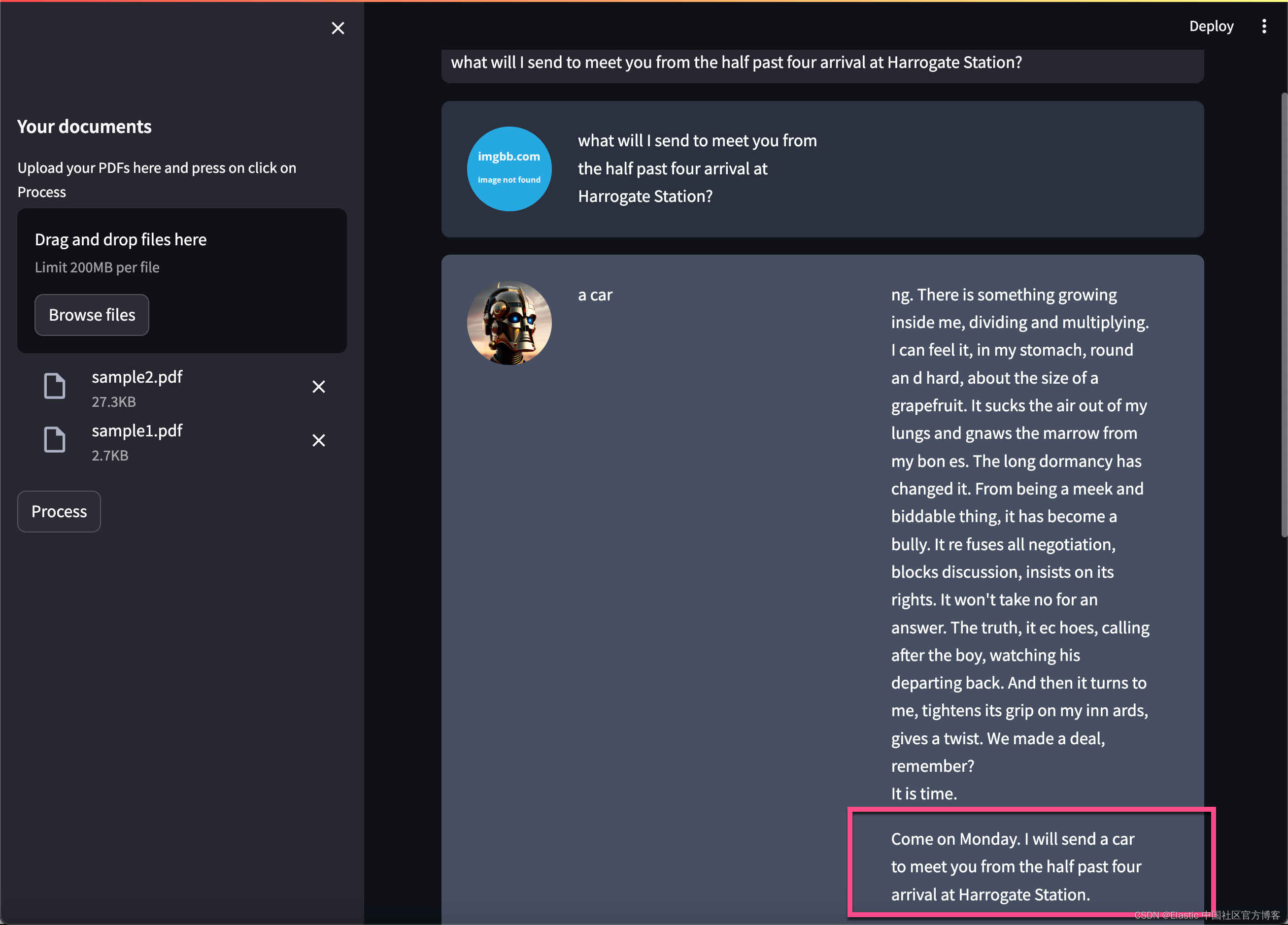
Elasticsearch:与多个 PDF 聊天 | LangChain Python 应用教程(免费 LLMs 和嵌入)
在本博客中,你将学习创建一个 LangChain 应用程序,以使用 ChatGPT API 和 Huggingface 语言模型与多个 PDF 文件聊天。 如上所示,我们在最最左边摄入 PDF 文件,并它们连成一起,并分为不同的 chunks。我们可以通过使用 …...

docker系列(7) - Dockerfile
文章目录 7. Dockerfile7.1 Dockerfile介绍7.2 指令规则7.3 指令说明7.3.1 RUN命令的两种格式7.3.1 CMD命令覆盖问题7.3.2 ENTRYPOINT命令使用7.3.3 ENV的使用 7.4 构建tomcat Dockerfile案例7.4.1 准备原始文件7.4.2 编写Dockerfile7.4.3 构建镜像7.4.4 验证镜像 7.5 构建jdk基…...

Spring面试题8:面试官:说一说Spring的BeanFactory
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:说一说Spring的BeanFactory Spring的BeanFactory是Spring框架的核心容器,负责管理和创建Bean对象。它是一个工厂类,用于实例化、配置和管理Bean的…...
Win10专业版系统一键重装怎么操作?
Win10专业版系统一键重装怎么操作?与传统的系统重装相比,一键重装不仅省去了繁琐的安装步骤,这一简单操作使得系统维护和恢复变得更加便捷,让用户不再为系统问题而烦恼。下面小编给大家详细介绍关于一键重装Win10专业版系统的操作…...
十大服装店收银系统有哪些 好用的服装收银软件推荐
服装店收银系统对于门店和服装卖场来说非常重要,可以提高工作效率。下面是推荐的十大服装店收银系统,供开设服装店的企业选择合适的收银软件用于经营管理。 1、核货宝收银系统 支持快速收银,同时适用于服装行业,能够支持多规格多…...
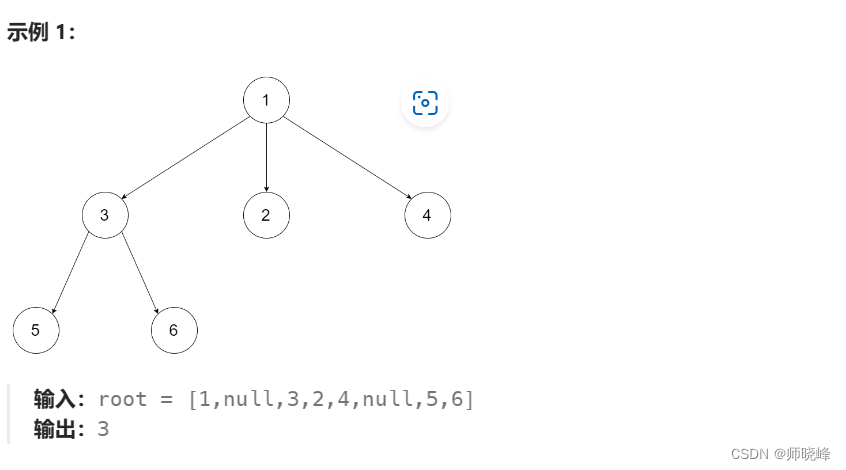
算法通过村第八关-树(深度优先)白银笔记|深度和高度问题
文章目录 前言1. 最大深度问题2. 判断平衡树3. 最小深度4. N叉树的最大深度总结 前言 提示:我的整个生命,只是一场为了提升社会地位的低俗斗争。--埃莱娜费兰特《失踪的孩子》 这一关我们看一些比较特别的题目,关于二叉树的深度和高度问题。这…...

Redis安装和使用
这里写目录标题 Redis安装和使用一.数据库类型1.关系型数据库2.非关系型数据库3.区别(1)数据存储方式不同(2)扩展方式不同(3)对事务性的支持不同 二.redis简介1.Redis 优点2.哪些数据适合放入缓存中&#x…...

UML基础与应用之面向对象
UML(Unified Modeling Language)是一种用于软件系统建模的标准化语言,它使用图形符号和文本来描述软件系统的结构、行为和交互。在面向对象编程中,UML被广泛应用于软件系统的设计和分析阶段。本文将总结UML基础与应用之面向对象的…...
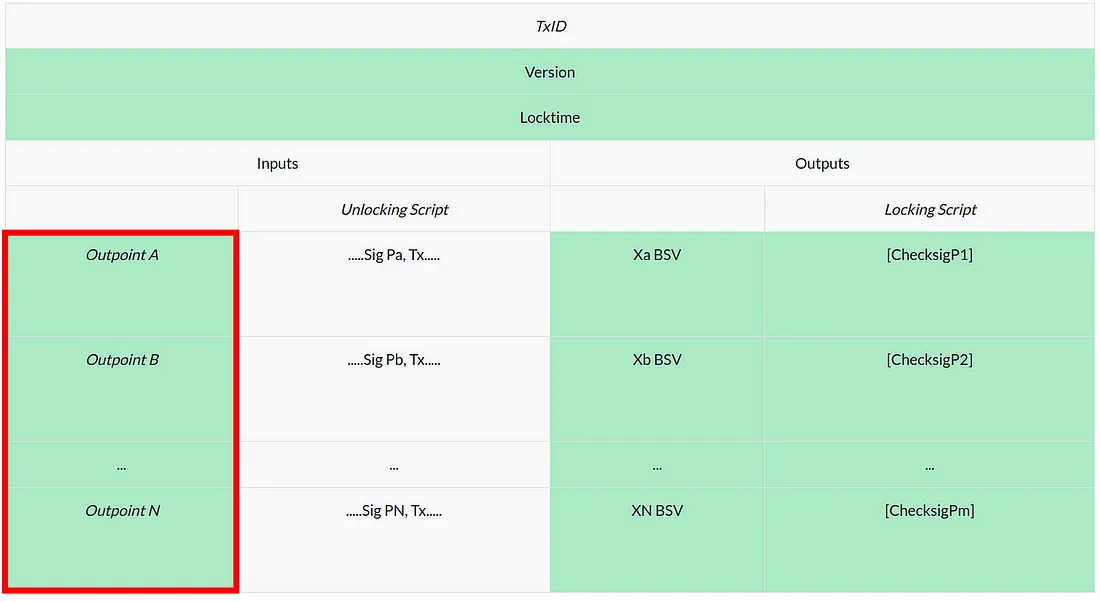
将 Ordinals 与比特币智能合约集成:第 2 部分
在上一篇文章中,我们展示了一种将 Ordinal 与智能合约集成的方法,即将Ordinal和合约放在同一个 UTXO 中。 今天,我们介绍了一种集成它们的替代方案,即它们位于单独的 UTXO 中。 作为展示,我们开发了一个智能合约&…...
)
PCL 法线空间采样(C++详细过程版)
法线空间采样 一、概述二、代码实现三、结果展示1、原始点云2、采样结果一、概述 法线空间采样在PCL里有现成的调用函数,具体算法原理和实现代码见:PCL 法线空间采样。为充分了解法线空间采样算法实现的每一个细节和有待改进的地方,使用C++代码对算法实现过程进行复现。 二…...

用PyTorch复现BCNet息肉分割模型:从论文到代码的保姆级实践指南
用PyTorch复现BCNet息肉分割模型:从论文到代码的保姆级实践指南 医学影像分析领域,息肉分割一直是内窥镜诊断的关键技术。传统方法依赖医生手动标注,效率低下且易受主观因素影响。近年来,深度学习在医学图像分割领域展现出强大潜…...

服务号版本:weixin-java-mp=4.8.3.B,spring-boot=3.3.1,httpclient5=5.5.2
文章目录 引言 I 微信绑定服务号 II 推荐使用成熟 SDK 基于微信code登录:前端先调用loginByWxCode接口 解绑 依赖版本冲突 III httpclient5版本问题 问题 分析 解决方案: 强制锁定 HttpClient 5.5.2 IV httpcore5版本冲突问题 问题 分析 解决方案 引言 本文介绍了微信开发中…...

快速解密QQ音乐加密文件:qmc-decoder完整指南
快速解密QQ音乐加密文件:qmc-decoder完整指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 还在为QQ音乐下载的.qmc、.qmc3、.qmcflac格式文件无法在其他播放…...

SAP SD新手避坑指南:交货工厂和装运点配置错了,小心订单发不出去!
SAP SD配置实战:交货工厂与装运点配置错误的深度排查手册 当销售订单在SAP系统中卡在发货环节时,背后往往隐藏着交货工厂(Plant)与装运点(Shipping Point)的配置逻辑问题。这类错误不仅会导致业务流程中断&…...

AMD Ryzen SMU调试工具完全指南:免费开源硬件调优神器入门教程
AMD Ryzen SMU调试工具完全指南:免费开源硬件调优神器入门教程 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

从IMX334到HDMI输入:Hi3559AV100 MPP代码中VI参数配置的保姆级调整指南
从IMX334到HDMI输入:Hi3559AV100 MPP代码中VI参数配置实战解析 当我们需要将Hi3559AV100开发板从默认的IMX334 MIPI摄像头切换为HDMI输入时,整个视频输入(VI)通道的参数配置需要彻底重构。这不仅涉及硬件接口的转换,更需要深入理解MPP框架中V…...

一道2厘米的伤口,照见了人间的双重标准
一道2厘米的伤口,照见了人间的双重标准简介昨天清晨六点,天色刚泛白。我照例牵着家里那只黑白分明的边牧出门。它在晨光里撒腿跑开的姿势依旧敏捷而优雅——这个品种天生属于旷野,即使被圈养在城市的钢筋水泥里,那股源自苏格兰边境…...

华为BGP路由实战:从原理到策略调优的深度解析
1. 华为BGP路由技术入门指南 第一次接触华为BGP路由配置时,我被那些专业术语搞得晕头转向。经过多次实战后才发现,BGP就像互联网世界的邮局系统,负责在不同自治系统(AS)之间传递路由信息。华为设备的BGP实现特别适合企…...
)
RWKV vs. LLaMA2:在论文审稿任务上,我为什么第一版选了它(以及为什么后来放弃了)
RWKV与LLaMA2在论文审稿任务中的技术选型反思 当面对一个需要处理长文档的AI审稿系统时,模型选型往往成为决定项目成败的关键因素。2023年第三季度,我们在构建论文审稿GPT第一版时,做出了一个在当时看来合理但事后证明值得商榷的决策——选择…...
)
别再只用MSE了!PyTorch中SmoothL1Loss的保姆级使用指南(附代码对比)
深度学习回归任务中SmoothL1Loss的实战应用与MSE对比解析 在目标检测、房价预测等回归任务中,选择合适的损失函数往往决定了模型的收敛速度和最终性能。许多初学者会习惯性选择最熟悉的均方误差(MSE)损失函数,但当数据中存在离群点时,MSE的二…...