HashMap源码解析_jdk1.8(一)
HashMap解析
- HashMap源码解析_jdk1.8(一)
- 哈希
- 常用数据结构查找/插入/删除性能比较。
- 哈希冲突
- HashMap的数据结构
- HashMap相关变量
- size和capacity
HashMap源码解析_jdk1.8(一)
哈希
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
常用数据结构查找/插入/删除性能比较。
-
数组
采用一段连续的存储单元来存储数据。
查找:时间复杂度
O(1)插入删除:时间复杂度
O(n),插入删除操作,涉及到数组元素的移动。 -
线性链表
查找:时间复杂度
O(n),需要遍历链表。插入删除:时间复杂度
O(1),仅需处理链表指针的指向。 -
二叉树
对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为
O(logn)。 -
哈希表
在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为
O(1)。哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
映射函数:
存储位置 = f(关键字)其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。
哈希冲突
哈希是通过对数据进行再压缩,提高效率的一种解决方法。但由于通过哈希函数产生的哈希值是有限的,而数据可能比较多,导致经过哈希函数处理后仍然有不同的数据对应相同的值。这时候就产生了哈希冲突(哈希碰撞)。
解决哈希冲突的方法:
-
开放地址方法
1). 线性探测:冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
2). 再平方探测: 冲突发生时,在表的左右进行跳跃式探测,在原来值的基础上先加1的平方个单位,若仍然存在则减1的平方个单位。随之是2的平方,3的平方等等。直至不发生哈希冲突。
3). 伪随机探测: 冲突发生时,通过随机函数随机生成一个数,直至不发生哈希冲突。
-
链式地址法(HashMap的哈希冲突解决方法)
将所有哈希地址为i的元素构成一个单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在链表中进行。
-
再哈希法
对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突。
-
建立公共溢出区
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
HashMap的数据结构
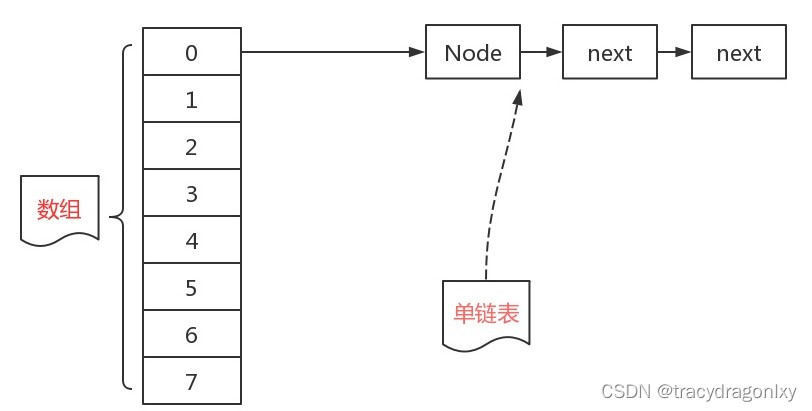
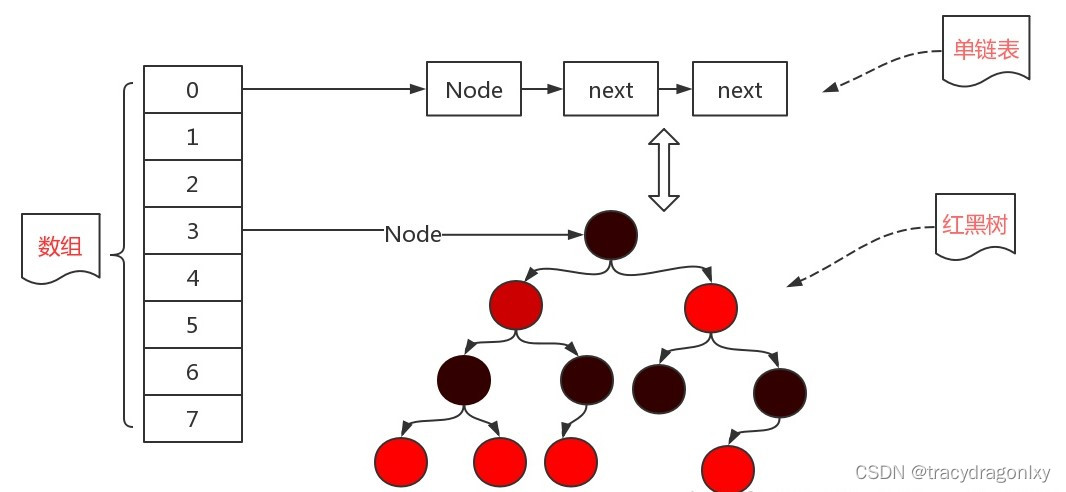
HashMap的底层主要是基于数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。
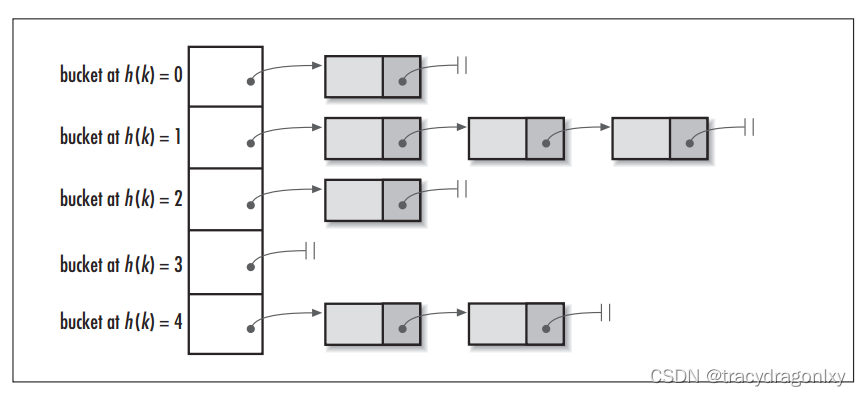
从上图看到,左边是个数组,数组的每个成员是一个链表。该数据结构所容纳的所有元素均包含一个指针,用于元素间的链接。
JDK1.7中HashMap的数据结构:数组+链表
JDK1.8中HashMap的数据结构:数组+链表+红黑树,只有在链表的长度不小于8,而且数组的长度不小于64的时候才会将链表转化为红黑树。
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。Entry是HashMap中的一个静态内部类。代码如下:
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}
}
HashMap相关变量
HashMap类中有以下主要成员变量:
/*** 默认初始容量 - 必须是2的幕数.*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16/*** node数组最大容量:2^30=1073741824.* MUST be a power of two <= 1<<30.*/
static final int MAXIMUM_CAPACITY = 1 << 30;/*** 默认的负载因子,用来衡量HashMap满的程度。*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;/*** 将链表转换为树的阈值。当链表长度超过8时,链表就转换为红黑树。*/
static final int TREEIFY_THRESHOLD = 8;/*** 树转链表阀值,小于等于6(tranfer时,lc、hc=0两个计数器分别++记录原bin、新binTreeNode数量,<=UNTREEIFY_THRESHOLD 则untreeify(lo))*/
static final int UNTREEIFY_THRESHOLD = 6;/*** The smallest table capacity for which bins may be treeified.* (Otherwise the table is resized if too many nodes in a bin.)* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts* between resizing and treeification thresholds.*/
static final int MIN_TREEIFY_CAPACITY = 64;/* ---------------- Fields -------------- *//*** 存放node的数组,分配长度后,长度始终为2的幂*/
transient Node<K,V>[] table;/*** Holds cached entrySet(). Note that AbstractMap fields are used* for keySet() and values().*/
transient Set<Map.Entry<K,V>> entrySet;/*** 记录了Map中Key-Value对的个数*/
transient int size;/**
* 记录当前集合被修改(添加,删除)的次数
*
* 当我们使用迭代器或foreach遍历时,如果你在foreach遍历时,自动调用迭代器的迭代方法,* 此时在遍历过程中调用了集合的add,remove方法时,modCount就会改变,* 而迭代器记录的modCount是开始迭代之前的,如果两个不一致,就会报异常,* 说明有两个线路(线程)同时操作集合。这种操作有风险,为了保证结果的正确性,* 避免这样的情况发生,一旦发现modCount与expectedModCount不一致,立即保错。
*
* This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;/*** 下一个要调整大小的大小值,当实际KV个数超过threshold时,HashMap会将容量扩容,threshold=capacity * load factor.*/
int threshold;/*** The load factor for the hash table.*/
final float loadFactor;
size和capacity
HashMap就像一个“桶”,那么capacity就是这个桶“当前”最多可以装多少元素,而size表示这个桶已经装了多少元素。
HashMap<Integer, Integer> map = new HashMap<>();map.put(1, 1);try {Class<?> mapClass = map.getClass();Method capacity = mapClass.getDeclaredMethod("capacity");capacity.setAccessible(true);System.out.println("capacity: " + capacity.invoke(map));Field size = mapClass.getDeclaredField("size");size.setAccessible(true);System.out.println("size: " + size.get(map));} catch (NoSuchMethodException | IllegalAccessException | InvocationTargetException | NoSuchFieldException e) {e.printStackTrace();}
}
capacity: 16
size: 1
我们定义了一个新的HashMap,向其中put了一个元素,然后通过反射的方式打印capacity和size。输出结果为:capacity : 16、size : 1
默认情况下HashMap的容量是16,但是,如果用户通过构造函数指定了一个数字作为容量,那么Hash会选择大于该数字的第一个2的幂作为容量。(1->1、7->8、9->16)
/*** Returns a power of two size for the given target capacity.*/
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
public static void main(String[] args) {HashMap<Integer, Integer> map1 = new HashMap<>(1);HashMap<Integer, Integer> map2 = new HashMap<>(7);HashMap<Integer, Integer> map3 = new HashMap<>(9);demoCapacity(map1);demoCapacity(map2);demoCapacity(map3);
}private static void demoCapacity(HashMap<Integer, Integer> map) {try {Class<?> mapClass = map.getClass();Method capacity = mapClass.getDeclaredMethod("capacity");capacity.setAccessible(true);System.out.println("capacity: " + capacity.invoke(map));} catch (NoSuchMethodException | IllegalAccessException | InvocationTargetException e) {e.printStackTrace();}
}capacity: 1
capacity: 8
capacity: 16
参考:
https://zhuanlan.zhihu.com/p/79219960
https://www.cnblogs.com/theRhyme/p/9404082.html#_lab2_1_1
相关文章:
HashMap源码解析_jdk1.8(一)
HashMap解析 HashMap源码解析_jdk1.8(一)哈希常用数据结构查找/插入/删除性能比较。哈希冲突 HashMap的数据结构HashMap相关变量size和capacity HashMap源码解析_jdk1.8(一) 哈希 Hash,一般翻译做“散列”࿰…...
Android最好用的日志打印库(自动追踪日志代码位置)
给大家推荐一个自己写的日志打印的库,我愿称之为最强日志打印库:BytUtilLog Byt是Big一统的缩写,大一统日志打印库,哈哈!搞个笑,很早就写好了,但后面忙起来就忘了写一篇文章推一下它了ÿ…...

面试官的哪些举动,暗示你通过了面试?
其实在求职过程中都会发现,求职者面试时间一般在20分钟以上,如果求职者较多,可能会在10分钟左右。(会在介绍以往工作上减少时间,内容主要以简单介绍,薪资要求,能力评价,到岗时间等等) 拿面试时…...

旅行季《乡村振兴战略下传统村落文化旅游设计》许少辉八一新著想象和世界一样宽广
旅行季《乡村振兴战略下传统村落文化旅游设计》许少辉八一新著想象和世界一样宽广...
Linux学习第19天:Linux并发与竞争实例: 没有规矩不成方圆
Linux版本号4.1.15 芯片I.MX6ULL 大叔学Linux 品人间百味 思文短情长 先说点题外话,上周参加行业年会,停更了一周。接下来的周五就要开启国庆中秋双节模式,所以有的时候,尤其是工作以后…...

Unity添加自定义菜单按钮
如果你想在Unity编辑器中添加自定义菜单按钮,你可以使用Unity的MenuSystem API。这是一个简单的示例: 首先需要引用using UnityEditor; using UnityEngine; using UnityEditor; 两个命名空间 然后在方法前添加 [MenuItem("原菜单名/自定义名…...

PHP8的类与对象的基本操作之类的实例化-PHP8知识详解
定义完类和方法后,并不是真正创建一个对象。类和对象可以描述为如下关系。类用来描述具有相同数据结构和特征的“一组对象”,“类”是“对象”的抽象,而“对象”是“类”的具体实例,即一个类中的对象具有相同的“型”,…...

C/S架构学习之TCP服务器
TCP服务器的实现流程:一、创建套接字(socket函数):通信域选择IPV4网络协议、套接字类型选择流式; int sockfd socket(AF_INET,SOCK_STREAM,0); //通信域选择IPV4、套接字类型选择流式二、填充服务器的网络信息结构体&…...

基于微信小程序的线上教育课程付费商城(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...

Linux基础指令(五)
目录 前言1. 打包和压缩1.1 是什么1.2 为什么1.3 怎么办? 2. zip & unzip3. tar 指令结语: 前言 欢迎各位伙伴来到学习 Linux 指令的 第五天!!! 在上一篇文章 Linux基本指令(四) 当中,我们学习了 fin…...
C语言结构体的一些鲜为人知的小秘密
目录 一、结构体内存对齐规则: 1.1范例 1.2结构体内存对齐规则 1.3自定义默认对齐数 二、位段 2.1什么是位段 2.2位段的内存分配 2.3位段的不足 三、枚举和联合体 3.1枚举 3.1.1枚举类型的定义 3.1.2枚举类型的使用 3.2联合体 3.2.1联合体的定义 3.…...
-探究Pod被驱逐的原因及解决方法)
kubernetes问题(一)-探究Pod被驱逐的原因及解决方法
1 k8s evicted是什么 k8s evicted是Kubernetes中的一个组件,主要用于处理Pod驱逐的情况。在Kubernetes中,当Node节点资源不够用时,为了保证整个集群的运行稳定,会按照一定的优先级和策略将其中的Pod驱逐出去。这时就需要一个组件…...

论文速览【序列模型 seq2seq】—— 【Ptr-Net】Pointer Networks
标题:Pointer Networks文章链接:Pointer Networks参考代码(非官方):keon/pointer-networks发表:NIPS 2015领域:序列模型(RNN seq2seq)改进 / 深度学习解决组合优化问题【…...
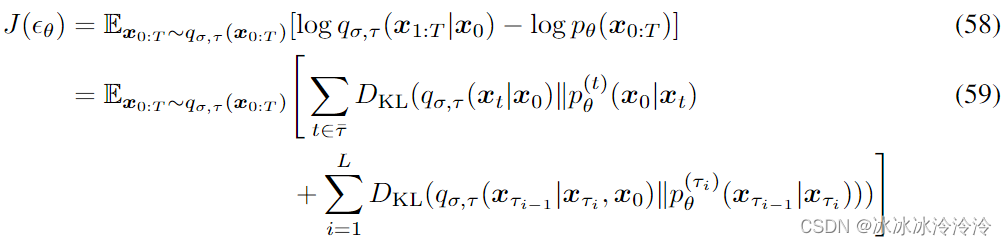
Denoising diffusion implicit models 阅读笔记
Denoising diffusion probabilistic models (DDPMs)从马尔科夫链中采样生成样本,需要迭代多次,速度较慢。Denoising diffusion implicit models (DDIMs)的提出是为了加速采样过程,减少迭代的次数,并且要求DDIM可以复用DDPM训练的网…...

【Java 基础篇】Executors工厂类详解
在多线程编程中,线程池是一项重要的工具,它可以有效地管理和控制线程的生命周期,提高程序的性能和可维护性。Java提供了java.util.concurrent包来支持线程池的创建和管理,而Executors工厂类是其中的一部分,它提供了一些…...

SpringBoot MongoDB操作封装
1.引入Jar包 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-mongodb</artifactId></dependency> 2.MongoDbHelper操作 /*** MongoDB Operation class* author Mr.Li* date 2022-12-05*…...

PyTorch 模型性能分析和优化 — 第 1 部分
一、说明 这篇文章的重点将是GPU上的PyTorch培训。更具体地说,我们将专注于 PyTorch 的内置性能分析器 PyTorch Profiler,以及查看其结果的方法之一,即 PyTorch Profiler TensorBoard 插件。 二、深度框架 训练深度学习模型,尤其是…...

Unity3D 简易音频管理器
依赖于Addressable 依赖于单例模板:传送门 using System.Collections.Generic; using System.Security.Cryptography; using System; using UnityEngine; using UnityEngine.AddressableAssets;namespace EasyAVG {public class AudioManager : MonoSingleton<…...

【李沐深度学习笔记】线性回归
课程地址和说明 线性回归p1 本系列文章是我学习李沐老师深度学习系列课程的学习笔记,可能会对李沐老师上课没讲到的进行补充。 线性回归 如何在美国买房(经典买房预测问题) 一个简化的模型 线性模型 其中, x → [ x 1 , x 2 ,…...
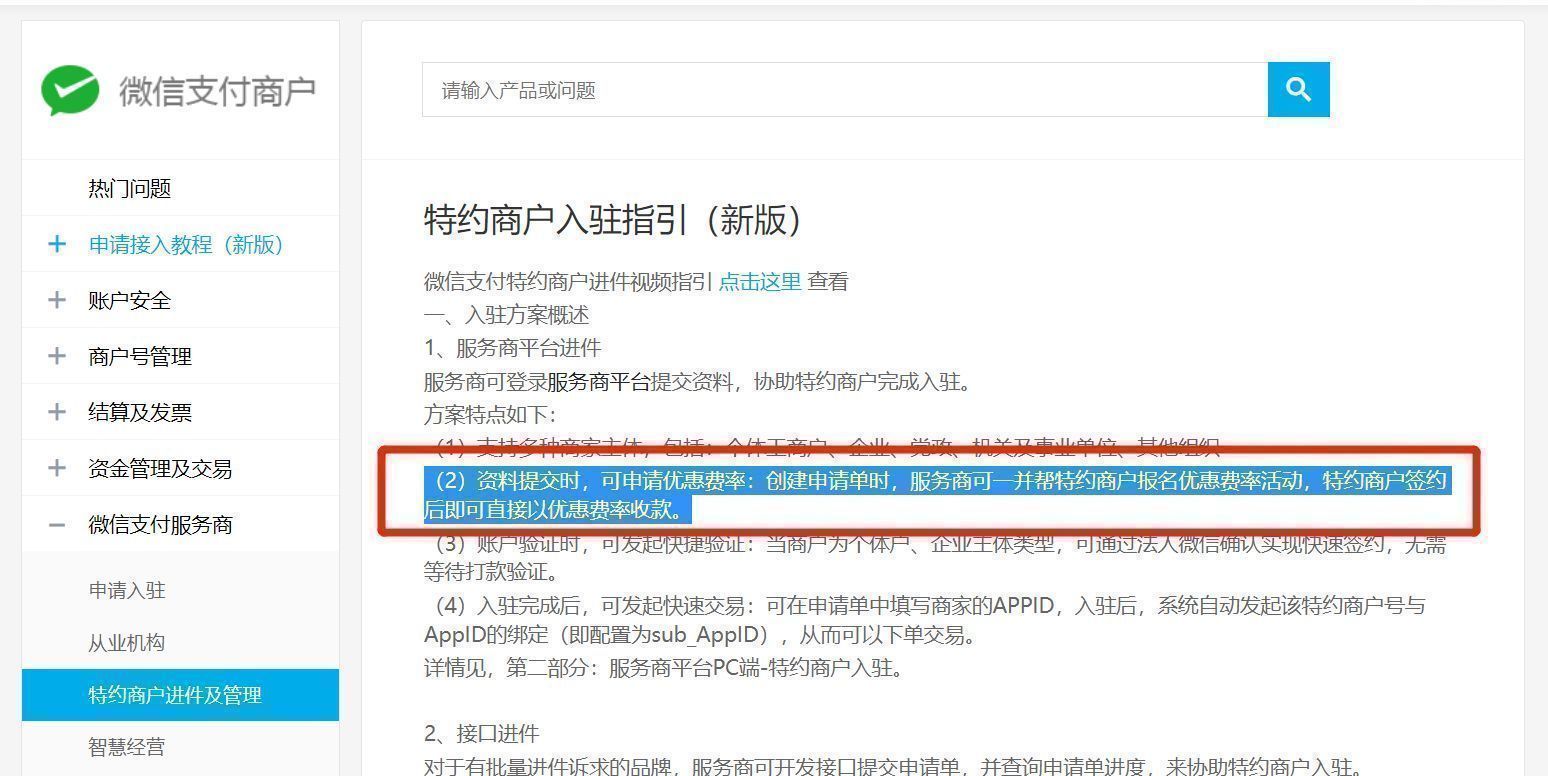
微信收款码费率0.38太坑了
作为一个有多年运营经验的商家,我本人在申请收款功能时曾经走过了不少弯路。我找遍了市面上的知名的支付公司,但了解到的收款手续费率通常都在0.6左右,最低也只能降到0.38。这个过程吃过不少苦头。毕竟,收款功能是我们商家的命脉&…...
)
告别GUI框架:在嵌入式Linux上用framebuffer手撸一个简易绘图库(附完整代码)
告别GUI框架:在嵌入式Linux上用framebuffer手撸一个简易绘图库 在资源受限的嵌入式Linux环境中,图形界面开发往往面临两难选择:要么使用Qt、SDL等重型框架消耗宝贵的内存和CPU资源,要么放弃图形功能转向纯命令行交互。本文将为开发…...
)
大模型查询质量评估新范式(Perplexity算法底层逻辑首次公开)
更多请点击: https://codechina.net 第一章:大模型查询质量评估新范式(Perplexity算法底层逻辑首次公开) Perplexity(困惑度)并非仅是语言模型训练阶段的监控指标,而是当前大模型查询质量评估中…...

magic-api Swagger文档自动生成:让API文档维护变得简单
magic-api Swagger文档自动生成:让API文档维护变得简单 【免费下载链接】magic-api magic-api 是一个接口快速开发框架,通过Web页面编写脚本以及配置,自动映射为HTTP接口,无需定义Controller、Service、Dao、Mapper、XML、VO等Jav…...

【免费下载】 Cadence Allegro 多层板设计经典案例分享:助你快速提升设计技能
Cadence Allegro 多层板设计经典案例分享:助你快速提升设计技能 项目介绍 在电子设计领域,Cadence Allegro 是一款广泛使用的 PCB 设计软件,尤其在多层板设计中表现出色。为了帮助广大工程师和学习者更好地掌握 Allegro 的使用技巧࿰…...

【亲测免费】 探索INA282:电流检测与测量的利器
探索INA282:电流检测与测量的利器 【下载地址】INA282电路图与使用说明 INA282电路图与使用说明本仓库提供了一个关于INA282的详细资源文件,包括电路图和使用说明 项目地址: https://gitcode.com/open-source-toolkit/9e96c 项目介绍 INA282是一…...

深入理解强化学习基础:价值函数、策略梯度与PPO算法核心原理
深入理解强化学习基础:价值函数、策略梯度与PPO算法核心原理 【免费下载链接】LLM-RL-Visualized 🌟100 原创 LLM / RL 原理图📚,《大模型算法》作者巨献!💥(100 LLM/RL Algorithm Maps &#x…...

智能字幕革命:Open-Lyrics如何用AI重新定义音频内容处理
智能字幕革命:Open-Lyrics如何用AI重新定义音频内容处理 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。 项…...

终极免费AI图像放大工具Upscayl完整指南:高效提升图片分辨率
终极免费AI图像放大工具Upscayl完整指南:高效提升图片分辨率 【免费下载链接】upscayl 🆙 Upscayl - #1 Free and Open Source AI Image Upscaler for Linux, MacOS and Windows. 项目地址: https://gitcode.com/GitHub_Trending/up/upscayl Upsc…...

3步打造你的专属Minecraft领地世界:PlotSquared终极指南
3步打造你的专属Minecraft领地世界:PlotSquared终极指南 【免费下载链接】PlotSquared PlotSquared - Reinventing the plotworld 项目地址: https://gitcode.com/gh_mirrors/pl/PlotSquared 还在为Minecraft服务器管理混乱而烦恼吗?想要创建一个…...
的3D视觉原理与应用)
从‘看见’到‘看懂’:手把手拆解RGB-D摄像头(如Intel Realsense)的3D视觉原理与应用
从‘看见’到‘看懂’:手把手拆解RGB-D摄像头的3D视觉原理与应用 当你第一次看到RGB-D摄像头生成的彩色点云在屏幕上旋转时,那种将现实世界数字化的震撼感令人难忘。但真正让这种设备发挥价值的,是理解它如何将光信号转化为三维坐标的完整技术…...