计算机视觉与深度学习-经典网络解析-AlexNet-[北邮鲁鹏]
这里写目录标题
- AlexNet
- 参考文章
- AlexNet模型结构
- AlexNet共8层:
- AlexNet运作流程
- 简单代码实现
- 重要说明
- 重要技巧
- 主要贡献
AlexNet
AlexNet 是一种卷积神经网络(Convolutional Neural Network,CNN)的架构。它是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton提出的,并在2012年的ImageNet大规模视觉识别挑战赛(ILSVRC)中获胜。
AlexNet是推动深度学习在计算机视觉任务中应用的先驱之一
AlexNet跟LeNet-5类似也是一个用于图像识别的卷积神经网络。AlexNet网络结构更加复杂,参数更多。
验证了深度卷积神经网络的高效性
参考文章
手撕 CNN 经典网络之 AlexNet(理论篇)
论文《ImageNet Classification with Deep Convolutional Neural Networks》
【动手学计算机视觉】第十六讲:卷积神经网络之AlexNet
AlexNet模型结构
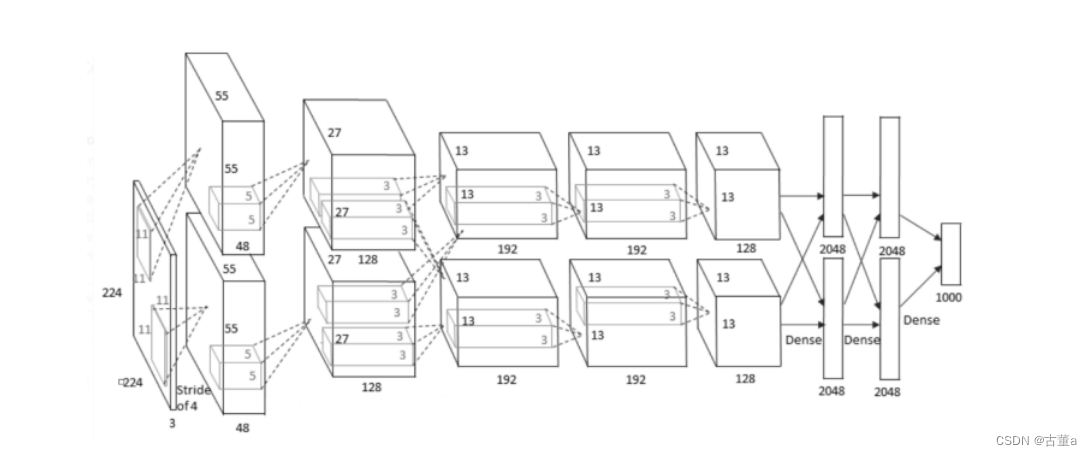
AlexNet中使用的是ReLU激活函数,它5层卷积层除了第一层卷积核为 11 ∗ 11 11*11 11∗11、第二次为 5 ∗ 5 5*5 5∗5之外,其余三层均为 3 ∗ 3 3*3 3∗3
1. 第一层:卷积层
输入
输入为 224 ∗ 224 ∗ 3 224 * 224 * 3 224∗224∗3的图像,输入之前进行了去均值处理(AlexNet对数据集中所有图像向量求均值,均值为 224 ∗ 224 ∗ 3 224 * 224 * 3 224∗224∗3,去均值操作为原图减去均值,绝对数值对分类没有意义,去均值之后的相对数值可以正确分类且计算量小)
卷积
卷积核的数量为96,论文中两块GPU分别计算48个核;
卷积核大小 11 ∗ 11 ∗ 3 , s t r i d e = 4 11 * 11 * 3,stride=4 11∗11∗3,stride=4,stride表示的是步长,padding = 0,表示不填充边缘。
卷积后的图形大小:
w i d e = ( 224 − k e r n e l _ s i z e + 2 ∗ p a d d i n g ) / s t r i d e + 1 = 54 wide = (224 - kernel\_size+2 * padding) / stride + 1 = 54 wide=(224−kernel_size+2∗padding)/stride+1=54
h e i g h t = ( 224 − k e r n e l _ s i z e + 2 ∗ p a d d i n g ) / s t r i d e + 1 = 54 height = (224 - kernel\_size+2 * padding) / stride + 1 = 54 height=(224−kernel_size+2∗padding)/stride+1=54
d i m e n t i o n = 96 dimention = 96 dimention=96
参考个数: ( 11 × 11 × 3 + 1 ) × 96 = 35 k (11 \times 11 \times 3 + 1) \times 96 = 35k (11×11×3+1)×96=35k

池化
输入通道数根据输入图像而定,输出通道数为96,步长为4。

注:窗口大小3*3,步长2,池化过程出现重叠,现在一般不使用重叠池化。
池化结果:27x27x96 特征图组
局部响应归一化层(Local Response Normalized)

为什么要引入LRN层?
首先要引入一个神经生物学的概念:侧抑制(lateral inhibitio),即指被激活的神经元抑制相邻的神经元。
归一化(normaliazation)的目的就是“抑制”,LRN就是借鉴这种侧抑制来实现局部抑制,尤其是我们使用RELU的时候,这种“侧抑制”很有效 ,因而在AlexNet里使用有较好的效果。
归一化有什么好处?
1 归一化有助于快速收敛;
2 对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
【补充:神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
深度网络的训练是复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。】
2. 第二层:卷积层
输入为上一层卷积的 feature map, 27 × 27 × 96 27 \times 27 \times 96 27×27×96大小的特诊图组。
卷积核的个数为256个,论文中的两个GPU分别有128个卷积核。
卷积核大小 5 ∗ 5 5*5 5∗5,输入通道数为96,输出通道数为256,步长为2,padding = 2。
卷积结果: ( 27 − 5 + 2 × 2 ) / 1 + 1 , 27 × 27 × 256 (27 - 5 + 2 \times 2) / 1 + 1,27 \times 27 \times 256 (27−5+2×2)/1+1,27×27×256的特征图组。
然后做LRN。
最后最大化池化
池化层窗口大小为3*3,步长为2。
池化结果: 13 × 13 × 256 13 \times 13 \times 256 13×13×256的特征图组。

3. 第三层:卷积层
输入为第二层的输出,没有LRN和Pool。
卷积核大小 3 ∗ 3 3*3 3∗3,输入通道数为256,输出通道数为384,stride为1,padding = 1。
图像尺寸为: ( 13 − 3 + 2 × 1 ) / 1 + 1 = 13 (13 - 3 + 2 \times 1) / 1 + 1 = 13 (13−3+2×1)/1+1=13
输出: 13 × 13 × 384 13 \times 13 \times 384 13×13×384
4. 第四层:卷积层
输入为第三层的输出,没有LRN和Pool。
卷积核个数为384,大小 3 ∗ 3 3*3 3∗3,输入通道数为384,输出通道数为384,stride为1,padding = 1。
图像尺寸为: ( 13 − 3 + 2 × 1 ) / 1 + 1 = 13 (13 - 3 + 2 \times 1) / 1 + 1 = 13 (13−3+2×1)/1+1=13
输出: 13 × 13 × 384 13 \times 13 \times 384 13×13×384
5. 第五层:卷积层
输入为第四层的输出。
卷积核大小 3 ∗ 3 3*3 3∗3,输入通道数为384,输出通道数为256,stride为1,padding = 1。
图像尺寸为: ( 13 − 3 + 2 × 1 ) / 1 + 1 = 13 (13 - 3 + 2 \times 1) / 1 + 1 = 13 (13−3+2×1)/1+1=13
卷积结果为: 13 × 13 × 256 13 \times 13 \times 256 13×13×256
池化层窗口大小为 3 ∗ 3 3*3 3∗3,步长为2。
图像尺寸为: ( 13 − 3 ) / 2 + 1 = 6 (13 - 3) / 2 + 1 = 6 (13−3)/2+1=6
池化结果为: 6 × 6 × 256 6 \times 6 \times 256 6×6×256
6. 第六层:全连接层
输入大小为上一层的输出,输出大小为4096。
Dropout概率为0.5。
7. 第七层:全连接层
输入大小为上一层的输出,输出大小为4096。
Dropout概率为0.5。
8. 第八层:全连接层
输入大小为4096,输出大小为分类数。
Dropout概率为0.5。

需要将第五层池化结果6×6×256转换为向量9216×1。因为全连接层不能输入矩阵,要输入向量。
注意: 需要注意一点,5个卷积层中前2个卷积层后面都会紧跟一个池化层,而第3、4层卷积层后面没有池化层,而是连续3、4、5层三个卷积层后才加入一个池化层。
AlexNet共8层:
- 5个卷积层(CONV1——CONV5)
- 3个全连接层(FC6-FC8)

AlexNet运作流程
- conv1:输入→卷积→ReLU→局部响应归一化→重叠最大池化层
- conv2:卷积→ReLU→局部响应归一化→重叠最大池化层
- conv3:卷积→ReLU
- conv4:卷积→ReLU
- conv5:卷积→ReLU→重叠最大池化层(经过这层之后还要进行flatten展平操作)
- FC1:全连接→ReLU→Dropout
- FC2:全连接→ReLU→Dropout
- FC3(可看作softmax层):全连接→ReLU→Softmax
简单代码实现
使用pytorch
import torch
import torch.nn as nnclass AlexNet(nn.Module):def __init__(self, num_classes=1000):super(AlexNet, self).__init__()# 第一个卷积层,输入通道3(RGB图像),输出通道64,卷积核大小11x11,步长4,填充2self.conv1 = nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2)self.relu1 = nn.ReLU(inplace=True)# 最大池化层,窗口大小3x3,步长2self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2)# 第二个卷积层,输入通道64,输出通道192,卷积核大小5x5,填充2self.conv2 = nn.Conv2d(64, 192, kernel_size=5, padding=2)self.relu2 = nn.ReLU(inplace=True)# 第二个最大池化层,窗口大小3x3,步长2self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2)# 第三个卷积层,输入通道192,输出通道384,卷积核大小3x3,填充1self.conv3 = nn.Conv2d(192, 384, kernel_size=3, padding=1)self.relu3 = nn.ReLU(inplace=True)# 第四个卷积层,输入通道384,输出通道256,卷积核大小3x3,填充1self.conv4 = nn.Conv2d(384, 256, kernel_size=3, padding=1)self.relu4 = nn.ReLU(inplace=True)# 第五个卷积层,输入通道256,输出通道256,卷积核大小3x3,填充1self.conv5 = nn.Conv2d(256, 256, kernel_size=3, padding=1)self.relu5 = nn.ReLU(inplace=True)# 第三个最大池化层,窗口大小3x3,步长2self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2)# 自适应平均池化层,输出特征图大小为6x6self.avgpool = nn.AdaptiveAvgPool2d((6, 6))# 全连接层,输入大小为256x6x6,输出大小为4096self.fc1 = nn.Linear(256 * 6 * 6, 4096)self.relu6 = nn.ReLU(inplace=True)# 全连接层,输入大小为4096,输出大小为4096self.fc2 = nn.Linear(4096, 4096)self.relu7 = nn.ReLU(inplace=True)# 全连接层,输入大小为4096,输出大小为num_classesself.fc3 = nn.Linear(4096, num_classes)def forward(self, x):x = self.conv1(x)x = self.relu1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.relu2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.relu3(x)x = self.conv4(x)x = self.relu4(x)x = self.conv5(x)x = self.relu5(x)x = self.maxpool3(x)x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.fc1(x)x = self.relu6(x)x = self.fc2(x)x = self.relu7(x)x = self.fc3(x)return x# 创建AlexNet模型的实例
model = AlexNet(num_classes=1000)# 打印模型结构
print(model)
重要说明
- 用于提取图像特征的卷积层以及用于分类的全连接层是同时学习的。
- 卷积层与全连接层在学习过程中会相互影响、相互促进
重要技巧
- Dropout策略防止过拟合;
- 使用动量的随机梯度下降算法,加速收敛;
- 验证集损失不下降时,手动降低10倍的学习率;
- 采用样本增强策略增加训练样本数量,防止过拟合;
- 集成多个模型,进一步提高精度。
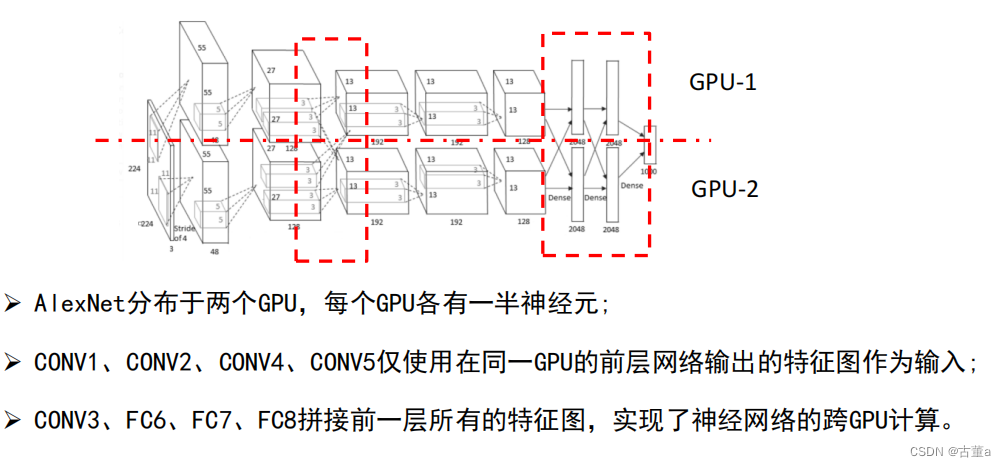
现在显存基本都够用,不需要再考虑分两个GPU计算。
AlexNet卷积层在做什么?

主要贡献
- 提出了一种卷积层加全连接层的卷积神经网络结构
- 首次使用ReLU函数做为神经网络的激活函数
- 首次提出Dropout正则化来控制过拟合
- 使用加入动量的小批量梯度下降算法加速了训练过程的收敛
- 使用数据增强策略极大地抑制了训练过程的过拟合
- 利用了GPU的并行计算能力,加速了网络的训练与推断
相关文章:
计算机视觉与深度学习-经典网络解析-AlexNet-[北邮鲁鹏]
这里写目录标题 AlexNet参考文章AlexNet模型结构AlexNet共8层:AlexNet运作流程 简单代码实现重要说明重要技巧主要贡献 AlexNet AlexNet 是一种卷积神经网络(Convolutional Neural Network,CNN)的架构。它是由Alex Krizhevsky、Il…...
)
Django学习笔记-实现联机对战(下)
笔记内容转载自 AcWing 的 Django 框架课讲义,课程链接:AcWing Django 框架课。 CONTENTS 1. 编写移动同步函数move_to2. 编写攻击同步函数shoot_fireball 1. 编写移动同步函数move_to 与上一章中的 create_player 同步函数相似,移动函数的同…...

一文了解什么SEO
搜索引擎优化 (SEO) 是一门让页面在 Google 等搜索引擎中排名更高的艺术和科学。 一、搜索引擎优化的好处 搜索引擎优化是在线营销的关键部分,因为搜索是用户浏览网络的主要方式之一。 搜索结果以有序列表的形式呈现,网站在该列表中的排名越高&#x…...

SpringBoot+Jpa+Thymeleaf实现增删改查
SpringBootJpaThymeleaf实现增删改查 这篇文章介绍如何使用 Jpa 和 Thymeleaf 做一个增删改查的示例。 1、pom依赖 pom 包里面添加Jpa 和 Thymeleaf 的相关包引用 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.…...
最快的包管理器--pnpm创建vue项目完整步骤
1.用npm全局安装pnpm npm install -g pnpm 2.在要创建vue项目的包下进入cmd,输入: pnpm create vue 3.输入项目名字,选择Router,Pinia,ESLint,Prettier之后点确定 4.cd到创建好的项目 ,安装依赖 cd .\刚创建好的项目名称\ p…...

算法通过村第九关-二分(中序遍历)黄金笔记|二叉搜索树
文章目录 前言1. 有序数组转二叉搜索树2. 寻找连个正序数组的中位数总结 前言 提示:有时候,我感觉自己一辈子活在两个闹钟之间,早上的第一次闹钟,以及5分钟之后的第二次闹钟。 --奥利弗萨克斯《意识的河流》 每个专题都有简单题&a…...

Mock.js之Element-ui搭建首页导航与左侧菜单
🎬 艳艳耶✌️:个人主页 🔥 个人专栏 :《Spring与Mybatis集成整合》《springMvc使用》 ⛺️ 生活的理想,为了不断更新自己 ! 1、Mock.js的使用 1.1.什么是Mock.js Mock.js是一个模拟数据的生成器,用来帮助前…...
robotframework在Jenkins执行踩坑
1. Groovy Template file [robot_results.groovy] was not found in $JENKINS_HOME/email_template 1.需要在managed files 添加robot_results.groovy。这个名字需要和配置在构建项目里default content一致(Extended E-mail Notification默认设置里Default Content…...
关于ElementUI之首页导航与左侧菜单实现
目录 一.Mock 1.1.什么是Mock.js 1.2.特点 1.3.安装与配置 1.3.1. 安装mock.js 1.3.2.引入mock.js 1.4.mockjs使用 1.4.1.定义测试数据文件 1.4.2.mock拦截Ajax请求 1.4.3.界面代码优化 二.总线 2.1.是什么 2.2.前期准备 2.3.配置组件与路由关系 2.3.1. 配置组件 …...
基于springboot小区疫情防控系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...

【k8s】YAML语言基础
文章目录 YAML介绍语法支持的数据类型注意事项json与yaml互转 YAML介绍 YAML是一个类似于XML、JSON的标记语言。强调以数据为中心,并不是以标记语言为中心 <heima><age>15</age><address>Beijing</address> </heima>heima:age:…...

AI时代的中国困境: ChatGPT为什么难以复制
如今,几乎所有中国互联网大厂都公布了自己的“类ChatGPT”解决方案,有些还公布了背后的关于AI技术模型的详情。 其中最高调的是百度,其“文心一言”解决方案号称即将接入数十家内容平台和数以百计的媒体、自媒体。腾讯公布的微信 AI 模型“W…...

如何使用Docker安装最新版本的Redis并设置远程访问(含免费可视化工具)
文章目录 安装Docker安装Redisredis.conf文件远程访问Redis免费可视化工具相关链接Docker是一种开源的应用容器引擎,使用Docker可以让我们快速部署应用环境,本文介绍如何使用Docker安装最新版本的Redis。 安装Docker 首先需要安装Docker,具体的安装方法可以参考Docker官方文…...
怒刷LeetCode的第8天(Java版)
目录 第一题 题目来源 题目内容 解决方法 方法一:双指针和排序 编辑第二题 题目来源 题目内容 解决方法 方法一:双指针 方法二:递归 方法三:快慢指针 方法四:栈 第三题 题目来源 题目内容 解决方法…...

Vue Hooks 让Vue开发更简单与高效
Vue Hooks 让Vue开发更简单与高效 介绍 Vue Hooks 是一个基于 Vue.js 的插件,它提供了一种新的方式来编写 Vue 组件,使得开发更加简单和高效。它借鉴了 React Hooks 的概念,通过使用 Hooks,我们可以在不编写类组件的情况下&…...

Go编程规范
文章目录 注释转义符定义变量方法一:指定变量类型,声明后若不赋值,使用默认值方法二:根据值自行判定变量类型(类型推导)方法三:省略var, 注意:左侧的变量不应该是已经声明过的,否则会导致编译错误[推荐]全局…...
premiere 新建 视频导入 视频拼接 视频截取 多余视频删除
1 新建项目 文件 -> 新建 -> 项目 2 导入 2.1 方法一 直接从本地 将 文件拖入对应的文件夹 2.2 方法二 鼠标右键在指定素材文件夹, 选择导入 选择对应本地文件夹对应素材 3 预设 -> 粗剪 -> 在指定模块处 创建序列预设 3.1 指定模块处 鼠标右键 -> 新建项目…...

笔记01:第一行Python
NameError 名字不含特殊符号(只能是英文、数字、下划线、中文等)名字区分大小写名字先定义后使用 SyntaxError 不符合Python语法书写规范除了语法成分中的保留拼写错误输出中文符号if、for、def等语句末尾忘记冒号 IdentationError 缩进错误&#x…...

资产连接支持会话分屏,新增Passkey用户认证方式,支持查看在线用户信息,JumpServer堡垒机v3.7.0发布
2023年9月25日,JumpServer开源堡垒机正式发布v3.7.0版本。在这一版本中,在用户管理层面,为了提高使用JumpServer操作资产的效率,JumpServer支持对会话进行分屏操作,用户可以在一个浏览器页面打开多个会话,方…...
分包优化和游客模式)
uniapp项目实践总结(二十二)分包优化和游客模式
导语:这篇主要介绍应用分包和游客模式相关的内容。 目录 应用分包游客模式 应用分包 微信对于小程序的打包压缩后的代码体积是有限制的,网页和 APP 也可以适用分包功能,因此需要进行分包添加以及分包优化。 分包添加 在pages.json文件中…...

5分钟掌握MAA:解放双手的明日方舟智能助手终极指南
5分钟掌握MAA:解放双手的明日方舟智能助手终极指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcod…...

工业软件与高性能算力融合:重构智能制造核心引擎
在制造业数字化转型向纵深推进的今天,工业软件与高性能算力的深度融合,正在成为驱动高端制造、关键装备、核心工业领域突破瓶颈的关键力量。长期以来,我国工业领域面临着研发周期长、仿真效率低、系统集成复杂、国产化替代缓慢等多重难题&…...

深度解析SacreBLEU:5个实战技巧提升机器翻译评估效率
深度解析SacreBLEU:5个实战技巧提升机器翻译评估效率 【免费下载链接】sacrebleu Reference BLEU implementation that auto-downloads test sets and reports a version string to facilitate cross-lab comparisons 项目地址: https://gitcode.com/gh_mirrors/s…...

从硬件电路深入理解计算机中断机制:8088到现代中断控制器
1. 项目概述:从硬件视角重新认识中断在计算机的世界里,中断(Interrupt)是一个既基础又至关重要的概念。它就像是程序世界里的“紧急呼叫”系统,允许CPU这个“大管家”在埋头处理日常事务(执行主程序&#x…...

数字孪生+高斯泼溅+CIMPro孪大师,打造申报“硬通货”
当前,2026年全国智能工厂梯度培育申报窗口期正在密集推进中。从四川、江苏到福建、安徽,各地工信部门纷纷下发《关于做好2026年度智能工厂梯度培育有关工作的通知》,2025年至2027年是基础级、卓越级、领航级智能工厂建设的三年关键窗口期。你…...

【亲测免费】 轻松转换:Hex文件转Bin文件工具推荐
轻松转换:Hex文件转Bin文件工具推荐 【下载地址】hex文件转bin文件工具 本仓库提供了一个用于将.hex文件转换为.bin文件的工具。该工具包含源代码,用户只需将.hex文件拖放到hex2bin.exe上,即可自动生成对应的.bin文件 项目地址: https://gi…...

CVBS转BT656/BT601,能成熟、应用广泛的低功耗视频解码器
GM7150是一款低功耗、9位NTSC/PAL视频解码器,由成都振芯科技股份有限公司生产。该芯片采用CMOS工艺,通过IC总线与PC或DSP相连构成应用系统。它内部包含1个模拟处理通道,能实现CVBS、S-Video视频信号源选择、A/D转换、自动钳位、自动增益控制(…...

告别轮询!STM32CubeMX配置DMA串口收发485数据,并详解HAL库回调函数使用避坑
STM32CubeMX实战:DMA驱动RS485通信与HAL库回调机制深度解析 当我们需要在工业环境中实现稳定可靠的串行通信时,RS485总线因其抗干扰能力强、传输距离远等优势成为首选。而STM32系列MCU配合HAL库的开发模式,能够显著提升开发效率。本文将彻底改…...

如何快速清理Mac残留文件:免费开源工具终极指南
如何快速清理Mac残留文件:免费开源工具终极指南 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经遇到过这样的困扰?明明已经…...

BSS138I现货供应
在当今快速发展的电子行业中,BSS138I MOSFET作为一款广受欢迎的小信号N沟道MOSFET,因其低导通电阻、高可靠性和紧凑的SOT-23封装而备受青睐。对于需要采购BSS138I的客户来说,选择一个可靠的供应商至关重要。本文将深入探讨为何深圳市粤科源兴…...