pg数据表同步到hive表数据压缩总结
1、背景
pg库存放了大量的历史数据,pg的存储方式比较耗磁盘空间,pg的备份方式,通过pgdump导出后,进行gzip压缩,压缩比大概1/10,随着数据的积累磁盘空间告警。为了解决pg的压力,尝试采用hive数据仓库存数,利用hive支持的parquet列式存储,同时支持lzo、none、uncompressed、brotil、snappy和gzip的压缩算法,更节省空间。pg同步到hive可以利用sqoop,sqoop的原理是将pg的表按一定的策略进行分批,然后并行导入以实现对大表的同步,本文尝试用spark对pg表进行读取,然后按指定的格式写入hdfs,然后与hive表进行绑定。
2、方案
2.1 spark读取pg的方法
(1)spark.read.jdbc(url, table, props)以该方式读取,默认只有一个分区,即单线程读取所有数据。该方式主要是表数据量小的本地测试,容易出现OOM问题。
(2)spark.read.jdbc(url, table, column, lower, upper, parts, props),以该方式读取,需要指定一个上届和下届,和一个分区数以及分区字段。但是这里注意,该分区字段必须是Int/Long的数值型,且该字段最好有索引,不然每个分区都是全表扫,且该方法只能全量读,比如该表有1000条记录,指定了下届是1,上届100,那么还是会读取全量1000的数据。所以该方式可以作为全量读取大表的一个方式,因为该方法会以多分区去读
(3)spark.read.jdbc(url, table, predicates, props)以该方式读取,需要指定一批分区条件这些分区条件会拼装到where后进行读取。这里注意,该条件字段可以是任意字段,但该字段最好有索引,不然每个并发都是全表扫,且该方法可以支持下推limit逻辑,比如该表有1000条记录,指定了根据id过滤,过滤条件是: id >= 1 and id <= 10,那么该方式只会读取10条记录,且可以按指定的分区去读。所以该方式可以作为读取超大表的一个方式,非常建议读取大表直接用该方式读取。
2.2 spark的parquet列式存储及压缩算法的对比
parquet是一种列式存储嵌套包含嵌套结构的数据集。RowGroup首先,要存储的对象是一个数据集,而这个数据集往往包含上亿条record,所以会进行一次水平切分,把这些record切成多个“分片”,每个分片被称为Row Group。为什么要进行水平切分?虽然Parquet的官方文档没有解释,但我认为主要和HDFS有关。因为HDFS存储数据的单位是Block,默认为128m。如果不对数据进行水平切分,只要数据量足够大(超过128m),一条record的数据就会跨越多个Block,会增加很多IO开销。Parquet的官方文档也建议,把HDFS的block size设置为1g,同时把Parquet的parquet.block.size也设置为1g,目的就是使一个Row Group正好存放在一个HDFS Block里面;Column Chunk在水平切分之后,就轮到列式存储标志性的垂直切分了。切分方式和上文提到的一致,会把一个嵌套结构打平以后拆分成多列,其中每一列的数据所构成的分片就被称为Column Chunk。最后再把这些Column Chunk顺序地保存。Page把数据拆解到Column Chunk级别之后,其结构已经相当简单了。对Column Chunk,Parquet会进行最后一次水平切分,分解成为一个个的Page。每个Page的默认大小为1m。尽管Parquet的官方文档又一次地没有解释,我认为主要是为了让数据读取的粒度足够小,便于单条数据或小批量数据的查询。因为Page是Parquet文件最小的读取单位,同时也是压缩的单位,如果没有Page这一级别,压缩就只能对整个Column Chunk进行压缩,而Column Chunk如果整个被压缩,就无法从中间读取数据,只能把Column Chunk整个读出来之后解压,才能读到其中的数据。
2.3 spark的partition的分区原理
HashPartitioner:一般是默认分区器,分析源码可知是按key求取hash值,再对hash值除以分区个数取余,如果余数<0,则用余数+分区的个数,最后返回的值就是这个key所属的分区ID。
RangePartitioner:由于HashPartitioner根据key值hash取模方法可能导致每个分区中数据量不均匀,RangePartitioner则尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,也就是说一个分区中的元素肯定都是比另一个分区内的元素小或者大;但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。参考:https://www.iteblog.com/archives/1522.html
GridPartitioner:一个网格Partitioner,采用了规则的网格划分坐标,numPartitions等于行和列之积,一般用于mlib中。
PartitionIdPassthrough:一个虚拟Partitioner,用于已计算好分区的记录,例如:在(Int, Row)对的RDD上使用,其中Int就是分区id。
CoalescedPartitioner:把父分区映射为新的分区,例如:父分区个数为5,映射后的分区起始索引为[0,2,4],则映射后的新的分区为[[0, 1], [2, 3], [4]]
PythonPartitioner:提供给Python Api的分区器
2.3 parquet文件格式与hive表的绑定
hive表的建表语句要与pg库保持一致,parquet是一种列式存储,同时可以按gz进行压缩。需要hive表在创建的时候指定Serde,Hive Serde用来做序列化和反序列化,构建在数据存储和执行引擎之间,对两者实现解耦,对于分隔符,写入hdfs文件存入的是parquet格式,org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe,以行为\n,列为^A(\001)为分隔符,hive表是可以解析hdfs的,SerDe支持parquet。
3、 碰到的问题及解决
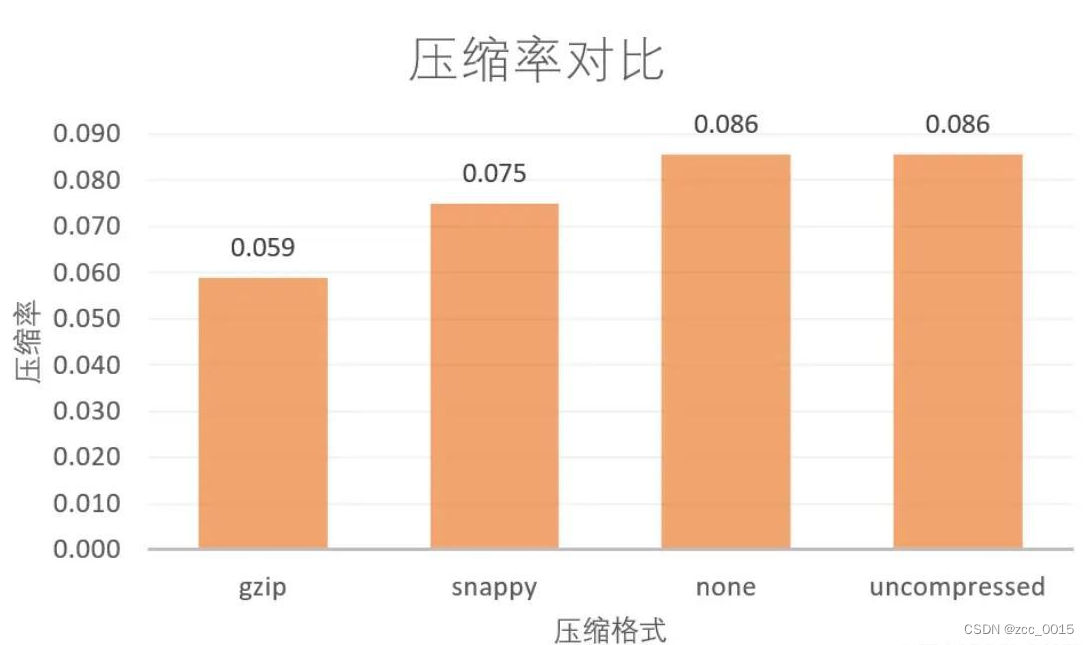
3.1 如何让spark的parquet格式使用gzip压缩
parquet默认采用的是snappy压缩算法,为了使得输出格式为gz.parquet,需要指定参数:
--conf spark.sql.parquet.compression.codec=gzip
3.2解决parquet.io.ParquetDecodingException: Can not read value at 0 in block -1 in file
该问题涉及到对decimal数据的支持问题。需要设置:
--conf spark.sql.parquet.writeLegacyFormat=true
该该参数(默认false)的作用:
(1)设置为true时,数据会以Spark1.4和更早的版本的格式写入。比如decimal类型的值会被以Apache Parquet的fixed-length byte array格式写出,该格式是其他系统例如Hive、Impala等使用的。
(2)设置为false时,会使用parquet的新版格式。例如,decimals会以int-based格式写出。如果Spark SQL要以Parquet输出并且结果会被不支持新格式的其他系统使用的话,需要设置为true。
4、同步效果
spark 3.2.2 hive-3.1.3 hadoop-3.3.4
用pg自带的hash函数分桶,执行过程cpu 80%
效果:5G的pg表,同步完200M
相关文章:
pg数据表同步到hive表数据压缩总结
1、背景 pg库存放了大量的历史数据,pg的存储方式比较耗磁盘空间,pg的备份方式,通过pgdump导出后,进行gzip压缩,压缩比大概1/10,随着数据的积累磁盘空间告警。为了解决pg的压力,尝试采用hive数据…...

2023-Chrome插件推荐
Chrome插件推荐 一键管理扩展 链接 https://chromewebstore.google.com/detail/lboblnfejcmcaplhnbkkfcienhlhpnni 介绍 一键开启、禁用Chrome插件。 Checker Plus for Gmail™ 链接 https://jasonsavard.com/zh-CN/Checker-Plus-for-Gmail https://chromewebstore.goo…...
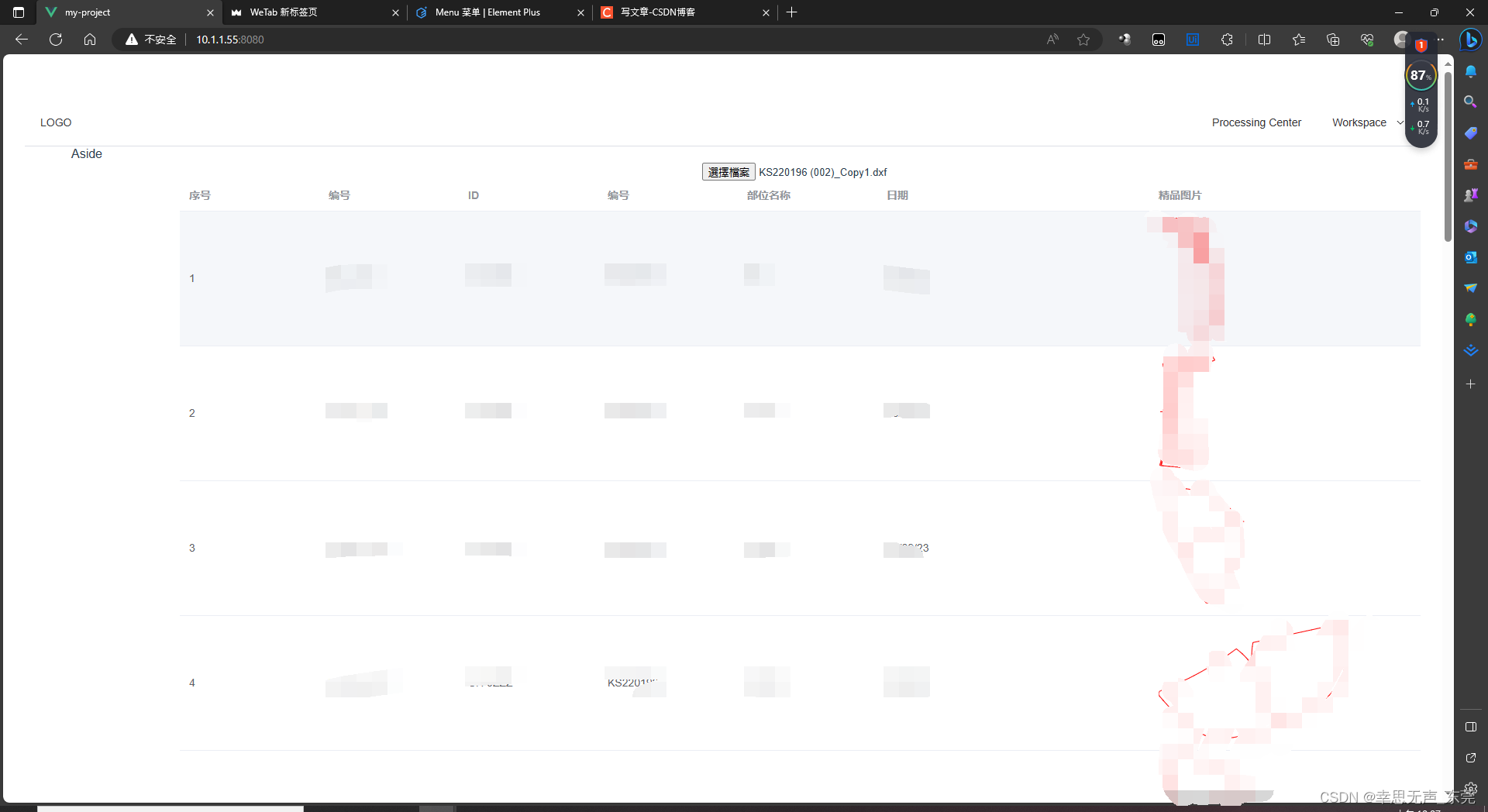
VUE使用DXFParser组件解析dxf文件生成图片
<template><div><input type"file" change"handleFileChange" /></div><el-table :data"tableData" style"width: 100%"><el-table-column prop"Control_No" label"序号" width…...

SpringBoot 集成 AKKA
文章目录 应用场景与 SpringBoot 集成示例 应用场景 AKKA 是一个用于构建高并发、分布式和容错应用程序的开源框架。它基于Actor模型,提供了强大的并发抽象和工具,适用于各种业务场景。以下是一些使用AKKA框架的常见业务场景的示例: 实时数据…...

什么是Service Worker?它在PWA中的作用是什么?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ Service Worker的作用是什么?⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前…...

【算法深入浅出】字符串匹配之 KMP 算法
KMP 算法是一种字符串匹配算法。字符串匹配算法的目标是:在字符串 s 中找到与模式串 p 相等的子串,输出其位置。例如:s “abcdef”,p “cdef”,p 在 s 中的位置是 2(从 0 开始计数)。 容易想到…...

放弃webstrom转战vscode
本来是webstrom的忠实用户,无奈webstrom要么需要在网上找一个破解版或者不断的去找激活码,且破解版和激活码的文章总是很多,但是要找到真正有效的却总是要花费不少功夫。终于忍无可忍,转战vscode。(注:文中…...

VSCode 和 CLion
文章目录 一、VSCode1、文档2、插件3、智能编写4、VSCode 与 C(1)安装(2)调试(a)使用 CMake 进行跨平台编译与调试(b)launch.json(c)传参 (3&…...

Learn Prompt- Midjourney Prompt:Prompt 提示语
基础结构 一个基本的提示可以简单到一个单词、短语或表情符号。非常短的提示将在很大程度上依赖于 Midjourney 的默认样式。 完整 prompt:可以包括一个或多个图像链接、多个文本短语或单词,以及一个或多个后缀参数 Image Prompts: 可以将图像 URL 添加…...

uvm白皮书练习_ch2_ch223_加入objection机制
UVM中通过objection机制来控制验证平台的关闭。 在每个phase中,UVM会检查是否有objection被提起(raise_ objection),如果有,那么等待这个objection被撤销(drop_objection)后停止仿真;…...

利用C++开发一个迷你的英文单词录入和测试小程序-增强功能
小玩具基本完成之后,在日常工作中,记录一些单词,然后定时再复习下,还真的有那么一点点用(毕竟自己做的小玩具)。 在使用过程中,遇到不认识的单词,总去翻译软件翻译,然后…...

kibana启动报错
1.响应 超过时间30000ms (1) docker rm elasticsearch #从docker中删除es docker rm kibana #从docker中删除kibana (2)重新安装启动es加大最大运行内存 :1024M docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e "discovery.typesingle-node" \ -…...
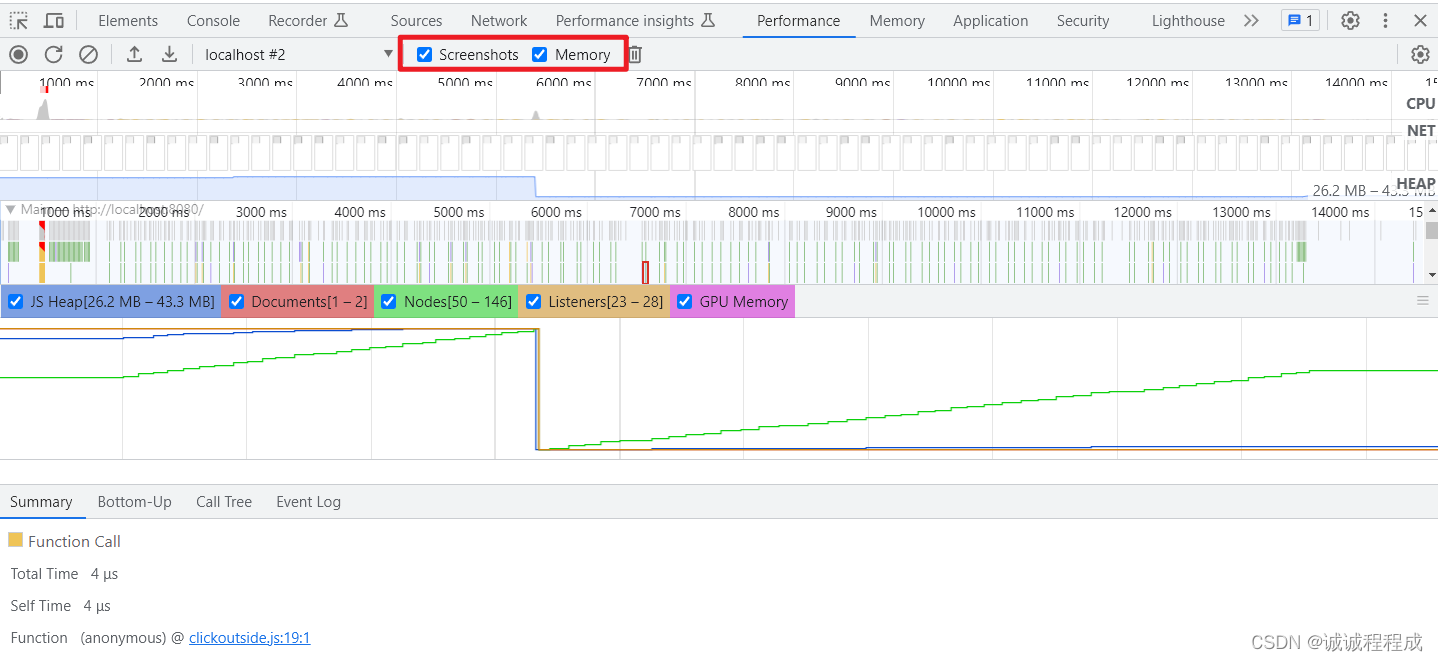
排查内存泄露
1 通过Performance确认是否存在内存泄露 一个存在内存泄露的 DEMO 代码: App.vue <template><div><button click"myFn" style"width: 200px; height: 200px;"></button><home v-if"ishow"></hom…...
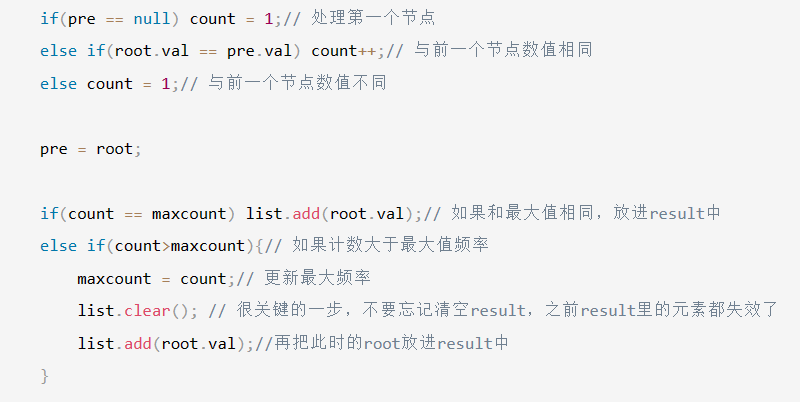
【LeetCode-简单题】501. 二叉搜索树中的众数
文章目录 题目方法一:暴力哈希方法二:利用二叉搜索树的特性(递归双指针) 题目 方法一:暴力哈希 这是针对于普通二叉树的解法 统计number出现次数 然后将次数最大的众数集 取出来 Map<Integer , Integer > map …...
MAC word 如何并列排列两张图片
系统:MAC os 参考博客 https://baijiahao.baidu.com/s?id1700824516945958911&wfrspider&forpc 步骤1 新建一个word文档和表格 修改表格属性 去掉自动重调尺寸以适应内容 插入图片 在表格的位置插入对应的图片如下 去除边框 最终结果如下...

PTA第三章作业题
文章目录 前言7-1 比较大小Ⅰ. 方法一 :直接判断法Ⅱ. 方法二:交换法 7-2 比较两个数的大小Ⅰ. 方法 :直接判断法 7-3 成绩等级Ⅰ. 方法 :直接判断法 7-4 打鱼晒网Ⅰ. 方法 :直接判断法 7-5 计算奖金Ⅰ. 方法 …...
vscode vue html 快捷键
css文件 选择多行 按下ctrl不放 按下鼠标滚轮不放(鼠标中键) 鼠标向下移动 同时修改多个相同的字符串 <style> .base-goods-item li {width: 304px;height: 404px;background-color: #eef9f4; } .base-goods-item li {display: block; } .base-…...

mysql锁相关的总结
1、参考文章 MySQL 主键索引在 RR 和 RC 隔离级别下的加锁情况总结_51CTO博客_mysql二级索引加锁 2、 show OPEN TABLES where In_use > 0; -- 类似rc的需求 show variables like innodb_locks_unsafe_for_binlog; SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX; -- …...

计算机竞赛 深度学习乳腺癌分类
文章目录 1 前言2 前言3 数据集3.1 良性样本3.2 病变样本 4 开发环境5 代码实现5.1 实现流程5.2 部分代码实现5.2.1 导入库5.2.2 图像加载5.2.3 标记5.2.4 分组5.2.5 构建模型训练 6 分析指标6.1 精度,召回率和F1度量6.2 混淆矩阵 7 结果和结论8 最后 1 前言 &…...

docker-compose搭建的mysql,如何定时备份数据
一、前言 使用docker-compose搭建的mysql中自带了mysqldump,所以在服务器上如何使用容器中的mysqldump命令是实现备份的原理,下面是主要实现的命令 docker exec -it mysql mysqldump -u root -p$mysql_password $database_name > $backup_file二、备…...

别再只会用menuconfig了!手把手教你为ESP32项目定制专属Kconfig配置菜单
从配置使用者到设计者:ESP32项目中的Kconfig高级定制指南 在ESP-IDF开发环境中,menuconfig几乎是每个开发者每天都要接触的工具。但大多数开发者仅仅停留在"使用者"层面——他们知道如何勾选选项、调整参数,却很少思考这些配置菜单…...

Office Custom UI Editor:终极指南:如何彻底改造你的Office工作界面?
Office Custom UI Editor:终极指南:如何彻底改造你的Office工作界面? 【免费下载链接】office-custom-ui-editor Standalone tool to edit custom UI part of Office open document file format 项目地址: https://gitcode.com/gh_mirrors/…...
GitGitHub实操图文详解教程(05)—git init命令)
(最新版)GitGitHub实操图文详解教程(05)—git init命令
版权声明 本文原创作者:谷哥的小弟 作者博客地址:http://blog.csdn.net/lfdfhl 1. 应用场景 git init 用于将一个普通目录初始化为 Git 仓库,从而使 Git 开始对该目录及其文件进行版本管理。 在实际开发中,常见应用场景包括: 新建本地项目 当你创建一个 Spring Boot 项目…...

前端工程化:Vite与Rollup构建优化
前端工程化:Vite与Rollup构建优化 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊前端工程化这个重要话题。作为一个全栈开发者,构建工具是日常开发中不可或缺的一部分。今天就来分享一下Vite和Rollup的构建优化技巧…...

CST仿真入门实战:Dipole天线结果解读与关键参数分析
1. Dipole天线仿真结果初探 第一次打开CST仿真软件完成Dipole天线仿真后,面对密密麻麻的结果图表,相信很多人都会感到无从下手。我刚开始接触电磁仿真时也是这样,盯着那些S参数曲线和远场辐射图发愣。其实读懂这些结果并不难,关键…...
)
【免费下载】 AD7124中文手册(非常完整)
AD7124中文手册(非常完整) 【下载地址】AD7124中文手册非常完整 AD7124-8是一款高性能模拟前端,设计用于在各种苛刻环境中实现精确的数据采集。这款芯片的特点在于其内置的高精度24位Σ-Δ模数转换器(ADC),能够灵活配置以支持8个差…...
)
【亲测免费】 探索VBA编程的利器:VBA参考手册(CHM)
探索VBA编程的利器:VBA参考手册(CHM) 【下载地址】VBA参考手册chm 本仓库提供了一个VBA参考手册的下载资源,文件格式为CHM(Compiled HTML Help)。该手册是学习和使用VBA(Visual Basic for Applications)的重…...

【NotebookLM戏剧研究辅助实战指南】:20年戏剧学者亲授AI赋能文本细读的5大黄金工作流
更多请点击: https://intelliparadigm.com 第一章:NotebookLM戏剧研究辅助的底层逻辑与学科适配性 NotebookLM 以“语义锚点驱动”为核心机制,将用户上传的原始文本(如莎士比亚手稿影印本OCR结果、梅兰芳口述史转录稿、《奥尼尔书…...

欧美客户下最后通牒:2026年起没有Sedex,订单再多也出不了货!
各位外贸老板、工厂负责人注意了!2026年,全球供应链的ESG合规风暴已经进入下半场。如果你还在做纺织品、家具、电子、玩具出口,还没搞懂Sedex和SMETA新政,很可能随时被踢出欧美客户的供应商名录!没有这块“敲门砖”&am…...

基于WiFi与OPC协议的可穿戴LED灯光同步系统设计与实现
1. 项目概述:打造你的无线光影秀发想象一下,你亲手制作的LED帽子、发光外套,甚至是手中的光绘道具,都能随着你电脑屏幕上的音乐可视化效果或视频内容同步闪烁、流动。无需复杂的编程,只需一个简单的播放指令࿰…...