什么是哈希表?如何使用哈希表进行数据存储和查找?
什么是哈希表?
哈希表(Hash Table),也被称为散列表,是一种用于存储键值对数据的数据结构。它是一种非常高效的数据结构,可以实现快速的数据插入、查找和删除操作。哈希表的核心思想是通过将键(key)映射到一个固定大小的数组(通常称为哈希表或哈希桶)来实现高效的数据访问。
哈希表的运作原理基于一个重要的概念,即哈希函数(Hash Function)。哈希函数负责将给定的键转换成一个索引,这个索引用于在数组中定位值。在哈希表中,每个键都对应一个唯一的索引,因此你可以以常量时间复杂度(O(1))访问任何键的值。
下面让我们更深入地了解哈希表的工作原理和如何使用它进行数据存储和查找。
哈希函数的作用
哈希表的核心在于哈希函数。哈希函数接受一个键作为输入,然后返回一个索引,这个索引用于在数组中查找或存储值。好的哈希函数应该满足以下条件:
-
一致性:对于相同的输入键,哈希函数应该始终返回相同的索引。
-
均匀性:哈希函数应该尽可能均匀地分布键,以减少冲突(多个键映射到同一个索引)的可能性。
-
高效性:哈希函数的计算速度应该尽可能快,以确保快速的数据访问。
哈希冲突
虽然哈希表是一种高效的数据结构,但它并不是完美的。由于键的数量可能大于哈希表的大小,不同的键可能映射到相同的索引,这种情况被称为哈希冲突。处理哈希冲突是使用哈希表时需要考虑的重要问题。
有多种方法可以处理哈希冲突,以下是两种常见的方法:
-
链地址法(Chaining):在每个哈希桶中存储一个链表或其他数据结构,用于存储冲突的键值对。当发生冲突时,新的键值对被添加到链表的末尾。这种方法适用于允许多个键映射到同一个索引的情况。
-
开放地址法(Open Addressing):在哈希桶中尝试寻找下一个可用的空槽来存储冲突的键值对。有多种开放地址法的变体,如线性探测、二次探测和双散列等。这种方法适用于尽量减少冲突的情况。
哈希表的应用
哈希表广泛应用于计算机科学和编程中,以下是一些常见的应用场景:
-
字典和集合:编程语言中的字典(Dictionary)和集合(Set)通常使用哈希表来实现。它们用于快速查找和存储键值对数据。
-
缓存:缓存通常使用哈希表来存储已经计算过的结果,以便在后续的计算中重复使用。这可以大大提高程序的性能。
-
数据库索引:数据库管理系统使用哈希表来加速数据的检索。索引通常是基于表中某一列的哈希值构建的。
-
哈希表算法:一些哈希算法本身就是使用哈希表来实现的,例如SHA-1和MD5等散列函数。
如何使用哈希表进行数据存储和查找?
现在让我们详细了解如何使用哈希表进行数据存储和查找的步骤:
步骤1:选择合适的数据结构
首先,你需要选择一个适合的数据结构来实现哈希表。通常,哈希表是一个固定大小的数组,数组中的每个元素称为一个哈希桶,每个哈希桶可以存储一个键值对。你可以选择使用编程语言提供的数组或列表来表示哈希表。
步骤2:设计哈希函数
接下来,你需要设计一个哈希函数,它将键映射到哈希表的索引。好的哈希函数应该满足一致性、均匀性和高效性的要求。通常,哈希函数会采用键的某种特性来计算哈希值,例如:
- 如果键是整数,可以直接使用它作为哈希值。
- 如果键是字符串,可以计算字符串的哈希码(hash code)作为哈希值。
- 如果键是自定义对象,可以使用对象的某些属性计算哈希值。
例如,以下是一个简单的哈希函数,将整数键映射到哈希表的索引:
def hash_function(key, table_size):return key % table_size
步骤3:初始化哈希表
在开始使用哈希表之前,你需要初始化它。这通常包括创建一个固定大小的数组,并将每个哈希桶初始化为空。具体初始化过程取决于编程语言和数据结构的实现方式。
步骤4:插入数据
要向哈希表中插入数据,首先将键传递给哈希函数,计算出相应的索引。然后,在该索引处的哈希桶中存储键值对。如果发生哈希冲突,根据所选的冲突解决方法(如链地址法或开放地址法),将键值对插入到冲突解决数据结构中。
以下是一个简单的示例,演示如何向哈希表中插入数据:
# 初始化哈希表
table_size = 10
hash_table = [None] * table_size# 哈希函数
def hash_function(key):return key % table_size# 插入数据
def insert(hash_table, key, value):index = hash_function(key)if hash_table[index] is None:hash_table[index] = [(key, value)] # 使用列表存储冲突的键值对else:hash_table[index].append((key, value)) # 添加到已有的键值对列表# 插入数据
insert(hash_table, 5, "apple")
insert(hash_table, 15, "banana")
insert(hash_table, 25, "cherry")
步骤5:查找数据
要查找哈希表中的数据,首先将键传递给哈希函数,计算出相应的索引。然后,在该索引处查找键值对。如果发生哈希冲突,根据所选的冲突解决方法,在冲突解决数据结构中查找键值对。
以下是一个示例,演示如何查找哈希表中的数据:
# 查找数据
def find(hash_table, key):index = hash_function(key)if hash_table[index] is not None:for k, v in hash_table[index]:if k == key:return v # 找到匹配的键,返回对应的值return None # 未找到键,返回None# 查找数据
result = find(hash_table, 15)
if result is not None:print("找到结果:", result)
else:print("未找到结果")
步骤6:删除数据
要删除哈希表中的数据,首先将键传递给哈希函数,计算出相应的索引。然后,在该索引处查找键值对并将其删除。如果发生哈希冲突,根据所选的冲突解决方法,在冲突解决数据结构中删除键值对。
以下是一个示例,演示如何删除哈希表中的数据:
# 删除数据
def delete(hash_table, key):index = hash_function(key)if hash_table[index] is not None:for i, (k, v) in enumerate(hash_table[index]):if k == key:del hash_table[index][i] # 找到匹配的键,删除对应的键值对# 删除数据
delete(hash_table, 15)
总结
哈希表是一种高效的数据结构,用于存储和查找键值对数据。它的核心思想在于哈希函数,它将键映射到固定大小的数组中,以实现快速的数据访问。虽然哈希表在处理大量数据时非常有效,但需要谨慎设计好的哈希函数和适当的冲突解决策略。希望这个详细的解答能够帮助你理解哈希表的工作原理和如何使用它进行数据存储和查找。继续学习和实践,你将能够更深入地掌握这个重要的数据结构。
相关文章:

什么是哈希表?如何使用哈希表进行数据存储和查找?
什么是哈希表? 哈希表(Hash Table),也被称为散列表,是一种用于存储键值对数据的数据结构。它是一种非常高效的数据结构,可以实现快速的数据插入、查找和删除操作。哈希表的核心思想是通过将键(…...

脑机接口的发展研究
1.调研对象:智能制造人机交互; 2.作业内容,关于个人所选技术的近期发展(2020-2023年)期间的相关技术问题和研究进展; 3.内容结构,分为摘要介绍(100字以内),近…...
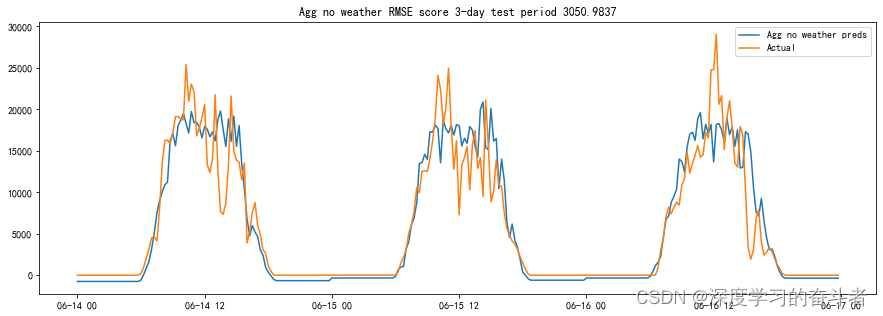
短期光伏发电量短期预测(Python代码,先对异常值处理,再基于XGBoost模型预测)
一.代码流程(运行效果:短期光伏发电量短期预测(Python代码,先对异常值处理,再基于XGBoost模型预测)_哔哩哔哩_bilibili 模型流程: 导入所需的库,包括NumPy、Pandas、Matplotlib、Sea…...
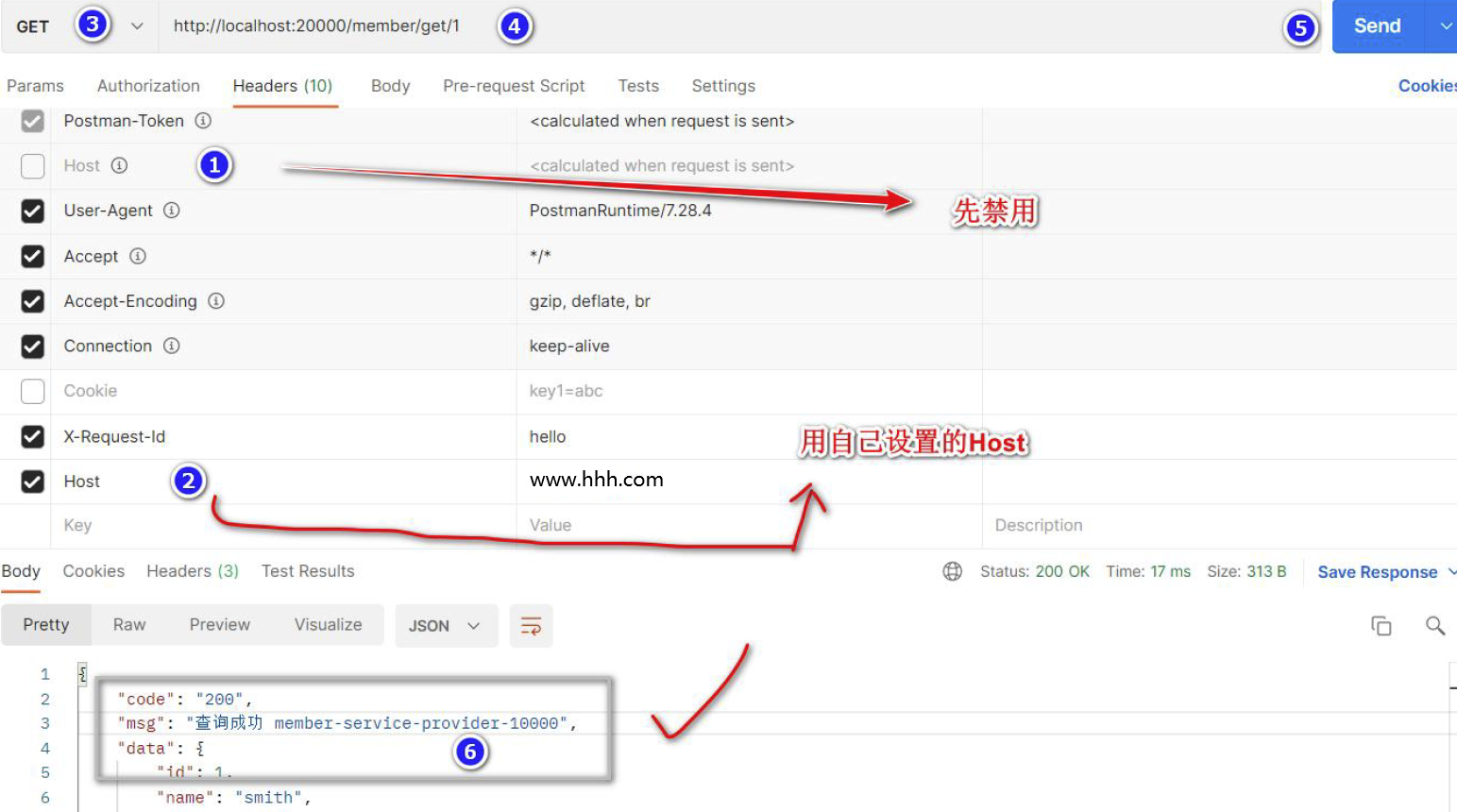
SpringCloud Gateway--Predicate/断言(详细介绍)中
😀前言 本篇博文是关于SpringCloud Gateway–Predicate/断言(详细介绍)中,希望你能够喜欢 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章可以…...

Linux内核启动流程-第一阶段汇编流程简介
一. Linux启动流程 看完 Linux 内核的顶层 Makefile 以后再来看 Linux 内核的大致启动流程, Linux 内核的启 动流程要比 uboot 复杂的多,涉及到的内容也更多。 本文中,我们就大致的了解一下 Linux 内 核的启动流程。 要分析 Li…...

SpringBoot-Druid
目录 1.什么是Druid 2.主要优点和原因 3.误区 4.Part代码 0.pom 1.Spring.datasource.type: com.alibaba.druid.pool.DruidDataSource 2.Druid用Jasypt加密任意内容 EnableEncryptableProperties开启加密注解 3.Druid监控平台 1.什么是Druid Druid 是一个开源的数据库…...

PAT甲级真题1006:签到与签出
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…...
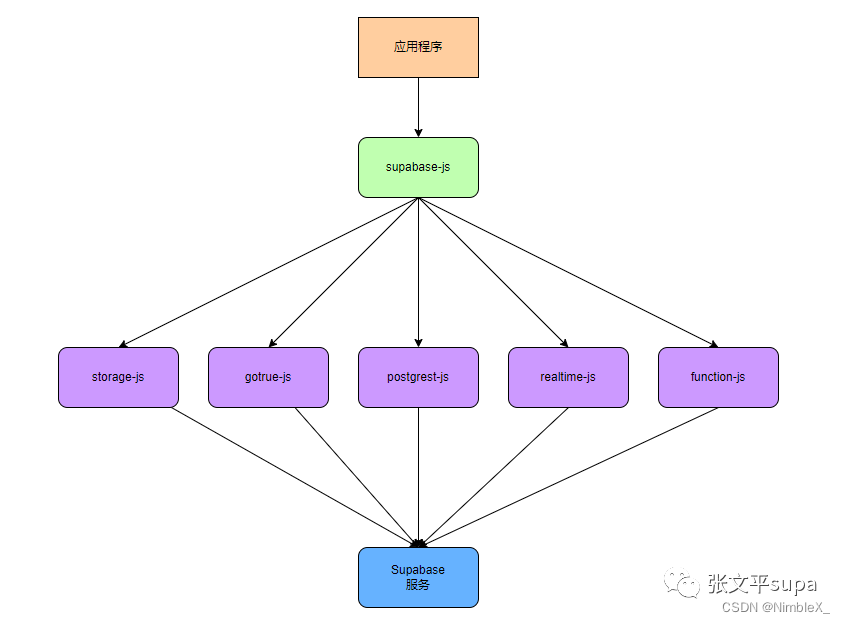
【架构篇】Supabase架构和功能介绍
Supabase是什么 Supabase将自己定位为Firebase的开源替代品,提供了一套工具来帮助开发者构建web或移动应用程序。Supabase是建立在Postgres之上的,Postgres是一个免费的开源数据库,被认为是世界上最稳定、最先进的数据库之一。Supabase对标F…...

Github主页无法打开和Assets转圈
1、cmd启动命令行 2、github.com打不开,多刷新几遍。等成功打开时,命令行输入nslookup github.com,把非权威应答下的IP地址复制到C:\Windows\System32\drivers\etc\hosts里,如查到的IP是192.30.255.112,则填写 192.30.255.112 gi…...
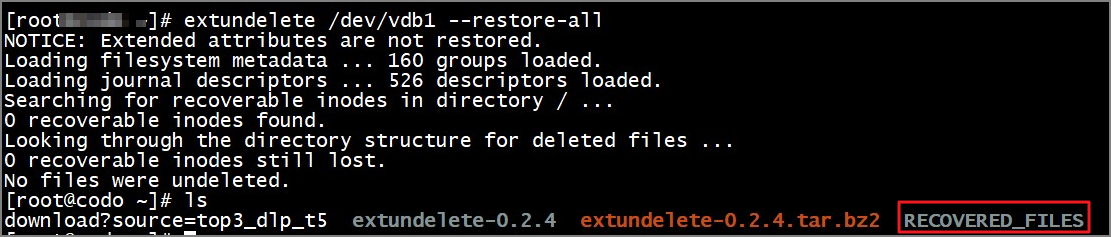
rm误删文件恢复
rm误删文件恢复 问题描述安装extundeleteyum安装extundelete编译安装extundelete 常用参数动作(action): 尝试数据恢复前置条件卸载磁盘分区查看被删除数据信息 恢复文件恢复指定inode号文件恢复指定文件名恢复指定目录恢复所有可恢复文件恢复指定时间的文件恢复指定…...

爬虫 — 多线程
目录 一、多任务概念二、实现多任务方式1、多进程 (Multiprocessing)2、多线程(Multithreading)3、协程(Coroutine) 三、多线程执行顺序四、多线程的方法1、join()2、setDaemon()3、threading.enumerate() …...
)
Cython 笔记 (Python/Jython)
目录 1. Cython 笔记 (Python)2. python 加速库 cython 简介2.1. Cython 是什么?2.2. 如何安装 Cython?2.3. 简单示例2.4. 性能比对2.5. 总结 3. PYTHON, CYTHON, JYTHON, IRONPYTHON 的区别 (注意: 此篇有误导,表述不一定正确,只提供一个方向)3.1. PY…...

[React] react-hooks如何使用
react-hooks思想和初衷,也是把组件,颗粒化,单元化,形成独立的渲染环境,减少渲染次数,优化性能。 文章目录 1.为什么要使用hooks2.如何使用hooks2.1 useState2.2 useEffect2.3 useLayoutEffect2.4 useRef2.5…...
多个pdf合并成一个文件,3个方法合并pdf
如何把多个pdf合并成一个文件?在我们日常的工作中,经常会遇到一些需要处理的文件,其中包括PDF文件。特别是当我们需要将多个PDF文件合并成一个PDF文件时,会面临一些困难。这样的情况下,我们的阅读能力会受到限制&#…...

代码随想录 动态规划Ⅸ
198. 打家劫舍 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 给定一个代表每个…...

【数据结构】散列表(哈希表)的学习知识总结
目录 1、散列表 2、散列函数 2.1 定义 2.2 散列函数的构造 2.2.1 除留余数法 2.2.2 直接定址法 2.2.3 数字分析法 2.2.4 平方取中法 3、冲突(碰撞) 4、处理冲突的方法 4.1 拉链法(链接法) 4.2 开放定址法 5、C语言…...
2023智慧云打印小程序源码多店铺开源版 +前端
智慧自助云打印系统/智慧云打印小程序源码 前端 这是一款全新的基于Thinkphp的最新自助打印系统,最新UI界面设计的云打印小程序源码...
利用亚马逊 云服务器 EC2 和S3免费套餐搭建私人网盘
网盘是一种在线存储服务,提供文件存储,访问,备份,贡献等功能,是我们日常中不可或缺的一种服务。很多互联网公司都为个人和企业提供免费的网盘服务。但这些免费服务都有一些限制,比如限制下载速度࿰…...

数据分析技能点-数据的种类
在日常生活中,数据无处不在。当你去超市购物时,你可能会注意到商品的价格、重量、口味等;当你在社交媒体上浏览时,你可能会注意到好友的点赞数、评论等。这些都是数据的一种形式,而了解这些数据的种类和特点有助于我们更好地理解和使用它们。 数据的基本分类 数据大致可…...

解读:ISO 14644-21:2023《洁净室及相关受控环境:悬浮粒子采样》发布指导粒子采样!
药品洁净实验室环境监测结果是否满足微生物检测需求,直接决定检测结果的有效性准确性,进行药品微生物检测,必须对实验环境进行日常和定期监测,其内容包括非生物活性的空气悬浮粒子数及有生物活性的微生物监测。 悬浮粒子监测是保证…...

FPGA加速储层计算:DPRR设计与时序数据处理优化
1. 储层计算与FPGA加速概述储层计算(Reservoir Computing)作为递归神经网络(RNN)的一种高效训练范式,近年来在时序数据处理领域展现出独特优势。与传统RNN需要调整所有连接权重不同,储层计算的核心思想是仅…...

数据表结构管理:RPFM的Schema更新架构设计与安全实践
数据表结构管理:RPFM的Schema更新架构设计与安全实践 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: https://gitc…...

华为HCSP认证备考全攻略:5G网优方向
华为HCSP(Huawei Certified Service Professional)认证是5G网优行业的重要资质认证。本文从考试内容、备考策略、真题分析三个维度,帮你一次性通过考试。一、HCSP认证体系概览1.1 认证等级等级全称定位考试难度薪资加成HCIAHuawei Certified …...

基于合宙Air001的交互式地球名片:从硬件焊接、Arduino编程到触摸优化
1. 项目概述与核心思路最近在创客圈子里,合宙的Air001开发板可以说是火得一塌糊涂。包装设计得挺酷,价格更是香到没朋友,最关键的是它完美支持Arduino IDE开发,对于咱们这些习惯了Arduino生态的玩家来说,上手门槛几乎为…...
)
NotebookLM图书馆学研究风险清单(含3类学术伦理红线+4种元数据污染场景)
更多请点击: https://kaifayun.com 第一章:NotebookLM图书馆学研究风险清单(含3类学术伦理红线4种元数据污染场景) NotebookLM 作为面向研究者的AI增强型笔记工具,其在图书馆学实证研究中的深度应用正引发对学术规范与…...
)
用Java+GDAL+OpenCV玩转遥感图像:手把手教你实现Landsat标准假彩色合成(附完整代码)
JavaGDALOpenCV遥感图像处理实战:Landsat标准假彩色合成全流程解析 遥感图像处理正逐渐从专业软件向通用编程语言生态迁移。对于熟悉Java的开发者而言,利用GDAL和OpenCV这两个强大的库,完全可以构建自主可控的遥感处理流程。本文将完整展示如…...

杰理之满电后每个耳机功耗在20UA到30UA 处理方法【篇】
下拉200K电阻要开启...

AMD Ryzen处理器终极调试指南:SMU Debug Tool实战技巧与完整解决方案
AMD Ryzen处理器终极调试指南:SMU Debug Tool实战技巧与完整解决方案 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...

晶圆为何是圆形而芯片是方形?揭秘半导体制造的工程智慧
1. 项目概述:一个看似简单却充满工程智慧的谜题“为什么晶圆是圆的,而芯片是方的?” 这个问题,乍一听像是半导体行业里一个有趣的脑筋急转弯,但它背后却串联起了从材料科学、物理化学到精密制造、经济学乃至数学几何的…...

智慧树网课自动化学习插件:三步告别手动刷课的完整指南
智慧树网课自动化学习插件:三步告别手动刷课的完整指南 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台冗长的网课视频而烦恼吗࿱…...