Linux高性能服务器编程 学习笔记 第八章 高性能服务器程序框架
TCP/IP协议在设计和实现上没有客户端和服务器的概念,在通信过程中所有机器都是对等的。但由于资源(视频、新闻、软件等)被数据提供者所垄断,所以几乎所有网络应用程序都采用了下图所示的C/S(客户端/服务器)模型,所有客户端都通过访问服务器来获取所需资源:
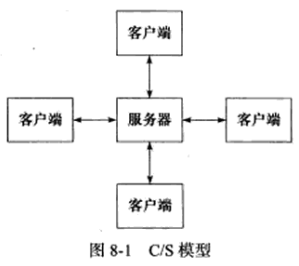
采用C/S模型的TCP服务器和客户端的工作流程:
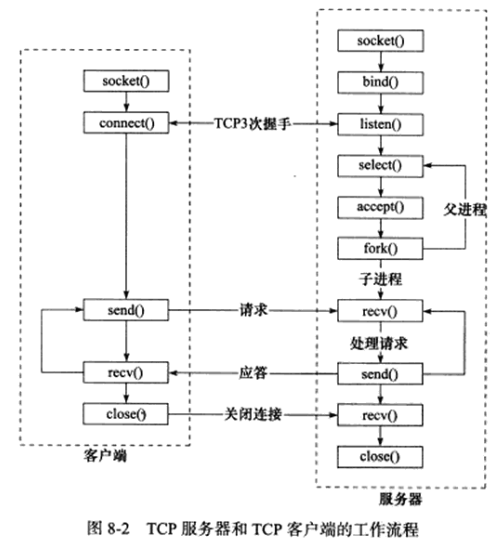
C/S模型中,服务器启动后,首先创建一个或多个监听socket,并调用bind将其绑定到服务器感兴趣的端口上,然后调用listen等待客户连接,之后客户端就可以调用connect向服务器发起连接了。由于客户连接请求是随机到达的异步事件,服务器需要使用某种IO模型来监听这一事件,上图中,服务器使用的是IO复用技术(select系统调用),当监听到连接请求后,服务器就调用accept函数接受它,并分配一个逻辑单元来服务新的连接,逻辑单元可以是新创建的子进程、子线程或其他,上图中,服务器给客户端分配的逻辑单元是由fork系统调用创建的子进程。逻辑单元读取客户请求,处理该请求,然后将处理结果返回给客户端,客户端接收到服务器反馈的结果后,可以继续向服务器发送请求,也可以立即主动关闭连接。如果客户端主动关闭连接,则服务器执行被动关闭连接。至此,双方的通信结束。服务器在处理一个客户请求的同时还会继续监听其他客户请求,否则就变成了效率低下的串行服务器(必须先处理完前一个客户的请求,才能继续处理下一个客户请求)了。
C/S模型适合资源相对集中的场合,且它的实现也很简单,但其缺点也很明显:服务器是通信的中心,当访问量过大时,可能所有客户都将得到很慢的响应。P2P模型解决了这个缺点。
P2P(Peer to Peer,点对点)模型比C/S模型更符合网络通信的实际情况,它摒弃了以服务器为中心的格局,让网络上所有主机重新回归对等的地位,P2P模型如下图所示:
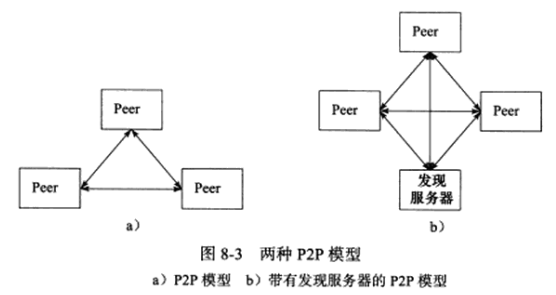
P2P模型使得每台机器在使用服务的同时也给别人提供服务,这样资源能充分、自由地共享。云计算机群(一组云计算资源的集合)可以看做P2P模型的一个典范,但P2P模型也有缺点:当用户之间传输的请求过多时,网络的负载将加重。
图8-3a所示的P2P模型中,主机之间很难互相发现,所以实际使用的P2P模型通常有一个专门的发现服务器,如图8-3b所示,这个发现服务器通常提供查找服务(甚至还可以提供内容服务),使每个客户都能尽快找到自己需要的资源。
从编程角度讲,P2P模型可看作C/S模型的扩展,每台主机既是客户端,又是服务器。
虽然服务器程序种类繁多,但其基本框架都一样,不同之处在于逻辑处理,基本框架见下图:
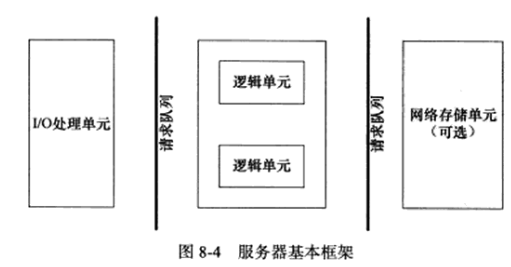
上图既能用来描述一台服务器,也能用来描述一个服务器机群,两种情况下各个部件的含义和功能见下表:


IO处理单元是服务器管理客户连接的模块,它通常要完成以下工作:等待并接受新的客户连接,接收客户数据,将服务器响应数据返回给客户端。但数据的收发不一定在IO处理单元中执行,也可能在逻辑单元中执行,具体在何处执行取决于事件处理模式。对一个服务器机群来说,IO处理单元是一个专门的接入服务器,它实现负载均衡,从所有逻辑服务器中选取符合最小的一台来为新客户服务。
一个逻辑单元通常是一个进程或线程,它分析并处理客户数据,然后将结果传递给IO处理单元或直接发送给客户端(取决于事件处理模式)。对服务器机群而言,一个逻辑单元本身就是一台逻辑服务器,服务器通常拥有多个逻辑单元,以实现对多个客户任务的并行处理。
网络存储单元可以是数据库、缓存、文件,甚至是一台独立的服务器。但它不是必须得,如ssh、telnet等登录服务器就不需要这个单元。
请求队列是各个单元之间的通信方式的抽象,IO处理单元接收到客户请求时,需要以某种方式通知一个逻辑单元来处理该请求,同样,多个逻辑单元同时访问一个存储单元时,也需要某种机制来协调处理竞态条件。请求队列通常被实现为池的一部分。对于服务器机群而言,请求队列是各台服务器之间预先建立的、静态的、永久的TCP连接,这种TCP连接能提高服务器之间交换数据的效率,因为它避免了动态建立TCP连接导致的额外的系统开销。
socket在创建的时候默认是阻塞的,我们可以给socket系统调用的第2个参数传递SOCK_NONBLOCK标志,或通过fcntl系统调用的F_SETFL命令,将其设置为非阻塞的。阻塞和非阻塞的概念能应用于所有文件描述符,而不仅仅是socket。我们称阻塞的文件描述符为阻塞IO,称非阻塞的文件描述符为非阻塞IO。
针对阻塞IO执行的系统调用可能因为无法立即完成而非操作系统挂起,直到等待的事件发生为止,比如,客户端通过connect函数向服务器发起连接时,connect函数首先发送同步报文段给服务器,然后等待服务器返回确认报文段,如果服务器的确认报文端没有立即到达客户端,则connect函数将被挂起,直到客户端收到确认报文段并唤醒connect函数。socket的基础API中,可能被阻塞的系统调用包括accept、send、recv、connect。
针对非阻塞IO执行的系统调用总是立即返回,而不管事件是否已经发生。如果事件没有立即发生,这些系统调用返回-1,这和出错返回相同,此时我们要根据errno来区分是出错还是非阻塞情况,对accept、send、recv函数而言,事件未发生时errno通常被设置成EAGAIN(意为再来一次)或者EWOULDBLOCK(意为期望阻塞),对connect函数而言,errno则被设置成EINPROGRESS(意为在处理中)。
我们只有在时间已经发生的情况下操作非阻塞IO(读、写等),才能提高程序的效率,因此,非阻塞IO通常要和其他IO通知机制一起使用,比如IO复用和SIGIO信号。
IO复用是最常使用的IO通知机制,它指的是,应用进程通过IO复用函数向内核注册一组事件,内核通过IO复用函数把其中就绪的事件通知给应用程序。Linux上常用的IO复用函数是select、poll、epoll_wait。IO复用函数本身是阻塞的,它能提高程序效率的原因在于它们具有同时监听多个IO事件的能力。
SIGIO信号也能用来报告IO事件,我们可以为一个目标文件描述符指定宿主进程,被指定的宿主进程将捕获到SIGIO信号,这样,当目标文件描述符上有事件发生时,SIGIO信号的信号处理函数将被触发,我们就能在该信号处理函数中对目标文件描述符执行非阻塞IO操作了。
理论上,阻塞IO、IO复用、信号驱动IO都是同步IO模型,因为在这三种IO模型中,IO的读写操作,都是在IO事件发生之后,由应用进程来完成的。而POSIX规范所定义的异步IO模型中,用户可以直接对IO执行读写操作,这些操作告诉内核用户读写缓冲区的位置,以及IO操作完成后内核通知应用进程的方式。异步IO的读写操作总是立即返回,而不论IO是否是阻塞的,因为真正的读写操作已经由内核接管。同步IO模型要求用户代码自行执行IO操作(将数据从内核缓冲区读入用户缓冲区,或将数据从用户缓冲区写入内核缓冲区),而异步IO机制则由内核来执行IO操作(数据在内核缓冲区和用户缓冲区之间的移动是由内核在“后台”完成的)。同步IO向应用进程通知的是IO就绪事件,而异步IO向应用进程通知的是IO完成事件。Linux环境下,aio.h头文件中定义的函数提供了对异步IO的支持。
几种IO模型的差异:

服务器进程通常需要处理三类事件:IO事件、信号、定时事件。我们先整体介绍一下两种高效的事件处理模式Reactor和Proactor。
同步IO模型通常用于实现Reactor模式,异步IO模型则用于实现Proactor模式,也可用同步IO方式模拟出Proactor模式。
Reactor模式要求主线程(IO处理单元)只负责监听文件描述符上是否有事件发生,有的话立即将该事件通知工作线程(逻辑单元),除此之外,主线程不做任何其他实质性的工作。读写数据、接受新连接、处理客户请求均在工作线程中完成。
使用同步IO模型(以epoll_wait函数为例)实现的Reactor模式的工作流程是:
1.主线程往epoll内核事件表中注册socket上的读就绪事件。
2.主线程调用epoll_wait等待socket上有数据可读。
3.当socket上有数据可读,epoll_wait函数通知主线程,主线程将socket可读事件放入请求队列。
4.睡眠在请求队列上的某个工作线程被唤醒,它从socket读取数据,并处理客户请求,然后往epoll内核事件表中注册该socket上的写就绪事件。
5.主线程调用epoll_wait等待socket可写。
6.当socket可写时,epoll_wait函数通知主线程,主线程将socket可写事件放入请求队列。
7.睡眠在请求队列上的某个工作线程被唤醒,它往socket上写入服务器处理客户请求的结果。
Reactor模式的工作流程:
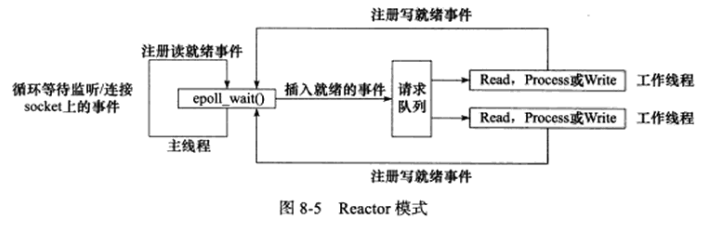
上图中,工作线程从请求队列中取出事件后,将根据事件的类型决定如何处理它:对于可读事件,执行读数据和处理请求的操作;对于可写事件,执行写数据操作。因此上图中没必要区分读工作线程和写工作线程。
Proactor模式将所有IO操作都交给主线程和内核来处理,工作线程仅仅负责业务逻辑,因此,Proactor模式更符合图8-4所描述的服务器编程框架。
使用异步IO模型(如aio_read、aio_write函数)实现的Proactor模型的工作流程是:
1.主线程调用aio_read向内核注册socket上的读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时如何通知应用程序(这里以信号为例)。
2.主线程等待读完成期间可继续处理其他逻辑。
3.当socket上的数据被读入用户缓冲区后,内核向应用进程发送一个信号,以通知数据已可用。
4.应用进程预先定义好的信号处理函数选择一个工作线程来处理客户请求,工作线程处理完客户请求后,调用aio_write向内核注册socket上的写完成事件,并告诉内核用户写缓冲区的位置,以及写操作完成时如何通知应用进程(仍以信号为例)。
5.主线程继续处理其他逻辑。
6.当用户缓冲区中的数据被写入socket后,内核向应用进程发送一个信号,以通知应用进程数据已经发送完毕。
7.应用进程预先定义好的信号处理函数选择一个工作线程做善后处理,如是否关闭socket。
以下是Proactor模式的工作流程:
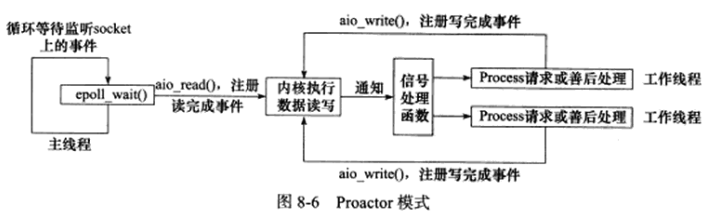
上图中,连接socket上的读写事件是通过aio_read/aio_write函数向内核注册的,因此内核将通过信号来向应用进程报告连接socket上的读写事件,因此,主线程中的epoll_wait函数只能用来监听socket上的连接请求事件,而不能用来检测连接socket上的读写事件。
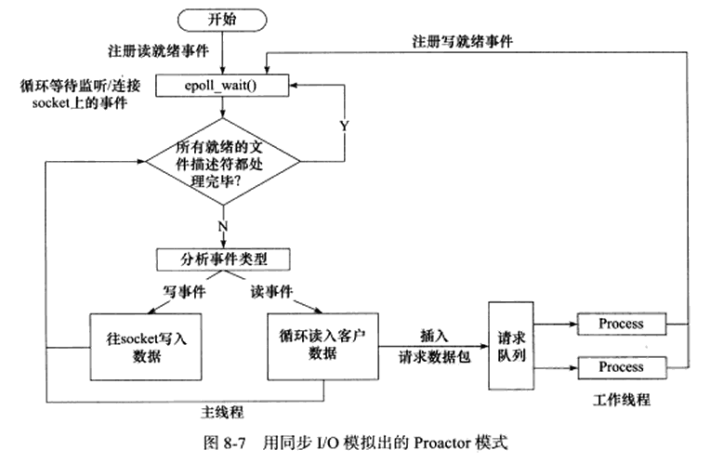
使用同步IO方式模拟Proactor模式的一种方法:主线程执行数据读写操作,读写完成后,主线程向工作线程通知这一完成事件,从工作线程的角度来看,它们直接获得了数据读写的结果,接下来只需对读写的结果进行逻辑处理。
使用同步IO模型(以epoll_wait函数为例)模拟出的Proactor模式的工作流程如下:
1.主线程往epoll内核事件表中注册socket上的读就绪事件。
2.主线程调用epoll_wait等待socket上有数据可读。
3.当socket上有数据可读时,epoll_wait函数通知主线程,主线程从socket循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
4.睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往epoll内核事件表中注册socket上的写就绪事件。
5.主线程调用epoll_wait等待socket可写。
6.当socket可写时,epoll_wait函数通知主线程,主线程往socket上写入服务器处理客户请求的结果。
下图总结了用同步IO模型模拟出Proactor模式的工作流程:
并发编程的目的是让进程“同时”执行多个任务,如果程序是计算密集型的,并发编程并没有优势,反而由于任务的切换使效率降低,但如果进程是IO密集型的,如经常读写文件、访问数据库等,并发编程就有优势了,由于IO操作的速度远没有CPU的计算速度快,所以让程序阻塞于IO操作将浪费大量CPU时间。如果进程有多个执行线程,则当前被IO操作所阻塞的执行线程可主动放弃CPU(或由操作系统来调度),CPU将执行其他线程(而非单线程时一直阻塞),这样一来,CPU就能用来做更有意义的事(除非所有线程同时被IO操作所阻塞),而不是等待IO操作完成,因此多线程能使CPU的利用率提升。
从实现上来说,并发编程主要有多进程和多线程两种方式。我们先讨论并发模式,并发模式指IO处理单元和多个逻辑单元之间协调完成任务的方法,服务器主要有两种并发编程模式:半同步/半异步(half-sync/half-async)和领导者/追随者(Leader/Follwers)模式。
半同步/半异步模式中的同步和异步与前面讨论的IO模型中的同步和异步是不同的概念,在IO模型中,同步和异步区分的是内核向应用进程通知的是何种IO事件(是就绪时间还是完成事件),以及该由谁来完成IO读写(是应用进程还是内核)。在并发模式中,同步指的是进程完全按照代码序列顺序执行,异步指的是程序的执行需要由系统事件来驱动,常见的系统事件包括中断、信号。下图描述了并发模式中的同步和异步:
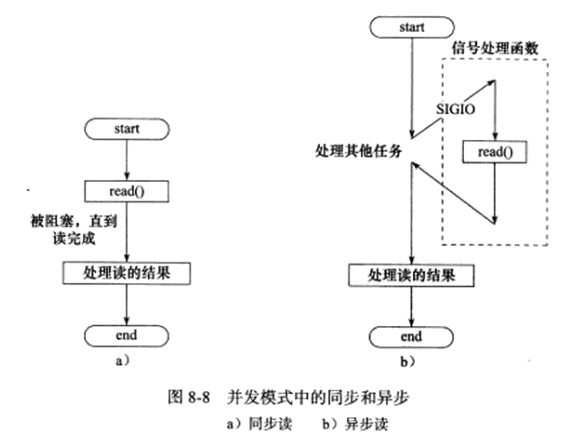
按照同步方式运行的线程称为同步线程,按照异步方式运行的线程称为异步线程。异步线程的执行效率高,实时性强,这是很多嵌入式程序采用的模型,但编写以异步方式执行的程序相对复杂,难以调试和扩展,且不适合大量的并发(大量信号和跳转)。而同步线程虽然执行效率相对较低,实时性较差(阻塞中,其他IO被搁置),但逻辑简单。对于像服务器这种既要求较好的实时性,又要求能同时处理多个客户请求的应用,就应该同时使用同步线程和异步线程来实现,即半同步/半异步模式。
半同步/半异步模式中,同步线程用于处理客户逻辑,相当于逻辑单元,异步线程用于处理IO时间,相当于IO处理单元。异步线程监听到客户请求后,就将其封装成请求对象插入请求队列,请求队列将通知某个工作在同步模式的工作线程来读取并处理该请求对象。具体选择哪个工作线程来为新的客户请求服务,取决于请求队列的设计,如最简单的轮流选取工作线程的Round Robin算法,也可通过条件变量或信号量来随机选择一个工作线程。下图总结了半同步/半异步模式的工作流程:
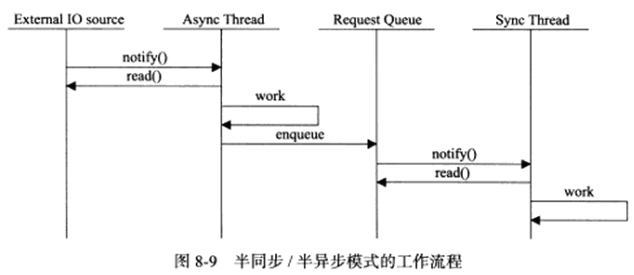
如果考虑两种事件处理模式(reactor和preactor)和几种IO模型,则半同步/半异步模式就存在多种变体,其中一种变体被称为半同步/半反应堆(half-sync/half-reactive)模式:
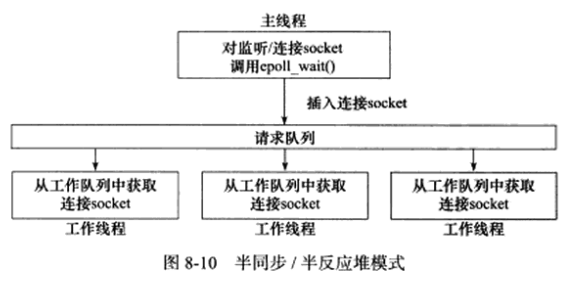
上图中,异步线程只有主线程,它负责监听所有socket上的事件,如果监听socket上有可读事件发生,即有新的连接请求到来,主线程就接受它以得到新的连接socket,然后往epoll内核事件表中注册新的已连接socket上的读写事件。如果连接socket上有读写事件发生,即有新的客户请求到来或有数据要发送到客户端,主线程就将该连接socket插入请求队列中。所有工作线程都睡眠在请求队列上,有任务到来时,它们通过竞争(如申请互斥锁)获得任务的接管权,这种竞争机制使得只有空闲的工作线程才有机会处理新任务。
上图中,主线程插入请求队列中的任务是就绪的连接socket,说明采用的事件处理模式是Reactor模式(它要求工作线程自己从socket上读取客户请求和往socket写入服务器应答),这就是该模式的名称中half-reactive的含义。实际上,半同步/半反应堆模式也能使用模拟的Proactor事件处理模式,即由主线程完成数据的读写,此时,主线程一般会将应用数据、任务类型等信息封装为一个任务对象,然后将其(或指向该任务对象的一个指针)插入请求队列,工作线程从请求队列中取得任务对象后,即可处理它,而无须执行读写操作了。
半同步/半反应堆模式存在如下缺点:
1.主线程和工作线程共享请求队列,主线程往请求队列中添加任务,或工作线程从请求队列中取出任务,都需要对请求队列加锁保护,从而白白耗费CPU时间。
2.每个工作线程同一时间只能处理一个客户请求,如果客户数量较多,而工作线程较少,则请求队列中将堆积很多任务,客户端的响应速度将变慢,如果通过增加工作线程来解决这一问题,则工作线程的切换也将耗费大量CPU时间。
下图描述了一种相对高效的半同步/半异步模式,它的每个工作线程都能同时处理多个客户连接:
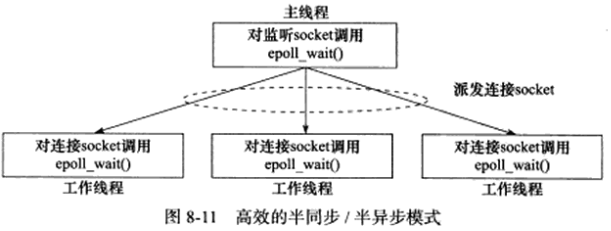
上图中,主线程只管理监听socket,连接socket由工作线程来管理,当有新连接到来时,主线程就接受之并将新返回的连接socket派发给某个工作线程,此后该新socket上的任何IO操作都由被选中的工作线程来处理,直到客户关闭连接。主线程往工作线程派发socket的最简单方式,是往它和工作线程之间的管道里写数据,工作线程检测到管道上有数据可读时,就分析是否是一个新客户连接请求到来,如果是,就把新socket上的读、写事件注册到自己的epoll内核事件表中。
可见,上图中每个线程(主线程和工作线程)都维持自己的事件循环,它们各自独立地监听不同的事件,因此,在这种高效的半同步/半异步模式中,每个线程都工作在异步模式,所以它并非严格意义上的半同步/半异步模式。
领导者/追随者模式是多个工作线程轮流获得事件源集合,轮流监听、分发并处理事件的一种模式。在任意时间点,程序都仅有一个领导者线程,它负责监听IO事件,而其他线程都是追随者,他们休眠在线程池中等待成为新领导者。当前的领导者如果检测到IO事件,首先从线程池中推选出新的领导者线程,然后处理IO事件,此时,新的领导者等待新的IO事件,而原来的领导者则处理IO事件,两者实现了并发。
领导者/追随者模式包含以下几个组件:句柄集(HandleSet)、线程集(ThreadSet)、事件处理器(EventHandler)、具体的事件处理器(ConcreteEventHandler),它们的关系见下图:
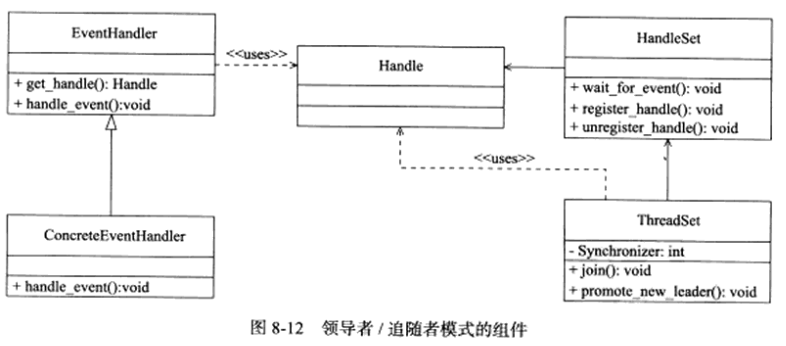
1.句柄集:句柄(Handle)用于表示IO资源,在Linux下通常是一个文件描述符。句柄集管理众多句柄,它使用wait_for_event方法来监听这些句柄上的IO事件,并将其中的就绪事件通知给领导者线程。领导者则调用绑定到Handle上的事件处理器来处理事件。领导者将Handle和事件处理器绑定是通过register_handle方法实现的。
2.线程集:这个组件是所有工作线程(包括领导者线程和追随者线程)的管理者。它负责各线程之间的同步,以及新领导者线程的推选。线程集中的线程在任一时间必处于以下三种状态之一:
(1)Leader:线程当前处于领导者身份,负责等待句柄集上的IO事件。
(2)Processing:线程正在处理事件。领导者检测到IO事件之后,可以转移到Processing状态来处理该事件,并调用promote_new_leader方法推选新的领导者;也可以指定其他追随者来处理事件(Event Handoff),此时领导者的地位不变。当处于Processing状态的线程处理完事件后,如果当前线程中没有领导者,则它将成为新的领导者,否则它直接转变为追随者。
(3)Follower:线程当前处于追随者身份,通过调用线程集的join方法等待成为新领导者,也可能被当前的领导者指定来处理新任务。
下图显示了线程集中的线程的这三种状态之间的转换关系:
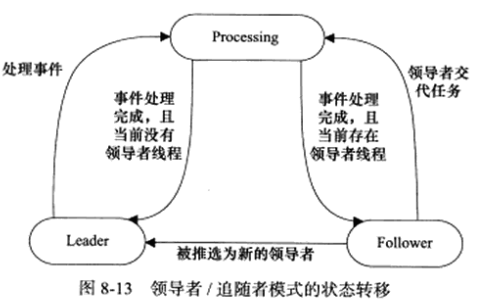
领导者线程推选新的领导者和追随者等待成为新领导者这两个操作都将修改线程集,因此线程集提供一个成员Synchronizer来同步这两个操作,避免竞态条件。
3.事件处理器和具体的事件处理器:通常包含一个或多个回调函数handle_event,这些回调函数用于处理事件对应的业务逻辑。事件处理器在使用前需要被绑定到某个句柄上,当该句柄上有事件发生时,领导者就执行与之绑定的事件处理器中的回调函数。具体的事件处理器是事件处理器的派生类,它们必须重新实现基类的handle_event方法,以处理特定的任务。
领导者/追随者模式的工作流程:
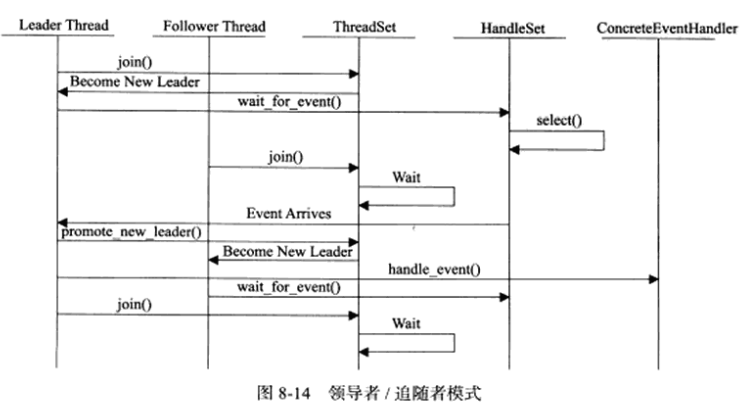
由于领导者线程自己监听IO事件并处理客户请求,因此领导者/追随者模式不需要在线程之间传递任何额外数据,也无须像半同步/半反应堆模式那样在线程之间同步对请求队列的访问。但领导者/追随者的一个缺点是无法让每个工作线程像图8-11那样独立管理多个客户连接。
接下来介绍一种逻辑单元内部的高效编程方法:有限状态机(finite state machine)。
有的应用层协议头部包含数据包类型字段,每种类型可以映射为逻辑单元的一种执行状态,服务器可根据它来编写相应的处理逻辑:
STATE_MACHINE (Package _pack) {PackageType _type = _pack.GetType();switch (_type) {case type_A:process_package_A(_pack);break;case type_B:process_package_B(_pack);break;}
}
上例代码就是一个简单的有限状态机,只不过该状态机的每个状态都是相互独立的,即状态之间没有相互转移。状态之间的转移需要状态机内部驱动:
STATE_MACHINE() {State cur_State = type_A;while (cur_State != type_C) {Package _pack = getNewPackage();switch (cur_State) {case type_A:process_package_state_A(_pack);cur_State = type_B;break;case type_B:process_package_state_B(_pack);cur_State = type_C;break;}}
}
该状态机包含三种状态:type_A、type_B、type_C,其中type_A是状态机的开始状态,type_C是状态机的结束状态。状态机的当前状态记录在cur_State变量中。在一次循环中,状态机先通过getNewPackage方法获得一个新数据包,然后根据cur_State变量的值判断如何处理该数据包,数据包处理完后,状态机通过给cur_State变量传递目标状态值来实现状态转移,那么当状态机进入下一次循环时,它将执行新的状态对应的逻辑。
下面考虑有限状态机的一个实例:HTTP请求的读取和分析。很多网络协议,包括TCP和IP协议,都在首部中提供首部长度字段,程序根据该字段的值就可知道是否接收到一个完整的协议头部。但HTTP协议没有这样的头部长度字段,且其头部长度变化也很大,可以只有十几字节,也可以有上百字节。根据HTTP协议,我们判断HTTP头部结束的依据是遇到一个空行,该空行仅包含一对回车换行符(<CR><LF>)。如果一次读操作没有读入HTTP请求的整个头部,即没有遇到空行,那么我们必须等待客户继续写数据并再次读入。因此,我们每完成一次读操作,就要分析新读入的数据中是否有空行。但在寻找空行的过程中,我们可以同时完成对整个HTTP头的分析,以提高解析HTTP请求的效率。以下代码使用主、从两个有限状态机实现了最简单的HTTP请求的读取和分析:
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <libgen.h>
#define BUFFER_SIZE 4096
// 主状态机有两种状态,当前正在分析请求行(HTTP请求头部的第一行)、当前正在分析头部字段
enum CHECK_STATE {CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER};
// 从状态机有三种状态,用来表示行的读取状态,分别表示读到一个完整行、行出错、行数据尚不完整
enum LINE_STATUS {LINE_OK = 0, LINE_BAD, LINE_OPEN};
// 服务器处理HTTP请求的结果:
// NO_REQUEST:请求不完整,需要继续读取客户数据
// GET_REQUEST:获得了一个完整的客户请求
// BAD_REQUEST:客户请求有语法错误
// FORBIDDEN_REQUEST:客户对资源没有足够的访问权限
// INTERNAL_ERROR:服务器内部错误
// CLOSED_CONNECTION:客户已经关闭连接
enum HTTP_CODE {NO_REQUEST, GET_REQUEST, BAD_REQUEST, FORBIDDEN_REQUEST, INTERNAL_ERROR,CLOSED_CONNECTION};
// 为简化问题,我们不给客户发送一个完整的HTTP应答报文,而是根据服务器的处理结果发送如下成功或失败信息
static const char *szret[] = {"I get a correct result\n", "Something wrong\n"};// 解析出首部中一行的内容,返回值是从状态机的一个状态
LINE_STATUS parse_line(char *buffer, int &checked_index, int &read_index) {char temp;// checked_index指向buffer(用户的读缓冲区)中当前正在分析的字节,read_index指向buffer中客户数据的尾后字节// buffer中第0~checked_index字节都已分析完毕,第checked_index~read_index-1字节由以下循环逐个分析for (; checked_index < read_index; ++checked_index) {// 获得当前要分析的字节temp = buffer[checked_index];// 如果当前分析的字节是\r,即回车符,则说明可能读到了一个完整行if (temp == '\r') {// 如果\r字符是目前buffer中最后一个读到的客户数据,则此次分析没有读到一个完整行// 返回LINE_OPEN表示还要继续读取客户数据才能进一步分析if ((checked_index + 1) == read_index) {return LINE_OPEN;// 如果下一个字符是\n,说明我们成功读到一个完整的行} else if (buffer[checked_index + 1] == '\n') {buffer[checked_index++] = '\0';buffer[checked_index++] = '\0';return LINE_OK;}// 否则说明客户发送的HTTP请求存在语法问题(这意味着除了每行结尾,行内不能出现\r)return LINE_BAD;// 如果当前的字节是\n,即换行符,则说明可能读到一个完整的行} else if (temp == '\n') {// 如果有前一个字符,且前一个字符是\r,说明读到了一个完整的行if ((checked_index > 1) && buffer[checked_index - 1] == '\r') {buffer[checked_index - 1] = '\0';buffer[checked_index++] = '\0';return LINE_OK;}// 否则说明客户发送的HTTP请求存在语法问题(这意味着除了每行结尾,行内不能出现\n)return BAD_LINE;}}// 如果没有遇到\r或\n,则返回LINE_OPEN,表示还需继续读取客户数据才能进一步分析return LINE_OPEN;
}// 分析请求行(HTTP头部中的第一行)
// 一个请求行的例子:GET http://www.a.com/index.html HTTP/1.0
HTTP_CODE parse_requestline(char *temp, CHECK_STATE &checkstate) {// strpbrk函数在一个字符串中查找第一个匹配指定字符集合中任何字符的位置char *url = strpbrk(temp, " \t");// 如果请求行中没有\t或空格,则HTTP请求有语法错误if (!url) {return BAD_REQUEST;}// 此处将上例中,GET后的空格或\t改为了\0,并将url指向了http::的h*url++ = '\0';char *method = temp;// 如果不是GET请求,当成语法错误处理if (strcasecmp(method, "GET") == 0) {printf("The request method is GET\n");} else {return BAD_REQUEST;}// strspn函数用于计算一个字符串中连续包含在另一个字符串中的字符的长度// 此处是为了跳过上例中的GET和http::之间的多个空格或\turl += strspn(url, " \t");char *version = strpbrk(url, " \t");if (!version) {return BAD_REQUEST;}// 此处将上例中url和HTTP版本之间的空格或\t换成\0*version++ = '\0';// 防止url和HTTP版本之间有多个空格或\tversion += strspn(version, " \t");// 只处理HTTP/1.1版本if (strcasecmp(version, "HTTP/1.1") != 0) {return BAD_REQUEST;}// 检查url是否以http://开头if (strncasecmp(url, "http://", 7) == 0) {// 将url指向上例中的www的第一个wurl += 7;// strchr函数用于在一个字符串中查找指定字符的第一次出现的位置,并返回该位置的指针// 这里将url指向上例中的www.a.com/index.html中的/url = strchr(url, '/');}if (!url || url[0] != '/') {return BAD_REQUEST;}printf("The request URL is: %s\n", url);// 读完请求行,将从状态机改为CHECK_STATE_HEADER,表示接下来分析头部字段checkstate = CHECK_STATE_HEADER;// 继续读更多数据return NO_REQUEST;
}// 分析头部字段
HTTP_CODE parse_headers(char *temp) {// 遇到一个空行,说明我们得到了正确的HTTP请求,返回GET_REQUEST表示我们获得了一个完整的客户请求// 在读取一行数据时,我们把该行中所有\r\n都改成了\0if (temp[0] == '\0') {return GET_REQUEST;// 处理HOST头部字段} else if (strncasecmp(temp, "Host:", 5) == 0) {temp += 5;// 跳过冒号后的一个或多个空格或\ttemp += strspn(temp, " \t");printf("the request host is: %s\n", temp);// 其他头部字段不处理} else {printf("I can not handle this header\n");}// 没有遇到空行,返回NO_REQUEST表示请求不完整,需要继续读取客户数据return NO_REQUEST;
}// 分析HTTP请求的入口函数
HTTP_CODE parse_content(char *buffer, int &checked_index, CHECK_STATE &checkstate, int &read_index, int &start_line) {LINE_STATUS linestatus = LINE_OK;HTTP_CODE retcode = NO_REQUEST;// 如果读到了一整行while ((linestatus = parse_line(buffer, checked_index, read_index)) == LINE_OK) {// start_line是当前行的起始位置char *temp = buffer + start_line;// 更新下一行的起始位置start_line = checked_index;// checkstate是主状态机当前的状态switch (checkstate) {// 分析请求行case CHECK_STATE_REQUESTLINE:{retcode = parse_requestline(temp, checkstate);// 语法错误if (retcode == BAD_REQUEST) {return BAD_REQUEST;}break;}// 分析头部字段case CHECK_STATE_HEADER:{retcode = parse_headers(temp);// 语法错误if (retcode == BAD_REQUEST) {return BAD_REQUEST;// 已读到完整HTTP请求} else if (retcode == GET_REQUEST) {return GET_REQUEST;}break;}default: {return INTERVAL_ERROR;}}}// 如果没有读到完整行,表示还需继续读取客户数据才能进一步分析if (linestatus == LINE_OPEN) {return NO_REQUEST;// 既没有读到完整行,也没有返回继续读取数据,说明返回了LINE_BAD(语法错误)} else {return BAD_REQUEST;}
}int main(int argc, char *argv[]) {if (argc < 2) {printf("usage: %s ip_address port_number\n", basename(argv[0]));return 1;}const char *ip = argv[1];int port = atoi(argv[2]);struct sockaddr_in address;bzero(&address, sizeof(address));address.sin_family = AF_INET;inet_pton(AF_INET, ip, &address.sin_addr);address.sin_port = htons(port);int listenfd = socket(PF_INET, SOCK_STREAM, 0);assert(listenfd >= 0);int ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address));assert(ret != -1);ret = listen(listenfd, 5);assert(ret != -1);struct sockaddr_in client_address;socklen_t client_addrlength = sizeof(client_address);int fd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength);if (fd < 0) {printf("errno is: %s\n", errno);} else {char buffer[BUFFER_SIZE];memset(buffer, '\0', BUFFER_SIZE);int data_read = 0;int read_index = 0; // 当前已读了多少客户数据int checked_index = 0; // 当前已经分析完了多少字节的客户数据int start_line = 0; // 行在buffer中的起始位置// 将主状态机状态设置为读请求行CHECK_STATE checkstate = CHECK_STATE_REQUESTLINE;while (1) { // 循环读取客户数据并分析data_read = recv(fd, buffer + read_index, BUFFER_SIZE - read_index, 0);if (data_read == -1) {printf("reading failed\n");break;} else if (data_read == 0) {printf("remote client has closed the connection\n");break;}read_index += data_read;// 分析当前读取的数据HTTP_CODE result = parse_content(buffer, checked_index, checkstate, read_index, start_line);// 尚未得到完整的HTTP请求,接着读if (result == NO_REQUEST) {continue;// 得到了一个完整的、正确的HTTP请求} else if (result == GET_REQUEST) {send(fd, szret[0], strlen(szret[0]), 0);break;// 其他情况表示发生错误} else {send(fd, szret[1], strlen(szret[1]), 0);break;}}close(fd);}close(listenfd);return;
}
以上代码中有两个有限状态机,分别称其为主状态机和从状态机,主状态机在内部调用从状态机。先分析从状态机,即parse_line函数,它从buffer中解析出一个行,下图是它可能的状态和状态转移过程:
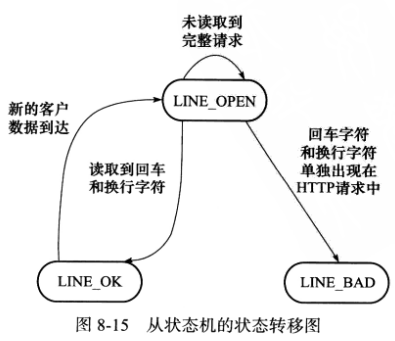
从状态机的初始状态是LINE_OK,其原始驱动力来自于buffer中新到达的客户数据。在main函数中,我们循环调用recv函数往buffer中读入客户数据,每次成功读取数据后,就调用parse_content分析新读入的数据,parse_content函数首先要做的就是调用parse_line来获取一个行,假设服务器经过一次recv调用后,buffer的内容和部分变量的值如图8-16a所示:
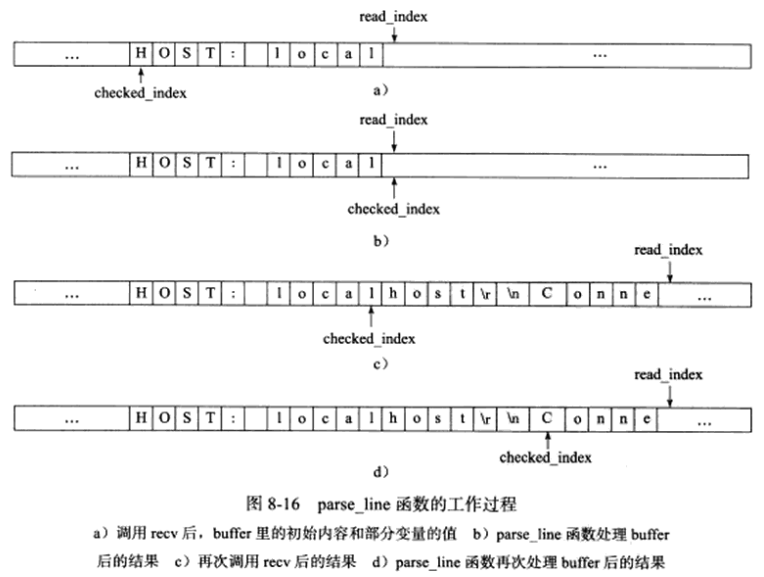
parse_line函数处理后的结果如图8-16b所示,它挨个检查图8-16a所示的buffer中checked_index到read_index-1之间的字节,判断是否存在行结束符,并更新checked_index的值,当前buffer中不存在行结束符,因此parse_line函数返回LINE_OPEN。接下来,程序继续调用recv读取更多客户数据,这次读操作后buffer中的内容和部分变量的值如图8-16c所示,然后parse_line函数处理这部分新到的数据,如图8-16d所示,这次它读到了一个完整的行,即HOST: localhost\r\n,此时,parse_line函数就可以将这行内容递交给parse_content函数中的主状态机来处理了。
主状态机使用checkstate变量记录当前状态,如果当前状态是CHECK_STATE_REQESTLINE,则表示parse_line函数解析出的行时请求行,于是主状态机调用parse_requestline来分析请求行,如果当前状态是CHECK_STATE_HEADER,则表示parse_line函数解析出的是头部字段行,于是调用parse_headers来分析头部字段。checkstate变量的初始值是CHECK_STATE_REQUESTLINE,parse_requestline函数在成功分析完请求行后将其设置为CHECK_STATE_HEADER,从而实现状态转移。
影响服务器性能的首要因素就是系统的硬件资源,如CPU个数、速度、内存大小等,但由于硬件技术飞速发展,现代服务器都不缺乏硬件资源,因此,我们需要考虑如何从软环境来提升服务器性能,服务器软环境一方面指系统的软件资源,如操作系统允许用户打开的最大文件描述符数量,另一方面指服务器程序本身,即如何从编程角度确保服务器的性能。
既然服务器的硬件资源充裕,那么提高服务器性能的一个直接的方法就是以空间换时间,池的概念就是这样,池是一组资源的集合,这组资源在服务器启动的时候就被完全创建好并初始化,这称为静态资源分配。当服务器进入正式运行阶段,即开始处理客户请求的时候,如果它需要相关资源,就可以直接从池中获取,无须动态分配。显然,直接从池中获取所需资源比动态分配资源的速度要快得多,因为分配系统资源的系统调用都是很耗时的。当服务器处理完一个客户连接后,可以把相关资源放回池中,无须执行系统调用来释放资源。从最终效果看,池相当于服务器管理系统资源的应用层设施,它避免了服务器对内核的频繁访问。
但既然池中的资源是预先静态分配的,我们无法预期应分配多少资源,这个问题的解决办法就是分配足够多的资源,即针对每个可能的客户连接都分配必要的资源,这通常会导致资源的浪费,因为任一时刻的客户数量都可能远远没有达到服务器能支持的最大客户数量,好在这种资源的浪费对服务器来说一般不会构成问题。还有一种解决方案是预先分配一定的资源,此后如果发现资源不够用,就再动态分配一些并加入池中。
根据不同的资源类型,池可分为多种,常见的有内存池、进程池、线程池、连接池。
内存池通常用于socket的接收缓存和发送缓存,对于某些长度有限的客户请求,如HTTP请求,预先分配一个大小足够的接收缓存区是合理的。当客户请求超过接收缓冲区大小时,我们可以选择丢弃请求或动态扩大接收缓冲区。
进程池和线程池在并发编程中很常用,当我们需要一个工作进程或工作线程来处理新到来的客户请求时,我们可以直接从进程池或线程池中取得一个执行实体,而无须动态调用fork或pthread_create等函数来创建进程或线程。
连接池通常用于服务器或服务器机群的内部永久连接,图8-4中,每个逻辑单元可能都需要频繁访问本地的某个数据库,简单做法是,逻辑单元每次需要访问数据库时,就向数据库进程发起连接,而访问完后释放连接,显然这样做效率太低,一种解决方案是使用连接池,连接池是服务器预先和数据库进程建立的一组连接的集合,当某个逻辑单元需要访问数据库时,它可以从连接池中取得一个连接的实体并使用之,待完成数据库的访问后,逻辑单元再将该连接返还给连接池。
高性能服务器应避免不必要的数据复制,尤其是当数据复制发生在用户代码和内核之间的时候。如果内核可以直接处理从socket或文件读入的数据,则应用进程就没必要将这些数据从内核缓冲区复制到应用缓冲区中,此处的直接处理指的是应用进程不关心这些数据的内容,不需要对它们做任何分析,如ftp服务器,当客户请求一个文件时,服务器只需检测目标文件是否存在,以及客户是否有读取它的权限,而不会关心文件的具体内容,因此ftp服务器就无须把目标文件的内容完整读入应用进程缓冲区中,并调用send来发送,而是可以使用零拷贝函数sendfile来直接将其发送给客户端。
此外,用户代码内部(不访问内核)的数据复制也应避免,例如,当两个工作进程之间要传递大量数据时,我们应考虑使用共享内存在它们之间直接共享这些数据,而不是使用管道或消息队列来传递,又比如我们可用指针来指出数据的位置,以便随后对该位置的内容进行访问,而不是把内容复制到另一个缓冲区中来使用,这样既浪费空间,又效率低下。
并发程序必须考虑上下文切换(context switch)问题,即进程切换或线程切换导致的系统开销。不应使用过多工作进程(线程),否则进程(线程)间的切换将占用大量CPU时间,服务器真正用于处理业务逻辑的CPU时间的比重就会变小。
并发编程需要考虑的另一个问题是共享资源的加锁保护,锁通常被认为是导致服务器效率低下的一个因素,因为由锁引入的代码不仅不处理任何业务逻辑,而且需要访问内核资源,因此,如果服务器有更好的解决方案,就应该避免使用锁。显然图8-11所描述的半同步/半异步模式就比图8-10所描述的半同步/半反应堆模式的效率高。如果服务器必须使用锁,则可以考虑减小锁的粒度,如使用读写锁,当所有工作线程只读取一块共享内存的内容时,读写锁并不会增加系统的额外开销,只有当一个工作线程需要写这块内存时,系统才必须去锁住这块区域。
相关文章:
Linux高性能服务器编程 学习笔记 第八章 高性能服务器程序框架
TCP/IP协议在设计和实现上没有客户端和服务器的概念,在通信过程中所有机器都是对等的。但由于资源(视频、新闻、软件等)被数据提供者所垄断,所以几乎所有网络应用程序都采用了下图所示的C/S(客户端/服务器)…...

技术对比:Flutter vs. 传统桌面应用开发框架
在移动应用开发领域,Flutter已经赢得了广泛的认可和采用,成为了跨平台移动应用开发的瑞士军刀。然而,Flutter的魅力并不仅限于移动平台,它还可以用于开发桌面应用程序,为开发人员提供了一种全新的选择。本文将深入探讨…...
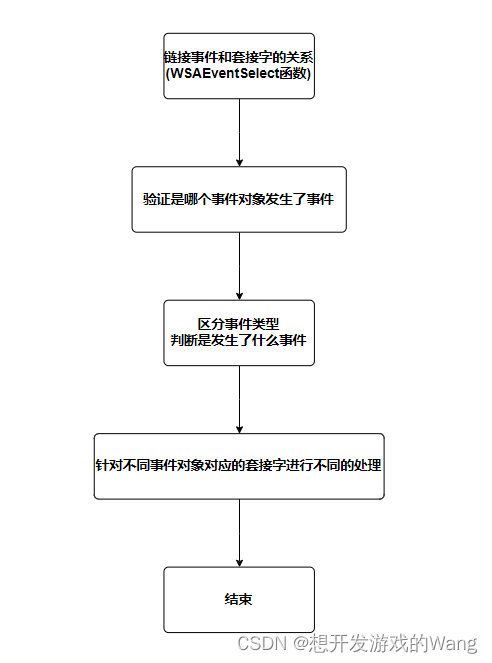
[C++ 网络协议] 异步通知I/O模型
1.什么是异步通知I/O模型 如图是同步I/O函数的调用时间流: 如图是异步I/O函数的调用时间流: 可以看出,同异步的差别主要是在时间流上的不一致。select属于同步I/O模型。epoll不确定是不是属于异步I/O模型,这个在概念上有些混乱&a…...

Postgresql事务测试
参考一个事务中 可以查询自己未提交的数据吗_最详细MySQL事务隔离级别及原理讲解!(二)-CSDN博客 一个事务中 可以查询自己未提交的数据吗_趣说数据库事务隔离级别与原理_weixin_39747293的博客-CSDN博客 【MySql:当前读与快照读…...
【数据结构--排序】冒泡排序,选择排序,插入排序
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...

vue pc端/手机移动端 — 下载导出当前表格页面pdf格式
一、需求:在手机端/pc端实现一个表格页面(缴费单/体检报告单等)的导出功能,便于用户在本地浏览打印。 二、实现:之前在pc端做过预览打印的功能,使用的是print.js之类的方法让当前页面直接唤起打印机的打印预…...

125. 验证回文串 【简单题】
题目 如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。 字母和数字都属于字母数字字符。 给你一个字符串 s,如果它是 回文串 ,返回 true ;否则…...
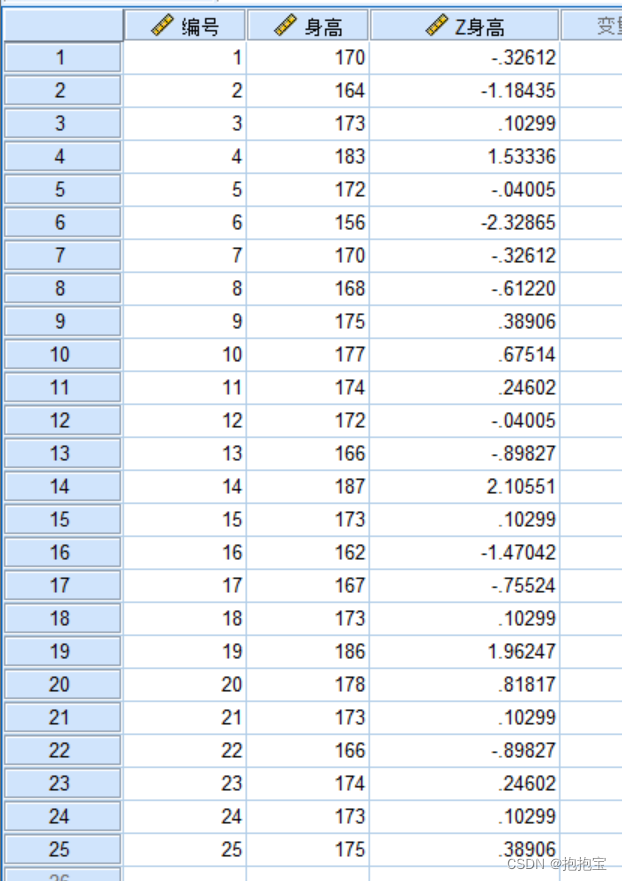
描述性统计分析
前言: 本专栏参考教材为《SPSS22.0从入门到精通》,由于软件版本原因,部分内容有所改变,为适应软件版本的变化,特此创作此专栏便于大家学习。本专栏使用软件为:SPSS25.0 本专栏所有的数据文件可在个人主页—…...

Visual Studio2019 C++ 编程问题集锦
“const char*” 类型的值不能用于初始化“char*"类型的实体 解决方案一: 点击项目->属性->C/C>语言->符合模式,将原来的“是”改为“否”即可。解决方案二: 在声明变量 char* 时改成 const char *即可...
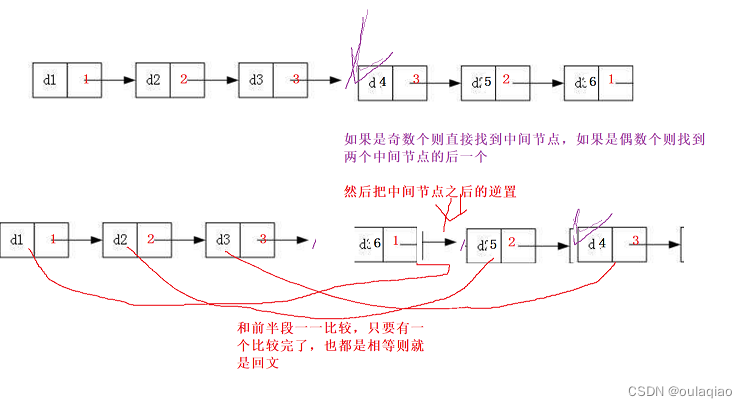
链表的回文判断
思路: 找中间节点–>逆置->比较 代码: /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/struct ListNode* middleNode(struct ListNode* head) { struct ListNode*slowhead; struct ListNode*f…...

281_JSON_两段例子的比较,哪一段更简洁、易懂、没有那么多嵌套
《第一份:》//组装Notificationif (bSendAINotification){BOOST_AUTO(iter_flashnotification, documentAll.FindMember("Notification"));if (iter_flashnotification != documentAll....

想要精通算法和SQL的成长之路 - 最长递增子序列 II(线段树的运用)
想要精通算法和SQL的成长之路 - 最长递增子序列 II(线段树的运用) 前言一. 最长递增子序列 II1.1 向下递推1.2 向上递推1.3 更新操作1.4 查询操作1.5 完整代码: 前言 想要精通算法和SQL的成长之路 - 系列导航 一. 最长递增子序列 II 原题链接…...

java用easyexcel按模版导出
首先在项目的resources下面建一个template包,之后在下面创建一个模版,模版格式如下: 名称为 financeReportBillStandardTemplateExcel.xlsx: {.fee}类型的属性值,是下面实体类的属性,要注意这里面的格式&a…...
Servlet执行流程生命周期方法介绍体系结构、Request和Response的功能详解
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 Servlet 一、 Servlet执行流程二、Servlet生…...
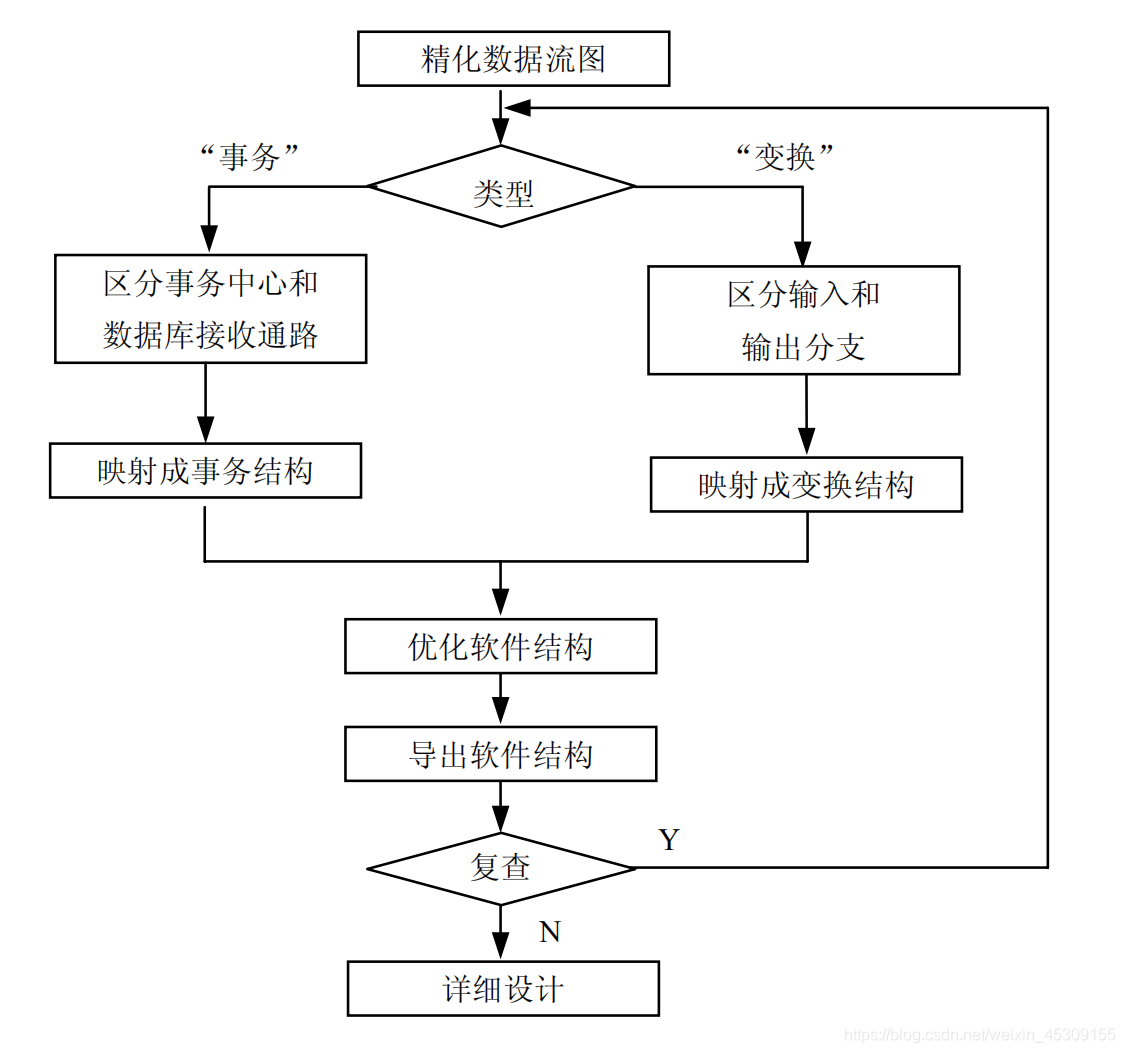
软件工程之总体设计
总体设计是软件工程中的一个重要阶段,它关注整个系统的结构和组织,旨在将系统需求转化为可执行的软件解决方案。总体设计决定了系统的架构、模块划分、功能组织以及数据流和控制流等关键方面。 可行性研究 具体方面:经济可行性、技术可行性…...

监控员工电脑文件拷贝记录:电脑怎么看员工复制文件的历史记录
在现代企业管理中,数据安全和保密是极其重要的一环。企业需要确保敏感信息不被泄露,以防止可能的法律纠纷和经济损失。为此,许多公司都采取了一些措施来监控员工的电脑使用行为。其中,监控文件拷贝记录是一种常见的方法。本文将详…...
文件通用下载方法封装)
vue中request.js中axios请求和(若依)文件通用下载方法封装
vue中request.js中axios请求和(若依)文件通用下载方法封装 1.request.js import axios from axios import { Message, Loading } from element-ui import { saveAs } from file-saver // 创建axios实例 const request axios.create({// 这里可以放一…...
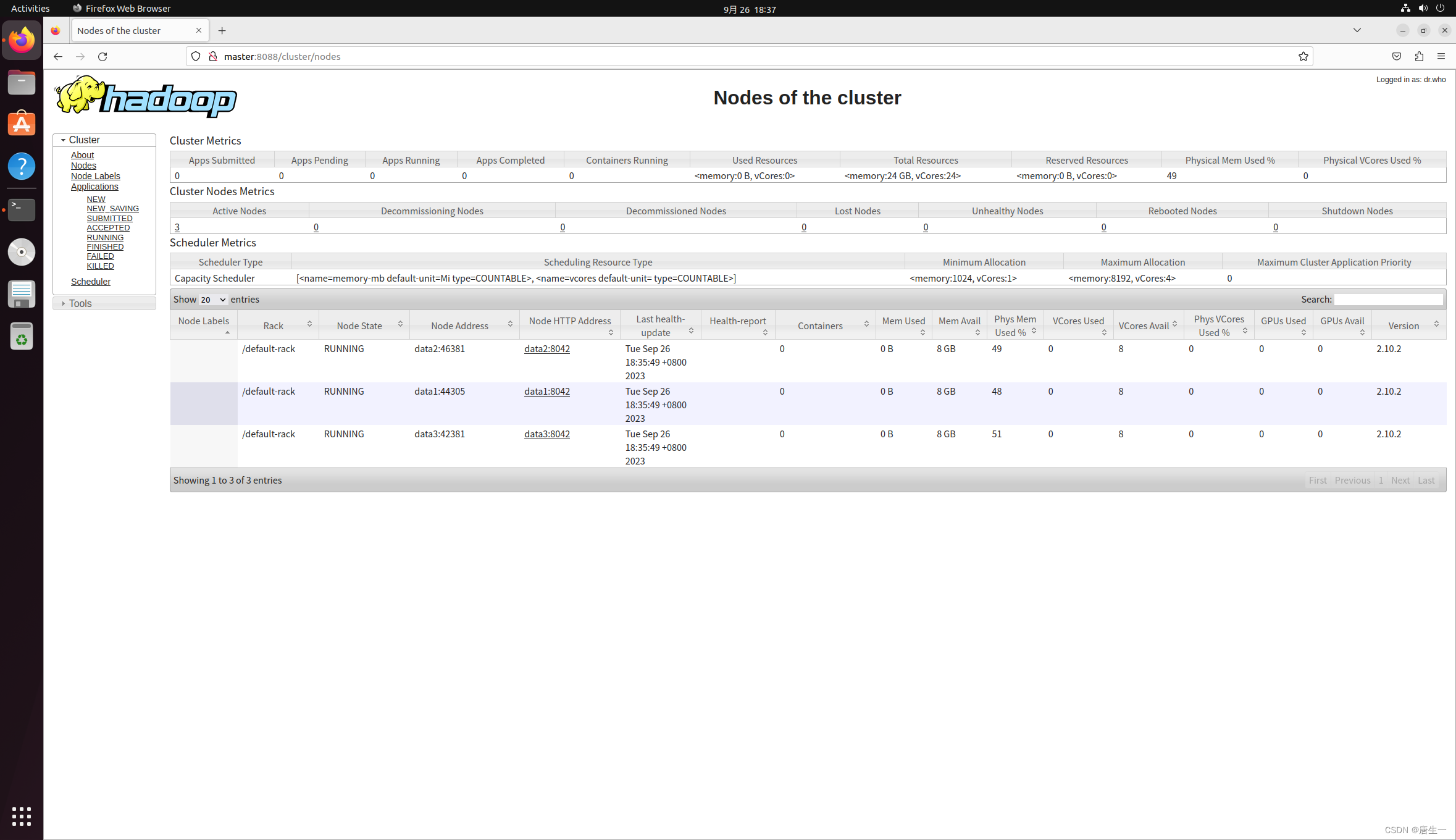
【大数据存储与处理】1. hadoop单机伪分布安装和集群安装
0. 写在前面 0.1 软件版本 hadoop2.10.2 ubuntu20.04 openjdk-8-jdk 0.2 hadoop介绍 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个…...

linux通过time命令统计代码编译时间
首先编写一个编译脚本 build.sh 内容如下: 然后执行time sh build.sh 编译完成后输出三个时间 time sh xxx.sh # 会返回3个时间数据 (1) real:从进程 ls 开始执行到完成所耗费的 CPU 总时间。该时间包括 ls 进程执行时实际使用的 CPU 时间,…...

logback日志是怎么保证多线程输出日志线程安全的
logback中的单例模式 logback日志框架使用了单例设计模式来进行日志输出。在logback中,Logger类是一个关键的组件,它负责记录和输出日志消息。 Logger类使用了单例设计模式,确保在一个应用程序中只存在一个Logger实例。这样做的好处是可以确…...

打破平台壁垒:Windows上安装APK文件的完整解决方案
打破平台壁垒:Windows上安装APK文件的完整解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行安卓应用ÿ…...

SAP KO88结算时,如何用BADI_FINS_ACDOC_POSTING_EVENTS把成本中心塞进自定义字段?
SAP KO88结算实战:通过BADI_FINS_ACDOC_POSTING_EVENTS实现成本中心到自定义字段的精准映射 在SAP工单结算(KO88)的复杂业务场景中,财务凭证的标准化字段往往无法满足企业多维度的分析需求。特别是当需要将特定成本中心信息映射到…...

低温预警!固化慢、易开裂……密封胶冬季施工手册
低温预警!固化慢、易开裂……密封胶冬季施工手册 硅酮耐候密封胶主要作用是保障幕墙的气密性、水密性。其出现问题,可能会导致耐候密封失效,从而造成幕墙漏水漏气,影响幕墙的正常使用。耐候密封胶由于考虑到现场施工,几乎都是单组分硅酮密封胶产品。进入冬季,气候变化明…...

Ruby中文分词利器Rurima:纯Ruby实现的高性能分词引擎详解
1. 项目概述:一个为Ruby打造的现代中文分词引擎在Ruby社区里,处理中文文本一直是个有点“硌脚”的活儿。如果你做过中文搜索、内容分析或者简单的词频统计,肯定遇到过这个经典难题:怎么把一串连续的中文字符,准确地切割…...

PCL2启动器离线登录按钮消失?5分钟快速修复指南
PCL2启动器离线登录按钮消失?5分钟快速修复指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否遇到过PCL2启动器离线登录按钮突然消失的困扰࿱…...

OpenAgentsControl:构建多智能体协同系统的开源框架解析
1. 项目概述:一个面向智能体控制的开放框架最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的开源仓库:darrenhinde/OpenAgentsControl。这个项目名字直译过来就是“开放智能体控制”,听起来就很有搞…...

柔性3D打印与生物仿生设计:从TPU材料到空气喷涂的完整实践
1. 项目概述:当柔性3D打印遇上生物仿生美学如果你和我一样,玩3D打印玩久了,总会对那些千篇一律的硬质塑料件感到一丝审美疲劳。我们总在追求更高的精度、更强的结构,却常常忽略了材料本身可以带来的、截然不同的体验。直到我开始接…...

Argo Workflows:Kubernetes原生工作流引擎从入门到生产实践
1. 项目概述:一个开源的容器化工作流引擎如果你在云原生、数据科学或者自动化运维领域摸爬滚打过一阵子,大概率听说过 Argo。它不是某个游戏里的角色,而是一个在 Kubernetes 生态中,用来编排和运行复杂工作流的强大引擎。简单来说…...

三维重建下半场,拼的全是底层基建实力!
三维重建已从算法创新竞赛正式迈入基础设施比拼新阶段,主流技术路线逐步收敛,单纯算法红利见顶,行业竞争核心转向数据、算力、平台、生态等底层综合能力。当下竞争不再只比模型效果,而是聚焦四大核心基建维度:采集传感…...

AI原生编程语言Reia:为LLM设计的编程范式变革
1. 项目概述:Reia,一个面向未来的AI原生编程语言最近在AI和编程语言交叉领域,一个名为Reia的项目引起了我的注意。它来自Quaint-Studios,定位是“AI原生”的编程语言。这听起来有点抽象,但简单来说,Reia试图…...