【Graph Net学习】LINE实现Graph Embedding
一、简介
LINE (Large-scale Information Network Embedding,2015) 是一种设计用于处理大规模信息网络的算法。它主要的目标是在给定的大规模信息网络中学习高质量的节点嵌入,并尽量保留网络中信息的丰富性。其具体的表现为在一个低 维空间里以向量形式表示网络中的节点,以便后续的机器学习任务可以更好地理解。
LINE算法根据两种相互关联的线性化策略去处理信息图,分别考虑了图节点的一阶邻居和二阶邻居。通过这种方式,LINE既能反映出网络的全局属性又能反映出网络的局部属性。
调用算法流程如下:
-
首先,为图中的每个节点初始化一个随机向量。
-
接着,使用一阶邻居的优化原型函数进行训练。在一阶近邻策略中,若两个节点存在直接连接,则他们的向量应该尽可能相近。
-
然后,使用二阶邻居的优化原型函数进行训练。在二阶近邻策略中,考虑两节点间的间接联系。例如,若两节点存在共享的邻居,即使他们之间没有直接的联系,他们的向量也应该相近。
-
对每个节点,计算其在一阶和二阶优化下的损失函数值,并对其进行优化。
-
优化完成后,此时每个节点上的向量就是最终的嵌入表示。
-
基于得到的嵌入表示进行后续的分析或机器学习任务。
接下来就是快乐的代码时间嘿嘿嘿
二、代码
import os
import pandas as pd
import numpy as np
import networkx as nx
import time
import scipy.sparse as sp
from torch_geometric.data import Data
from torch_geometric.transforms import ToSparseTensor
import torch_geometric.utils
from sklearn.preprocessing import LabelEncoderimport torch
import torch.nn as nn#配置项
class configs():def __init__(self):# Dataself.data_path = r'./data'self.save_model_dir = r'./'self.num_nodes = 2708self.embedding_dim = 128self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.learning_rate = 0.01self.epoch = 30self.criterion = nn.BCEWithLogitsLoss()self.istrain = Trueself.istest = Truecfg = configs()def load_cora_data(data_path = './data/cora'):content_df = pd.read_csv(os.path.join(data_path,"cora.content"), delimiter="\t", header=None)content_df.set_index(0, inplace=True)index = content_df.index.tolist()features = sp.csr_matrix(content_df.values[:,:-1], dtype=np.float32)# 处理标签labels = content_df.values[:,-1]class_encoder = LabelEncoder()labels = class_encoder.fit_transform(labels)# 读取引用关系cites_df = pd.read_csv(os.path.join(data_path,"cora.cites"), delimiter="\t", header=None)cites_df[0] = cites_df[0].astype(str)cites_df[1] = cites_df[1].astype(str)cites = [tuple(x) for x in cites_df.values]edges = [(index.index(int(cite[0])), index.index(int(cite[1]))) for cite in cites]edges = np.array(edges).T# 构造Data对象data = Data(x=torch.from_numpy(np.array(features.todense())),edge_index=torch.LongTensor(edges),y=torch.from_numpy(labels))idx_train = range(140)idx_val = range(200, 500)idx_test = range(500, 1500)# 读取Cora数据集 return geometric Data格式def index_to_mask(index, size):mask = np.zeros(size, dtype=bool)mask[index] = Truereturn maskdata.train_mask = index_to_mask(idx_train, size=labels.shape[0])data.val_mask = index_to_mask(idx_val, size=labels.shape[0])data.test_mask = index_to_mask(idx_test, size=labels.shape[0])def to_networkx(data):edge_index = data.edge_index.to(torch.device('cpu')).numpy()G = nx.DiGraph()for src, tar in edge_index.T:G.add_edge(src, tar)return Gnetworkx_data = to_networkx(data)return data,networkx_data
#获取数据:pyg_data:torch_geometric格式;networkx_data:networkx格式def generate_pairs(adj_matrix):# 根据邻接矩阵生成正例和负例pos_pairs = torch.nonzero(adj_matrix, as_tuple=True)pos_u = pos_pairs[0]pos_v = pos_pairs[1]mask = torch.ones_like(adj_matrix)for i in range(len(pos_u)):mask[pos_u[i]][pos_v[i]] = 0mask[pos_v[i]][pos_u[i]] = 0tmp = torch.nonzero(mask, as_tuple=True)#TODO 随机选取负例idx = torch.randperm(tmp[0].size(0))neg_u = tmp[0][idx][:pos_u.size(0)]neg_v = tmp[1][idx][:pos_v.size(0)]return pos_u, pos_v, neg_u, neg_v# 构建LINE网络
class LINE(nn.Module):def __init__(self, num_nodes, embed_dim):super(LINE, self).__init__()#num_nodes为Node个数 , embed_dim为描述Node的Embedding维度self.embed_dim = embed_dimself.num_nodes = num_nodesself.embeddings = nn.Embedding(self.num_nodes, self.embed_dim)self.reset_parameters()def reset_parameters(self):self.embeddings.weight.data.normal_(std=1 / self.embed_dim)def forward(self, pos_u, pos_v, neg_v):emb_pos_u = self.embeddings(pos_u)emb_pos_v = self.embeddings(pos_v)emb_neg_v = self.embeddings(neg_v)pos_scores = torch.sum(torch.mul(emb_pos_u, emb_pos_v), dim=1)neg_scores = torch.sum(torch.mul(emb_pos_u, emb_neg_v), dim=1)return pos_scores, neg_scoresclass LINE_run():def train(self):t = time.time()# 创建一个模型_, networkx_data = load_cora_data()adj_matrix = torch.tensor(nx.adjacency_matrix(networkx_data).toarray(), dtype=torch.float32)model = LINE(num_nodes=cfg.num_nodes, embed_dim=cfg.embedding_dim).to(cfg.device)optimizer = torch.optim.Adam(model.parameters(), lr=cfg.learning_rate)#Trainmodel.train()for epoch in range(cfg.epoch):optimizer.zero_grad()pos_u, pos_v, neg_u, neg_v = generate_pairs(adj_matrix)pos_u = pos_u.to(cfg.device)pos_v = pos_v.to(cfg.device)neg_v = neg_v.to(cfg.device)pos_scores, neg_scores = model(pos_u, pos_v, neg_v)pos_losses = cfg.criterion(pos_scores, torch.ones(len(pos_scores)).to(cfg.device))neg_losses = cfg.criterion(neg_scores, torch.zeros(len(neg_scores)).to(cfg.device))loss = pos_losses + neg_lossesloss.backward()optimizer.step()print('Epoch: {:04d}'.format(epoch + 1),'loss_train: {:.4f}'.format(loss.item()),'time: {:.4f}s'.format(time.time() - t))torch.save(model, os.path.join(cfg.save_model_dir, 'latest.pth')) # 模型保存print('Embedding dim : ({},{})'.format(model.embeddings.weight.shape[0],model.embeddings.weight.shape[1]))def infer(self):# Create Test Processing_, networkx_data = load_cora_data()adj_matrix = torch.tensor(nx.adjacency_matrix(networkx_data).toarray(), dtype=torch.float32)model_path = os.path.join(cfg.save_model_dir, 'latest.pth')model = torch.load(model_path, map_location=torch.device(cfg.device))model.eval()_, networkx_data = load_cora_data()pos_u, pos_v, neg_u, neg_v = generate_pairs(adj_matrix)pos_u = pos_u.to(cfg.device)pos_v = pos_v.to(cfg.device)neg_v = neg_v.to(cfg.device)pos_scores, neg_scores = model(pos_u, pos_v, neg_v)pos_losses = cfg.criterion(pos_scores, torch.ones(len(pos_scores)).to(cfg.device))neg_losses = cfg.criterion(neg_scores, torch.zeros(len(neg_scores)).to(cfg.device))loss = pos_losses + neg_lossesprint("Test set results:","loss= {:.4f}".format(loss.item()),'Embedding dim : ({},{})'.format(model.embeddings.weight.shape[0], model.embeddings.weight.shape[1]))if __name__ == '__main__':mygraph = LINE_run()if cfg.istrain == True:mygraph.train()if cfg.istest == True:mygraph.infer()三、输出结果
跑的是Cora数据,共2708个Node,设置的Embedding维度是128维。上面代码运行完就是长下面这个样子。
Epoch: 0001 loss_train: 1.3863 time: 3.0867s
Epoch: 0002 loss_train: 1.3832 time: 3.7739s
Epoch: 0003 loss_train: 1.3768 time: 4.4471s
...
Epoch: 0028 loss_train: 0.7739 time: 21.3568s
Epoch: 0029 loss_train: 0.7694 time: 22.0310s
Epoch: 0030 loss_train: 0.7663 time: 22.7042s
Embedding dim : (2708,128)
Test set results: loss= 0.7609 Embedding dim : (2708,128)
效果未知,没有用下游聚类测一下,反正看起来BCE loss是降了哈哈,这期就到这里。
相关文章:
【Graph Net学习】LINE实现Graph Embedding
一、简介 LINE (Large-scale Information Network Embedding,2015) 是一种设计用于处理大规模信息网络的算法。它主要的目标是在给定的大规模信息网络中学习高质量的节点嵌入,并尽量保留网络中信息的丰富性。其具体的表现为在一个低 维空间里以向量形式表示网络中的…...
docker安装使用xdebug
docker安装使用xdebug 1、需要先安装PHP xdebug扩展 1.1 到https://pecl.php.net/package/xdebug下载tgz文件,下载当前最新稳定版本的文件。然后把这个tgz文件放到php/extensions目录下,记得install.sh中要替换解压的文件名: installExtensio…...
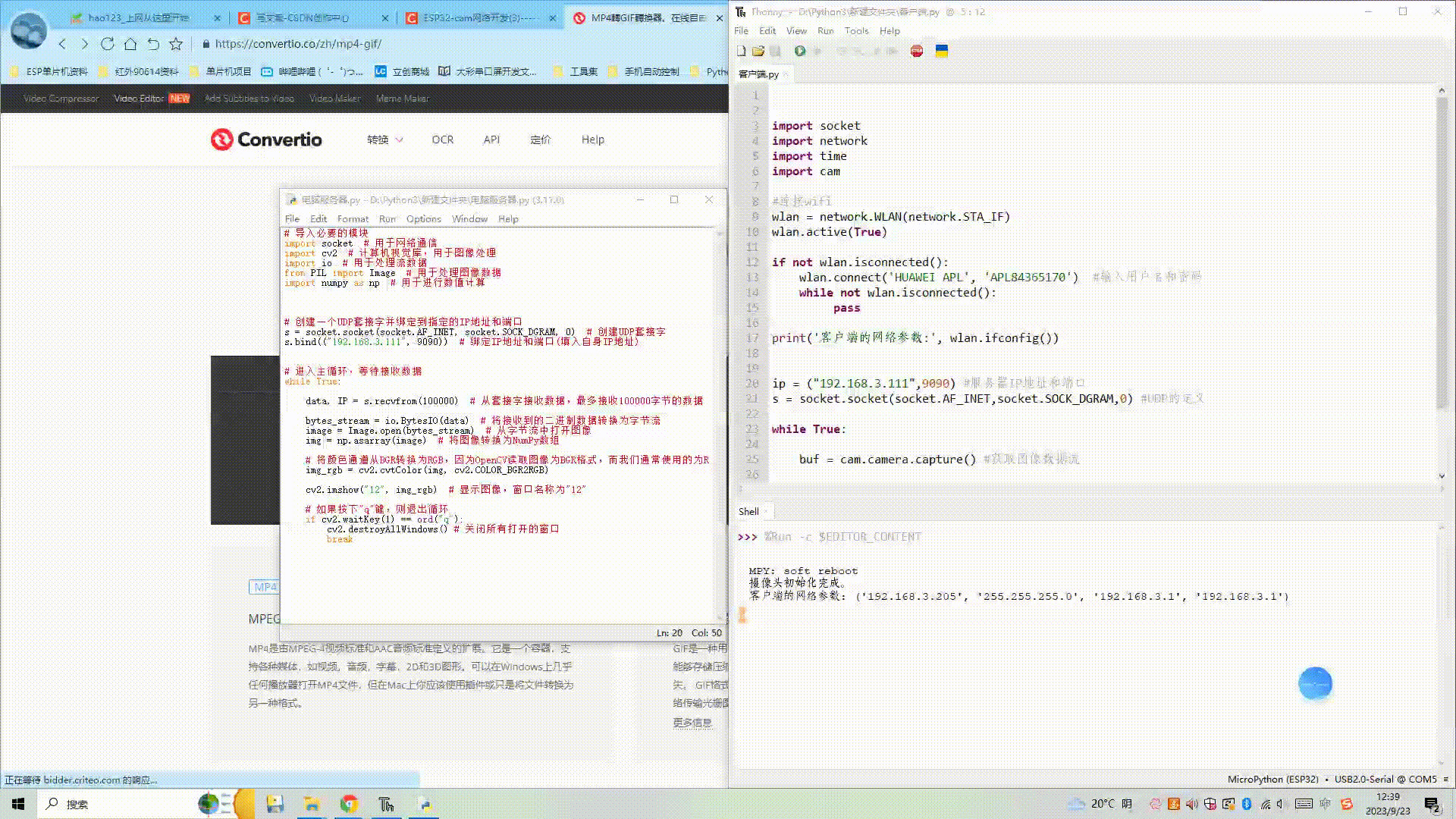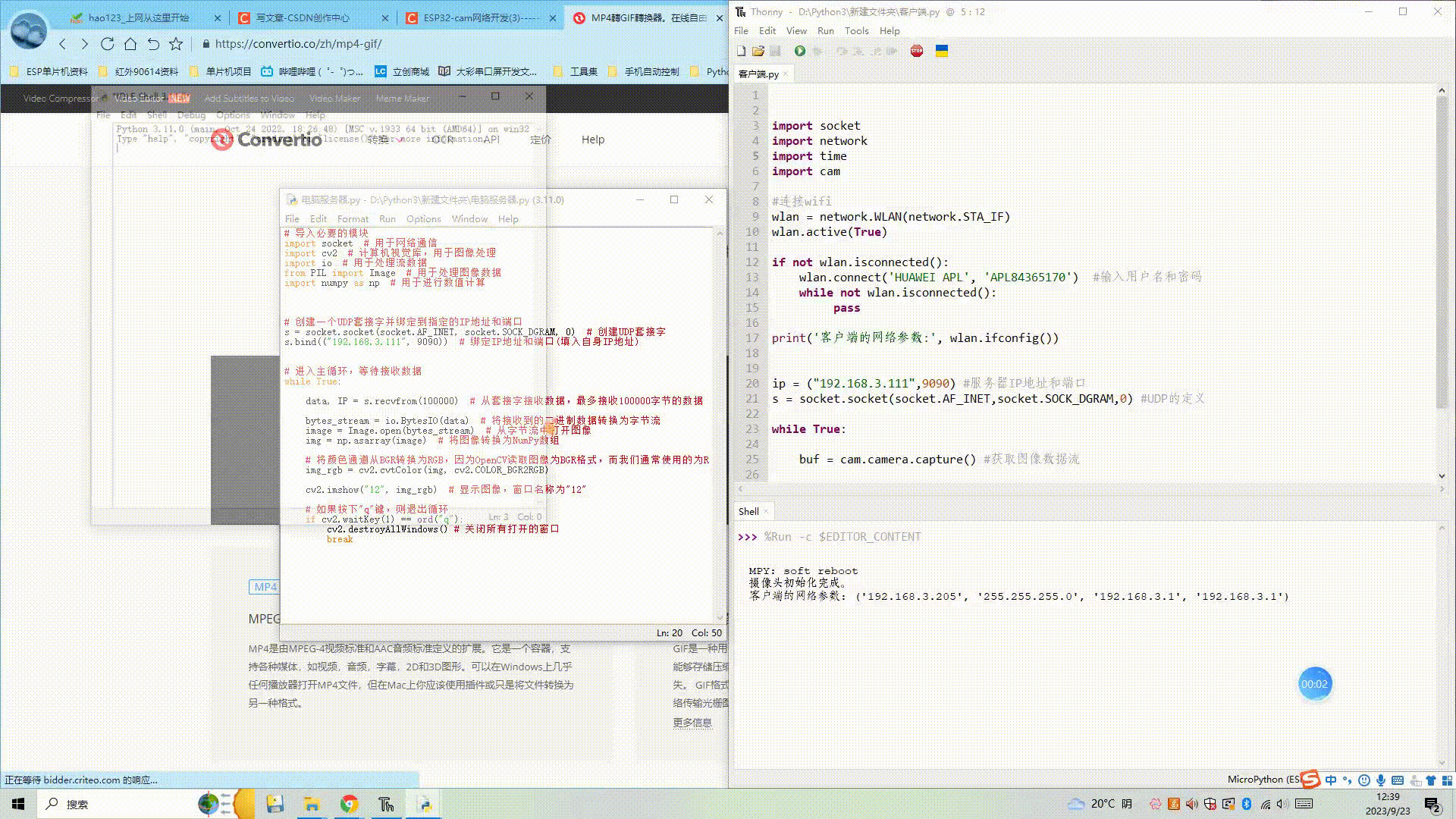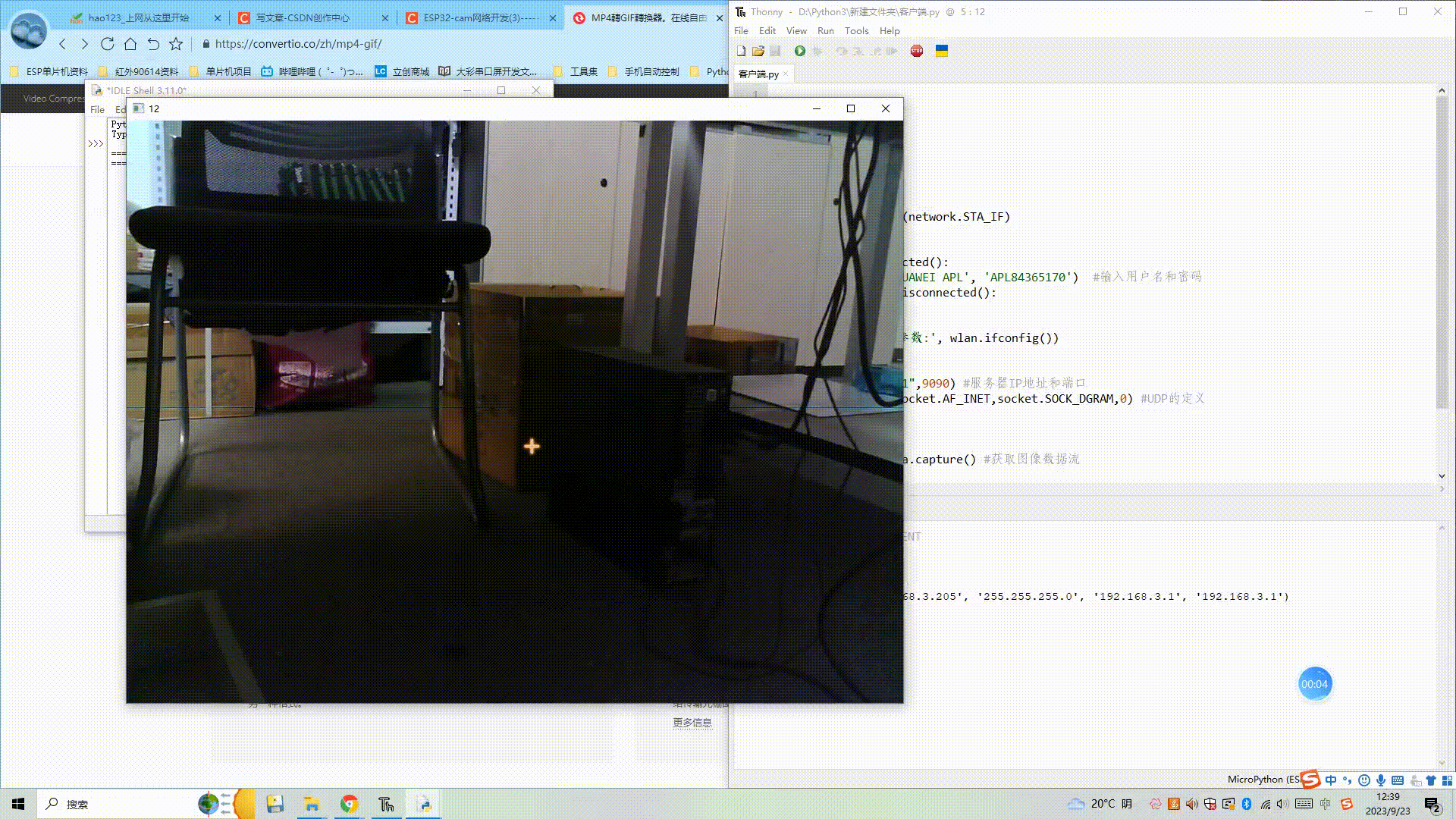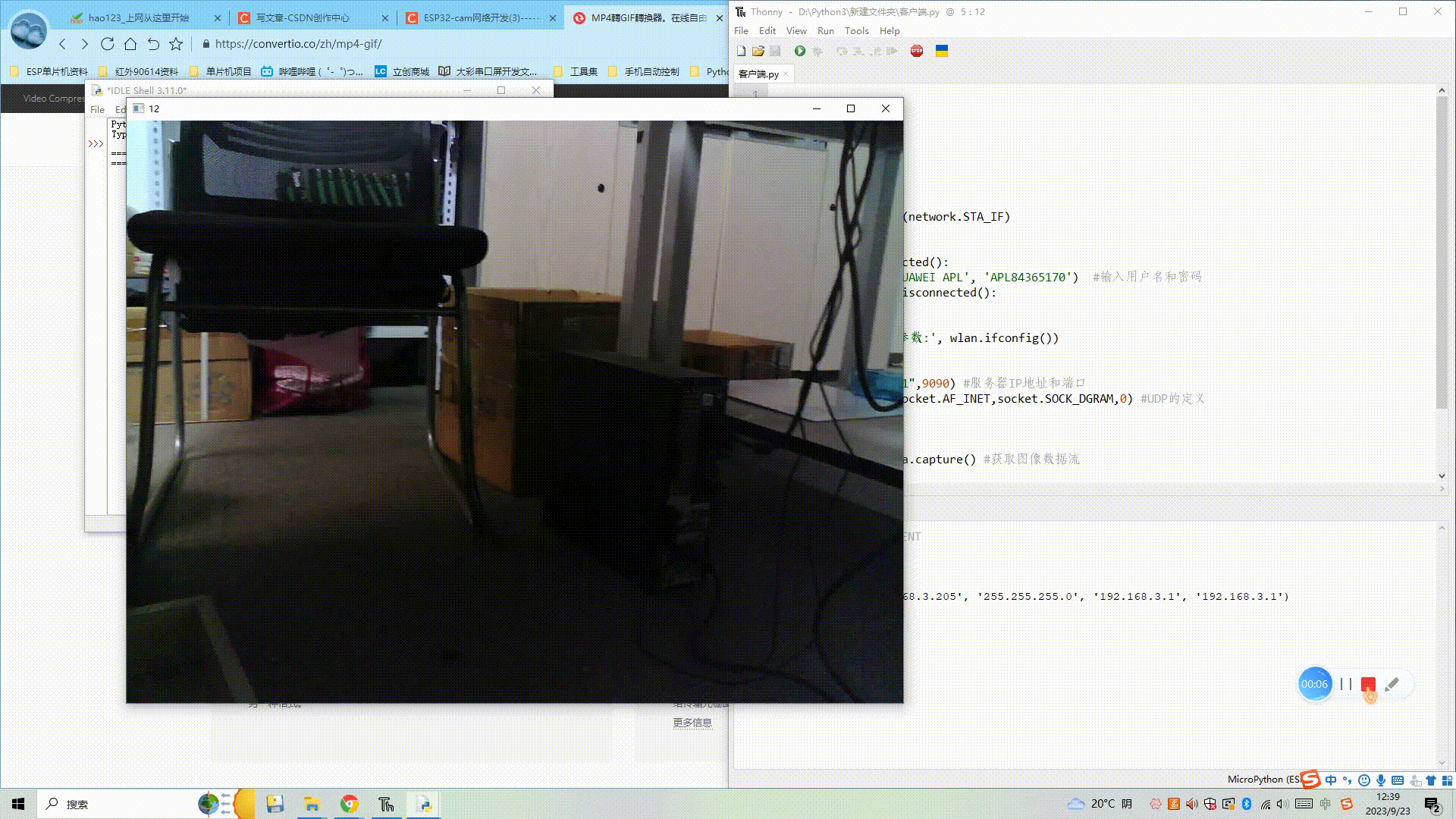
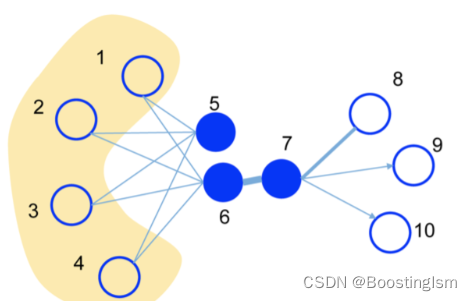
(1) ESP32获取图像,并通过电脑端服务器显示图像
目录 一、所需器件工具 二、客户端与服务器进行UDP通信 1、客户端代码 2、服务器端代码 3、效果展示 三、客户端拍照,通过UDP传输到服务器进行显示 1、客户端获取图像并UDP传输 2、电脑端服务器显示图像 3、效果展示 四、代码链接 一、所需器件工具 1.ESP3…...

乐鑫科技全球首批支持蓝牙 Mesh Protocol 1.1 协议
乐鑫科技 (688018.SH) 非常高兴地宣布,其自研的蓝牙 Mesh 协议栈 ESP-BLE-MESH 现已支持最新蓝牙 Mesh Protocol 1.1 协议的全部功能,成为全球首批在蓝牙技术联盟 (Bluetooth SIG) 正式发布该协议之前支持该更新的公司之一。这意味着乐鑫在低功耗蓝牙无线…...

1.算法——数据结构学习
算法是解决特定问题求解步骤的描述。 从1加到100的结果 # include <stdio.h> int main(){ int i, sum 0, n 100; // 执行1次for(i 1; i < n; i){ // 执行n 1次sum sum i; // 执行n次} printf("%d", sum); // 执行1次return 0; }高斯求和…...

信息论基础第二章阅读笔记
信息很难用一个简单的定义准确把握。 对于任何一个概率分布,可以定义一个熵(entropy)的量,它具有许多特性符合度量信息的直观要求。这个概念可以推广到互信息(mutual information),互信息是一种…...

Content-Type的取值
接口发送参数、接收响应数据,都需要双方约定好使用什么格式的数据,例如 json、xml。只有双方按照约定好的格式去解析数据才能正确的收发数据。而 Content-Type 就是用来告诉你数据的格式,这样我们才能知道怎么解析参数。 常见的 Content-Typ…...

【趣味JavaScript】5年前端开发都没有搞懂toString和valueOf这两个方法!
🚀 个人主页 极客小俊 ✍🏻 作者简介:web开发者、设计师、技术分享博主 🐋 希望大家多多支持一下, 我们一起进步!😄 🏅 如果文章对你有帮助的话,欢迎评论 💬点赞…...

Python中的接口是什么?
在Python中,接口是一种约定或协议,用于定义类应该实现哪些方法或属性。接口并不会提供实际的实现,而是只定义了类应该具有哪些方法和属性的签名。 Python中的接口通常通过抽象基类(Abstract Base Class,简称ABC&#…...
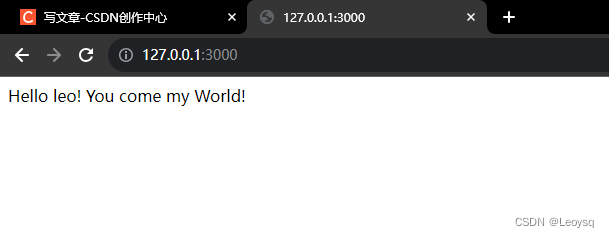
自学WEB后端01-安装Express+Node.js框架完成Hello World!
一、前言,网站开发扫盲知识 1.网站搭建开发包括什么? 前端 前端开发主要涉及用户界面(UI)和用户体验(UX),负责实现网站的外观和交互逻辑。前端开发使用HTML、CSS和JavaScript等技术来构建网页…...

从C语言到C++:C++入门知识(1)
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关C语言的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从入门到精通 数…...
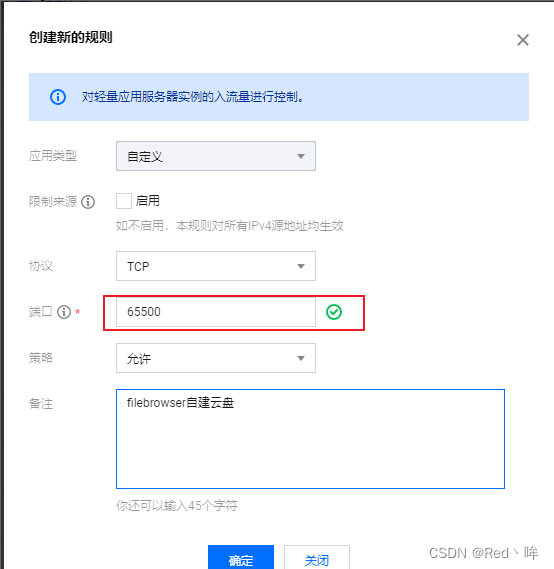
服务器(Windows系统)自建filebrowser网盘服务器超详细教程
需要依赖(工具) 轻量服务器(云服务器)一台 —— 环境Windows Server 2019filebrowser安装包(https://github.com/filebrowser/filebrowser/releases) 下载安装filebrowser 进入链接下载:https:/…...

扩展欧几里得
扩展欧几里得算法 求 a x b y d axbyd axbyd 的一组解, d gcd ( a , b ) d \gcd(a,b) dgcd(a,b)。 辗转相除递归求解。 假设已经求出 b x ( b m o d a ) y d bx (b \bmod a)y d bx(bmoda)yd 的一组解。 a x b y b x ′ ( b m o d a ) y ′ b x …...
)
MySQL 事务介绍 (事务篇 一)
什么是事务? 事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 注意点:默认MySQL的事务是自动提交…...

nvm nodejs的版本管理工具
nvm 全英文名叫 node.js version management,是一个 nodejs 的版本管理工具,为了解决 nodejs 各种版本存在不兼容现象可以通过他安装和切换不同版本的 nodejs。 一、完全删除之前的 node 和 npm 1. 打开 cmd 命令窗口,输入 npm cache clean…...
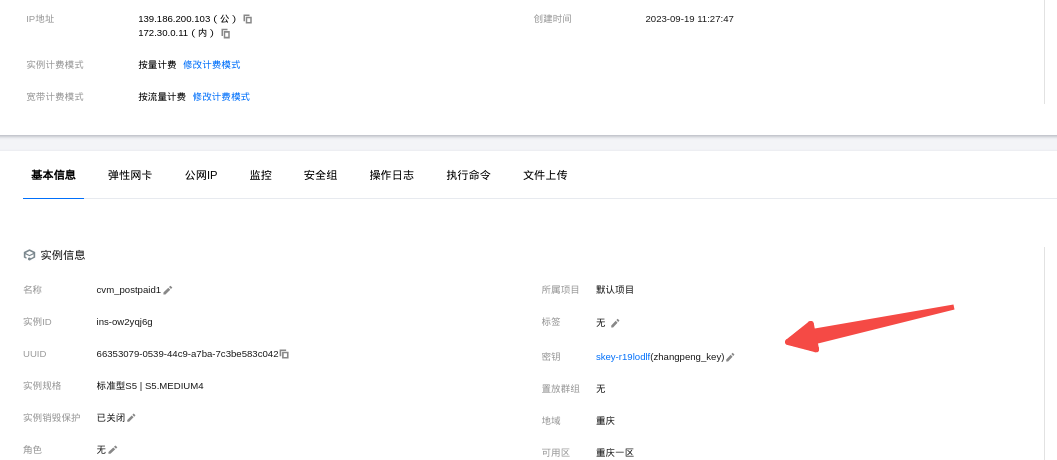
terraform简单的开始-vpc cvm创建
从网络开始 从创建VPC开始 复用前面的main.tf的代码: terraform {required_providers {tencentcloud {source "tencentcloudstack/tencentcloud"version "1.81.25"}} } variable "region" {description "腾讯云地域"…...
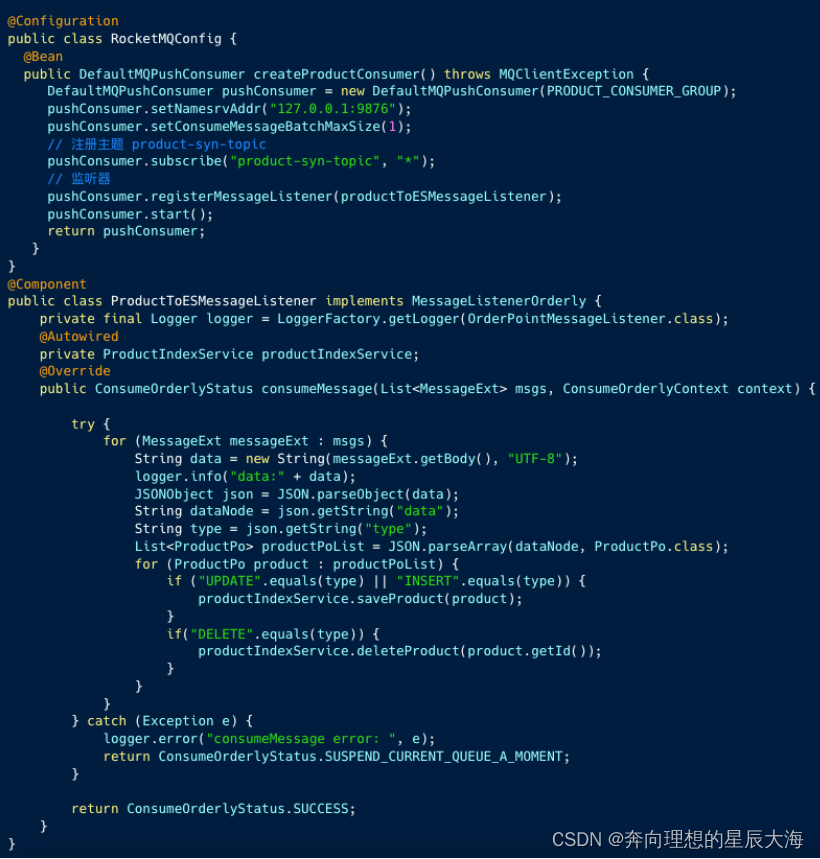
【MySQL】开启 canal同步MySQL增量数据到ES
开启 canal同步MySQL增量数据到ES canal 是阿里知名的开源项目,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。示使用 canal 将 MySQL 增量数据同步到ES。 一、集群模式 图中 server 对应一个 canal 运行实例 ,对应一…...
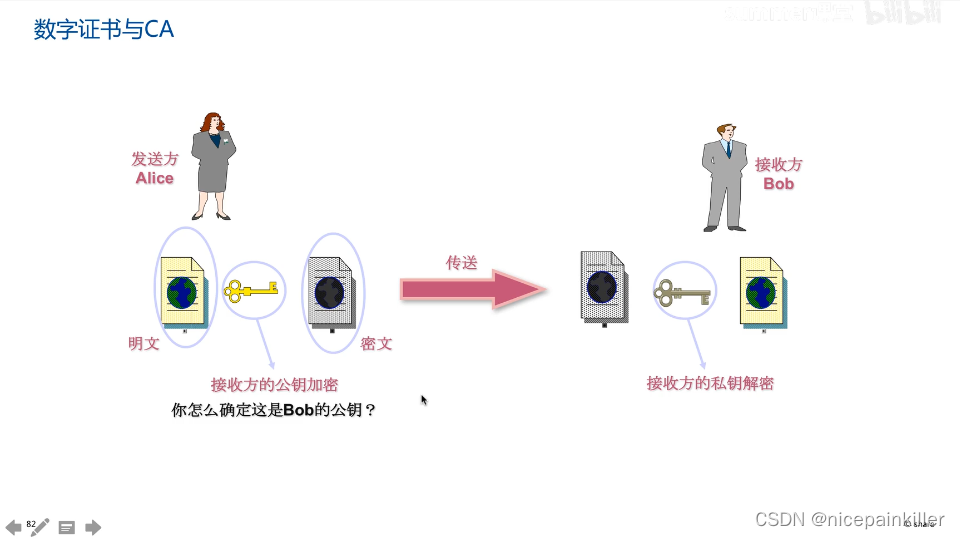
密码学概论
1.密码学的三大历史阶段: 第一阶段 古典密码学 依赖设备,主要特点 数据安全基于算法的保密,算法不公开,只要破译算法 密文就会被破解, 在1883年第一次提出 加密算法应该基于算法公开 不影响密文和秘钥的安全ÿ…...

渗透测试中的前端调试(一)
前言 前端调试是安全测试的重要组成部分。它能够帮助我们掌握网页的运行原理,包括js脚本的逻辑、加解密的方法、网络请求的参数等。利用这些信息,我们就可以更准确地发现网站的漏洞,制定出有效的攻击策略。前端知识对于安全来说,…...
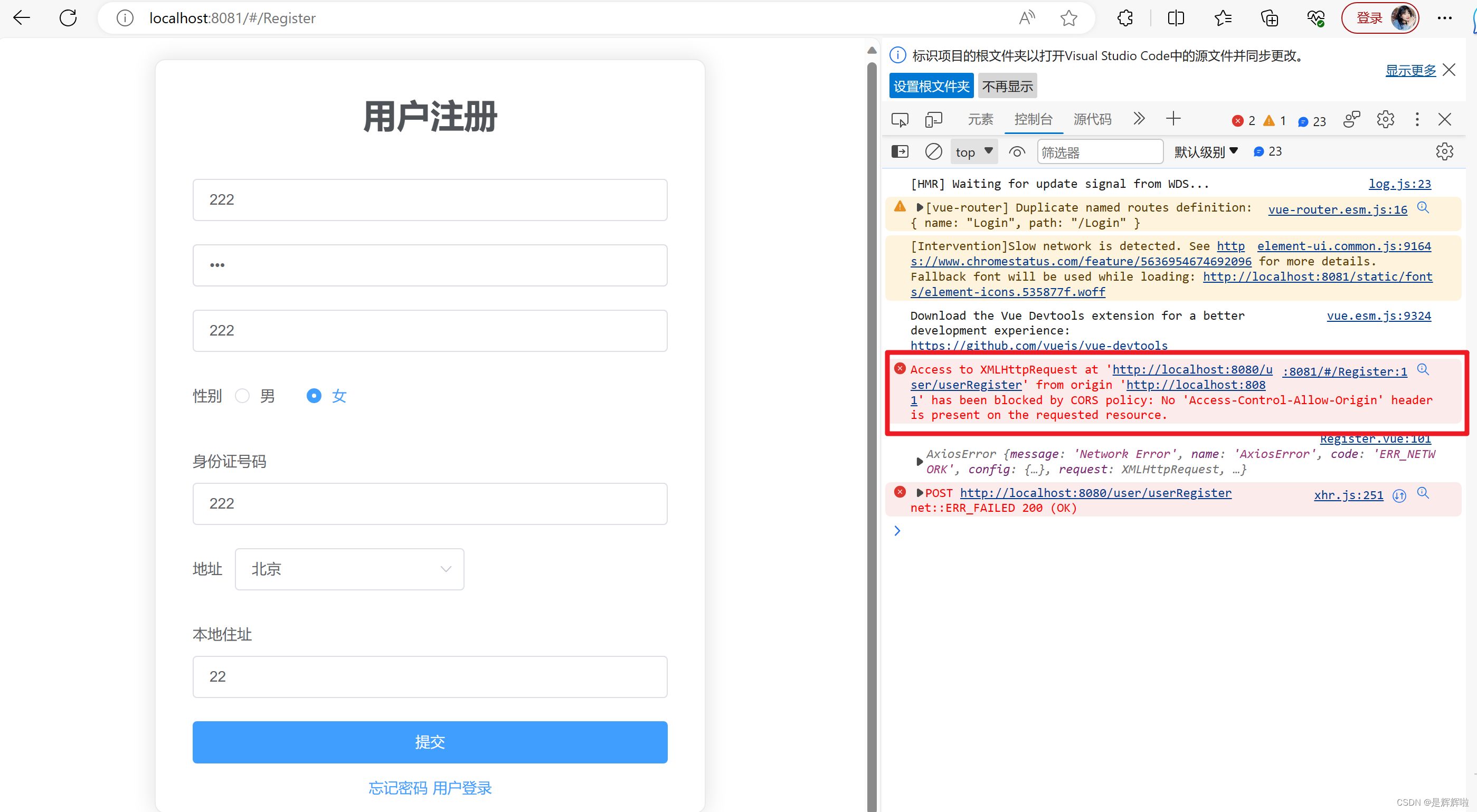
SPA项目之登录注册--请求问题(POSTGET)以及跨域问题
🥳🥳Welcome Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于VueElementUI的相关操作吧 目录 🥳🥳Welcome Huihuis Code World ! !🥳🥳 一.ElementUI是什么 💡…...

第08章 FastAPI 与 SSE 流式 RAG 后端
第08章 FastAPI 与 SSE 流式 RAG 后端 到目前为止,知识库、检索工具、MCP 客户端都已经就绪,但仍缺少一个面向最终用户的入口。本章用 FastAPI 把整条 RAG 链路串起来:接收前端发来的自然语言问题,调用 MCP 工具检索相关工单&…...

突破存储限制:群晖DSM7下Synology Photos自定义文件夹挂载实战
1. 为什么需要自定义文件夹挂载 很多群晖用户升级到DSM7后都会遇到一个头疼的问题:Synology Photos默认把所有个人照片都存放在/home/Photos目录下,而这个目录实际上位于/homes共享文件夹中。随着照片数量不断增加,/homes所在存储空间很快就会…...

5大优势解析:如何高效使用免费离线OCR工具
5大优势解析:如何高效使用免费离线OCR工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 项目…...

如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南
如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 您是否梦想过在任何设备上畅玩PC游戏&#x…...

UVa 366 Cutting Up
题目描述 拼布者经常需要将布料切割成 111 \times 111 的小正方形。他们有一种特殊工具(旋转切割刀),可以一次切割多层布料,切割层数的上限由布料类型决定(题目输入的第一个参数 KKK)。切割时,无…...

Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案
Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案 【免费下载链接】gopeed A fast, modern download manager for HTTP, BitTorrent, Magnet, and ed2k. Cross-platform, built with Golang and Flutter. 项目地址: https://gitcode.com/GitHub_Tre…...

从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程
从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程 在开源硬件社区,GitHub上每天都有大量优秀的STM32项目被分享——从智能家居控制器到四轴飞行器飞控系统。但当开发者满怀期待地git clone后,却常常在第一步"编译通过&…...

基于RAG的智能知识库问答系统:从原理到部署实战
1. 项目概述:当AI大模型遇见知识库,一个开源的智能问答解决方案 最近在折腾一个很有意思的开源项目,叫 zhimaAi/chatwiki 。光看名字,你大概能猜到它的核心: chat 代表对话, wiki 代表知识库。没错&a…...

基于Feather微控制器的智能灯光系统:颜色感应与BLE遥控实现
1. 项目概述与核心价值又到了折腾点节日氛围的时候了。往年都是买现成的彩灯串,总觉得少了点意思,今年决定自己动手,做个能“听懂”指令、甚至能“看见”颜色的智能灯光系统。这个项目的核心,就是用一块小小的微控制器,…...

终极网络资源下载神器:面向内容创作者的5步实战指南
终极网络资源下载神器:面向内容创作者的5步实战指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否曾为保…...