ElasticSearch - 文档 | 索引文档 | 检索文档 | 创建索引并指明映射
文章目录
- 1. ElasticSearch是面向文档的
- 2. 索引员工文档
- 3. 检索员工文档
- 4. 映射
1. ElasticSearch是面向文档的
在应用程序中对象很少只是一个简单的键和值的列表。通常,它们拥有更复杂的数据结构,可能包括日期、地理信息、其他对象或者数组等。
Elasticsearch 是面向文档的,意味着它存储整个对象或文档。Elasticsearch 不仅存储文档,而且索引每个文档的内容,使之可以被检索。在 Elasticsearch 中,我们对文档进行索引、检索、排序和过滤—而不是对行列数据。这是一种完全不同的思考数据的方式,也是 Elasticsearch 能支持复杂全文检索的原因。
ES使用 json 文档代表了一个对象,如 user 对象:
{"email": "john@smith.com","first_name": "John","last_name": "Smith","info": {"bio": "Eco-warrior and defender of the weak","age": 25,"interests": [ "dolphins", "whales" ]},"join_date": "2014/05/01"
}
虽然原始的 user 对象很复杂,但这个对象的结构和含义在 JSON 版本中都得到了体现和保留。
2. 索引员工文档
第一个业务需求是存储员工数据。 这将会以员工文档的形式存储:一个文档代表一个员工。存储数据到 Elasticsearch 的行为叫做索引 ,但在索引一个文档之前,需要确定将文档存储在哪里。
索引(名词):一个索引类似于传统关系数据库中的一个数据库,是一个存储关系型文档的地方。
索引(动词):索引一个文档就是存储一个文档到一个索引中以便被检索和查询。类似于 SQL 中的INSERT关键词。
对于员工目录,我们将做如下操作:
- 每个员工索引一个文档,文档包含该员工的所有信息。
- 该文档位于索引
user内。 - 该索引保存在我们的 Elasticsearch 集群中。
PUT /user/_doc/1
{"first_name" : "John","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests": [ "sports", "music" ]
}
json 文档 包含了这位员工的所有详细信息,他的名字叫 John Smith ,今年 25 岁,喜欢攀岩。无需进行执行管理任务,如创建一个索引或指定每个属性的数据类型之类的(可以不事先创建索引,也可以不事先指定映射),可以直接只索引一个文档。Elasticsearch 默认地完成其他一切,因此所有必需的管理任务都在后台使用默认设置完成。
索引更多的文档:
PUT /user/_doc/2
{"first_name" : "zhangsan","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests": [ "sports", "music" ]
}
PUT /user/_doc/3
{"first_name" : "lisi","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests": [ "sports", "music" ]
}
3. 检索员工文档
目前我们已经在Elasticsearch中存储了一些数据,接下来就能专注于实际应用的业务需求了。
① 第一个需求可以查询到单个雇员的数据:
GET /user/_doc/1
执行 一个 HTTP GET 请求并指定文档的地址就可以返回原始的 json 文档,返回结果包含了文档的一些元数据,以及 _source 属性,内容是 John Smith 雇员的原始 json 文档:
{"_index" : "user","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"first_name" : "John","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests" : ["sports","music"]}
}
将 HTTP 命令由 PUT 改为 GET 可以用来检索文档,同样的,可以使用 DELETE 命令来删除文档,以及使用 HEAD 指令来检查文档是否存在。如果想更新已存在的文档,只需再次 PUT 。
② 请求来搜索所有雇员:
GET /user/_search
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "user","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"first_name" : "John","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests" : ["sports","music"]}},{"_index" : "user","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"first_name" : "zhangsan","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests" : ["sports","music"]}},{"_index" : "user","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"first_name" : "lisi","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests" : ["sports","music"]}}]}
}
注意:返回结果不仅告知匹配了哪些文档,还包含了整个文档本身:显示搜索结果给最终用户所需的全部信息。
③ 尝试下搜索名为 John 的雇员,我们通过一个URL参数来传递查询信息给搜索接口:
GET /user/_search?q=first_name:John
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.9808292,"hits" : [{"_index" : "user","_type" : "_doc","_id" : "1","_score" : 0.9808292,"_source" : {"first_name" : "John","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests" : ["sports","music"]}}]}
}
4. 映射
映射是定义文档及其包含的字段如何存储和索引的过程。每个文档都是字段的集合,每个字段都有自己的数据类型。在映射数据时,创建一个映射定义,其中包含与文档相关的字段类型。
1、字符串类型:
(1) text类型:当一个字段需要用于全文搜索(会被分词),比如产品名称、产品描述信息, 就应该使用text类型。该类型字段会通过分析器转成terms list,然后存入索引。该类型字段不用于排序、聚合操作。
(2)keyword类型:当一个字段需要按照精确值进行过滤、排序、聚合等操作时, 就应该使用keyword类型。该类型的字段值不会被分析器处理(分词)
2、数值类型:
(1) byte:有符号的8位整数, 范围: [-128 ~ 127]
(2) short:有符号的16位整数, 范围: [-32768 ~ 32767]
(3) integer:有符号的32位整数, 范围: [−231−231 ~ 231231-1]
(4) long:有符号的64位整数, 范围: [−263−263 ~ 263263-1]
(5) float:32位单精度浮点数
(6) double:64位双精度浮点数
(7) half_float:16位半精度IEEE 754浮点类型
(8) scaled_float:缩放类型的的浮点数, 比如price字段只需精确到分, 57.34缩放因子为100, 存储结果为5734
3、boolean类型:
可以使用boolean类型的(true、false)也可以使用string类型的(“true”、“false”)。
4、日期类型:
JSON没有日期数据类型, 所以在ES中, 日期可以是:
- 包含格式化日期的字符串, “2018-10-01”, 或"2018/10/01 12:10:30".
- 代表时间毫秒数的长整型数字.
- 代表时间秒数的整数.
5、复杂数据类型:
es支持复杂的数据类型,包括:object、array、nested。
① 查看索引员工文档时默认创建的映射:
GET /user/_mapping
{"user" : {"mappings" : {"properties" : {"about" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"age" : {"type" : "long"},"first_name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"interests" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"last_name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}
}
② 索引文档之前,先创建索引并指定映射(文档理解为对象,映射理解为对象中属性的类型):
PUT /user
{"mappings": {"properties": {"age": {"type": "long"},"about": {"analyzer": "ik_max_word","search_analyzer": "ik_smart","type": "text"},"first_name": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"last_name": {"analyzer": "ik_max_word","search_analyzer": "ik_smart","type": "text"},"interests": {"analyzer": "ik_max_word","search_analyzer": "ik_smart","type": "text"}}}
}
相关文章:

ElasticSearch - 文档 | 索引文档 | 检索文档 | 创建索引并指明映射
文章目录1. ElasticSearch是面向文档的2. 索引员工文档3. 检索员工文档4. 映射1. ElasticSearch是面向文档的 在应用程序中对象很少只是一个简单的键和值的列表。通常,它们拥有更复杂的数据结构,可能包括日期、地理信息、其他对象或者数组等。 Elastic…...

SQL中的DML、DDL、DCL分别是什么意思
SQL命令的分类 数据定义语言 DDL(DataDefinition Language) 是 SQL 语言集中负责数据结构定义。 DDL 的核心指令是CREATE、ALTER、DROP。 操作的对象包括:库、表、视图、索引等。 如:CREATE TABLE ; ALTER INDEX; DROP VIEW; 数据…...

kubeasz部署k8s高可用集群
前言:如无特殊说明,所有操作都用root账号在所有节点执行。 说明:kubeasz是一款国产开源的k8s部署软件,采用ansible role的部署方式,部署k8s二进制集群。熟悉ansible role的用该软件部署k8s方便快捷。 一、机器 deplo…...

2022年工程机械出口专题研究【重工】
文章目录2022年工程机械出口专题研究1、中国是全球工程机械第一大市场,竞争力逐步提升2、工程机械出口高增,市场分布趋于多元,企业营收获益3、海外市场高速增长原因为何?4、海外市场增长动能预测附件:2022年工程机械出…...
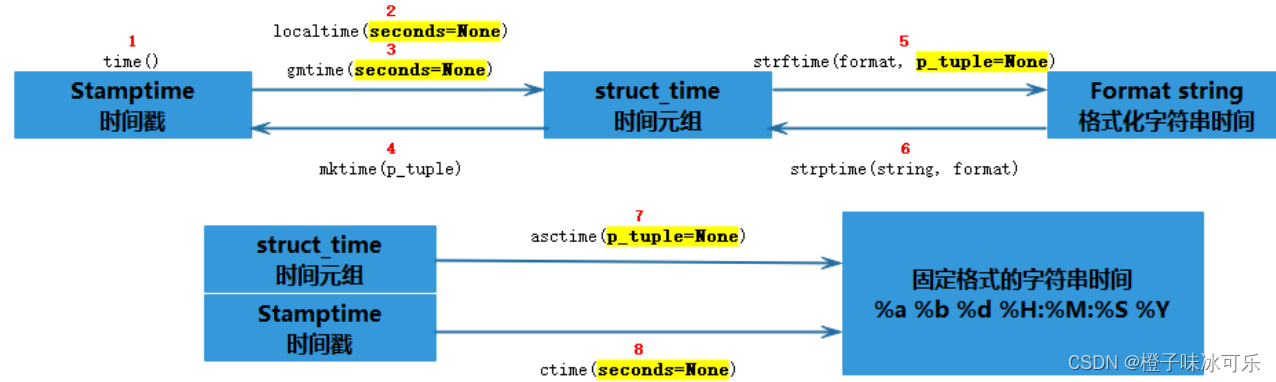
[python入门(51)] - python时间日期格式time和datetime
目录 ❤ 预备知识 ❤ UTC time Coordinated Universal Time ❤ epoch time ❤ timestamp(时间戳) ❤ stamptime时间戳 ❤ struct_time时间元组 ❤ format time 格式化时间 ❤ time模块编辑 ❤ 获取当前时间的方法 ❤ 当传入默认参…...
别担心ChatGPT距离替代程序猿还有距离
经过多天对chat-GPT在工作的使用,我得出一个结论,它睁眼瞎说就算了,它还积极认错,绝不改正,错误答案极具误导性,啥也不说了,请看图。 经过N次较量它固执的认为 0011 1101 0110 0101在最高位是左…...
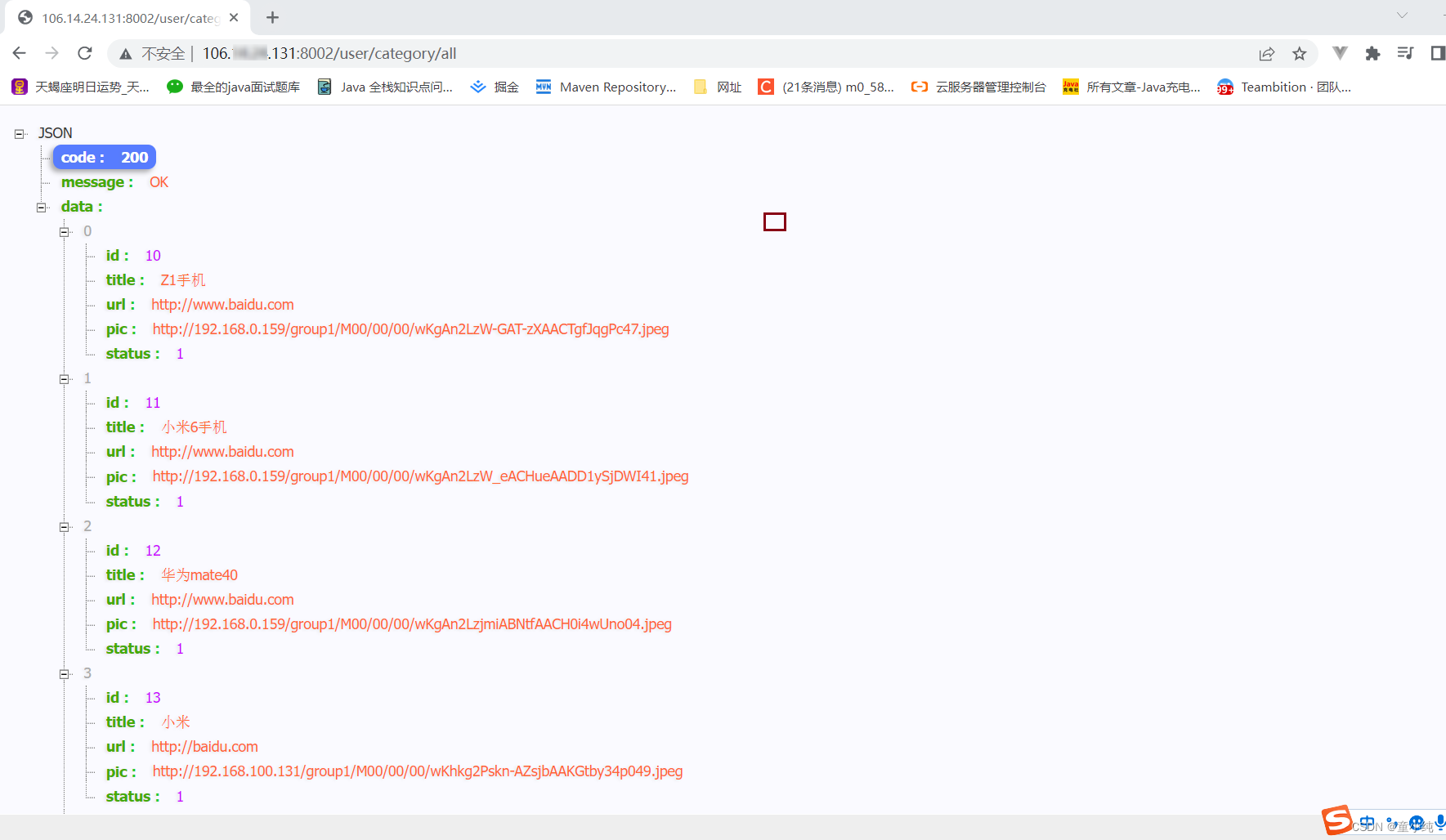
SpringBoot项目打包部署到阿里云服务器、通过Maven插件制作Docker镜像、部署项目容器、配置生产环境
制作通用模块jar包 通用模块不是运行的,而且要被其他模块引入的,所以该模块不能采用springboot打包方式制作jar包,否则其他模块无法引入通用模块。 1、修改通用模块,设置模块为非Springboot项目 <?xml version"1.0&qu…...
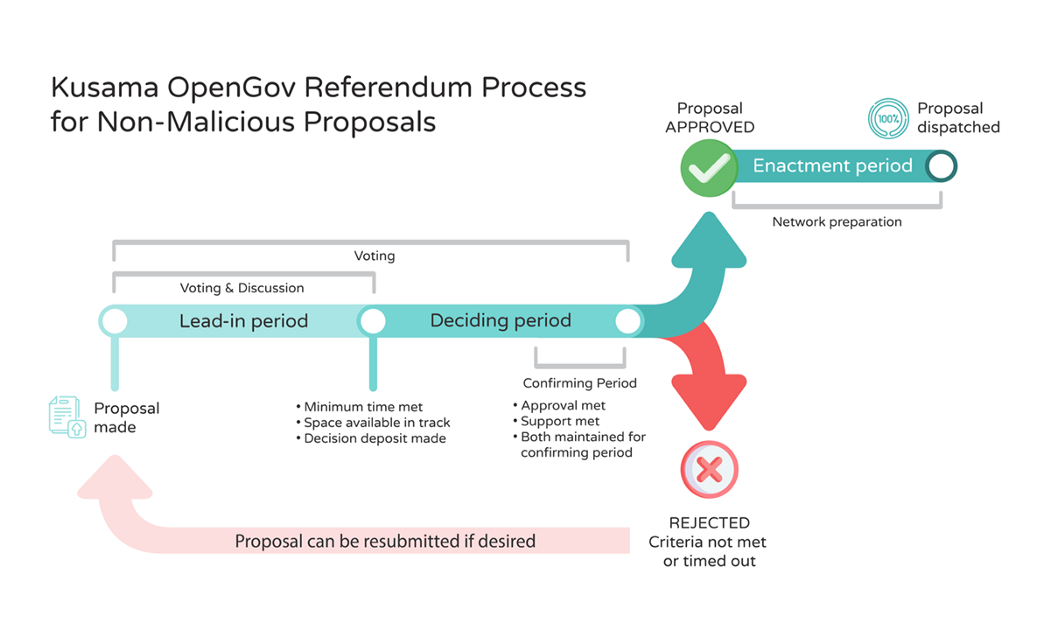
OpenGov的首个方案已上线Moonriver
随着公投128的通过,作为Runtime 2100的一部分,Moonbeam在Moonriver上推出了OpenGov。Moonbeam上的OpenGov部署将从Moonriver开始,以获得社区反馈。未来将举行公投,让社区来决定OpenGov如何发展并转移至Moonbeam。 Moonriver上的O…...

(三十一)大白话MySQL如果事务执行到一半要回滚怎么办?再探undo log回滚日志原理
之前我们已经给大家深入讲解了在执行增删改操作时候的redo log的重做日志原理,其实说白了,就是你对buffer pool里的缓存页执行增删改操作的时候,必须要写对应的redo log记录下来你做了哪些修改 如下图所示: 这样万一要是你提交事…...
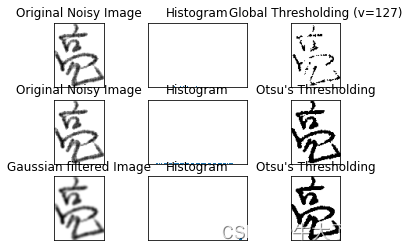
机器学习-基于KNN及其改进的汉字图像识别系统
一、简介和环境准备 knn一般指邻近算法。 邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。而lmknn是局部均值k最近邻分类算法。 本次实验环境需要用的是Google Colab和Google Dr…...

Zebec生态持续深度布局,ZBC通证月内翻倍或只是开始
“Zebec生态近日利好不断,除了推出了回购计划外, Nautilus Chain 、Zebec Labs等也即将面向市场,都将为ZBC通证深度赋能。而ZBC通证涨幅月内突破100%,或许只是开始。”近日,流支付生态Zebec生态通证ZBC迎来了大涨&…...

Leetcode.1238 循环码排列
题目链接 Leetcode.1238 循环码排列 Rating : 1775 题目描述 给你两个整数 n和 start。你的任务是返回任意 (0,1,2,,...,2^n-1)的排列 p,并且满足: p[0] startp[i]和 p[i1]的二进制表示形式只有一位不同p[0]和 p[2^n -1]的二进制表示形式也…...
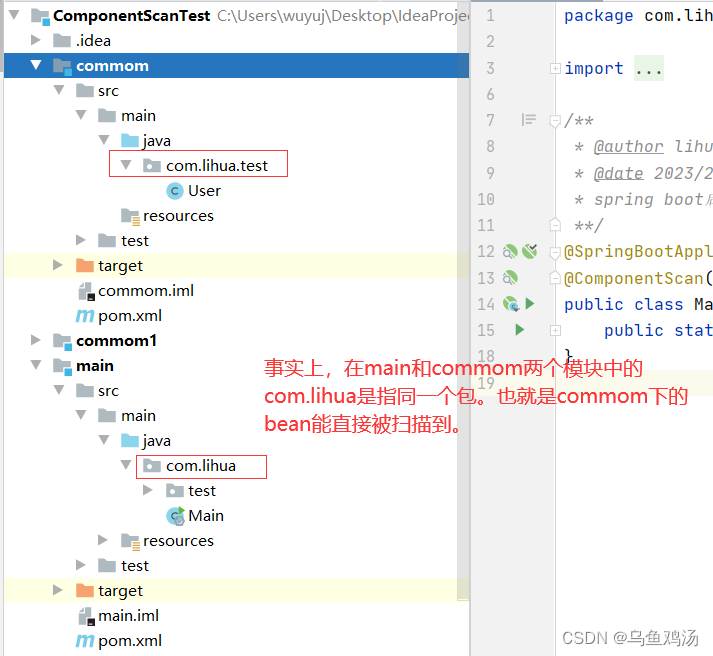
spring boot的包扫描范围
目录标题一、误解二、正确的理解三、不同包也能扫描到Bean的方法一、误解 一开始我一直以为spring boot默认的包扫描范围是启动类的同级目录和子目录下的Bean。其实正真是与启动类在同个包以及子包下的Bean。 我一直误解了包的概念,包并不是只文件夹(文…...

常青科技冲刺A股上市:研发费用率较低,关联方曾拆出资金达1亿元
近日,江苏常青树新材料科技股份有限公司(下称“常青科技”或“常青树科技”)递交招股书,准备在上海证券交易所主板上市。本次冲刺上市,常青科技计划募资8.50亿元,光大证券为其保荐机构。 据招股书介绍&…...
【Linux】工具(1)——yum
好久不见,让大家久等啦~最近开学被一系列琐事所耽误了,接下来会进入稳定更新状态~话不多说,在我们了解Linux基本内容之后,我们的目的是要在Linux环境下进行软硬件开发,在这个过程中我们会用到一系列工具,例…...

MySQL - 排序与分页
目录1. 排序1.2 排序规则1.2 单列排序1.3 多列排序2. 分页2.1 实现规则1. 排序 1.2 排序规则 使用 ORDER BY 子句排序 ASC(ascend):升序DESC(descend):降序 ORDER BY 子句在SELECT语句的结尾。 1.2 单列…...

自动化测试框架对比
Robot Framework(RF) 链接:http://robotframework.org/ Robot Framework(RF)是用于验收测试和验收测试驱动开发(ATDD)的自动化测试框架。 基于 Python 编写,但也可以在 Jython&…...

第7章 Memcached replace 命令教程
Memcached replace 命令教程用于替换已存在的 key(键) 的 value(数据值)。 如果 key 不存在,则替换失败,并且将获得响应 NOT_STORED。 语法: replace 命令的基本语法格式如下: replace key flags exptime bytes [noreply]value…...
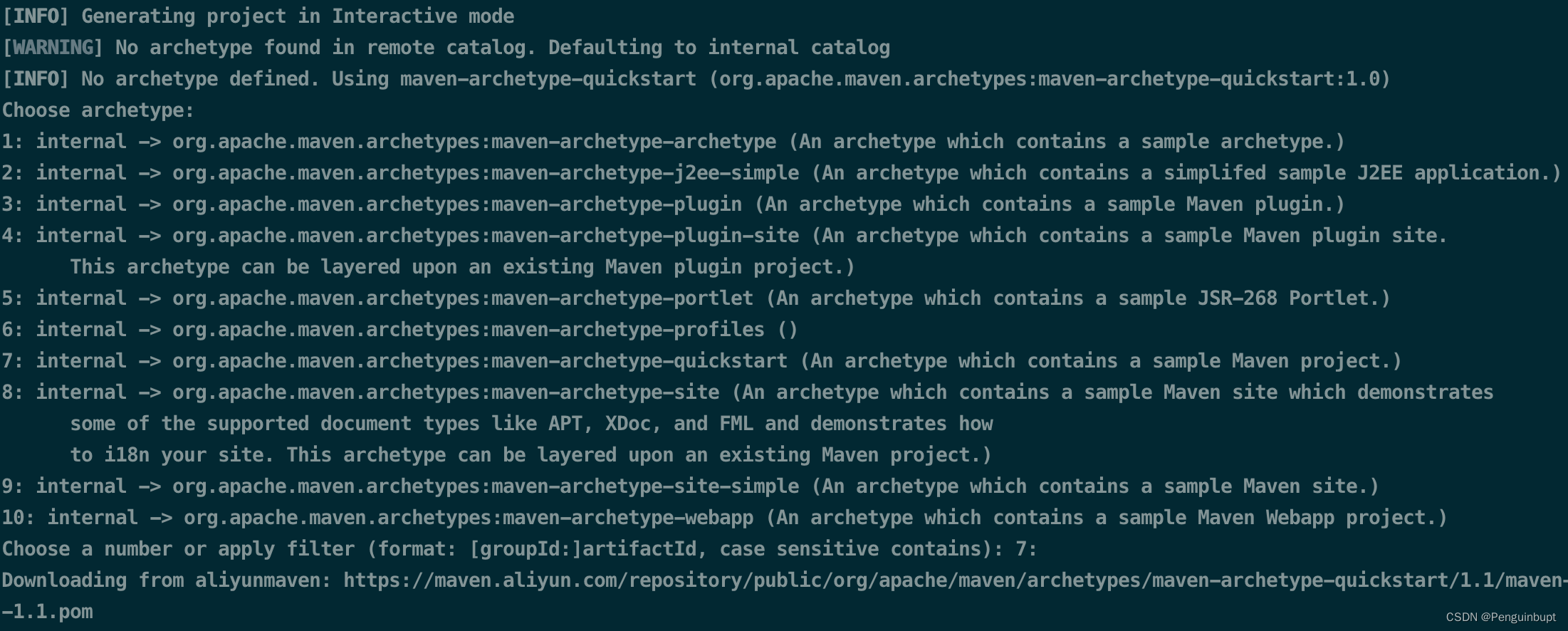
我记不住的那些maven内容
背景: 之前使用maven都是基于IDE并且对maven本身也很少究其过程和原理,当出现问题也不知道如何解决,后续想使用命令行来进行操作,并通过文档记录一下学习的内容加深理解以防止忘记。 一、简要介绍 maven是通过插件来增强功能&am…...
【Java】Spring更简单的读取和存储
文章目录Spring更简单的读取和存储对象1. 存储Bean对象1.1 前置工作:配置扫描路径1.2 添加注解存储Bean对象1.2.1 Controller(控制器存储)1.2.2 Service(服务存储)1.2.3 Repository(仓库存储)1.2.4 Component(组件存储)1.2.5 Configuration1.3 为什么要这么多类注解…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

13456
12356...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...