用于自然语言处理的 Python:理解文本数据

一、说明
Python是一种功能强大的编程语言,在自然语言处理(NLP)领域获得了极大的普及。凭借其丰富的库集,Python 为处理和分析文本数据提供了一个全面的生态系统。在本文中,我们将介绍 Python for NLP 的一些基础知识,重点是理解文本数据和实现代码来执行各种 NLP 任务。
二、用于自然语言处理的 Python:理解文本数据
文本数据在 NLP 应用程序中起着重要作用,从情感分析到机器翻译。了解文本数据的结构和属性对于有效地处理和从中提取有意义的信息非常重要。
2.1 什么是文本数据?
通常,文本数据是指任何形式的人类可读文本。它可以来自各种媒介,包括书籍、网站、社交媒体帖子或客户评论。文本数据通常表示为字符、单词或标记的序列。
2.2 标记化:将文本分解为单元
标记化是将文本数据分解为更小、有意义的单元(称为标记)的过程。标记可以是单词、短语,甚至是单个字符。有几个库,如NLTK(自然语言工具包)和spaCy,提供高效的标记化功能。
import nltk
nltk.download('punkt')text = "Python is my favourite programming language."
tokens = nltk.word_tokenize(text)
print(tokens)
2.3 词形还原和词干提取
词形还原和词干提取是用于规范化文本数据中的单词的技术。词形还原将单词简化为其基本形式或字典形式,称为引理。另一方面,词干分析通过删除前缀和后缀将单词修剪为根形式。这些技术有助于减少单词变化并提高后续NLP任务的效率。
from nltk.stem import WordNetLemmatizer, PorterStemmer
nltk.download('wordnet')lemmatizer = WordNetLemmatizer()
stemmer = PorterStemmer()word = "running"
print("Lemmatized Word:",lemmatizer.lemmatize(word))
print("Stemmed Word:",stemmer.stem(word))
2.4 停用词:滤除噪音
停用词是语言中通常出现的词,不具有重要意义。停用词的示例包括“the”、“is”和“and”。在NLP中,从文本数据中删除停用词通常是有益的,因为它们会引入噪声并阻碍分析的准确性。像NLTK这样的Python库为不同的语言提供了预定义的停用词列表。
from nltk.corpus import stopwords
nltk.download('stopwords')stop_words = set(stopwords.words('english'))
filtered_tokens = [token for token in tokens if token not in stop_words]
print(filtered_tokens)
2.5 词性 (POS) 标记
词性标记是为句子中的单词分配语法标签的过程,指示它们的句法角色。这些标签可以是名词、动词、形容词或其他词性。POS 标记对于理解文本数据中单词的上下文和含义至关重要。像NLTK和spaCy这样的库提供了高效的POS标记功能。
nltk.download('averaged_perceptron_tagger')pos_tags = nltk.pos_tag(tokens)
print(pos_tags)
三、不同应用和目的
3.1 命名实体识别 (NER)
命名实体识别是 NLP 的一个子任务,涉及识别和分类文本数据中的命名实体。命名实体可以是人员、组织、位置或任何其他专有名词的名称。像spaCy这样的Python库为NER提供了预先训练的模型,使得从文本中提取有价值的信息变得更加容易。
import spacynlp = spacy.load('en_core_web_sm')
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")for ent in doc.ents:print(ent.text, ent.label_)
3.2 情绪分析
情感分析是确定文本数据的情绪或情感基调的过程。它涉及将文本分类为正面、负面或中性。Python 提供了各种库,例如 NLTK 和 TextBlob,它们为情感分析提供了预先训练的模型。这些模型可用于分析客户反馈、社交媒体帖子或任何其他文本数据,以深入了解公众舆论。
from textblob import TextBlobtext = "Python is a great programming language." blob = TextBlob(text) print(blob.sentiment)
3.3 主题建模
主题建模是一种用于从文档集合中提取基础主题或主题的技术。它有助于理解文本数据中存在的主要思想或概念。Python的流行库Gensim为主题建模提供了有效的算法,例如潜在狄利克雷分配(LDA)。这些算法可以应用于大型文本语料库,以发现隐藏的模式并生成有意义的摘要。
from gensim import corpora, modelsdocuments = ["Human machine interface for lab abc computer applications","A survey of user opinion of computer system response time","The EPS user interface management system","System and human system engineering testing of EPS"]texts = [doc.split() for doc in documents] dictionary = corpora.Dictionary(texts) corpus = [dictionary.doc2bow(text) for text in texts]lda_model = models.LdaModel(corpus, num_topics=2, id2word=dictionary) print(lda_model.print_topics())
3.4 文本分类
文本分类是将文本数据分类为预定义类或类别的过程。它在垃圾邮件过滤、情绪分析、新闻分类和许多其他领域找到了应用。文本分类模型可以使用Python库(如scikit-learn和TensorFlow)进行构建和训练。
from sklearn.feature_extraction.text import CountVectorizer from sklearn.naive_bayes import MultinomialNBX = ["Python is a versatile programming language.", "I love Python.", "Python is great for data analysis."] y = ["positive", "positive", "positive"] vectorizer = CountVectorizer() X_transformed = vectorizer.fit_transform(X)clf = MultinomialNB().fit(X_transformed, y) print(clf.predict(vectorizer.transform(["Python is awesome!"])))
3.5 词嵌入
词嵌入是单词的密集向量表示,用于捕获它们之间的语义关系。它们广泛用于 NLP 任务,例如单词相似性、文档聚类和语言翻译。Python的库spaCy提供了预先训练的词嵌入模型,如Word2Vec和GloVe。
nlp = spacy.load('en_core_web_md')tokens = nlp("dog cat banana")for token in tokens:print(token.text, token.has_vector, token.vector_norm, token.is_oov)
3.6 语言翻译
语言翻译涉及将文本从一种语言转换为另一种语言。Python的流行库PyTorch提供了一个强大的机器翻译工具包,称为Fairseq。它利用深度学习模型(如变形金刚)来实现准确流畅的翻译。
您可以安装以下库
pip install torch fairseq
import torch
from fairseq.models.transformer import TransformerModel# Load the pre-trained translation model
model_name = 'transformer.wmt19.en-de'
model = TransformerModel.from_pretrained(model_name)# Set the model to evaluation mode
model.eval()# Define the source sentence to be translated
source_sentence = "Hello, how are you?"# Translate the source sentence to the target language
translated_sentence = model.translate(source_sentence)# Print the translated sentence
print("Translated Sentence:", translated_sentence)
3.7 文本生成
文本生成是一项具有挑战性的 NLP 任务,涉及根据给定提示生成连贯且上下文相关的文本。Python的库OpenAI GPT为ChatGPT提供支持,是一个最先进的模型,擅长文本生成。它可以在特定域上进行微调,也可以开箱即用地用于各种创意写作应用程序。
import openai# Set up your OpenAI GPT model
model_name = "text-davinci-003"
openai.api_key = "YOUR_API_KEY_HERE"# Define the prompt for text generation
prompt = "Once upon a time"# Set the maximum number of tokens to generate
max_tokens = 100# Generate text based on the prompt
response = openai.Completion.create(engine=model_name,prompt=prompt,max_tokens=max_tokens
)# Extract the generated text from the API response
generated_text = response.choices[0].text.strip()# Print the generated text
print("Generated Text:")
print(generated_text)
四、用于 NLP 的 Python 库
Python 为 NLP 提供了广泛的库和框架,使其成为文本数据处理的首选语言。一些流行的库包括:
- 自然语言工具包 (NLTK)
- 空间
- 根西姆
- TextBlob
- scikit-learn
- 张量流
- PyTorch
- 费尔塞克
- OpenAI GPT
这些库为各种 NLP 任务提供了广泛的功能和预先训练的模型,使开发人员能够专注于手头的特定问题。
五、结论
Python已经成为自然语言处理(NLP)的流行语言,因为它可以做许多不同的事情,并且有很多库。本文探讨了将 Python 用于 NLP 的基础知识,强调了理解文本数据和利用代码执行各种 NLP 任务的重要性。从词汇分词和词形还原到停止词删除、词性标记、命名实体识别、情感分析、主题建模、文本分类、单词嵌入、语言翻译和文本生成,Python 库(如 NLTK、spaCy、Gensim、TextBlob、scikit-learn、TensorFlow、PyTorch、Fairseq 和 OpenAI GPT)为高效的文本数据处理和分析提供了强大的解决方案和预训练模型。
纳文·潘迪
相关文章:
用于自然语言处理的 Python:理解文本数据
一、说明 Python是一种功能强大的编程语言,在自然语言处理(NLP)领域获得了极大的普及。凭借其丰富的库集,Python 为处理和分析文本数据提供了一个全面的生态系统。在本文中,我们将介绍 Python for NLP 的一些基础知识&…...

历史服务器
二、配置历史服务器 在spark-3.1.1-bin-hadoop2.7/conf/spark-defaults.conf添加以下配置,其中d:/log/spark为日志保存位置 spark.eventLog.enabled true spark.eventLog.dir file:///d:/log/spark spark.eventLog.compress true spark.history.fs.logDirectory fil…...

竞赛无人机搭积木式编程(四)---2023年TI电赛G题空地协同智能消防系统(无人机部分)
竞赛无人机搭积木式编程(四) ---2023年TI电赛G题空地协同智能消防系统(无人机部分) 无名小哥 2023年9月15日 赛题分析与解题思路综述 飞控用户在学习了TI电赛往届真题开源方案以及用户自定义航点自动飞行功能方案讲解后&#x…...
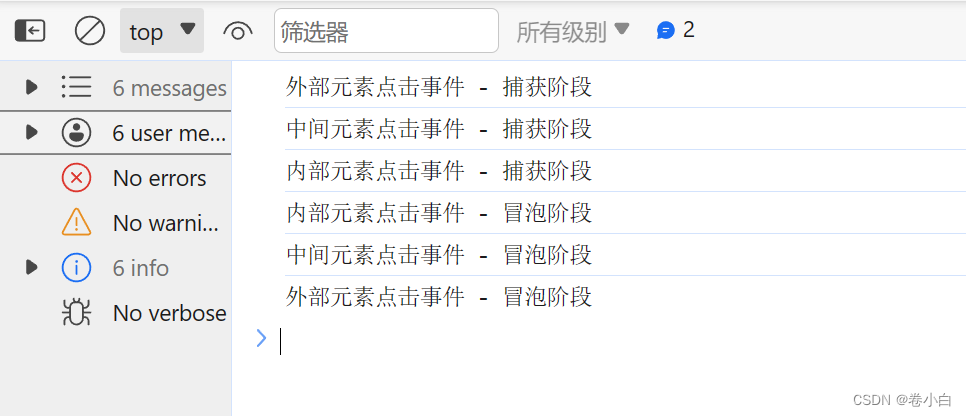
深入理解JavaScript中的事件冒泡与事件捕获
在JavaScript中,事件是交互式网页开发中的关键概念之一。了解事件冒泡和事件捕获是成为一名优秀的前端开发者所必需的技能之一。本文将深入探讨这两个概念,解释它们是如何工作的,以及如何在实际应用中使用它们来处理事件。 一.什么是事件冒泡…...

纯css html 真实水滴效果
惯例,不多说直接上图 秉承着开源精神,我们将这段代码无私地分享给大家,因为我们深信,信息的共享和互相学习是推动科技进步的关键。我们鼓励大家在使用这段代码的同时,也能够将其中的原理、思想和经验分享给更多的人。 这份代码是我们团队用心…...

HBASE集群主节点迁移割接手动操作步骤
HBASE集群主节点迁移割接手动操作步骤 HBASE集群主节点指的是包含zk、nn、HM和rm服务的节点,一般这类服务都是一起复用在同一批节点上,我把这一类节点统称为HBASE集群主节点。 本文中使用了rsync、pssh等工具,这类是开源的,自己…...

TRB爆仓分析,套利分析,行情判断!
毫无疑问昨日TRB又成为涨幅榜的明星,总结下来,多军赚麻,空头爆仓,套利爽歪歪! 先说风险最小的套利情况,这里两种套利都能实现收益。 现货与永续合约的资金费率套利年化资金费率达到惊人的3285%——DeFi的…...

LVGL - RV1109 LVGL UI刷新效率优化-02
说明 前面好早写过一个文章,说明如何把LVGL移到RV1109上的操作,使用DRM方式!但出现刷新效率不高的问题! 因为一直没有真正的应用在产品中,所以也就放下了! 最近开发上需要考虑低成本,低内存的…...

5、布局管理器
5、布局管理器 一、流式布局 package com.dryant.lesson1;import java.awt.*;public class TestFlowLayout {public static void main(String[] args) {Frame frame new Frame();Button button1 new Button("bt1");Button button2 new Button("bt2");…...
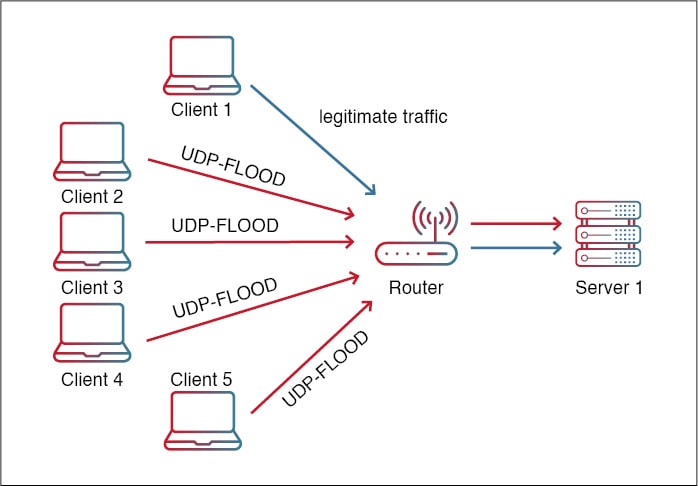
What is a UDP Flood Attack?
用户数据报协议 (UDP) 是计算机网络中使用的无连接、不可靠的协议。它在互联网协议 (IP) 的传输层上运行,并提供跨网络的快速、高效的数据传输。与TCP(其更可靠的对应物)不同,UDP不提…...

多核 ARM Server 性能调优
概述 thinkforce ARM Server是多核心ARM服务器,硬件环境资源如下: CPU信息如下: yuxunyuxun:/$ lscpu Architecture: aarch64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian …...
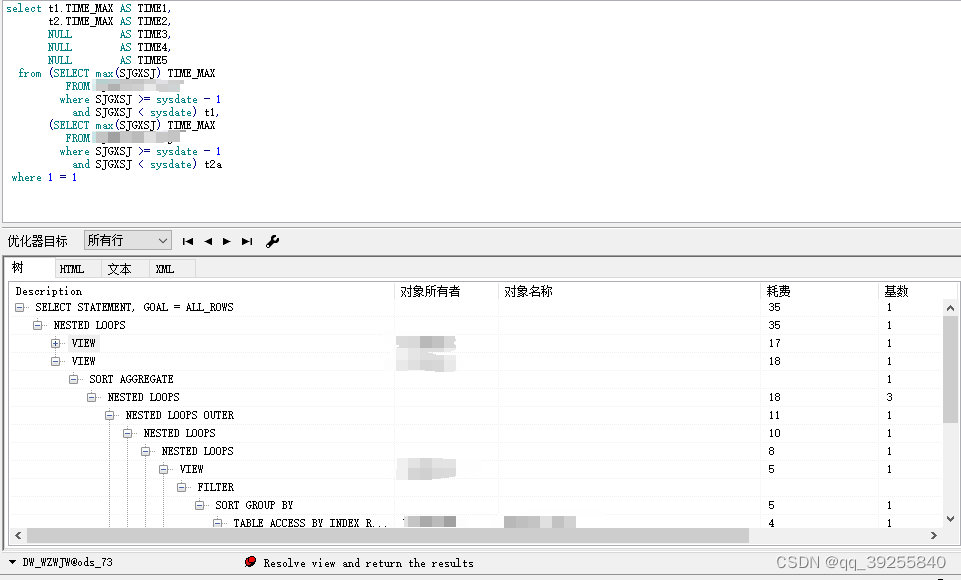
oracle执行计划中,同一条语句块,在不同情况下执行计划不一样问题。子查询,union 导致索引失效。
场景: 需要获取部分数据集(视图)的业务时间最大值,希望只通过一条语句获取多个的最大值。 则使用select (视图1业务时间最大值),(视图2业务时间最大值),(视图3业务时间最大值) from dual 程序执行过程中,发现语句执行较慢,则进行s…...

【新的小主机】向日葵远程控制ubuntu
向日葵远程控制ubuntu 一、简介二、问题及解决方法2.1 向日葵远程连接Ubuntu22主机黑屏?2.2 Ubuntu如何向日葵开机自启?2.3 无显示器情况下,windows远程桌面连接Ubuntu? 三、待续。。。 一、简介 系统:ubuntu22.04.3 目的&#…...

在Android studio高版本上使用低版本的Github项目库报错未能解析:Landroid/support/v4/app/FrageActivity;
我在我的项目中有一个导包: // 基础依赖包,必须要依赖 沉浸式狀態欄 implementation com.gyf.immersionbar:immersionbar:3.0.0 但是我的as版本比较高,我使用这个导包里面的方法会直接报错: java.lang.NoClassDefFoundError: Failed resolution of: Landroid/suppor…...
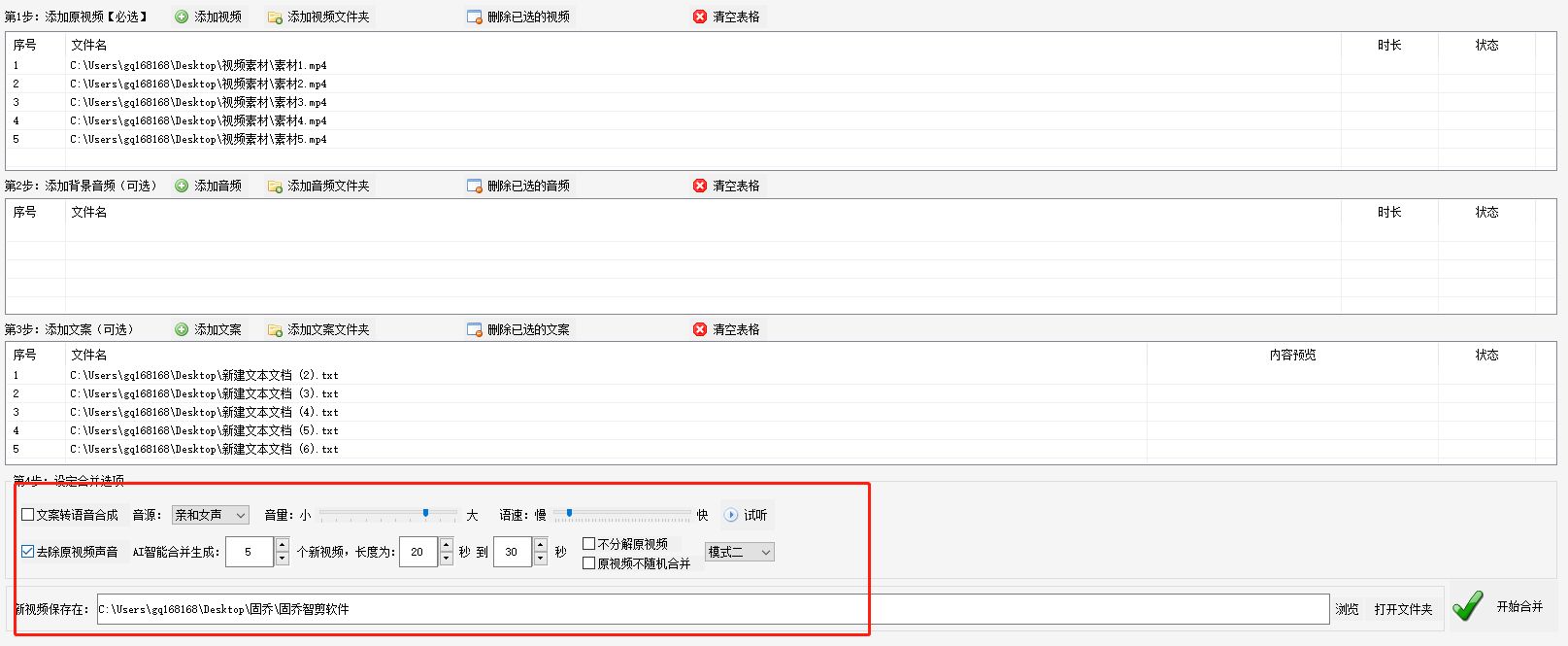
自动混剪多段视频、合并音频、添加文案的技巧分享
在如今的社交媒体时代,视频的重要性越来越被人们所重视。许多人喜欢记录生活中的美好瞬间,并将其制作成视频分享给朋友和家人。然而,对于那些拍摄了大量视频的人来说,一个一个地进行剪辑和合并可能是一项令人头痛的任务。但是&…...

学习笔记——BSGS
众所周知,北上广深是中国非常一线的城市,北京是首都,地处…… 正片开始! 一、BSGS基础算法 实现目标: A x ≡ B ( m o d P ) , ( gcd ( P , A ) 1 ) A^x\equiv B(\mod P),(\gcd(P,A)1) Ax≡B(modP),(gcd(P,A)1)…...

【AI视野·今日NLP 自然语言处理论文速览 第四十期】Mon, 25 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 25 Sep 2023 Totally 46 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs Authors Justin C…...
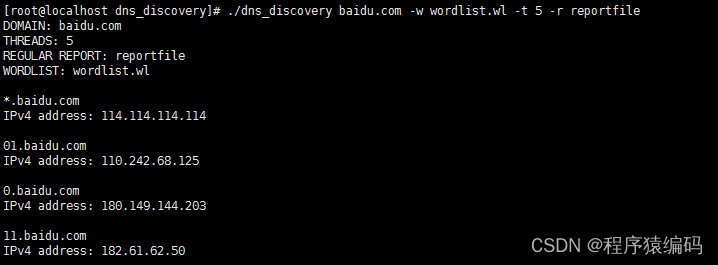
Linux C/C++下收集指定域名的子域名信息(类似dnsmap实现)
我们知道dnsmap是一个工具,主要用于收集指定域名的子域名信息。它对于渗透测试人员在基础结构安全评估的信息收集和枚举阶段非常有用,可以帮助他们发现目标公司的IP网络地址段、域名等信息。 dnsmap的操作原理 dnsmap(DNS Mappingÿ…...
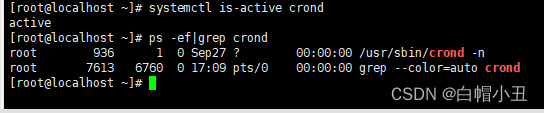
linux-定时任务
目录 一、crond命令 1、什么是计划任务 2、crond服务的概念 3、crontab 二、at命令 1、at任务的概念 三、邮件服务 1、概念 2、启动postfix 四、mailx命令 1、三个概念: 2、交互式发邮件 3、非交互式发邮件 四、cron定时任务实践 1、系统定时任务配置…...

在Spring Boot项目中使用Redisson
在Spring Boot项目中使用Redisson Redisson简介 Redisson官网仓库 Redisson中文文档 Redission是一个基于Java的分布式缓存和分布式任务调度框架,用于处理分布式系统中的缓存和任务队列。它是一个开源项目,旨在简化分布式系统的开发和管理。 以下是…...

AK7739 TDM调试避坑指南:从tinymix命令到SA6125平台时钟极性BUG排查
AK7739 TDM音频接口深度调试:从寄存器配置到时钟极性异常实战解析 当我们在嵌入式音频系统中集成AK7739编解码器时,TDM(时分复用)接口的调试往往是工程师面临的最大挑战之一。不同于标准的I2S协议,TDM接口的高度可配置…...

点云配准避坑指南:当ICP把深度图配到‘中心’时,我的自适应阈值调整方案
点云配准避坑指南:动态阈值优化解决ICP中心化失效问题 在三维重建和SLAM项目中,工程师们常常会遇到一个令人头疼的现象:使用标准ICP算法对深度图点云进行配准时,点云会神秘地"滑向"彼此的中心位置。这种看似魔法的行为背…...
)
NotebookLM私有知识库安全加固指南(GDPR/等保2.0双合规配置手册,仅限内部技术团队流通)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM私有知识库安全加固概览 NotebookLM 是 Google 推出的基于用户上传文档进行语义理解与问答的 AI 工具,其本地化部署或私有知识库场景下,数据驻留、访问控制与内容脱敏…...

C++核心语法:explicit与友元全解析
一、上期回顾搞定菱形继承、虚继承,解决多继承二义性与数据冗余,继承板块彻底学完。今天集中补齐 C 剩余高频语法细节:explicit 关键字、友元函数 / 友元类、命名空间深度、成员初始化细节,收尾 C 基础语法全部重难点。二、explic…...

OpenCorpo开源企业情报工具:从数据抓取到关系图谱构建实战
1. 项目概述:当开源情报遇上企业数据最近在开源情报(OSINT)的圈子里,一个名为 OpenCorpo 的项目引起了我的注意。它不是一个传统意义上的商业数据库,而是一个由社区驱动的、旨在聚合和解析全球企业公开信息的工具集。简…...

系统化交易资源宝库:从入门到实战的量化学习路径
1. 项目概述与核心价值如果你对量化交易、系统化投资感兴趣,并且正在寻找一个能帮你快速入门、避免重复造轮子的资源宝库,那么paperswithbacktest/awesome-systematic-trading这个项目绝对值得你花上几个小时好好研究。这个项目本质上是一个由社区驱动的…...

怀旧服WLK:10人NAXX教官拉苏维奥斯保姆级攻略,暗牧控制与学员轮换时间轴详解
怀旧服WLK:10人NAXX教官拉苏维奥斯保姆级攻略,暗牧控制与学员轮换时间轴详解 在《魔兽世界》怀旧服巫妖王之怒版本中,纳克萨玛斯军事区的教官拉苏维奥斯堪称团队配合的"试金石"。这个看似机制简单的BOSS,却因学员控制与…...

JavaScript 遍历 JSON 所有 Key 的方法
1️⃣ for…in 循环(最常用) const json {name: "张三",age: 25,city: "北京" };for (let key in json) {console.log(key); // name, age, cityconsole.log(json[key]); // 张三, 25, 北京 }2️⃣ Object.keys()&am…...

清华PPT模板:5分钟打造专业学术演示的终极方案
清华PPT模板:5分钟打造专业学术演示的终极方案 【免费下载链接】THU-PPT-Theme 清华主题PPT模板 项目地址: https://gitcode.com/gh_mirrors/th/THU-PPT-Theme 还在为每一次学术汇报、论文答辩或教学课件而烦恼吗?THU-PPT-Theme清华PPT模板库为你…...

作为一个网聊经常冷场的人,我试了试几款聊天回复神器
平时在线下跟人沟通还好,但一到微信或者Soul这种线上聊天环境,我就特别容易卡壳。尤其是遇到对方发来一些带有情绪的话,我经常不知道怎么接,打了一堆字又默默删掉,最后回个“哈哈”或者“早点休息”,硬生生…...