【Spark分布式内存计算框架——Spark Core】4. RDD函数(中)Transformation函数、Action函数
3.2 Transformation函数
在Spark中Transformation操作表示将一个RDD通过一系列操作变为另一个RDD的过程,这个操作可能是简单的加减操作,也可能是某个函数或某一系列函数。值得注意的是Transformation操作并不会触发真正的计算,只会建立RDD间的关系图。
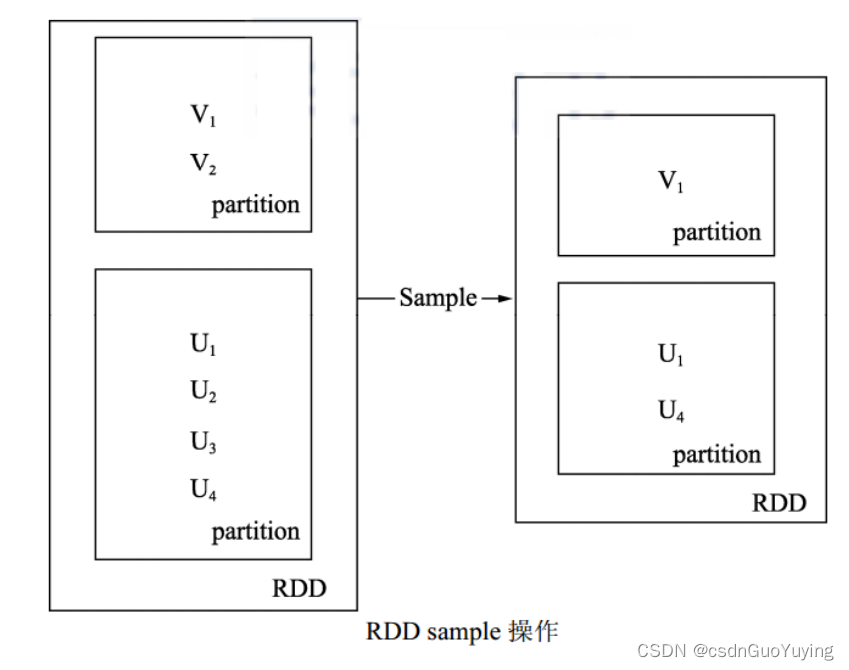
如下图所示,RDD内部每个方框是一个分区。假设需要采样50%的数据,通过sample函数,从 V1、V2、U1、U2、U3、U4 采样出数据 V1、U1 和 U4,形成新的RDD。
常用Transformation转换函数,加上底色为重要函数,重点讲解常使用函数:

3.3 Action函数
不同于Transformation操作,Action操作代表一次计算的结束,不再产生新的 RDD,将结果返回到Driver程序或者输出到外部。所以Transformation操作只是建立计算关系,而Action 操作才是实际的执行者。每个Action操作都会调用SparkContext的runJob 方法向集群正式提交请求,所以每个Action操作对应一个Job。
常用Action执行函数,加上底色为重要函数,后续重点讲解。

3.4 重要函数
RDD中包含很多函数,主要可以分为两类:Transformation转换函数和Action函数。
主要常见使用函数如下,一一通过演示范例讲解
基本函数
RDD中map、filter、flatMap及foreach等函数为最基本函数,都是都RDD中每个元素进行操作,将元素传递到函数中进行转换。
- map 函数:
map(f:T=>U) : RDD[T]=>RDD[U],表示将 RDD 经由某一函数 f 后,转变为另一个RDD。 - flatMap 函数:
flatMap(f:T=>Seq[U]) : RDD[T]=>RDD[U]),表示将 RDD 经由某一函数 f 后,转变为一个新的 RDD,但是与 map 不同,RDD 中的每一个元素会被映射成新的 0 到多个元素(f 函数返回的是一个序列 Seq)。 - filter 函数:
filter(f:T=>Bool) : RDD[T]=>RDD[T],表示将 RDD 经由某一函数 f 后,只保留 f 返回为 true 的数据,组成新的 RDD。 - foreach 函数:
foreach(func),将函数 func 应用在数据集的每一个元素上,通常用于更新一个累加器,或者和外部存储系统进行交互,例如 Redis。关于 foreach,在后续章节中还会使用,到时会详细介绍它的使用方法及注意事项。 - saveAsTextFile 函数:
saveAsTextFile(path:String),数据集内部的元素会调用其 toString 方法,转换为字符串形式,然后根据传入的路径保存成文本文件,既可以是本地文件系统,也可以是HDFS 等。
上述函数基本上都使用过,在后续的案例中继续使用,此处不再单独演示案例。
分区操作函数
每个RDD由多分区组成的,实际开发建议对每个分区数据的进行操作,map函数使用mapPartitions代替、foreache函数使用foreachPartition代替。

针对词频统计WordCount代码进行修改,针对分区数据操作,范例代码如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext, TaskContext}
/**
* 分区操作函数:mapPartitions和foreachPartition
*/
object SparkIterTest {def main(args: Array[String]): Unit = {// 创建应用程序入口SparkContext实例对象val sc: SparkContext = {// 1.a 创建SparkConf对象,设置应用的配置信息val sparkConf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName.stripSuffix("$")).setMaster("local[2]")// 1.b 传递SparkConf对象,构建Context实例new SparkContext(sparkConf)}sc.setLogLevel("WARN")// TODO: 1、从文件系统加载数据,创建RDD数据集val inputRDD: RDD[String] = sc.textFile("datas/wordcount/wordcount.data", minPartitions = 2)// TODO: 2、处理数据,调用RDD集合中函数(类比于Scala集合类中列表List)/*def mapPartitions[U: ClassTag](f: Iterator[T] => Iterator[U],preservesPartitioning: Boolean = false): RDD[U]*/val wordcountsRDD: RDD[(String, Int)] = inputRDD// 将每行数据按照分隔符进行分割,将数据扁平化.flatMap(line => line.trim.split("\\s+"))// TODO: 针对每个分区数据操作.mapPartitions{ iter =>// iter 表示RDD中每个分区中的数据,存储在迭代器中,相当于列表Listiter.map(word => (word, 1))}// 按照Key聚合统计, 先按照Key分组,再聚合统计(此函数局部聚合,再进行全局聚合).reduceByKey((a, b) => a + b )// TODO: 3、输出结果RDD到本地文件系统wordcountsRDD.foreachPartition{ datas =>// 获取各个分区IDval partitionId: Int = TaskContext.getPartitionId()// val xx: Iterator[(String, Int)] = datasdatas.foreach{ case (word, count) =>println(s"p-${partitionId}: word = $word, count = $count")}}// 应用程序运行结束,关闭资源sc.stop()}
}
为什么要对分区操作,而不是对每个数据操作,好处在哪里呢???
- 应用场景:处理网站日志数据,数据量为10GB,统计各个省份PV和UV。
- 假设10GB日志数据,从HDFS上读取的,此时RDD的分区数目:80 分区;
- 但是分析PV和UV有多少条数据:34,存储在80个分区中,实际项目中降低分区数目,比如设置为2个分区。

相关文章:
【Spark分布式内存计算框架——Spark Core】4. RDD函数(中)Transformation函数、Action函数
3.2 Transformation函数 在Spark中Transformation操作表示将一个RDD通过一系列操作变为另一个RDD的过程,这个操作可能是简单的加减操作,也可能是某个函数或某一系列函数。值得注意的是Transformation操作并不会触发真正的计算,只会建立RDD间…...
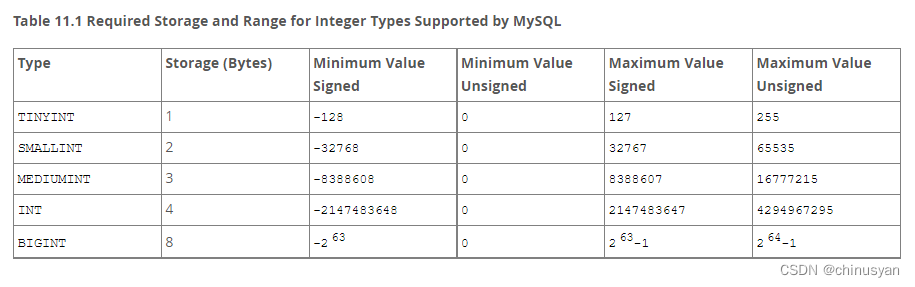
Mysql 数据类型
1、数值数据类型 1.1 整数类型(精确值) INTEGER, INT, SMALLINT, TINYINT, MEDIUMINT, BIGINT MySQL支持SQL标准的整数类型INTEGER (或INT)和SMALLINT。作为标准的扩展,MySQL还支持整数类型TINYINT、MEDIUMINT和BIGINT。下表显示了每种整数类型所需的存储和范围。…...

运行Whisper笔记(1)
最近chatGPT很火,就去逛了一下openai的github项目。发现了这个项目。 这个项目可以识别视频中的音频,转换出字幕。 带着一颗好奇的心就尝试自己去部署玩一玩 跟着这篇文章一步步来进行安装,并且跟着这篇文章解决途中遇到的问题。 途中还会遇…...
2023年最强大的12款数据可视化工具,值得收藏
做数据分析也有年头了,好的坏的工具都用过,推荐几个觉得很好用的,避坑必看! PS:一般比较成熟的公司里,数据分析工具不只是满足业务分析和报表制作,像我现在给我们公司选型BI工具,是做…...

LeetCode刷题系列 -- 523. 连续的子数组和
给你一个整数数组 nums 和一个整数 k ,编写一个函数来判断该数组是否含有同时满足下述条件的连续子数组:子数组大小 至少为 2 ,且子数组元素总和为 k 的倍数。如果存在,返回 true ;否则,返回 false 。如果存…...

LeetCode刷题系列 -- 525. 连续数组
给定一个二进制数组 nums , 找到含有相同数量的 0 和 1 的最长连续子数组,并返回该子数组的长度。示例 1:输入: nums [0,1]输出: 2说明: [0, 1] 是具有相同数量 0 和 1 的最长连续子数组。示例 2:输入: nums [0,1,0]输出: 2说明: [0, 1] (或 [1, 0]) 是具有相同数…...
JavaEE15-Spring Boot统一功能处理
目录 1.统一用户登录权限效验 1.1.最初用户登录验证 1.2.Spring AOP用户统一登录验证的问题 1.3.Spring拦截器 1.3.1.创建自定义拦截器,实现 HandlerInterceptor 接口并重写 preHandle(执行具体方法之前的预处理)方法 1.3.2.将自定义拦…...
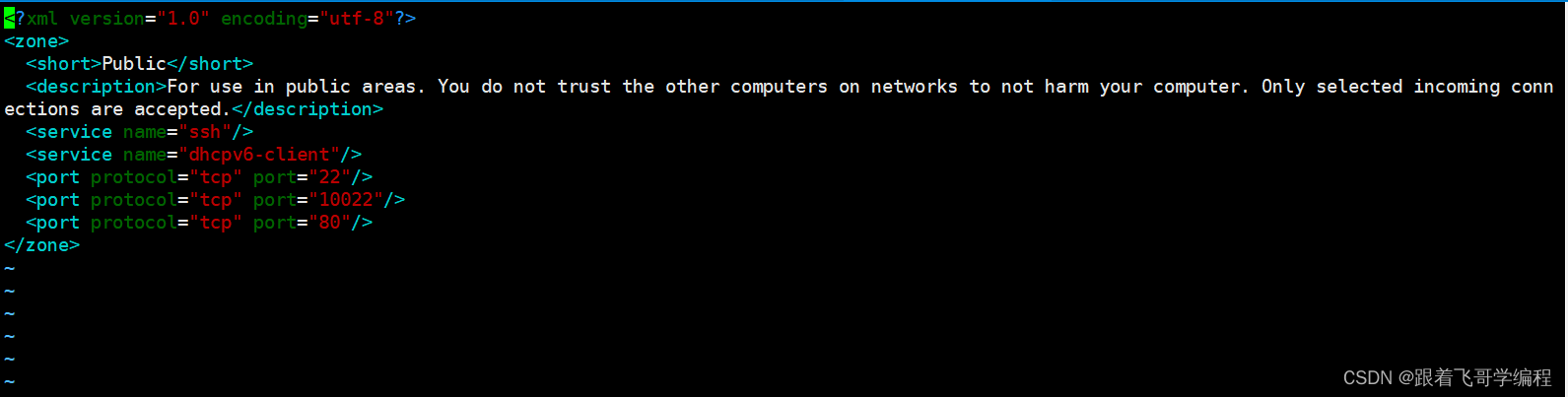
centos7.6 设置防火墙
1、查看系统版本 cat /etc/redhat-release2、查看防火墙运行状态 systemctl status firewalld这里可以看到当前是未运行状态(inactive)。 3、关闭开机自启动防火墙 systemctl disable firewalld.service4、启动防火墙并查看状态,系统默认 22 端口是开启的。 sy…...
在线支付系列【22】微信支付实战篇之集成服务商API
有道无术,术尚可求,有术无道,止于术。 文章目录前言1. 环境搭建2. 特约商户进件3. 统一下单总结前言 在上篇文档中,我们做好了接入前准备工作,接下来使用开源框架集成服务商相关API。 一个简单的支付系统完成支付流程…...

3.2 埃尔米特转置
定义 对于复矩阵,转置又不一样,常见的操作是共轭转置,也叫埃尔米特转置Hermitian transpose。埃尔米特转置就是对矩阵先共轭,再转置,一般来说用三种符号表示埃尔米特转置: 第一种符号是AHA^HAH,…...
Python爬虫之Scrapy框架系列(13)——实战ZH小说爬取数据入MySql数据库
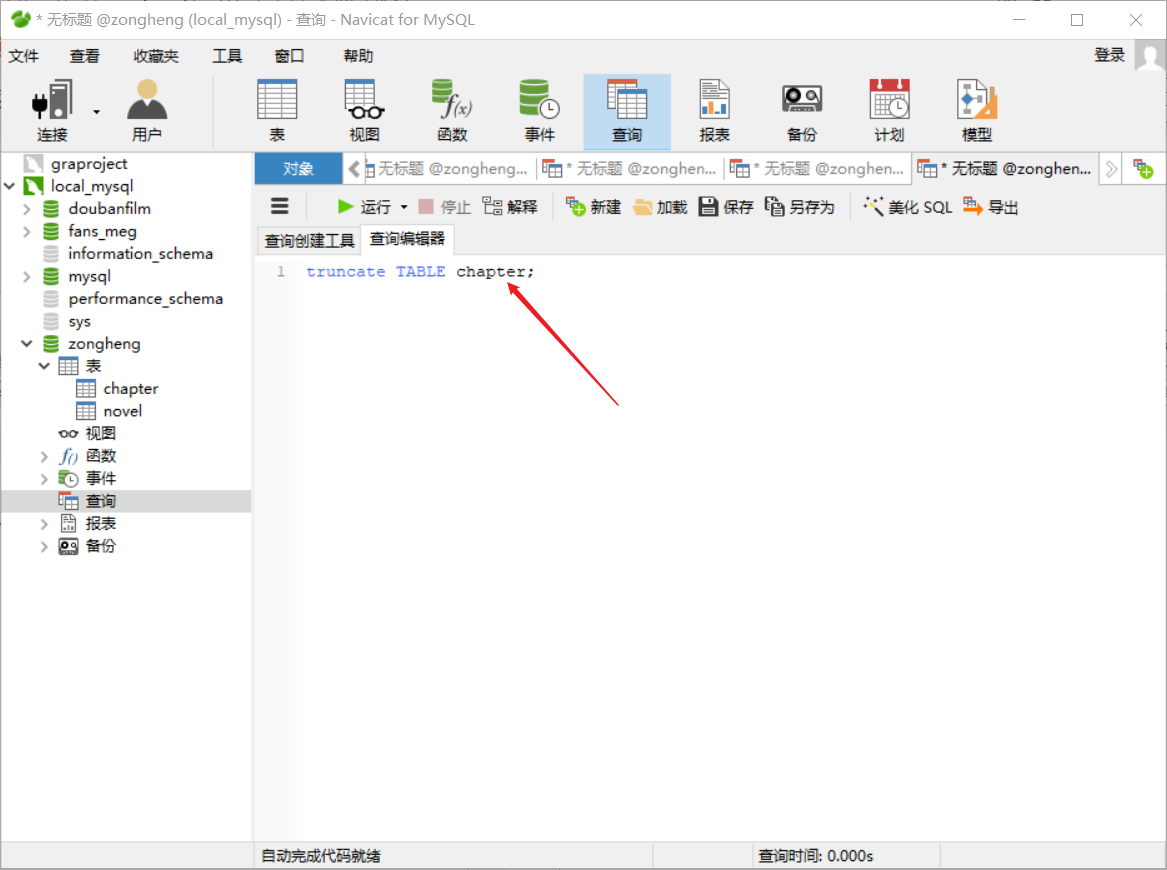
目录:1 数据持久化存储,写入Mysql数据库①定义结构化字段:②重新编写爬虫文件:③编写管道文件:④辅助配置(修改settings.py文件):⑤navicat创库建表:⑥ 效果如下…...
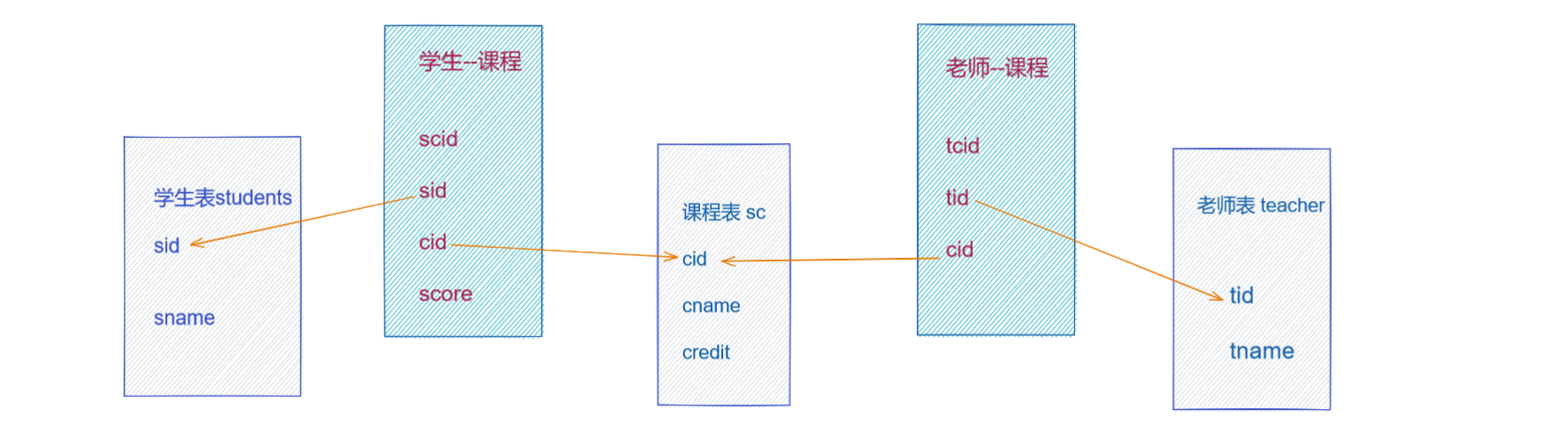
MySQL篇02-三大范式,多表查询
数据入库时,由于数据设计不合理,会存在数据重复、更新插入异常等情况, 故数据库中表的设计遵循的设计规范:三大范式1.第一范式(1NF)要求数据库的每一列都是不可分割的原子数据项,即原子性。强调的是列的原子性,即数据库中每一列的…...

vue-cli3创建Vue项目
文章目录前言一、使用vue-cli3创建项目1.检查当前vue的版本2.下载并安装Vue-cli33.使用命令行创建项目二、关于配置前言 本文讲解了如何使用vue-cli3创建属于自己的Vue项目,如果本文对你有所帮助请三连支持博主,你的支持是我更新的动力。 下面案例可供…...
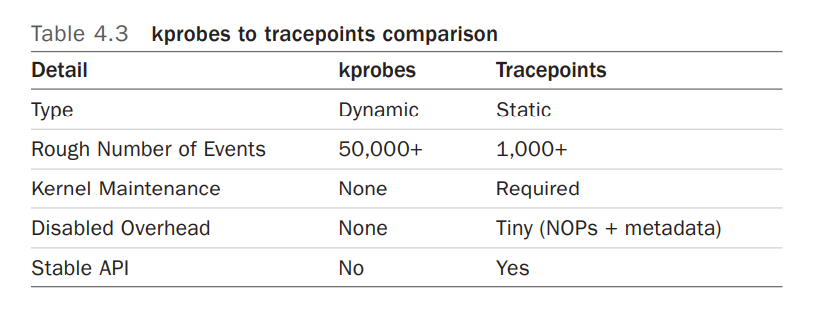
Linux perf probe 的使用(三)
文章目录前言一、Dynamic Tracing二、kprobes2.1 perf kprobe 的使用2.2 kprobe Arguments3.3 tcp_sendmsg()3.3.1 Kernel: tcp_sendmsg()3.3.2 Kernel: tcp_sendmsg() with size3.3.2 Kernel: tcp_sendmsg() line number and local variable三、uprobes的使用3.1 perf uprobe …...

python GUI编程 多窗口跳转
# 多窗口跳转例子from tkinter import *def main(): # 主窗体def goto(num):root.destroy() # 关闭主窗体if num 1:one() # 进入第1个窗体elif num 2:two() # 进入第2个窗体root Tk()root.geometry(300x150600200)root.title(登录窗口)but1 Button(root, text"进入…...
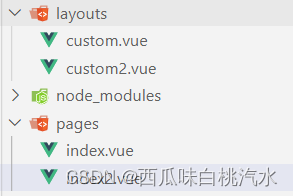
nuxt 学习笔记
这里写目录标题路由跳转NuxtLinkquery参数params参数嵌套路由tab切换效果layouts 文件夹强制约定放置所有布局文件,并以插槽的形式作用在页面中1.在app.vue里面2.component 组件使用Vue < component :is"">Vuex生命周期数据请求useFetchuseAsyncDat…...
Python编程自动化办公案例(1)
作者简介:一名在校计算机学生、每天分享Python的学习经验、和学习笔记。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.使用库讲解 1.xlrd 2.xlwt 二.主要案例 1.批量合并 模板如下…...
一站式 Elasticsearch 集群指标监控与运维管控平台
上篇文章写了一下消息运维管理平台,今天带来的是ES的监控和运维平台。目前初创企业,不像大型互联网公司,可以重复的造轮子。前期还是快速迭代试错阶段,方便拿到市场反馈,及时调整自己的战略和产品方向。让自己活下去&a…...

C# 调用Python
一、简介 IronPython 是一种在 NET 和 Mono 上实现的 Python 语言,由 Jim Hugunin(同时也是 Jython 创造者)所创造。 Python是一种跨平台的计算机程序设计语言。 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。 Python是…...
)
51单片机最强模块化封装(3)
文章目录 前言一、创建smg文件,添加smg文件路径二、smg文件编写三、模块化测试总结前言 本篇文章将带大家继续封装我们的代码。 这里我们会封装数码管的操作函数。 一、创建smg文件,添加smg文件路径 这里的操作就不过多解释了,大家自行看前面的文章即可。 51单片机模块化…...

00101
1001101...
如何使用olcPixelGameEngine创建炫酷视觉效果:完整着色器应用指南
如何使用olcPixelGameEngine创建炫酷视觉效果:完整着色器应用指南 【免费下载链接】olcPixelGameEngine The official distribution of olcPixelGameEngine, a tool used in javidx9s YouTube videos and projects 项目地址: https://gitcode.com/gh_mirrors/ol/o…...
)
【反蒸馏实战 14】BI工程师:从报表开发者到数据架构师@BI工程师反蒸馏进化论(附 Python/SQL 完整代码)
摘要:2026年Agentic BI全面爆发,业务人员借助AI问数工具3分钟即可完成传统BI工程师半天的工作,报表开发、SQL取数等基础岗位需求同比下降26%,但具备数据架构设计、数据治理能力的BI工程师薪资高达18.2K/月(较纯报表工程师溢价30%)。本文基于真实企业场景,通过3个完整实战…...
)
geography (Google Earth)
google 三维立体地图 geography (Google Earth) 地理学习...
)
别再混淆了!一文搞懂OpenHarmony NAPI中的同步、回调与Promise接口(附代码对比)
OpenHarmony NAPI接口设计实战:同步、回调与Promise的黄金选择法则 当你在OpenHarmony生态中封装一个底层功能时,总会面临这个灵魂拷问:该用同步接口、回调函数还是Promise?这个看似简单的选择背后,藏着性能、可维护性…...

二、linux目录编辑
二、linux目录编辑1.指令1.1echo基本语法echo 【选项】 【字符串/变量】重定向:把默认输出的方向进行修改>>:重定向追加 >:重定向覆盖例子:以追加的方式将“abc”写入index.html文件中echo "abc" >> index.html进阶案例&#x…...

基于KITTI数据集:从LIO-SAM部署到EVO精度评估全流程解析
1. KITTI数据集准备与格式转换 KITTI数据集作为自动驾驶领域最经典的公开数据集之一,包含了丰富的传感器数据和多场景的道路环境信息。对于SLAM研究者来说,2011_09_30_drive_0016等序列常被用作算法测试基准。但原始数据需要经过格式转换才能在ROS环境中…...

MCP 工具数量爆炸后,如何高效做 Tool Selection?
MCP 工具数量爆炸后,如何高效做 Tool Selection? 背景:规模扩展带来的路由难题 在 MCP(Model Context Protocol)架构中,随着接入工具数量的增长,一个问题会越来越突出:LLM 开始选错工…...

从all shards failed到精准定位:一次Elasticsearch mapping字段配置的排错实战
1. 当Elasticsearch突然罢工:从"all shards failed"开始的故事 那天早上,我正悠闲地喝着咖啡,突然收到报警短信——生产环境的搜索服务挂了。登录Kibana一看,满屏都是"search_phase_execution_exception: all shar…...

国民技术 N32G452CBL7 LQFP-48 单片机
关键特性 内核CPU 一32位ARMCortex-M4内核FPU,单周期硬件乘除法指令,支持DSP指令和MPU 内置8KB指令缓存,支持Flash加速单元执行程序0等待最高主频144MHz,180DMIPS 加密存储器 硬件ECC校验,10万次擦写次数,10年数据保持…...