Java初始化大量数据到Neo4j中(二)
接Java初始化大量数据到Neo4j中(一)继续探索,之前用create命令导入大量数据发现太过耗时,查阅资料说大量数据初始化到Neo4j需要使用neo4j-admin import
业务数据说明可以参加Java初始化大量数据到Neo4j中(一),这里主要是将处理好的节点数据和关系数据分别导出为csv
在这里插入代码片
入口controller.java
//导出节点数据到csv文件中
@GetMapping("exportNodeData")
public void exportNodeData(HttpServletResponse response) {service.exportNodeData(response);
}//导出关系数据到csv文件中
@GetMapping("exportRelationData")
public void exportRelationData(HttpServletResponse response) {service.exportRelationData(response);
}
service.java
//导出节点数据@Overridepublic void exportNodeData(HttpServletResponse response) {//节点数据,按照自己的实际业务添加,我这里对应的是所有表的数据,因为我业务中所有表结果基本一样,也即节点属性都一样。每个表的数据一个map,key是表名作为节点的标签Map<String, List<NodeData>> nodeDataMap;List<Map<String,String>> data = new ArrayList<>();for(String key:nodeDataMap.keySet()){List<NodeData> dataList = nodeDataMap.get(key);if (StringUtils.isEmpty(key) || dataList ==null || dataList .isEmpty()) {continue;}for (NodeData nodeData:dataList ) {Map<String,String> map = new HashMap<>();String id = nodeData.getId();String name = nodeData.getName();String table = nodeData.getName();//因为不同表的id会重复,需要一个不重复的值作为节点唯一值(我这里用的是表id拼接表数据id)String uniqueValue = nodeData.getUniqueValue(); map.put(":LABEL",table );map.put("id",id);map.put("name",name);map.put("uniqueValue:ID",uniqueValue);data.add(map);}}try {response.setCharacterEncoding("UTF-8");response.setHeader("Content-Disposition", "attachment;filename=" + new String("nodeimport.csv".getBytes(StandardCharsets.UTF_8), "ISO8859-1"));response.setContentType(ContentType.APPLICATION_OCTET_STREAM.toString());CsvWriter csvWriter = CsvUtil.getWriter(response.getWriter()) ;csvWriter.writeBeans(data);csvWriter.close();} catch (IOException e) {e.printStackTrace();}
}//导出关系数据@Overridepublic void exportRelationData(HttpServletResponse response) {//关系数据,将每一个表数据的关系作为RelationData实体List<RelationData> relationDatas;List<Map<String,String>> data = new ArrayList<>();for (RelationData relation : relationDatas) {Map<String,String> map = new HashMap<>();String relationName = relation .getRelationName();String id = relation .getId();//因为节点是通过表id拼接数据id,所以关系这里也需要加上拼接后不重复的值//开始节点唯一的值String uniqueStartValue = relation .getUniqueStartValue();//结束节点唯一的值String uniqueEndValue = relation .getUniqueEndValue();map.put("relationName",relationName) ;map.put("id",id) ;map.put(":START_ID",uniqueStartValue) ;map.put(":END_ID",uniqueEndValue) ;map.put(":TYPE",relationName) ;data.add(map);}try {response.setCharacterEncoding("UTF-8");response.setHeader("Content-Disposition", "attachment;filename=" + new String("relationimport.csv".getBytes(StandardCharsets.UTF_8), "ISO8859-1"));response.setContentType(ContentType.APPLICATION_OCTET_STREAM.toString());CsvWriter csvWriter = CsvUtil.getWriter(response.getWriter()) ;csvWriter.writeBeans(data);csvWriter.close();} catch (IOException e) {e.printStackTrace();}}
CsvUtil用的是Hutool中的工具类,引入下面依赖即可
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.21</version></dependency>
解释:
节点中的,
uniqueValue:ID 冒号前面可以随便写,冒号后端必须是ID,标识全局id,不可重复
:LABEL:这个是标签名,必须这样写
除了这两个以外的字段都是作为节点的属性。
导出的nodeimport.csv文件如下

关系中:
:START_ID:开始节点的唯一值
:END_ID:结束节点的唯一值
:TYPE:关系类型
除这三个外的字段都作为关系
导出的relationimport.csv文件如下:

之后找到Neo4j安装目录,找到import目录,将这个两个导出的文件放到import目录下
删除data\databases目录下的文件(neo4j-admin import要求是空文件 ) ,停掉Neo4j
cmd进入到bin目录,执行下面语句
neo4j-admin import --mode=csv --nodes "E:\work_soft\neo4j-community-3.5.5-windows\neo4j-community-3.5.5\import\nodeimport.csv" --relationships "E:\work_soft\neo4j-community-3.5.5-windows\neo4j-community-3.5.5\import\relationimport.csv" --ignore-extra-columns=true --ignore-missing-nodes=true --ignore-duplicate-nodes=true
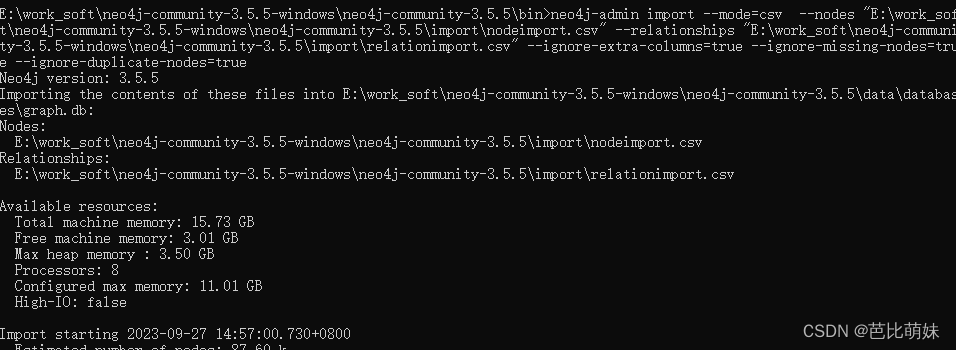
成功之后启动Neo4j,查看数据即可。
相关文章:
Java初始化大量数据到Neo4j中(二)
接Java初始化大量数据到Neo4j中(一)继续探索,之前用create命令导入大量数据发现太过耗时,查阅资料说大量数据初始化到Neo4j需要使用neo4j-admin import 业务数据说明可以参加Java初始化大量数据到Neo4j中(一),这里主要是将处理好的节点数据和…...

flink1.17安装
Flink1.17安装 官网地址: https://nightlies.apache.org/flink/flink-docs-release-1.17/zh//docs/try-flink/local_installation/ 安装jdk11 ps:只能安装openjdk11,昨天安装的oracle jdk17,结果怎么也运行不起来。 sudo apt …...

SLAM从入门到精通(gmapping建图)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 前面我们介绍了hector slam建图。相对而言,hector slam建图对数据的要求比较低,只需要lidar数据就可以建图了。但是hector …...
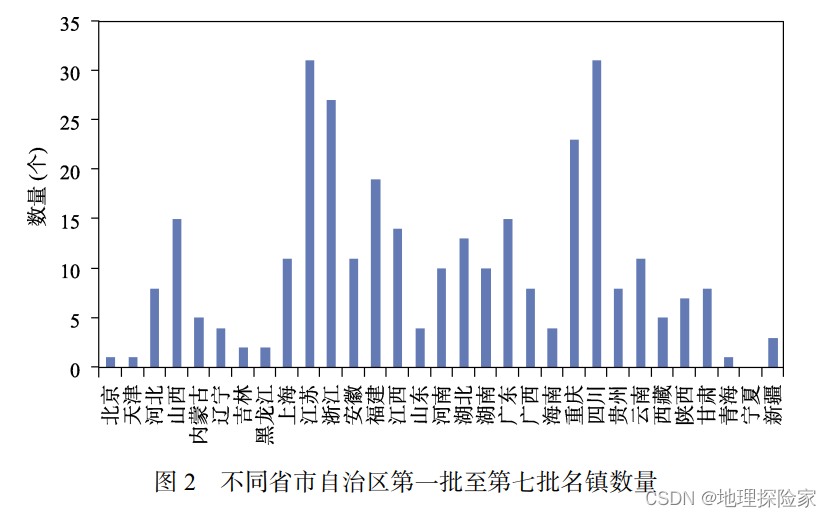
中国312个历史文化名镇及景区空间点位数据集
一部中华史,既是人类创造丰富物质财富的奋头史,又是与自然共生共存的和谐史不仅留存下悠久丰富的人文思想和情怀,还在各处镌刻下可流传的生活场景,历史文化名镇(以下简称:名镇)就是这样真实的历史画卷。“镇”是一方的政治文化中心…...

记一次Mybatis驼峰命名导致的线上BUG及处理方案
前言 方向从一开始就错了,还是执着的去寻找问题的解决方案,简直就是一场重大灾难,但这也是每个修行者的必由之路。这个线上问题,差点让我的心里防线崩溃,苦寻无门,最终得以解决也多亏了身边的各路大佬的群…...
在MyBatisPlus中添加分页插件
开发过程中,数据量大的时候,查询效率会有所下降,这时,我们往往会使用分页。 具体操作入下: 1、添加分页插件: package com.zhang.config;import com.baomidou.mybatisplus.extension.plugins.Pagination…...

算法题系列8·买卖股票的最佳时机
目录 题目描述 实现 提交结果 题目描述 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。 设计一个算法来计算你所能获取的最大利润。…...

DC电源模块关于宽电压输入和输出的范围
BOSHIDA DC电源模块关于宽电压输入和输出的范围 DC电源模块是一种电子设备,能够将输入的直流电源转换成所需的输出电源,用于供电各种电子设备。其中,关于宽电压输入和输出的范围,是DC电源模块常见的设计要求之一。本文将详细介绍…...

【Docker】docker拉取镜像错误 missing signature key
问题 当我使用docker拉取一个特定的镜像时,提示错误: 错误 missing signature key 但是拉取其他镜像又可以访问,,,,于是,我怀疑是否是docker版本问题。 docker --version结果确实࿰…...

C- 静态链接
静态链接意味着在编译时将所有库函数直接嵌入到最终的可执行文件中,而不是在运行时通过共享库来动态链接这些函数。静态链接的结果是一个更大的可执行文件,因为它包含了所有必要的代码,但它可以在没有外部依赖的情况下独立运行。 下面是一个…...
微信公众号开发(BUG集)
1.微信公众平台接口错误:不合法的自定义菜单使用用户 地址:解决地址 2.微信公众平台接口错误:invalid ip 180.101.72.196 ipv6 ::ffff:180.101.72.196, not in whitelist rid: 6511420b-60c59249-01084d02 白名单离开放服务器IP...
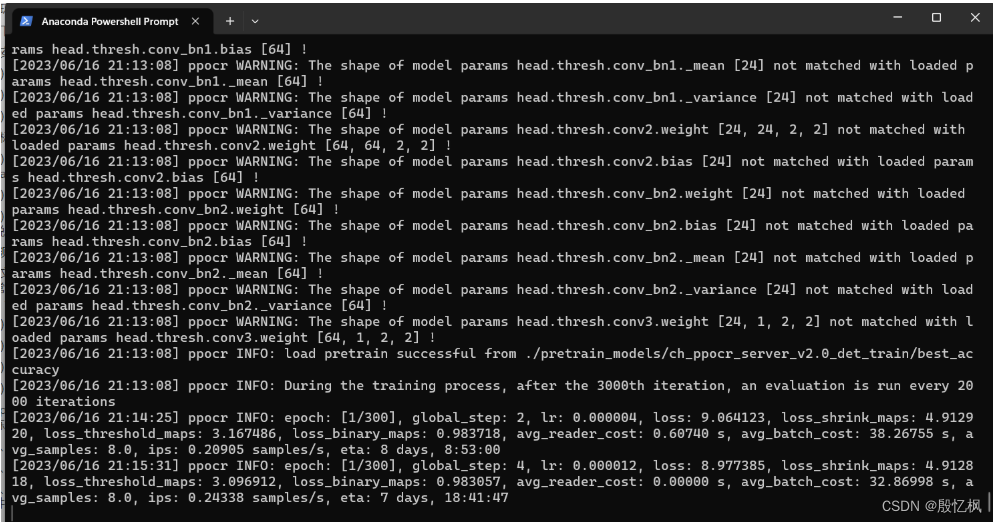
AI项目十三:PaddleOCR训练自定义数据集
若该文为原创文章,转载请注明原文出处。 续上一篇,PaddleOCR环境搭建好了,并测试通过,接下来训练自己的检测模型和识别模型。 paddleocr检测模型训练 1、准备数据集 在PaddleOCR目录下新建文件夹:train_data, 这个…...
你熟悉Docker吗?
你熟悉Docker吗? 文章目录 你熟悉Docker吗?快速入门Docker安装1.卸载旧版2.配置Docker的yum库3.安装Docker4.启动和校验5.配置镜像加速5.1.注册阿里云账号5.2.开通镜像服务5.3.配置镜像加速 部署MySQL镜像和容器命令解读 Docker基础常用命令数据卷数据卷…...

Nodejs错误处理详细指南
Nodejs错误处理详细指南 学习 Node.js 中的高级错误处理技术,以增强应用程序的可靠性和稳定性。 在 Node.js 中,我们可以使用各种技术和方法来处理错误,可以查看这篇文章。错误处理是任何 Node.js 应用程序的一个重要方面。正确管理错误可以…...

软考 系统架构设计师系列知识点之软件架构风格
这个十一注定是一个不能放松、保持“紧”的十一。由于报名了全国计算机技术与软件专业技术资格(水平)考试,11月4号就要考试,因此8天长假绝不能荒废,必须要好好利用起来。现在将各个核心知识点一一进行提炼并做记录。 所…...
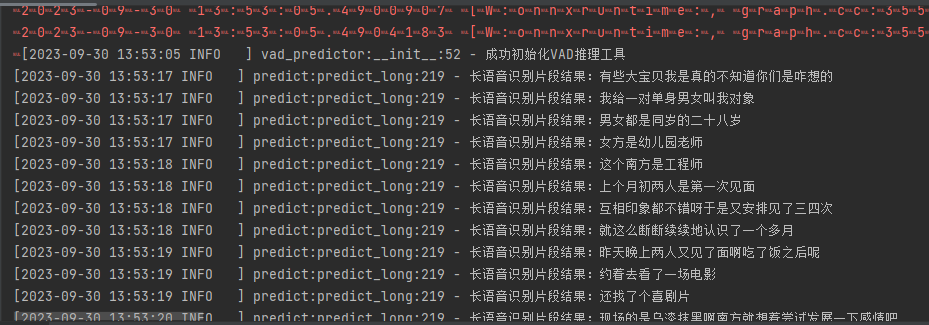
一键智能视频语音转文本——基于PaddlePaddle语音识别与Python轻松提取视频语音并生成文案
前言 如今进行入自媒体行业的人越来越多,短视频也逐渐成为了主流,但好多时候是想如何把视频里面的语音转成文字,比如,录制会议视频后,做会议纪要;比如,网课教程视频,想要做笔记&…...

[unity]对象的序列化
序 抽象的图纸叫类,包含具体数据的叫对象。 类的序列化和反序列化 using System.Collections; using System.Collections.Generic; using UnityEngine;using System; using System.IO; using System.Runtime.Serialization.Formatters.Binary; [Serializabl…...

java开发岗位面试
java开发岗位面试 技术栈:springboot框架+redis 个人笔试/技术面问题整理 1、SpringBoot有什么组件? 举例说几个: ①auto-configuration组件:核心特征。其约定大于配置思想,赋予了SpringBoot开箱即用的强…...

坠落防护 挂点装置
声明 本文是学习GB 30862-2014 坠落防护 挂点装置. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了高处坠落防护挂点装置的技术要求、检验方法、检验规则及标识。 本标准适用于防护高处坠落的挂点装置。 本标准不适用于体育及消…...
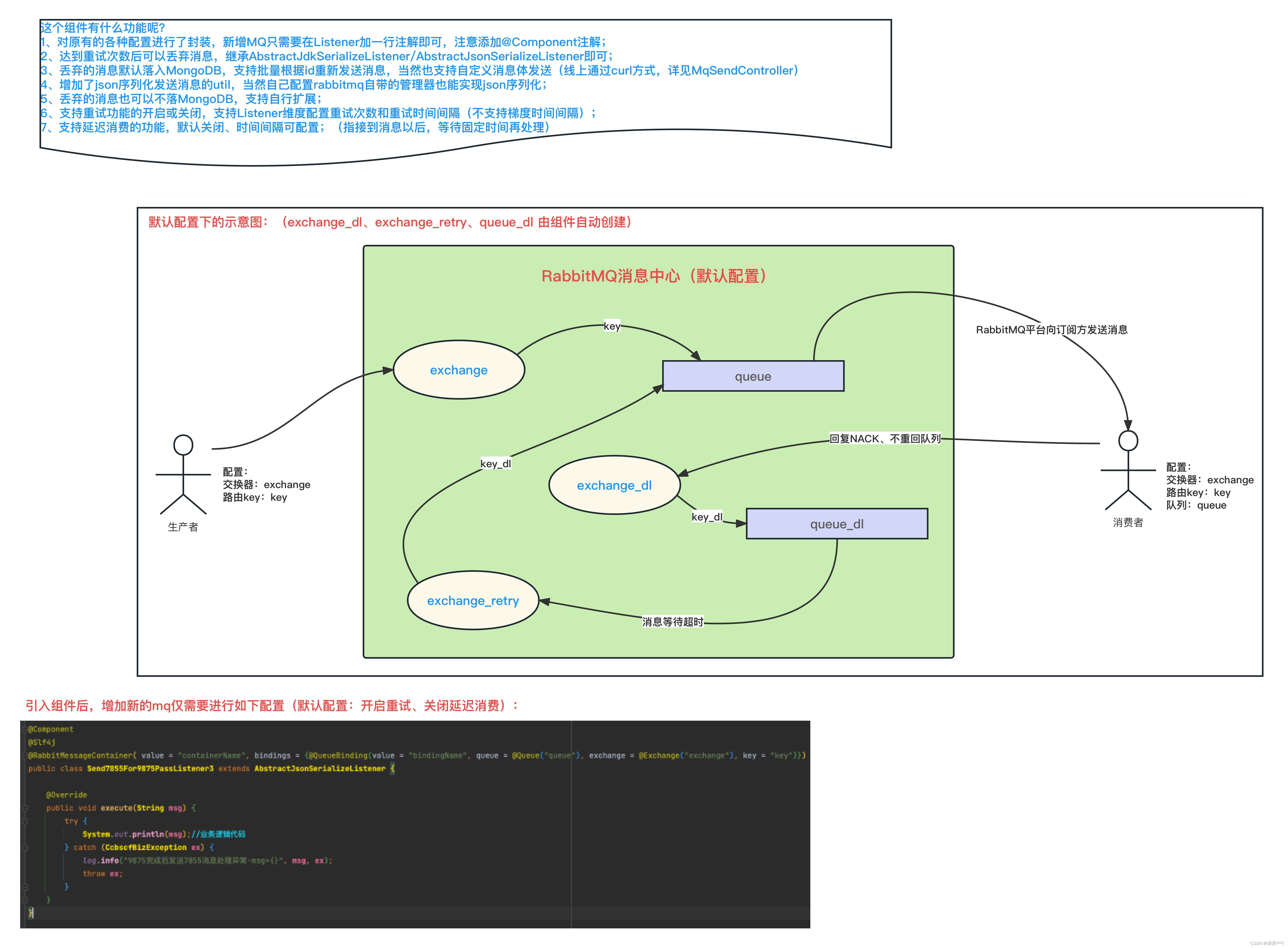
关于 自定义的RabbitMQ的RabbitMessageContainer注解-实现原理
概述 RabbitMessageContainer注解 的主要作用就是 替换掉Configuration配置类中的各种Bean配置; 采用注解的方式可以让我们 固化配置,降低代码编写复杂度、减少配置错误情况的发生,提升编码调试的效率、提高业务的可用性。 为什么说“降低…...
)
千问 LeetCode 2281.巫师的总力量和 public int totalStrength(int[] strength)
LeetCode 2281. 巫师的总力量和 是一道经典的 贡献法 + 单调栈 + 前缀和的前缀和 题目。题目要求对数组的所有非空连续子数组,计算: min(subarray) * sum(subarray) 的总和,并对 10^9 + 7 取模。 ✅ 解题思路(核心思想) 我们 不枚举所有子数组(那样是 O(n)),而是 枚…...

在Android Termux中搭建轻量级Docker容器环境:原理、部署与实战
1. 项目概述与核心价值最近在折腾移动设备上的开发环境,发现一个挺有意思的项目:George-Seven/Termux-Udocker。简单来说,它是在Android平台的Termux终端模拟器里,实现一个轻量级的Docker容器运行环境。这玩意儿解决了一个挺实际的…...

Cursor编辑器AI操作完成音效插件:原理、实现与效能提升
1. 项目概述:一个提升编码体验的“听觉反馈”工具如果你和我一样,每天有大量时间与代码编辑器为伴,那么你一定对那种“沉浸式”的编码状态又爱又恨。爱的是心流状态下的高效产出,恨的是一旦被打断,重新进入状态需要耗费…...
 的6个高阶用法,数据分析师必看)
别再只会用0填充了!Pandas DataFrame.fillna() 的6个高阶用法,数据分析师必看
别再只会用0填充了!Pandas DataFrame.fillna() 的6个高阶用法,数据分析师必看 在数据分析的日常工作中,缺失值处理就像是一道无法回避的数学题。许多刚入行的分析师会条件反射般地输入.fillna(0),这就像用创可贴处理所有伤口——有…...

Rust异步运行时rustclaw:高性能任务调度与并发编程实践
1. 项目概述与核心价值最近在折腾一个需要处理大量网络请求和并发任务的后台服务,性能瓶颈卡得我有点难受。传统的异步框架用起来总觉得不够“爽利”,要么是内存占用高,要么是并发模型复杂,调试起来像在走迷宫。就在我四处翻找有没…...

基于Helm与Kubernetes的以太坊节点自动化部署与运维实战
1. 项目概述:当以太坊遇见Kubernetes如果你和我一样,在区块链基础设施领域摸爬滚打多年,从早期手动编译客户端、配置systemd服务,到后来用Docker Compose编排节点,每一步都伴随着大量的重复劳动和运维痛点。当节点数量…...

Python 爬虫数据处理:特殊格式文档爬虫解析处理
前言 在 Python 爬虫规模化采集业务中,除常规 HTML 网页与 JSON 接口数据外,经常会遇到各类非网页型特殊格式文档资源,常见包含 PDF、Word、Excel、CSV、TXT、压缩包内嵌文档、Base64 加密文档、富文本混合格式文档等。这类文档无法通过常规…...

Python 爬虫高级实战:爬虫接口限流自适应调节
前言 网络目标站点普遍具备严格的接口访问限流、频率校验、IP 频次风控、接口令牌校验等防护机制,常规固定延时、固定并发的爬虫模式极易触发封禁、接口 429 限流、会话失效、IP 拉黑等问题。人工配置延时、手动调整并发阈值的传统方式,无法适配站点动态…...

一分钟看懂大模型备案
大模型备案,全称 “生成式人工智能服务上线备案”,是国内面向公众提供大模型服务的法定合规流程,核心是审核模型安全、数据合规与内容可控,未备案违规上线最高罚一千万元,该处罚依据主要来自两大核心法规:1…...
)
Codex入门09-Git工作流(小白入门:不会写commit信息?AI帮你自动生成规范提交)
🎯 本文目标 学会用 Codex 自动化 Git 操作:提交、冲突解决、PR 描述生成。 😰 Git 新手的典型痛点 你的提交记录是不是这样的: git log --oneline a3f4b2c fix 9d1e8c4 update 4c7b91f 修改了一些东西 f0a2d3e 。。。 b5c8e7a 又改了这就是"屎山提交记录"—…...