数据集划分——train_test_split函数使用说明
当我们拿到数据集时,首先需要对数据集进行划分训练集和测试集,sklearn提供了相应的函数供我们使用
一、讲解
快速随机划分数据集,可自定义比例进行划分训练集和测试集
二、官网API
官网API
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
导包:from sklearn.model_selection import train_test_split
为了方便说明,这里以一个具体的案例进行分析
织物起球等级评定,已知织物起球个数N、织物起球总面积S、织物起球最大面积Max_s、织物起球平均面积Aver_s、对比度C、光学体积V这六个特征参数来确定最终的织物起球等级Grade
说白了:六个特征(N、S、Max_s、Aver_s、C、V),来确定最终的等级(Grade)
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
参数:
①*arrays
传入因变量和自变量
这里的因变量为六个特征(N、S、Max_s、Aver_s、C、V)
自变量为最终评定的等级(Grade)
具体官网详情如下:
②test_size
若给该参数传入float浮点数,则范围为[0.0,1.0],表示测试集的比例
若给该参数传入int整型数,则表示测试集样本的具体数量
若为None,则设置为train_size参数的补数形式
若该test_size参数和train_size参数的值均为None,则该test_size设置为0.25,按float浮点型对待
具体官网详情如下:

③train_size
若给该参数传入float浮点数,则范围为[0.0,1.0],表示训练集的比例
若给该参数传入int整型数,则表示训练集样本的具体数量
若为None,则设置为test_size参数的补数形式
该参数跟test_size类似
具体官网详情如下:

④random_state
随机种子random_state,如果要是为了对比,需要控制变量的话,这里的随机种子最好设置为同一个整型数
具体官网详情如下:

⑤shuffle
是否在分割前对数据进行洗牌
如果 shuffle=False 则 stratify 必须为 None
具体官网详情如下:

⑥stratify
如果不是 “None”,数据将以分层方式分割,并以此作为类别标签
具体官网详情如下:

返回值:
splitting
返回一个包含训练和测试分割之后的列表
具体官网详情如下:

三、项目实战
①导包
若导入过程报错,pip安装即可
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
②加载数据集
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
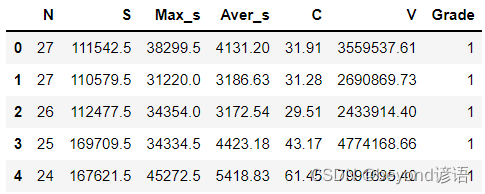
通过pandas读入文本数据集,展示前五行数据
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
③划分数据集
前六列是自变量X,最后一列是因变量Y
参数:
test_size:测试集数据所占比例,这里是0.25,表示测试集占总数据集的25%
train_size:训练集数据所占比例,这里是0.75,表示训练集占总数据集的75%
random_state:随机种子,为了控制变量
shuffle:是否将数据进行打乱
因为我这里的数据集共48个,训练集0.75,测试集0.25,即训练集36个,测试集12个
返回值:
依此返回四个list,分别为训练集的自变量、测试集的自变量、训练集的因变量和测试集的因变量,分别通过X_train, X_test, y_train, y_test进行接收
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True)print(X_train.shape) #(36,6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12,6)
print(y_test.shape) #(12,)
根据返回的四个list的shape可以看到数据集已经成功按自定义需求划分
⑤完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_splitfiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True)print(X_train.shape) #(36,6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12,6)
print(y_test.shape) #(12,)
相关文章:
数据集划分——train_test_split函数使用说明
当我们拿到数据集时,首先需要对数据集进行划分训练集和测试集,sklearn提供了相应的函数供我们使用 一、讲解 快速随机划分数据集,可自定义比例进行划分训练集和测试集 二、官网API 官网API sklearn.model_selection.train_test_split(*a…...

Pytorch中关于forward函数的理解与用法
目录 前言1. 问题所示2. 原理分析2.1 forward函数理解2.2 forward函数用法 前言 深入深度学习框架的代码,发现forward函数没有被显示调用 但代码确重写了forward函数,于是好奇是不是python的魔术方法作用 1. 问题所示 代码如下所示: cla…...
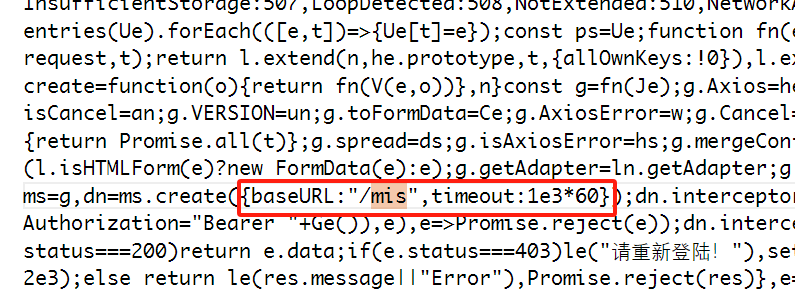
vite跨域proxy设置与开发、生产环境的接口配置,接口在生产环境下,还能使用proxy代理地址吗
文章目录 vite的proxy开发环境设置如果后端没有提供可以替换的/mis等可替换的后缀的处理办法接口如何区分.env.development开发和.env.production生产环境接口在生产环境下,还能使用proxy代理地址吗? vite的proxy开发环境设置 环境: vite 4…...
【嵌入式】使用MultiButton开源库驱动按键并控制多级界面切换
目录 一 背景说明 二 参考资料 三 MultiButton开源库移植 四 设计实现--驱动按键 五 设计实现--界面处理 一 背景说明 需要做一个通过不同按键控制多级界面切换以及界面动作的程序。 查阅相关资料,发现网上大多数的应用都比较繁琐,且对于多级界面的…...

【数据结构】树的概念理解和性质推导(保姆级详解,小白必看系列)
目录 一、前言 🍎 为什么要学习非线性结构 ---- 树(Tree) 💦 线性结构的优缺点 💦 优化方案 ----- 树(Tree) 💦 树的讲解流程 二、树的概念及结构 🍐 树的概念 &…...
融合之力:数字孪生、人工智能和数据分析的创新驱动
数字孪生、人工智能(AI)和数据分析是当今科技领域中的三个重要概念,它们之间存在着紧密的关联和互动,共同推动了许多领域的创新和发展。 一、概念 数字孪生是一种数字化的模拟技术,它通过复制现实世界中的物理实体、…...

Spring的注解开发-Spring配置类的开发
Bean配置类的注解开发 Component等注解替代了<bean>标签,但像<import>、<context:componentScan>等非<bean>标签怎样去使用注解去替代呢?定义一个配置类替代原有的xml配置文件,<bean>标签以外的标签ÿ…...
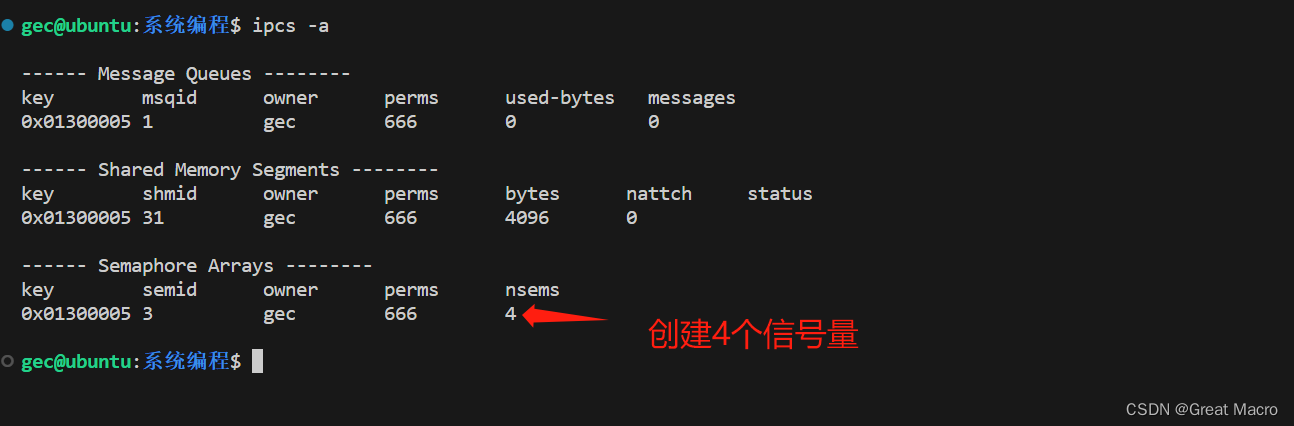
Linux系统编程系列之进程间通信-信号量组
一、什么是信号量组 信号量组是信号量的一种, 是system-V三种IPC对象之一,是进程间通信的一种方式。 二、信号量组的特性 信号量组不是用来传输数据的,而是作为“旗语”,用来协调各进程或者线程工作的。信号量组可以一次性在其内…...

centos 6使用yum安装软件
1. 执行以下命令,查看当前操作系统 CentOS 版本。 cat /etc/centos-release返回结果如下图所示,则说明当前操作系统版本为 CentOS 6.9。 2. 执行以下命令,编辑 CentOS-Base.repo 和CentOS-Epel.repo文件。 vim /etc/yum.repos.d/CentOS-Bas…...
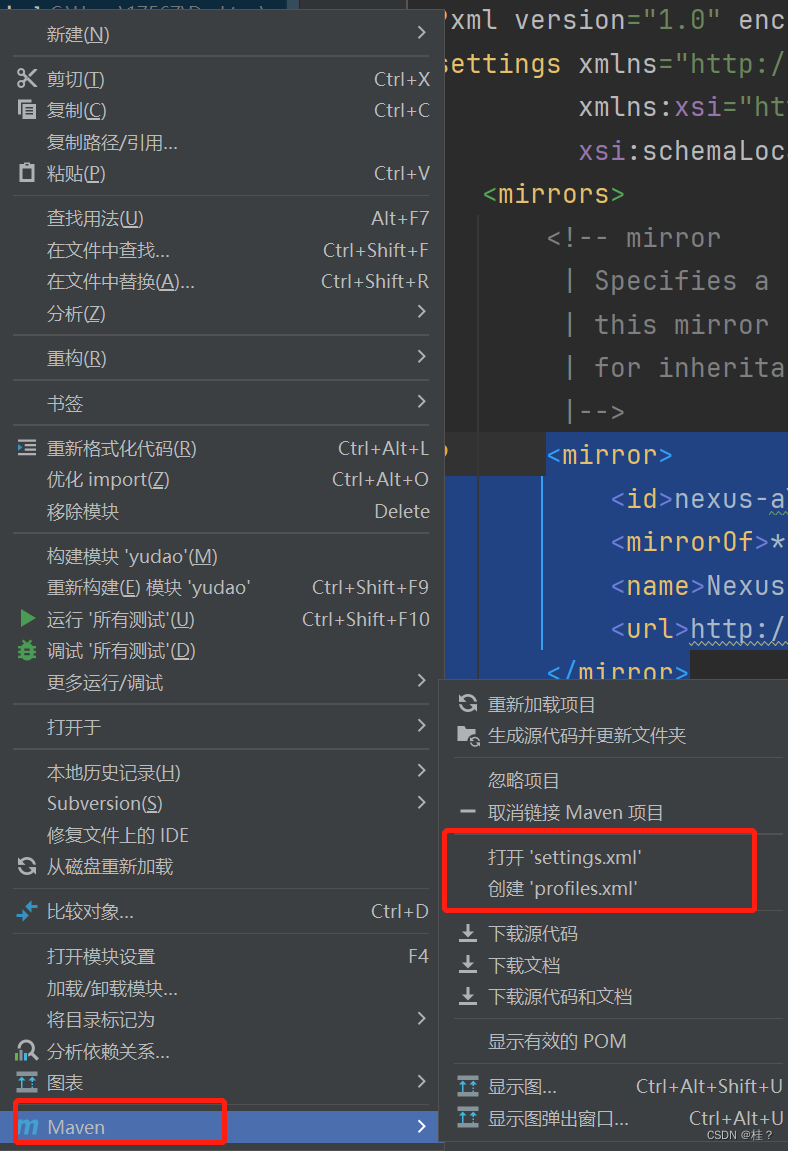
maven无法下载时的解决方法——笔记
右键项目然后点击创建setting.xml(因为现在创建了,所以没显示了,可以直接点击打开setting.xml) 然后添加 <mirror><id>nexus-aliyun</id><mirrorOf>*,!jeecg,!jeecg-snapshots</mirrorOf><name…...

Java Spring Boot 开发框架
Spring Boot是一种基于Java编程语言的开发框架,它的目标是简化Java应用程序的开发过程。Spring Boot提供了一种快速、易于使用的方式来创建独立的、生产级别的Java应用程序。本文将介绍Spring Boot的特性、优势以及如何使用它来开发高效、可靠的应用程序。 一、简介…...

Pytorch学习记录-1-张量
1. 张量 (Tensor): 数学中指的是多维数组; torch.Tensor data: 被封装的 Tensor dtype: 张量的数据类型 shape: 张量的形状 device: 张量所在的设备,GPU/CPU requires_grad: 指示是否需要计算梯度 grad: data 的梯度 grad_fn: 创建 Tensor 的 Functio…...
paddle2.3-基于联邦学习实现FedAVg算法-CNN
目录 1. 联邦学习介绍 2. 实验流程 3. 数据加载 4. 模型构建 5. 数据采样函数 6. 模型训练 1. 联邦学习介绍 联邦学习是一种分布式机器学习方法,中心节点为server(服务器),各分支节点为本地的client(设备&#…...

nuiapp保存canvas绘图
要保存一个 Canvas 绘图,可以使用以下步骤: 获取 Canvas 元素和其绘图上下文: var canvas document.getElementById("myCanvas"); var ctx canvas.getContext("2d");使用 Canvas 绘图 API 绘制图形。 使用 toDataUR…...
Object.defineProperty()方法详解,了解vue2的数据代理
假期第一篇,对于基础的知识点,我感觉自己还是很薄弱的。 趁着假期,再去复习一遍 Object.defineProperty(),对于这个方法,更多的还是停留在面试的时候,面试官问你vue2和vue3区别的时候,不免要提一提这个方法…...

Linux 磁盘管理
Linux 系统的磁盘管理直接关系到整个系统的性能表现。磁盘管理常用三个命令为: df、du 和 fdisk。 df df(英文全称:disk free)。df 命令用于显示磁盘空间的使用情况,包括文件系统的挂载点、总容量、已用空间、可用空间…...

大数据与人工智能的未来已来
大数据与人工智能的定义 大数据: 大数据指的是规模庞大、复杂性高、多样性丰富的数据集合。这些数据通常无法通过传统的数据库管理工具来捕获、存储、管理和处理。大数据的特点包括"3V": 大量(Volume):大数…...

【AI视野·今日Robot 机器人论文速览 第四十一期】Tue, 26 Sep 2023
AI视野今日CS.Robotics 机器人学论文速览 Tue, 26 Sep 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers Extreme Parkour with Legged Robots Authors Xuxin Cheng, Kexin Shi, Ananye Agarwal, Deepak Pathak人类可以通过以高度动态…...
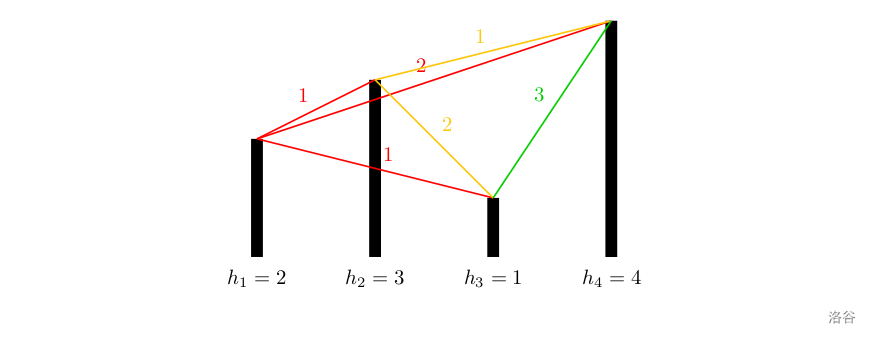
[NOIP2012 提高组] 开车旅行
[NOIP2012 提高组] 开车旅行 题目描述 小 A \text{A} A 和小 B \text{B} B 决定利用假期外出旅行,他们将想去的城市从 $1 $ 到 n n n 编号,且编号较小的城市在编号较大的城市的西边,已知各个城市的海拔高度互不相同,记城市 …...

数据库设计流程---以案例熟悉
案例名字:宠物商店系统 课程来源:点击跳转 信息->概念模型->数据模型->数据库结构模型 将现实世界中的信息转换为信息世界的概念模型(E-R模型) 业务逻辑 构建 E-R 图 确定三个实体:用户、商品、订单...

GPT-5.5不只是能写代码——ChatGPT Image 2模块“语义-结构-纹理“三级解耦机制详解
引言:图像生成能力的范式迁移过去两年,大模型的图像生成能力经历了从"能画"到"画对"的跃迁。早期的文生图模型普遍存在一个核心矛盾:用户想控制"画什么",模型却同时处理"画什么""怎…...

机器学习的几何本质:形状、距离与意义的三层重构
1. 这不是数学课,而是一场关于“机器如何看懂世界”的底层解剖你有没有想过,当一台机器识别出照片里是一只猫,它到底“看见”了什么?不是毛色、不是胡须、不是圆眼睛——它看见的是一组高维空间里的点云分布,是这些点之…...

UGUI三大Layout Group原理与避坑指南:Vertical、Horizontal、Grid布局本质解析
1. 为什么这三个Layout Group是UGUI里最常被误用、也最容易“看似正常实则埋雷”的组件?在Unity项目组做技术分享时,我常问新人一个问题:“你第一次用Vertical Layout Group,是不是拖进去一个空GameObject,加个组件&am…...

魔改frida-server实现反检测:从行为消除到可检测性归零
1. 为什么魔改frida-server比写检测绕过代码更根本?在Android逆向与安全测试一线干了十多年,我见过太多团队把精力耗在“检测逻辑对抗”上:写一堆Java层的isFridaPresent()、Native层的checkFridaPort()、甚至用ptrace自检父进程——结果呢&a…...

从芯片到产品:嵌入式AI与安全设计实战解析
1. 项目概述:一次面向未来的技术对话最近,我作为启扬智能的一员,有幸参与了「2025恩智浦技术巡回研讨会」的线下活动。这不仅仅是一次简单的产品展示或技术宣讲,更像是一场与产业链上下游伙伴、众多开发者同行进行的深度技术对话。…...

2026年,IP地理位置精准查询的几个硬核技术变化
关于IP定位相关最近和几个同行交流,发现大家对IP定位的理解还停留在之前,想把自己这段时间的一些实践整理出来,希望能给同样在搞网络或风控的同行一些参考。 IPv6流量超过IPv4、住宅代理攻击泛滥、CGNAT覆盖越来越广……这些变化正在悄悄改变…...
)
别再死记硬背公式了!用Matlab Robotics Toolbox玩转机器人姿态(旋转矩阵/欧拉角/四元数互转)
用Matlab Robotics Toolbox解锁机器人姿态转换的实战密码 在机器人学和计算机视觉领域,姿态表示就像工程师的第二语言。但当我们面对旋转矩阵、欧拉角和四元数这三种"方言"时,很多人会陷入公式记忆的泥潭。实际上,理解它们之间的关…...

YOLOv11养殖场羊群目标检测数据集-66张-sheep-1_3
YOLOv11养殖场羊群目标检测数据集 📊 数据集基本信息 目标类别: [‘sheep-1’, ‘sheep-10’, ‘sheep-11’, ‘sheep-2’, ‘sheep-3’, ‘sheep-4’, ‘sheep-5’, ‘sheep-6’, ‘sheep-7’, ‘sheep-8’, ‘sheep-9’]中文类别:[‘羊-1’…...

陆渔科技投入三千万学费:用AI擦去水产养殖不确定性,带来养殖确定性
创业故事:从偶然入局到屡败屡战陆渔科技深耕农业AI,两次失败、投入三千万学费,才拿到这张真实的“入场券”。鲁敏等四人原本与农业毫无关联,一次偶然饭局结识养鱼伙伴,了解到鲈鱼苗孵化项目。当时互联网、房地产市场饱…...

3个核心功能揭秘:JiYuTrainer如何让极域电子教室不再束缚你的学习自由
3个核心功能揭秘:JiYuTrainer如何让极域电子教室不再束缚你的学习自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在学校机房被极域电子教室的全屏广播困…...