ChatGPT 调教指南:从 PDF 提取标题并保存
一、请使用python编写一段代码,使用pymupdf包从pdf中提取标题,保存标题名称和页数。
我没有加任何的答案提示,看看 GPT 如何反应。它应该是知道 PDF 没有任何语义信息,一切标题或者正文全是文本框。
好的,以下是使用pymupdf包从pdf中提取标题,并保存标题名称和页数的代码示例:
import fitzdef extract_titles(pdf_path):doc = fitz.open(pdf_path)titles = []for page in doc:blocks = page.get_text("dict")["blocks"]for block in blocks:if block["type"] == 1 and block["bbox"][3] < 100:title = block["text"]page_num = page.number + 1titles.append({"title": title, "page": page_num})return titlespdf_path = "example.pdf"
titles = extract_titles(pdf_path)for title in titles:print("Title:", title["title"])print("Page:", title["page"])print()它里面有个错误,page.getText应该是page.get_text,我改了过来。
这个逻辑完全不对,我试了以下我手头的一个文字 PDF(三眼文集.pdf),第二页doc[1]的第一行就是标题。看看能不能提取
pdf_path = r"d:/docs/wealth-books-2023/权谋/三眼文集.pdf"
doc = fitz.open(pdf_path)
print(doc[1].get_text("dict")['blocks'][0])
'''
{'number': 0,'type': 0,'bbox': (48.0, 52.383140563964844, 531.0696411132812, 96.42223358154297),'lines': [{'spans': [{'size': 16.440000534057617,'flags': 4,'font': 'MicrosoftYaHeiUI','color': 0,'ascender': 1.015625,'descender': -0.25439453125,'text': '赚钱的本质套路一共就3个:底层收智商税、中层找接盘侠、上层','origin': (48.0, 69.08001708984375),'bbox': (48.0,52.383140563964844,531.0696411132812,73.26226043701172)}],'wmode': 0,'dir': (1.0, 0.0),'bbox': (48.0, 52.383140563964844, 531.0696411132812, 73.26226043701172)},{'spans': [{'size': 16.440000534057617,'flags': 4,'font': 'MicrosoftYaHeiUI','color': 0,'ascender': 1.015625,'descender': -0.25439453125,'text': '玩金融!(完整版)','origin': (48.0, 92.239990234375),'bbox': (48.0, 75.5431137084961, 199.65902709960938, 96.42223358154297)}],'wmode': 0,'dir': (1.0, 0.0),'bbox': (48.0, 75.5431137084961, 199.65902709960938, 96.42223358154297)}]}
'''
这个文本块的确是标题,但是type不是 1,根本提取不出来。
二、请使用python编写一段代码,使用pymupdf包从pdf中提取标题,保存标题名称和页数,注意不要根据文本块的类型来判断,而是根据其大小。
但是我们知道,标题的大小明显和正文不一样,比如正文大小是12,标题是16,那OK,我们引导 GPT 从大小方面区分。
您可以使用以下代码使用pymupdf包从PDF中提取标题和页数,并将其保存在列表中:
import fitzdef extract_titles(pdf_path):doc = fitz.open(pdf_path)titles = []for page_num in range(len(doc)):page = doc.load_page(page_num)blocks = page.get_text("dict", flags=11)["blocks"]for block in blocks:if block["type"] == 1 and block["bbox"][3] < 100:title = block["text"].strip()titles.append({"title": title, "page": page_num})return titlespdf_path = "your_pdf_path.pdf"
titles = extract_titles(pdf_path)for title in titles:print(f"Title: {title['title']}, Page: {title['page']}")请将代码中的"your_pdf_path.pdf"替换为您要提取标题的PDF路径。该代码使用pymupdf包打开PDF文件并迭代每个页面,然后检查每个文本块的类型和大小。如果文本块的类型为1(即标题)且其边界框高度小于100,将提取标题和页数,并将其添加到标题列表中。最后,打印出所有提取的标题和页数。
看来还是不改,还是按照文本框高度和类型区分。
三、请使用python编写一段代码,使用pymupdf包从pdf中提取标题大致方法是获取每一页的每个文本框,如果字体大小超出平均值一定倍数,就判断为标题,之后保存标题名称和页数。
你可以使用pymupdf包来提取PDF文件中的标题。以下是一个示例代码,根据字体大小判断标题并保存标题名称和页数:
import fitzdef extract_titles_from_pdf(file_path, threshold=1.5):doc = fitz.open(file_path)titles = []for page in doc:text_blocks = page.getTextBlocks()font_sizes = [block[1] for block in text_blocks]avg_font_size = sum(font_sizes) / len(font_sizes)for block in text_blocks:font_size = block[1]text = block[4]if font_size > avg_font_size * threshold:titles.append((text, page.number))return titles# 调用示例
pdf_path = "example.pdf"
titles = extract_titles_from_pdf(pdf_path)
for title, page_num in titles:print(f"标题: {title}\t页数: {page_num}")这段代码有个错误,就是
block的前四个数值是矩形四个分量并不是大小,不过这个思路改一改应该就可以用了。
四、修改后的代码
'''
block: {'number': 1,'type': 0,'bbox': (158.25, 569.15625, 446.25, 663.375),'lines': [{'spans': [{'size': 72.0,'flags': 0,'font': 'SimSun','color': 16776960,'ascender': 1.04296875,'descender': -0.265625,'text': '三眼文集','origin': (158.25, 644.25),'bbox': (158.25, 569.15625, 446.25, 663.375)}],'wmode': 0,'dir': (1.0, 0.0),'bbox': (158.25, 569.15625, 446.25, 663.375)}]}
'''def extract_titles_from_pdf(file_path, thres=1.2):doc = fitz.open(file_path)titles = []for i, page in enumerate(doc):blocks = [block for block in page.get_text("dict")["blocks"]if block['type'] == 0]sizes = [span['size'] for block in blocksfor line in block['lines']for span in line['spans']]avg_size = sum(sizes) / (len(sizes) + 1e-9)page_titles = [(span['text'], i) for block in blocksfor line in block['lines']for span in line['spans']if span['size'] > avg_size * thres]titles += page_titlesreturn titles
好,然后调用:
res = extract_titles_from_pdf(pdf_path, 1.2)
print(res)
'''
[('赚钱的本质套路一共就3个:底层收智商税、中层找接盘侠、上层', 1),('玩金融!(完整版)', 1),('钱就是债!——金融家的秘密,老百姓的盲点!明白这个才能不被', 8),('收割', 8),('穷人才想赚快钱!教人致富多为骗局!想变富要明白一个逻辑:分', 11),('配!', 11),('历史观比财经观更重要!经济是政治的延伸,而今天是昨日的推', 14),('演!', 14),('大钱要靠分配!不是卖苦力赚的!人生是无数个局,看局方能破局', 17),('为何啥都不好干了?为何经济放缓了?本质在于这一群体快被抽', 21),('干!', 21),('过去高增长的本质是什么?', 21),...]
'''
OK 初步完成。
相关文章:

ChatGPT 调教指南:从 PDF 提取标题并保存
一、请使用python编写一段代码,使用pymupdf包从pdf中提取标题,保存标题名称和页数。 我没有加任何的答案提示,看看 GPT 如何反应。它应该是知道 PDF 没有任何语义信息,一切标题或者正文全是文本框。 好的,以下是使用py…...
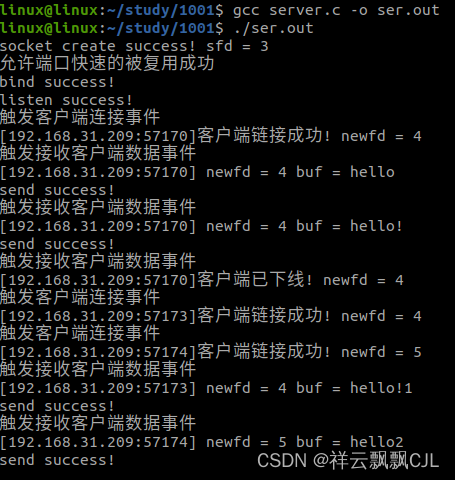
【day10.01】使用select实现服务器并发
用select实现服务器并发: linuxlinux:~/study/1001$ cat server.c #include <myhead.h>#define ERR_MSG(msg) do{\printf("%d\n",__LINE__);\perror(msg);\ }while(0)#define PORT 8880#define IP "192.168.31.38"int main(int argc, c…...

Android修行手册 - Activity 在 Java 和 Kotlin 中怎么写构造参数
点击跳转>Unity3D特效百例点击跳转>案例项目实战源码点击跳转>游戏脚本-辅助自动化点击跳转>Android控件全解手册点击跳转>Scratch编程案例点击跳转>软考全系列 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分享&…...
)
【IPC 通信】信号处理接口 Signal API(7)
收发信号思想是 Linux 程序设计特性之一,一个信号可以认为是一种软中断,通过用来向进程通知异步事件。 本文讲述的 信号处理内容源自 Linux man。本文主要对各 API 进行详细介绍,从而更好的理解信号编程。 exit(5) 遵循 C11, POSI…...
+导航守卫)
springboot和vue:十二、VueRouter(动态路由)+导航守卫
VueRouter的简介 VueRouter是官方的路由插件,适合单页面应用/网页的切换。VueRouter目前有3.x版本和4.x版本,3.x版本只能结合vue2使用,4.x版本只能结合vue3使用。安装:npm install vue-router3 目的 初始版本:我们想…...
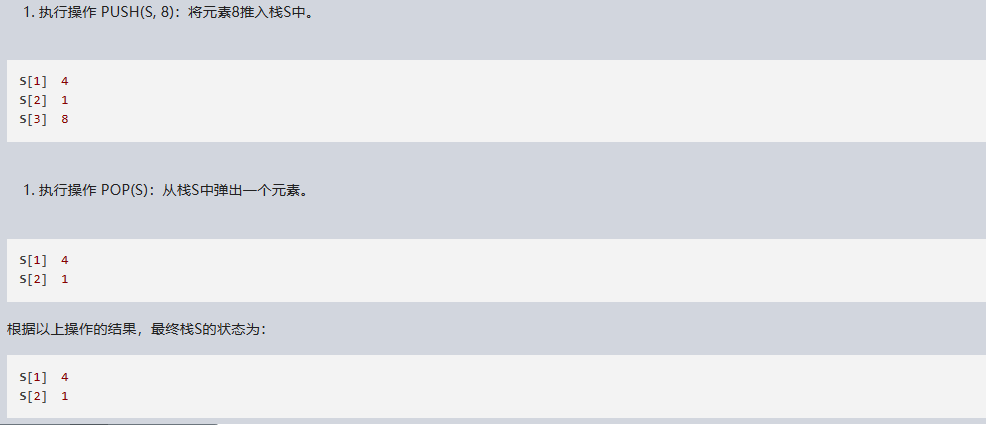
文心一言 VS 讯飞星火 VS chatgpt (103)-- 算法导论10.1 1题
一、用go语言,仿照图 10-1,画图表示依次执行操作 PUSH(S,4)、PUSH(S,1)、PUSH(S,3)、POP(S)、PUSH(S,8)和 POP(S)每一步的结果,栈 S初始为空,存储于数组 S[1…6]中。 文心一言&…...

【ShaderLab罪恶装备卡通角色_二次元风格_“Sol Badguy“_角色渲染(第二篇)】
罪恶装备背德之炎卡通角色_二次元风格_Unity 角色渲染 角色初始效果:基础渲染SimpleBas 资源分析模型顶点颜色: 贴图资源SOL_base_基础色块效果:其中SOL_base_A通道的效果: SOL_ilm:如下SOL_ilm模型上区域分布- 左到右…...
raw智能照片处理工具DxO PureRAW mac介绍
DxO PureRAW Mac版是一款raw智能照片处理工具,该软件采用了智能技术,以解决影响所有RAW文件的七个问题:去马赛克,降噪,波纹,变形,色差,不想要的渐晕,以及缺乏清晰度。 Dx…...

1.centos7 安装显卡驱动、cuda、cudnn
安装conda 参考 python包 2.安装conda python库-CSDN博客3.Cenots Swin-Transformer-Object-Detection环境配置-CSDN博客 1.安装显卡驱动 步骤1:安装依赖 yum -y install kernel-devel yum -y install epel-release yum -y install gcc 步骤2:查询显…...
之—— 主题开发示例)
WordPress主题开发( 十四)之—— 主题开发示例
要深入了解WordPress主题开发的最佳实践和标准,参考主题示例是一种非常有效的方法。在这里,我们将介绍两个主题示例:默认的Twenty主题和Underscores主题,它们都是出色的学习资源。 默认“Twenty”主题 自WordPress 3.0版本开始&a…...

rust学习-any中的downcast和downcast_ref
背景 看rust官方文档,好奇Any和Go的Any是否是一回事,看到下文的一行代码,了解下它的功能 pub trait Any: static {// Required methodfn type_id(&self) -> TypeId; }std::any 用于 dynamic typing 或者 type reflection 模拟动态类型的trait。 大多数类型都实现 …...

js检测数据类型总结
目录 一、typeof 二、instanceof 三、constructor 四、Object.prototype.toString.call() Object.prototype.toString.call(obj)类型检测原理 五、__proto__ 六、 其他 一、typeof typeof在对值类型number、string、boolean 、symbol、 undefined、 function的反应是精准…...

获奖作品展示 | 2023嵌入式大赛AidLux系列作品精彩纷呈
第六届(2023)全国大学生嵌入式芯片与系统设计竞赛应用赛道全国总决赛已于8月下旬圆满结束。 本届赛事中,AidLux是广和通5G智能物联网赛题的唯一软件支持,阿加犀为该赛题学生们提供了全程线上辅导、技术答疑,以及大赛专…...
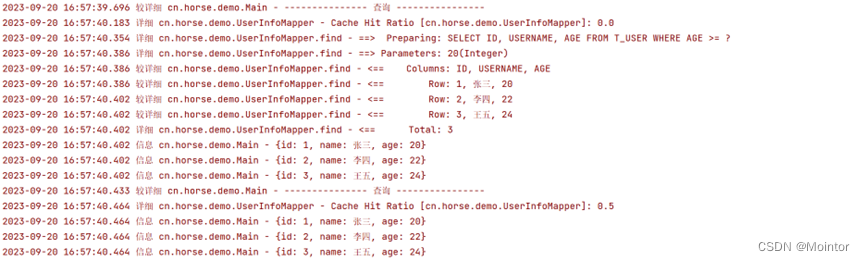
Mybatis 二级缓存(使用Redis作为二级缓存)
上一篇我们介绍了mybatis中二级缓存的使用,本篇我们在此基础上介绍Mybatis中如何使用Redis作为二级缓存。 如果您对mybatis中二级缓存的使用不太了解,建议您先进行了解后再阅读本篇,可以参考: Mybatis 二级缓存https://blog.csd…...

VMware vSphere ESXI 6.7 U3封装RTL8125B网卡驱动
之前的教程VMware vSphere ESXI 6.7 U3最新版本封装网卡驱动补丁可参考,本文为此文章的又一次实践 准备工作 1、ESXi-Customizer-PS-v2.6.0.ps1 (官网下载,Github下载) 2、ESXi670-202210001.zip (VMware vSphere Hy…...

黑马JVM总结(二十五)
(1)字节码指令-cinit 构造方法可以分为两类,一类是cinit 一类init cinit是整个类的构造方法 putstatic:进行static变量的赋值,是到常量池里找到名字一个叫做i的变量 (2)字节码指令-init in…...

基础数据结构之——【顺序表】(上)
从今天开始更新数据结构的相关内容。(我更新博文的顺序一般是按照我当前的学习进度来安排,学到什么就更新什么(简单来说就是我的学习笔记),所以不会对一个专栏一下子更新到底,哈哈哈哈哈哈哈!&a…...

Apollo自动驾驶系统概述(文末参与活动赠送百度周边)
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

Java 21 新特性:Unnamed Classes and Instance Main Methods
Java 21引入了两个语言核心功能: 未命名的Java类你说新的启动协议:该协议允许更简单地运行Java类,并且无需太多样板 下面一起来看个例子。通常,我们初学Java的时候,都会写类似下面这样的 Hello World 程序࿱…...

Tomcat启动后的日志输出为乱码
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

2021年5月AI工程化三大关键突破:Deformable DETR、REALM与WB Model Registry
1. 项目概述:这不是一份榜单,而是一份2021年5月AI领域真实水位的切片报告“The AI Monthly Top 3 — May 2021”这个标题乍看像一份轻量级资讯简报,但在我连续追踪AI领域动态超过十年、亲手部署过从BERT-base到GPT-3早期API调用、从YOLOv3训练…...

Unity中DragonBones多动画性能优化:图集复用与骨骼模板化
1. 为什么DragonBones动画在Unity里总“卡得莫名其妙”?我第一次在Unity项目里接入DragonBones时,美术给的是一套角色的12个独立动画:idle、walk、run、jump、attack1、attack2、hurt、die、victory、taunt、cast、reload——每个都带完整骨骼…...

5月22日截止报名!重庆农商行2026求职报名+备考解读
本文涵盖:重庆农村商业银行2026招聘报名时间、重庆农商行笔试内容、重庆农商行面试真题、在线刷题等备考信息小职划重点!重庆农村商业银行2026招聘,报名截止时间为2026年5月22日17:00① 招聘流程:报名→在线测评→资格审查→测试→…...

大规模数据降维中迹比率问题与非负矩阵分解的快速算法【附代码】
✨ 长期致力于数据降维、大规模判别分析、迹比率问题、快速算法、非负矩阵分解研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)随机迹比率问题的显式解…...

洛圣都生存指南:YimMenu开源游戏增强工具与安全防护系统深度解析
洛圣都生存指南:YimMenu开源游戏增强工具与安全防护系统深度解析 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trendi…...

No!! MeiryoUI终极指南:3步恢复Windows界面字体自定义功能
No!! MeiryoUI终极指南:3步恢复Windows界面字体自定义功能 【免费下载链接】noMeiryoUI No!! MeiryoUI is Windows system font setting tool on Windows 8.1/10/11. 项目地址: https://gitcode.com/gh_mirrors/no/noMeiryoUI 你是否曾经为Windows 8.1/10/11…...
超精密反射镜技术壁垒)
0602光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)超精密反射镜技术壁垒
第2小节:超精密反射镜技术壁垒(基底加工镀膜检测,全量化死磕)前置硬核声明EUV整机90%的成像误差、波像差、良率波动,最终全部归因于超精密反射镜的制造壁垒。EUV不是“普通光学抛光”,是原子级表面重构、皮…...

如何用 polyfill-iconv 处理中文编码?GBK、BIG5、UTF-8 转换终极指南
如何用 polyfill-iconv 处理中文编码?GBK、BIG5、UTF-8 转换终极指南 【免费下载链接】polyfill-iconv This component provides a native PHP implementation of the php.net/iconv functions. 项目地址: https://gitcode.com/gh_mirrors/po/polyfill-iconv …...

根据等价类划分法,**有效等价类**是指符合系统规格说明、应被系统正常接受的输入范围
根据等价类划分法,有效等价类是指符合系统规格说明、应被系统正常接受的输入范围。 题目中密码长度要求为 6–12位(含端点),即最小长度为6,最大长度为12,且为整数位数。 因此,关于密码长度的有效…...
)
Midjourney金属质感渲染实战手册(航天级铝钛合金/做旧铜锈/镜面不锈钢三重进阶)
更多请点击: https://intelliparadigm.com 第一章:Midjourney金属质感渲染的核心原理与演进脉络 金属质感在AI图像生成中属于高阶视觉建模任务,其本质依赖于对微观表面结构、镜面反射路径与环境光交互的隐式学习。Midjourney自V5起引入更精细…...