谈谈 Redis 数据类型底层的数据结构?
谈谈 Redis 数据类型底层的数据结构?
RedisObject
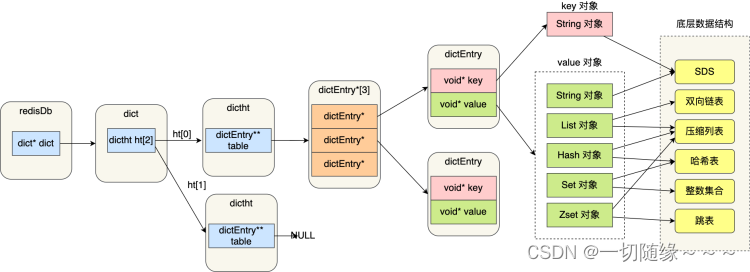
在 Redis 中,redisObject 是一个非常重要的数据结构,它用于保存字符串、列表、集合、哈希表和有序集合等类型的值。以下是关于 redisObject 结构体的定义:
typedef struct redisObject {unsigned type:4;unsigned encoding:4;unsigned lru:24; /* lru time (relative to server.lruclock) */int refcount;void *ptr;
} robj;
各个属性解析如下:
● type:用于标识对象所属的类型,分别是 REDIS_STRING、REDIS_LIST、REDIS_SET、REDIS_ZSET 和 REDIS_HASH 等。
● encoding: 用于标识对象内部的编码方式, 如 REDIS_ENCODING_INT、REDIS_ENCODING_HT、REDIS_ENCODING_ZIPMAP 等。
● lru:这个字段记录了对象被命令调用的时间, 它是缓存淘汰策略(LRU)的一部分。
● refcount:引用计数,当 refcount 减少到0时,对象就可以被清理并回收内存。
● ptr:一个指针,根据对象的类型和编码方式的不同,这个指针可能会指向各种不同的类型,比如整数、动态字符串、链表、字典等。
SDS
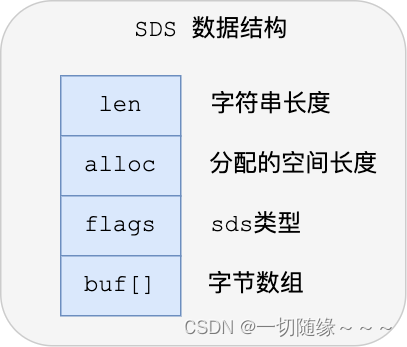
结构中的每个成员变量分别介绍下:
● len,记录了字符串长度。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。
● alloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过 alloc - len 计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。
● flags,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,后面在说明区别之处。
● buf[],字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。
总的来说,Redis 的 SDS 结构在原本字符数组之上,增加了三个元数据:len、alloc、flags,用来解决 C 语言字符串的缺陷。
O(1)复杂度获取字符串长度
二进制安全
不会发生缓冲区溢出
节省内存空间
双端链表
Redis 的链表实现优点如下:
● listNode 链表节点的结构里带有 prev 和 next 指针,获取某个节点的前置节点或后置节点的时间复杂度只需O(1),而且这两个指针都可以指向 NULL,所以链表是无环链表;
● list 结构因为提供了表头指针 head 和表尾节点 tail,所以获取链表的表头节点和表尾节点的时间复杂度只需O(1);
● list 结构因为提供了链表节点数量 len,所以获取链表中的节点数量的时间复杂度只需O(1);
● listNode 链表节使用 void* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此链表节点可以保存各种不同类型的值;
链表的缺陷也是有的:
● 链表每个节点之间的内存都是不连续的,意味着无法很好利用 CPU 缓存。能很好利用 CPU 缓存的数据结构就是数组,因为数组的内存是连续的,这样就可以充分利用 CPU 缓存来加速访问。
● 还有一点,保存一个链表节点的值都需要一个链表节点结构头的分配,内存开销较大。
因此,Redis 3.0 的 List 对象在数据量比较少的情况下,会采用「压缩列表」作为底层数据结构的实现,它的优势是节省内存空间,并且是内存紧凑型的数据结构。
不过,压缩列表存在性能问题(具体什么问题,下面会说),所以 Redis 在 3.2 版本设计了新的数据结构 quicklist,并将 List 对象的底层数据结构改由 quicklist 实现。
然后在 Redis 5.0 设计了新的数据结构 listpack,沿用了压缩列表紧凑型的内存布局,最终在最新的 Redis 版本,将 Hash 对象和 Zset 对象的底层数据结构实现之一的压缩列表,替换成由 listpack 实现。
压缩链表 ziplist
压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。
但是,压缩列表的缺陷也是有的:
● 不能保存过多的元素,否则查询效率就会降低;
● 新增或修改某个元素时,压缩列表占用的内存空间需要重新分配,甚至可能引发连锁更新的问题。
因此,Redis 对象(List 对象、Hash 对象、Zset 对象)包含的元素数量较少,或者元素值不大的情况才会使用压缩列表作为底层数据结构。

压缩列表在表头有三个字段:
● zlbytes,记录整个压缩列表占用对内存字节数;
● zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
● zllen,记录压缩列表包含的节点数量;
● zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段(zllen)的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,因此压缩列表不适合保存过多的元素。
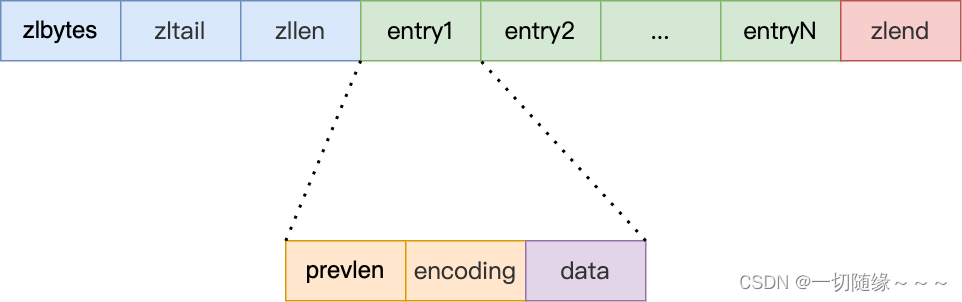
压缩列表节点包含三部分内容:
● prevlen,记录了「前一个节点」的长度,目的是为了实现从后向前遍历;
● encoding,记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。
● data,记录了当前节点的实际数据,类型和长度都由 encoding 决定;
当我们往压缩列表中插入数据时,压缩列表就会根据数据类型是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
查找复杂度高,不适合存储过多的元素
连锁更新问题
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
压缩列表的缺陷
空间扩展操作也就是重新分配内存,因此连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。
所以说,虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题。
因此,压缩列表只会用于保存的节点数量不多的场景,只要节点数量足够小,即使发生连锁更新,也是能接受的。
虽说如此,Redis 针对压缩列表在设计上的不足,在后来的版本中,新增设计了两种数据结构:quicklist(Redis 3.2 引入) 和 listpack(Redis 5.0 引入)。这两种数据结构的设计目标,就是尽可能地保持压缩列表节省内存的优势,同时解决压缩列表的「连锁更新」的问题。
哈希表
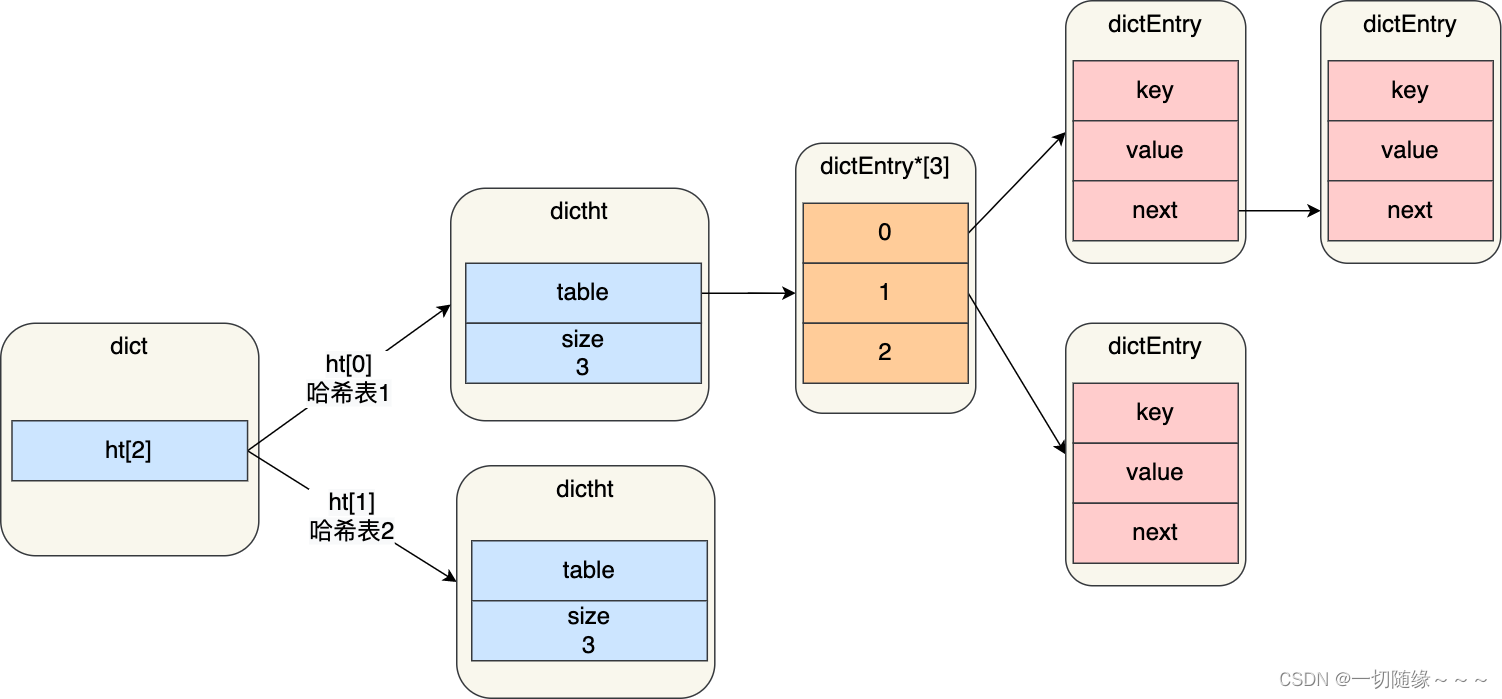
原理跟 Java 的 HashMap 差不多。
Redis 采用了「链式哈希」的方法来解决哈希冲突。
渐进式 rehash
为了避免 rehash 在数据迁移过程中,因拷贝数据的耗时,影响 Redis 性能的情况,所以 Redis 采用了渐进式 rehash,也就是将数据的迁移的工作不再是一次性迁移完成,而是分多次迁移。
渐进式 rehash 步骤如下:
● 给「哈希表 2」 分配空间;
● 在 rehash 进行期间,每次哈希表元素进行新增、删除、查找或者更新操作时,Redis 除了会执行对应的操作之外,还会顺序将「哈希表 1 」中索引位置上的所有 key-value 迁移到「哈希表 2」 上;
● 随着处理客户端发起的哈希表操作请求数量越多,最终在某个时间点会把「哈希表 1 」的所有 key-value 迁移到「哈希表 2」,从而完成 rehash 操作。
这样就巧妙地把一次性大量数据迁移工作的开销,分摊到了多次处理请求的过程中,避免了一次性 rehash 的耗时操作。
在进行渐进式 rehash 的过程中,会有两个哈希表,所以在渐进式 rehash 进行期间,哈希表元素的删除、查找、更新等操作都会在这两个哈希表进行。
比如,查找一个 key 的值的话,先会在「哈希表 1」 里面进行查找,如果没找到,就会继续到哈希表 2 里面进行找到。
另外,在渐进式 rehash 进行期间,新增一个 key-value 时,会被保存到「哈希表 2 」里面,而「哈希表 1」 则不再进行任何添加操作,这样保证了「哈希表 1 」的 key-value 数量只会减少,随着 rehash 操作的完成,最终「哈希表 1 」就会变成空表。
rehash 触发条件
介绍了 rehash 那么多,还没说什么时情况下会触发 rehash 操作呢?
rehash 的触发条件跟负载因子(load factor)有关系。
负载因子可以通过下面这个公式计算:

触发 rehash 操作的条件,主要有两个:
● 当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
● 当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。
整数集合
跳表
zset 结构体里有两个数据结构:一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
Zset 对象在执行数据插入或是数据更新的过程中,会依次在跳表和哈希表中插入或更新相应的数据,从而保证了跳表和哈希表中记录的信息一致。
Zset 对象能支持范围查询(如 ZRANGEBYSCORE 操作),这是因为它的数据结构设计采用了跳表,而又能以常数复杂度获取元素权重(如 ZSCORE 操作),这是因为它同时采用了哈希表进行索引。

第一眼看到跨度的时候,以为是遍历操作有关,实际上并没有任何关系,遍历操作只需要用前向指针(struct zskiplistNode *forward)就可以完成了。
跨度实际上是为了计算这个节点在跳表中的排位。具体怎么做的呢?因为跳表中的节点都是按序排列的,那么计算某个节点排位的时候,从头节点点到该结点的查询路径上,将沿途访问过的所有层的跨度累加起来,得到的结果就是目标节点在跳表中的排位。
举个例子,查找图中节点 3 在跳表中的排位,从头节点开始查找节点 3,查找的过程只经过了一个层(L2),并且层的跨度是 3,所以节点 3 在跳表中的排位是 3。
跳表节点查询过程
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
● 如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
● 如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
为什么用跳表而不用平衡树?
● 从内存占用上来比较,跳表比平衡树更灵活一些。平衡树每个节点包含 2 个指针(分别指向左右子树),而跳表每个节点包含的指针数目平均为 1/(1-p),具体取决于参数 p 的大小。如果像 Redis里的实现一样,取 p=1/4,那么平均每个节点包含 1.33 个指针,比平衡树更有优势。
● 在做范围查找的时候,跳表比平衡树操作要简单。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在跳表上进行范围查找就非常简单,只需要在找到小值之后,对第 1 层链表进行若干步的遍历就可以实现。
● 从算法实现难度上来比较,跳表比平衡树要简单得多。平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而跳表的插入和删除只需要修改相邻节点的指针,操作简单又快速
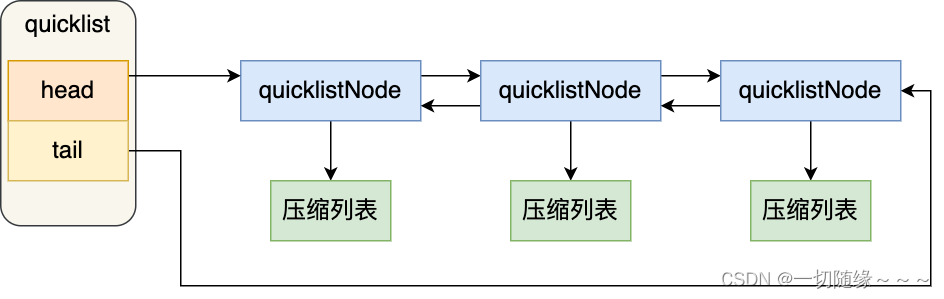
quicklist
在 Redis 3.0 之前,List 对象的底层数据结构是双向链表或者压缩列表。然后在 Redis 3.2 的时候,List 对象的底层改由 quicklist 数据结构实现。
其实 quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
在前面讲压缩列表的时候,我也提到了压缩列表的不足,虽然压缩列表是通过紧凑型的内存布局节省了内存开销,但是因为它的结构设计,如果保存的元素数量增加,或者元素变大了,压缩列表会有「连锁更新」的风险,一旦发生,会造成性能下降。
quicklist 解决办法,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
listpack
quicklist 虽然通过控制 quicklistNode 结构里的压缩列表的大小或者元素个数,来减少连锁更新带来的性能影响,但是并没有完全解决连锁更新的问题。
因为 quicklistNode 还是用了压缩列表来保存元素,压缩列表连锁更新的问题,来源于它的结构设计,所以要想彻底解决这个问题,需要设计一个新的数据结构。
于是,Redis 在 5.0 新设计一个数据结构叫 listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
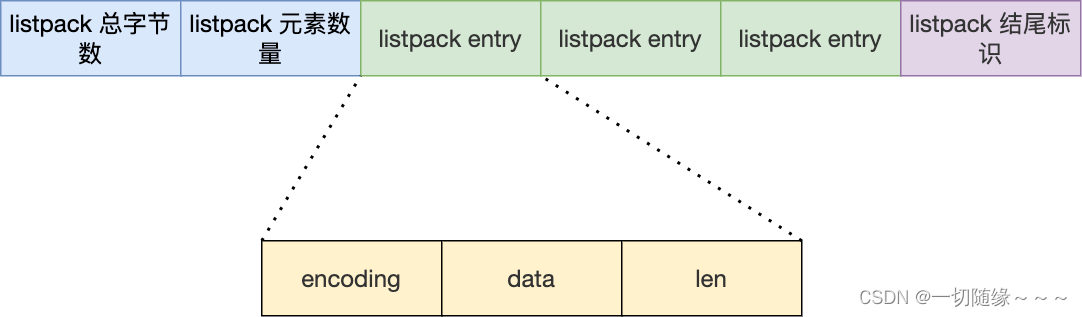
可以看到,listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。
相关文章:
谈谈 Redis 数据类型底层的数据结构?
谈谈 Redis 数据类型底层的数据结构? RedisObject 在 Redis 中,redisObject 是一个非常重要的数据结构,它用于保存字符串、列表、集合、哈希表和有序集合等类型的值。以下是关于 redisObject 结构体的定义: typedef struct redisObject {…...

九、GC收集日志
JVM由浅入深系列一、关于Java性能的误解二、Java性能概述三、了解JVM概述四、探索JVM架构五、垃圾收集基础六、HotSpot中的垃圾收集七、垃圾收集中级八、垃圾收集高级👋GC收集日志 ⚽️1. 认识GC收集日志 垃圾收集日志是一个重要的信息来源,对于与性能相关的一些悬而未决的…...
SimpleCG动画示例--汉诺塔动画演示
前言 SimpleCG的使用方法在前面已经介绍了许多,有兴趣的同学如果有去动手,制作一些简单动画应该没多大问题的。所以这次我们来演示一下简单动画。我们刚学习C语言的递归函数时,有一个经典例子相信很多同学都写过,那就是汉诺塔。那…...
)
反弹shell脚本(php-reverse-shell)
平时经常打靶机 这里贴一个 反弹shell的脚本 <?php // php-reverse-shell - A Reverse Shell implementation in PHP // Copyright (C) 2007 pentestmonkeypentestmonkey.net // // This tool may be used for legal purposes only. Users take full responsibility // f…...

XSS-labs
XSS常见的触发标签_xss标签_H3rmesk1t的博客-CSDN博客 该补习补习xss漏洞了 漏洞原理 网站存在 静态 和 动态 网站 xss 针对的网站 就是 动态网站 动态网站会根据 用户的环境 与 需求 反馈出 不同的响应静态页面 代码写死了 只会存在代码中有的内容 通过动态网站 用户体…...

C++简单实现AVL树
目录 一、AVL树的概念 二、AVL树的性质 三、AVL树节点的定义 四、AVL树的插入 4.1 parent的平衡因子为0 4.2 parent的平衡因子为1或-1 4.3 parent的平衡因子为2或-2 4.3.1 左单旋 4.3.2 右单旋 4.3.3 先左单旋再右单旋 4.3.4 先右单旋再左单旋 4.4 插入节点完整代码…...
UE4 Cesium 与ultra dynamic sky插件天气融合
晴天: 雨天: 雨天湿度: 小雪: 中雪: 找到该路径这个材质: 双击点开: 将Wet_Weather_Effects与Snow_Weather_Effects复制下来,包括参数节点 找到该路径这个材质,双击点开&…...
SpringCloud Gateway--Predicate/断言(详细介绍)下
😀前言 本篇博文是关于SpringCloud Gateway–Predicate/断言(详细介绍)下,希望你能够喜欢 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章可以…...
SOC芯片学习--GPIO简介
原创 硬件设计技术 硬件设计技术 2023-07-20 00:04 发表于广东 收录于合集#集成电路--IC7个 一、GPIO定义、分类: GPIO(英语:General-purpose input/output),通用型之输入输出的简称,其接脚可以供使用者由…...

skywalking源码本地编译运行经验总结
前言 最近工作原因在弄skywalking,为了进一步熟悉拉了代码下来准备debug,但是编译启动项目我就费了老大劲了,所以准备写这篇,帮兄弟们少踩点坑。 正确步骤 既然是用开源的东西,那么最好就是按照人家的方式使用&…...
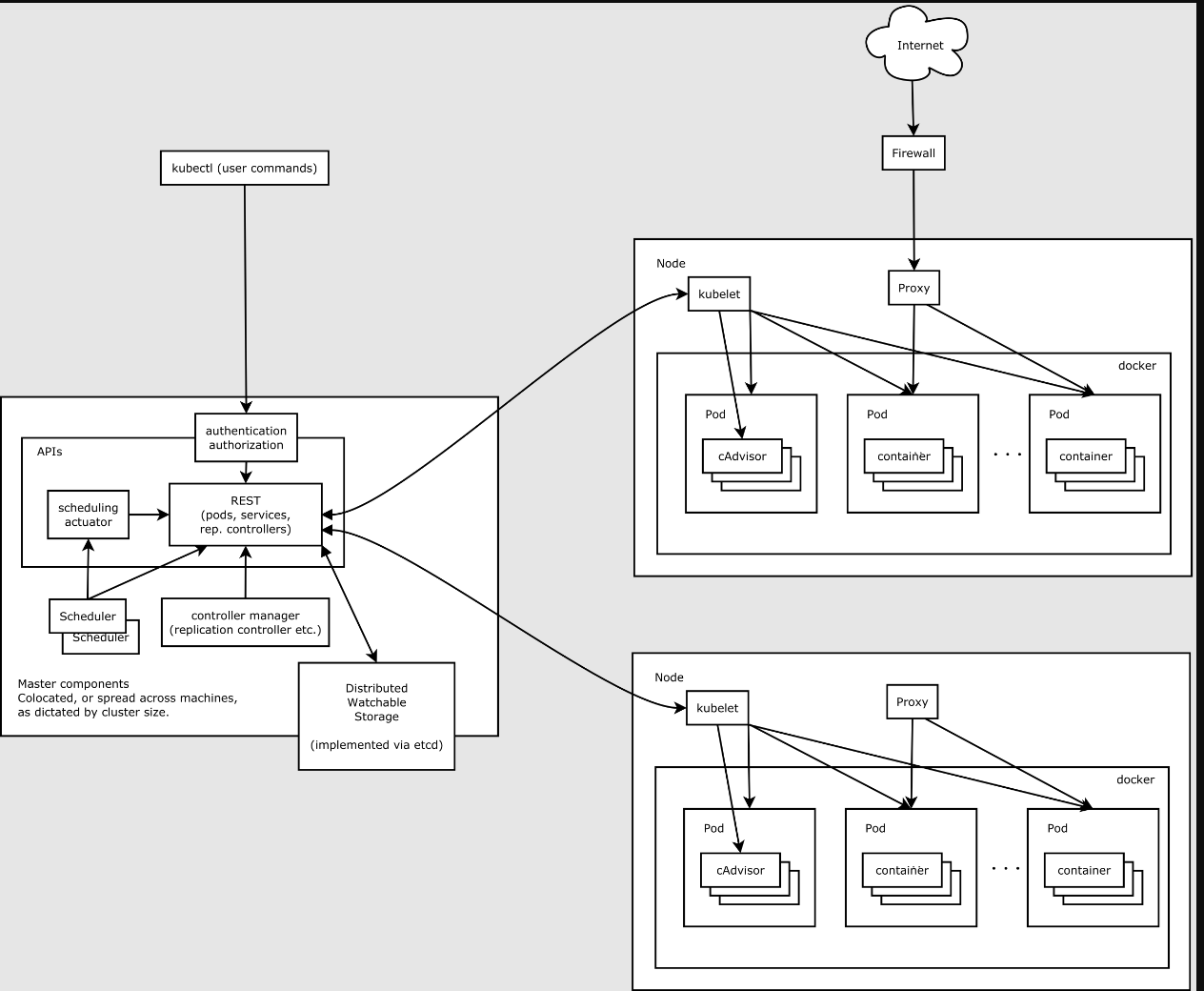
K8s架构简述
以部署一个nginx服务说明kubernetes系统各个组件调用关系: 一旦kubernetes环境启动之后,master和node都会将自身的信息存储到etcd数据库中 一个nginx服务的安装请求会首先被发送到master节点的apiServer组件 apiServer组件会调用scheduler组件来决定到底…...

linkedlist和arraylist的区别
LinkedList和ArrayList都是常见的数据结构,用于存储和操作集合元素,如果需要频繁进行插入和删除操作,LinkedList可能更适合。如果需要快速随机访问和较小的内存占用,ArrayList可能更合适。 以下是它们之间存在一些关键的区别&…...

[尚硅谷React笔记]——第2章 React面向组件编程
目录: 基本理解和使用: 使用React开发者工具调试函数式组件复习类的基本知识类式组件组件三大核心属性1: state 复习类中方法this指向: 复习bind函数:解决changeWeather中this指向问题:一般写法:state.htm…...

嵌入式学习笔记(40)看门狗定时器
7.5.1什么是看门狗、有何用 (1)看门狗定时器和普通定时器并无本质区别。定时器可以设定一个时间,在这个时间完成之前定时器不断计时,时间到的时候定时器会复位CPU(重启系统)。 (2)系统正常工作的时候当然不希望被重启࿰…...

点击、拖拉拽,BI系统让业务掌握数据分析主动权
在今天的商业环境中,数据分析已经成为企业获取竞争优势的关键因素之一。然而,许多企业在面对复杂的数据分析工具时,却常常感到困扰。这些工具往往需要专业的技术人员操作,而且界面复杂,难以理解和使用。对业务人员来说…...

C++模拟题[第一周-T1] 扑克
[第一周-T1] 扑克 题目描述 斗地主是一种使用 A \tt A A 到 K \tt K K 加上大小王的共 54 54 54 张扑克牌来进行的游戏,其中大小王各一张,其它数码牌各四张。在斗地主中,牌的大小关系根据牌的数码表示如下: 3 < 4 < 5 …...

ciscn_2019_s_9
ciscn_2019_s_9 Arch: i386-32-little RELRO: Partial RELRO Stack: No canary found NX: NX disabled PIE: No PIE (0x8048000) RWX: Has RWX segments32位,啥也没开,开心愉悦写shellcode int pwn() {char s[24]; // [esp8…...

微信、支付宝、百度、抖音开放平台第三方代小程序开发总结
大家好,我是小悟 小伙伴们都开启小长假了吧,值此中秋国庆双节之际,小悟祝所有的小伙伴们节日快乐。 支付宝社区很用心,还特意给寄了袋月饼,愿中秋节的圆月带给你身体健康,幸福团圆,国庆节的旗帜…...

C语言协程
协程(Coroutine)是一种程序运行方式,相比于线程和进程,协程更加轻量级,可以被视为一种用户态的线程,不需要内核的参与。 协程的特点在于其执行过程中可以被挂起(Suspend)࿰…...
)
RK3588安装python3.11(ubuntu18.04)
1.前言 看到rknn_toolkit_lite2更新了python3.11的安装包,马上更新一下 2.RK3588安装python3.11 Ubuntu上编译Python 3.11,您可以按照以下步骤进行操作: (1) 准备编译环境 在开始之前,确保您的系统已安装必要的编译工具和依赖项…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

Unity iOS构建报错SDK version is 0的根因与精准修复
1. 这个报错不是Unity在“发脾气”,而是工程配置在“装死”刚接手一个老项目,打开Unity编辑器,点Build Settings准备打包iOS,结果弹出一行红字:“SDK version is 0, cannot build”。我第一反应是——这什么鬼…...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...

什么情况下会核销贷款
贷款核销的核心前提是:贷款被认定为 “损失类” 且经 “穷尽追偿” 仍无法收回,银行按监管与会计规则从账面冲销,但债权不消灭、仍可追偿。一、核心认定条件(满足其一即可)破产 / 注销 / 吊销:借款人和担保…...