【Java 进阶篇】JDBC查询操作详解

在数据库编程中,查询是一项非常常见且重要的操作。JDBC(Java Database Connectivity)提供了丰富的API来执行各种类型的查询操作。本篇博客将详细介绍如何使用JDBC进行查询操作,包括连接数据库、创建查询语句、执行查询、处理结果集等方面的内容。无论你是初学者还是有一定经验的开发者,都可以从中获得有价值的信息。
准备工作
在进行JDBC查询操作之前,我们需要进行一些准备工作:
-
安装数据库驱动程序:首先,确保你已经安装了与你使用的数据库相对应的JDBC驱动程序。不同数据库有不同的JDBC驱动,你需要下载并将其添加到你的项目中。
-
创建数据库:如果还没有数据库,可以使用数据库管理工具(如MySQL Workbench)创建一个数据库,然后在该数据库中创建表格并插入一些数据,以便进行查询操作的演示。
-
导入JDBC库:在Java项目中,你需要导入JDBC库,通常是
java.sql包下的类和接口。
连接数据库
在进行任何数据库操作之前,首先需要建立与数据库的连接。连接数据库是通过Connection对象来完成的。以下是连接到数据库的基本步骤:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;public class JDBCDemo {public static void main(String[] args) {// JDBC连接URL,其中mydatabase是数据库名String jdbcUrl = "jdbc:mysql://localhost:3306/mydatabase";String username = "your_username";String password = "your_password";try {// 创建数据库连接Connection connection = DriverManager.getConnection(jdbcUrl, username, password);// 在此处执行查询操作// 关闭连接connection.close();} catch (SQLException e) {e.printStackTrace();}}
}
在上面的代码中,我们首先指定了数据库的连接URL、用户名和密码。然后,通过DriverManager.getConnection()方法创建了与数据库的连接,并在最后关闭了连接。请替换jdbcUrl、username和password为你自己的数据库信息。
创建查询语句
一旦建立了数据库连接,我们就可以创建查询语句。查询语句是使用Statement或PreparedStatement对象来执行的。这里我们介绍两种常见的创建查询语句的方式。
使用Statement
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;public class JDBCDemo {public static void main(String[] args) {String jdbcUrl = "jdbc:mysql://localhost:3306/mydatabase";String username = "your_username";String password = "your_password";try {Connection connection = DriverManager.getConnection(jdbcUrl, username, password);// 创建Statement对象Statement statement = connection.createStatement();// 在此处执行查询操作// 关闭连接和Statementstatement.close();connection.close();} catch (SQLException e) {e.printStackTrace();}}
}
上述代码中,我们通过connection.createStatement()方法创建了一个Statement对象,它用于执行SQL语句。这种方式适用于静态的SQL查询。
使用PreparedStatement
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;public class JDBCDemo {public static void main(String[] args) {String jdbcUrl = "jdbc:mysql://localhost:3306/mydatabase";String username = "your_username";String password = "your_password";try {Connection connection = DriverManager.getConnection(jdbcUrl, username, password);// 创建PreparedStatement对象,可以使用占位符String sql = "SELECT * FROM students WHERE age > ?";PreparedStatement preparedStatement = connection.prepareStatement(sql);// 设置占位符的值preparedStatement.setInt(1, 18);// 在此处执行查询操作// 关闭连接和PreparedStatementpreparedStatement.close();connection.close();} catch (SQLException e) {e.printStackTrace();}}
}
在上述代码中,我们使用connection.prepareStatement()方法创建了一个PreparedStatement对象,它可以包含占位符。这种方式适用于需要动态生成SQL查询的情况,同时也有助于防止SQL注入攻击。
执行查询
一旦创建了查询语句,我们就可以执行查询操作了。执行查询的方式主要有两种:使用executeQuery()方法执行查询并返回结果集,以及使用executeUpdate()方法执行更新操作。
使用executeQuery()
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;public class JDBCDemo {public static void main(String[] args) {String jdbcUrl = "jdbc:mysql://localhost:3306/mydatabase";String username = "your_username";String password = "your_password";try {Connection connection = DriverManager.getConnection(jdbcUrl, username, password);Statement statement = connection.createStatement();// 执行查询操作,将结果存储在ResultSet对象中String query = "SELECT * FROM students";ResultSet resultSet = statement.executeQuery(query);// 遍历结果集并处理数据while (resultSet.next()) {int id = resultSet.getInt("id");String name = resultSet.getString("name");int age = resultSet.getInt("age");System.out.println("ID: " + id + ", Name: " + name + ", Age: " + age);}// 关闭连接、Statement和ResultSetresultSet.close();statement.close();connection.close();} catch (SQLException e) {e.printStackTrace();}}
}
在上面的代码中,我们使用executeQuery()方法执行了一个查询操作,并将结果存储在ResultSet对象中。然后,我们通过遍历ResultSet来访问查询结果的每一行。
使用executeUpdate()
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;public class JDBCDemo {public static void main(String[] args) {String jdbcUrl = "jdbc:mysql://localhost:3306/mydatabase";String username = "your_username";String password = "your_password";try {Connection connection = DriverManager.getConnection(jdbcUrl, username, password);Statement statement = connection.createStatement();// 执行更新操作,返回受影响的行数String update = "UPDATE students SET age = 20 WHERE id = 1";int rowsAffected = statement.executeUpdate(update);System.out.println("Rows affected: " + rowsAffected);// 关闭连接和Statementstatement.close();connection.close();} catch (SQLException e) {e.printStackTrace();}}
}
在上述代码中,我们使用executeUpdate()方法执行了一个更新操作,例如更新表中的某些数据。它返回受影响的行数,以便我们知道操作的结果。
处理结果集
一旦我们执行了查询操作并获得了结果集,就需要对结果集进行处理。常见的处理方式包括遍历结果集、提取数据以及关闭结果集。
// 遍历结果集并处理数据
while (resultSet.next()) {int id = resultSet.getInt("id");String name = resultSet.getString("name");int age = resultSet.getInt("age");System.out.println("ID: " + id + ", Name: " + name + ", Age: " + age);
}// 提取数据
if (resultSet.next()) {int id = resultSet.getInt("id");String name = resultSet.getString("name");int age = resultSet.getInt("age");
}// 关闭结果集
resultSet.close();
遍历结果集时,我们使用next()方法来移动到结果集的下一行。然后,使用getXXX()方法(例如getInt()、getString())来提取数据。最后,使用close()方法关闭结果集。
异常处理
在进行任何数据库操作时,务必进行异常处理以处理潜在的错误情况。在上述代码示例中,我们使用了try-catch块来捕获SQLException异常,并在异常发生时打印错误信息。
try {// 执行数据库操作
} catch (SQLException e) {e.printStackTrace();
}
这样可以确保在遇到问题时能够及时识别和解决。
总结
本篇博客介绍了如何使用JDBC进行查询操作的基本步骤,包括连接数据库、创建查询语句、执行查询操作和处理结果集。希望这些示例能够帮助你更好地理解和使用JDBC进行数据库查询操作。在实际开发中,你可以根据自己的需求和数据库类型来编写相应代码,来完成自己的需求。
| 作者信息 作者 : 繁依Fanyi CSDN: https://techfanyi.blog.csdn.net 掘金:https://juejin.cn/user/4154386571867191 |
相关文章:
【Java 进阶篇】JDBC查询操作详解
在数据库编程中,查询是一项非常常见且重要的操作。JDBC(Java Database Connectivity)提供了丰富的API来执行各种类型的查询操作。本篇博客将详细介绍如何使用JDBC进行查询操作,包括连接数据库、创建查询语句、执行查询、处理结果集…...

我的企业证书是正常的但是下载应用app到手机提示无法安装“app名字”无法安装此app,因为无法验证其完整性解决方案
我的企业证书是正常的但是下载应用app到手机提示无法安装“app名字”无法安装此app,因为无法验证其完整性解决方案 首先,确保您从可信任的来源下载并安装企业开发者签名过的应用程序。如果您不确定应用程序的来源,建议您联系应用程序提供者…...
【数据结构】排序(2)—冒泡排序 快速排序
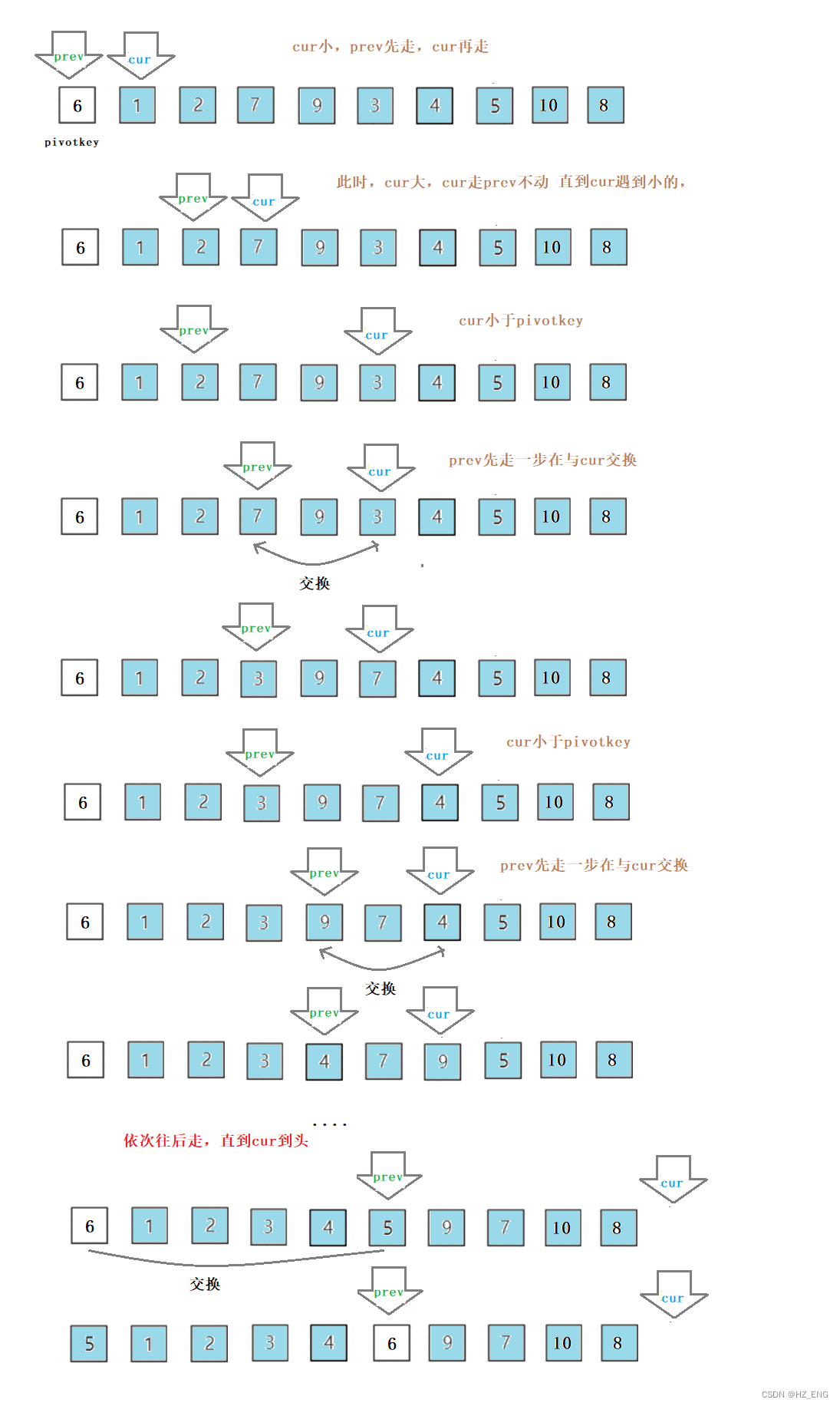
目录 一. 冒泡排序 基本思想 代码实现 时间和空间复杂度 稳定性 二. 快速排序 基本思想 代码实现 hoare法 挖坑法 前后指针法 时间和空间复杂度 稳定性 一. 冒泡排序 基本思想 冒泡排序是一种交换排序。两两比较数组元素,如果是逆序(即排列顺序与排序后…...

Redis与分布式-分布式锁
接上文 Redis与分布式-集群搭建 1.分布式锁 为了解决上述问题,可以利用分布式锁来实现。 重新复制一份redis,配置文件都是刚下载时候的不用更改,然后启动redis服务和redis客户。 redis存在这样的命令:和set命令差不多࿰…...

docker安装nginx详解
创建html的挂载目录docker volume create nginx8020 创建conf的挂载目录mkdir -p /opt/nginx/conf 拉取镜像docker pull nginx 初始化挂载目录的配置文件docker run --rm --name nginx-short -p 8020:80 -d nginx docker cp nginx-short:/etc/nginx/nginx.conf /opt/nginx/…...

优化思考二
优化思考一_云湖在成长的博客-CSDN博客 翻到了两年前写文章,有了不一样的观点。 先说一样的想法吧:数据(输入)>>优化模型(处理)>>结果方案(输出)。优化是其中最重要的…...

大模型微调概览
文章目录 微调 和 高效微调高效微调技术方法概述高效微调方法一:LoRA高效微调方法二: Prefix Tuning高效微调方法三: Prompt Tuning高效微调方法四: P-Tuning v2基于强化学习的进阶微调方法RLHF 训练流程微调 和 高效微调 微调,Fine-Tuning, 一般指全参数的微调(全量微调),…...

利用norm.ppfnorm.interval分别计算正态置信区间[实例]
scipy.stats.norm.ppf用于计算正态分布的累积分布函数CDF的逆函数,也称为百分位点函数。它的作用是根据给定的概率值,计算对应的随机变量值。scipy.stats.norm.interval:用于计算正态分布的置信区间,可指定均值和标准差。scipy.st…...

计算机网络各层设备
计算机网络通常被分为七层,每一层都有对应的设备。以下是各层设备的简要介绍: 物理层(Physical Layer):负责传输二进制数据位流的物理媒体和设备,例如网线、光纤、中继器、集线器等。 数据链路层…...

java this用法
在Java中,this是一个关键字,表示当前对象。它可以用来引用当前对象的实例变量、实例方法或者调用当前对象的构造方法。在本文中,我们将深入探讨Java中this关键字的用法。 1. 引用当前对象的实例变量 在Java中,this关键字可以用来…...

【AI视野·今日NLP 自然语言处理论文速览 第四十六期】Tue, 3 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 3 Oct 2023 (showing first 100 of 110 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Its MBR All the Way Down: Modern Generation Techniques Through the …...

Unity ddx与ddy
有关Unity的dx与dy的概念 引用的文章 1link 2link 3link 4link 有关概念 我们知道在光栅化的时刻,GPUs会在同一时刻并行运行很多Fragment Shader,但是并不是一个pixel一个pixel去执行的,而是将其组织在2x2的一组pixels分块中,…...

bootstrap.xml 和applicaiton.properties和applicaiton.yml的区别和联系
当谈到Spring Boot应用程序的配置时,有三个关键文件经常被提到:bootstrap.xml、application.properties和application.yml。这些文件在应用程序的不同阶段起着不同的作用,并在配置应用程序属性时有一些区别和联系。本文将探讨这些文件的作用、…...
基于被囊群优化的BP神经网络(分类应用) - 附代码
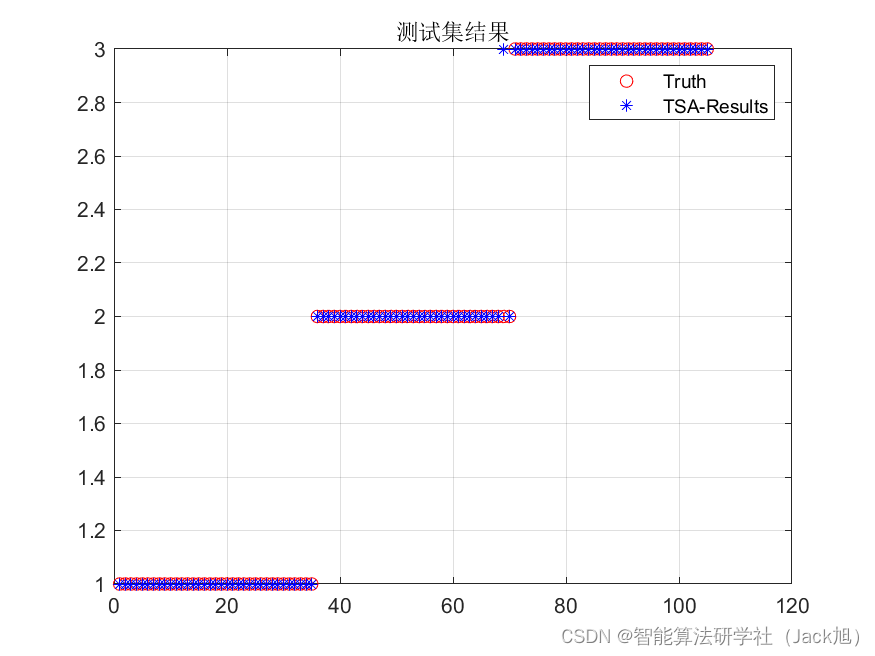
基于被囊群优化的BP神经网络(分类应用) - 附代码 文章目录 基于被囊群优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.被囊群优化BP神经网络3.1 BP神经网络参数设置3.2 被囊群算法应用 4.测试结果&#x…...
我的第一个react.js 的router工程
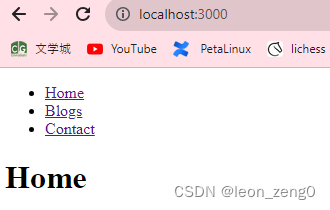
react.js 开发的时候,都是针对一个页面的,多个页面就要用Router了,本文介绍我在vscode 下的第一个router 工程。 我在学习react.js 前端开发,学到router 路由的时候有点犯难了。经过1-2天的努力,终于完成了第一个工程…...

XXPermissions权限请求框架
官网 项目地址:Github博文地址:一句代码搞定权限请求,从未如此简单 框架亮点 一马当先:首款适配 Android 13 的权限请求框架简洁易用:采用链式调用的方式,使用只需一句代码体积感人:功能在同类…...

远程代码执行渗透测试—Server2128
远程代码执行渗透测试 任务环境说明: √ 服务器场景:Server2128(开放链接) √服务器场景操作系统:Windows √服务器用户名:Administrator密码:pssw0rd 1.找出靶机桌面上文件夹1中的文件RCEBac…...

阿里云关系型数据库有哪些?RDS云数据库汇总
阿里云RDS关系型数据库大全,关系型数据库包括MySQL版、PolarDB、PostgreSQL、SQL Server和MariaDB等,NoSQL数据库如Redis、Tair、Lindorm和MongoDB,阿里云百科分享阿里云RDS关系型数据库大全: 目录 阿里云RDS关系型数据库大全 …...

Linux--socket编程--服务端代码
查看struct sockaddr_in包含的东西: 在/user/include下搜索:grep "struct sockaddr_in { " * -nir r : 递归 i : 不区分大小写 n : 显示行号 socket编程–服务端代码 /* 1、调用 socket 创建套接字 2、调用 bind 添加地址 3、lis…...
安装Vue脚手架图文详解教程
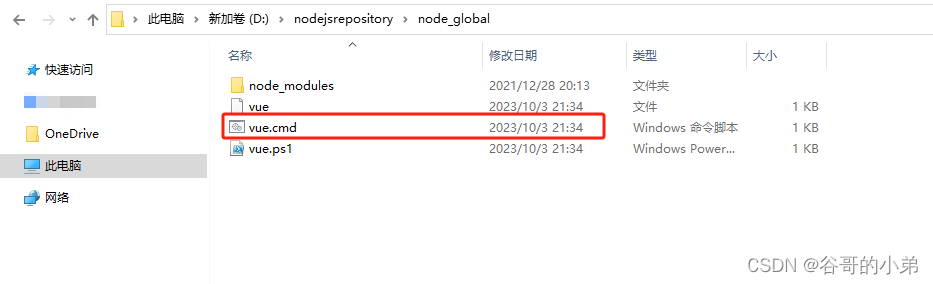
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 预备工作 在安装Vue脚手架之前,请确保您已经正确安装了npm;假若还尚未安装npm,请你参考 Node.js安装教程图文详解。 安装Vue脚手架 请…...

好写作AI:利用多轮人机交互迭代实现深度降AIGC的方法论
改一遍不够?那就改三遍——但每遍都要改对地方很多同学用AI辅助写论文,流程是这样的:用AI生成一段文字 → 觉得“AI味儿”有点重 → 手动改几个词 → 提交。然后被检测系统打回来。于是困惑:我都改了,怎么还是不行&…...

UDS诊断自动化测试入门:用Python模拟Tester端,批量刷写DID与安全访问
UDS诊断自动化测试实战:Python构建高覆盖率ECU测试框架 在汽车电子控制单元(ECU)开发中,诊断功能测试往往是最耗时的手工操作环节之一。想象一下,当需要验证数百个数据标识符(DID)的读写功能时&…...

CVPR 2026 | 全架构通吃!MatchED 插件式模块,CNN/Transformer/扩散模型都能无缝集成
点击上方“小白学视觉”,选择加"星标"或“置顶” 重磅干货,第一时间送达边缘检测是计算机视觉领域的基石任务,从图像分割、深度估计到3D重建,几乎所有高阶视觉任务都依赖精准的边缘信息。但长期以来,一个核心…...

沉浸式翻译扩展常见问题解决方案
沉浸式翻译扩展常见问题解决方案 【免费下载链接】immersive-translate 沉浸式双语网页翻译扩展 , 支持输入框翻译, 鼠标悬停翻译, PDF, Epub, 字幕文件, TXT 文件翻译 - Immersive Dual Web Page Translation Extension 项目地址: https://gitcode.c…...

OpenClaw 深度研究报告:从开源框架到企业级智能体平台的演进之路
一、核心定位:突破"对话天花板"的执行中枢 OpenClaw(外号"龙虾") 是由奥地利工程师 Peter Steinberger 于 2025 年底开发的本地优先、模型无关的 AI 智能体运行框架。其核心价值主张极为鲜明: “The AI that …...

3大创新让OpenRocket成为开源工程工具的典范:从问题到实践的完整指南
3大创新让OpenRocket成为开源工程工具的典范:从问题到实践的完整指南 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket OpenRocket是一款基于Jav…...
)
从键盘敲击到屏幕显示:一个字符在Linux内核里的完整旅程(附C代码模拟)
从键盘敲击到屏幕显示:一个字符在Linux内核里的完整旅程 当你在终端敲下字母"A"时,这个简单的动作背后隐藏着一场跨越硬件、内核和用户空间的精密协作。让我们跟随这个字符的脚步,揭开Linux系统如何处理键盘输入的神秘面纱。 1. …...

掌握TegraRcmGUI:从入门到精通的Switch注入实践指南
掌握TegraRcmGUI:从入门到精通的Switch注入实践指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是一款基于C开发的图形化界面工具…...

Linux环境下Python段错误全解析:从内存管理到线程安全的避坑手册
Linux环境下Python段错误全解析:从内存管理到线程安全的避坑手册 当你在深夜调试一个复杂的Python项目时,突然看到屏幕上跳出"Segmentation fault (core dumped)"的提示,那种感觉就像在高速公路上爆胎——明明代码逻辑看起来没问题…...

eNSP安装避坑指南:WinPcap/Wireshark/VirtualBox依赖关系解析
eNSP安装避坑指南:WinPcap/Wireshark/VirtualBox依赖关系解析 当你第一次打开eNSP安装包时,可能会疑惑为什么需要同时安装WinPcap、Wireshark和VirtualBox这三个看似不相关的软件。这就像组装一台精密仪器——少了任何一个螺丝,整台机器都无法…...