Python中匹配模糊的字符串
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取
如何使用thefuzz 库,它允许我们在python中进行模糊字符串匹配。
此外,我们将学习如何使用process 模块,该模块允许我们在模糊字符串逻辑的帮助下有效地匹配或提取字符串。
使用thefuzz 模块来匹配模糊字符串
这个库在旧版本中有一个有趣的名字,因为它有一个特定的名字,这个名字被重新命名。
所以现在是由不同的库来维护;但是,它目前的版本叫做thefuzz ,所以这就是你可以通过下面的命令来安装的。
pip install thefuzz
但是,如果你在网上看例子,你会发现一些例子的旧名称是fuzzywuzzy 。所以,它已经不再被维护并且过时了,但是你可能会发现一些用这个名字的例子。
thefuzz 库是基于 ,所以你必须用这个命令来安装它。python-Levenshtei
pip install python-Levenshtein
而如果你在安装过程中遇到一些问题,你可以使用下面的命令,如果再次遇到错误,那么你可以在google上搜索,找到相关的解决方案。
pip install python-Levenshtein-wheels
本质上,模糊匹配字符串就像使用regex或沿着两个字符串的比较。
在模糊逻辑的情况下,你的条件的真值可以是0 和1 之间的任何实数。
因此,基本上,不是说任何东西是True 或False ,你只是给它在0 到1 之间的任何值。
它是通过使用距离度量计算两个字符串之间的不相似性,其形式是一个称为距离的值。
使用给定的字符串,你使用一些算法找到两个字符串之间的距离。一旦你完成了安装过程,你必须从thefuzz 模块中导入fuzz 和process 。
from thefuzz import fuzz, process
在使用fuzz ,我们将手动检查两个字符串之间的不相似性。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
ST1='Just a test'
ST2='just a test'
print(ST1==ST2)
print(ST1!=ST2)
它将返回一个布尔值,但以一种模糊的方式,你会得到这些字符串的相似程度的百分数。
False
True
模糊字符串匹配允许我们以模糊的方式更有效、更快速地完成这项工作。假设我们有一个例子,有两个字符串,其中一个字符串与大写的J (如上所述)不相同。
如果我们现在去调用ratio() 函数,它给我们一个相似性的度量,那么这将为我们提供一个相当高的比率,即91 ,而不是100 。
from thefuzz import fuzz, process
print(fuzz.ratio(ST1, ST2))
输出:
91
如果字符串更加延长,例如,如果我们不只是改变一个字符,而是改变一个完全不同的字符串,那么看看它的回报,看一看。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
ST1='This is a test string for test'
ST2='There aresome test string for testing'
print(fuzz.ratio(ST1,ST2))
现在可能会有一些相似之处,但会很75 ;这只是一个简单的比率,并不复杂。
75
我们还可以继续尝试像部分比例这样的东西。例如,我们有两个字符串,我们想确定它们的分数。
ST1='There are test'
ST2='There are test string for testing'
print(fuzz.partial_ratio(ST1,ST2))
使用partial_ratio() ,我们会得到100%,因为这两个字符串有相同的子字符串(There are test)。
在ST2 ,我们有一些不同的词(字符串),但这并不重要,因为我们看的是部分比率或个别部分,但简单的比率并不类似。
100
假设我们有相似的字符串,但有不同的顺序;然后,我们使用另一个度量。
CASE_1='This generation rules the nation'
CASE_2='Rules the nation This generation'
两种情况下,在该短语的相同含义上有完全相同的文字,但使用ratio() ,就会有相当大的不同,而使用partial_ratio() ,就会有不同。
如果我们通过token_sort_ratio() ,这将是100%,因为它基本上是完全相同的文字,但顺序不同。
因此,这就是token_sort_ratio() ,该函数将单个标记进行排序,它们的顺序并不重要。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
print(fuzz.ratio(CASE_1,CASE_2))
print(fuzz.partial_ratio(CASE_1,CASE_2))
print(fuzz.token_sort_ratio(CASE_1,CASE_2))
输出:
47
64
100
现在,如果我们用另一个词来改变一些词,我们会有一个不同的数字,但基本上,这是一个比率;
它不关心个别标记的顺序。
CASE_1='This generation rules the nation'
CASE_2='Rules the nation has This generation'
print(fuzz.ratio(CASE_1,CASE_2))
print(fuzz.partial_ratio(CASE_1,CASE_2))
print(fuzz.token_sort_ratio(CASE_1,CASE_2))
输出:
44
64
94
token_sort_ratio() 也是不同的,因为它有更多的词在里面,但我们也有一个叫做token_set_ratio() 的东西,一个集合包含每个标记只有一次。
所以,它出现的频率并不重要;让我们看看一个例子字符串。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
CASE_1='This generation'
CASE_2='This This generation generation generation generation'
print(fuzz.ratio(CASE_1,CASE_2))
print(fuzz.partial_ratio(CASE_1,CASE_2))
print(fuzz.token_sort_ratio(CASE_1,CASE_2))
print(fuzz.token_set_ratio(CASE_1,CASE_2))
我们可以看到一些相当低的分数,但是我们使用token_set_ratio() 函数得到了100%的分数,因为我们有两个令牌,This 和generation 存在于两个字符串中。
使用process 模块,以高效的方式使用模糊字符串匹配
不仅有fuzz ,还有process ,因为process 是有帮助的,可以使用这种模糊匹配从一个集合中提取出来。
例如,我们准备了几个列表项来演示。
Diff_items=['programing language','Native language','React language','People stuff', 'This generation', 'Coding and stuff']
其中一些是非常相似的,你可以看到(母语或编程语言),现在我们可以去挑选最好的个别匹配。
我们可以手动操作,只需评估分数,然后挑选出最优秀的人选,但我们也可以用process 。
要做到这一点,我们必须调用process 模块中的extract() 函数。
它需要几个参数,第一个是目标字符串,第二个是你要提取的集合,第三个是限制,将匹配或提取的内容限制为两个。
例如,如果我们想提取像language ,在这种情况下,选择母语和编程语言。
print(process.extract('language',Diff_items,limit=2))
输出:
[('programing language', 90), ('Native language', 90)]
问题是:
-
这不是NLP(自然语言处理);
-
这背后没有智能;
-
它只是看单个标记。
因此,举例来说,如果我们使用programming 作为目标字符串并运行这个。
第一个匹配将是programming language ,但第二个匹配将是Native language ,这将不是编码。
即使我们有编码,因为从语义上讲,编码更接近于编程,但这并不重要,因为我们在这里没有使用AI。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
Diff_items=['programing language','Native language','React language','People stuff', 'Hello World', 'Coding and stuff']
print(process.extract('programing',Diff_items,limit=2))
输出:
[('programing language', 90), ('Native language', 36)]
另一个最后的例子是这是如何有用的;
我们有一个庞大的书库,想找到一本书,但我们不知道确切的名字或如何调用它。
在这种情况下,我们可以使用extract() ,在这个函数里面,我们将把fuzz.token_sort_ratio 传给scorer 参数。
LISt_OF_Books=['The python everyone volume 1 - Beginner','The python everyone volume 2 - Machine Learning','The python everyone volume 3 - Data Science','The python everyone volume 4 - Finance','The python everyone volume 5 - Neural Network','The python everyone volume 6 - Computer Vision','Different Data Science book','Java everyone beginner book','python everyone Algorithms and Data Structure']
print(process.extract('python Data Science',LISt_OF_Books,limit=3,scorer=fuzz.token_sort_ratio))
我们只是传递它,我们并没有调用它,现在,我们在这里得到了最高的结果,我们得到了另一本数据科学书作为第二个结果。
输出:
[('The python everyone volume 3 - Data Science', 63), ('Different Data Science book', 61), ('python everyone Algorithms and Data Structure', 47)]
这就是如何是相当准确的,如果你有一个项目,你必须以模糊的方式找到它,它可以相当有帮助。
我们也可以用它来实现你的程序自动化。
还有一些额外的资源,你可以使用github和stackoverflow找到更多帮助。
尾语
最后感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。

相关文章:
Python中匹配模糊的字符串
嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 如何使用thefuzz 库,它允许我们在python中进行模糊字符串匹配。 此外,我们将学习如何使用process 模块,该模块允许我们在模糊…...
PHP图片文件管理功能系统源码
文件图库管理单PHP源码直接解压就能用,单文件,indexm.php文件可以重新命名,上传到需要访问的目录中, 可以查看目录以及各个文件,图片等和下载及修改管理服务。 源码下载:https://download.csdn.net/downloa…...

(枚举 + 树上倍增)Codeforces Round 900 (Div. 3) G
Problem - G - Codeforces 题意: 思路: 首先,目标值和结点权值是直接联系的,最值不可能直接贪心,一定是考虑去枚举一些东西,依靠这种枚举可以遍历所有的有效情况,思考的方向一定是枚举 如果去…...
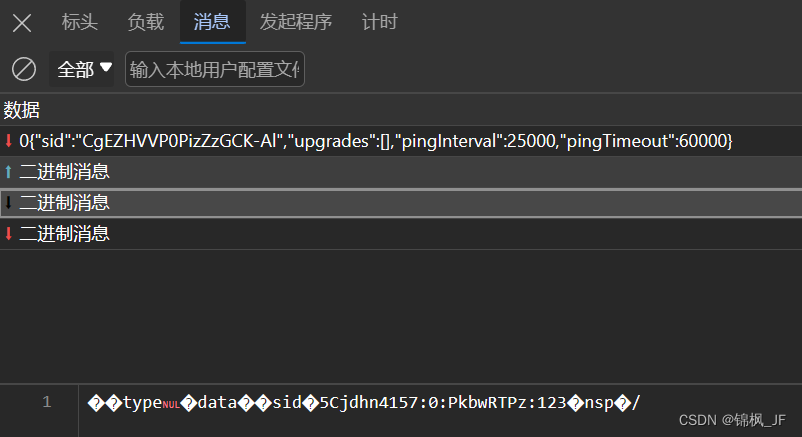
websocket逆向【python实现websocket拦截】
python实现websocket拦截 前言一、拦截的优缺点优点:缺点:二、实现方法1.环境配置2.代码三、总结前言 开发者工具F12,筛选ws后,websocket的消息是这样显示的,如何获取这里面的消息呢? 以下是本篇文章正文内容 一、拦截的优缺点 主要讲解一下websocket拦截的实现,现在…...

软件测试自动化的成本效益分析
随着软件测试技术的发展,人们已经从最初的手工测试转变为手工和自动化技术相结合的测试方法。目前,人们更多的是关心自动化测试框架、自动化测试工具以及脚本研究等技术方面,而在软件自动化测试方案的效益分析方面涉及较少。 软件测试的目的是…...

【Java】状态修饰符 final static
目录 final 修饰我们的成员方法、成员变量、类 示例代码: final 修饰的局部变量 示例代码: static 示例代码: static 访问特点: 示例代码: static关键字的用途 示例代码: static 修饰常量 示例…...

笔试编程ACM模式JS(V8)、JS(Node)框架、输入输出初始化处理、常用方法、技巧
目录 考试注意事项 先审完题意,再动手 在本地编辑器(有提示) 简单题515min 通过率0%,有额外log 常见输入处理 str-> num arr:line.split( ).map(val>Number(val)) 初始化数组 new Array(length).fill(v…...
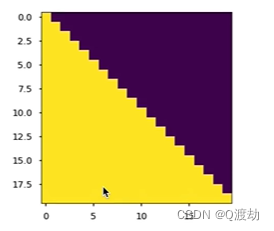
learn掩码张量
目录 1、什么是掩码张量 2、掩码张量的作用 3、代码演示 (1)、定义一个上三角矩阵,k0或者 k默认为 0 (2)、k1 (3)、k-1 4、掩码张量代码实现 (1)、输出效果 &…...
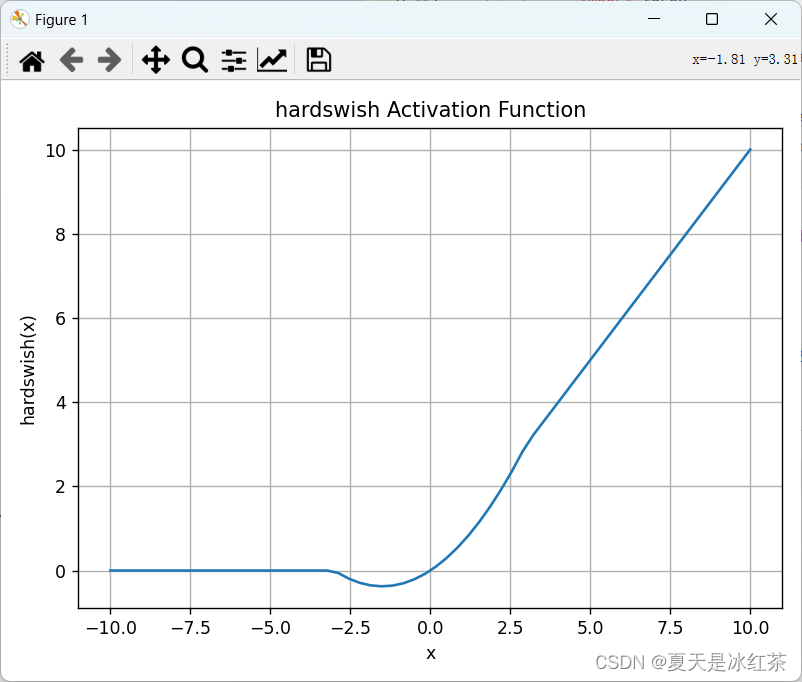
激活函数介绍
介绍 神经网络当中的激活函数用来提升网络的非线性,以增强网络的表征能力。它有这样几个特点:有界,必须为非常数,单调递增且连续可求导。我们常用的有sigmoid或者tanh,但我们都知道这两个都存在一定的缺点,…...
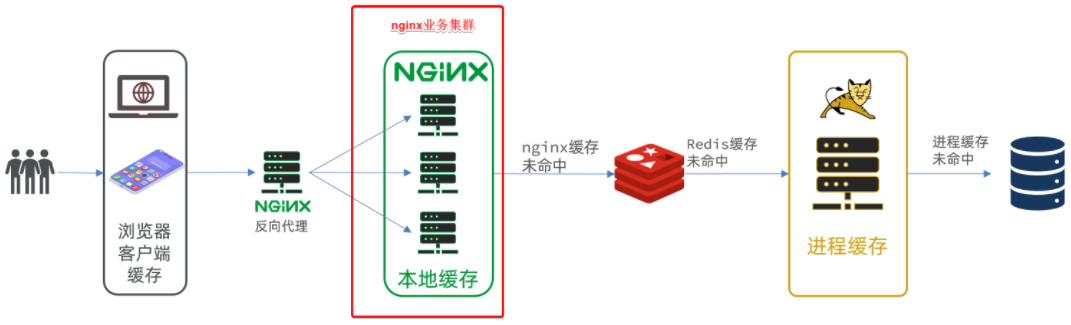
docker方式启动一个java项目-Nginx本地有代码,并配置反向代理
文章目录 案例导入说明1.安装MySQL1.1.准备目录1.2.运行命令1.3.修改配置1.4.重启 2.导入SQL3.导入Demo工程3.1.分页查询商品(仔细看代码,很多新的MP编程技巧)3.2.新增商品3.3.修改商品3.4.修改库存3.5.删除商品3.6.根据id查询商品3.7.根据id…...

前端和后端是Web开发选哪个好?
前端和后端是Web开发中的两个不同的领域,哪一种更适合学习?前景更广呢? 一、引言 Web前端开发就像装饰房间的小瓦匠,勤勤恳恳,仔仔细细,粉饰墙壁,妆点家具。会 HTML,CSS,懂点 JS。…...

HTTP协议,请求响应
、概述 二、HTTP请求协议 三、HTTP响应协议 四、请求数据 1.简单实体参数 RequestMapping("/simpleParam")public String simpleParam(RequestParam(name "name" ,required false ) String username, Integer age){System.out.println (username "…...
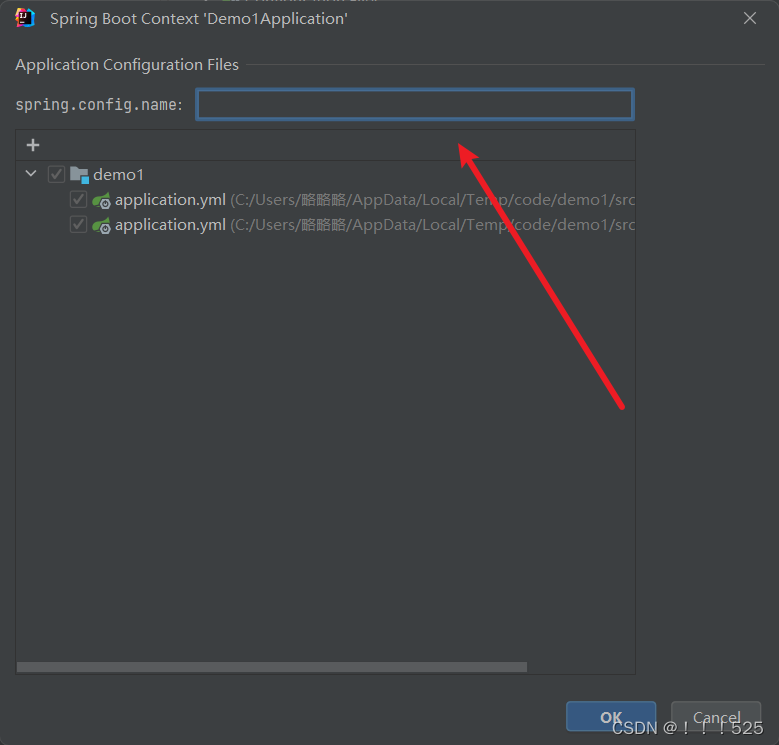
idea配置文件属性提示消息解决方案
在项目文件路径下找到你没有属性提示消息的文件 选中,ok即可 如果遇到ok无法确认的情况: 在下图所示位置填写配置文件名称即可...

EdgeView 4 for Mac:重新定义您的图像查看体验
您是否厌倦了那些功能繁杂、操作复杂的图像查看器?您是否渴望一款简单、快速且高效的工具,以便更轻松地浏览和管理您的图像库?如果答案是肯定的,那么EdgeView 4 for Mac将是您的理想之选! EdgeView 4是一款专为Mac用户…...
的好处有哪些?)
流程自动化(RPA)的好处有哪些?
流程自动化(RPA)是一种通过软件机器人实现业务流程自动化的技术。它可以模拟人类在计算机上执行的操作,从而自动化重复性、繁琐的任务,提高工作效率和准确性。流程自动化(RPA)的好处很多,下面我…...

医学影像系统【简称PACS】源码
PACS(Picture Archiving and Comuniations Systems)即PACS,图像存储与传输系统,是应用于医院中管理医疗设备如CT,MR等产生的医学图像的信息系统。目标是支持在医院内部所有关于图像的活动,集成了医疗设备,图像存储和分…...

大家都在用哪些敏捷开发项目管理软件?
敏捷开发是一种以人为核心、迭代、循序渐进的开发方法。 敏捷开发的特点是高度灵活性和适应性、迭代式开发。 敏捷开发方法强调快速响应变化,因此它具有高度的灵活性和适应性。开发团队可以根据客户需求和市场变化快速调整开发计划和产品功能,以确保产品…...

python机器学习基础教程01-环境搭建
书籍源代码 github上源代码 https://github.com/amueller/introduction_to_ml_with_python 安装anaconda虚拟环境 创建虚拟环境 conda create -p E:\Python\envs\mlstupy35 python3.5 # 激活环境 conda activate E:\Python\envs\mlstupy35 # 创建学习目录 cd G:\Python\ml…...

TinyWebServer学习笔记-Config
为了弄清楚具体的业务逻辑,我们直接从主函数开始看源代码: #include "config.h"int main(int argc, char *argv[]) {//需要修改的数据库信息,登录名,密码,库名string user "root";string passwd "root";string databas…...

数据结构与算法--算法
这里写目录标题 线性表顺序表链表插入删除算法 一级目录二级目录二级目录二级目录 一级目录二级目录二级目录二级目录 一级目录二级目录二级目录二级目录 一级目录二级目录二级目录二级目录 线性表 顺序表 链表 插入删除算法 步骤 1.通过循环到达指定位置的前一个位置 2.新建…...
lambda表达式、function、bind)
C++11(三)lambda表达式、function、bind
一、lambda 1. lambda表达式语法 lambda表达式本质是一个匿名函数对象(这个原理部分会讲到),不过与普通函数只能定义在全局或类内部不同,它可以直接定义在函数内部。lambda表达式格式: 代码语言:javascr…...

Windows on ARM:从技术预言到生态重塑的十年架构演进
1. 项目概述:一次重塑计算格局的“联姻”2010年,当业界还在消化Windows 7带来的变化时,一则关于“Windows 8将支持ARM架构”的传闻,在半导体和操作系统领域投下了一颗重磅炸弹。这不仅仅是关于一个新操作系统的功能更新࿰…...

修复肝衰竭的“免疫刹车”:ANXA1是控制炎症失控、促进消退的关键内源信号
慢加急性肝衰竭(ACLF)的发病进程主要由全身性炎症反应及免疫功能紊乱共同驱动,其病理机制复杂且临床预后较差。2026年4月,浙江大学与斯坦福大学,在Hepatology期刊在线发表了题为“Dissecting the liver inflammation e…...

近屿AI学:产品经理转AI开发,开局20K
许知言(化名)做过B端产品经理,也有悉尼大学硕士背景。听起来,她本可以继续走产品路线。但AI开始快速改变产品形态后,她心里一直有个问题:如果未来的产品经理不懂AI开发,会不会很快被甩开&#x…...

【负荷预测】基于LSTM-KAN的负荷预测研究附Python代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

流式Markdown解析器:实现实时渲染与性能优化的核心技术
1. 项目概述:一个实时渲染的Markdown流式解析器如果你经常需要处理动态生成的Markdown内容,比如从API接口实时获取、从数据库流式读取,或者构建一个支持用户边输入边预览的编辑器,那你一定遇到过这样的痛点:传统的Mark…...

扰动补偿自触发MPC控制器设计【附代码】
✨ 长期致力于永磁同步电机、模型预测控制、扰动补偿、死区时间优化、自触发控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于预测误差驱动的扰…...

3PEAK思瑞浦 TP2272-SO1R SOP8 精密运放
特性 增益带宽积:7MHz 高斜率:20V/us 宽电源范围:3.1V至36V或2.25V至18V 低失调电压:0.5mV(最大值) 低输入偏置电流:30pA(典型值) 轨到轨输出电压范围 单位增益稳定: 工作温度范围:-40C至125C...

无人机+点云+Civil3D:无控制点场景下的高精度土方算量实战
1. 无人机航测在复杂地形土方算量中的优势 石头山这类复杂地形一直是工程测绘的难点。传统全站仪测量需要测绘人员翻山越岭布设控制点,不仅效率低下,还存在安全隐患。而无人机航测就像给工程装上了"天眼",特别适合解决这类难题。 去…...

如何用ComfyUI MixLab插件重塑你的AI创作流程:5个颠覆性应用场景
如何用ComfyUI MixLab插件重塑你的AI创作流程:5个颠覆性应用场景 【免费下载链接】comfyui-mixlab-nodes Workflow-to-APP、ScreenShare&FloatingVideo、GPT & 3D、SpeechRecognition&TTS 项目地址: https://gitcode.com/gh_mirrors/co/comfyui-mixla…...