docker方式启动一个java项目-Nginx本地有代码,并配置反向代理
文章目录
- 案例导入说明
- 1.安装MySQL
- 1.1.准备目录
- 1.2.运行命令
- 1.3.修改配置
- 1.4.重启
- 2.导入SQL
- 3.导入Demo工程
- 3.1.分页查询商品(仔细看代码,很多新的MP编程技巧)
- 3.2.新增商品
- 3.3.修改商品
- 3.4.修改库存
- 3.5.删除商品
- 3.6.根据id查询商品
- 3.7.根据id查询库存
- 3.8.启动
- 4.导入商品查询页面
- 4.1.运行nginx服务
- 4.2.反向代理
案例导入说明
导入一个现成的IDEA项目工程,但是利用Docker从0开始配置环境,最终达到项目成功运行的目的
此外,我们导入的是一个商品管理的案例,其中包含商品的CRUD功能。我们将来会给查询商品添加多级缓存。
也即本项目可以用于演示多级缓存。
1.安装MySQL
后期做数据同步需要用到MySQL的主从功能,所以需要在虚拟机中,利用Docker来运行一个MySQL容器。
1.1.准备目录
为了方便后期配置MySQL,我们先准备两个目录,用于挂载容器的数据和配置文件目录:
# 进入/tmp目录
cd /tmp
# 创建文件夹
mkdir mysql
# 进入mysql目录
cd mysql
1.2.运行命令
进入mysql目录后,执行下面的Docker命令:
注意之前别忘了先启动docker
systemctl start docker
docker run \-p 3306:3306 \--name mysql \-v $PWD/conf:/etc/mysql/conf.d \-v $PWD/logs:/logs \-v $PWD/data:/var/lib/mysql \-e MYSQL_ROOT_PASSWORD=1234 \--privileged \-d \mysql:5.7.25
docker run创建一个新容器,并运行他
--name给容器取个名字 (此处给容器取名就叫mysql)
-d后面接一个镜像名称 表示根据哪个镜像创建新容器
-p 宿主机端口:容器端口隔离容器配置绑定端口,否则访问不了
-v 本地目录:容器内的目录本地数据卷挂载到容器内的数据卷上
1.3.修改配置
在/tmp/mysql/conf目录添加一个my.cnf文件,作为mysql的配置文件:
# 创建文件
touch /tmp/mysql/conf/my.cnf
文件的内容如下:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
1.4.重启
配置修改后,必须重启容器:
docker restart mysql上面给容器取了名字的好处,这里可以直接使用name启动容器,而非容器id(需要docker ps 或者docker ps -a查一下,比较麻烦)
注意是docker start 不是docker run(创建并运行容器)
查看:
docker ps --format "table {{.ID}}\t{{.Names}}\t{{.Image}}\t{{.Status}}"
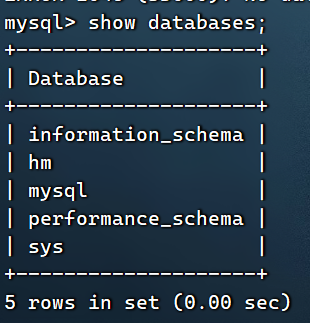
进入容器登陆看看:docker exec -it mysql bash mysql -uroot -p1234 show databases;
宿主机无法直接登陆mysql,做了隔离了,找不到该进程:



2.导入SQL
接下来,利用Navicat客户端连接MySQL,然后导入资料提供的sql文件:
链接:https://pan.baidu.com/s/1dv6ydcwaum3tXRnqmCNxmA
提取码:hzan
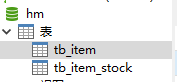
其中包含两张表:
- tb_item:商品表,包含商品的基本信息
- tb_item_stock:商品库存表,包含商品的库存信息
之所以将库存分离出来,是因为库存是更新比较频繁的信息,写操作较多。而其他信息修改的频率非常低。
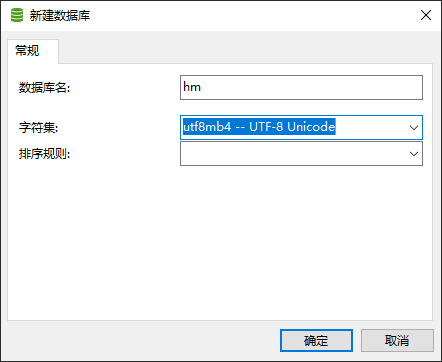
- 先创建数据库
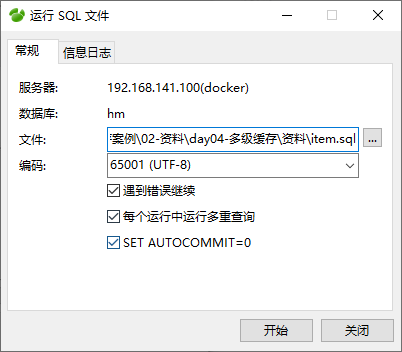
- 导入数据
3.导入Demo工程
下面导入资料提供的工程:
项目结构如图所示:
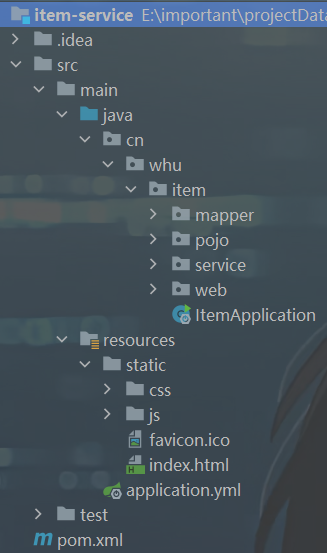
其中的业务包括:
- 分页查询商品
- 新增商品
- 修改商品
- 修改库存
- 删除商品
- 根据id查询商品
- 根据id查询库存
业务全部使用mybatis-plus来实现,如有需要请自行修改业务逻辑。
3.1.分页查询商品(仔细看代码,很多新的MP编程技巧)
在cn.whu.item.web包的ItemController中可以看到接口定义:
@GetMapping("list")
public PageDTO queryItemPage(@RequestParam(value = "page", defaultValue = "1") Integer page,@RequestParam(value = "size", defaultValue = "5") Integer size){// 一般名称不一致或者需要设置默认值时,才需要用到@RequestParam注解// 此注解是接受url参数的 value是前端的name值,映射到后面变量里面 (一般name和形参名不一致时才需要指定)// 当然,还可以设置默认值 如此处的defaultValue// 分页查询商品Page<Item> result = itemService.query() //用query方法,链式编程,好处:不用写lambda条件了.ne("status", 3).page(new Page<>(page, size));// 查询库存List<Item> list = result.getRecords().stream().peek(item -> {ItemStock stock = stockService.getById(item.getId());item.setStock(stock.getStock());item.setSold(stock.getSold());//库存和余量在另一张表 需要一个个查出来然后设置}).collect(Collectors.toList());// 封装返回return new PageDTO(result.getTotal(), list);
}
3.2.新增商品
在cn.whu.item.web包的ItemController中可以看到接口定义:

3.3.修改商品
在cn.whu.item.web包的ItemController中可以看到接口定义:

3.4.修改库存
在cn.whu.item.web包的ItemController中可以看到接口定义:

3.5.删除商品
在cn.whu.item.web包的ItemController中可以看到接口定义:
逻辑删除,修改状态为3 (MP内部有这个机制呀,这里竟然没用)

这里是采用了逻辑删除,将商品状态修改为3
3.6.根据id查询商品
在cn.whu.item.web包的ItemController中可以看到接口定义:

这里只返回了商品信息,不包含库存
3.7.根据id查询库存
在cn.whu.item.web包的ItemController中可以看到接口定义:

3.8.启动
注意修改application.yml文件中配置的mysql地址信息:
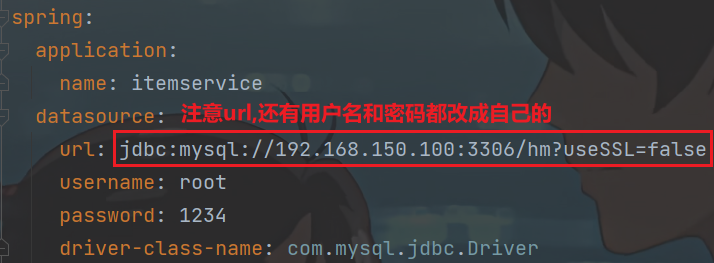
需要修改为自己的虚拟机地址信息、还有账号和密码。
修改后,启动服务,访问:http://localhost:8081/item/10001即可查询数据
- 完整Controller代码
package cn.whu.item.web;import cn.whu.item.service.IItemService;
import cn.whu.item.service.IItemStockService;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import cn.whu.item.pojo.Item;
import cn.whu.item.pojo.ItemStock;
import cn.whu.item.pojo.PageDTO;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;import java.util.List;
import java.util.stream.Collectors;@RestController
@RequestMapping("item")
public class ItemController {@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;@GetMapping("list")public PageDTO queryItemPage(@RequestParam(value = "page", defaultValue = "1") Integer page,@RequestParam(value = "size", defaultValue = "5") Integer size){// 一般名称不一致或者需要设置默认值时,才需要用到@RequestParam注解// 此注解是接受url参数的 value是前端的name值,映射到后面变量里面 (一般name和形参名不一致时才需要指定)// 当然,还可以设置默认值 如此处的defaultValue// 分页查询商品Page<Item> result = itemService.query() //用query方法,链式编程,好处:不用写lambda条件了.ne("status", 3).page(new Page<>(page, size));// 查询库存List<Item> list = result.getRecords().stream().peek(item -> {ItemStock stock = stockService.getById(item.getId());item.setStock(stock.getStock());item.setSold(stock.getSold());//库存和余量在另一张表 需要一个个查出来然后设置}).collect(Collectors.toList());// 封装返回return new PageDTO(result.getTotal(), list);}@PostMappingpublic void saveItem(@RequestBody Item item){itemService.saveItem(item);}@PutMappingpublic void updateItem(@RequestBody Item item) {itemService.updateById(item);}@PutMapping("stock")public void updateStock(@RequestBody ItemStock itemStock){stockService.updateById(itemStock);}@DeleteMapping("/{id}")public void deleteById(@PathVariable("id") Long id){itemService.update().set("status", 3).eq("id", id).update();}@GetMapping("/{id}")public Item findById(@PathVariable("id") Long id){return itemService.query().ne("status", 3).eq("id", id).one();}@GetMapping("/stock/{id}")public ItemStock findStockById(@PathVariable("id") Long id){return stockService.getById(id);}
}4.导入商品查询页面
商品查询是购物页面,与商品管理的页面是分离的。
部署方式如图:
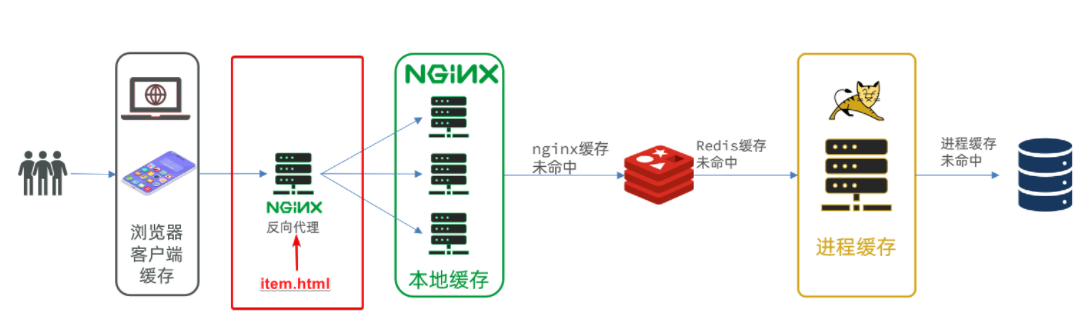
我们需要准备一个反向代理的nginx服务器,如上图红框所示,将静态的商品页面放到nginx目录中。
页面需要的数据通过ajax向服务端(nginx业务集群)查询。
4.1.运行nginx服务
这里直接使用资料中准备好了的nginx反向代理服务器和静态资源。
链接:https://pan.baidu.com/s/1dv6ydcwaum3tXRnqmCNxmA
提取码:hzan
找到资料的nginx目录:

将其拷贝到一个非中文无空格的目录下,运行这个nginx服务。
运行命令:
start nginx.exe
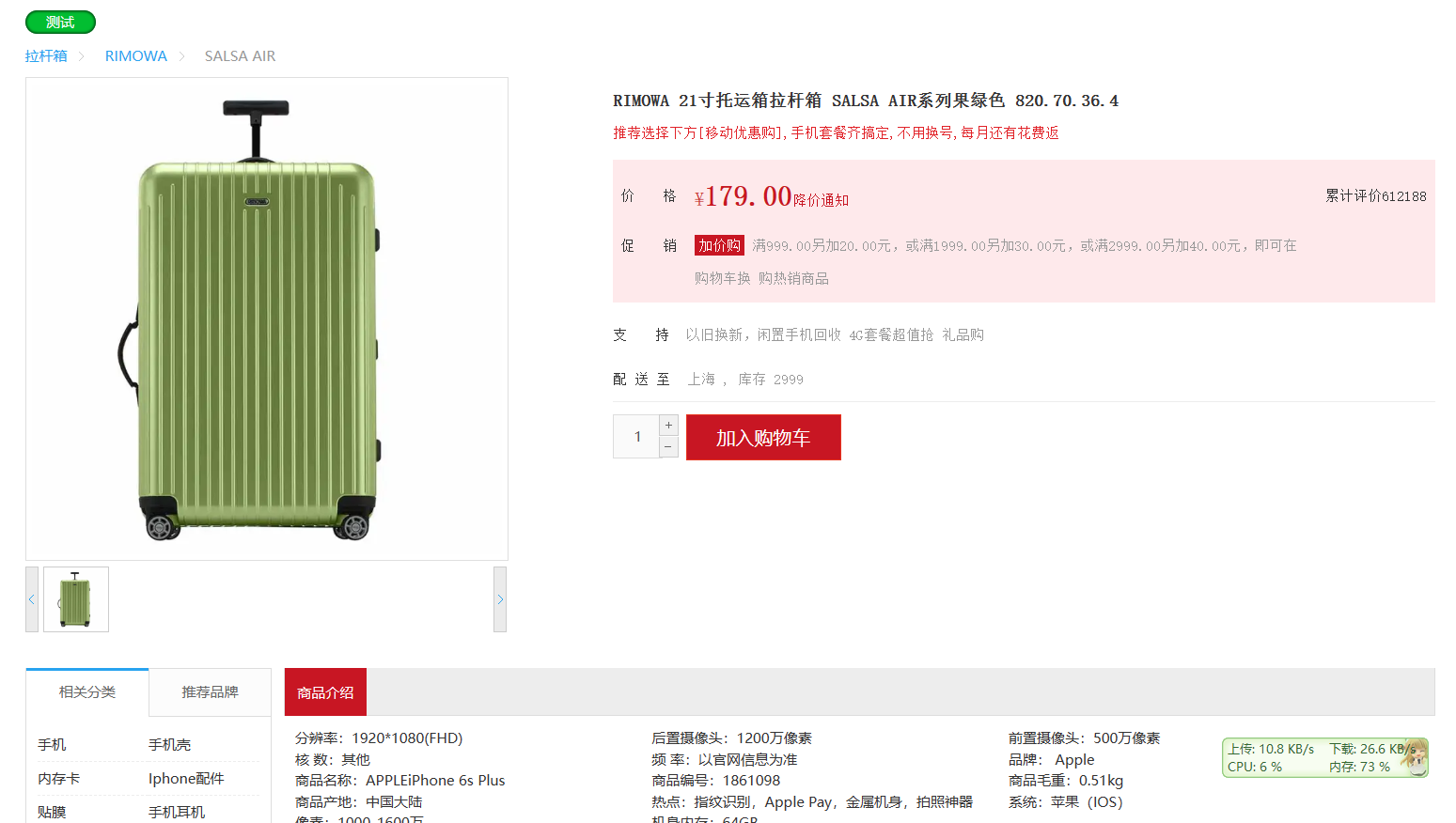
然后访问 http://localhost/item.html?id=10001即可:
4.2.反向代理
现在,页面是假数据展示的。我们需要向服务器发送ajax请求,查询商品数据。
打开控制台,可以看到页面有发起ajax查询数据:
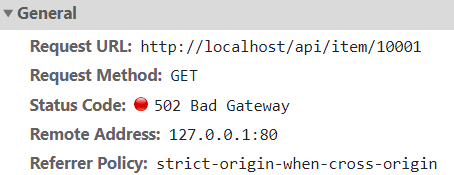
而这个请求地址同样是80端口,所以被当前的nginx反向代理了。
http://localhost/api/item/10002其中的api一看就知道是nginx.conf里配置的反向代理规则
查看nginx的conf目录下的nginx.conf文件:
其中的关键配置如下:
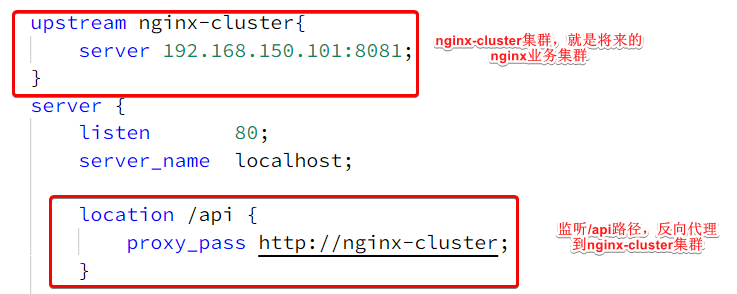
监听80端口,以/api开头的请求
其中的192.168.150.101是我的虚拟机IP,也就是我的Nginx业务集群要部署的地方:
若你的不一样,如:192.168.141.100 , 手动修改一下
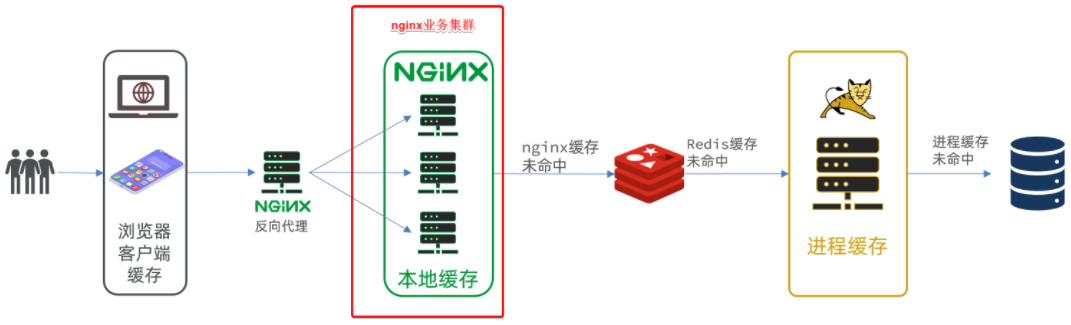
完整内容如下:
#user nobody;
worker_processes 1;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;sendfile on;#tcp_nopush on;keepalive_timeout 65;#nginx的业务集群,集群里可以做:nginx本地缓存、redis缓存、tomcat查询upstream nginx-cluster{server 192.168.141.100:8081;server 192.168.141.100:8082;}server {listen 80;server_name localhost;location /api {proxy_pass http://nginx-cluster;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}
环境都准备好啦,接下来实现nginx集群(部署到linux端)(然后windows端一个nginx做反向代理即可)
相关文章:
docker方式启动一个java项目-Nginx本地有代码,并配置反向代理
文章目录 案例导入说明1.安装MySQL1.1.准备目录1.2.运行命令1.3.修改配置1.4.重启 2.导入SQL3.导入Demo工程3.1.分页查询商品(仔细看代码,很多新的MP编程技巧)3.2.新增商品3.3.修改商品3.4.修改库存3.5.删除商品3.6.根据id查询商品3.7.根据id…...

前端和后端是Web开发选哪个好?
前端和后端是Web开发中的两个不同的领域,哪一种更适合学习?前景更广呢? 一、引言 Web前端开发就像装饰房间的小瓦匠,勤勤恳恳,仔仔细细,粉饰墙壁,妆点家具。会 HTML,CSS,懂点 JS。…...

HTTP协议,请求响应
、概述 二、HTTP请求协议 三、HTTP响应协议 四、请求数据 1.简单实体参数 RequestMapping("/simpleParam")public String simpleParam(RequestParam(name "name" ,required false ) String username, Integer age){System.out.println (username "…...
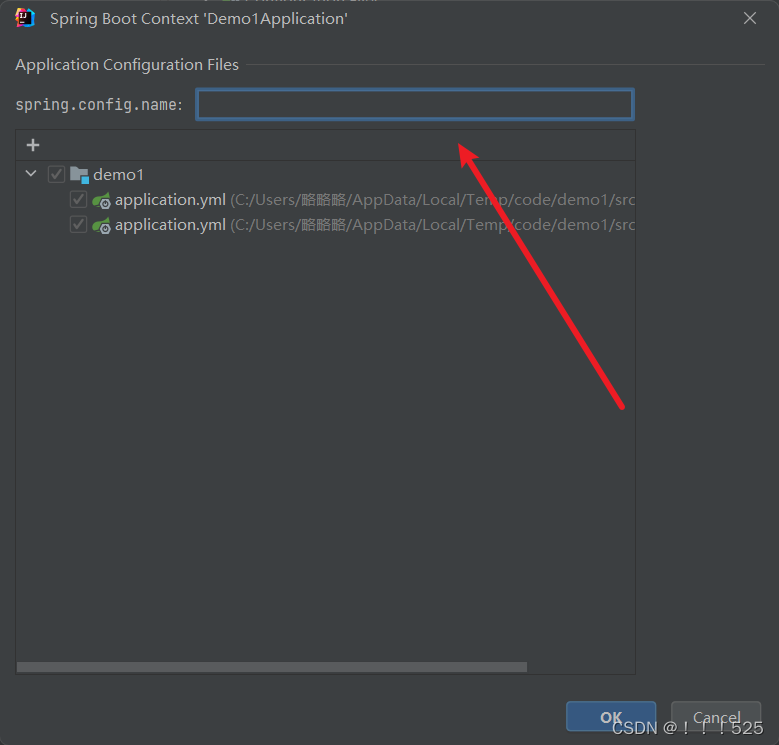
idea配置文件属性提示消息解决方案
在项目文件路径下找到你没有属性提示消息的文件 选中,ok即可 如果遇到ok无法确认的情况: 在下图所示位置填写配置文件名称即可...

EdgeView 4 for Mac:重新定义您的图像查看体验
您是否厌倦了那些功能繁杂、操作复杂的图像查看器?您是否渴望一款简单、快速且高效的工具,以便更轻松地浏览和管理您的图像库?如果答案是肯定的,那么EdgeView 4 for Mac将是您的理想之选! EdgeView 4是一款专为Mac用户…...
的好处有哪些?)
流程自动化(RPA)的好处有哪些?
流程自动化(RPA)是一种通过软件机器人实现业务流程自动化的技术。它可以模拟人类在计算机上执行的操作,从而自动化重复性、繁琐的任务,提高工作效率和准确性。流程自动化(RPA)的好处很多,下面我…...

医学影像系统【简称PACS】源码
PACS(Picture Archiving and Comuniations Systems)即PACS,图像存储与传输系统,是应用于医院中管理医疗设备如CT,MR等产生的医学图像的信息系统。目标是支持在医院内部所有关于图像的活动,集成了医疗设备,图像存储和分…...

大家都在用哪些敏捷开发项目管理软件?
敏捷开发是一种以人为核心、迭代、循序渐进的开发方法。 敏捷开发的特点是高度灵活性和适应性、迭代式开发。 敏捷开发方法强调快速响应变化,因此它具有高度的灵活性和适应性。开发团队可以根据客户需求和市场变化快速调整开发计划和产品功能,以确保产品…...

python机器学习基础教程01-环境搭建
书籍源代码 github上源代码 https://github.com/amueller/introduction_to_ml_with_python 安装anaconda虚拟环境 创建虚拟环境 conda create -p E:\Python\envs\mlstupy35 python3.5 # 激活环境 conda activate E:\Python\envs\mlstupy35 # 创建学习目录 cd G:\Python\ml…...

TinyWebServer学习笔记-Config
为了弄清楚具体的业务逻辑,我们直接从主函数开始看源代码: #include "config.h"int main(int argc, char *argv[]) {//需要修改的数据库信息,登录名,密码,库名string user "root";string passwd "root";string databas…...

数据结构与算法--算法
这里写目录标题 线性表顺序表链表插入删除算法 一级目录二级目录二级目录二级目录 一级目录二级目录二级目录二级目录 一级目录二级目录二级目录二级目录 一级目录二级目录二级目录二级目录 线性表 顺序表 链表 插入删除算法 步骤 1.通过循环到达指定位置的前一个位置 2.新建…...
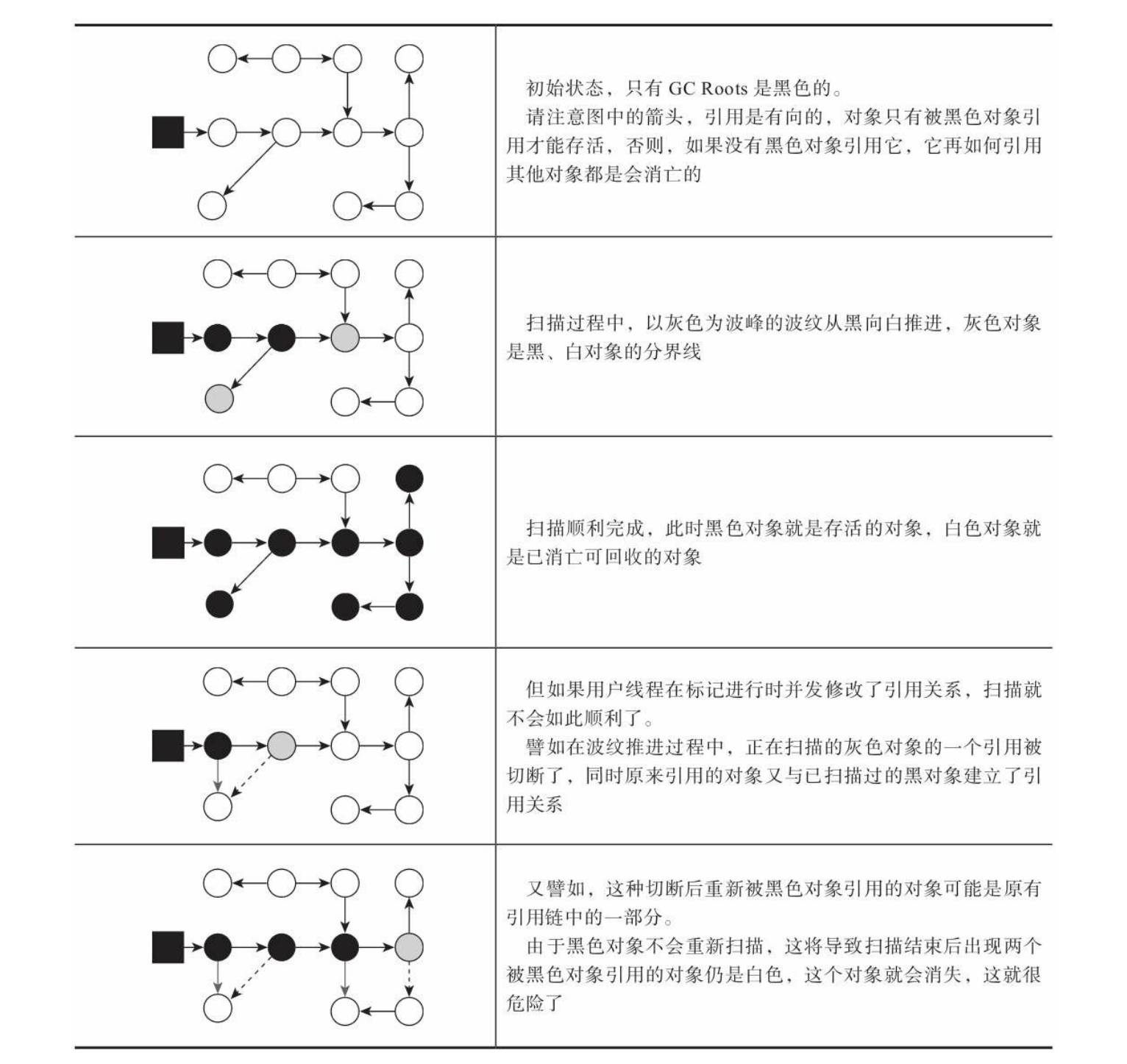
JVM:如何通俗的理解并发的可达性分析
并发的可达性分析 前面在介绍对象是否已死那一节有说到可达性分析算法,它理论上是要求全过程都基于一个能保障一致性的快照(类比 MySQL 的MVCC)中才能够进行分析,也就意味着必须全程冻结用户线程的运行(STW࿰…...

传统机器学习聚类算法——总集篇
工作需要,涉及到一些聚类算法相关的知识。工作中需要综合考虑数据量、算法效果、性能之间的平衡,所以开启新的篇章——机器学习聚类算法篇。 传统机器学习中聚类算法主要分为以下几类: 1. 层次聚类算法 层次聚类算法是一种无监督学习算法&am…...

Ajax
一、什么是Ajax <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"widthdevice-wid…...

SQL_ERROR_INFO: “Duplicate entry ‘9003‘ for key ‘examination_info.exam_id‘“
今天刷题的时候,往数据库中插入一条语句,但是这个语句已经存在于数据库中了,所以不能用insert into 语句来插入,应该使用replace into 来插入。 REPLACE INTO examination_info(exam_id,tag,difficulty,duration,release_time) V…...
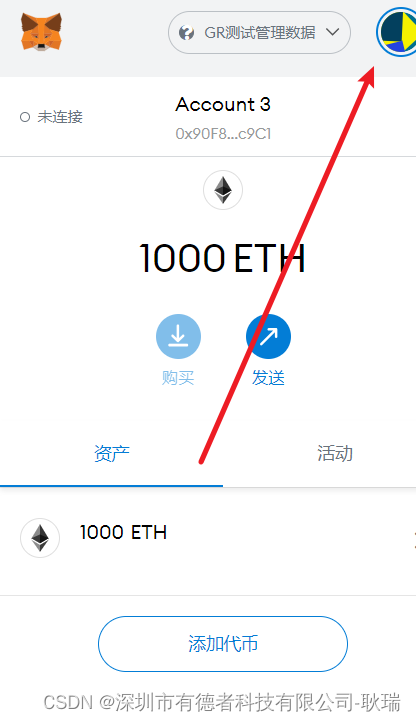
解决每次重启ganache虚拟环境,十个账号秘钥都会改变问题
很多时候 我们启动一个 ganache 环境 然后 通过私钥 在 MetaMask 中 导入用户 但是 当我们因为 电脑要关机呀 或者 ETH 消耗没了呀 那我们就不得不重启一个ganache虚拟环境 然后 你在切一下网络 让它刷新一下 你就会发现 上一次导入的用户就没有了 这是因为 你每次 ganache…...

sheng的学习笔记-【中文】【吴恩达课后测验】Course 2 - 改善深层神经网络 - 第一周测验
课程2_第1周_测验题 目录:目录 第一题 1.如果你有10,000,000个例子,你会如何划分训练/验证/测试集? A. 【 】33%训练,33%验证,33%测试 B. 【 】60%训练,20%验证,20%测试 C. 【 】98…...
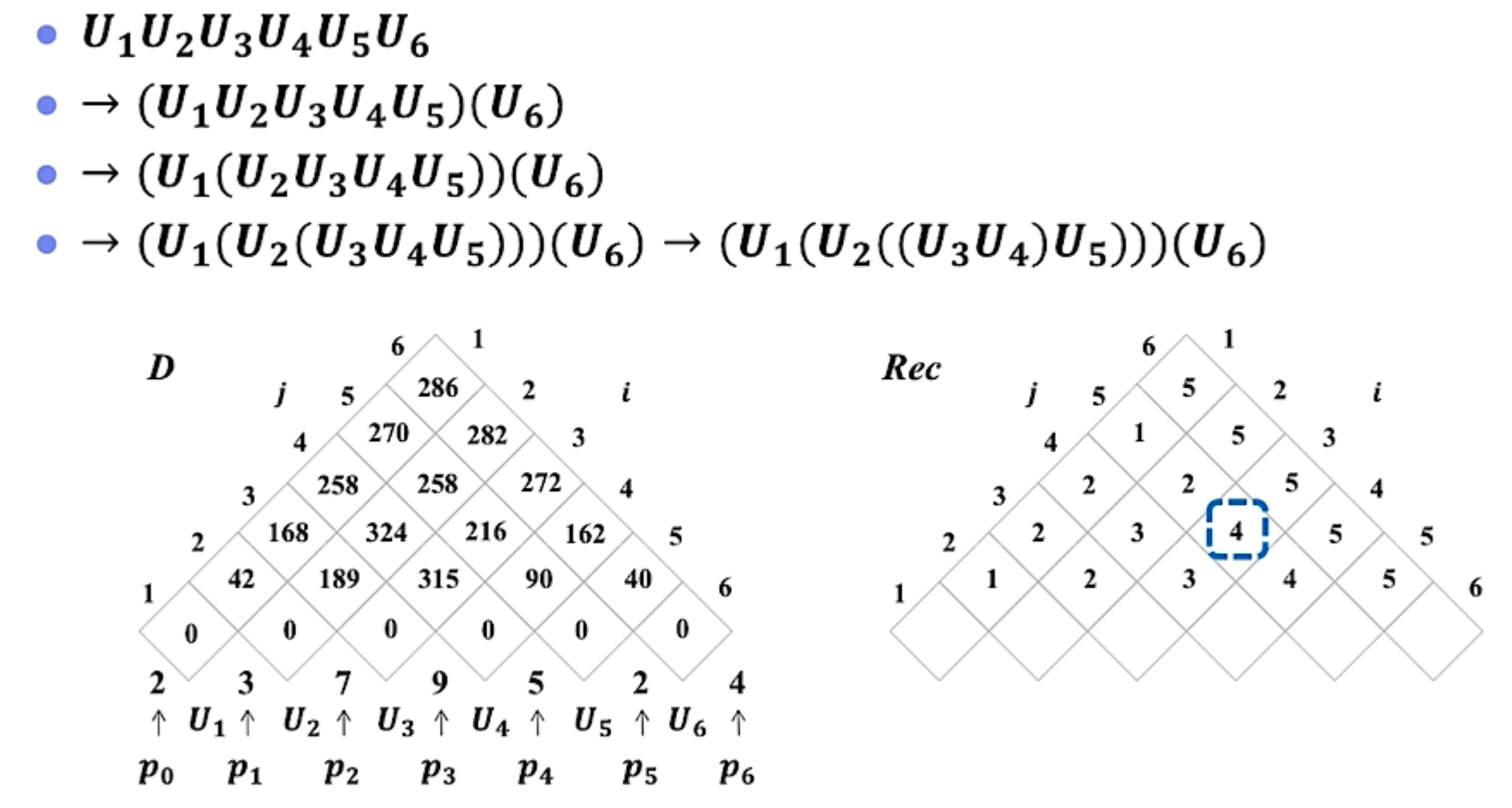
(粗糙的笔记)动态规划
动态规划算法框架: 问题结构分析递推关系建立自底向上计算最优方案追踪 背包问题 输入: n n n个商品组成的集合 O O O,每个商品有两个属性 v i v_i vi和 p i p_i pi,分别表示体积和价格背包容量 C C C 输出: …...
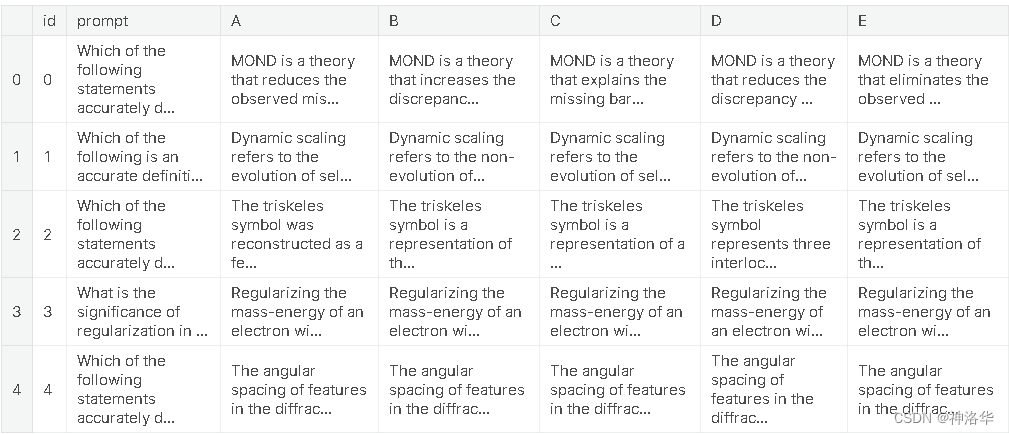
Kaggle - LLM Science Exam上:赛事概述、数据收集、BERT Baseline
文章目录 一、赛事概述1.1 OpenBookQA Dataset1.2 比赛背景1.3 评估方法和代码要求1.4 比赛数据集1.5 优秀notebook 二、BERT Baseline2.1 数据预处理2.2 定义data_collator2.3 加载模型,配置trainer并训练2.4 预测结果并提交2.5 相关优化 前言:国庆期间…...

数据分析三剑客之一:Numpy详解及实战
1 NumPy介绍 NumPy 软件包是Python生态系统中数据分析、机器学习和科学计算的主力军。它极大地简化了向量和矩阵的操作处理。Python的一些主要软件包(如 scikit-learn、SciPy、pandas 和 tensorflow)都以 NumPy 作为其架构的基础部分。除了能对数值数据…...

《机密计算破局政务金融、截图工具漏洞泄露NTLM哈希、智能体仿冒日增200+:AI安全的三场“攻防战”》
一、全链路机密计算破局:政务/金融敏感数据进入“可信推理”时代当前,大模型落地过程中面临的核心矛盾在于:越是高价值的专业技术领域,其训练数据和实时推理数据的安全级别就越高。在政务场景中,政府规划、财政数据、内…...

开源项目发布自动化:GitHub与ClawHub技能包一键发布工具详解
1. 项目概述与核心价值如果你和我一样,经常需要将本地开发的项目,尤其是那些为ClawHub平台准备的技能包,发布到GitHub并同步推送到ClawHub技能市场,那你一定对下面这个场景不陌生:每次发布前,都要在脑子里重…...

weave-compose实战:用Docker Compose语法轻松构建多主机容器集群
1. 项目概述与核心价值最近在折腾容器编排,特别是想找一个比Kubernetes更轻量、更贴近Docker原生体验的方案。在GitHub上闲逛时,发现了Adityaraj0421/weave-compose这个项目。乍一看名字,以为是Docker Compose的某个魔改版,但深入…...

HALO框架:硬件感知量化技术优化LLM推理
1. HALO框架:硬件感知量化技术解析在大型语言模型(LLM)的实际部署中,我们常常面临一个核心矛盾:模型规模的指数级增长与硬件算力提升缓慢之间的鸿沟。以LLaMA-65B和GPT-4为例,这些模型的参数量分别达到650亿…...

企业知识管理新方案:OpenCorpo开源项目部署与RAG架构实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 OpenCorpo。这名字听起来有点“高大上”,但说白了,它就是一个帮你把公司内部那些零散、混乱的文档、知识、流程给“盘活”的工具。想象一下,你公司里是不是有无数个共享…...

认知神经科学研究报告【20260062】
ForeSight 5.88.2 算术推理能力报告 主题:从个位数原子规则到多位数加减法的L4+自主涌现一、系统拥有的先验知识 系统仅被赋予 390 条个位数四则运算的原子事实(如 358、7963、1-7-6),这些是最底…...
linux删除无用依赖 —东方仙盟)
服务器运维(四十八)linux删除无用依赖 —东方仙盟
一、逐条安全性分析1. sudo dnf autoremove -y作用:删掉安装软件后遗留的无用依赖包风险:极低禁忌:你现在只跑 nginxmysqllua,没有冷门依赖,随便跑效果:清大量残留库、编译依赖2. sudo dnf clean all作用&a…...

工业仿真软件推荐指南|高解析度、低成本、自主可控的长期之选
在工业数字化与AI融合的当下,选择一款值得长期投入的工业仿真软件,已成为企业研发效率与成本控制的关键。面对市场上众多CAE/CFD软件,如何从“能用”到“好用”,再到“值得长期持有”,需要一套清晰的评估框架。本文将从…...

Windows Cleaner终极指南:5个技巧让C盘空间瞬间释放
Windows Cleaner终极指南:5个技巧让C盘空间瞬间释放 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows系统设计的开源…...

基于MCP协议构建AI工具服务器:从原理到企业级实践
1. 项目概述:一个连接上下文与工具的智能服务器最近在折腾AI应用开发,特别是想让大语言模型(LLM)能更“聪明”地使用外部工具和数据。我发现,很多项目要么是把工具调用逻辑硬编码在提示词里,要么就是搞一套…...